SpringBoot操作Redis
Redis
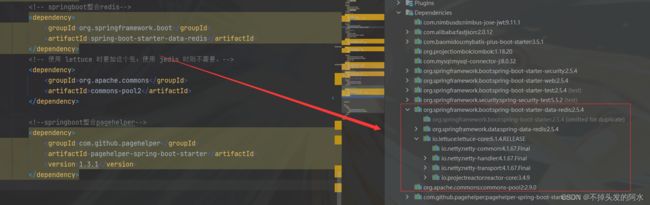
1、 添加redis依赖
spring Boot 提供了对 Redis 集成的组件包:spring-boot-starter-data-redis,它依赖于 spring-data-redis 和 lettuce 。
另外,这里还有两个小细节:
- Spring Boot 1.x 时代,spring-data-redis 底层使用的是 Jedis;2.x 时代换成了 Lettuce 。
- Lettuce依赖于 commons-pool2
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
2、配置文件
## Redis 服务器地址
spring.redis.host=localhost
## Redis 服务器连接端口
spring.redis.port=6379
## Redis 数据库索引(默认为 0)
spring.redis.database=0
## 以下非必须,有默认值
## Redis 服务器连接密码(默认为空)
spring.redis.password=
## 连接池最大连接数(使用负值表示没有限制)默认 8
spring.redis.lettuce.pool.max-active=8
## 连接池最大阻塞等待时间(使用负值表示没有限制)默认 -1
spring.redis.lettuce.pool.max-wait=-1
## 连接池中的最大空闲连接 默认 8
spring.redis.lett uce.pool.max-idle=8
## 连接池中的最小空闲连接 默认 0
spring.redis.lettuce.pool.min-idle=0
3、操作redis API
在这个单元测试中,我们使用 redisTemplate 存储了一个字符串 "Hello Redis" 。
Spring Data Redis 针对 api 进行了重新归类与封装,将同一类型的操作封装为 Operation 接口:
| 专有操作 | 说明 |
|---|---|
| ValueOperations | string 类型的数据操作 |
| ListOperations | list 类型的数据操作 |
| SetOperations | set 类型数据操作 |
| ZSetOperations | zset 类型数据操作 |
| HashOperations | map 类型的数据操作 |
//解决中文乱码问题
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate redisTemplateInit(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置序列化Key的实例化对象
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置序列化Value的实例化对象
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
/**
*
* 设置Hash类型存储时,对象序列化报错解决
*/
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
}
4、RedisTemplate 和 StringRedisTemplate
RedisTemplate
但是很显然,这和 Redis 的实际情况是相违背的:在最小的存储单元层面,Redis 本质上只能存字符串,不可能存其它的类型。这么看来,StringRedisTemplate 更贴合 Redis 的存储本质。那么 RedisTemplate 是如何实现以任何类型(通过对value 值的序列化完成的)。
而使用RedisTemplate 存储对象时会把对象的地址保存起来,以便反序列化,这样就大大浪费存储空间,解决这个问题使用StringRedisTemplate ,认为手动对对想序列化与反序化
Users users = new Users();
users.setId(2);
users.setUsername("李四2");
redisTemplate.opsForValue().set("user:2", JSON.toJSONString(users)); //存的时候序列化对象
String u = redisTemplate.opsForValue().get("user:2"); //redis 只能返回字符串
System.out.println("u="+ JSON.parseObject(u,Users.class)); //使用JSON工具反序化成对象
若springboot中没有引入spring-boot-starter-web依赖,需要加jackson 的依赖。
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
dependency>
5、SpringBoot操作String字符串
a、键过期
key的自动过期问题,Redis 在存入每一个数据的时候都可以设置一个超时间,过了这个时间就会自动删除数据。
常用的redis时间单位
MINUTES:分钟
SECONDS:秒
DAYS: 天
//给user对象设置10分钟过期时间
redisTemplate.opsForValue().set("user:1", JSON.toJSONString(users),10,TimeUnit.MINUTES );
b、删除数据
//删除键
redisTemplate.delete(key);
//判断键是否存在
boolean exists = redisTemplate.hasKey(key);
6、SpringBoot操作Hash(哈希)
一般我们存储一个键,很自然的就会使用 get/set 去存储,实际上这并不是很好的做法。Redis 存储一个 key 会有一个最小内存,不管你存的这个键多小,都不会低于这个内存,因此合理的使用 Hash 可以帮我们节省很多内存。
@Test
public void testHash() {
String key = "tom";
HashOperations<String, Object, Object> operations = redisTemplate.opsForHash();
operations.put(key, "name", "tom");
operations.put(key, "age", "20");
String value= (String) operations.get(key,"name");
System.out.println(value);
}
根据上面测试用例发现,Hash set 的时候需要传入三个参数,第一个为 key,第二个为 field,第三个为存储的值。一般情况下 Key 代表一组数据,field 为 key 相关的属性,而 value 就是属性对应的值。
7、SpringBoot操作List集合类型
Redis List 的应用场景非常多,也是 Redis 最重要的数据结构之一。 使用 List 可以轻松的实现一个队列, List 典型的应用场景就是消息队列,可以利用 List 的 Push 操作,将任务存在 List 中,然后工作线程再用 POP 操作将任务取出进行执行。
/**
* 测试List
* leftPush 将数据添加到key对应的现有数据的左边,也就是头部
* leftPop 取队列最左边数据(从数据库移除)
* rightPush 将数据添加到key对应的现有数据的右边,也就是尾部
*/
@Test
public void testList() {
final String key = "list";
ListOperations<String,Object> list = redisTemplate.opsForList();
list.leftPush(key, "hello");
list.leftPush(key, "world");
list.leftPush(key, "goodbye");
Object mete = list.leftPop("list");
System.out.println("删除的元素是:"+mete); //删除 goodbye
String value = (String) list.leftPop(key);
System.out.println(value.toString());
// range(key, 0, 2) 从下标0开始找,找到2下标
List<Object> values = list.range(key, 0, 2);
for (Object v : values) {
System.out.println("list range :" + v);
}
}
}
Redis List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
8、SpringBoot操作Set集合类型
Redis Set 对外提供的功能与 List 类似,是一个列表的功能,特殊之处在于 Set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个成员是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
/**
* 测试Set
*/
@Test
public void testSet() {
final String key = "set";
SetOperations<String,Object> set = redisTemplate.opsForSet();
set.add(key, "hello");
set.add(key, "world");
set.add(key, "world");
set.add(key, "goodbye");
Set<Object> values = set.members(key);
for (Object v : values) {
System.out.println("set value :" + v);
}
Boolean exist = set.isMember(key,"hello") //判断是否存在某个元素
operations.move("set", "hello", "setcopy"); //把set集合中的hello元素放到setcopy 中
}
}
9、SpringBoot操作ZSet集合类型
Redis ZSet 的使用场景与 Set 类似,区别是 Set 不是自动有序的,而 ZSet 可以通过用户额外提供一个优先级(Score)的参数来为成员排序,并且是插入有序,即自动排序。
/**
* 测试ZSet
* range(key, 0, 3) 从开始下标到结束下标,score从小到大排序
* reverseRange score从大到小排序
* rangeByScore(key, 0, 3); 返回Score在0至3之间的数据
*/
@Test
public void testZset() {
final String key = "lz";
ZSetOperations<String,Object> zset = redisTemplate.opsForZSet();
zset.add(key, "hello", 1);
zset.add(key, "world", 6);
zset.add(key, "good", 4);
zset.add(key, "bye", 3);
Set<Object> zsets = zset.range(key, 0, 3);
for (Object v : zsets) {
System.out.println("zset-A value :"+v);
}
System.out.println("=======");
Set<Object> zsetB = zset.rangeByScore(key, 0, 3);
for (Object v : zsetB) {
System.out.println("zset-B value :"+v);
}
}
}