一个新的微型ORM开源框架
Weed3 一个微型ORM框架(只有0.1Mb哦)
源码:https://github.com/noear/weed3
源码:https://gitee.com/noear/weed3
05年的时候开始写这个框架的1代版本。。。
08年时进入互联网公司重构写了2代版本。。。
14年重构写了现在的3代版本(有java 和 .net 的两个平台版本)。。。
最近被迫加了xml sql mapper的支持。。。
然后顺带加了sql注解。。。
终于包也变大到0.1Mb了。。。
上次一个群里的朋友说,这是个清奇的框架。这个讲法很有意思啊。。
总体上来讲,这个框架的特点就是不喜欢反射、不喜欢配置(但仍然避免不了)!!!是希望通过良好的接口设计,来完全成简洁的操控体验。或许你觉得随便手写点sql都比它好(怎么可能呢,哈哈~~)
对于一些老人来说,这样描述可能给较好:它相当于 mybatis + mybatis-puls (有个对标物,容易理解些)。。。不过我没用过它们,可能讲得也不对。
另外,它很小,它很快,它很自由(也有人说,太自由反而难控制)
【1】先Hello world一下
- 建个任何类型的java项目,引入框架包
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3artifactId>
<version>3.2.3.4version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
- 不用任何配置,三行代码就可运行
// hello world 走起...(数据库链接改个对口的...)
public static void main(String[] args){
DbContext db = new DbContext("user","jdbc:mysql://127.0.0.1:3306/user","root","1234");
String rst = db.sql("SELECT 'hello world!'").getValue();//获取值
System.out.println(rst);
}
//
// 如果是 mybatis ,估计得先忙会儿配置...
//
- 应该算是简单的吧(引入两外包;写三行代码)
不能hello world的东西不是好东西。哈哈:-P
weed3 支持纯java链式写法 或者 xml mapper写法。安排上会先介绍纯java写法。。。再慢慢讲开来。
【2.1】开始纯java使用
纯java使用时,有三大接口可用:
db.table(..), db.call(..), db.sql()。一般使用db.table(..)接口进行链式操作居多。它的接口采用与SQL映射的方式命名。。。使用的人,容易想到能有哪些链式接口。像:.where(..) .and(..) .innerJoin(..)等…
链式操作的套路:
以db.table(..)开始。
以.update(..)或.insert(..)或.delete(..)或.select(..)。
其中.select(..)会返回IQuery接口,提供了各种类型结果的选择。
首先,添加meven依赖
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3artifactId>
<version>3.2.3.4version>
dependency>
然后,实例化数据库上下文对象
- 所有weed3的操作,都是基于DbContext。所以要先实列化一下。。。
- 需要有配置,可以在
application.properties获取,可以通过配置服务获取,可以临时手写一下。。
如果是 Spring 框架,可以通过注解获取配置
如果是 solon 框架,可以通过注解 或 Aop.prop().get(“xxx”)获取配置
2.有配置之后开始实列化DbContext。这里临时手写一下。
//使用proxool线程池配置的示例(好像现在不流行了)
DbContext db = new DbContext("user","proxool.xxx_db");
//使用DataSource配置的示例(一般使用连接池框架时用;推荐 Hikari 连接池)
//下行demo里用的正是 Hikari 连接池
DbContext db = new DbContext("user",new HikariDataSource(...));
//还有就是用url,username,password
DbContext db = new DbContext("user","jdbc:mysql://x.x.x:3306/user","root","1234");
/* 我平时都用配置服务,所以直接由配置提供数据库上下文对象。 */
现在,开始做简单的数据操作
- 常规查询操作
//统计小于10的用户数量
long num = db.table("user_info").where("user_id, 10).count();
//检查用户是不是存在
bool rst = db.table("user_info").where("user_id=?", 10).exists();
//获取用户性别
int sex = db.table("user_info").where("user_id=?", 10)
.select("sex").getValue();
//获取一个用户信息
UserModel mod = db.table("user_info").where("user_id=?", 10).and("sex=1")
.select("*").getItem(UserModel.class);
- 再来一把全套的"增删改查"
//简易.增
db.table("test").set("log_time", "$DATE(NOW())").insert();
//简易.删
db.table("test").where("id=?",1).delete();
//简易.改
db.table("test").set("log_time", "$DATE(NOW())").where("id=?",1).update();
//简易.查
var map = db.table("test").where("id=?",1).select("*").getMap();
关于条件的另一套接口
//where 组
whreEq(filed,val) //filed等于val
whereLt(filed,val) //小于
whereLte(filed,val) //小于等于
whereGt(filed,val) //大于
whereGte(filed,val) //大于等于
whereLk(filed,val) // LIKE
whereIn(filed,ary) // IN
whereNin(filed,ary) // NOT IN
//and 组
andEq(filed,val) //filed等于val
andLt(filed,val) //小于
andLte(filed,val) //小于等于
andGt(filed,val) //大于
andGte(filed,val) //大于等于
andLk(filed,val) // LIKE
andIn(filed,ary) // IN
andNin(filed,ary) // NOT IN
//or 组
orEq(filed,val) //filed等于val
orLt(filed,val) //小于
orLte(filed,val) //小于等于
orGt(filed,val) //大于
orGte(filed,val) //大于等于
orLk(filed,val) // LIKE
orIn(filed,ary) // IN
orNin(filed,ary) // NOT IN
//demo::
db.table("test").whereEq("id",1).delete();
db.table("test").whereEq("id",1).orEq("name","xidong").delete();
这是一个简单的开始,希望能有个好的印象。
【2.2】细讲插入和更新
这一节重点讲讲插入和更新的赋值
- 支持常规赋值
String mobile="xxx"; //我的手机号不能写
db.table("test")
.set("mobile",mobile) //变量赋值
.set("sex",1) //常量赋值
.insert();
- 支持sql附值(这个是可以带来方便的***)
如果值以:$开头,表示后面为SQL代码(不能出现空隔,且100字符以内。否则视为普通字符串值),如下:
//比如:当前时间赋值
db.table("test").set("log_time","$NOW()").insert();
//再比如:字段加1附值
db.table("test").set("num","$num+1")
.where("id=?",1).update();
//再比如:根据另一个字段的md5,批量更新
db.table("test").set("txt_md5","$MD5(txt)")
.where("id>? AND id,1000,2000).update();
/* 如何开启或禁用功能?(其实,它是挺安全的)*/
//1.只控制本次操作是否使用此功能
db.table("test").usingExpr(false) // true 开启,false 关闭
//2.全局配置开启或关掉这个功能:
WeedConfig.isUsingValueExpression=false; //全局默认关掉
- 支持map附值(字段不能是数据表里没有的…)
Map<String,Object> map = new HashMap<>();
...
//插入
db.table("test").setMap(map).insert();
//更新
db.table("test").setMap(map).where("id=?",1).update();
- 支持 entity 附值(字段不能是数据表里没有的…)
UserModel user = new UserModel();
//插入
db.table("test").setEntity(user).insert();
//更新
db.table("test").setEntity(user).where("id=?",1).update();
- 支持(没有则插入,有则更新)的简化操作
//简化方案
db.table("test")
.set("mobile","111")
.set("sex",1)
.set("icon","http://xxxx")
.updateExt("mobile");
//此代码相当于:(下面这个可麻烦了很多哦)
if(db.talbe("test").where("mobile=?","111").exists()){
db.talbe("test")
.set("mobile","111")
.set("sex",1)
.set("icon","http://xxxx")
.insert()
}else{
db.talbe("test")
.set("sex",1)
.set("icon","http://xxxx")
.where("mobile=?","111").update();
}
- 支持根据情况附值(讲法来怪怪的…)
//1.老套跑
var qr = db.table("test").set("sex",1);
if(icon!=null){
qr.set("icon",icon);
}
qr.where("mobile=?","111").update();
//2.链式操作套路
db.table("test").set("sex",1).expre((tb)->{ //加个表达式
if(icon!=null){
tb.set("icon",icon);
}
}).where("mobile=?","111").update();
关于更新和删除的条件,参考查询的章节。条件都是一样的嘛
【2.3.1】查询之输出
查询可是个复杂的话题了,可能我们80%的数据库处理都在查询。
今天先讲讲weed3的查询能输出什么?
- 1.1.快捷查询数量
db.table("user_info").where("user_id, 10).count();
- 1.2.快捷查询是否存在
db.table("user_info").where("user_id, 10).exists();
- 2.1.查询一行的一个字段,输出单值
bool val = db.table("user_info")
.where("user_id=?", 10)
.select("sex").getValue(false); //设个默认值为:false
- 2.2.查询多行的一个字段,输出数组
List<String> ary = db.table("user_info")
.where("user_id=?", 10)
.select("mobile").getArray("mobile");
- 3.1.查询一行,输出map
Map<String,Object> map = db.table("user_info")
.where("user_id=?", 10)
.select("*").getMap();
- 3.2.查询多行,输出map list
List<Map<String,Object>> list = db.table("user_info")
.where("user_id>?", 10).limit(20) //限20条记录
.select("*").getMapList();
- 4.1.查询一行,输出entity
UserModel m = db.table("user_info")
.where("user_id=?", 10)
.select("*").getItem(UserModel.class);
//用户模型(我统叫它模型)
//这里写了最简单的格式,可以改为bean风格
public class UserModel{
public String name;
public String mobile;
public int sex;
}
- 4.2.查询多行,输出entity list
List<UserModel> list = db.table("user_info")
.where("user_id>?", 10).limit(0,20) //分页取20行
.select("*").getList(UserModel.class);
那还能再输出什么?
- 1.select("…") 返回的是一个:IQuery
public interface IQuery extends ICacheController<IQuery> {
long getCount() throws SQLException;
Object getValue() throws SQLException;
<T> T getValue(T def) throws SQLException;
Variate getVariate() throws SQLException;
Variate getVariate(Act2<CacheUsing,Variate> cacheCondition) throws SQLException;
<T extends IBinder> T getItem(T model) throws SQLException;
<T extends IBinder> T getItem(T model, Act2<CacheUsing, T> cacheCondition) throws SQLException;
<T extends IBinder> List<T> getList(T model) throws SQLException;
<T extends IBinder> List<T> getList(T model, Act2<CacheUsing, List<T>> cacheCondition) throws SQLException;
<T> T getItem(Class<T> cls) throws SQLException;
<T> T getItem(Class<T> cls,Act2<CacheUsing, T> cacheCondition) throws SQLException;
<T> List<T> getList(Class<T> cls) throws SQLException;
<T> List<T> getList(Class<T> cls,Act2<CacheUsing, List<T>> cacheCondition) throws SQLException;
DataList getDataList() throws SQLException;
DataList getDataList(Act2<CacheUsing, DataList> cacheCondition) throws SQLException;
DataItem getDataItem() throws SQLException;
DataItem getDataItem(Act2<CacheUsing, DataItem> cacheCondition) throws SQLException;
List<Map<String,Object>> getMapList() throws SQLException;
Map<String,Object> getMap() throws SQLException;
<T> List<T> getArray(String column) throws SQLException;
<T> List<T> getArray(int columnIndex) throws SQLException;
}
- 2.其中 getDataList() 返加的是 DataList,它有一些类型转换接口:
/** 将所有列转为类做为数组的数据(类为:IBinder 子类) */
List<T> toList(T model);
/** 将所有列转为类做为数组的数据 */
List<T> toEntityList(Class<T> cls);
/** 选1列做为MAP的key,并把行数据做为val */
Map<String,Object> toMap(String keyColumn);
/** 选两列做为MAP的数据 */
Map<String,Object> toMap(String keyColumn,String valColumn);
/** 选一列做为SET的数据 */
Set<T> toSet(String column)
/** 选一列做为数组的数据 */
List<T> toArray(String columnName)
/** 选一列做为数组的数据 */
List<T> toArray(int columnIndex)
/** 转为json字符串 */
String toJson();
-
- 其中 getVariate() 返回的是 Variate,也提供了些转换接口
T value(T def);
double doubleValue(double def);
long longValue(long def);
int intValue(int def);
String stringValue(String def);
【2.3.2】查询之条件
查询查然是个麻烦的话题。。。
还好这节的条件会比较简单
- 单表条件查询(有了简单的自然能拼成复杂的)
//weed3 的条件构建,是相当自由的
String mobile = "111";
db.table("test")
.where("mobile=?",mobile).and().begin("sex=?",1).or("sex=2").end()
.limit(20)
.select("*").getMapList()
db.table("test")
.where("mobile=?",mobile).and("(sex=? OR sex=2)",1)
.limit(20)
.select("*").getMapList()
db.table("test").where("mible=? AND (sex=1 OR sex=2)",mobile)
.limit(20)
.select("*")
//以上三种,效果是一样的。。。因为很自由,所以很容易使用(也有观点认为:所以很难控制)
- 有时候一些条件需要动态控制
//这个示例,管理后台很常见
int type=ctx.paramAsInt("type",0);
String key=ctx.param("key");
int date_start=ctx.paramAsInt("date_start",0);
int date_end=ctx.paramAsInt("date_end",0);
DbTableQuery qr = db.table("test").where("1=1");
if(type > 0){
qr.and("type=?", type);
}
if(key != null){
qr.and('"title LIKE ?",key+"%");
}
if(date_start>0 && date_end >0){
qr.and("( date >=? AND date<=? )", date_start, date_end);
}
qr.select("id,title,icon,slug").getMapList();
- 多表关联查询:innerJoin(…), leftJoin(…), rightJoin(…)
//innerJoin()
db.table("user u")
.innerJoin("user_book b").on("u.id = b.user_id")
.select("u.name,b.*")
//leftJoin()
db.table("user u")
.leftJoin("user_book b").on("u.id = b.user_id").and("u.type=1")
.select("u.name,b.*")
//rightJoin()
db.table("user u")
.rightJoin("user_book b").on("u.id = b.user_id")
.where("b.type=1").and("b.price>",12)
.select("u.name,b.*")
- 想别的关联查询怎么样?(如:full join)
//因为不是所有的数据库都支持 full join,所以...
db.table("user u")
.append("FULL JOIN user_book b").on("u.id = b.user_id")
.select("u.name,b.*")
//.append(..) 可以添加任何内容的接口
【2.3.3】查询之缓存控制
缓存控制,是查询中的重点
框架提供的是控制服务。而非缓存服务本身,了解这个很重要。
缓存控制需要两个重要的接口定义:
- 1.缓存服务适配接口 ICacheService
(平常用它的加强版 ICacheServiceEx )
//用它可以包装各种缓存服务
public interface ICacheService {
void store(String key, Object obj, int seconds);
Object get(String key);
void remove(String key);
int getDefalutSeconds();
String getCacheKeyHead();
}
/** weed3内置了三个实现类:
*EmptyCache,空缓存
*LocalCache,本地缓存
*SecondCache,二级缓存容器(可以把两个 ICacheService 拼到一起,变成一个二级缓存服务;多嵌套一下就是三级缓存服务了)
*/
- 2.在缓存服务上进行的操控接口:ICacheController
(所有的weed操控对象都实现了ICacheController)
public interface ICacheController<T> {
//使用哪个缓存服务
T caching(ICacheService service);
//是否使用缓存
T usingCache(boolean isCache);
//使用缓存并设置时间
T usingCache(int seconds);
//为缓存添加标签
T cacheTag(String tag);
}
有了上面的基础后,现在开始使用缓存控制
- 1.先搞个服务实例出来
//缓存key header为 test , 默认缓存时间为 60s
ICacheService cache = new LocalCache("test",60);
- 2.用起来
使用缓存,时间为默认(会自动产生稳定的缓存key)
db.table("test").select("*").caching(cache).getMapList();
使用缓存,并缓存30s
db.table("test")
.caching(cache).usingCache(30) //也可以放在table() 和 select()之间
.select("*").getMapList();
给缓存加个tag(tag 相当于 缓存key的虚拟文件夹)
db.table("test")
.caching(cache)
.usingCache(30).cacheTag('test_all') //这是tag,不是key
.limit(10,20)
.select("*").getMapList();
*3.精细控制
根据查询结果控制缓存时间
db.table("test").where("id=?",10)
.caching(cache)
.select("*").getItem(UserModel.class,(cu,m)->{
if(m.hot > 2){
uc.usingCache(60 * 5); //热门用户缓存5分钟
}else{
uc.usingCache(30);
}
});
- 4.缓存清除
以一个分页查询为例
db.table("test").limit(20,10)
.caching(cache).cacheTag("test_all")
.select("*").getMapList();
db.table("test").limit(30,10)
.caching(cache).cacheTag("test_all")
.select("*").getMapList();
//不管你有多少分页,一个tag把它清光
cache.clear("test_all");
- 5.缓存更新
这个极少用(需要单项更新的缓存,建议用redis)
db.table("test").where("id=?",10)
.caching(cache).cacheTag("test_"+10)
.select("*").getItem(UserModel.class);
cache.update("test_"+10,(UserModel m)->{
m.sex = 10;
return m;
});
框架的缓存控制,也是极为自由的哟。应该是的吧?哈合。
缓存服务的可用情况
1.内置缓存服务
- org.noear.weed.cache.EmptyCache // 空缓存
- org.noear.weed.cache.LocalCache // 轻量级本地缓存(基于Map实现)
- org.noear.weed.cache.SecondCache // 二级缓存(组装两个 ICacheServiceEx 实现)
2.扩展缓存服务
- org.noear.weed.cache.ehcache.EhCache // 基于ehcache封装
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3.cache.ehcacheartifactId>
<version>3.2.3.4version>
dependency>
- org.noear.weed.cache.j2cache.J2Cache // 基于国人开发的J2Cache封装
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3.cache.j2cacheartifactId>
<version>3.2.3.4version>
dependency>
- org.noear.weed.cache.memcached.MemCache // 基于memcached封装
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3.cache.memcachedartifactId>
<version>3.2.3.4version>
dependency>
- org.noear.weed.cache.redis.RedisCache // 基于redis封装
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3.cache.redisartifactId>
<version>3.2.3.4version>
dependency>
- 也可以自己封装个 ICacheServiceEx …
要不要自己封装个?
【2.3.4】查询之其它
再补充些查询相关的内容
- 别名
db.table("user u")
.limit(20)
.select("u.mobile mob");
- 去重
db.table("user")
.limit(20)
.select("distinct mobile");
- 分组
db.table("user u")
.groupBy("u.mobile").having("count(*) > 1")
.select("u.mobile,count(*) num");
- 排序
db.table("user u")
.orderBy("u.mobile ASC")
.select("u.mobile,count(*) num");
- 分组+排序(或者随意组合)
db.table("user u")
.where("u.id < ?",1000)
.groupBy("u.mobile").having("count(*) > 1")
.orderBy("u.mobile ASC")
.caching(cache)
.select("u.mobile,count(*) num").getMap("mobile,num")
【2.4】存储过程与查询过程
关于存储过程的支持,设计了两个方案
- 1.对接数据库的存储过程调用
db.call("user_get").set("_user_id",1).getMap();
- 2.SQL查询过程(我叫它:查询过程)
看起来跟mybatis的SQL注解代码有点儿像
//由SQL构建的一个查询
db.call("SELECT * FROM user WHERE id=@{user_id}").set("user_id",1).getMap();
还可以对它们进行实体化(变成一个独立的类)
实体化的作用在于,可将数据处理安排到别的模块(或文件夹)
- 1.对接数据库的存储过程实体化
public class user_get extends DbStoredProcedure {
public user_get() {
super(DbConfig.test);
call("user_get");
set("_userID", () -> userID);
}
public long userID;
}
user_get sp =new user_get();
sp.userID=10;
Map<String,Object> map = sp.caching(cache).getMap();//顺带加个缓存
- 2.查询过程的实体化
public class user_get2 extends DbQueryProcedure {
public user_get2() {
super(db);
sql("select * from user where type=@{type} AND sex=@{sex}");
// 这个绑定写法,想了很久才想出来的(就是不想反射!)
set("type", () -> type);
set("sex", () -> sex);
}
public int type;
public int sex;
}
//DbQueryProcedure 提供了与 DbStoredProcedure 相同的接口
user_get2 sp =new user_get2();
sp.userID=10;
Map<String,Object> map = sp.caching(cache).getMap();
【2.5】解决数据库关键字问题
weed3提供了字段和对象格式化支持,通过DbContext进行设定
//以mysql为例
DbContext db = new DbContext(...).fieldFormatSet("`%`")//设定字段格式符
.objectFormatSet("`%`");//设定对象格式符
//%号为占位符,`%`表过你的字段会转为:`字段名`
字段格式符对会对:
.set(…), .select(…), .orderBy(…), .groupBy(…) 里的字段进行处理
对对象格式符对会:
.table(…), innerJoin(…), leftJoin(…), rightJoin(…) 里的表名进行处理
如果不设置,则需要自己手动处理关键字;手动处理与自动处理并不冲突。
//手动处理
db.table("`user`").where("`count`<10 AND sex=1").count();
格式化是由IDbFormater来处理的,如果觉得里面的实现不好,还可以自己写一个替换它:)
IDbFormater df = new DfNew(); //DfNew 算是自己写的
db.formaterSet(df); //搞定
//附:
public interface IDbFormater {
/** 字段格式符设置 */
void fieldFormatSet(String format);
/** 对象格式符设置 */
void objectFormatSet(String format);
/** 格式化字段(用于:set(..,v)) */
String formatField(String name);
/** 格式化多列(用于:select(..) orderBy(..) groupBy(..)) */
String formatColumns(String columns);
/** 格式化条件(用于:where(..) and(..) or(..)) */
String formatCondition(String condition);
/** 格式化对象(用于:from(..), join(..)) */
String formatObject(String name);
}
【2.5】盘点三大java使用接口(table,call,sql)
1.table() 执行:链式ORM操作
此处略(前面主要就讲这个接口)
2.call(…) 执行:存储过程 或 查询过程
//执行存储过程
db.call("user_get").set("_user_id",1).getMap();
//执行查询过程(我暂时这么叫它)
db.call("select * from user where id=@{user_id}").set("user_id",1).getMap();
3.sql(…) 执行:SQL语句
db.sql("select * from user where id=?",1).getMap();
db.sql(…) 还有一个快捷版:db.exec(…)。相当于:db.sql(…).execute(); //批处理时,可快速写增、删、改动作
例:db.exec("DELETE FROM test where a=1")
最终统一返回:IQuery (保证了体验的统一性)
db.table(..).select(..) -> IQuery
db.call(..) -> IQuery
db.sql(..) -> IQuery
public interface IQuery extends ICacheController<IQuery> {
long getCount() throws SQLException;
Object getValue() throws SQLException;
<T> T getValue(T def) throws SQLException;
Variate getVariate() throws SQLException;
Variate getVariate(Act2<CacheUsing,Variate> cacheCondition) throws SQLException;
<T extends IBinder> T getItem(T model) throws SQLException;
<T extends IBinder> T getItem(T model, Act2<CacheUsing, T> cacheCondition) throws SQLException;
<T extends IBinder> List<T> getList(T model) throws SQLException;
<T extends IBinder> List<T> getList(T model, Act2<CacheUsing, List<T>> cacheCondition) throws SQLException;
<T> T getItem(Class<T> cls) throws SQLException;
<T> T getItem(Class<T> cls,Act2<CacheUsing, T> cacheCondition) throws SQLException;
<T> List<T> getList(Class<T> cls) throws SQLException;
<T> List<T> getList(Class<T> cls,Act2<CacheUsing, List<T>> cacheCondition) throws SQLException;
DataList getDataList() throws SQLException;
DataList getDataList(Act2<CacheUsing, DataList> cacheCondition) throws SQLException;
DataItem getDataItem() throws SQLException;
DataItem getDataItem(Act2<CacheUsing, DataItem> cacheCondition) throws SQLException;
List<Map<String,Object>> getMapList() throws SQLException;
Map<String,Object> getMap() throws SQLException;
<T> List<T> getArray(String column) throws SQLException;
<T> List<T> getArray(int columnIndex) throws SQLException;
}
【3.1】开始Xml Mapper的使用
使用约定***
- 1.约定
resources/weed3/为 xml sql 根目录 - 2.项目开启编译参数:
-parameters
准备开始做个简单的例子
这次需要引用一个meven插件(玩过mybatis都懂的)
框架引用
<dependency>
<groupId>org.noeargroupId>
<artifactId>weed3artifactId>
<version>3.2.3.4version>
dependency>
meven插件引用(用于生成mapper类)
<plugin>
<groupId>org.noeargroupId>
<artifactId>weed3-maven-pluginartifactId>
<version>3.2.3.4version>
plugin>
(一)现在,先写个简单的xml文件
- resources/weed3/DbUserApi.xml
<mapper namespace="weed3demo.xmlsql" :db="testdb">
<sql id="user_get"
:return="weed3demo.mapper.UserModel"
:note="获取用户信息">
SELECT * FROM `user` WHERE id=@{user_id}
sql>
mapper>
(二)可以有两种方式调用刚才的xml sql
通过 db.call("@…") 调用
DbContext db = new DbContext(...);
UserModel um = db.call("@weed3demo.xmlsql.user_get")
.set("user_id")
.getItem(UserModel.class);
生成Mapper接口,通过动态代理使用
1.用meven插件把它生成(双击:weed3:generator)
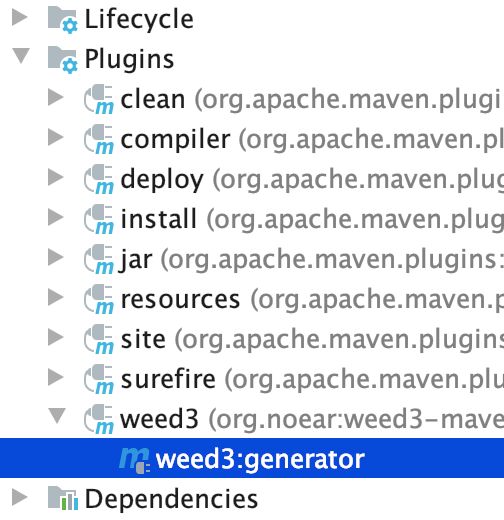
2.生成的Java文件(java/weed3demo/xmlsql/DbUserApi.java)
package weed3demo.xmlsql;
@Namespace("weed3demo.xmlsql")
public interface DbUserApi{
/** 获取用户信息*/
weed3demo.mapper.UserModel user_get(int user_id);
}
3.试一下
//全局
public static void main(String[] args){
//配置一个上下文,并加上名字(给xml mapper 用)
DbContext db = new DbContext(...).nameSet("testdb");
//通过代理获取xml mapper
DbUserApi dbUserApi = XmlSqlMapper.get(DbUserApi.class);
//使用它
UserModel tmp = dbUserApi.user_get(10);
}
【3.2】Xml Mapper的指令和语法
五个指令 + 三种变量形式。先来段xml
这个示例里把各种情况应该呈现出来了
<mapper namespace="weed3demo.xmlsql2" :db="testdb">
<sql id="user_add1" :return="long"
:param="m:weed3demo.mapper.UserModel,sex:int"
:note="添加用户">
INSERT user(user_id,mobile,sex) VALUES(@{m.user_id},@{m.mobile},@{sex})
sql>
<sql id="user_add2" :return="long" :note="添加用户">
INSERT user(user_id) VALUES(@{user_id:int})
sql>
<sql id="user_add_for" :return="long" :note="批量添加用户3">
INSERT user(id,mobile,sex) VALUES
<for var="m:weed3demo.mapper.UserModel" items="list">
(@{m.user_id},@{m.mobile},@{m.sex})
for>
sql>
<sql id="user_del" :note="删除一个用户">
DELETE FROM user WHERE id=@{m.user_id:long}
<if test="sex gt 0">
AND sex=@{sex:int}
if>
sql>
<sql id="user_set"
:note="更新一个用户,并清理相关相存"
:caching="localCache"
:cacheClear="user_${user_id},user_1">
UPDATE user SET mobile=@{mobile:String},sex=@{sex:int}
<if test="icon != null">
icon=@{icon:String}
if>
sql>
<sql id="user_get_list"
:note="获取一批符合条件的用户"
:declare="foList:int,user_id:long"
:return="List[weed3demo.mapper.UserModel]"
:caching="localCache"
:cacheTag="user_${user_id},user_1">
SELECT id,${cols:String} FROM user
<trim prefix="WHERE" trimStart="AND ">
<if test="mobile?!">
AND mobile LIKE '${mobile:String}%'
if>
<if test="foList == 0">
AND type='article'
if>
<if test="foList == 1">
AND type='post'
if>
trim>
sql>
<sql id="user_cols1">name,title,style,labelsql>
<sql id="user_cols2">name,titlesql>
<sql id="user_get_list2"
:note="获取一批符合条件的用户"
:declare="foList:int,user_id:long"
:return="List[weed3demo.mapper.UserModel]"
:caching="localCache"
:cacheTag="user_${user_id},user_1">
SELECT id,
<if test="foList == 0">
<ref sql="user_cols1"/>
if>
<if test="foList == 1">
<ref sql="user_cols2"/>
if>
FROM user WHERE sex>1 AND mobile LIKE '${mobile:String}%'
sql>
mapper>
四个指令说明
sql 代码块定义指令
:require(属性:导入包或类)
:param?(属性:外部输入变量申明;默认会自动生成::新增***)
:declare(属性:内部变量类型预申明)
:return(属性:返回类型)
:db (属性:数据库上下文name)
:note(属性:描述、说明、注解)
:caching(属性:缓存服务name) //是对 ICacheController 接口的映射
:cacheClear?(属性:清除缓存)
:cacheTag?(属性:缓存标签,支持在入参或结果里取值替换)
:usingCache?(属性:缓存时间,int)
if 判断控制指令(没有else)
test (属性:判断检测代码)
//xml避免语法增强:
//lt(<) lte(<=) gt(>) gte(>=) and(&&) or(||)
//例:m.sex gt 12 :: m.sex >=12
//简化语法增强:
//??(非null,var!=null) ?!(非空字符串,StringUtils.isEmpty(var)==false)
//例:m.icon?? ::m.icon!=null
//例:m.icon?! ::StringUtils.isEmpty(m.icon)==false
for 循环控制指令 (通过 ${var}_index 可获得序号,例:m_index::新增***)
var (属性:循环变量申明)
items (属性:集合变量名称)
sep? (属性:分隔符::新增***)
trim 修剪指令
trimStart(属性:开始位去除)
trimEnd(属性:结尾位去除)
prefix(属性:添加前缀)
suffix(属性:添加后缀)
ref 引用代码块指令
sql (属性:代码块id)
三种变量形式
name:type = 变量申明(仅用于var ,或:declare)
@{name:type} = 变量注入(仅用于代码块)
${name:type} = 变量替换(用于代码块,或:cacheTag,或:cacheClear)
关于返回值的几种形式说明
//多行,列表(用[]替代<>)
:return="List[weed3demo.mapper.UserModel]" //将返回 List<UserModel>
:return="List[String]" //将返回 List<String> (Date,Long,...大写开头的单值类型)
:return="MapList" //将返回 List<String,Object>>
:return="DataList" //将返回 DataList
//一行
:return="weed3demo.mapper.UserModel" //将返回 UserModel
:return="Map" //将返回 Map<String,Object>
:return="DataItem" //将返回 DataItem
//单值
:return="String" //将返回 String (或别的任何单职类型)
【4.1】开始注解sql的使用
使用约定***
- 1.项目开启编译参数:
-parameters
先来个demo
- 1.申明一个mapper
public interface DbMapper1{
@Sql(value = "select * from ${tb} where app_id = @{app_id} limit 1",
caching = "test",
cacheTag = "app_${app_id}")
AppxModel appx_get(String tb, int app_id) throws Exception;
}
- 2.使用它
DbContext db = new DbContext(...);
DbMapper1 dm = db.mapper(DbMapper1.class);
AppxModel m = dm.appx_get("appx",1);
两种变量形式 + 缓存控制
两种变量形式
${}替代变量(相当于占位符,进行字符串拼接)@{}编译变量(会编译为?,通过变量传递给jdbc)
缓存控制
caching缓存服务cacheTag缓存标签(在key之上,建立的虚拟tag;为便于清理)usingCache缓存使用时间cacheClear缓存清理(通过cacheTag形式清理)
再来一个demo2
更新之后,清掉缓存:app_${app_id}
public interface DbMapper2{
@Sql(value = "update appx set name=@{name} where app_id = @{app_id}",
caching = "test",
cacheClear = "app_${app_id}")
void appx_set(int app_id, String name) throws Exception;
}
再来一个demo3
使用查询结果构建cahce tag:app_type${type}
public interface DbMapper3{
@Sql(value = "select * from appx where app_id = @{app_id} limit 1",
caching = "test",
cacheTag = "app_${app_id},app_type${type}")
AppxModel appx_get(int app_id) throws Exception;
}
补充:构建一个缓存服务
//随便写在哪里
//1.初始化一个ICacheServiceEx
//2.通过nameSet("test") 注册到缓存库
//3.之后就可以被 @sql的 caching 使用(xml sql 的 caching 同样如此)
//
new LocalCache("test",60).nameSet("test");
【5】事务和事务队列
之前讲过插入和更新
这次讲事务(写操作总会傍随事务嘛…)
- weed3 支持两种方式的事务
- 1.事务(主要用于单个库)
//demo1:: //事务组 // 在一个事务里,做4个插入//如果出错了,自动回滚
DbUserApi dbUserApi = XmlSqlProxy.getSingleton(DbUserApi.class);
db.tran((t) -> {
//
// 此表达式内的操作,会自动加入事务
//
//sql接口
db.sql("insert into test(txt) values(?)", "cc").insert();
db.sql("update test set txt='1' where id=1").execute();
//call接口
db.call("user_del").set("_user_id",10).execute();
//table()接口
db.table("a_config").set("cfg_id",1).insert();
//xml mapper
dbUserApi.user_add(12);
//大家使用统一的事务模式
});
- 2.事务队列(主要用于多个库的情况)
//demo2:: //事务队列
//
//假如,要跨两个数据库操作(一个事务对象没法用了)
//
DbContext db = DbConfig.pc_user;
DbContext db2 = DbConfig.pc_base;
//创建个事务队列(和传统概念的队列不一样)
DbTranQueue queue = new DbTranQueue();
//数据库1的事务
db.tran().join(queue).execute((t) => {
//
// 在这个表达示内,会自动加入事物
//
db.sql("insert into test(txt) values(?)", "cc").execute();
db.sql("insert into test(txt) values(?)", "dd").execute();
db.sql("insert into test(txt) values(?)", "ee").execute();
});
//数据库2的事务
db2.tran().join(queue).execute((t) => {
//
// 在这个表达示内,会自动加入事物
//
db2.sql("insert into test(txt) values(?)", "gg").execute();
});
//队列结组完成(即开始跑事务)
queue.complete();
- 3.事务队列的加强版,跨函数或模块跑事务
public void test_main(){
DbTranQueue queue = new DbTranQueue();
test1(queue);
test2(queue);
}
public void test1(DbTranQueue queue){
DbTran tran = DbConfig.db1.tran();//生成个事务对象
tran.join(queue).execute((t) -> {
//
// 在这个表达示内,会自动加入事物
//
t.db().sql("insert into $.test(txt) values(?)", "cc").insert();
t.db().sql("insert into $.test(txt) values(?)", "dd").execute();
t.db().sql("insert into $.test(txt) values(?)", "ee").execute();
t.result = t.db().sql("select name from $.user_info where user_id=3").getValue("");
});
}
public void test2(DbTranQueue queue){
//...test2就不写了
}
【6】对所有执行进行监视
通过WeedConfig开放了一些监听接口
比如:异常监听,慢SQL监听
//监听异常,以便统一的打印或记录
WeedConfig.onException((cmd, ex) -> {
if (cmd.text.indexOf("a_log") < 0 && cmd.isLog >= 0) {
System.out.println(cmd.text);
}
});
//监听SQL性能,以便统一记录
WeedConfig.onExecuteAft((cmd)->{
if(cmd.timespan()>1000){ //执行超过1000毫秒的..
System.out.println(cmd.text + "::" + cmd.timespan() +"ms");
}
});
具体的可监听事件
//异常事件
WeedConfig.onException(Act2<Command, Exception> listener);
//日志事件(可以把命令信息记录下来)
WeedConfig.onLog(Act1<Command> listener);
//执行前事件
WeedConfig.onExecuteBef(Fun1<Boolean, Command> listener);
//执行中事件(可以监听,Statement)
WeedConfig.onExecuteStm(Act2<Command, Statement> listener);
//执行后事件
WeedConfig.onExecuteAft(Act1<Command> listener);
【7】嵌入到脚本或模板
嵌入到脚本引擎
- 嵌入到javascript引擎(nashorn)
ScriptEngineManager scriptEngineManager = new ScriptEngineManager();
ScriptEngine _eng = scriptEngineManager.getEngineByName("nashorn");
Invocable _eng_call = (Invocable)_eng;
_eng.put("db", db);
var map = db.table("test").where('id=?',1).getMap();
- 嵌入到groovy引擎
ScriptEngineManager scriptEngineManager = new ScriptEngineManager();
ScriptEngine _eng = scriptEngineManager.getEngineByName("groovy");
Invocable _eng_call = (Invocable)_eng;
_eng.put("db", db);
def map = db.table("test").where('id=?',1).getMap();
嵌入到模板引擎
- 嵌入到Freemarker引擎
<#assign tag_name=ctx.param('tag_name','') />
<#assign tags=db.table("a_config").where('label=?',label).groupBy('edit_placeholder').select("edit_placeholder as tag").getMapList() />
<html>
<head>
...