XML解析之详解
编译软件:IntelliJ IDEA 2019.2.4 x64
DOM4J包版本:dom4j-1.6.1
目录
- 一、XML是什么?
- 二、如何体现XML语言的可扩展性?
- 三、XML主要用来干嘛?
- 四、XML的基本语法
-
- 4.1 语法规范
- 4.2 文档声明
- 4.3 约束文件
- 五、如何进行XML解析?(以Java为例)
一、XML是什么?
XML是一种标记语言,全称为可扩展标记语言(Extensible Markup Language),用于描述数据的结构和内容。它可以被用于表示各种类型的数据,例如文本、数字、图像等。
XML的设计目的是为了使数据的交换和共享更加容易,同时也可以被用于数据的存储和传输。XML文档由标签、属性和文本内容组成,可以通过DTD(文档类型定义)或XML Schema进行验证。XML的语法简单、灵活,被广泛应用于Web服务、数据交换、配置文件等领域。
二、如何体现XML语言的可扩展性?
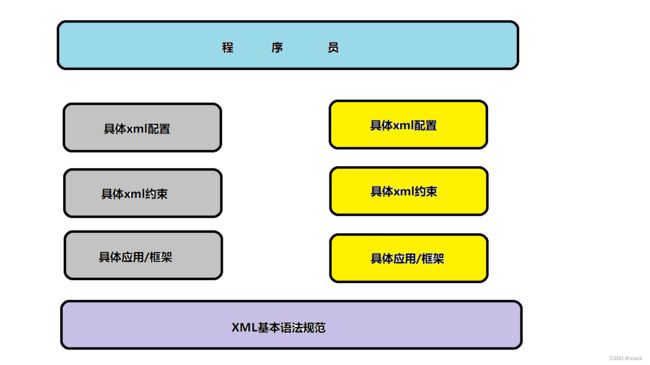
什么是可扩展?顾名思义,就是说可以在原有的基础上增加新的功能。但在XML语言中,意思虽然大致相同,但更为精确的阐述是:虽然XML语言允许我们可以自由定义格式,但并非可以随便乱写,而是要遵从具体的XML约束。
而这些约束则是由各个不同的组织去定义,不同的组织定义了不同的约束。
例如在Java EE中我们常见的web-xml文件,它主要用于用于描述Java Web应用程序的部署信息和配置,有了它,开发人员可以更专注于业务逻辑的实现。而定义它的组织是Java Community Process(JCP)社区,若要编辑web-xml文件,就必须遵从该组织制定的具体约束文件才行。
其他的第三方工具同样如此。在XML基本语法规范的基础上定义它们自己的约束强制规定配置文件中可以写什么和不可以写什么。如下图所示。
三、XML主要用来干嘛?
用途:
-
①异步系统之间进行数据传输的媒介(现在json已经代替了该功能)什么意思? 就是说如果想要Java程序和python程序,c++程序之间进行数据传输,就可以用它作为存放数据的载体,以此传输。
-
②作为配置文件使用什么是配置文件?配置文件是用于给应用程序提供配置参数以及初始化设置的一些有特殊格式的文件,如jdbc中的druid连接池就是使用properties文件作为配置文件。
四、XML的基本语法
XML的基本语法主要由标签、元素、属性和文本内容等语法规范,文档声明(Document Declaration)以及可选的约束文件(例如DTD或XSD)组成。
4.1 语法规范
- 根标签
根标签有且只能有一个。
- 标签关闭
- 双标签:开始标签和结束标签必须成对出现。
- 单标签:单标签在标签内关闭。
- 标签嵌套
- 可以嵌套,但是不能交叉嵌套。
- 注释不能嵌套
- 标签名、属性名建议使用小写字母
- 属性
- 属性必须有值
- 属性值必须加引号,单双都行
ps:上述语法规范和HTML语言的语言规范完全一致,极易简单上手。
4.2 文档声明
文档声明指定了XML版本和字符集信息,一般位于XML文档的第一行
例如如下的代码:
//定义该xml文件的版本为1.0,字符集编码为utf-8
4.3 约束文件
约束文件定义了XML文档的结构和规范,用于确保XML文档的有效性和一致性。主要包括DTD和Schema两种。
需要注意的是,约束文件虽然是XML的重要组成部分之一,但并不是基本语法的必要组成部分。在某些情况下,开发人员可以选择不使用约束文件,而仅仅依赖于XML文档本身的结构和逻辑关系来实现数据的验证和处理。
五、如何进行XML解析?(以Java为例)
作用:
用Java代码读取xml中的数据
步骤:
①准备一个要解析的XML文件,自定义内容
代码演示如下:
<employees>
<employee id="101">
<name>张三name>
<age>18age>
<address>北京address>
employee>
<employee id="102">
<name>李思思name>
<age>22age>
<address>武汉address>
employee>
<employee id="103">
<name>王五name>
<age>32age>
<address>上海address>
employee>
employees>
②在项目中导入DOM4J (
DOM4J是一个Java的XML解析库)包,用IDEA编写相关代码。
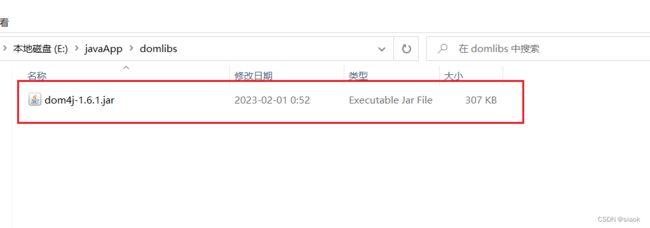
ps:给项目导包与导入Juniite包的步骤一致,这里暂不赘述,如有疑问,可参考这篇博客《Java SE: JUnit快速入门指南》。
a. 创建开始创建xml解析器对象
```java
//1.创建解析器对象
SAXReader reader=new SAXReader();
```
b. 让解析器对象去解析xml文件
```java
//解析XML获取Document对象: 需要传入要解析的XML文件的字节输入流
Document document = reader.read(domTest.class.getClassLoader().getResourceAsStream("employees.xml"));
```
c. 开始获取内容
```java
//获取根节点对象
Element rootElement = document.getRootElement();
//在xml文件里自根节点下如果有多个同名节点的元素,默认找第一个,这里返回第一个employee
Element employee = rootElement.element("employee");
//从employee元素下找名称为name的标签
Element name = employee.element("name");
//获取标签name的内容
System.out.println("name中的内容:"+name.getText());
//获取子标签(每一个element元素)下的标签name的标签体
List elements = rootElement.elements();
for (Element element : elements) {
//获取每一个element元素下的标签name的标签体
System.out.println(element.element("name").getText());
}
//获取第一个employee元素的属性id的值
//获取第一个employee元素
Element element1 = rootElement.element("employee");
//获取属性对象id
Attribute id = element1.attribute("id");
//获取属性对象id的值,然后赋给value
String value = id.getValue();
System.out.println("id:"+value);//打印属性id的值
```
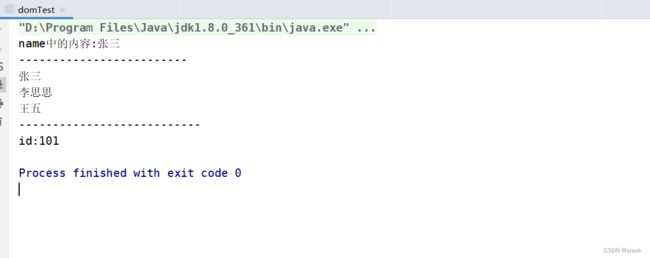
案例:在刚才创建的employees.xml文件中,用Java分别获取第一个子标签employee中的标签name的标签体,所有的子标签employee中的标签name的标签体,以及第一个子标签employee的属性id的属性值
案例完整代码如下(示例):
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.List;
public class domTest {
public static void main(String[] args) {
//1.创建解析器对象
SAXReader reader=new SAXReader();
try {
//写法1获取根标签对象
Document document = reader.read(domTest.class.getClassLoader().getResourceAsStream("employees.xml"));
/*
//写法2获取根标签对象
File file=new File("E:\\javaApp\\day04_xml\\src\\employees.xml");
FileInputStream fis=new FileInputStream(file);
Document document = reader.read(fis);
*/
Element rootElement = document.getRootElement();//获取根节点对象
Element employee = rootElement.element("employee");//在xml文件里自根节点下如果有多个同名节点的元素,默认找第一个,这里返回第一个employee
Element name = employee.element("name");//从employee节点下找名称为name的标签
System.out.println("name中的内容:"+name.getText());//获取标签name的内容
System.out.println("-------------------------");
//获取子标签(每一个element元素)下的标签name的标签体
List<Element> elements = rootElement.elements();
for (Element element : elements) {
//获取每一个element元素下的标签name的标签体
System.out.println(element.element("name").getText());
}
System.out.println("---------------------------");
Element element1 = rootElement.element("employee");//获取第一个employee
Attribute id = element1.attribute("id");//获取属性对象id
String value = id.getValue();//将属性对象id的值赋给value
System.out.println("id:"+value);//打印属性id的值
} catch (Exception e) {
e.printStackTrace();
}
}
}