入门JAVA第十六天 数据库
一 、数据库技术学习内容与方法
1.1学习内容
1 Oracle 数据库
目前最好的关系型数据库
基本的CRUD命令。
SQL语句。select(R),update(U),detele(D),insert(C)
2 MySQL数据库
中小型醒目非常好用的关系型数据库。
灵活,小巧。
3 扩展软件开发流程中数据库设计原则
ER图--->根据需求分析数据库结构。
三范式--->学会使用凡是来规范表结构
4 JDBC
再Java中链接数据库技术
在Java代码中向操作数据库中的数据。就必须使用到JDBC技术。
工具类的封装。DAO-Service的分层。
一定要遵守编码规范
1.2 学习难点
1 数据库高级查询:子查询,多表连接查询,自连接查询。
2 分级查询与聚合函数。
3 分层时事务处理,异常处理,资源释放。必须按规范编写。
1.3 学习方法
1 背:SQL语句就是一些固定的格式。
例如查询所有:select*from 表名
2练习:JDBC的规范
二、 数据库,数据库管理系统,数据库可视化工具
2.1 数据库(DataBase)
数据库:一个保存数据的仓库。
在计算机中只有因公安能长期保存数据。
数据库主要是保存到硬盘的数据。都是以文件的形式保存
2.2 数据库管理系统(DataBase Manager System)
我们平时叫数据库,说的其实是DBSM。
数据库管理系统就是一个软件系统。我们使用这个软件系统来管理保存数据的文件。
我们通过向管理系统发送命令的方式,让管理系统帮我们去管理保存数据的文件。
通过DBMS可更方便的进行数据库的查询,过滤,保存,更新。
2.3 数据库可视化工具
这是一个与数据库管理系统无关的软件。
使用数据库可视化工具可以以界面的方式来管理数据。
 操作Oracle数据库的可视化工具
操作Oracle数据库的可视化工具
 操作MySQL数据库的可视化工具
操作MySQL数据库的可视化工具
三、Oracle 数据库管理系统
3.1 Oracle数据库版本
XE 简化版,是一个可以实现CRUD的一个版本。
企业版和标准版,目前学习阶段不会使用
3.2 SID
我们使用Oracle数据库时。每一个库都是一个实例。实例的位移标识 称为SID。
在Oracle数据库中每一个新工程,是分别创建不同的用户来实现区分。新工程与原有老工程,使用的库是同一个。
Oracle数据库一般只有一个库。其他都是创建不同的用户来实现对应不同的工程。
企业版:SID:orcl
简化版:SID:XE
3.3 sys和system
这是两个Oracle数据库中的管理员账号(DBA)。
Sys有最高的管理权限
但是平时我们是不适用sys与system。
3.4 Scott账号
Oracle数据库中的一个案例账号。
XE版本中没有scott账号。
四、使用可视化工具
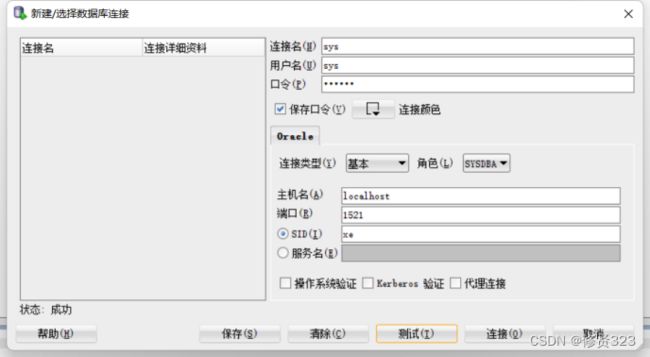
4.1 创建连接
第一步:使用sys或system创建连接
4.2 创建新用户
在Oracle数据库,当有一个新的工程需要开发时,不是创建一个新的数据库。
而是创建新用户来使用。
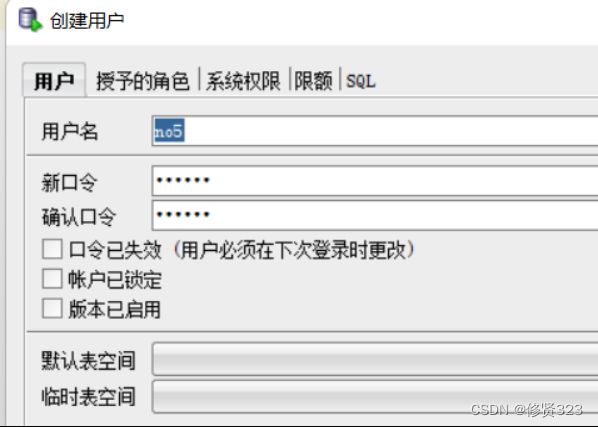
还要为用户绑定角色
CONNECT和RESOURCE
五、数据表(table)
5.1 关系型数据库
Oracle数据库号称关系-对象型数据库。
其实就是在关系型数据库基础上,使用了些对象的概念。
关系:一个关系其实就是一个二维表格。有行和列组成。
5.2 表的结构由列确定
5.3 创建数据表
表中的列由:列名,数据类型,长度大小,非空约束,默认值约束,PK主键约束
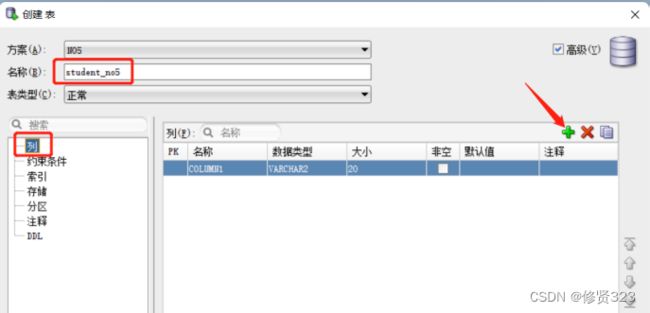
创建数据表就是为表设置列的过程。
列中:数据类型和约束。
六、数据类型
6.1 可变长字符串类型varchar2
一个可以更具输入的字符串大小自动变短的数据类型。
Varchar2(20)表示最长可以保存20个字符长度的字符串类型。
但是当输入的字符串长度不够20时,可以自动将大小缩短到合适的长度。
6.2 数据类型
Integer/int
Float/number(10,2)
number(10,2)表示可以保留10位有效数字,其中小数位是2位
6.3 日期时间
Date 日期
Timestqmp 时间戳
七、完整性约束
完整性约束。是在数据库中为了保证数据 正确性的。
(1) 实体完整性约束
实体:表中每一行
完全完整性约束只有一个:主键约束(PK)
必须保证每一个实体的唯一性。
使用主键约束的列(字段)具有唯一和非空二项属性。
(2)域完整性约束
域:表中的列
域完整性就是用来维护一列数据的正确性。
域完整性约束:数据类型,长度大小,非空,唯一,检查,默认值
(3) 引用完整性约束
引用:两张表之间的关系


引用完整性的约束只有一种:外键约束(FK) 。
(4) 自定义完整性约束
自定义完整性是使用存储过程来实现的。
存储过程。在现在的开发中,明确不在使用的技术。
八、创建数据表
每张表都应该由一个主键字段。
主键字段的条件是实体之间唯一。
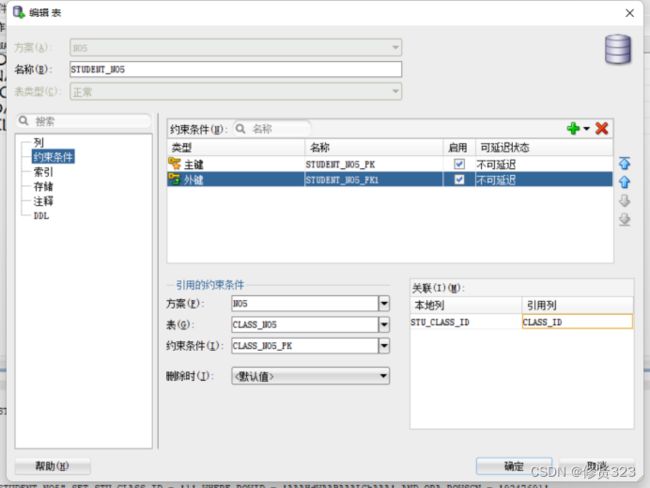
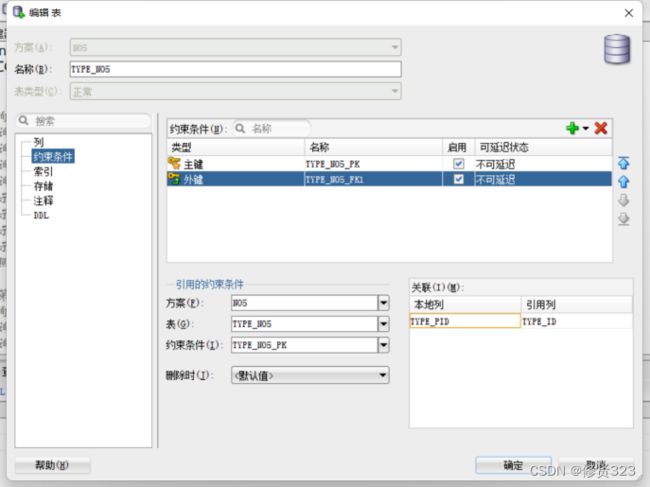
九、创建外键约束
外键约束完成引用完整性的约束条件。
引用完整性一定是两张表。
班级表class_no5 主键表 主键是 class_id
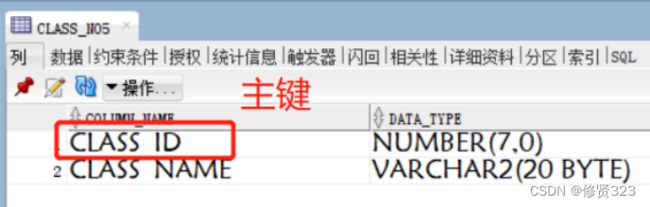
学员表student_no5 外键表 外键是 stu_class_id
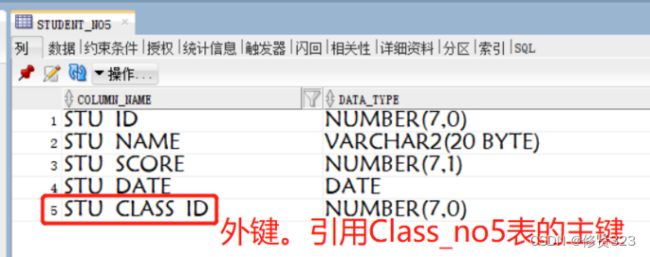
需要stu_ class_id 的字段的值受class_id的约束。
应该为stu_class_id字段加外键约束条件。
十、 三范式
第一范式(1NF):保证域的原子性
列不可再拆分。如果有违反的地方,就需要进行拆分列
例如:地址,姓名。
地址可以拆分省,市,区,街道,详细地址。
姓名可以拆分姓,名。
拆分列
第二范式(2NF):表中的所有非主键字段都依赖于表中的主键字段
取消部分依赖。如果有违反的地方,就需要拆分表。
拆分表 把与主键无关的字段从本表中拆分出去。
第三范式(3NF):表中的所有非主键字段都直接依赖于表中的主键字段
取消传递依赖。如果有违反的地方,就需要进行拆分表。
拆分出去的表,与本表还有关系。
例如:学号,姓名,班级号,教员名
但是教员名是直接依赖于班级。拆分出来两张表。
学号(PK),姓名,学员班级号(FK,引用班级号)
班级号(PK),班级名,教员名
十一、表与表之间关系的映射基数
在数据库中映射基数就四种情况:
一对一,一对多,多对一,多对多。
11.1 一对一映射
当我们发现有两张表之间的关系是一对一映射时,可以合成一张表。
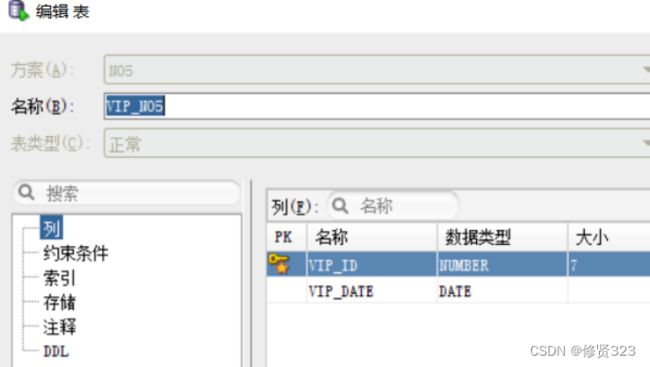
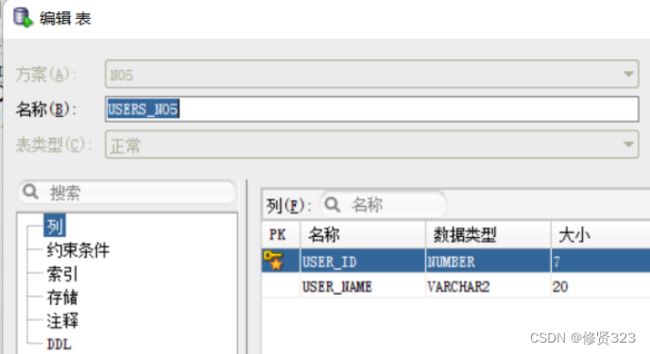
一个用户只能办理一张VIP卡。
两种方案:1 合成一张表。如何选择主键。一定看业务逻辑。
两种方案:2 就两张表。共享主键。A表的主键同时也是B表的外键。
11.2 一对多和多对一
例如:商品与类型
商品N:1类型
一个商品只能属于一种类型。一种类型下可以有多种商品。
商品与类型之间是多对一。
类型与商品之间是一对多。
一对多和多对一 ,一定是两张表。
一定是多的表中加外键,引用一的表。
11.3 多对多映射
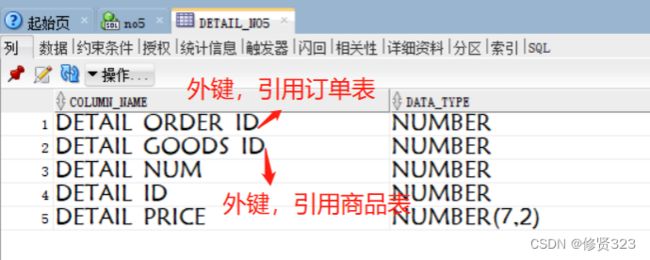
例如:订单与商品
订单 M:N 商品
一个订单可以订购多个商品。一个商品可以被对各订单购物。
订单与商品之间就是多对多关系。
多对多不能只依靠两张表处理,需要创建第三张关系表。将多对多。拆分成两个多对一。
第三章关系表中必须有两张表的外键。
十二、 案例:三范式
总表:将这张表进行拆分

拆分后的人员表单:
| 员工编号 |
姓名 |
年龄 |
地址 |
入职时间 |
职务编号 |
| 1 |
李英豪 |
25 |
南阳 |
2017/2/14 |
1 |
| 3 |
王继成 |
24 |
信阳 |
2017/2/14 |
1 |
| 5 |
高歌 |
30 |
周口 |
2017/2/14 |
2 |
拆分后的职务表单:
| 职务编号 |
职务 |
基本工资 |
| 1 |
软件工程师 |
8K |
| 2 |
高级软件工程师 |
15K |
拆分后的项目表单:
| 项目编号 |
项目 |
| 1 |
河南婚恋云服务平台 |
| 2 |
河南离婚服务系统 |
| 3 |
河南复婚服务系统 |
| 4 |
全国婚恋标准云服务系统 |
拆分后的身份表单:
| 身份编号 |
身份 |
| 1 |
工程师 |
| 2 |
项目经理 |
拆分之后的项目结算表单:
| 编号 |
员工编号 |
项目编号 |
身份编号 |
工时 |
小时工资 |
| 1 |
1 |
1 |
1 |
10 |
0.5K |
| 2 |
1 |
2 |
1 |
30 |
0.7K |
| 3 |
3 |
1 |
1 |
15 |
0.7K |
| 4 |
3 |
2 |
1 |
20 |
0.5K |
| 5 |
3 |
3 |
1 |
10 |
0.5K |
| 6 |
5 |
1 |
2 |
8 |
1K |
| 7 |
5 |
2 |
2 |
5 |
1K |
| 8 |
5 |
3 |
2 |
5 |
1K |
| 9 |
5 |
4 |
1 |
20 |
1K |
十三、SQL命令
13.1 SQL是什么?
SQL结构化查询语言。一种解释型语言。语法结构很简单。
SQL92是一种标准。所有数据库厂商使用SQL语句的标准。
一般数据库厂商也会在SQL92标准之上扩展一些自己的内容。例如函数。
SQL92标准:count(*).
Oracle扩展to_date(),to_char()
13.2 insert语句
用来向数据表中插入记录。
insert into 表名(列名,列名)values(值,值)
insert into type_no5(type_id,type_name)values(3,'甜点');
13.3 使用序列对象
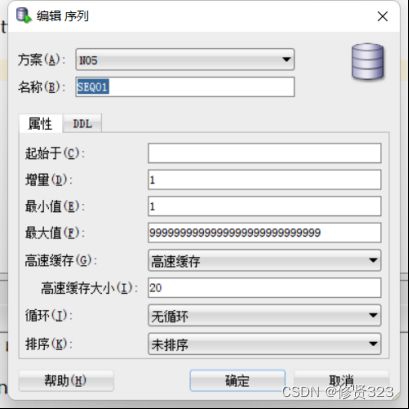
1 创建序列对象
SEQ01
2序列的使用
select seq01.nextval from dual;
序列对象。nextval 表示获取序列的下一个值。
dual是系统提供的一张虚拟表。
因为Oracle数据库不支持只有select语句的格式。 select seq01.nextval X
insert into type_no5(type_id,type_name)values(seq01.nextval,'甜点')
13.4 插入时使用默认值
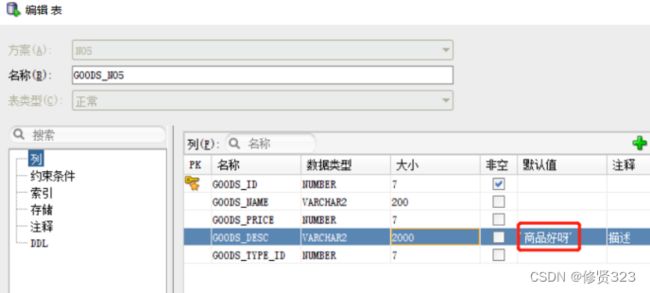
方式一:使用default关键字
insert into goods_no5(goods_id , goods_name,goods_price,goods_desc,goods_type_id)
values(seq01.nextval , '小米手机' , 3.0 , default , 1 )
方式二:不为对应字段插入数据
insert into goods_no5(goods_id , goods_name,goods_price ,goods_type_id)
values(seq01.nextval , '小米手机' , 3.0 , 1 );
13.5 update语句
Update 语句叫更新
update 表名 set 列 = 值,列 = 值 where 条件
满足条件的记录被更新。
update goods_no5 set goods_name='小米6' , goods_price=3999 where goods_id=12
13.6 delete语句
删除记录
delete from 表 where 条件
delete from goods_no5 where goods_id = 14
13.7 两个日期函数
to_date(字符串值,日期模式); 将字符串转成日期类型数据。多用于insert语句。
insert into order_no5(order_id,order_price,order_date)
values(seq01.nextval,100,to_date(‘2023-3-2’,’yyyy-mm-dd‘));
to_char(日期值,日期格式); 将日期类型传承字符串类型。多用于select语句。
select to_char(order_date,'yyyy-mm-dd hh24 :mi:ss') from order_no5;
14 Select语句
14.1 select语句的完整子句
select 查什么,显示什么,
from 从哪查,从哪些表中进行数据的查询。多表查询
where 条件,过来吧记录(行)。满足条件的记录才会被查询出来。
group by 分组惊醒数据统计时经常使用到分组操作。
having 条件,过滤记录(行)。对分组之后的汇总统计结果进行过滤。
order by 排序,对查询结果进行排序。
14.2 select 子句 - 查询所有
Select 子句是对列的过滤。只有在select子句后面出现的列名。才是我们需要查询的列。
Select * from表;
select * from goods_no5;
14.3 select 子句 - 投影查询
投影查询,就是制定和一些字段进行查询显示。
Select 列名,列名 from 表;
select goods_name ,goods_price from goods_no5;
14.4 select 子句 - 别名
别名,可以为每一列创建一个新的别名。
Select字段[as] 别名,表达式 as 别名 from 表 别名
select o1.order_id“编号”,to_char(o1.order_date,'yyyy - mm - dd') as "日期" from order_no5 o1
14.5 select 子句 - 去重
因为 select 子句的查询支持投影查询的方式。
select distinct goods_name from goods_no5;
14.6 where 子句 - 基本应用
在基本应用中,比较基础的判断表达式。
比较运算符。
Where 字段 = 值
Where 年龄 > 20
Where 字段 != 值
逻辑运算符。and or not
Where 字段 = 值 and 字段 > 值
Where not 字段 = 值
14.7 where子句-模糊查询like
Like关键字是在Where子句中的模糊查询。
模糊查询就是一个像什么样的一个查询。
模糊查询只适用于字符串类型。
在使用模糊查询时,必须使用到二个 通配符。
1 % 表示任意多个字符。
2 _ 表示任意一个字符。
Where 字段 like ‘通配符字符串’
查询所有刘姓的同学:select * from 表 where name like ‘刘%’
‘abc’可以在任意位置出现:where 字段 like ‘%abc%’
14.8 where子句-区间查询between…and
Between…and 是区间查询,用来在二个取值的范围之间查询。
区间查询只能应用到数值类型和日期类型
Where 字段 between A and B;
表示字段的取值范围在A-B之间。 [A,B]
等价于 where 字段 >=A and 字段 <=B
Select * from student_no5 where stu_score between 90 and 100 ; --90-100之间的学员信息
14.9 where 子句 - 值列表查询 in
In关键字叫值列表拆线呢,是将多个值,作为一个列表。字段与其中任意一个值相等就表示true。
Where 字段 in (值,值,值)
select * from emp where job in ('SALESMAN','MANAGER');
所有'SALESMAN'和'MANAGER'的emp信息。
14.10 where 子句 - 空值查询 is null
Is null 是用来判断是不是为null。
Where 字段 is null;
select * from emp where comm is not null;
select * from emp where not comm is null;
14.11 Order by 子句 - 排序
Order by 做为select语句的最后一个子句。它的作用也是最后产生的。
是对查询结果的排序。
asc 表示升序。也是默认排序。
desc 表示降序。
Order by 字段1 [asc|desc] [, 字段2 [asc|desc] ]
主排序规则为字段1,字段2只有在字段1相同的记录上起作用。
select * from emp where comm is not null order by sal desc , empno ;
十五、from子句 - 多表查询
在多表查询中,哪一种是按SQL92标准的写法。
但是在Oracle数据库中,将多表查询进行优化。同时也提供一种新的写法。
15.1 多表查询
因为我们按照三范式的要求,将表进行拆分,以减少数据冗余。
拆分开的表,其实在数据上是有关系的。我们在创建数据表时为了维护这个关系使用了主外键约束。
很多时候,在进行查询时,我们时希望同时查询到两张表的数据。
查询商品表时,也希望能将商品关联的类型信息也一次性查询出来。
15.2 多表查询的种类
多表连接拆线呢一共分两类:
1 内连接查询 inner join ... on
2 外连接拆线呢
2.1 左外连接查询 left [outer] join ... on
2.2 右外连接查询 right [outer] join ... on
2.3 完全外连接查询 full [outer] join ... on
(1) 内连接查询
From A inner join B on A_B_ID = B_ID
内连只要满足连接条件的记录。
select * from A inner join B on a_b_id = b_id;
查询方式:用A表中的所有记录与B表中的所有记录进行一一匹配。
(2) 左外连接查询
From A left join B on A_B_id = b_id;
左连要满足连接条件的记录,同时还要坐标中所有记录。使用null值来补右表的字段值。
(3) 右外连接查询
From A right join B on A_B_ID = B_ID
右连要满足连接条件的记录 ,同时还要右表中所有记录。使用null值来补左表的字段值。
(4) 完全外连接查询
From A full join B on a_b_id = b_id
完全连接要满足连接条件的记录,同时还要左表和右表中的所有记录。使用null值来补。
(5) Oracle 数据库中对多表查询的扩展
1 内联
select * from A,B where a_b_id = b_id ;
2 左联
select * from A,B where a_b_id = b_id(+) ;
3 右联
select * from A,B where a_b_id(+) = b_id ;
十六、自连接
自连接:一种数据表结构。
自连接:自己连接自己的数据表结构。
自连接:自己表中的外键字段,引用自己表中的主键字段的数据表结构。
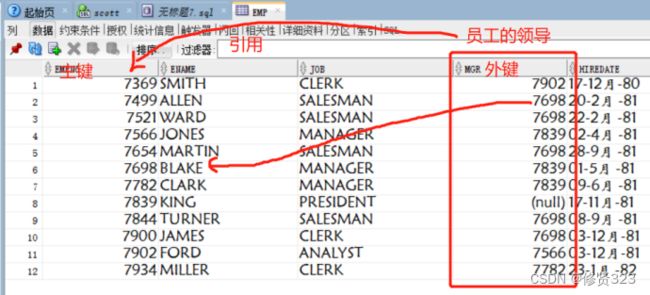
16.1 为什么使用自连接方式
需求:
商品有类型,类型分大类和小类。商品属于小类。小类属于大类。
大类表:
大类id,大类名称
小类表:
小类id,小类名称,大类id
商品表:
商品id,商品名称,商品价格,小类id
需求变化:类型想多分一级。大,中,小。
将大,中,小全部放到一张表中。
商品类型表:
类型id,类型名称,父类型id
1 手机 null
2 苹果手机 1
3 果14 2
4 果14 pro 2
商品表:
商品id,商品名称,商品价格,类型id
16.2 自连接的查询
select e1.empno,e1.ename,e1.mgr,e2.name
from emp e1 left join emp e2
on e1.mgr = e2.empno;
一定要为表起别名,否则在自连接时会无法确定是哪张表的数据。
16.3 扩展类型表
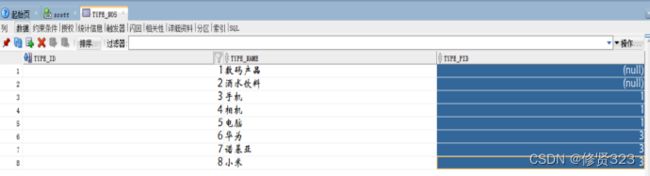
如果有一个商品是属于类型编号8的商品。
要求按类型编号1查询商品?
select * from goods_no5 where goods_type_id
in (
select type_id from type_no5 where type_path like '%|1|%'
);
在类型表中加入一些字段。
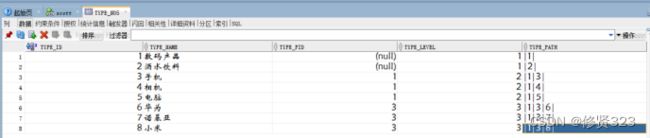
Type_level 表示级别,Type_path 表示路径
在自连接表结构中,针对第一级(顶级)和其他子类的操作一定是不相同的。
1 第一级(顶级)
type_pid = null,type_level = 1,type_path = '|自己的ID|'
2 其他子类
先确定是哪一个节点的子级。(例如:为4节点增加一个子级-卡片机)
type_pid = 4,type_level = 3(父节点 level +1),
type_path = '|1|4|9|' (父节点path|自己的ID|)

实际开发中发现了一个问题?使用父类型编号查询时,应该也可以查询出所有属于子类型的商品信息。
如果有一个商品是属于类型编号8的商品。
要求按类型编号3(手机)查询商品?
第一步:查询3类型下的所有子类型的编号列表
select type_id from type_no5 where type_path like '%|3|%'
第二步:拆线呢所有属于第一步查询到的编号列表的商品
select * from goods_no5 where goods_type_id in(第一步查询结果)
第三步:整合
select * from goods_no5 where goods_type_id
in (
select type_id from type_no5 where type_path like '%|3|%'
)
十七、group by 子句 - 分组查询
分组:将数据按只当的字段,将相同的值分成一组。
select ?
from 表
group by 分组字段
在数据库中,分组之后,每一组的多条记录,就为当成一个整体。
每一组只能提供一个整体的数据。例如:每组的人数是多少,总分是多少。
因为魅族只有能一个结果。分组之后。每一组只能是一行数据。
在使用select子句时,只能出现整体的数据(人数,总分,平均分,最大,最小)和分组字段。
1 分组字段
2 整体的数据
select deptno from emp group by deptno;
select job from emp group by job;
select dept.deptno,dept.dname,dept.loc
from emp left join dept on emp.deptno = dept.deptno
group by dept.deptno,dept.dname,dept.loc;十八、 聚合函数
Count(字段) 计数 统计非null的个数。
select count (*) from emp;
select count (comm) from emp; --4.因为有8个null;
Sum (字段) 和
Avg (字段) 平均值
select count(comm), sum(comm), avg(comm) from emp;
4 2200 550
Min(字段) 最小
Max(字段) 最大
聚合函数一般都要配合分组一起使用。当一起使用时,表示每组进行单独的统计。
select deptno,count(*),sum(sal) from emp group by deptno;
十九、分组过滤条件 - having
Having的过滤是在分组聚合之后,将分组聚合之后的数据进行记录的过滤。
例一. 显示各个部门经理('MANAGER')的工资,并显示低于2500的记录
select deptno,sum(sal) from emp
where job = 'MANAGER'
group by deptno
having sum(sal) < 2500 ;
例二.查出平均工资大于2000的部门
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > 2000 ;
例三. 查询出有3个以上下属的员工信息(分级查询-having)
select e2.empno,e2.ename,e2.job , count(*)
from emp e1 left join emp e2 on e1.mgr = e2.empno
group by e2.empno,e2.ename,e2.job
having count(*) > 3 ;
二十、任务:完成行转列
case ... end case
学员考勤记录表:
| 编号 | 学员ID | 日期 | 记录类型 |
| 1 | 1 | 3.1 | 迟到 |
| 2 | 1 | 3.2 | 迟到 |
| 3 | 3 | 3.2 | 迟到 |
| 4 | 4 | 3.2 | 迟到 |
| 5 | 3 | 3.3 | 旷课 |
| 6 | 3 | 3.4 | 早退 |
| 7 | 4 | 3.4 | 请假 |
| 8 | 1 | 3.5 | 迟到 |
| 9 | 1 | 3.6 | 迟到 |
| 10 | 2 | 3.6 | 请假 |
查询的结果是每一个人的当月出勤统计情况。
| 学员ID | 月份 | 迟到 | 早退 | 旷课 | 请假 |
| 1 | 3 | 4 | 0 | 0 | 0 |
| 2 | 3 | 0 | 0 | 0 | 1 |
| 3 | 3 | 1 | 1 | 1 | 0 |
| 4 | 3 | 1 | 0 | 0 | 1 |