JDBC和数据库连接池
JDBC基本概念
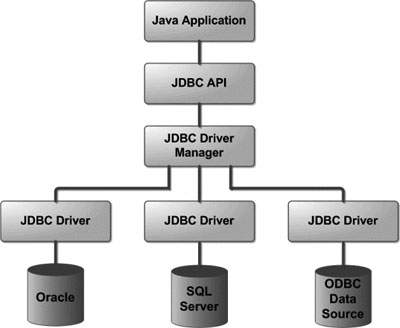
jdbc:Java Database Connectivity
sun公司为了统一对数据库的操作,定义了一套api,称之为jdbc
这套api完全由接口组成,我们在编写程序的时候针对接口进行调用
这些接口交给数据库厂家去实现, 不同的数据库厂商会提供不同的实现类,这些实现类被我们称作数据库的驱动
JDBC基本结构
JDBC API提供了以下接口和类:
- DriverManager: 这个类管理数据库驱动程序的列表。确定内容是否符合从Java应用程序使用的通信子协议正确的数据库驱动程序的连接请求。识别JDBC在一定子协议的第一个驱动器将被用来建立数据库连接。
- Driver: 此接口处理与数据库服务器通信。很少直接直接使用驱动程序(Driver)对象,一般使用DriverManager中的对象,它用于管理此类型的对象。它也抽象与驱动程序对象工作相关的详细信息
- Connection: 此接口与接触数据库的所有方法。连接对象表示通信上下文,即,与数据库中的所有的通信是通过此唯一的连接对象。
- Statement: 可以使用这个接口创建的对象的SQL语句提交到数据库。一些派生的接口接受除执行存储过程的参数。
- ResultSet: 这些对象保存从数据库后,执行使用Statement对象的SQL查询中检索数据。它作为一个迭代器,可以通过移动它来检索下一个数据。
- SQLException: 这个类用于处理发生在数据库应用程序中的任何错误。
JDBC基本操作
// 1. 注册数据库的驱动
DriverManager.registerDriver(new com.mysql.jdbc.Driver());
// 2. 建立与mysql数据库的连接 用到 jdbc api
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "root";
Connection conn = DriverManager.getConnection(url, user, password);
// 3. 创建用于发送sql语句的 Statement 对象
Statement stmt = conn.createStatement();
// 4. 编写一句 sql
String sql = "select * from users";
// 5. 发送sql, 获得结果集
ResultSet rs = stmt.executeQuery(sql);
// 6. 处理结果集
System.out.println("id | name | password | email | birthday");
while(rs.next()) {
// 有第一行
int id = rs.getInt("id"); // 通过列名取值比较直观
String name = rs.getString("name");
String psw = rs.getString("password");
String email = rs.getString("email");
Date birthday = rs.getDate("birthday");
System.out.println(id + " | " + name + " | " + psw + " | " + email + " | " + birthday);
}
// 7. 关闭连接 释放资源
rs.close();
stmt.close();
conn.close();JDBC程序详解
注册驱动
DriverManager.registerDriver(new com.mysql.jdbc.Driver()); 上面的语句会导致注册两次驱动
原因在于,查看Driver类的源码会发现在静态代码块中完成了注册驱动的工作,
也就是说注册驱动其实很简单,只需要加载驱动类即可
Class.forName("com.mysql.jdbc.Driver");创建数据库的连接
Connection conn = DriverManager.getConnection(url, user, password); url: 相当于数据库的访问地址
jdbc:mysql://localhost:3306/test
jdbc: 主协议
mysql:子协议
localhost: 主机名
3306: 端口号
test: 数据库名
url的后面可以跟参数,常用的参数有:user=root&password=root&characterEncoding=UTF-8
如果url地址后面跟了user和password,创建Connection对象时将不必再次传入值
String url = "jdbc:mysql://localhost:3306/test?user=root&password=root&characterEncoding=UTF-8";
Connection conn = DriverManager.getConnection(url);补充: 如果访问的localhost:3306,url 可省写为jdbc:mysql:///test
Statement和PrepareStatement
其实这俩干的活儿都一样,就是创建了一个对象然后去通过对象调用executeQuery方法来执行sql语句。最明显的区别,就是执行的sql语句格式不同。
代码背景:我们有一个数据库,里面有一个user表,有username,userpwd两列。我们要查出这两列的数据。
// 使用
String sql = "select * from users where username= '"+username+"' and userpwd='"+userpwd+"'";
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql); String sql = "select * from users where username=? and userpwd=?";
PrepareStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, username);
pstmt.setString(2, userpwd);
ResultSet rs = pstmt.executeQuery(); PrepareStatement接口是Statement接口的子接口,他继承了Statement接口的所有功能。它主要是拿来解决我们使用Statement对象多次执行同一个SQL语句的效率问题的。ParperStatement接口的机制是在数据库支持预编译的情况下预先将SQL语句编译,当多次执行这条SQL语句时,可以直接执行编译好的SQL语句,这样就大大提高了程序的灵活性和执行效率。
因为预编译,所以PrepareStatement还可以防止sql注入
JDBC事务
什么是事务
所谓事务,就是针对数据库的一组操作(多条sql)
位于同一个事务的操作具备同步的特点,也就是要么都成功,要么都失败
事务的作用
在实际中,我们的很多操作都是需要由多条sql来共同完成的,例如,A账户给B账户转账就会对应两条sql
update account set money=money-100 where name='a';
update account set money=money+100 where name='b';假设第一条sql成功了,而第二条sql失败了,这样就会导致a账户损失了100元,而b账户并未得到100元
如果将两条sql放在一个sql中,当第二条语句失败时,第一条sql语句也同样不会生效,这样a账户就不会有任何的损失—————->这就是事务
事务的实现原理
默认情况下,我们向数据库发送的sql语句是会被自动提交的,开启事务就是相当于关闭自动提交功能,改为手动提交,我们只需要将提交事务的操作放在最后一个操作,这样一来,如果在提交事务之前出现异常,由于没有执行提交操作,事务中未提交的操作就会被回滚掉
事务的特性
事务有四大特性,一般来讲,判断一个数据库是否支持事务,就看数据库是否支持这四个特性
- 原子性(Atomicity): 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生
- 一致性(Consistency): 事务必须使数据库从一个一致性状态变换到另外一个一致性状态
- 隔离性(Isolation): 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离
- 持久性(Durability): 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
事务的隔离级别
多线程开启事务
由于数据库是多线程并发访问的,所以很容易出现多个线程同时开启事务的情况
多线程开事务容易引起 赃读、不可重复读、幻读 的情况发生
赃读:dirty read
是指一个事务读取了另一个事务未提交的数据,这是相当危险的。
设想一下,A要给B转账100元购买商品, 如果A开启了一个事务做了转账的工作
update account set money=money+100 while name='b';
update account set money=money -100 while name='a';A先不提交事务,通知B来查询
这时B来查询账户,由于会读到A开启的事务中未提交的数据,就会发现A确实给自己转了100元
自然就会给A发货,A等B发货后就将事务回滚,不提交,此时,B就会受到损失
不可重复读:non-repeatable read
是指一个事务范围内两个相同的查询却返回了不同数据,原因是在查询的过程中其他事务做了更新的操作
例如,银行做报表,第一次查询A账户有100元,第二次查询A账户有200元,原因是期间A存了100元,这样就会导致一行多次统计的报表不一致
一种更易理解的说法是:在一个事务内,多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该同一数据。那么,在第一个事务的两次读数据之间。由于第二个事务的修改,那么第一个事务读到的数据可能不一样,这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读,即原始读取不可重复。
不可重复读和脏读的区别是:
脏读是读取前一事务未提交的脏数据,不可重复读是在事务内重复读取了别的线程已提交的数据。
有的时候大家会认为这样的结果是正确的,没问题
我们可以考虑这样一种情况:比如银行程序需要将查询结果分别输出到电脑屏幕和写到文件中,结果在一个事务中针对输出的目的地,进行的两次查询不一致,导致文件和屏幕中的结果不一致,银行工作人员就不知道以哪个为准了。
幻读:phantom read 又名虚读
事务1读取指定的where子句所返回的一些行。然后,事务2插入一个新行,这个新行也满足事务1使用的查询
where子句。然后事务1再次使用相同的查询读取行,但是现在它看到了事务2刚插入的行。这个行被称为幻象
例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,以后就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样.
幻读和不同重复度的区别:
从总的结果来看, 似乎两者都表现为两次读取的结果不一致.
但如果你从控制的角度来看,两者的区别就比较大:
对于前者 -> 只需要锁住满足条件的记录
对于后者 -> 要锁住满足条件及其相近的记录
事务的隔离级别
为了避免多线程开事务引发的问题,我们需要将事务进行隔离
事务有四种隔离级别,不同的隔离级别可以防止不同的错误发生
- serializable:可串行化,能避免脏读、不可重复读、幻读情况的发生
- repeatable read:可重读,能避免脏读、不可重复读情况的发生
- read committed:读取提交的内容,可避免脏读情况发生
- read uncommitted:读取未提交的内容最低级别,避免不了任何情况
大多数的数据库系统的默认事务隔离级别都是:Read committed
而MySQL的默认事务隔离级别是:Repeatable Read
数据库连接池
什么是连接池
传统的开发模式下,Servlet处理用户的请求,找Dao查询数据,dao会创建与数据库之间的链接,完成数据查询后会关闭数据库的链接。
这样的方式会导致用户每次请求都要向数据库建立链接而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长。假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大的浪费数据库的资源,并且极易造成数据库服务器内存溢出、宕机。
解决方案: 就是数据库连接池
连接池就是数据库连接对象的一个缓冲池
我们可以先创建10个数据库连接缓存在连接池中,当用户有请求过来的时候,dao不必创建数据库连接,而是从数据库连接池中获取一个,用完了也不必关闭连接,而是将连接换回池子当中,继续缓存
使用数据库连接池可以极大地提高系统的性能
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
实现数据库连接池
dbc针对数据库连接池定义的接口java.sql.DataSource,所有的数据库连接池实现都要实现该接口
该接口中定义了两个重载的方法
Connection getConnection()
Connection getConnection(String username, String password) 数据库连接池实现思路
1. 定义一个类实现java.sql.DataSource接口
2. 定义一个集合用于保存Connection对象,由于频繁地增删操作,用LinkedList比较好
3. 实现getConnection方法,在方法中取出LinkedList集合中的一个连接对象返回
注意:
- 返回的Connection对象不是从集合中获得,而是删除
- 用户用完Connection,会调用close方法释放资源,此时要保证连接换回连接池,而不是关闭连接
- 重写close方法是难点,解决方案: 装饰设计模式、动态代理
开源的数据库连接池
通常我们把DataSource的实现,按其英文含义称之为数据源,数据源中都包含了数据库连接池的实现。
DBCP数据源
DBCP 是 Apache 软件基金组织下的开源连接池实现。
Tomcat 的连接池正是采用该连接池来实现的。该数据库连接池既可以与应用服务器整合使用,也可由应用程序独立使用。
C3P0数据源
C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate,Spring等。C3P0数据源在项目开发中使用得比较多。
c3p0与dbcp区别:
1. dbcp没有自动回收空闲连接的功能
2. c3p0有自动回收空闲连接功能