Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<六>--电子书管理功能开发二
在上一次Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<五>--电子书管理功能开发已经实现了电子书管理列表的分页加载功能,接下来则继续来完善剩下的功能。
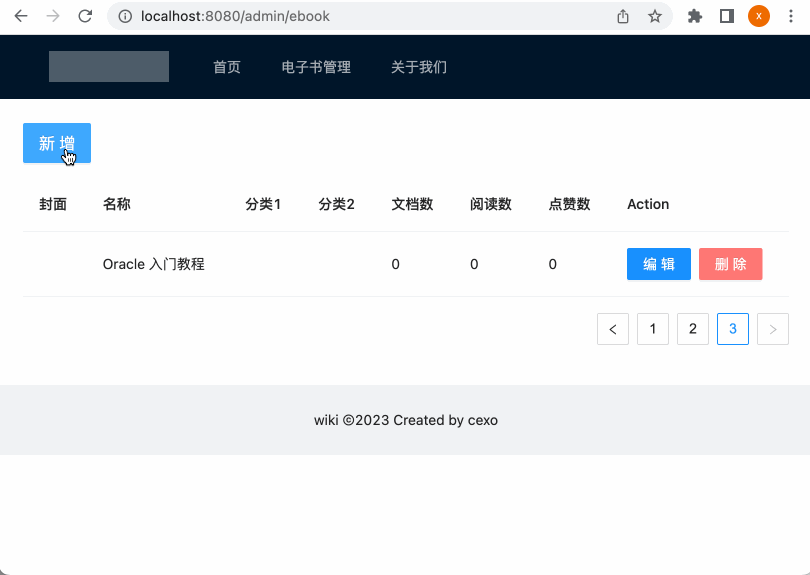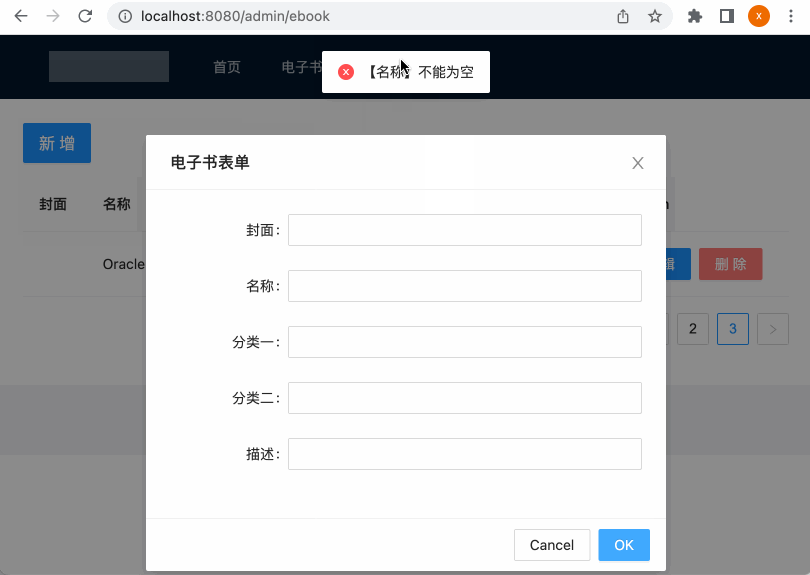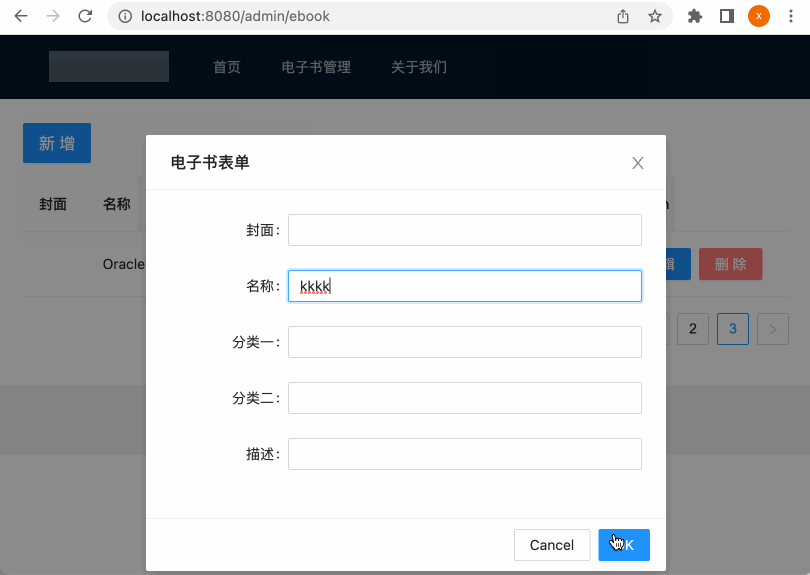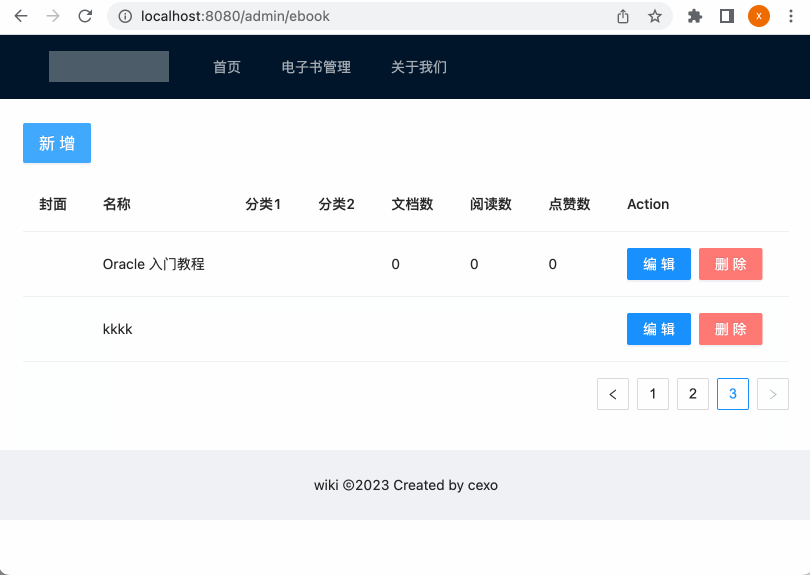
制作电子书表单:
点击每一行编辑按钮,弹出编辑框:
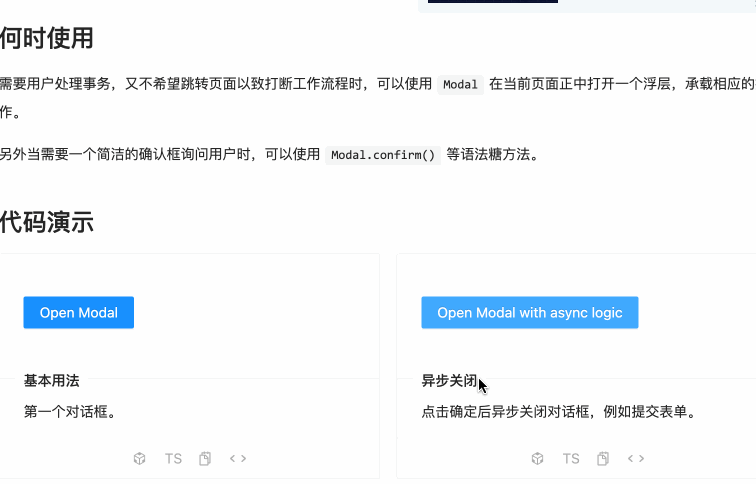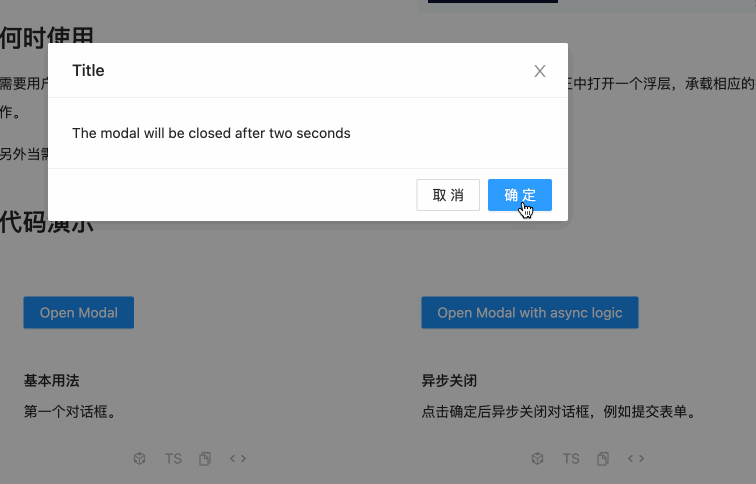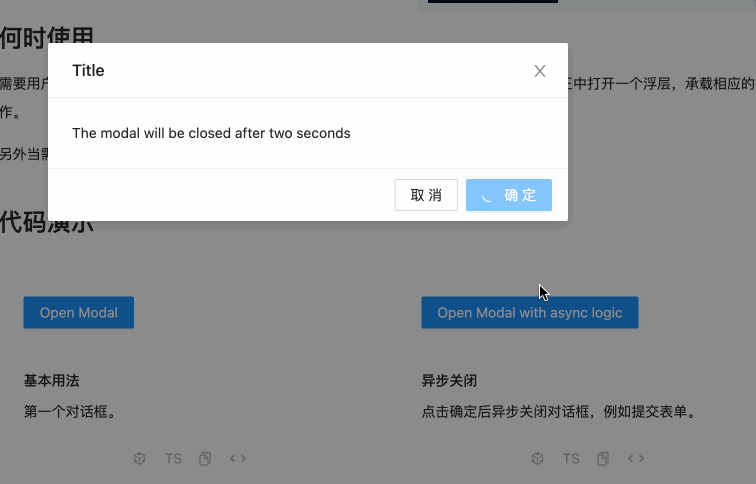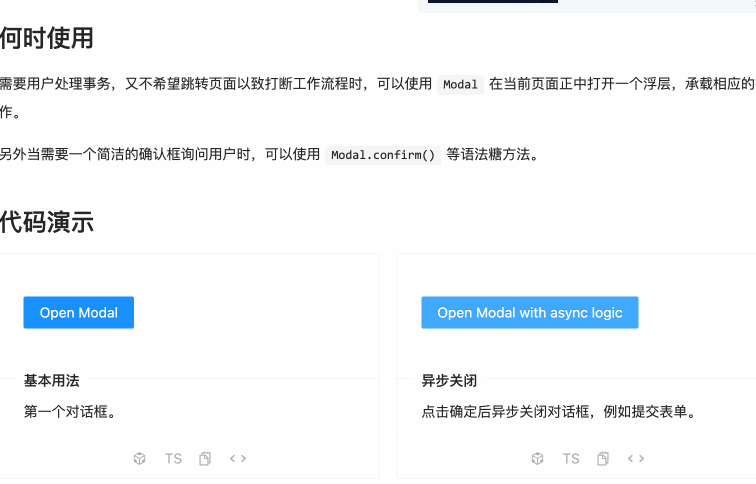
1、上Ant Design Vue找到合适的效果组件:
点击编辑需要且个弹框,所以先来找一个合适的显示框:
选择这样的一个效果:
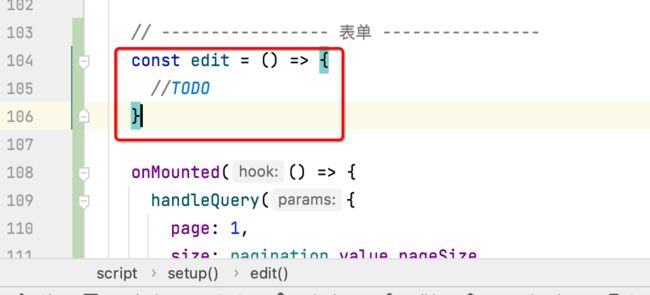
2、编辑按钮增加点击事件:
接下来咱们在点击编辑时,弹出这么一个效果弹框:

3、将对话框的代码从官网拷贝至工程中:

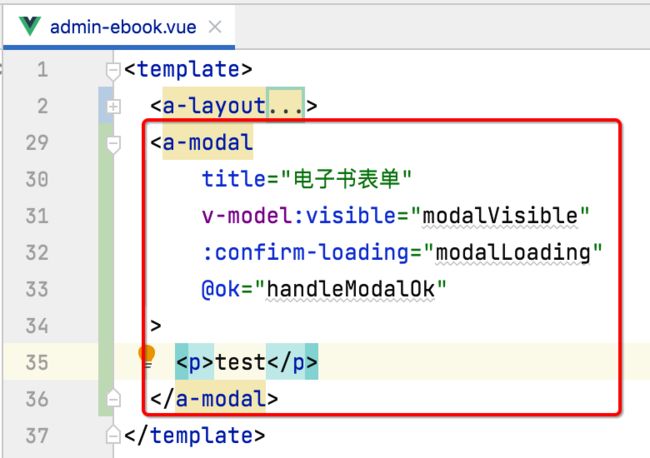
这里有一个细节需要了解一下,就是在Vue2中,是不支持template下有多个子节点的,也就是如果在Vue2中,需要将
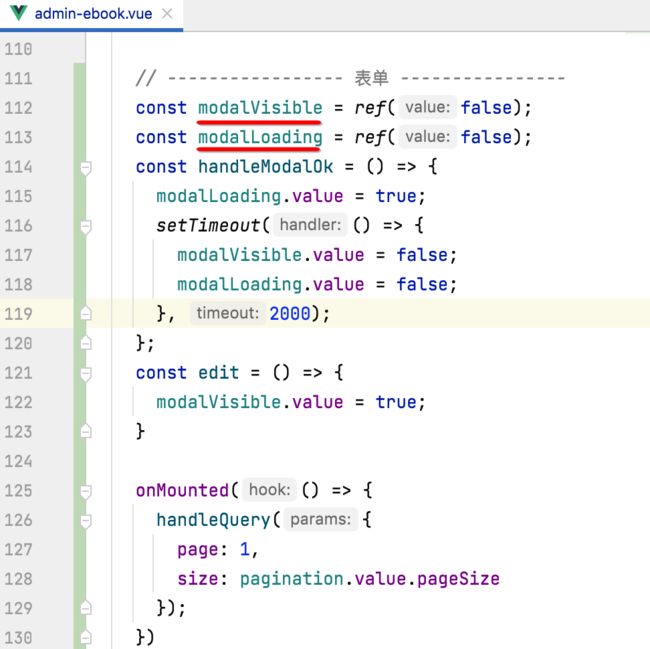
4、定义modalVisible、modalLoading、handleModalOk:
这里当然就得回到js中了,参照官网的写法,如下:

运行:
这里又有一个跟vue2对比的细节,就是在vue2中,这些变量的定义是需要写在data里面的:
这些方法需要写在method里面:

代码比较分散,但是在Vue3中就木有此限制了,代码可发按自己的想法写,比如这里将表单相关的都写在一起,大大加大可读性。
另外这里有一个好的习惯,就是将生命周期函数可以放到return之前:
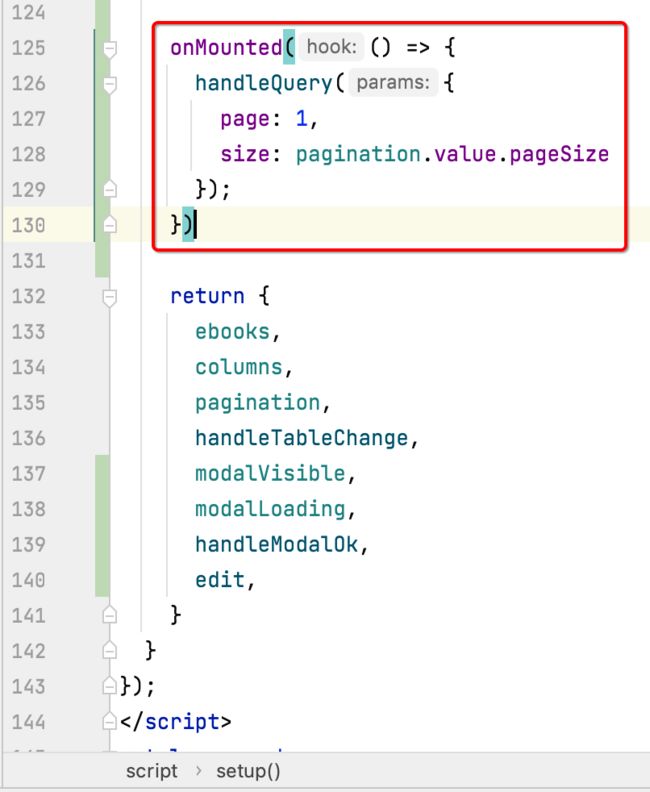
这样的话以后找方法就可以按照你的规律来进行查找,当然这块按自己的习惯来。
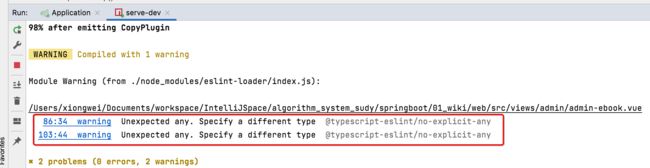
5、@typescript-eslint/no-explicit-any警告忽略:
目前在运行时,其实控制台报一个警告:
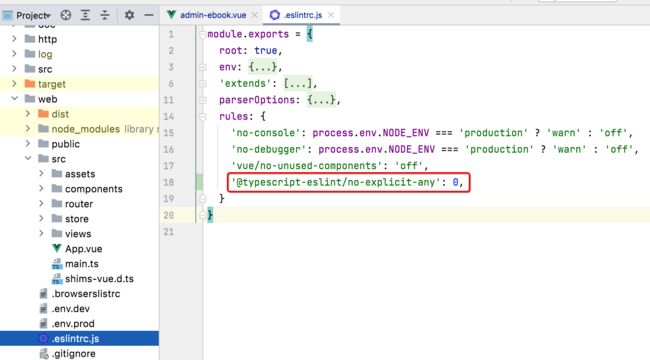
在之前Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<三>--Vue3 + Vue CLI 项Vue3 + Vue CLI 项目搭建目搭建我们已经学过如何将警告忽略了,所以咱们将它配置一下:
另外再加两个警告的忽略,这个也是之后会遇到的:
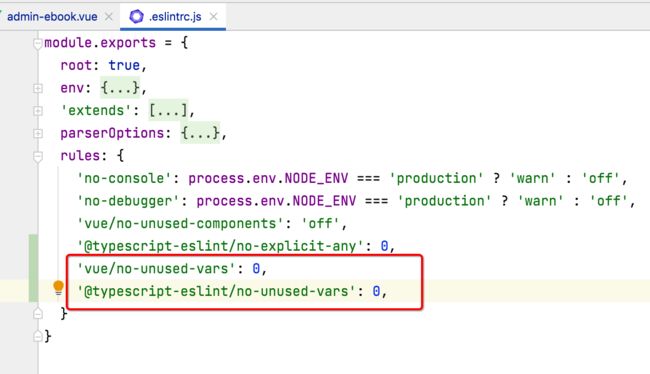
此时再运行就木有相关的警告了。
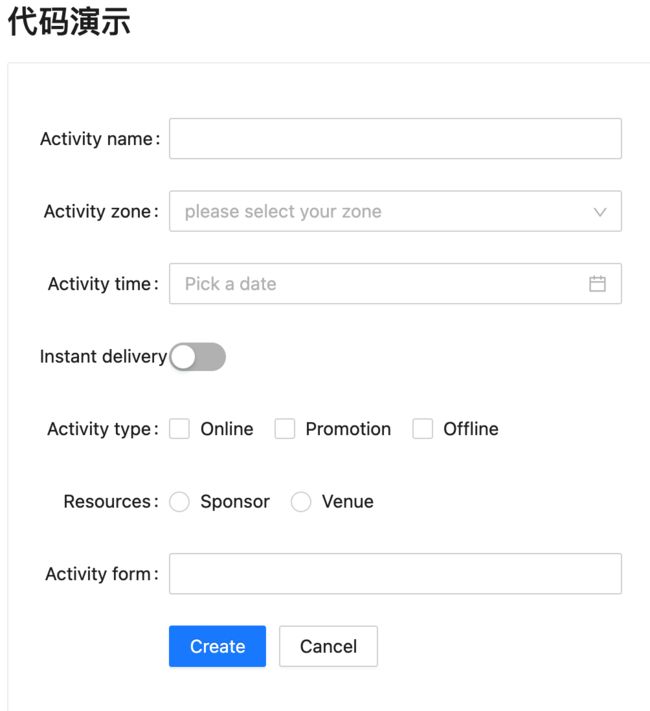
编辑框显示电子书表单:
1、Ant Design Vue寻找表单组件:
接下来在编辑框中应该有表单的输入,所以需要上Ant Design Vue中来找一个相关的表单组件:
其实它的用法比较简单,找第一个效果中的代码简单看一下:

所以下面咱们直接校仿着来实现咱们自己的表单。
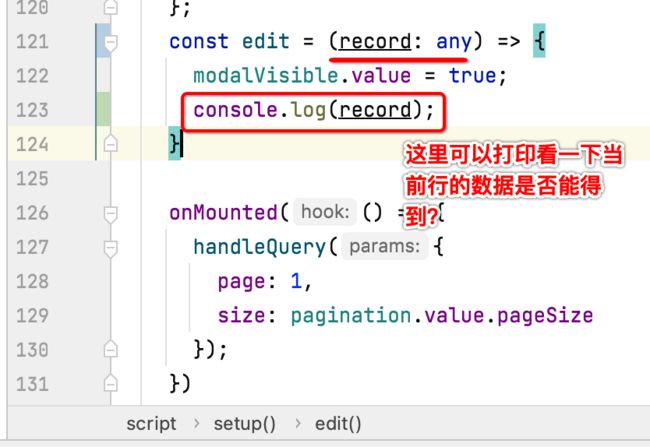
2、编辑事件增加参数:
此时编辑时就需要携带数据了,所以修改一下点击:

修改为:

运行:
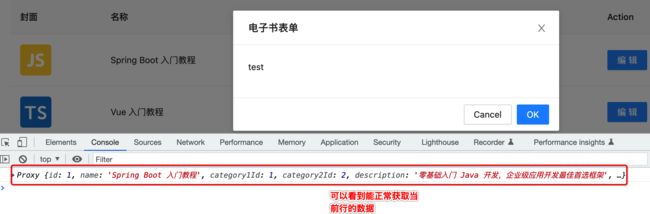
另外关于这块代码还有另一种写法:
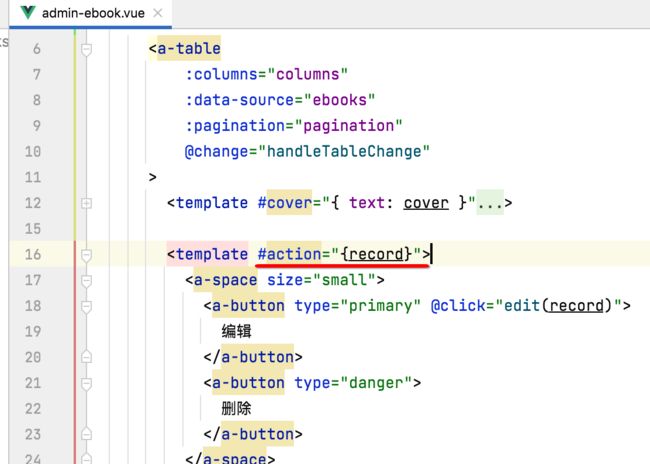
可以写成:
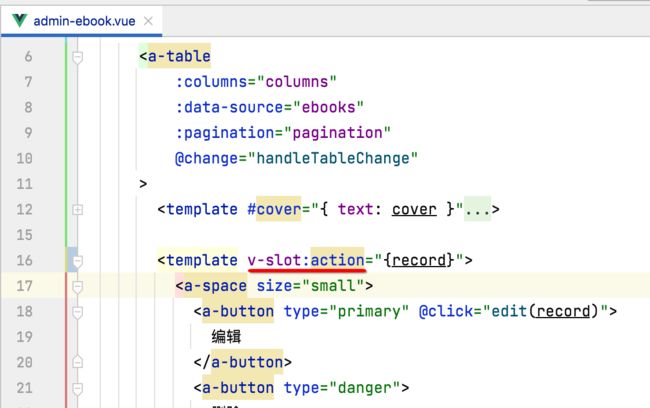
这俩有啥区别呢?目前暂时不太清楚,这里涉及到vue的插槽的语法,待未来有机会再来专门研究一下Vue,在项目学习的路上先不过多刨根问底,完整的把它学完目前是主要目标,这里就用v-slot的方式了。
提示:上面这句话刚写完,心里还是有点想搞明白#和v-slot方式的,于是乎度娘了一下,在这篇找到了答案:vue2 <template>里的#name #符号作用 ,表示意思_template #_Lan.W的博客-CSDN博客,截个结论图:

3、编辑表单实现:
接下来则来定义一下表单的内容,如下:
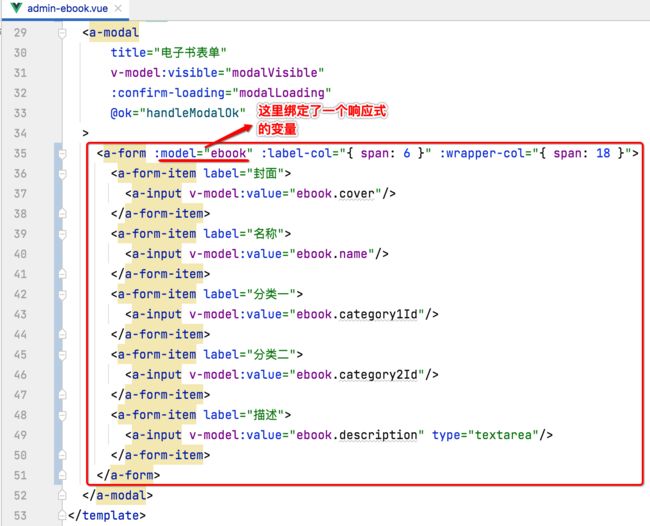
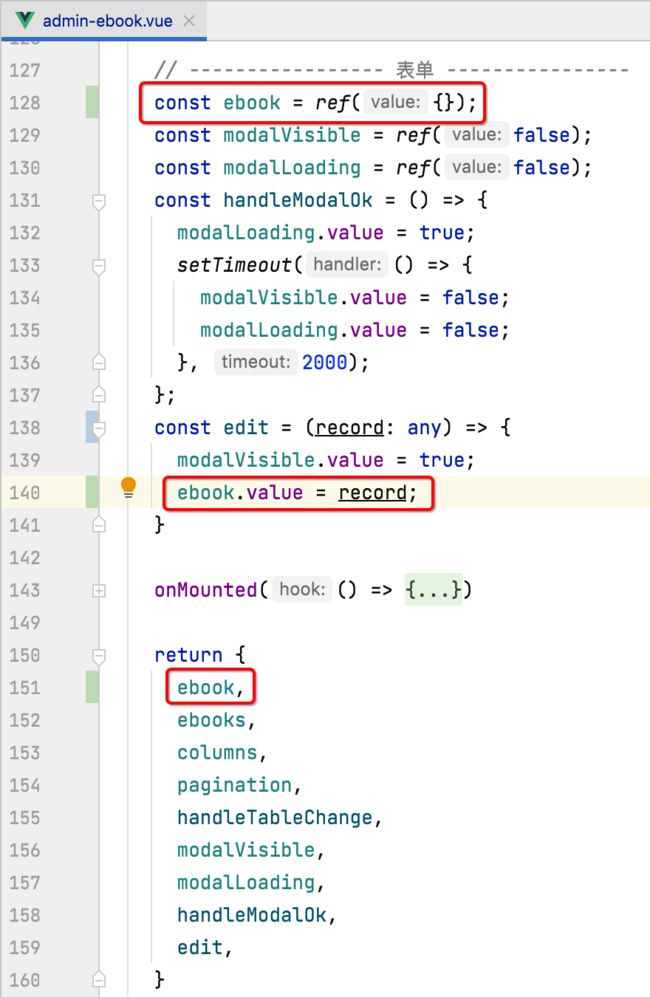
这些代码都是通用的套路,就不过多说明了,然后此时运行的效果如下:
完成电子书编辑功能:
增加后端保存接口:
接下来则需要回到后台增加一个电子书保存的接口,为前端的电子书编辑功能做准备。
1、Cotroller中新增接口:

2、准备请求参数实体:
接着则需要更改一下请求实体:

很明显目前这个请求实体是用来进行电子书列表查询的,而电子书保存的参数又跟查询还不太一样,所以这里先将它改个名字:
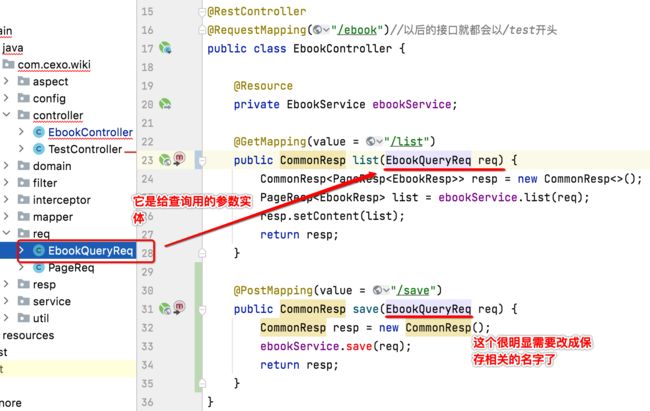
而由于电子书的保存实体其实跟domain中的Ebook实体属性是差不多的,所以直接基于Ebook拷贝,定义保存的实体:

3、service层实现保存逻辑:
目前这块还没有定义:

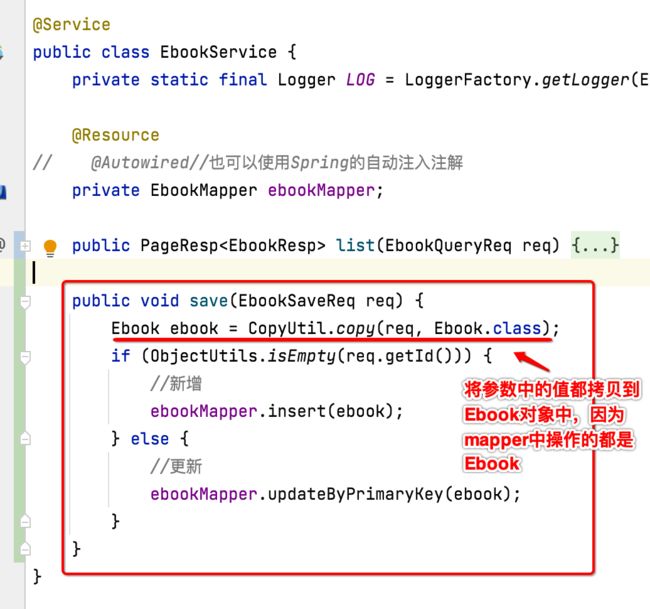
这块逻辑比较简单,从这里可以看出,有了mapper生成的代码,所有sql的操作都不用自己写了,自己调用相关的方法既可,大大增加开发效率。
4、接口测试:
接口写好之后有木有问题还得交由单元测试来验证,如下:

那如何编写呢?还记得之前https://www.cnblogs.com/webor2006/p/17114996.html我们保存了Live Template POST的代码模板不?所以此时就可以派上用场了,敲个快捷键既可:

然后再改一改post请求用例就写好了,这里就暂且不写了,直接用前端的页面来进行接口的测试。
点击保存时,调用保存接口:
接下来则找到编辑框保存按钮的点击事件:
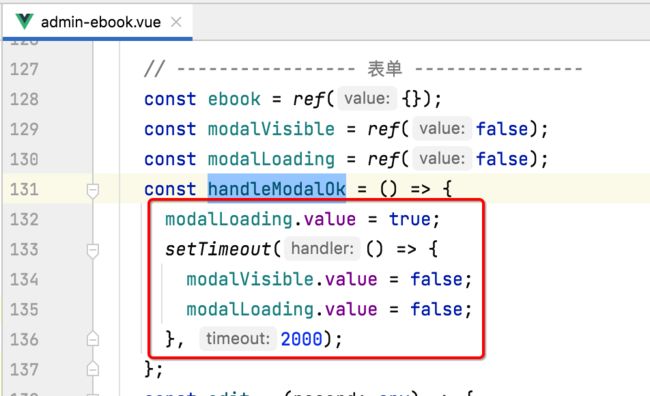
将它改为发起post请求,如下:
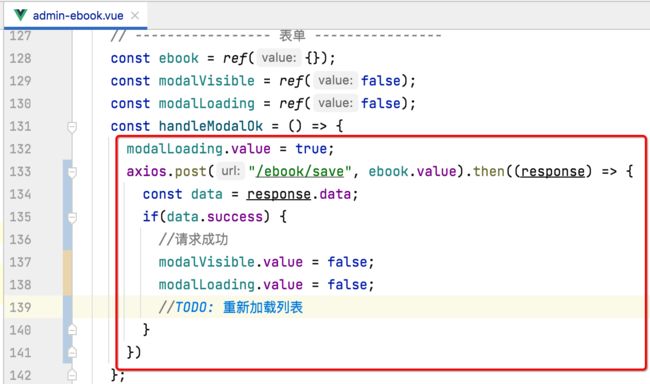
保存成功刷新列表:
接下来保存成功之后,则应该刷新一下当前页,所以:
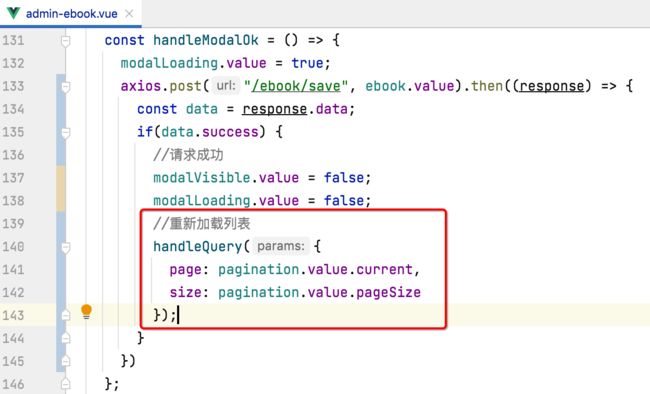
测试:
接下来测试一下,看好不好使:
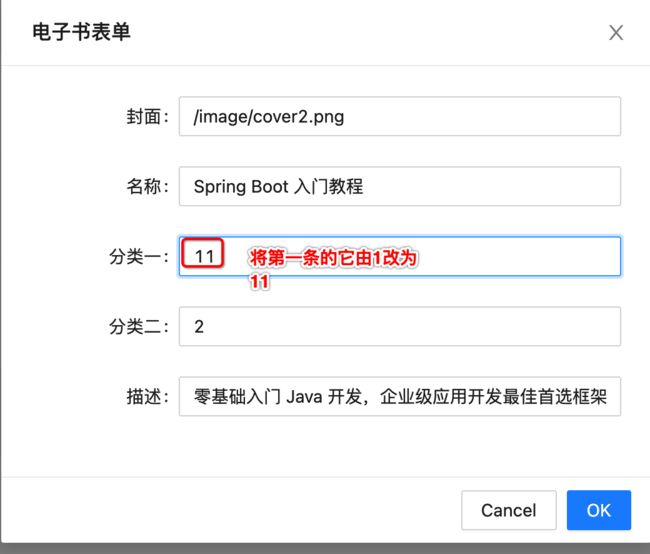
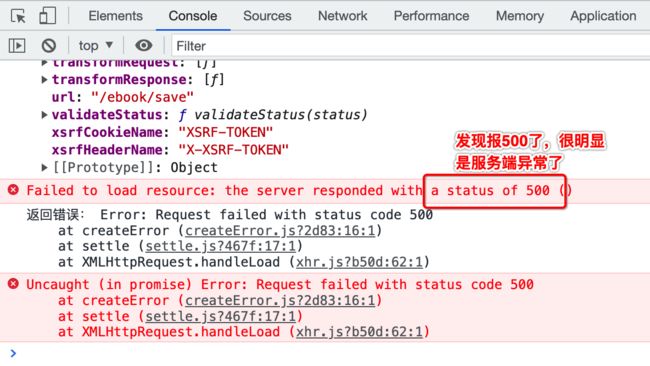
此时回到后端看一下日志:

id为空。。不可能呀,前端点击编辑时肯定当前记录的id是有值的,那此时看一下后端参数的接收正不正常了:

那。。这是为何呢?其实是因为我们在定义接口时少加了一个注解,如下:

这是因为如果是“Content-Type: application/json”的请求方式,就需要带这个注解,而如果是“Content-Type: application/x-www-form-urlencoded” 则不需要加,而目前axios的post请求默认就是以json的形式提交的:

改完之后,再来运行看一下,为了看到效果,在运行之前这里先将分类的显示改一下,目前分类没有显示分类一和分类二:
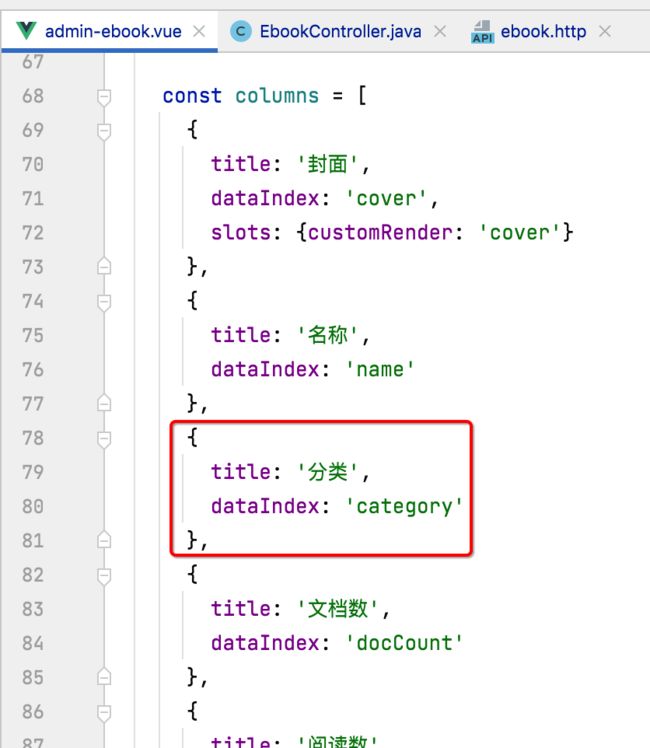

改成:

这时分类就都正常展示了:

接下来咱们来编辑看一下:

此时看一下表中的数据是否被更改过来:

嗯,木问题。
优化代码:
接下来有一个代码需要优化一下,就是:
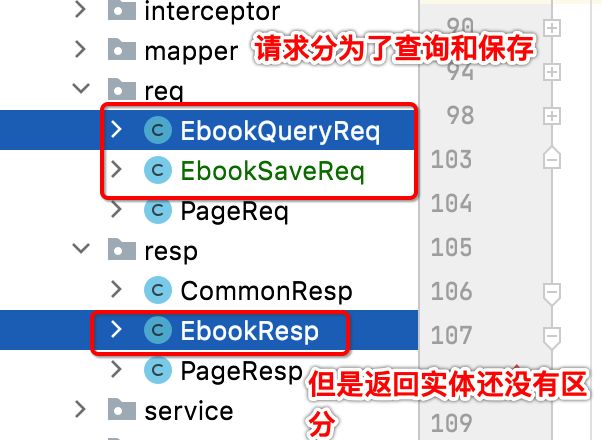
所以接下来咱们来将EbookResp改为EbookQueryResp:

而保存由于只有请求参数,不需要返回,所以这里就不再弄一个EbookSaveResp了。这种写法其实看似有很多冗余,比如这俩类,几乎里面的字段一模一样:
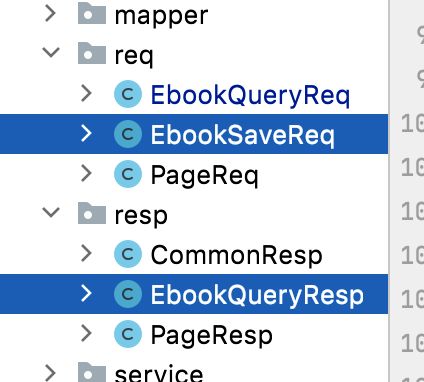
但是!!!这样设计会比较灵活,这个在之后的参数校验中会有体现,目前的设计思想就是将query和save分开,并且request和response也是分开的,即使它里面的属性是完全一模一样的
雪花算法与新增功能:
时间戳概念:
先来对时间戳进行一个了解,因为雪花算法用到了它,其实这个人人都知道,在Java中可以通过它来获取时间戳:
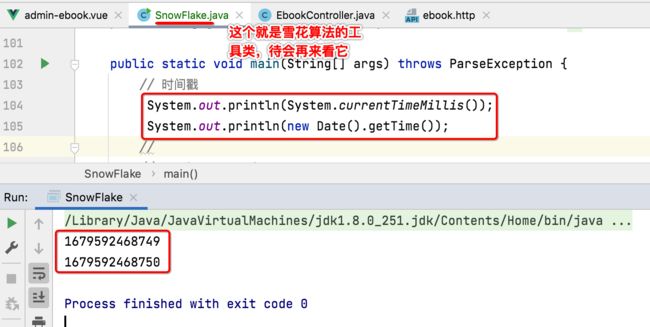
那你知道它是怎么算出来的么?接下来咱们再来看一下这个时间的时间戳:
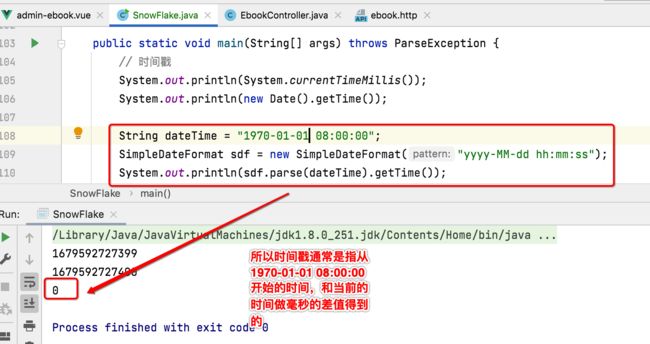
那为啥是从8点开始呢?因为这里是以北京时间为准,有8小时的时间差。
雪花算法工具类:
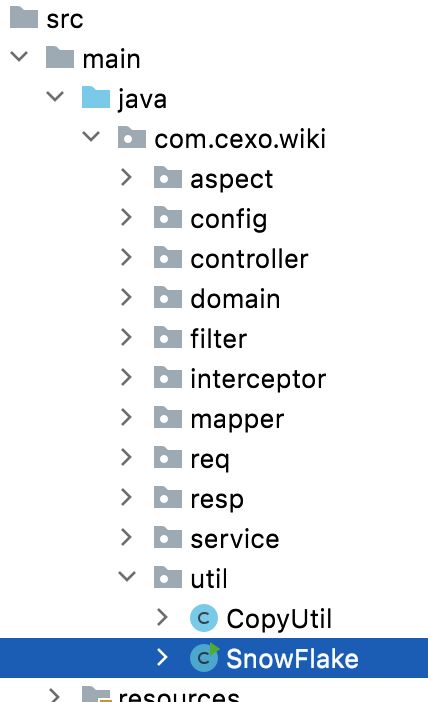
接下来先来贴一下雪花算法的代码:
package com.cexo.wiki.util;
import org.springframework.stereotype.Component;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* Twitter的分布式自增ID雪花算法
**/
@Component
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1609459200000L; // 2021-01-01 00:00:00
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId = 1; //数据中心
private long machineId = 1; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake() {
}
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) throws ParseException {
// 时间戳
System.out.println(System.currentTimeMillis());
System.out.println(new Date().getTime());
String dateTime = "1970-01-01 08:00:00";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
System.out.println(sdf.parse(dateTime).getTime());
// SnowFlake snowFlake = new SnowFlake(1, 1);
//
// long start = System.currentTimeMillis();
// for (int i = 0; i < 10; i++) {
// System.out.println(snowFlake.nextId());
// System.out.println(System.currentTimeMillis() - start);
// }
}
}这里简单对它进行一个解,它其实是由以下几部分组成:

其中如果将START_STMP设置为0:

那么就表示从1970年算这个时间差,但是有个问题就是跟现在的时间差会非常长,所以咱们这里就取一个相对近一点的时间,就以2021年为起始时间戳,
接下来有三个核心常量:

其中一位就是二进制的0和1,所以比如MACHINE_BIT=5则表示它最多可以表示二的五次方台机器,也就是32台机器,这块可以根据实际的情况动态修改,其中SEQUENCE_BIT位表示的是我一个毫秒内最多可以生成二的十二次方个id,这只是一台机器的,再加上机器最多可以有二的五次方台机器,二的五次方个数据中心,其中核心方法是这个:

接下来咱们调用看一下:

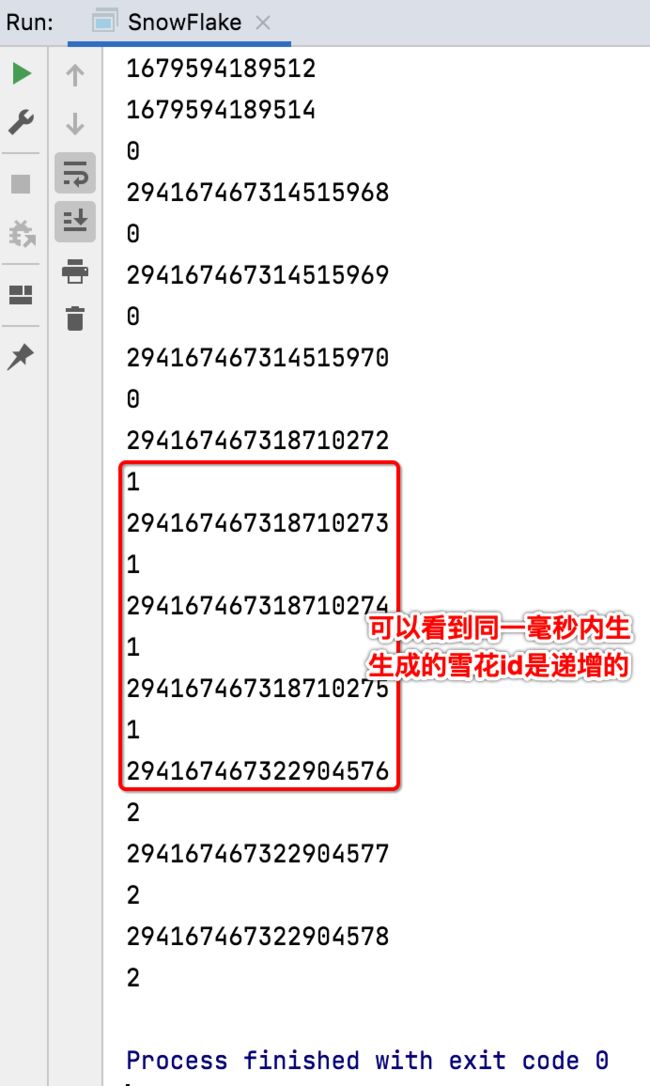
暂且先了解到这,反正就是用来生成id用的,另外对于这个类的使用需要交由Spring来初始化,而不用new的方式来创建了,所以需要加一个注解:
完成新增功能:
1、修改后台接口:
这里回到保存接口,在新增情况下,我们加入雪花算法:

2、修改前端逻辑:
接下来在前端增加一个新增的按钮:


此时看一下效果:
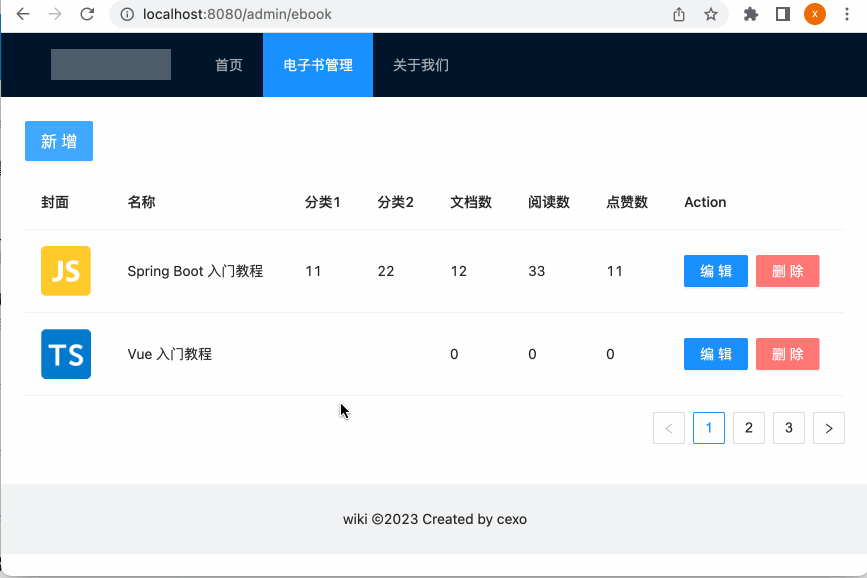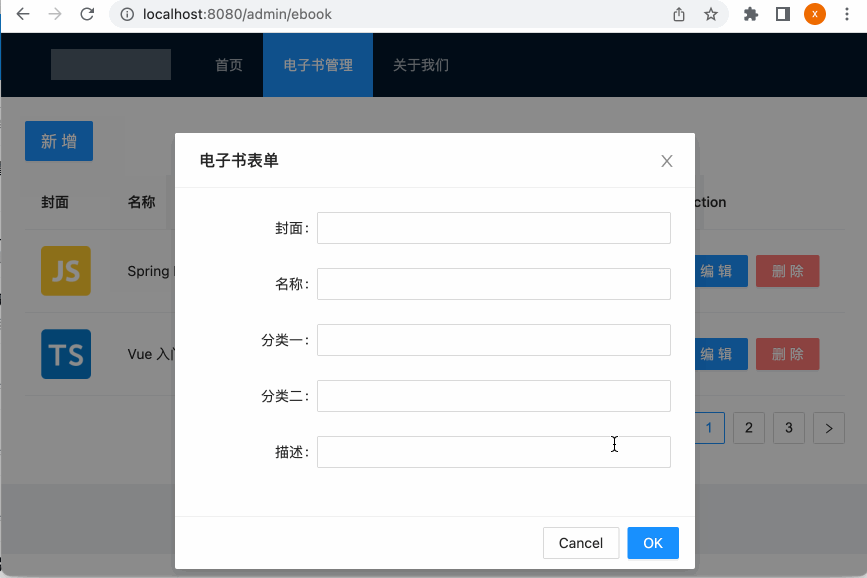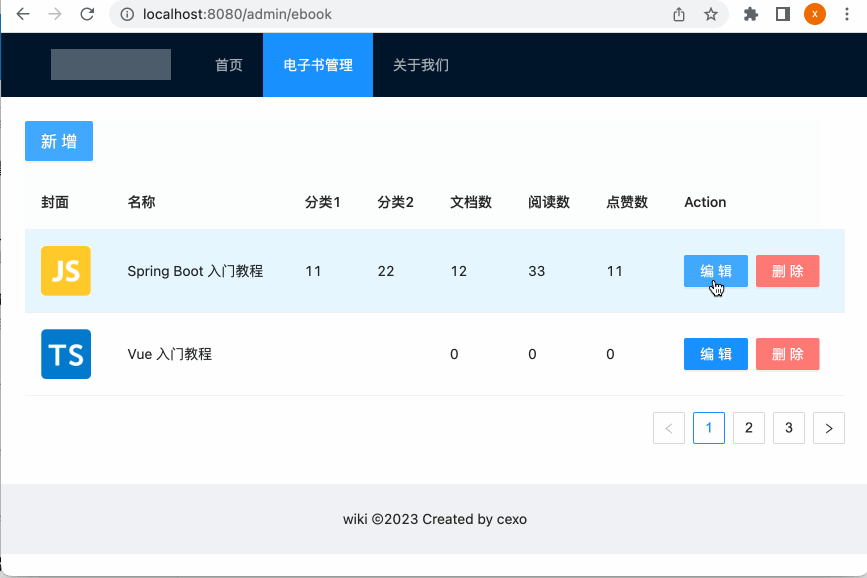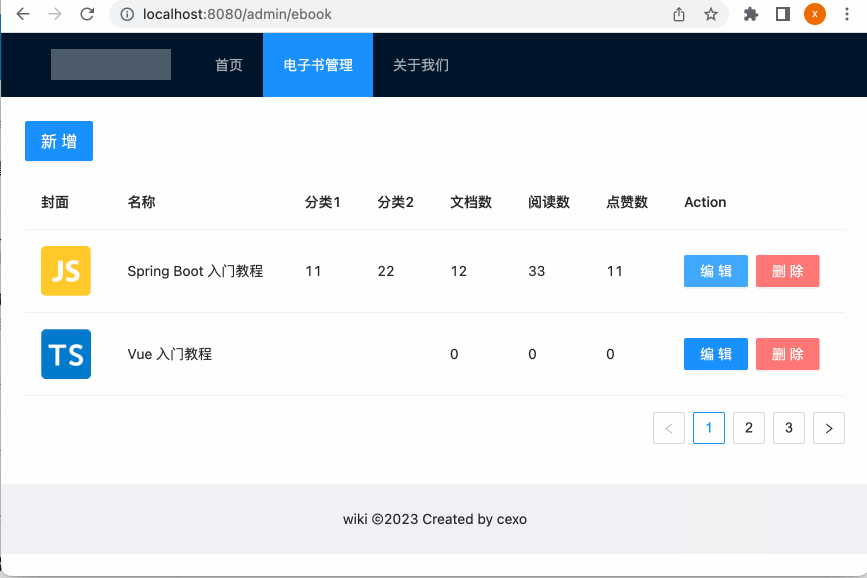
在继续编写新增逻辑之前,这里对代码做一个小小的优化,就是这块可以做一个分类,可以提高代码的阅读性:
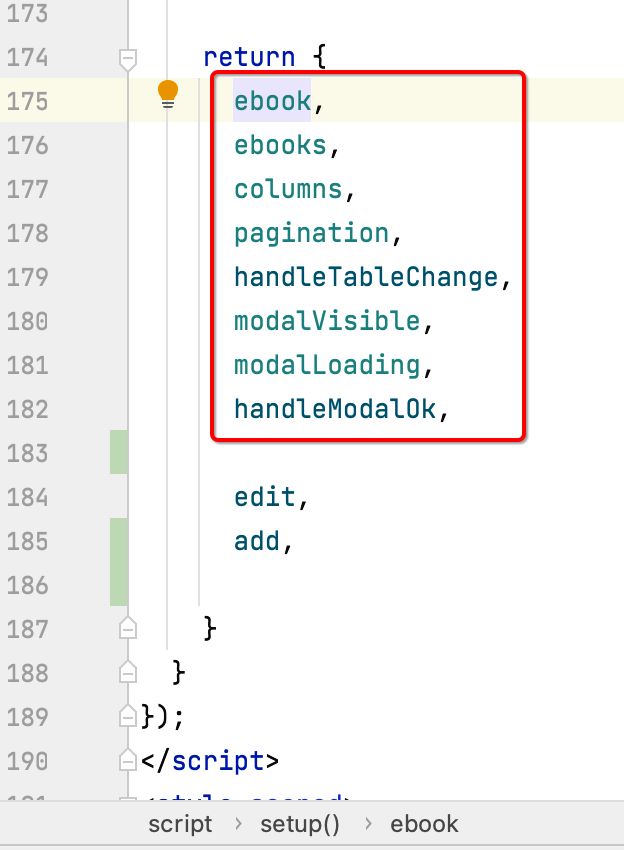
我们可以稍稍进行一个分类,代码的可读性瞬间就上来了:

另外这里还需要增加一个逻辑,就是表单应该有个加载中的效果,具体修改如下:
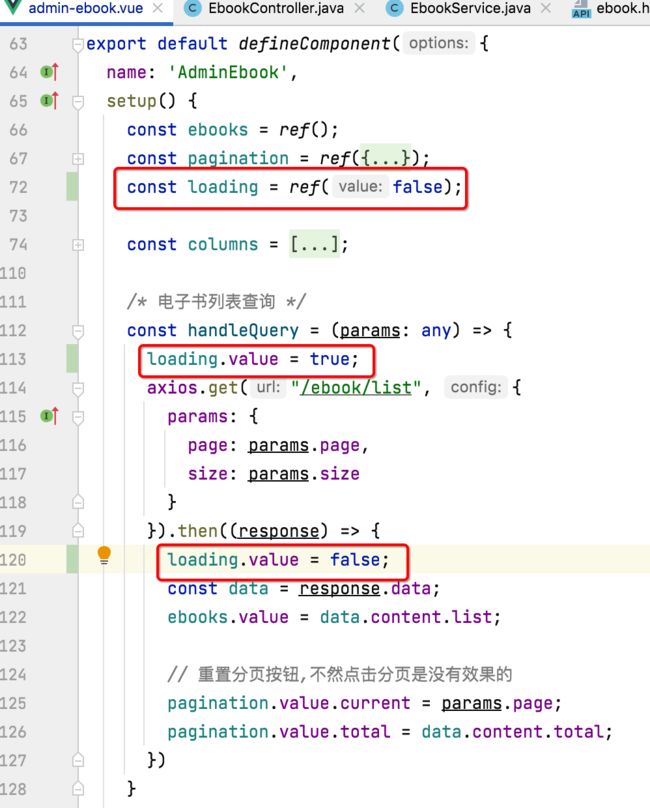

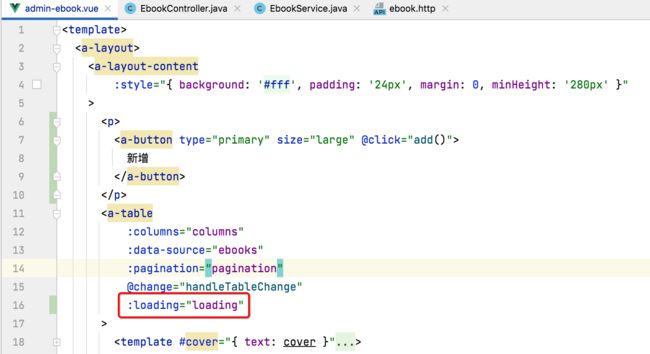
4、测试:
接下来咱们就可以测试了,其保存方法跟编辑方法调用的是同一个,这块就不需要进行啥调整了,发现运行报错了。。
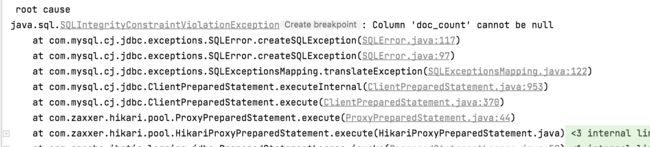
这是因为咱们创建的电子书的表这几个字段是非空的:
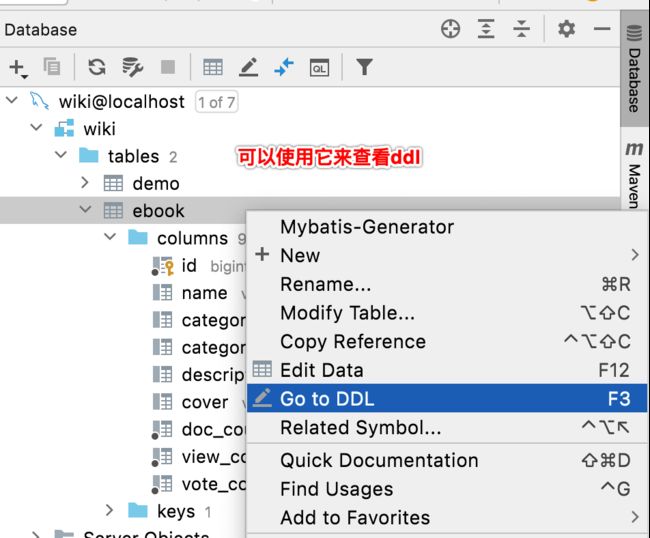

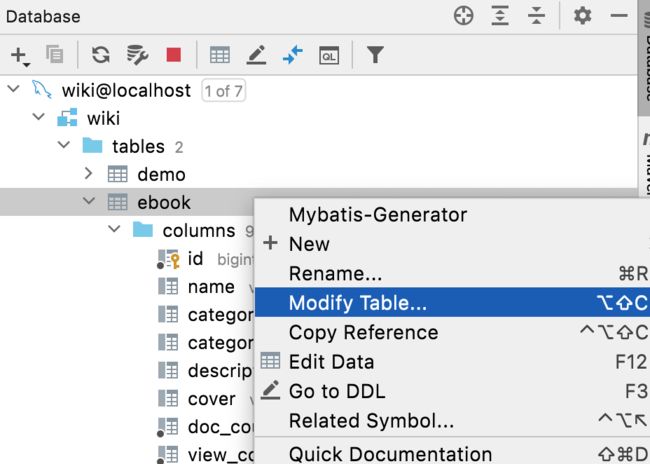
这里暂且先将非空属性给去掉,在之后会有参数校验处理的:
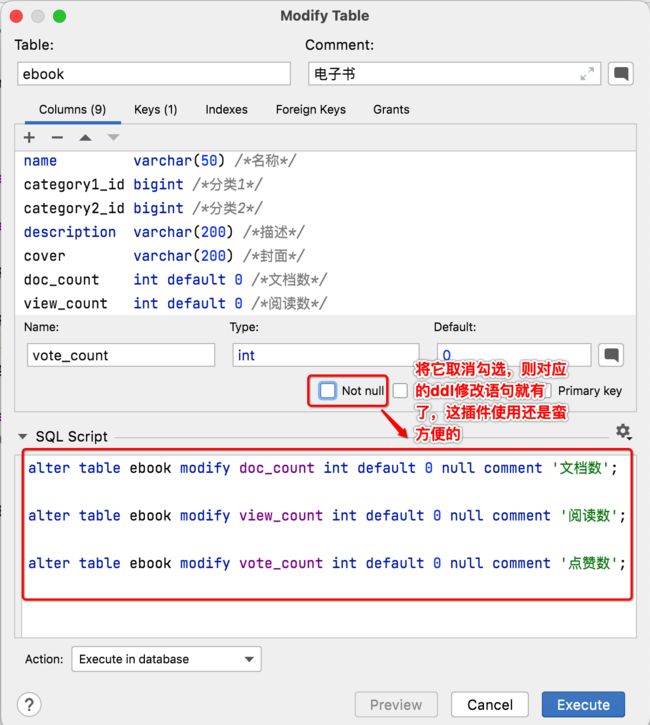
此时再运行:
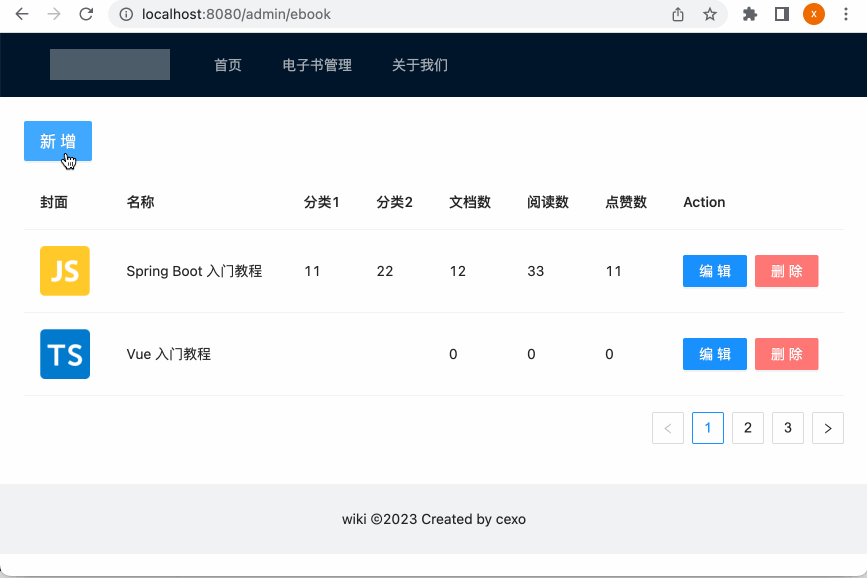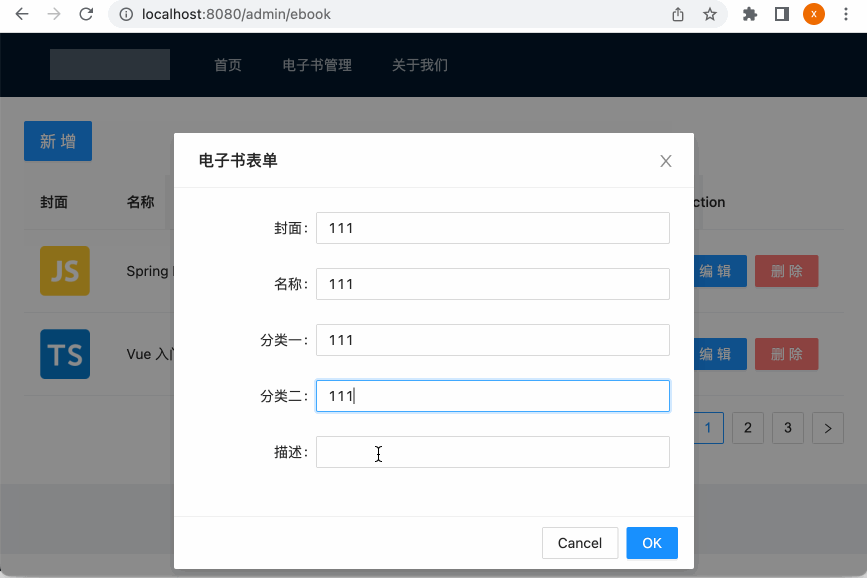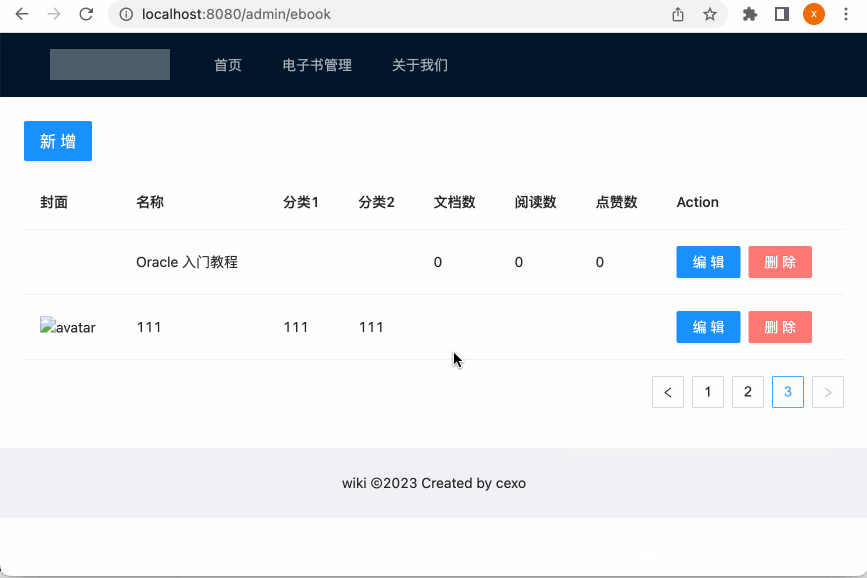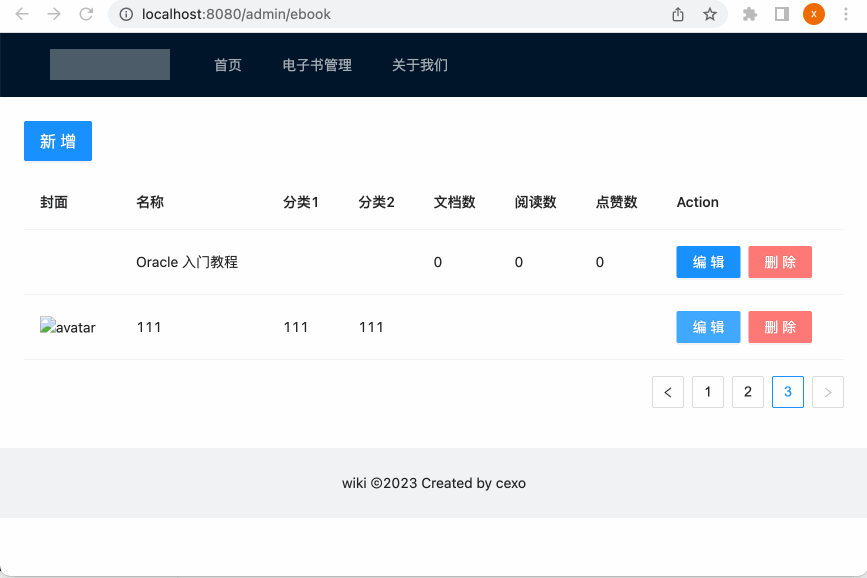
5、Bug修复:
不过现在有一个bug,这里先来看看,目前由于刚才新加的封面的值是随意填写的,所以现在网页显示了一个出错的图:
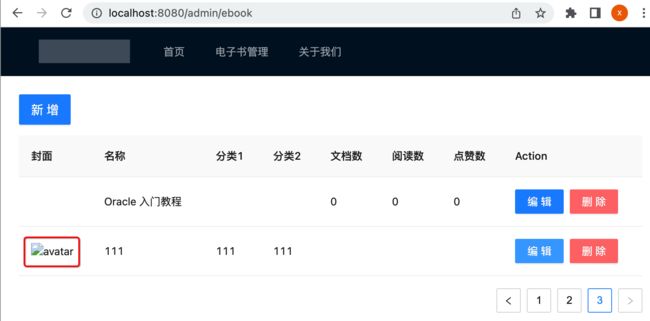
所以这里编辑一个正常能显示出图的数据来,你会发现,都不用点击编辑按钮,只要填写表单其该条的封面图就可以正常显示了:

很明显是不符合预期的,其原因也比较好理解,就是因为目前用的是响应式变量:
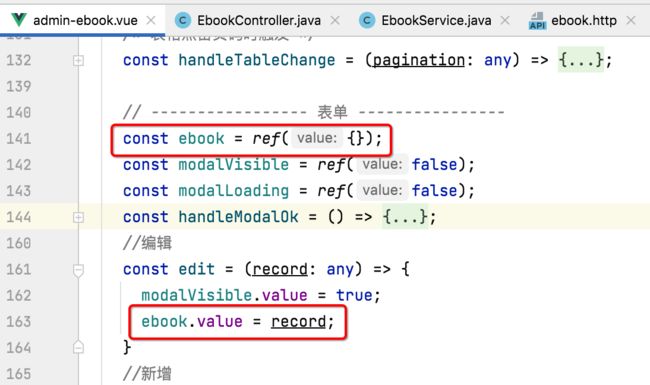
页面表单的数据修改会直接影响到ebook这个变量造成没有点击“ok”也实时在页面上进行数据的变更了,其解决起来也比较简单,就是让这里的ebook是一个拷贝的变量,具体做法如下,先导入一下工具类:
其内容如下,直接拿来用既可:
export class Tool {
/**
* 空校验 null或""都返回true
*/
public static isEmpty(obj: any) {
if ((typeof obj === 'string')) {
return !obj || obj.replace(/\s+/g, "") === ""
} else {
return (!obj || JSON.stringify(obj) === "{}" || obj.length === 0);
}
}
/**
* 非空校验
*/
public static isNotEmpty(obj: any) {
return !this.isEmpty(obj);
}
/**
* 对象复制
* @param obj
*/
public static copy(obj: object) {
if (Tool.isNotEmpty(obj)) {
return JSON.parse(JSON.stringify(obj));
}
}
/**
* 使用递归将数组转为树形结构
* 父ID属性为parent
*/
public static array2Tree(array: any, parentId: number) {
if (Tool.isEmpty(array)) {
return [];
}
const result = [];
for (let i = 0; i < array.length; i++) {
const c = array[i];
// console.log(Number(c.parent), Number(parentId));
if (Number(c.parent) === Number(parentId)) {
result.push(c);
// 递归查看当前节点对应的子节点
const children = Tool.array2Tree(array, c.id);
if (Tool.isNotEmpty(children)) {
c.children = children;
}
}
}
return result;
}
/**
* 随机生成[len]长度的[radix]进制数
* @param len
* @param radix 默认62
* @returns {string}
*/
public static uuid(len: number, radix = 62) {
const chars = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'.split('');
const uuid = [];
radix = radix || chars.length;
for (let i = 0; i < len; i++) {
uuid[i] = chars[0 | Math.random() * radix];
}
return uuid.join('');
}
}然后咱们就可以在编辑时这样使用它了:
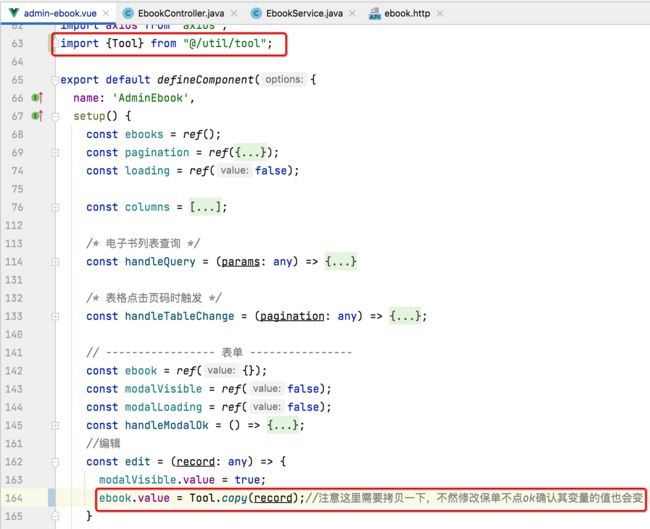
此时再运行就正常了:
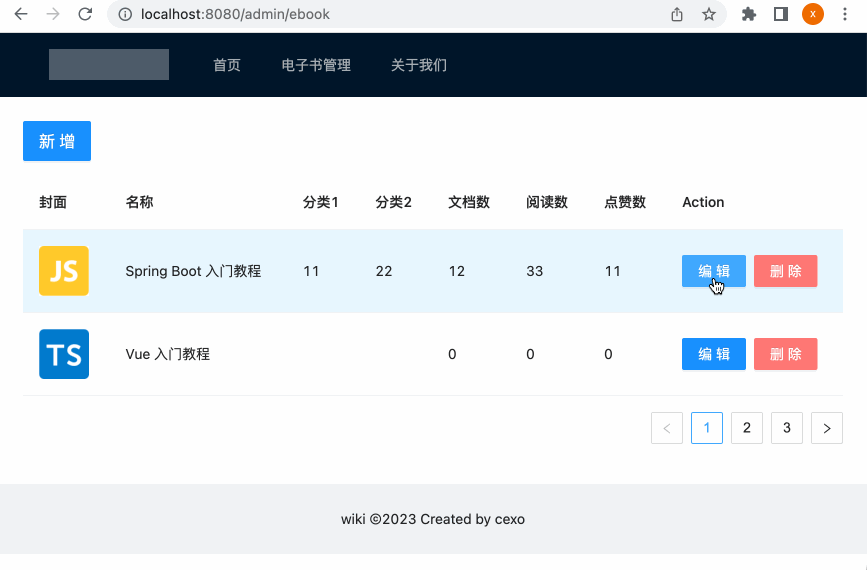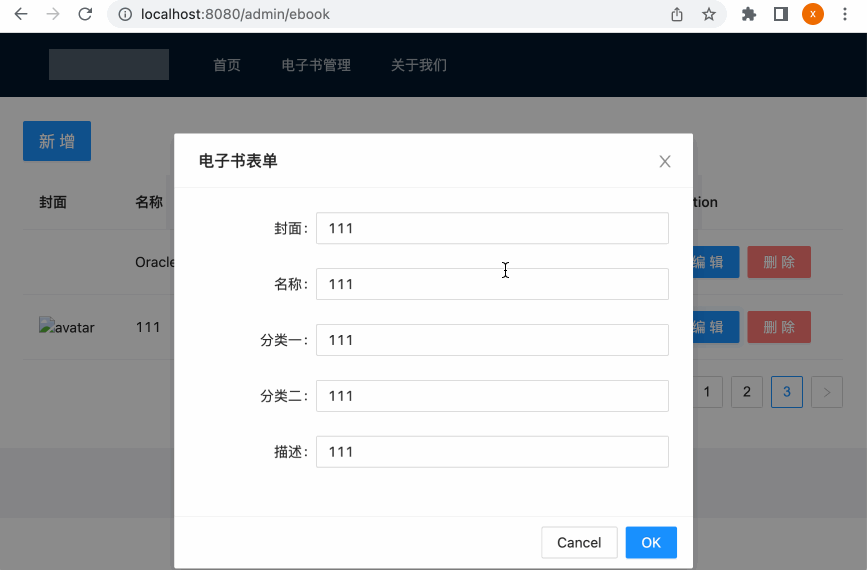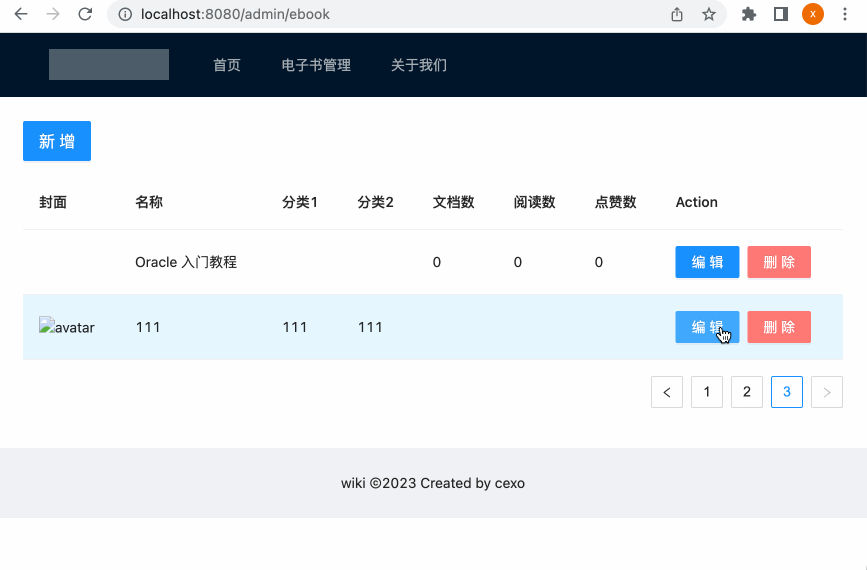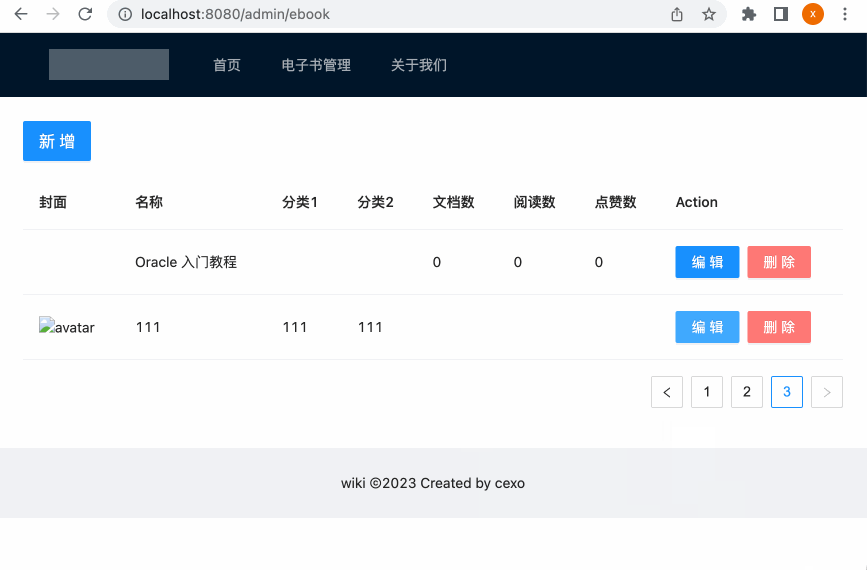
呃,发现编辑功能木有生效。。这又是啥问题呢?查看后台的sql语句更新,貌似id不对:

但是其实数据库要编辑的这台的id是:

这是什么导致的呢?暂时没想到,这里为了将此功能跑通,手动回到数据库中将此id修改成前端的这个:

此时再来编辑一下:
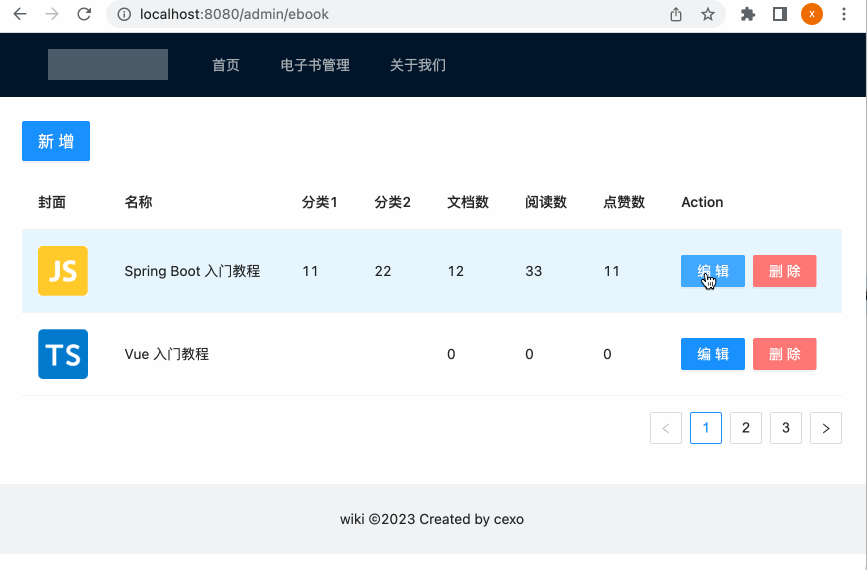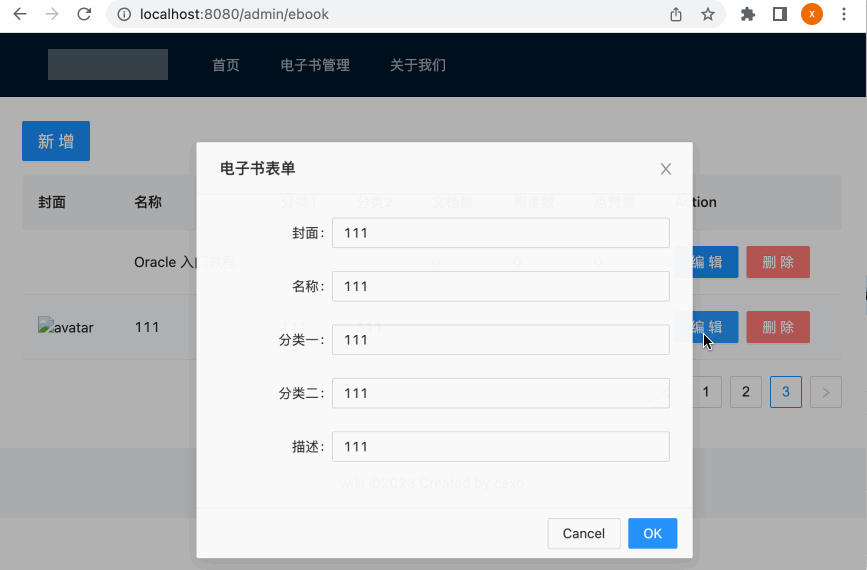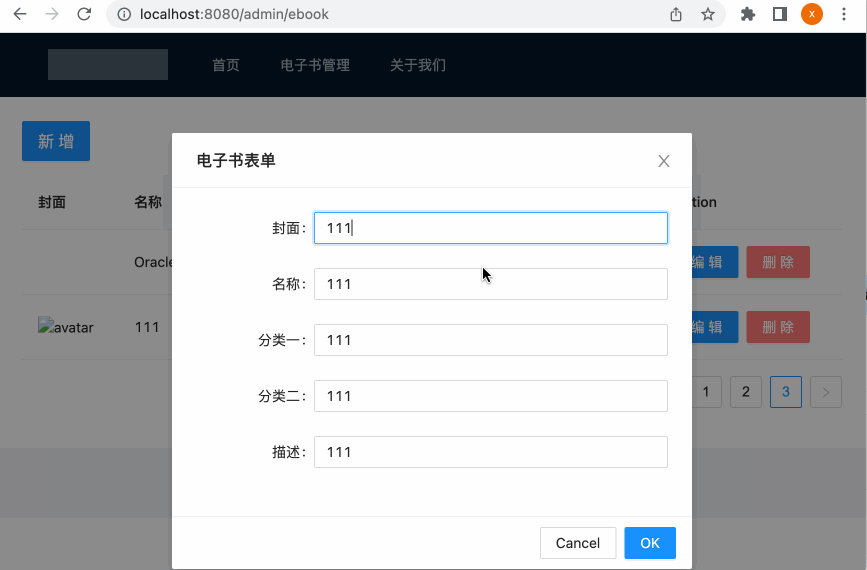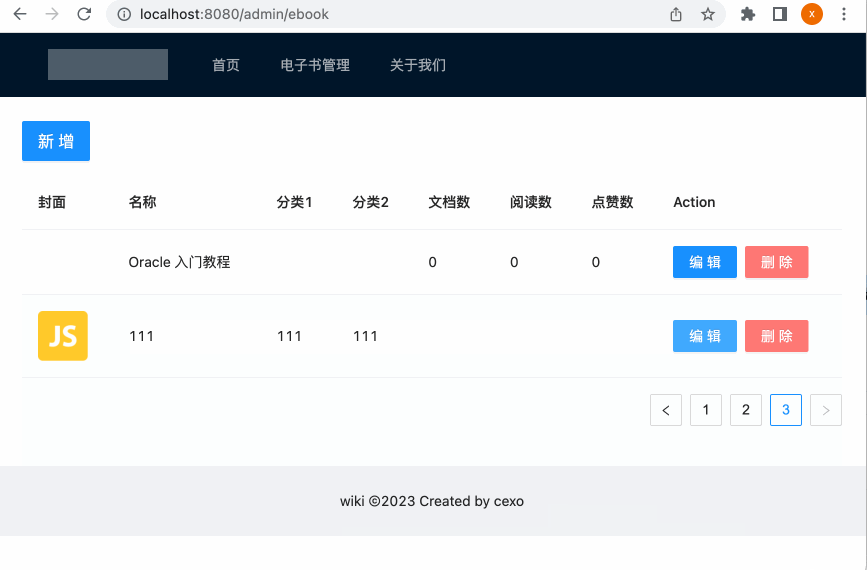
增加删除电子书功能:
后台增加删除接口:
先来上后台增加删除接口:
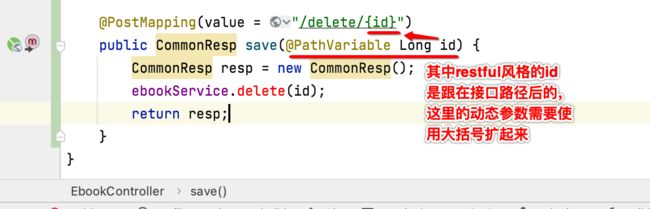
接下来service中定义一下:
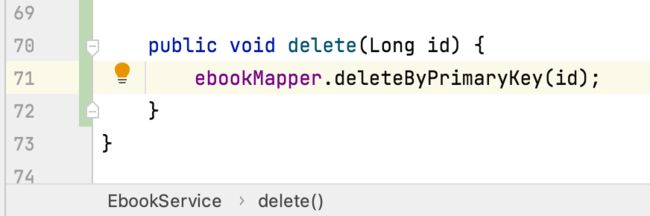
其中有个注解给改一下:

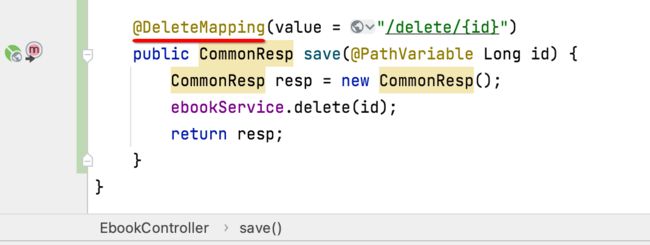
前端删除逻辑处理:
添加点击事件:
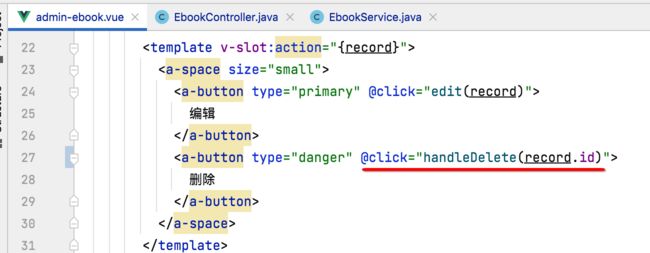
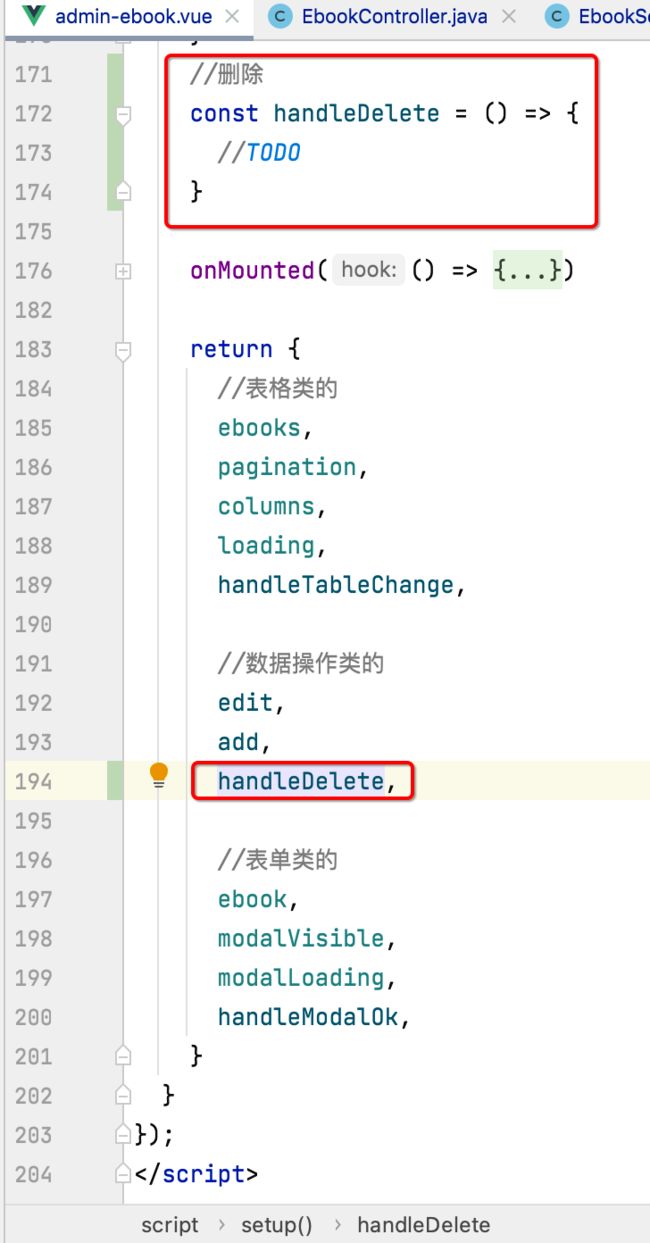
接下来则来发起删除请求:

这里只处理了成功的情况,异常情况之后会完善,目前先来运行看一下效果:
上数据库中查看一下这要数据是否真正删除了:
加入确认提示框:
上Ant Design Vue找一个最简单的:
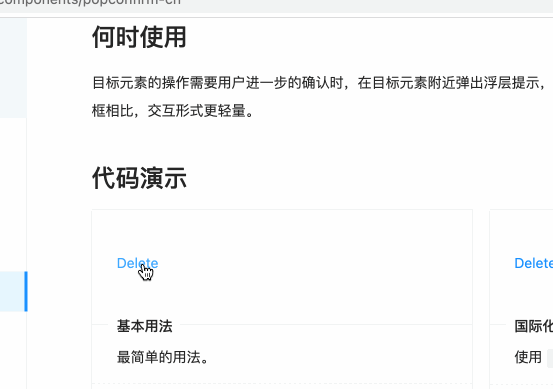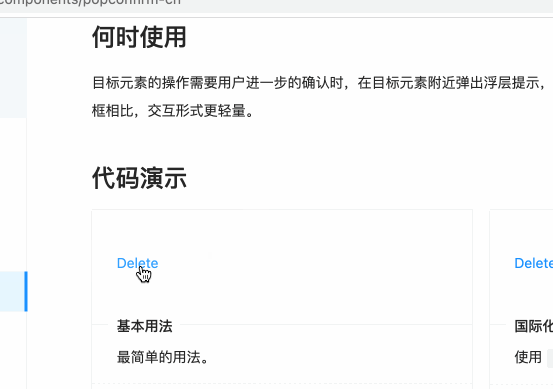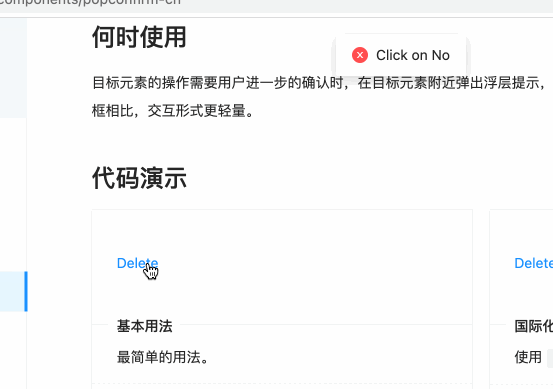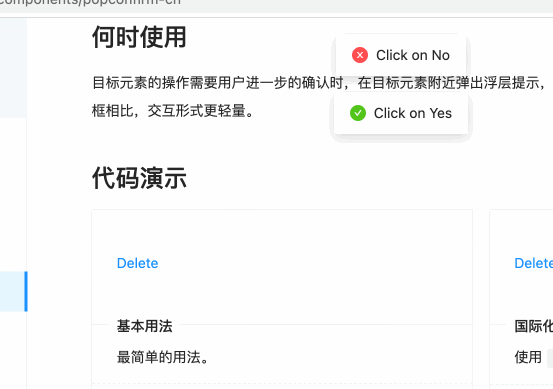
其用法也比较简单:

所以,拷贝至咱们的页面中:
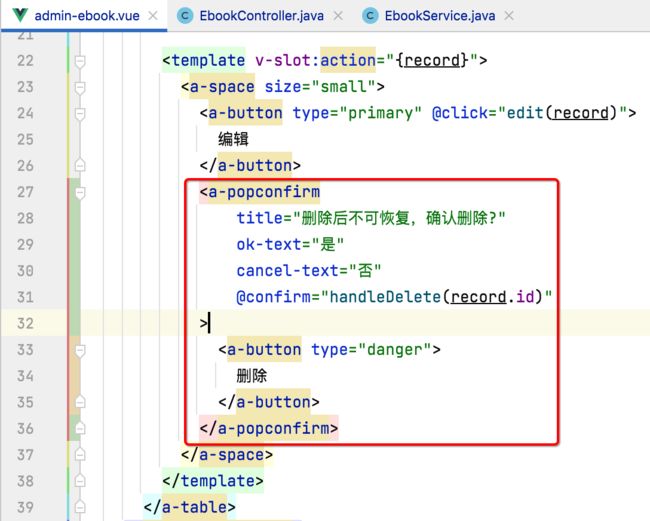
测试:
最后整体测试一下:

集成Validation做参数校验:
概述:
目前在保存时,没有做任何表单的校验,比如有些字段是非空的,这时如果用户不输入值得给相应的错误提示,所以接下来则来对参数进行一个校验的处理。
集成spring-boot-starter-validation:
用Spring自带的校验组件,先添加依赖:
org.springframework.boot
spring-boot-starter-validation

由于它是SpringBoot内置的,所以这里就不需要加版本号了。
对保存接口和查询接口增加参数校验:
查询接口:
1、后端增加校验:
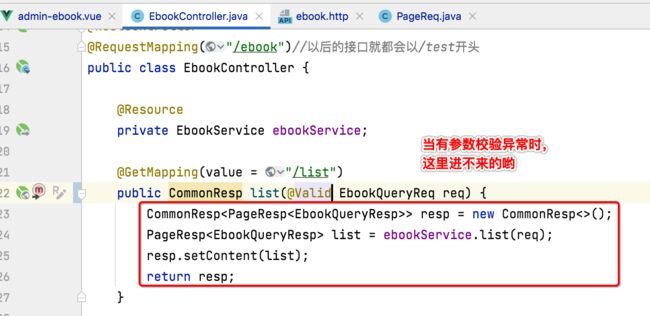
目前对于电子书的查询是支持分页的,而分页的关键参数是:
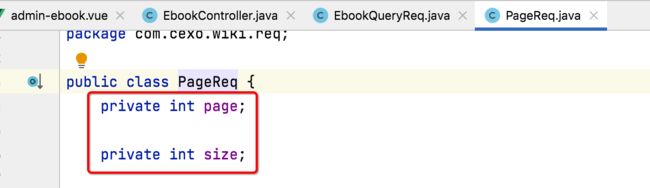
如果不做校验,是不是用户可以传空,而且对于size也可以传无限大,因为接口是可以绕过前端,通过脚本来发起请求的,比如传了个一千万,是不是瞬间就可以把服务器给搞崩了?所以说接下来咱们来对这两个参数增加校验。

关于这个没啥好解释的,直接这么做就成了,另外要让这个校验规则生效,还得在这块加一个注解:
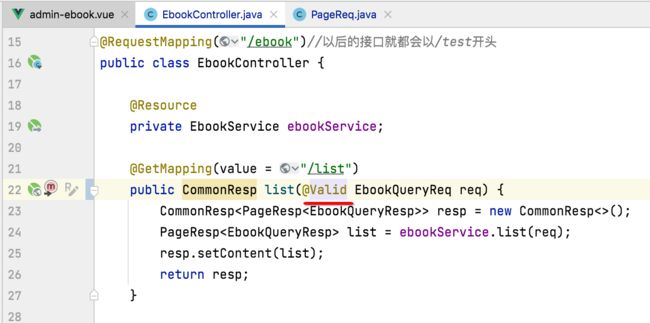
此时咱们来运行测试一下效果:
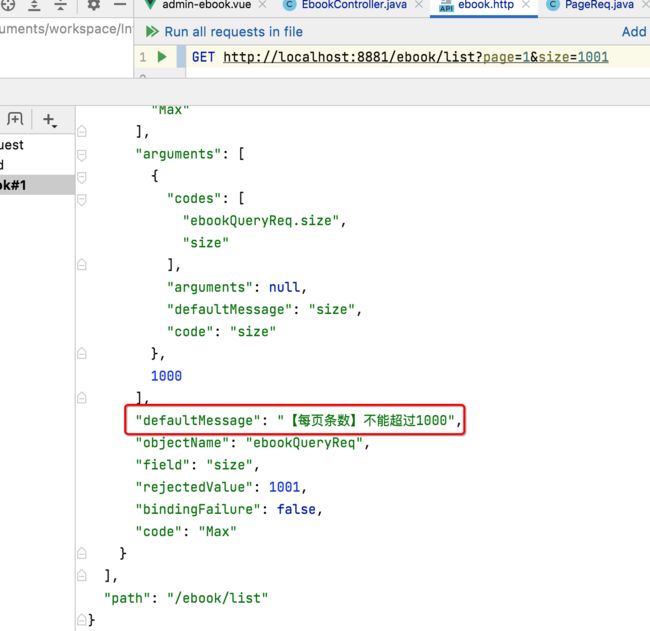
这个错误码是400:
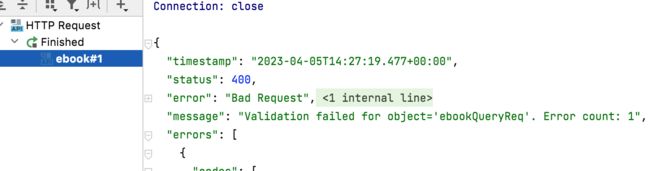
其中看一下控制台,这个信息就是由validation这个框架打印出来的:

其中有个类提前有个印象,因为之后会用到:

2、前端测试异常:
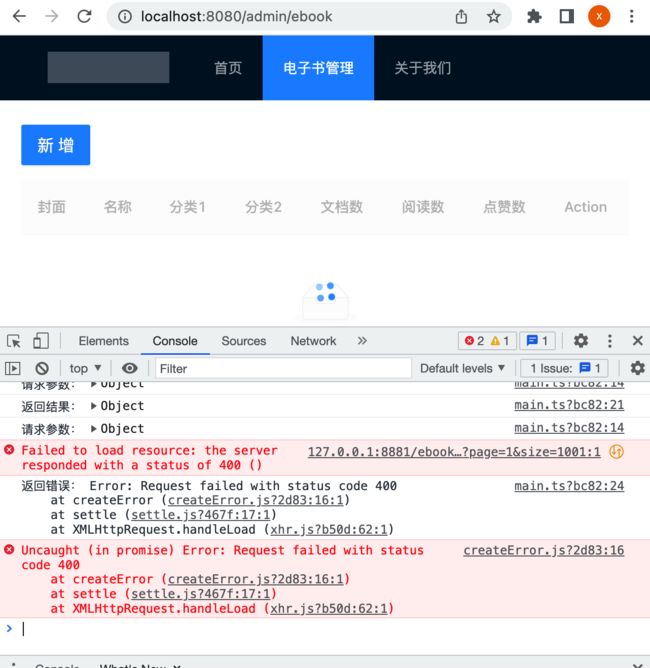
好,接下来咱们用前端来测试一下这个异常,会发现界面流程就不对了:

运行:
3、后端增加统一异常处理:
由于目前后端的参数校验异常是由validation框架统一处理了,也就是当有参数异常时,是不会执行咱们正常的业务方法的:
所以,咱们就没办法在异常时给前端返回一个CommonResp的异常信息,那很显然不太人性,目前validation返回的异常格式太乱了,需要转换成咱们自己CommonResp的格式,此时就需要用到SpringBoot的全局异常处理了,这块也是直接看做法,比较简单,有个类增加个对应的注解既可:

package com.cexo.wiki.controller;
import com.cexo.wiki.resp.CommonResp;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.validation.BindException;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
/**
* 统一异常处理、数据预处理等
*/
@ControllerAdvice
public class ControllerExceptionHandler {
private static final Logger LOG = LoggerFactory.getLogger(ControllerExceptionHandler.class);
/**
* 校验异常统一处理
*/
@ExceptionHandler(value = BindException.class)
@ResponseBody
public CommonResp validExceptionHandler(BindException e) {
CommonResp commonResp = new CommonResp();
LOG.warn("参数校验失败:{}", e.getBindingResult().getAllErrors().get(0).getDefaultMessage());
commonResp.setSuccess(false);
commonResp.setMessage(e.getBindingResult().getAllErrors().get(0).getDefaultMessage());
return commonResp;
}
}其中关键点就是注解:

再测试一下,此时返回格式就如我们的预期了:
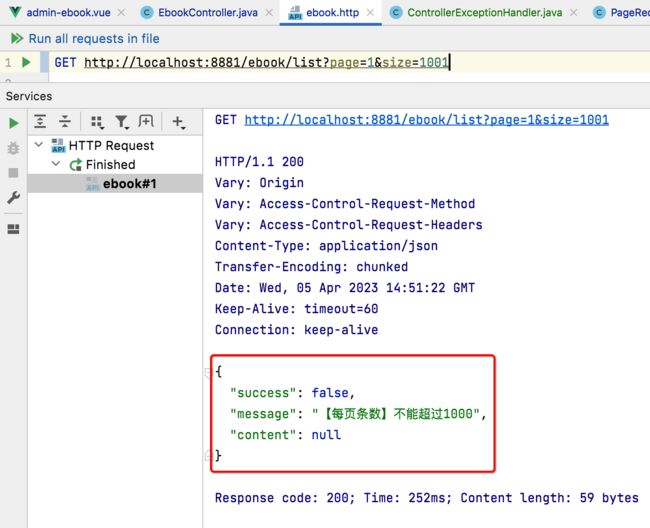
有了这个思路,以后如果项目中还有其它异常,都可以通过这种全局的异常拦截方式进行处理了。
4、前端增加错误提示:
先来上Ant Design Vue找对应的效果组件:

它的效果如下:

使用方式也超简单:

接一下咱们回到前端的查询请求这块增加异常的条件判断,如下:
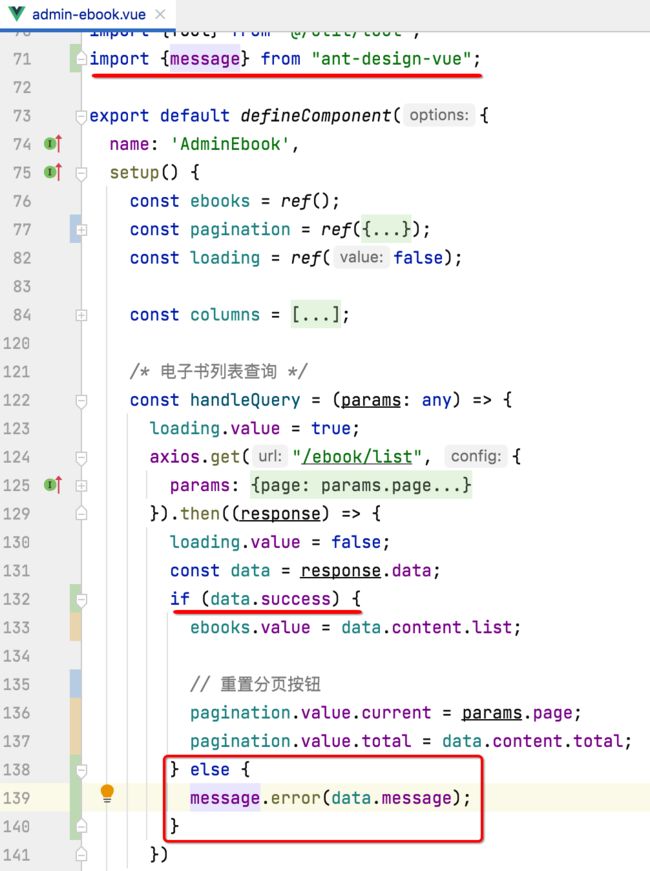
再次运行,效果如下:
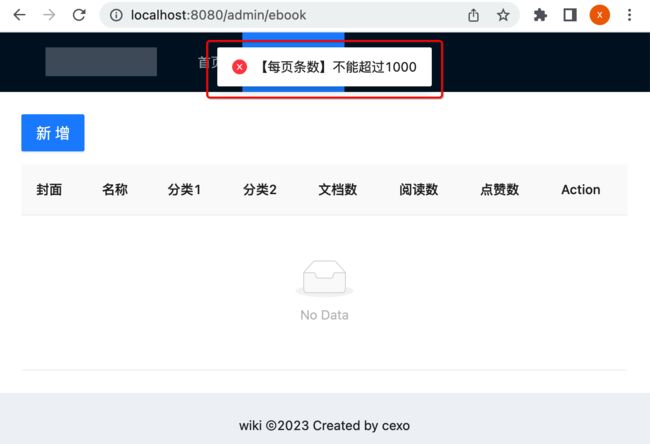
保存接口:
1、后端保存接口增加参数校验:
接下来咱们再给保存接口增加一个参数校验,目前我们在前端保存时,所有表单的字段都是可以为空的:
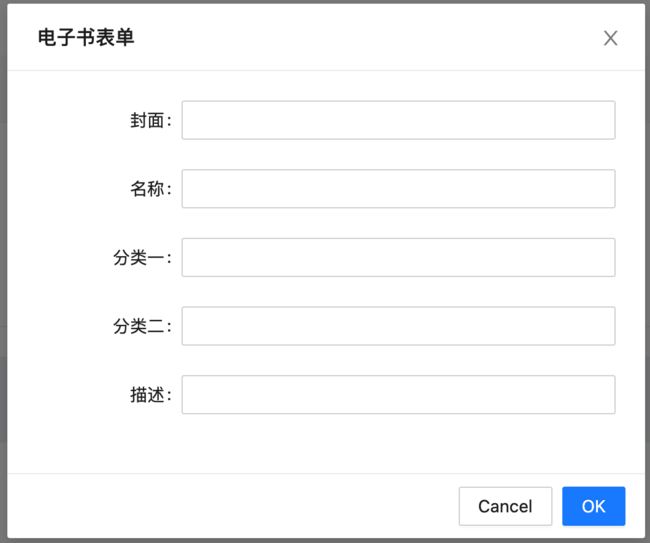
这里咱们给名称增加一个非空的校验,基本步骤是一样的,先来修改保存实体:

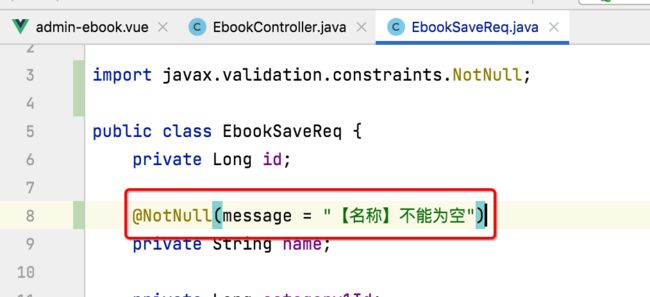
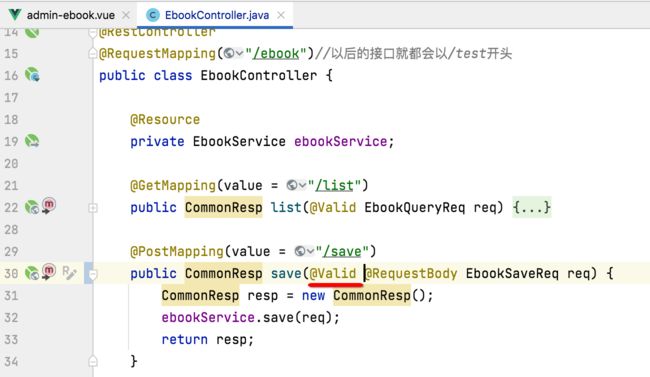
然后再到controller中增加一个注解:
2、前端进行异常处理:
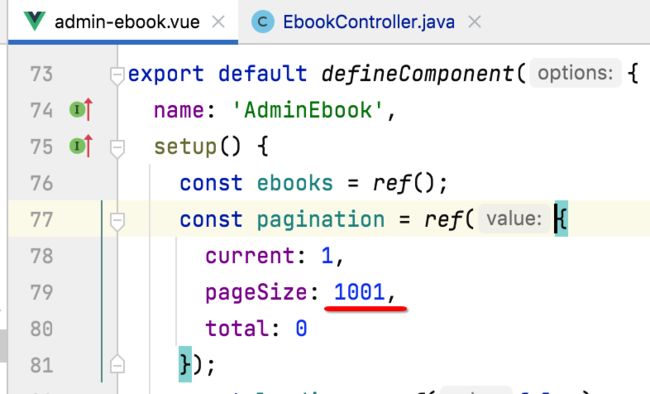
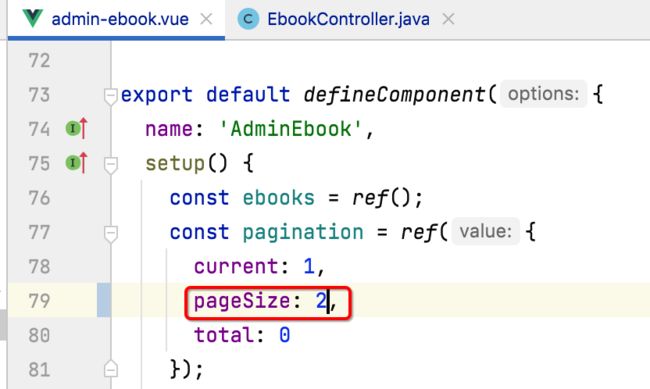
先来将之前测试的pageSize的值还原成正常的:
接下来再来修改保存的代码:
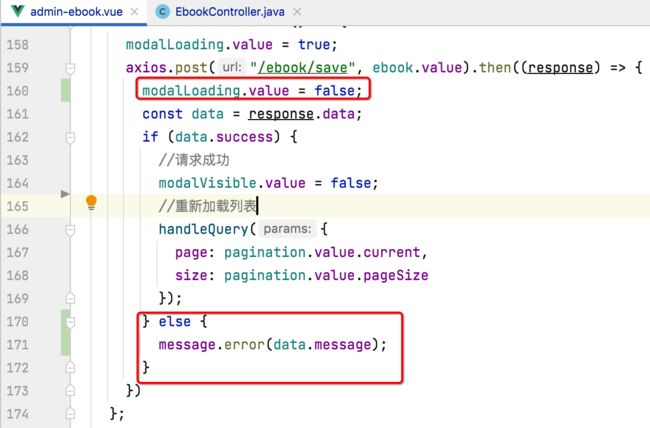
运行:
3、体会将实体类拆分的好处:
还记得上面提到过实体拆分的一个细节么?

其中在这个参数校验的场景中就可以体会分开的好处了:

这块可以仔细体会一下。
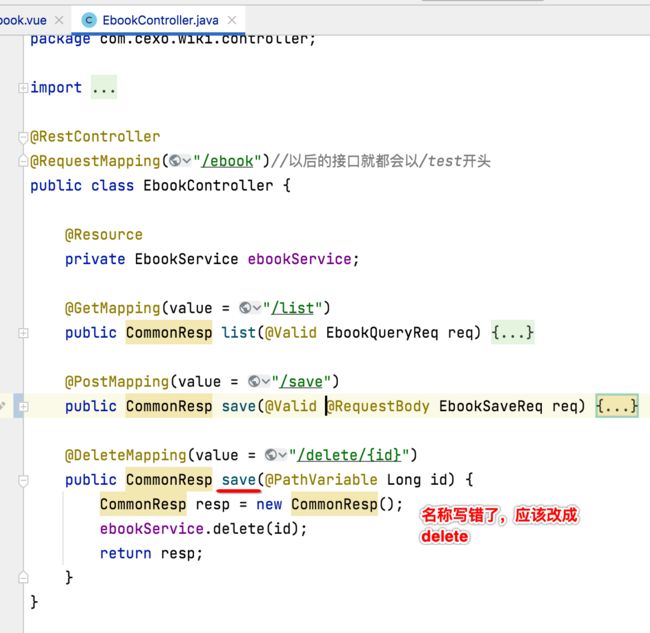
4、手误改正:
这里有一处代码手误,就是删除接口:

电子书增加名字查询功能:
接下来咱们给电子书列表增加一个名字查询功能。
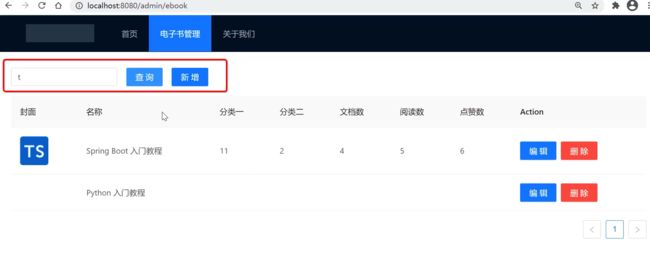
1、增加查询操作入口:
接下来增加一个查询的入口,UI效果如下:
这里依然可以使用ant design的组件,如下:
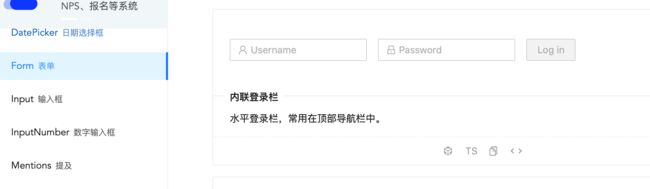
先来看一下它是如何使用的:

所以咱们先来来使用一下:
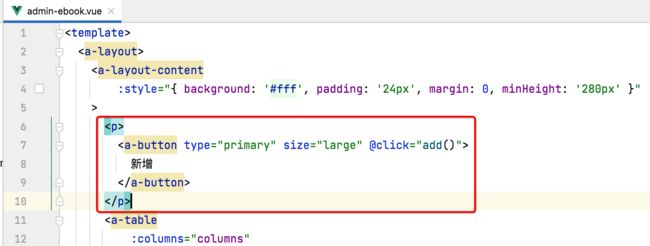
修改为:

此时的效果就出来了。
2、实现查询逻辑:
给查询按钮增加点击事件:

由于在vue中需要调用handleQuery,所以需要将它返回一下:

而handleQuery目前查询入参只传了这俩参数:

很明显此时需要增加一个名称的入参了:

这里应该取名称搜索框中的值对吧,所以此时又需要定义一个响应式的变量了,如下:

那这个响应式的变量怎么跟这个名称的文本框来绑定呢?其实这个在电子书增加编辑那块已经用到过了,这里再来复习一下:

所以:
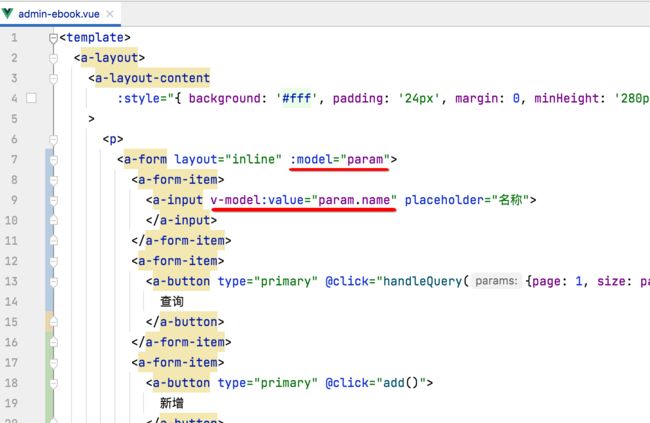
由于在vue元素中需要用到这个响应式的变量,所以我们需要在这return一下它:

就这样根据名称查询的功能就好使了,接口不需要动,为啥?看一下查询接口:

而前端的name输入之后,会自动映射到EbookQueryReq中的name:

3、测试:
接下来咱们测试一下效果,发现报错了:
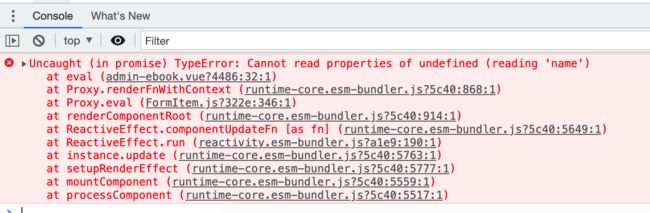
其实是因为没有对这个响应式变量param进行初始化,增加这么一行既可:

那为啥ebooks这个响应式变量在定义的时候貌似也没初始化为啥它不报错呢?其实它也初始化了:

这个细节需要知道,修正之后现在就可以测试一下效果了:
总结:
至此,对于增、删、改、查的前端和后端的效果就已经完整实现了,涉及到的知识点还是很多的,需好好消化,下次继续~~
关注个人公众号,获得实时推送
