InnoDB内部架构
以一条更新语句,初步了解InnoDB存储引擎的架构设计:
Update users set name=’xxx’ where id = 10
Buffer Pool: 缓冲池
在读取id = 10的这条数据的时候,如果不在的话,从磁盘中加载到buffer pool,而且对这行数据加独占锁。
undo日志:保证数据可以回滚
回滚可以放在一个事务的任何地方,为了考虑未来可能的数据回滚,需要把更新前的数据写入undo日志文件。
undo日志是存储引擎层的日志,是InnoDB特有的。
Redo 日志:事务提交之后,保证数据的不丢失
分为redo log buffer(即内存中的redo日志)和redo日志
记录的是物理层面的重做日志:对哪个数据页中的什么数据行,做了什么修改(这里的数据页、数据行都是物理层面的概念)
redo日志也是存储引擎层的日志,是InnoDB特有的。
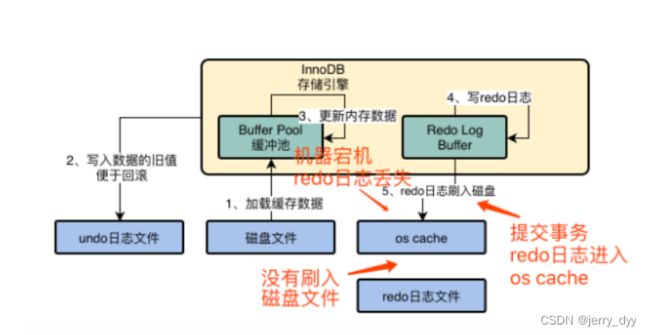
其中1,2,3,4步骤都是每次SQL执行都会去执行,5步骤是在提交事务的时候执行
redo日志的刷盘策略:
设置Innodb_flush_log_at_trx_commit
0:提交事务的时候,不会把redo log buffer刷入磁盘
1:提交事务的时候,会把redo log buffer刷入os cache,并且刷入redo日志文件中
2:提交事务的时候,会把redo log buffer刷入os cache中,然后每过1秒将os cache中的内容输入redo日志文件
默认为1,也就是1的时候,才能完全保证Mysql不丢失数据,才能保证Mysql事务的持久化特性
Binlog日志:归档日志
记录的是逻辑性质的日志,记录的是SQL语句:对users表中的id=10的记录做了更新操作,更新以后的值是什么
Binlog不是InnoDB特有的,是Mysql Server本就有的日志文件,是Server层的日志
提交事务的时候,会写binlog日志
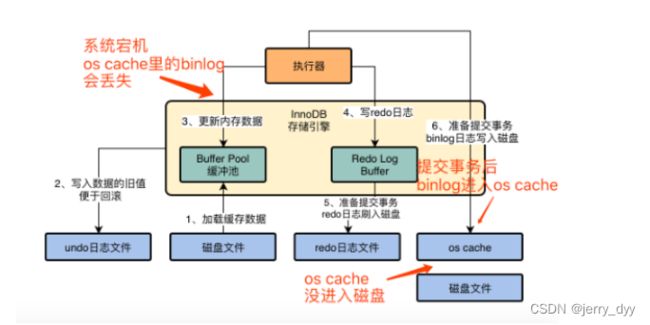
1,2,3,4步骤在执行每条SQL语句的时候都会进行,5,6步骤是提交事务的时候进行的
Binlog日志的刷盘策略:
设置sync_binlog
0:每次提交事务的时候,其实是把binlog写入到了os cache(内存缓存),如果机器宕机,是可能会丢失的
1:每次提交事务的时候,把binlog写入到磁盘文件中,即使机器宕机,也不会丢失数据
默认为0
基于binlog和redo log完成事务的提交
把本次更新对应的binlog文件名称、binlog文件位置都写入到redo log中;同时在redo log文件日志中写入一个commit标记
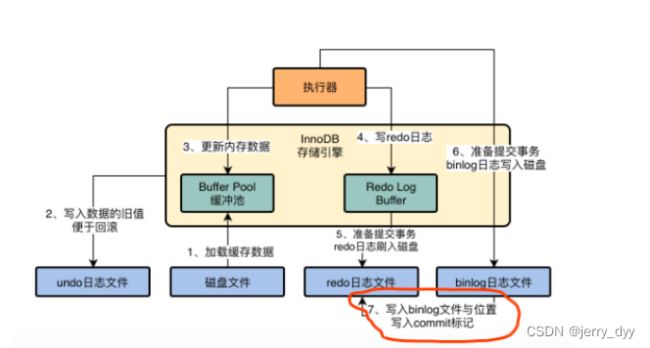
1,2,3,4步骤在执行每条SQL语句的时候都会进行,5,6,7步骤是提交事务的时候进行的
其中commit标记是为了保证redo log与binlog的同步:
假如刚完成了5操作,数据库机器宕机了,那么就不会任务事务时成功的,只有6,7步骤全部进行完,有了commit标志,才会认为这个事务成功了
后台IO线程随机将内存更新后的数据刷回磁盘
后台IO会在之后的某个时间,随机地把内存buffer pool中修改后的脏数据刷回磁盘上的数据文件里去
在IO线程没有把数据刷回磁盘之前,如果数据库机器宕机,也没关系,重启之后,会根据redo日志恢复之前提交事务做过的修改到buffer pool中,IO线程还是会后面某个时间把这个数据刷到磁盘文件中的
思考:
Mysql的缓存机制:
整个Mysql数据库其实是会使用到内存中,使用内存做缓存,但是这和redis的缓存机制不太一样,Mysql主要维护的就是这个缓存,通过undo日志、redo日志、binlog日志来保证缓存数据的正确性,然后后台IO线程不定期将缓存数据刷回磁盘。
为什么不直接写磁盘?而要去写redo日志、undo日志搞得这么复杂?
直接去写磁盘,肯定面临的是随机磁盘IO操作,而写redo日志、undo日志则是顺序IO,顺序磁盘IO的效率是远远高于随机磁盘IO的,因为随机磁盘IO还得去转动磁臂,去寻找扇区、磁道什么的。
效率比较:
直接写磁盘(随机IO) < 顺序磁盘IO(redo日志、undo日志、binlog日志)维护缓存数据正确性 < 只写缓存
Mysql内部架构_jerry_dyy的博客-CSDN博客
Mysql存储模型_jerry_dyy的博客-CSDN博客
InnoDB内部架构_jerry_dyy的博客-CSDN博客
Buffer Pool 核心原理_jerry_dyy的博客-CSDN博客
Buffer Pool生产实践_jerry_dyy的博客-CSDN博客
Mysql事务隔离机制_jerry_dyy的博客-CSDN博客
Mysql的锁机制_jerry_dyy的博客-CSDN博客
Mysql的索引深度讲解_jerry_dyy的博客-CSDN博客
Mysql索引的使用_jerry_dyy的博客-CSDN博客
SQL语句的执行计划_jerry_dyy的博客-CSDN博客_sql语句的执行计划