在ubuntu64下实现 小型 C 运行时库
前言
最近看的《程序员的自我修养——链接、装载与库》也将告一段落了,虽然说里面的很多核心知识,我还是没有搞懂,但是看完之后真的受益匪浅,大开眼界,真不愧是一本宝书,真的拥有它就用了财富。既然大致读完了,那肯定要把最后的终极练习写了,不然那算哪门子看完,只有动手实践才能理解的更加深刻。
这本书由于出版的时间太早了,使用的操作系统是32位的,所以如果在64位操作系统上进行实操,根据这本书的讲解是会有不少编译错误出现,因为64位操作系统的系统调用号是不一样的,汇编指令也不是很一样,所以遇到不少知识不仅要查资料,还要学会模仿,变通。
系统调用和运行时库
可能很多人都听过系统调用和运行时库,但让你说出他们有什么区别,可能大部分人就无法说个一二。先来看个图:

从图来看 library rountines 包裹着系统调用,但是有不完全包裹,其实我们可以说运行时库是对系统调用的封装,但运行时库里的函数并不是所有函数都对系统调用进行封装,只有当调度系统资源的时候,我们才会需要用到系统调用,举个例子:fread 这个函数,就是c运行时库对系统调用 read 的 一个封装

在书中他的实现大致是这样的,看下方代码:
/* read syscall number 0 */
static int read(int fd, void * buffer, unsigned size){
int ret = 0;
asm("movl $0, %%eax \n\t"
"movl %1, %%ebx \n\t"
"movl %2, %%ecx \n\t"
"movl %3, %%edx \n\t"
"syscall \n\t"
"movl %%eax, %0 \n\t"
: "=m"(ret): "m"(fd),"m"(buffer),"m"(size));
return ret;
}
int fread(void *buffer,int size,int count,FILE * stream){
return read((int)stream, buffer, size * count);
}
这个只是一个非常轻微的实现一个基本功能,真实的glibc库实现的十分复杂,不过在这里够用了。
fread()是对 read()的一个封装,而read()里面内联了一个汇编代码,这个代码的功能其实就是调用read系统调用,让内核帮我们做一些事情,这些事情是用户态进程没法做到的。就如这个read,我们要读取系统资源,但是在进程的用户态是不允许去访问系统资源的,所以我们要调用系统调用的时候,传进去一个系统调用号,放到 eax 寄存器中,参数都放到寄存器中,之后发生中断,从用户态进程转变为内核态,且切换用户栈为内核栈,然后根据我们的系统调用号,从系统调用表中,找到我们要执行的操作,内核帮我们执行,这里read就是,从内核空间向用户空间拷贝数据,当拷贝完成后,切换回用户态,此时我们的指针所指向的地址上,就有了我们想要读取的数据了。这里我把这张图搬过来:
系统调用是在内核空间进行执行的,也可以说系统调用会触发中断,使用户态切换为内核态,在内核空间执行函数的调用。
那么这里在举一个c运行时库不执行系统调用的函数例子:
unsigned strlen(const char *str){
if(str == NULL){
return 0;
}
unsigned ret = 0;
while(*str != '\0'){
str++;
ret++;
}
return ret;
}
这个函数就不需要执行系统调用,不需要发生中断,在用户态就可以完成,不涉及用户态到内核态的转变。
那么做个总结系统调用和运行时库函数的区别:
- c运行时库实现了对系统调用的封装,但c运行时库中的函数不一定是系统调用的封装。
- 系统调用会触发中断,进程从用户态陷入内核态。系统调用是对kernel的封装。
那么来看一下系统调用的执行流程图:
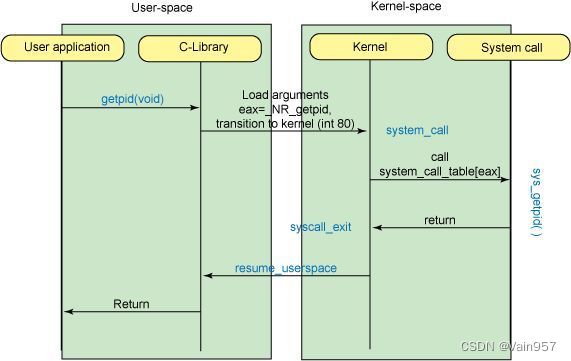
不懂可参考这位大佬的文章:Linux系统调用原理
此时我们已经理解系统调用与c运行时库了,也就是说由于c语言实现了对系统调用的封装,我们现在才能如此简单的使用c语言的库函数做丰富的操作,且十分简单方便。
程序从main函数开始的吗
先说结论:不是
先举个例子,c++ 的析构函数,在 int main()申请个类对象,当int main结束后,析构函数会执行,那他就是在main结束后执行的。还有int main()结束就代表程序结束了吗,其实在main()结束后会执行exit()函数,main 的返回值就是exit()的参数,所以可以理解为什么main 要return 0了吧,return 0其实是将返回的参数传入exit(0)中,0是状态码,标识这个进程是正常结束的,如果是1,或者其他值,那代表其他状态,表示这个进程是怎么怎么样结束的,后续可能会根据这个状态码打印log,用于调试也说不定。
那么很明显了,exit()这个函数肯定是一个系统调用,那么他的作用呢?其实就是结束进程,只有调用exit()进程资源才会被操作系统回收,不然这个进程就会一直跑,直到触发段错误。那么为什么我们平常的写法没见过exit呢?原因当然是glibc的库他自动调用了,他帮你做了这类操作,你只用在主线程里实现一下自己的逻辑,就不用关心其他操作了。
那么在main之前有操作吗,答案是有,在执行main之前,需要初始化堆和io。如下图解释的那:

那么理解了这一点,对于我们写c的运行时库就有更近了一步,毕竟我们不准备依赖c的glibc库,那么我们 的程序就不会执行glibc给我们的一切,那么我们就需要自己实现,让进程结束,让进程在终端打印,读取文件操作,等等的一类活动。
堆和栈
堆和栈的区别,相信大家都知道。但这里说的不是栈递增的方向和堆递增的方向之类的,而是从管理角度来讲,栈内存是操作系统自己管理,而堆内存是由程程序员管理,我们写代码的时候用c需要malloc, free, c++时需要 new delete,但是如果每次申请和释放都要向操作系统申请,那么就会严重影响系统的性能,毕竟过多的使用系统调用会大大影响系统开销的。那么此时就需要一个中间人来管理内存,而操作系统,只负责和中间人进行交互就行了,不需要和程序员交互,这里举个例子:
程序员 malloc 操作系统,这三个互相信任,存在一个借东西和还东西的逻辑,程序员每次向malloc借的内存是很少量的,malloc 向操作系统借的东西是比较大量的,如果程序员使用的是1,那么malloc就是1000,但是虽然他们是相互信任的,但是程序员这个老6,常常不守信用,不还东西,其实程序员也不想啊,但是有些粗心的程序员或者阅历不够的程序员在使用系统调用及申请的内存时,总是忘记还,这就造成了我们经常说的内存泄漏。那么还是存在很多明智的程序员懂得还的,品质优良,他们把这些不用的内存还给malloc,此时malloc不会立即把内存还给操作系统,而是把这些内存重新整理整理放到货架上,等下次程序员来申请的时候重新拿给他用,那么就大大减少了系统调用操作,提升了效率。
那么我们要实现c运行库,实现堆管理内存是必须完成的,栈的话是由操作系统管理的,我们不需要管。
实现strcpy拷贝输出
这里要实现的是,将栈内存上的数据拷贝到堆上。
因为我们不依赖glibc库,所以我们需要先写一个入口函数,让进程执行的时候先进入这里来执行,如下:
extern int my_main(int argc,char * argv[]);
void exit(int exitcode);
void _entry(){
int ret;
int argc;
char **argv;
char *ebp_reg = 0;
asm("movq %%rbp, %0 \n" :"=r"(ebp_reg));
argc = *(int *)(ebp_reg + 4);
argv = (char**)(ebp_reg + 8);
if(!heap_init()){
fputs("heap_init error!", stdout);
}
ret = my_main(argc, argv);
exit(ret);
}
void exit(int exitcode){
asm("movq %0, %%rbx \n\t"
"movq $60, %%rax \n\t"
"syscall \n\t"
"hlt \n\t"
::"m"(exitcode));
}
那么如何指定_entry位程序入口呢,我们可以在链接的时候用 -e 这个参数来指定,下面给出我的编译shell,automake.sh
gcc -g -c -fno-builtin -nostdlib -fno-stack-protector *.c
ar -rs minicrt.a heap_init.o io_init.o pint.o string.o
ld -static -e _entry entry.o test.o minicrt.a -o test
mv test ./bin/
rm *.o
rm minicrt.a
下面是关于gcc 参数的解释

my_main是我们的主线程,它就是我们经常使用的 int main,在执行 my_main之前,需要先执行一些初始化操作。
比如我们平常在Linux 执行一个进程的时候:./main 这种,他的这个参数就会传进栈空间来,那么我门要如何获取这个值呢,并将其打印出来?接下来看一个图

我反汇编了这个代码的执行,然后看这个图:

因为Linux 栈是向下增长的,所以可以推测出 ebp+4 = argc ebp+8 = argv ,那么我们就可以通过ebp的地址得到这两个参数的值。接下来就要初始化我们的堆了,具体措施是,通过brk系统调用向操作系统申请32M的内存,malloc对这一片区域施行管理,申请一块我们就对整体进行分裂,释放一块,就看是否可以合并,如此类推:
#include "header.h"
#define ADDR_ADD(a,o) (((char*)(a)) + o)
typedef struct _heap_header{
enum{
HEAP_BLOCK_FREE = 0xABABABAB,
HEAP_BLOCK_USED = 0xCDCDCDCD
} _use_stat;
unsigned size;
struct _heap_header * next;
struct _heap_header * prev;
} heap_header;
#define HEADER_SIZE (sizeof(heap_header))
static heap_header * list_head = NULL;
void* malloc(unsigned size){
heap_header * header;
if(size == 0)return NULL;
header = list_head;
while(header != NULL){
if(header->_use_stat == HEAP_BLOCK_USED){
header = header->next;
continue;
}
if(header->size > size + HEADER_SIZE && header->size <= size + HEADER_SIZE * 2){
header->_use_stat == HEAP_BLOCK_USED;
}
if(header->size > size + HEADER_SIZE * 2){
/* split block */
heap_header * next = (heap_header *)ADDR_ADD(header, size + HEADER_SIZE);
next->prev = header;
next->next = header->next;
next->_use_stat = HEAP_BLOCK_FREE;
/* clac next memory */
next->size = header->size - (size + HEADER_SIZE);
header->next = next;
header->size = size + HEADER_SIZE;
header->_use_stat = HEAP_BLOCK_USED;
/* Maintain doubly linked list */
if(next->next != NULL){
next->next->prev = next;
}
return ADDR_ADD(header, HEADER_SIZE);
}
header = header->next;
}
return NULL;
}
void free(void * ptr){
heap_header * header = (heap_header*)ADDR_ADD(ptr, -HEADER_SIZE);
if(header->_use_stat != HEAP_BLOCK_USED){
return;
}
header->_use_stat = HEAP_BLOCK_FREE;
if(header->prev != NULL && header->prev->_use_stat == HEAP_BLOCK_FREE){
/* merge */
header->prev->next = header->next;
if(header->next != NULL){
header->next->prev = header->prev;
}
header->prev->size += header->size;
header = header->prev;
}
if(header->next != NULL && header->next->_use_stat == HEAP_BLOCK_FREE){
/* merge */
header->size += header->next->size;
header->next = header->next->next;
if(header->next != NULL){
header->next->prev = header;
}
}
}
static int brk(void * end_data_segment){
int ret = 0;
/*x64 brk syscall number 12 */
asm( "movl $12, %%eax \n\t"
"movl %1, %%ebx \n\t"
"syscall \n\t"
"movl %%eax, %0 \n\t"
: "=r"(ret): "m"(end_data_segment) );
return ret;
}
int heap_init(){
void * base = NULL;
heap_header * header = NULL;
unsigned heap_size = 1024 * 1024 * 32;
base = (void*)brk(0);
void * end = ADDR_ADD(base, heap_size);
end = (void *)brk(end);
if(!end)
return 0;
header = (heap_header*)base;
header->size = heap_size;
header->_use_stat = HEAP_BLOCK_FREE;
header->next = NULL;
header->prev = NULL;
list_head = header;
return 1;
}
现在我们来实现一个简单操作,malloc 一个内存空间,然后将拷贝一个字符串到这部分内存上,并将拷贝的字符串打印到终端上,主函数我们自己定义,我定义成了 my_main(int argc,int argv)。我们来实现一下IO操作,通过内联汇编,不依靠glibc库,封装一个可以打印字符到终端上的库函数。如下:
/* write syscall number 1 */
static int write(int fd, const void * buffer, unsigned size){
int ret = 0;
asm("movl $1, %%eax \n\t"
"movl %1, %%ebx \n\t"
"movl %2, %%ecx \n\t"
"movl %3, %%edx \n\t"
"syscall \n\t"
"movl %%eax, %0 \n\t"
: "=m"(ret): "m"(fd),"m"(buffer),"m"(size));
}
int fputc(int c, FILE *stream){
if(fwrite(&c, 1, 1, stream) != 1){
return EOF;
}else{
return c;
}
}
int fputs(const char *str, FILE *stream){
int len = strlen(str);
if(fwrite(str, 1, len, stream) != len){
return EOF;
}else{
return len;
}
}
现在有了打印字符串的库函数,打印到终端的操作其实就是像1号文件描述符写数据,即可实现打印到终端上操作,因为在创建进程时,会将0,1文件描述符注册到这个进程的文件描述符表里,自动打开。
此时只需要再实现一个字符串拷贝的函数即可完成操作。函数如下:
char * strcpy(char * dest,const char *src){
char * ret = dest;
while(*src){
*dest++ = *src++;
}
*dest = '\0';
return ret;
}
这里把头文件给出来,里面一些函数定义并不涉及这个实验,但是可以继续扩充,这个小小的项目只是一个知识框架,如果感觉很low,可以继续向其中扩充库函数,实现一个属于自己的库函数。
#ifndef _HEADER_H
#define _HEADER_H
#define NULL 0
#define O_RDONLY 00
#define O_WRONLY 01
#define O_RDWR 02
#define O_CREAT 0100
#define O_TRUNC 01000
#define O_APPEND 02000
typedef int FILE;
#define EOF (-1)
#define stdin ((FILE*) 0)
#define stdout ((FILE*) 1)
#define stderr ((FILE*) 2)
void * malloc(unsigned size);
void free(void *ptr);
int heap_init();
/* char * itoa(int n,char * str, int radix); */
int strcmp(const char * src, const char *dst);
char *strcpy(char *dest, const char *src);
unsigned strlen(const char *str);
FILE *fopen(const char *filename,const char *mode);
int fread(void *buffer,int size,int count,FILE * stream);
int fwrite(const void *ptr,int size,int count,FILE * stream);
int fclose(FILE * stream);
int fseek(FILE * stream, int offset, int set);
int fputc(int c, FILE *stream);
int fputs(const char *str,FILE *stream);
#endif
最后写一个测试程序,使用静态链接的方式,将我们实现的库打包成静态库,链接的时候链接进来,实现我测试程序的功能
测试程序:
#include "header.h"
int my_main(int argc,char *argv[]){
/* print argv[]*/
fputs(argv[1],stdout);
fputc('\n',stdout);
char * heaps = (char*)malloc(20);
strcpy(heaps,"Hello World!\n");
fputs(heaps, stdout);
free(heaps);
return 0;
}
测试结果:

当然还能做很多有意思的实现,这里看大家的兴趣了,如果感兴趣,可以更充实自己的库函数,当然做这个项目也很有意义,能更清楚的理解语言库函数背后发生了什么,他们又是如何产生的,这才是做这个项目的真正意义。
总结
我实现的这个,非常的局限,只添加了一些非常简单的逻辑操作,不过用来理解背后的一些机制 已经够用了,有时间的时候再添加新的库函数。在malloc 的时候他的实现也是比较简单的,只使用了brk系统调用,没有使用mmap系统调用分配内存,真实的glibc库是异常复杂的,例如printf 是线程安全的,考虑的事情是非常多的,我们当然是很难完成的,所以不必纠结自己的项目太拉跨,这里能学到的东西是非常有用的,甚至说不少的面试官他对背后发生了什么也不得而知,所以不要做一个只会搬砖的码农。