基于深度学习的跨分量预测技术
在最新的视频编码标准VVC中,首次提出了跨分量预测技术CCLM,通过建立亮度分量和色度分量的线性模型,实现从亮度分量到色度分量的映射。但是亮度和色度分量间并不总是线性关系,因此许多人提出通过网络来学习亮度分量与色度分量间的关系,来进一步提升的色度分量的预测性能。
目录
2018-ICIP-A HYBRID NEURAL NETWORK FOR CHROMA INTRA PREDICTION
2020-TCSVT-Deep Learning-Based Chroma Prediction for Intra Versatile Video Coding
2020-JSTSP-Attention-Based Neural Networks for Chroma Intra Prediction in Video Coding
2021-ACM-Neural-Network-Based Cross-Channel Intra Prediction
JVET-W0111-AHG11: neural network based cross-component prediction model(Tencent)
JVET-X0130-AHG11: Cross-component prediction based on a neural network model
2018-ICIP-A HYBRID NEURAL NETWORK FOR CHROMA INTRA PREDICTION
这篇文章应该是最早提出将神经网络用于分量间预测的文章。
基于之前的亮度和色度之间建立线性模型从而预测色度像素的LM方法,该文章研究了一种利用神经网络提取亮度像素和色度像素间的相关性,并通过神经网络来预测色度像素的方法。
该文章采用了全连接网络和卷积网络相结合的方法:
- 使用全连接网络提取相邻重建像素的信息
- 使用卷积网络提取重建亮度块的信息
- 将提取出的亮度信息和相邻像素的信息以点乘的方式融合起来再通过卷积网络产生预测值
网络结构:

如图,以YUV420视频中的32x32大小的亮度块为例,由于色度块大小为16x16,所以需要对亮度块先进行下采样, 使其与色度块的分辨率对齐
(1)全连接层:
将下采样后的亮度块的上相邻像素和左相邻像素(16+16+1=33)以及Cb、Cr块的相邻像素拼接成长度为99的一维向量,将其通过三层全连接层,如上图上半部分所示,最终输出长度为128的一维向量,然后将该向量平铺成维度为128x16x16的特征图
(2)卷积层
整个网络总共包含四个卷积层,卷积层的输入是下采样后的16x16的亮度块,首先将16x16的亮度块通过一个5x5的卷积层获得128x16x16的特征图,再将其通过5x5和3x3的组合卷积层,获得128x16x16的特征图,再将该特征图和全连接层输出的128x16x16的特征图进行融合(Element wise Product 对应元素相乘),再将其通过一个1x1和3x3的组合卷积层和一个3x3的卷积层,最终输出2x16x16的图(Cb和Cr)
集成到HEVC
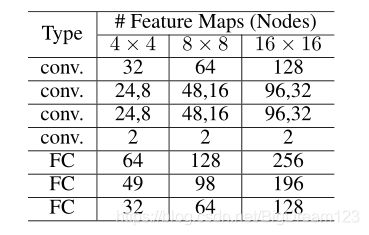
HEVC中,预测是基于变换块大小进行预测的,即色度TU大小包括4x4、8x8和16x16,为了处理不同大小的块,对不同块使用上图所示相同的网络但不同的超参数,各个尺寸TU使用的网络超参数如下:
实验结果
作者将上述的神经网络预测方法和LM预测方法同时集成在HM12.0中,二者共同的增益如下:
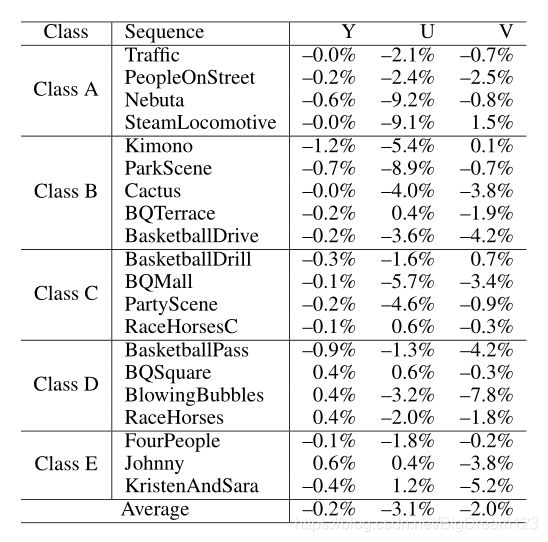
作者同时单独测试了LM方法和该方法的性能,结果表明该方法的性能优于LM方法。图2显示了为序列BQMall选择的色度预测模式,其中蓝色框表示该方法,红色框表示LM方法,可以观察到,提出的模式主要是为具有丰富纹理或结构的区域选择的。此外,提出的模式可以选择相当大的块,但LM主要用于较小的块。

2020-TCSVT-Deep Learning-Based Chroma Prediction for Intra Versatile Video Coding
本文章的亮点在于不再针对每个CU调用一次网络进行预测,而是在通过网络得到整个CTU的预测值,再通过相应CU的位置取出对应位置的预测像素。并且,本文将待预测位置处的像素使用CCLM预测技术初始化,通过网络对预测值进行增强。该网络的性能是跨分量预测相关论文中最好的。
本文提出了使用神经网络进行色度预测,主要包括以下三个方面的内容:
- 本文利用当前块对应的重建亮度块和相邻重建亮度像素以及当前色度块的相邻像素,通过神经网络预测当前色度块(CNN based Chroma Prediction ,CNNCP)
- 整个网络包括两个子网络:亮度下采样网络和色度预测网络;
- 将CNNCP集成到VTM中,通过RDO选出最佳预测模式
整个网络的框架如下图所示:

下采样网络
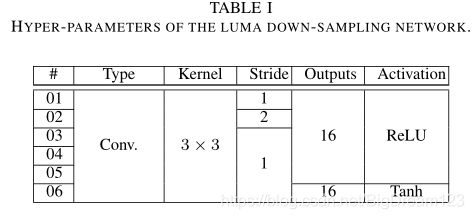
首先将4Nx4N的亮度块通过一个亮度下采样网络将亮度块变为2Nx2N大小,与色度块大小一致。亮度下采样网络包括6个卷积层,第二层的Stride是2,其余层的Stride为1;前5层的激活函数是ReLU,最后一层的激活函数为Tanh;下采样网络的超参数如下图所示
色度预测网络
输入:亮度块通过下采样网络后,获得2Nx2Nx16的亮度下采样图,再使用CCLM预测模式对当前色度块进行预测,将当前预测块和左侧、上侧、左上侧NxN大小的重建块拼成两个大小为2Nx2N的新的色度重建块(Cb、Cr),然后将亮度下采样块和新的色度重建块以及失真D(用Qp表征)级联,共同送入色度预测网络。
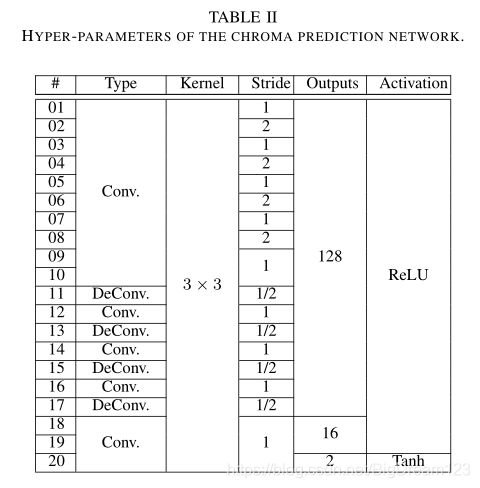
网络结构:色度预测网络共包括20个卷积层,所有卷积层的卷积核大小为3x3,前1-17层输出128个特征图,18-19层输出16个特征图,最后一层输出2Nx2N大小的Cb、Cr分量。整个网络的超参数如下图所示:
获得2Nx2N大小的Cb、Cr分量之后,取出其右下得NxN大小的块即为最终的预测结果。
训练:
使用DIV2K和UCID数据集,使用VTM4.0 Qp{22, 27, 32, 37}对其进行编码,然后进行数据增强后切割为128x128大小的Patch;对于这两个网络,使用如下图c所示的联合训练方法,不考虑亮度下采样的性能,仅考虑最终色度预测的性能。
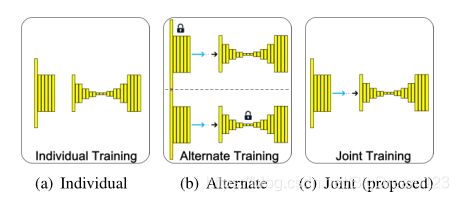
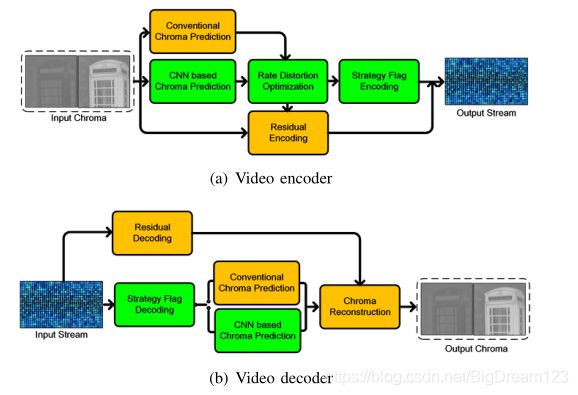
集成到VVC中
在编码端,新增一个标志指示当前色度块使用CNNCP模式还是常规色度模式,通过RDO选择选出最佳的预测模式(常规预测模式、CNNCP),然后将其传到解码端。注意,CNNCP用于CTU level,对于小于CTU的情况,直接将预测结果拷贝到对应区域。
在解码端,首先解出是否使用CNNCP。在CTU中,如果解码标志为1,则使用空间信息和CCLM预测值作为输入计算CNNCP。
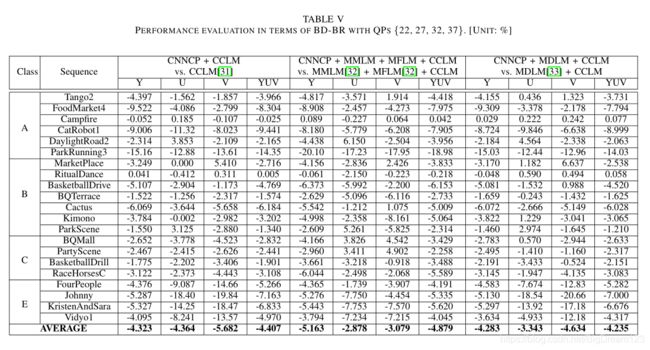
CNNCP和CCLM等的性能比较 :
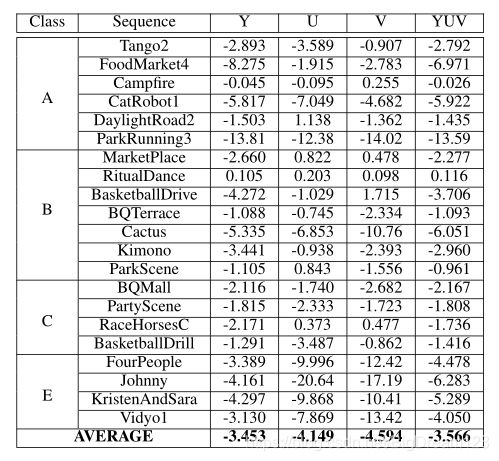
CNNCP在VTM9.3版本的性能:
2020-JSTSP-Attention-Based Neural Networks for Chroma Intra Prediction in Video Coding
本文是基于论文CHROMA INTRA PREDICTION WITH ATTENTION-BASED CNN ARCHITECTURES的改进,在该论文的基础上提出了三种改进方法,但基本思路保存不变,这里仅记录该论文的核心思路,而不记录三种改进方法。

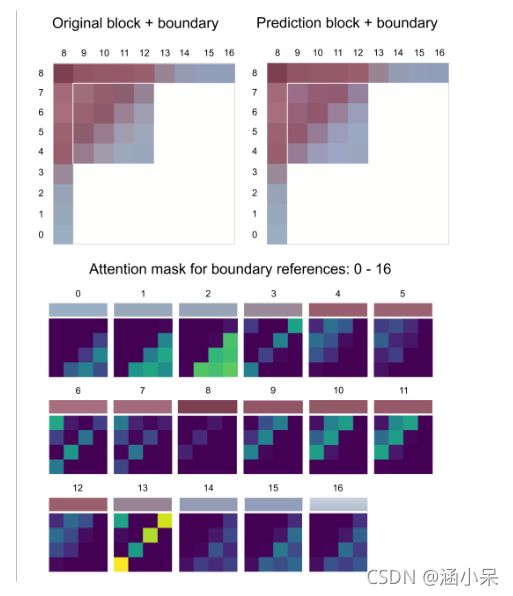
本文提出了一种基于注意力机制的色度预测技术,网络结构如上图所示。网络的输入是YUV三分量的相邻重建像素和下采样后的亮度块。首先分别将相邻重建像素通过卷积提取特征,然后将提取出的特征通过矩阵乘法的方法融合并通过softmax得到上图中的attention mask,将该mask再用于相邻重建像素提取出的特征得到masked volume,最后将其与亮度重建像素提取出的特征通过点乘进行特征融合,得到最后的预测像素。
我认为本文的核心思想是通过相邻重建像素和亮度重建像素,得到了相邻重建像素在当前块各个位置的权重(即attention mask),将该权重再用于相邻重建像素得到色度的初步预测像素(masked volume),再将亮度信息通过点乘的方式和其结合起来,得到最终的预测像素。
本文在该网络的基础上,提出了三种改进:
- 降低卷积运算复杂度;
- 使用稀疏自动编码器的简化跨分量模块
- 将模型整数精度化
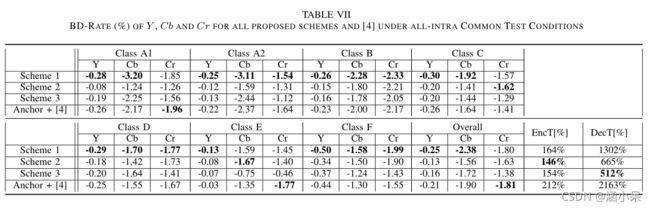
该网络在VTM7.0 的性能如下:(其中Anchor和测试都禁用二叉树、三叉树划分)
2021-ACM-Neural-Network-Based Cross-Channel Intra Prediction
本篇是在第一篇的基础上做的改进,网络的基本思路没变,核心思想是在做预测网络时引入了DCT Loss训练,认为使用DCT Loss训练网络,可以使得loss更接近实际编码中的残差,更好地模拟编码中的损失。

网络基本框架如上图所示,大体结构和第一篇文章类似,只是在融合相邻重建块提取出的信息和亮度块提取出的信息时,使用级联替代点乘的方式。并且在得到最终预测块和原始块计算残差后,将其通过DCT变换,得到频域的残差。
本文还根据网络结构,做了很多消融实验,讨论了不同网络结构参数对性能的影响,在此不做讨论。
训练:
使用DIV2K 训练集,本文认为使用原图训练可以在HM各种质量级别的图像上有很好地泛化能力,因此本文使用原始图进行训练。
实验结果:
本文研究了不同的损失函数对编码性能的影响,如下图所示,通过表中数据可以发现使用DCT域的L1 Loss性能要由于L2 loss和L1 Loss。在之前的研究中曾有人提出L2-Spatial会导致陷入局部极小点而差于L1-Spatial。本文作者发现在训练过程中先使用L2-Spatial损失函数进行训练,再使用L1-Spatial损失函数进行训练,会大幅降低L2-Spatial Loss。

本文还测试了网络在VTM9.0的性能,如下表所示:
其中总共使用4x4、8x8、16x16和32x32四种模型,并对 2N×N或者N×2N将其下采样成NxN的块再通过相应的网络。这样,可以将网络应用于VVC中的10种不同块大小:4×4、8×4、4×8、8×8、16×8、8×16、16×16、32×16、16×32和32×32。
JVET-W0111-AHG11: neural network based cross-component prediction model(Tencent)
本提案提出将当前块的相邻重建像素和对应位置的亮度重建像素共同送入网络中产生UV分量的预测。
如下图所示,先对相邻重建像素和亮度重建像素进行预处理。预处理单元以 YUV 和相邻重建样本作为输入。亮度分量下采样由双三次插值滤波器执行。相邻样本的高度/宽度由 n 决定,其中 n 设置为 4。相邻样本 (n, H) 或 (W, n) 被Transformation为大小 (W, H)。Transformation是通过 W/n 或 H/n 次复制来执行的。亮度通道提供 (W, H, 3) patch,U 和 V 均提供 (W, H, 2) patch。然后全部级联成一个 (W, H, 7) 作为神经网络的输入。

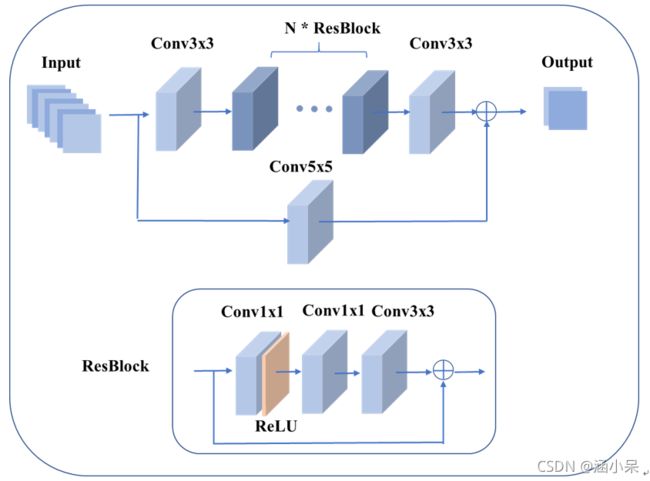
下图显示了网络结构。 第一层和最后一层是核大小为3的常规卷积层。跳过层是核大小为5的规则卷积层。残差块(ResBlock)的结构由3个规则卷积层组成,其中N表示ResBlock的数量。 在此贡献中,N 设置为 8。 在 ResBlock 中,第一层是 1x1 卷积层,后面是 ReLU 激活函数,第二层是 1x1 卷积层,第三层是 3x3 卷积层。 对于内部卷积层,特征图的数量设置为 32。
训练:
| Network Information in Training Stage |
||
| Mandatory |
GPU Type |
GPU: V100 |
| Framework: |
PyTorch v1.5 |
|
| Number of GPUs per Task |
1 |
|
|
|
|
|
| Epoch: |
500 |
|
| Batch size: |
16 |
|
| Loss function: |
L1 |
|
| Training time: |
50h |
|
| Training data information: |
DIV2K |
|
| Training configurations for generating compressed training data (if different to VTM CTC): |
QP = 22, 27, 32, 37, 42 |
|
| Optional |
|
|
| Number of iterations |
||
| Patch size |
32*32 |
|
| Learning rate: |
1e-4 |
|
| Optimizer: |
ADAM |
|
| Preprocessing: |
||
| Mini-batch selection process: |
|
|
| Other information: |
|
|
|
|
|
|
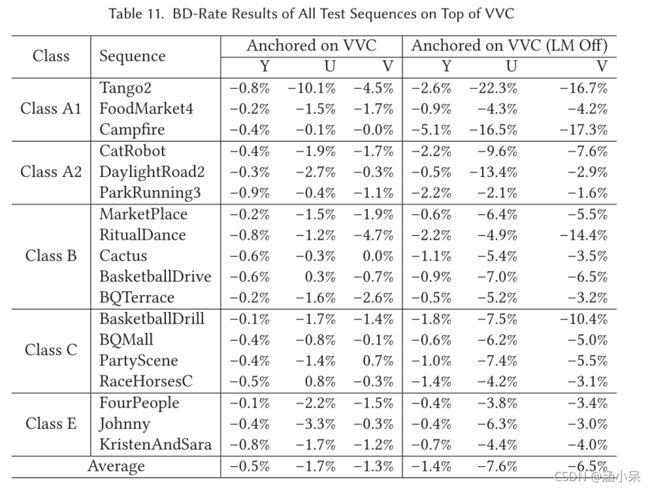
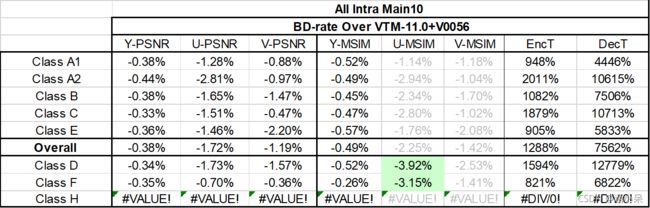
实验结果:(Anchor是VTM11+V0056)
测试1:NNCCP 仅对 8x8、16x16 和 32x32 色度块启用

测试2:NNCCP对所有色度块启用
JVET-X0130-AHG11: Cross-component prediction based on a neural network model
本文提出了一个CCNN网络框架用于UV分量的预测。
CCNN结构如下图所示。 CCNN 将 YUV 420 格式的样本作为输入。为了预测大小为 (W, H) 的色度样本,CCNN 的输入是大小为 (2*W, 2*H) 的亮度重建样本以及亮度和色度分量的相邻重建样本。亮度分量下采样由双三次插值滤波器执行。将(1, H) 或 (W, 1) 的相邻重构样本沿轴复制转换为大小 (W, H)。这些输入样本级联起来形成一个大小为 (W, H, 7) 的张量。第一层、最后一层和跳过层是核大小为5的2D卷积层。残差块(ResBlock)的结构由两个核大小为3的卷积层组成,其中N表示ResBlock的数量,N 设置为 7。InstanceNorm和leaky ReLU激活函数结合到卷积层。对于卷积层,特征图的数量设置为 128。
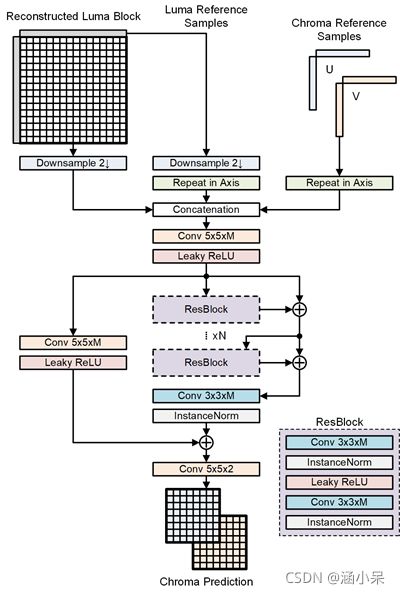
分析:本提案和上篇腾讯的提案输入输出类似,网络结构大体相似,但性能更优,或许是Instance Norm起了一定作用???
训练:
| Network Information in Training Stage |
||
| Mandatory |
GPU Type |
GPU: RTX 3090 x 2 x 24GB |
| Framework: |
PyTorch v1.7.1 |
|
| Number of GPUs per Task |
2 |
|
|
|
|
|
| Epoch: |
48 |
|
| Batch size: |
512 x 2 |
|
| Loss function: |
L2 |
|
| Training time: |
37h |
|
| Training data information: |
BVI-DVC |
|
| Training configurations for generating compressed training data (if different to VTM CTC): |
||
| Optional |
|
|
| Number of iterations |
||
| Patch size |
32*32 |
|
| Learning rate: |
3.16e-4 |
|
| Optimizer: |
ADAM |
|
| Preprocessing: |
normalization |
|
| Mini-batch selection process: |
|
|
| Other information: |
|
|
|
|
|
|
实验结果:(Anchor是VTM11+V0056)
Test1:CCNN仅用于16x16和32x32的色度块
| BD-rate Over VTM-11.0+V0056 |
||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
|
| Class A1 |
-1.19% |
0.16% |
0.79% |
-1.42% |
0.38% |
0.35% |
478% |
8442% |
| Class A2 |
-1.89% |
1.69% |
1.66% |
-2.21% |
1.01% |
1.71% |
374% |
6959% |
| Class B |
-0.54% |
0.91% |
1.27% |
-0.67% |
0.70% |
1.57% |
317% |
6397% |
| Class C |
-0.42% |
0.88% |
1.61% |
-0.63% |
1.25% |
2.76% |
272% |
5228% |
| Class E |
-0.62% |
0.35% |
-0.50% |
-0.80% |
0.96% |
0.30% |
355% |
9782% |
| Overall |
-0.86% |
0.82% |
1.04% |
-1.07% |
0.86% |
1.44% |
344% |
6973% |
| Class D |
-0.34% |
0.49% |
1.89% |
-0.58% |
1.08% |
3.74% |
228% |
6028% |
| Class F |
-0.30% |
0.41% |
0.52% |
-0.26% |
0.99% |
1.39% |
200% |
4637% |
| Random access Main10 |
||||||||
| BD-rate Over VTM-11.0+V0056 |
||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
|
| Class A1 |
-0.38% |
-0.37% |
0.10% |
-0.47% |
0.24% |
-0.03% |
220% |
772% |
| Class A2 |
-0.72% |
0.78% |
0.67% |
-0.83% |
0.61% |
1.18% |
182% |
494% |
| Class B |
-0.23% |
0.47% |
0.95% |
-0.27% |
0.31% |
1.24% |
164% |
439% |
| Class C |
-0.10% |
0.42% |
0.56% |
-0.17% |
0.21% |
1.28% |
166% |
425% |
| Class E |
||||||||
| Overall |
-0.32% |
0.35% |
0.62% |
-0.40% |
0.33% |
0.98% |
178% |
499% |
| Class D |
-0.10% |
0.74% |
1.11% |
-0.23% |
0.73% |
1.92% |
192% |
734% |
| Class F |
-0.11% |
0.23% |
0.03% |
-0.09% |
0.85% |
0.69% |
206% |
345% |
Test2:CCNN仅用于16x16 和 32x32 色度块,并进行 lambda 调整。
| BD-rate Over VTM-11.0+V0056 |
||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
|
| Class A1 |
-0.56% |
-3.71% |
-2.44% |
-0.66% |
-2.83% |
-2.62% |
493% |
9518% |
| Class A2 |
-0.90% |
-2.55% |
-2.17% |
-1.19% |
-3.26% |
-2.32% |
383% |
7965% |
| Class B |
-0.19% |
-3.01% |
-2.91% |
-0.33% |
-3.54% |
-3.01% |
324% |
6900% |
| Class C |
-0.04% |
-2.60% |
-2.03% |
-0.26% |
-3.02% |
-1.93% |
274% |
3974% |
| Class E |
-0.36% |
-2.83% |
-4.02% |
-0.54% |
-2.56% |
-3.68% |
360% |
9704% |
| Overall |
-0.37% |
-2.93% |
-2.70% |
-0.55% |
-3.10% |
-2.70% |
351% |
6982% |
| Class D |
0.03% |
-2.93% |
-1.76% |
-0.18% |
-3.30% |
-0.96% |
231% |
4269% |
| Class F |
0.10% |
-1.94% |
-1.90% |
0.00% |
-2.24% |
-1.65% |
203% |
3803% |
| BD-rate Over VTM-11.0+V0056 |
||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
|
| Class A1 |
0.66% |
-4.04% |
-3.32% |
0.79% |
-3.44% |
-3.10% |
101% |
95% |
| Class A2 |
1.04% |
-4.04% |
-3.74% |
1.10% |
-4.13% |
-3.94% |
101% |
103% |
| Class B |
0.38% |
-3.87% |
-4.13% |
0.37% |
-4.38% |
-4.60% |
101% |
102% |
| Class C |
0.37% |
-3.64% |
-3.61% |
0.41% |
-4.77% |
-4.75% |
101% |
104% |
| Class E |
0.29% |
-3.29% |
-3.77% |
0.23% |
-3.64% |
-4.22% |
101% |
99% |
| Overall |
0.52% |
-3.78% |
-3.76% |
0.55% |
-4.14% |
-4.21% |
101% |
101% |
| Class D |
0.37% |
-3.43% |
-3.54% |
0.34% |
-4.50% |
-4.56% |
101% |
102% |
| Class F |
0.39% |
-2.33% |
-2.41% |
0.40% |
-3.09% |
-3.12% |
100% |
94% |