[ 数据结构 -- 手撕排序算法第六篇 ] 归并排序(下)-- 非递归方法实现
手撕排序算法系列之第六篇:归并排序(下)
从本篇文章开始,我会介绍并分析常见的几种排序,大致包括直接插入排序,冒泡排序,希尔排序,选择排序,堆排序,快速排序,归并排序(上)等。
大家可以点击此链接阅读其他排序算法:排序算法_大合集(data-structure_Sort)
本篇我们一起来手撕归并排序的非递归实现方法
目录
1.归并排序非递归的思想
2.归并排序非递归的实现步骤及注意事项
2.1实现步骤
2.2 注意事项
2.2.1谨防区间访问越界
2.2区间修正
3.归并非递归的代码实现
4.归并排序非递归测试
5.归并排序的特性总结
1.归并排序非递归的思想
在上一篇我们我们形象的演示了归并排序的整个过程,其实归并的非递归是和递归的思想是一样的,只不过原来我们是大区间划小区间采用递归的方式解决,而归并的非递归方法是对数组元素进行分组,然后直接合并的过程。这不过这个过程中的细节要比归并多很多。
归并排序的递归流程:
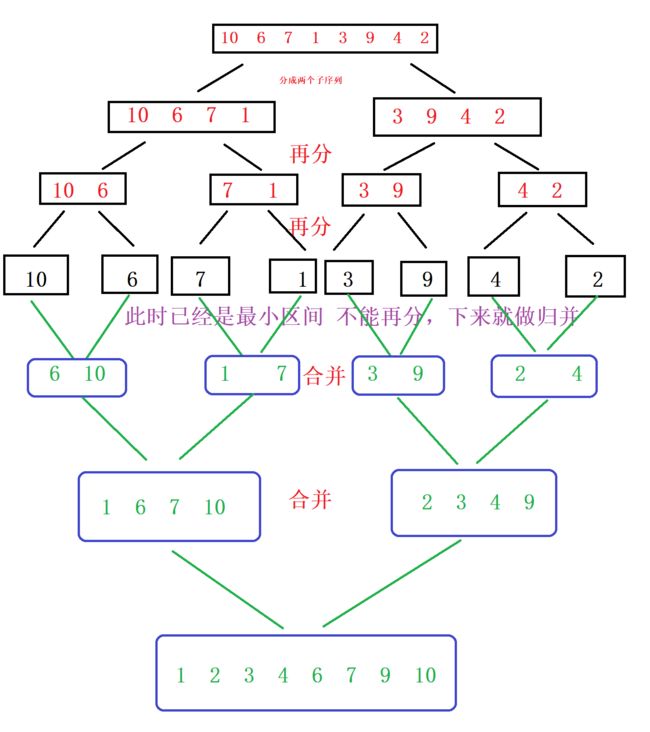
归并排序的非递归流程是直接从合并开始的。
2.归并排序非递归的实现步骤及注意事项
2.1实现步骤
归并排序的非递归是对小区间进行合并然后再拿到小区间进行合并直到拿到整个数组。
具体步骤如下:
1、我们定义一个gap变量,这个gap是用来控制分组的,归并排序的合并过程使用一个数据的最小区间进行合并,然后到2个,4个,8个等等。
2、初始这个gap变量的值是1,因为我们合并过程是对两个有序数组进行合并,因此其实gap等于1我们可以来让数组的每个数据成为一个最小区间。这就达到了我们递归中分解的那个作用。
3、我们要考虑到数组非常大,因此我们要对这两个区间的begin和end做出合理的划分。我们需要使用循环来进行对不用区间的合并。这里我们 区间1[i,i+gap-1];区间2[i+gap,i+2*gap-1]。
4、区间划分好后就是合并的过程,这一步的思想和逻辑就是归并的逻辑,不难。
5、到这里我们对一个相邻的两个小区间进行了合并,合并好后memcpy到原数组即可。
因为我们是同步对整个数组进行等gap的划分,因此当一组gap划分完后我们要修正区间的大小,要对更大的区间进行合并(由于是对两个区间合并,因此我们让gap = gap*2就可达到要求)。
6、最后我们只需要将临时拷贝的数组memcpy到原数组,再free掉新开辟的数组即可。
我们再来通过画图来更加了解这一过程
![[ 数据结构 -- 手撕排序算法第六篇 ] 归并排序(下)-- 非递归方法实现_第1张图片](http://img.e-com-net.com/image/info8/a6852caa73364374b18781ca07abb597.jpg)
2.2 注意事项
2.2.1谨防区间访问越界
在上述所做的步骤中,局限性是非常大的,因为我们在扩大区间的时候总是给gap*2来进行调整,而由于我们对区间合并时是对2个区间进行合并的,因此我们只有当数组的元素是2的倍数时才能百分百保证没问题,但是我们并不能保证所有的数组都只有2的倍数个大小的数据,如果不是2的倍数呢,会造成什么问题?
答:这时就很有可能造成区间越界。
为了更好的演示这种情况,我们就以刚刚的例子(6个数据)为例,我们将这个非递归归并一直做下去,做到结束。
![[ 数据结构 -- 手撕排序算法第六篇 ] 归并排序(下)-- 非递归方法实现_第2张图片](http://img.e-com-net.com/image/info8/c870a1f284c64d5b804100a9546b14c0.jpg)
并且我们可以通过打印区间看看是否造成了这种现象。
![[ 数据结构 -- 手撕排序算法第六篇 ] 归并排序(下)-- 非递归方法实现_第3张图片](http://img.e-com-net.com/image/info8/9144e4d9da034357b573a3a08953dd67.jpg)
我们发现和我们分析的一模一样。因此我们需要对区间进行修正:
2.2区间修正
在上述过程发现区间2的end2出现越界的风险,其实在begin1,end1,begin2,end2中,只有begin1没有越界的风险,因为begin1等于i,只要i能进入循环就说明begin1不越界
那么我们怎么对区间进行修正呢,其实我们只需要考虑我们到那种情况怎么进行归并即可。在上述情况中,第二次分组时,第一到4个元素分到了第一组,原本归并思想第二组也是4个元素,但是由于整个数组只有6个元素,就剩下了2个元素,因此我们第二组就让 剩下的两个元素成一个组即可。
因此我们对区间进行修正如下:
// end1 越界,修正
if (end1 >= n)
end1 = n - 1;
// begin2 越界,第二个区间不存在
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
// begin2 ok, end2越界,修正end2即可
if (begin2 < n && end2 >= n)
end2 = n - 1;
修正end1:
当end1越界时,让end1等于最后一个元素下标即可。 end1 = n-1
修正begin2:
如果begin2越界,就说明第二个区间并不存在,我们都不需要合并了,因为区间2不存在,区间1就是我们最终的数组,因此我们就让区间2搞成一个不存在 begin = n,end2 = n-1.
修正end2:
当begin2ok,end2越界时,我们修正end2等于最后一个元素下标即可。 end2 = n-1
![[ 数据结构 -- 手撕排序算法第六篇 ] 归并排序(下)-- 非递归方法实现_第4张图片](http://img.e-com-net.com/image/info8/e5bd9092cd0e4b90b13bcf6f2784f46e.jpg)
此时我们测试一下发现:没什么错了。
3.归并非递归的代码实现
//归并排序 -- 非递归
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1;
while (gap < n)
{
// 间距为gap是一组,两两归并
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// end1 越界,修正
if (end1 >= n)
end1 = n - 1;
// begin2 越界,第二个区间不存在
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
// begin2 ok, end2越界,修正end2即可
if (begin2 < n && end2 >= n)
end2 = n - 1;
printf("归并[%d,%d][%d,%d]\n", begin1, end1, begin2, end2);
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
tmp[index++] = a[begin1++];
else
tmp[index++] = a[begin2++];
}
while (begin1 <= end1)
tmp[index++] = a[begin1++];
while (begin2 <= end2)
tmp[index++] = a[begin2++];
}
memcpy(a, tmp, n * sizeof(int));
//PrintArray(a, n);
gap *= 2;
}
free(tmp);
}4.归并排序非递归测试
//归并排序 -- 非递归
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1;
while (gap < n)
{
// 间距为gap是一组,两两归并
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// end1 越界,修正
if (end1 >= n)
end1 = n - 1;
// begin2 越界,第二个区间不存在
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
// begin2 ok, end2越界,修正end2即可
if (begin2 < n && end2 >= n)
end2 = n - 1;
printf("归并[%d,%d][%d,%d]\n", begin1, end1, begin2, end2);
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
tmp[index++] = a[begin1++];
else
tmp[index++] = a[begin2++];
}
while (begin1 <= end1)
tmp[index++] = a[begin1++];
while (begin2 <= end2)
tmp[index++] = a[begin2++];
}
memcpy(a, tmp, n * sizeof(int));
//PrintArray(a, n);
gap *= 2;
}
free(tmp);
}
//归并排序
void TestMergeSort()
{
int a[] = { 6,1,2,7,9,3,4,5,10,8 };
MergeSortNonR(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
int main()
{
//归并排序
TestMergeSort();
return 0;
}测试结果:
![[ 数据结构 -- 手撕排序算法第六篇 ] 归并排序(下)-- 非递归方法实现_第5张图片](http://img.e-com-net.com/image/info8/94e66fa3d0c74d6db8f5ee684c31d18d.jpg)
5.归并排序的特性总结
归并排序的特性总结:1. 归并的缺点在于需要 O(N) 的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。2. 时间复杂度: O(N*logN)3. 空间复杂度: O(N)4. 稳定性:稳定
至此,归并排序的递归和非递归都实现啦, 排序算法也完成啦,感谢各位的关注和支持
我将所有的排序算法总结到了一个专栏,大家可以收藏专栏持续阅读~
[数据结构 - C实现 ] 排序算法 专栏
(本篇完)