ES入门学习:ElasticSearch、Kibana、ik分词器的安装、简单使用及SpringBoot集成
前言
- es是采用Java语言开发,因此,想要安装运行es需要提前准备好jdk环境,关于linux配置jdk在前文linux配置jdk
- 本文主要介绍es的安装、kibana的安装和简单使用及ik分词器的简单使用以及SpringBoot整合es的简单测试。需要的安装包可以从官网下载
https://www.elastic.co/cn/downloads,注意版本要对应,这里也有8.4.1版本的百度云链接链接:https://pan.baidu.com/s/1WtyRIZMKqdUD4dEM_C5ROQ?pwd=dykl 提取码:dykl - 注意,文中安装的es版本为8.4.1,相对来说版本过于靠前,建议选择7版本的es作为自己的学习内容,文中所写的一些内容对于7版本的es适配性更强,学习起来也相对简单一些。当然,选择本文的8.4.1版本也没有任何阻断性的错误,作为学习来说,学习较新的版本肯定能获取更多的经验和知识。
一、安装测试es
1、安装
注意:es为了安全考虑,不允许使用root账户安装,因此我们首先需要创建一个账号创建用户:useradd esuser、设置密码:passwd esuser,我的虚拟机已经设置过一个普通账号,因此略过此步骤。
解压安装包tar -zxvf elasticsearch-8.4.1-linux-x86_64.tar.gz,得到的目录结构如下

2、修改配置文件&设置登录密码&启动
进入config目录,需要修改两个配置文件

将运行内存修改小一点,找到配置文件的如下内容,修改为-Xms512m -Xmx512m

然后修改elasticsearch.yml文件,主要修改数据和日志存放目录,如下所示
#集群的名称
cluster.name: my-application
#节点名称
node.name: node-1
#数据存放目录
path.data: /home/ysgs/tools/elasticsearch/elasticsearch-8.4.1/data
#日志存放目录
path.logs: /home/ysgs/tools/elasticsearch/elasticsearch-8.4.1/log
#主机连接,默认只允许本机,修改成0.0.0.0允许所有主机
network.host: 0.0.0.0
#端口
http.port: 9200
编辑/etc/security/limits.conf文件,添加如下内容,如果当前用户为只读状态,切换root账户把文件权限赋给当前用户chown -R ysgs /etc/security/limits.conf,ysgs对应你的es用户,下面内容中,*也可以用你的es用户代替
* soft nofile 65536
* hard nofile 65536
修改完这些,我尝试启动es,切换到bin目录下,./elasticsearch启动,发现控制台报了如下错误:
max number of threads [3790] for user [ysgs] is too low, increase to at least [4096]
该报错是因为 elasticsearch 启动的时候要求当前用户最大线程数至少为 4096 个线程,而操作系统限制该用户最大线程数为 3795,只需要修改当前用户的最大线程数即可。用ulimit -a查看当前用户最大线程数

我们修改/etc/security/limits.conf文件,添加一行ysgs - nproc 65535,ysgs是我的es用户。重新登录用户,发现最大线程数已经修改成功
![]()
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存区域vm.max_map_count[65530]太低,请至少增加到[262144],我们需要切换到root用户下,修改/etc/sysctl.conf文件,添加vm.max_map_count=655360,保存后,执行sysctl -p,然后切换到es用户下,再次启动es,这次启动成功,但是访问ip:9200发现页面访问失败,控制台提示如下
![]()
这是因为es8之后,开启了ssl验证,我们需要在es的elasticsearch.yml配置文件将其关闭,修改xpack.security.enabled: true改为false,然后再启动,启动成功后,发现可以访问页面了
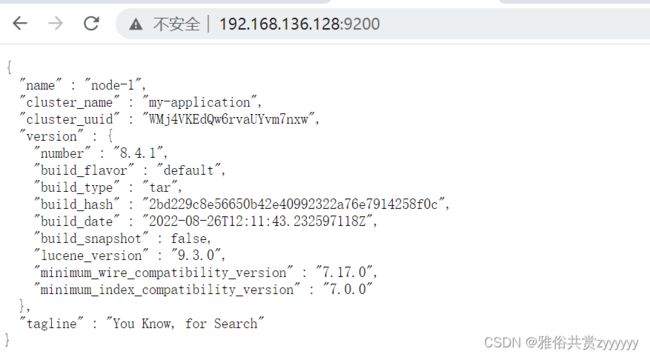
这是关闭了登录验证的情况,如果想要设置用户名密码,执行curl -XDELETE 127.0.0.1:9200/.security-7

然后将上面的配置文件还原为true,启动
访问https://ip:9200,输入用户名,密码elastic、5_R5ZGoSBJejxNi6KM0O登陆成功

如果你启动后没有注意保存密码,也可以采用./elasticsearch-reset-password -u elastic重置密码,或者自定义密码./elasticsearch-reset-password -u elastic -i。当然,在我们自己测试使用过程中,还是建议将ssl验证关闭,es8的安全配置详解如下
##安全验证配置总开关,也可以根据需要单独配置下面的各项
xpack.security.enabled: false
#是否需要用户名密码
xpack.security.enrollment.enabled: false
# 客户端访问是否使用https
xpack.security.http.ssl:
enabled: false
# 集群间访问是否需要https
xpack.security.transport.ssl:
enabled: false
再后面启动es的时候,发现控制台有如下报错
exception during geoip databases updateorg.elasticsearch.ElasticsearchException: not all primary shards of [.geoip_databases] index are active
这个是es启动时会去更新地图的一些数据库,这里直接禁掉即可,添加配置文件ingest.geoip.downloader.enabled: false
nohup bin/elasticsearch >logs/log.log 2>&1 &至此,单机版的elasticsearch已经安装完成。
二、安装Kibana
1、安装
解压安装包tar -zxvf kibana-8.4.1-linux-x86_64.tar.gz,得到的目录结构如下

2、修改配置&运行
修改配置文件kibana.yml文件,具体内容及注释如下
#服务端口
server.port: 5601
#允许访问的主机,默认是本机,开放为所有主机
server.host: "0.0.0.0"
#服务器请求的最大负载,单位字节,默认1048576
server.maxPayload: 1048576
#服务名称
server.name: "ysgs"
#是否启用ssl验证,要么同时开启,要么同时关闭
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key
#es的服务地址,我这里是同一台机器
elasticsearch.hosts: ["http://localhost:9200"]
#es的用户名和密码
#elasticsearch.username: "kibana_system"
#elasticsearch.password: "pass"
#等待es的响应时间
elasticsearch.pingTimeout: 1500
#等待后端或es的响应时间
elasticsearch.requestTimeout: 30000
#界面显示语言,设置为中文
i18n.locale: "zh-CN"
在bin目录,启动./kibana,访问ip:5601,提示要配置es,如下所示

首先将es的安全认证打开,在es的bin目录下,执行./elasticsearch-create-enrollment-token -s kibana --url "https://127.0.0.1:9200",复制生成的token到页面上,点击“配置Elastic",在kibana的控制台生成一个6位的验证码,输入,会弹出登陆页面,输入之前配置的es的用户名、密码即可登录。

三、基本概念&使用
1、ES基础概念
索引(index):作为名词,相当于mysql中的数据库;作为动词,相当于insert,例如索引一个文档,就是将一个文档存储到一个索引下
类型(type):相当于mysql中的表,一个索引下可以有多个类型,同种类型的数据放到一起 ,注意,从ES8之后,类型已经不再使用,因此,ES8之后要将索引由多类型改为单类型,每种类型的文档存放一个独立索引
文档(document):保存在某个索引下的一个数据,文档是json格式的,相当于mysql的某个表中的数据

倒排索引:我们先了解一下正排索引,正排索引是以文档对象的唯一 ID 作为索引,以文档内容作为记录,而倒排索引呢,是以文档记录的分词作为索引,以包含分词的文档id作为记录。举个例子来说明倒排索引的过程,例如我们想搜索“盖茨比了不起”,现有的记录正排索引为
| 文档ID | 文档内容 |
|---|---|
| 1 | 了不起的盖茨比 |
| 2 | 盖茨比的爱情故事 |
| 3 | 了不起的爱情故事 |
然后对上述内容进行分词,大致分为了不起、盖茨比、爱情故事,的,对分词生成倒排索引表,如下
| 分词 | 文档ID |
|---|---|
| 了不起 | 1,3 |
| 盖茨比 | 1,2 |
| 爱情故事 | 2,3 |
| 的 | 1,2,3 |
然后,我们对要搜索的内容“盖茨比了不起”也分词,分成了盖茨比、了不起,检索倒排索引表,发现盖茨比在记录1和2中,了不起在记录1和3中,取交集,记录1的相关性最高,因此,返回了不起的盖茨比。
2、导入测试数据
先导入一份数据集,从官网下载虚拟账号数据集,解压缩后的到一份json文件,上传到kibana控制台,点击“home”,选择上传文件,将json文件拖进去,点击“导入”,给这个数据集起一个索引名称,“导入”即可。

控制台–Discover–选择索引,即可看到我们导入的数据

3、接口调用
用postman等接口测试工具,不同的请求类型GET、PUT、POST、DELETE分别对应着查、增、改、删,例如,我们想要查询一下节点信息,在postman输入https://ip:9200/_cat/nodes,这里对应你的请求方式,可以看到返回了错误信息missing authentication credentials for REST request [/_cat/nodes],这是因为我的ES开启了认证,需要先设置用户名密码,如下所示

可以看到,返回了我的所有的索引信息。我们再尝试新增一个索引,请求如下,创建了一个index1的索引

单个索引查询:GET https://192.168.136.128:9200/index1
所有索引查询GET https://192.168.136.128:9200/_cat/indices?v
索引删除DELETE https://192.168.136.128:9200/index1
文档创建POST https://192.168.136.128:9200/index1/_doc或者指定文档idPOST https://192.168.136.128:9200/index1/_doc/1,添加属性(请求体),如下所示
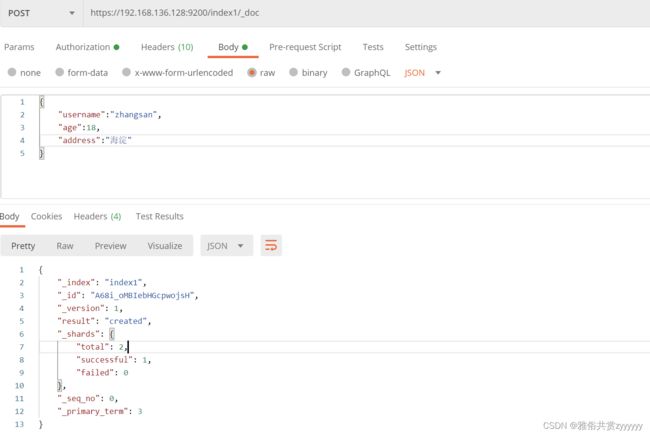
文档查询GET https://192.168.136.128:9200/index1/_doc/A68i_oMBIebHGcpwojsH或者GET https://192.168.136.128:9200/index1/_search
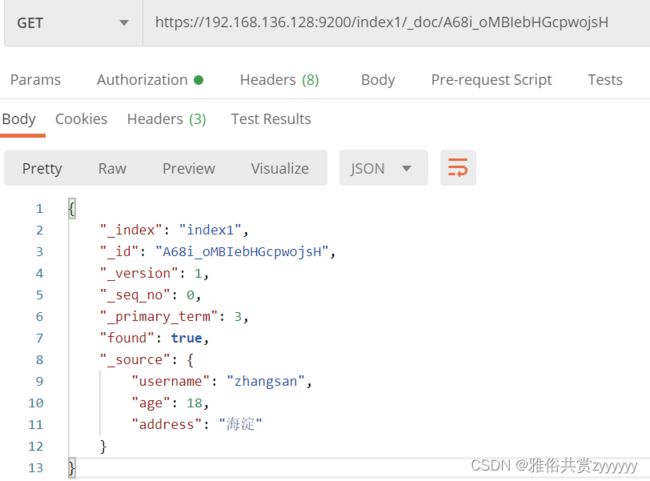

文档修改PUT https://192.168.136.128:9200/index1/_doc/A68i_oMBIebHGcpwojsH,全量修改参数如下
{
"username":"李四",
"age":24,
"address":"海淀区"
}
局部修改只需要传递对应参数
{
"username":"张三"
}
删除文档DELETC https://192.168.136.128:9200/index1/_doc/A68i_oMBIebHGcpwojsH
组合查询GET https://192.168.136.128:9200/index1/_search,添加查询参数,放在请求体中,例如
单个条件查询带参数
{
"query": {
"match": {
"username": "张三"
}
}
}
条件查询分页
{
"query": {
"match_all": {}
},
"from": 0, //偏移量,0表示第一页,即页码-1
"size": 2, //每页的个数
"_source": [
"title" //查询结果仅显示title字段
],
"sort": {
"price": {
"order": "asc" //asc升序,desc降序
}
}
}
多条件查询
{
//bool表示条件的意思
"query": {
"bool": {
//must表示多个条件必须同时成立,[]表示数组
"must": [
{
"match": {
"category": "小米"
}
},
{
"match": {
"price": 3999.00
}
}
]
}
}
}
or
{
//bool表示条件的意思
"query": {
"bool": {
//should表示或者,华为或者小米满足一个就能查出来
//效果不明显的话自行创建/修改数据
"should": [
{
"match": {
"category": "小米"
}
},
{
"match": {
"category": "华为"
}
}
]
}
}
}
聚合查询
{
"aggs": { //聚合操作
"price_group": { //名称,随意取名
"terms": { //可选项:分组terms/平均值avg/最大值max/最小值min
"field": "price" //(分组)字段
}
}
},
"size": 0 //不显示原始数据,只看分组数据
}
#查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg":{
"terms": {
"field": "gender.keyword"
},
"aggs": {
"balanceAgg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBalanceAvg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
上面只是一些dsl的语法,这里不再多做赘述,多写多用才能较好的掌握,这是一个mysql语句转es的dsl语句的工具https://printlove.cn/tools/sql2es/,它可以帮我们转化一些复杂的查询,对新手熟悉dsl语句比较友好
4、控制台使用
在前面我们导入了一个账号数据集,在控制台找到Discover,选择account数据集,可以看到下面展示了数据集中的所有字段,我们点击“+”号添加几个,可以看到右侧对应的展示了我们选中的字段的数据

以可视化表格的形式展现给我们,在上面还可以通过输入KQL语句进行数据筛选,例如我们筛选年龄≤20且城市为Elizaville的数据

是不是和我们使用关系型数据库的可视化工具查询一样呢,这里是数据的查询,Kibana提供了更多的功能,例如,图形化展示,我们点击“Dashboard”,创建一个仪表盘,例如,我们创建一个折线图,展示排名前十的城市的年龄的平均值,点击保存,即可创建一个仪表盘。

Kibana的功能远不止这些,还需要我们去摸索和使用。
四、IK分词器
ES的默认分词设置是standard,分词方式是单字拆分。但是在实际应用中,我们还是需要自然语言分词的,否则使用起来会很奇怪。
1、安装
首先去下载.zip格式的ik压缩包,其他两种格式的压缩包可能会缺少配置文件,对应es版本即可,下载地址https://github.com/medcl/elasticsearch-analysis-ik/releases,下载完成后,在es的安装目录的plugins目录下创建一个ik文件夹,注意一定是ik文件夹,将压缩包上传到ik文件夹下,解压缩unzip elasticsearch-analysis-ik-8.4.1.zip,重新启动es。
2、测试
打开Kibana控制台,在开发工具中进行测试,输入如下请求,得到的分词是按照自然语言进行分词的
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
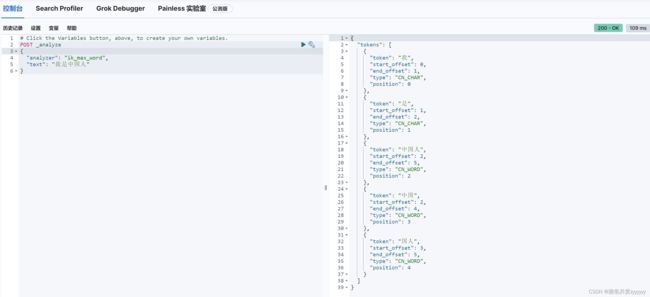
IK分词器提供了ik_smart(最少切分)和ik_max_word(最细粒度划分),切着分词结果少于后者。
3、功能扩展
IK分词器还支持自定义的分词,例如设置扩展词(不让哪些词被分开,让它们分成一个词)和停用词(有些词出现的频率很高但没什么实际意义,我们可以不再将它们分词,例如的、啊等等)。进入到ik分词器的config目录下,我们可以看到有很多词典,这些都是已经定义好的,我们创建一个自己的扩展词典,vi my_extra_word.dic,添加一些词语,同理定义一个停用词词典,例如my_stop_word.dic。然后编辑IKAnalyzer.cfg.xml文件,将我们自定义的词典添加到配置中去,修改如下配置
my_extra_word.dic
my_stop_word.dic">
然后重启es和kibana进行测试。可以看到我们自定义的词典已经被加载
![]()

可以看到我们自定义的扩展词典已经生效了,如果你的自定义词典没有生效的话,将文件下载到本地,通过notepad++等工具确认编码是否为UTF-8,保证编码没问题。我们也可以将IK分词器设置为默认的分词器
PUT /索引
{
"settings": {
"index" :{
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
五、SpringBoot集成
这里我把https配置关闭了,目前没有找到解决https连接的方法。
1、添加依赖、配置
在Kibana控制台的JavaApi集成中,对于es8.4版本,通过maven项目导入依赖如下
co.elastic.clients
elasticsearch-java
8.4.1
com.fasterxml.jackson.core
jackson-databind
2.12.3
jakarta.json
jakarta.json-api
2.0.1
2、创建连接工具类
package com.example.dailyrecords.es.config;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.Header;
import org.apache.http.HttpHost;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.RestClient;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.Base64Utils;
/**
* @author zy
* @version 1.0.0
* @ClassName EsConfig.java
* @Description TODO
* @createTime 2022/10/23
*/
@Configuration
public class EsConfig {
public ElasticsearchClient configClient() throws Exception{
//设置请求头,主要设置用户名,密码
String auth = Base64Utils.encodeToString("elastic:123456".getBytes());
Header authHeader = new BasicHeader("Authorization", String.format("Basic %s", auth));
Header[] header = {authHeader};
//设置连接
RestClient restClient = RestClient.builder(new HttpHost("192.168.136.128",9200)).setDefaultHeaders(header).build();
//设置传输
ElasticsearchTransport elasticsearchTransport = new RestClientTransport(restClient,new JacksonJsonpMapper());
//客户端
ElasticsearchClient elasticsearchClient = new ElasticsearchClient(elasticsearchTransport);
return elasticsearchClient;
}
}
3、实体类
package com.example.dailyrecords.es.entity;
import lombok.Data;
/**
* @author zy
* @version 1.0.0
* @ClassName Account.java
* @Description TODO
* @createTime 2022/10/23
*/
@Data
public class Account {
public String id;
public Integer age;
public String address;
public String employer;
public Account(String id, Integer age, String address, String employer) {
this.id = id;
this.age = age;
this.address = address;
this.employer = employer;
}
}
4、测试代码及效果
package com.example.dailyrecords;
import co.elastic.clients.elasticsearch.core.IndexRequest;
import co.elastic.clients.elasticsearch.core.IndexResponse;
import co.elastic.clients.elasticsearch.core.SearchRequest;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.Hit;
import co.elastic.clients.elasticsearch.core.search.TotalHits;
import co.elastic.clients.elasticsearch.core.search.TotalHitsRelation;
import co.elastic.clients.elasticsearch.indices.*;
import co.elastic.clients.transport.endpoints.BooleanResponse;
import com.example.dailyrecords.es.config.EsConfig;
import com.example.dailyrecords.es.entity.Account;
import com.example.dailyrecords.redis.RedisUtil;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
@SpringBootTest
class ElasticSearchTests {
@Autowired
private EsConfig esConfig;
@Test
void contextLoads() {
}
/**
* 判断索引是否存在
*/
@Test
void existsIndex() throws Exception {
ExistsRequest existsRequest = new ExistsRequest.Builder().index("account").build();
BooleanResponse existsResponse = esConfig.configClient().indices().exists(existsRequest);
System.out.println("是否存在:"+existsResponse.value());
}
/**
* 创建索引
* @throws Exception
*/
@Test
void createIndex() throws Exception {
CreateIndexRequest createIndexRequest = new CreateIndexRequest.Builder().index("myindex").build();
CreateIndexResponse createIndexResponse = esConfig.configClient().indices().create(createIndexRequest);
System.out.println("是否成功:"+createIndexResponse.acknowledged());
}
/**
* 删除索引
*/
@Test
void deleteIndex() throws Exception {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest.Builder().index("myindex").build();
DeleteIndexResponse deleteIndexResponse = esConfig.configClient().indices().delete(deleteIndexRequest);
System.out.println("是否成功:"+deleteIndexResponse.acknowledged());
}
/**
* 添加数据,不存在索引直接创造索引
*/
@Test
void setIndex() throws Exception {
Account account = new Account("testid",24,"北京市海淀区","张三");
IndexRequest indexRequest = new IndexRequest.Builder().index("account")
.document(account)
.build();
IndexResponse indexResponse = esConfig.configClient().index(indexRequest);
System.out.println(indexResponse);
}
/**
* 简单查询
*/
@Test
void getSearch() throws Exception{
//查询条件
MatchQuery query = QueryBuilders.match().field("employer").query("张三").build();
//查询请求
SearchRequest request = new SearchRequest.Builder().index("myindex").query(query._toQuery()).build();
//查询结果
SearchResponseresponse = esConfig.configClient().search(request,Account.class);
//解析请求结果
TotalHits totalHits = response.hits().total();
boolean exist = totalHits.relation() == TotalHitsRelation.Eq;
if(exist){
//命中的记录
List> hits = response.hits().hits();
for (Hit hit : hits) {
//记录解析成实体类
Account account = hit.source();
System.out.println(account.toString());
}
}else{
System.out.println("命中的记录数为"+totalHits.value());
}
}
}
判断索引是否存在
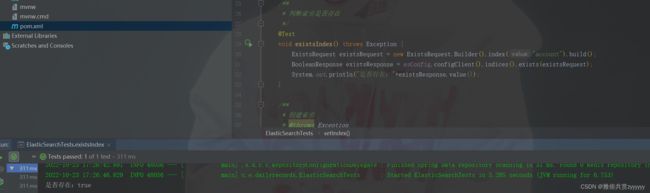
添加数据
在测试简单查询的时候,出现了一个问题,控制台在执行查询时报错了co.elastic.clients.json.JsonpMappingException: Error deserializing co.elastic.clients.elasticsearch.core.search.Hit: jakarta.json.JsonException: Jackson exception (JSON path: hits.hits[0].,这个问题是由于实体类中构造了一个方便实例化该类的有参构造函数,导致JVM不会添加默认的无参构造函数,而jackson的反序列化需要无参构造函数造成的,因此在实体类中添加一个无参构造,问题成功解决
package com.example.dailyrecords.es.entity;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.Data;
/**
* @author zy
* @version 1.0.0
* @ClassName Account.java
* @Description TODO
* @createTime 2022/10/23
*/
@Data
public class Account {
public String id;
public Integer age;
public String address;
public String employer;
public Account(String id, Integer age, String address, String employer) {
this.id = id;
this.age = age;
this.address = address;
this.employer = employer;
}
public Account() {
}
}
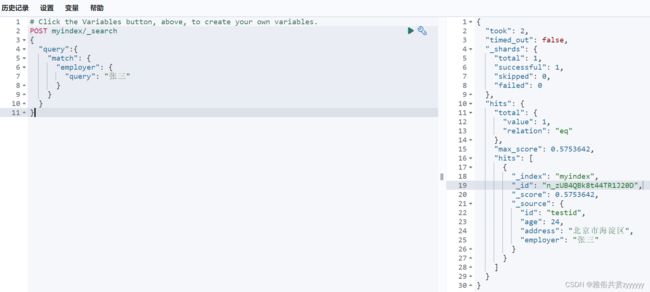
上面的简单查询是先在Kibana控制台构造了查询条件进行测试,然后根据构造条件写的代码。但是,光看这些代码和配置是不是感觉很繁琐,SpringBoot为我们提供了开箱即用的一个工具去操作ES,没错,就是spring-boot-starter-data-elasticsearch,看到这熟悉的starter是不是感觉很亲切!!!
5、通过spring-boot-starter-data-elasticsearch操作ES
首先,还是要引入依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
然后,我们需要到配置文件进行一些ES的连接配置,很简单,如下所示
#ES配置
spring.elasticsearch.uris=192.168.136.128:9200
spring.elasticsearch.username=elastic
spring.elasticsearch.password=123456
只需要上面三个配置(甚至是只有url即可,只要你把es的配置文件中安全认证关闭),即可连接es。接下来我们创建一个新的实体类,代码如下
package com.example.dailyrecords.es.entity;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
* @author zy
* @version 1.0.0
* @ClassName Account.java
* @Description TODO
* @createTime 2022/10/23
*/
@Data
@Document(indexName = "myindex")
public class AccountEntity {
@Id
public String id;
@Field(type = FieldType.Integer)
public Integer age;
@Field(analyzer = "ik_max_word",searchAnalyzer = "ik_max_word",type = FieldType.Text)
public String address;
@Field(type = FieldType.Text)
public String employer;
public AccountEntity(String id, Integer age, String address, String employer) {
this.id = id;
this.age = age;
this.address = address;
this.employer = employer;
}
public AccountEntity() {
}
}
这里,要对其中的注解要做一些说明
@Document(indexName = "es",type = "user",shards = 5,replicas = 0):标注在实体类上,声明存储的索引和类型。indexName-索引名称、type-索引类型(注意后面弃用了)、shards-分片数量、replicas-副本数量
@Id,主键注解,标注一个属性为主键
@Field,标注再属性上,用来指定属性的类型。analyzer-指定分词器,例如ik_max_word、type-指定属性在es中的类型,例如FieldType.Integer、index-指定是否需要索引,默认true、store-指定内容是否需要存储,默认true、fielddata-指定该属性能否进行排序、searchAnalyzer-指定搜索使用的分词器。如果我们指定属性类型为Date类型,需要指定日期格式,@Field(type = FieldType.Date,format = DateFormat.custom, pattern ="yyyy-MM-dd HH:mm:ss")
接下来,创建一个接口,让它继承ElasticsearchRepository,它为我们提供了一些基本的CRUD操作,代码如下
package com.example.dailyrecords.es.service;
import com.example.dailyrecords.es.entity.AccountEntity;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* @author zy
* @version 1.0.0
* @ClassName AccountService.java
* @Description TODO
* @createTime 2022/10/24
*/
@Repository
public interface AccountService extends ElasticsearchRepository {
}
一切准备就绪,我们就可以来写一些测试代码,体验一下它的使用
package com.example.dailyrecords.es.controller;
import com.example.dailyrecords.es.entity.AccountEntity;
import com.example.dailyrecords.es.service.AccountService;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
/**
* @author zy
* @version 1.0.0
* @ClassName ElasticSearchController.java
* @Description TODO
* @createTime 2022/10/23
*/
@RestController
public class ElasticSearchController {
@Autowired
private AccountService accountService;
/**
* 通过主键查询
* @param id
* @return
*/
@RequestMapping("/findById")
public String findById(String id){
Optional accountEntity = accountService.findById(id);
return accountEntity.toString();
}
/**
* 批量新增
* @return
* 这里报了一个错nested exception is java.lang.RuntimeException: Unable to parse response body for Response,原因是因为es服务器的响应程序解析不了
* 有可能是spring-boot版本低了,我的es是8.4.1版本的,但是数据是能保存进es的,而且es那边也不报错
*/
@RequestMapping("/save")
public String save(){
try{
Listlist = new ArrayList<>();
list.add(new AccountEntity("11111",38,"北京市昌平区","王五"));
list.add(new AccountEntity("22222",20,"北京市朝阳区","李三"));
list.add(new AccountEntity("33333",28,"秦皇岛市海港区男子职业技术学院","赵四"));
Iterable accountEntities = accountService.saveAll(list);
}catch (Exception e){
e.getMessage();
}
return "success";
}
/**
* 自定义方法,例如根据地址搜索,只需要在service层添加如下方法
* @Query("{\"match\": {\"address\": {\"query\": \"北京\"}}}")
* List searchByAddress(MatchQueryBuilder addressQuery);
* @return
*/
@RequestMapping("/search")
public List search(){
MatchQueryBuilder addressQuery = QueryBuilders.matchQuery("address","北京");
Listlist = accountService.searchByAddress(addressQuery);
return list;
}
}


上面给出了一些使用spring-boot-starter-data-elasticsearch操作es数据的一些代码示例,这些都是很简单的例子,其中还有很多有趣的方法和实例,例如匹配查询match query、精确查询term query、布尔过滤器bool query、范围查询range query等等,请参考官网https://docs.spring.io/spring-data/elasticsearch/docs/
六、总结
这篇文章主要介绍了es的单机版安装、kibana控制台的安装和ik分词器插件的使用以及SpringBoot项目如何调用API去进行一些数据的CURD操作,这只是入门级的知识,同时文章中的内容并不是很详尽,还需要参照官方文档做进一步的学习。