图床项目功能实现以及分析
文章目录
- 一、图床项目架构分析
- 二、注册功能
-
-
- (1)首先是对接收到的数据请求进行获取
- (2)解析收到的用户注册信息的json数据包
- (3)获取数据库用户名、用户密码、数据库标示等信息
- (4)连接数据库,查看用户信息是否存在
- (5)存取用户信息
- (6)返回状态信息给前端
-
- 三、登录功能
-
-
- (2)解析出用名和密码
- (3)判断登录成功与否
- (4)生成和设置token并存储到redis中
-
- 四、上传文件
-
-
- 秒传文件
- (2)获取用户登录信息
- (3)验证token登陆
- (4)秒传文件
- 上传文件
- (2)得到上传文件并保存在本地
- (3)将这个本地文件上传到 后台分布式文件系统(fastdfs)中
- (4)删除本地临时存放的上传文件
- (5)得到文件所存放storage的host_name,并拼接出完整的http地址
- (6)把文件信息存储到数据库
-
- 五、获取用户文件列表
-
-
- (2)获取URL地址 "?" 后面的cmd
- (3)根据cmd的不同内容执行不同的操作
-
- 六、获取共享文件或下载榜
-
-
- (2)获取共享文件个数
- (3)解析JSON包获取文件起点和文件请求个数
- (4)获取共享文件列表
- (5)获取共享文件排行榜
-
- 七、删除文件
-
-
- (1) 先判断此文件是否已经分享
- (2)若此文件被分享,删除分享列表(share_file_list)的数据
- (3)删除用户文件列表的数据并使用户文件数量-1
- (4)当文件引用计数为0时,在storage删除此文件
-
- 八、分享文件
-
-
- (1)先判断此文件是否已经分享,判断集合有没有这个文件,如果有,说明别人已经分享此文件,中断操作(redis操作),直接返回前端信息
- (2)若redis没记录,mysql中有记录,
- (3)如果mysql中也没有此操作
- (4)共享操作
-
- 九、更新文件下载计数
- 十、处理分享文件
-
-
- 取消分享文件
- 转载文件
- 下载共享文件
-
- 十一、图床分享图片
-
-
- 图片分享
-
一、图床项目架构分析
该项目的系统架构如下图所示:

该项目一共要实现9大功能,分别是。
接下来对这些功能的实现进行一一的分析
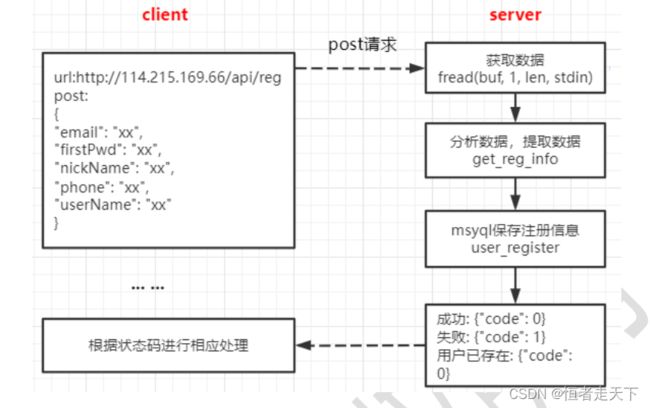
二、注册功能
注册功能的实现的逻辑如下图所示:
通过fastCGI了解与学习使用这篇对fastCGI的学习我们知道了,web服务器收到的请求都要通过fastCGI接口来调用解析。
对于程序的解析,执行套用fastCGI的执行过程代码就是了。本次的注册功能的实现也是如此:
//阻塞等待用户连接
while (FCGI_Accept() >= 0)
{
//获得http的长度
char *contentLength = getenv("CONTENT_LENGTH");
int len;
printf("Content-type: text/html\r\n\r\n");
套用流程还是不变的,不熟悉的可以回看fastCGI这篇文章。
本次主要讲述注册功能逻辑代码的实现:
(1)首先是对接收到的数据请求进行获取
直接通过系统调用,读取内核缓冲区接受到的内容
char buf[4*1024] = {0};
int ret = 0;
char *out = NULL;
ret = fread(buf, 1, len, stdin); //从标准输入(web服务器)读取内容
本项目是选的json进行数据传输的,对于json不了解的可以参考这篇文章
(2)解析收到的用户注册信息的json数据包
/*json数据如下
{
userName:xxxx,
nickName:xxx,
firstPwd:xxx,
phone:xxx,
email:xxx
}
*/
cJSON * root = cJSON_Parse(reg_buf);
if(NULL == root)
{
LOG(REG_LOG_MODULE, REG_LOG_PROC, "cJSON_Parse err\n");
ret = -1;
goto END;
}
//返回指定字符串对应的json对象
//用户
cJSON *child1 = cJSON_GetObjectItem(root, "userName");
注册信息的解析,只是用到了cJSON_Parse()将读取到的json数据初始化cJSON指针,cJSON_GetObjectItem()通过键直接进行解析。对于这些用法,在写的关于json的文章中都有记述。
(3)获取数据库用户名、用户密码、数据库标示等信息
注意对于项目中用到的服务的配置项已经写到了一个json文件里,用到谁解析它就可以了

因此要获取数据库用户名、用户密码、数据库标示等信息,解析这个文件即可。
流程也比较简单,读取这个文件,然后解析json数据即可(还是上面用到的那两个函数)
//只读方式打开文件
fp = fopen(profile, "rb");
fseek(fp, 0, SEEK_END);//光标移动到末尾
long size = ftell(fp); //获取文件大小
fseek(fp, 0, SEEK_SET);//光标移动到开头
buf = (char *)calloc(1, size+1); //动态分配空间
//读取文件内容
fread(buf, 1, size, fp);
//解析一个json字符串为cJSON对象
cJSON * root = cJSON_Parse(buf);
//返回指定字符串对应的json对象
cJSON * father = cJSON_GetObjectItem(root, title);
(4)连接数据库,查看用户信息是否存在
数据库连接如下:
MYSQL *conn = NULL; //MYSQL对象句柄
//用来分配或者初始化一个MYSQL对象,用于连接mysql服务端
conn = mysql_init(NULL);
//mysql_real_connect()尝试与运行在主机上的MySQL数据库引擎建立连接
mysql_real_connect(conn, NULL, user_name, passwd, db_name, 0, NULL, 0);
判断用户信息是否存在
//设置数据库编码,主要处理中文编码问题
mysql_query(conn, "set names utf8");
//查询数据库中是否已经存在user_name
char sql_cmd[SQL_MAX_LEN] = {0};
sprintf(sql_cmd, "select * from user_info where user_name = '%s'", user_name);
mysql_query(conn, sql_cmd);//查询
MYSQL_RES *res_set = NULL; //结果集结构的指针
res_set = mysql_store_result(conn);//生成结果集
//mysql_num_rows接受由mysql_store_result返回的结果结构集,并返回结构集中的行数
line = mysql_num_rows(res_set);
/*根据行数进行判断,如果为0行说明,没有存入该用户信息;否则,说明用户信息已经插入*/
(5)存取用户信息
//当前时间戳
struct timeval tv;
struct tm* ptm;
char time_str[128];
//使用函数gettimeofday()函数来得到时间。它的精度可以达到微妙
gettimeofday(&tv, NULL);
ptm = localtime(&tv.tv_sec);//把从1970-1-1零点零分到当前时间系统所偏移的秒数时间转换为本地时间
//strftime() 函数根据区域设置格式化本地时间/日期,函数的功能将时间格式化,或者说格式化一个时间字符串
strftime(time_str, sizeof(time_str), "%Y-%m-%d %H:%M:%S", ptm);
//sql 语句, 插入注册信息
sprintf(sql_cmd, "insert into user_info (user_name, nick_name, password, phone, email, create_time) values ('%s', '%s', '%s', '%s', '%s', '%s')", user_name, nick_name, pwd, tel, email, time_str);
mysql_query(conn, sql_cmd);
(6)返回状态信息给前端
也是通过json数据包返回
/*
注册:
成功:{"code": 0}
失败:{"code":1}
该用户已存在:{"code":2}*/
//返回前端情况,NULL代表失败, 返回的指针不为空,则需要free
char * return_status(int ret_code)
{
//ret_code 0 1 2
char *out = NULL;
cJSON *root = cJSON_CreateObject(); //创建json项目
cJSON_AddItemToObject(root, "code", cJSON_CreateNumber(ret_code));//
out = cJSON_Print(root);//cJSON to string(char *)
cJSON_Delete(root);
return out;
}
三、登录功能
登录功能的实现的逻辑如下图所示:

通过fastCGI接口来调用解析,以及对接收到的数据请求进行获取与注册功能的实现一样,这里就不在赘述。
(2)解析出用名和密码
//获取登陆用户的信息
char username[512] = {0};
char pwd[512] = {0};
//解析json包
//解析一个json字符串为cJSON对象
cJSON * root = cJSON_Parse(buf);
//返回指定字符串对应的json对象
//用户
cJSON *child1 = cJSON_GetObjectItem(root, "user");
strcpy(username, child1->valuestring); //拷贝内容
(3)判断登录成功与否
首先要获取数据库用户名、用户密码、数据库标示等信息,并且连接数据库。这其实就是注册功能中的步骤(3)和(4),也不再赘述。不懂的可以回去看。这里主要说下查询判断即可。
//设置数据库编码,主要处理中文编码问题
mysql_query(conn, "set names utf8");
//sql语句,查找某个用户对应的密码
char sql_cmd[SQL_MAX_LEN] = {0};
sprintf(sql_cmd, "select password from user_info where user_name='%s'", username);
/*验证密码是否正确与注册功能(4)判断用户信息是否存在一样,只不过多了个把查询到的密码信息保存下来,与pwd进行比较而已*/
(4)生成和设置token并存储到redis中
看到这,如果对token,请看我写的关于token的这篇文章文章
首先要连接redis数据库,连接redis数据库前必须获得redis服务的ip和端口(cfg.json中)与注册功能的步骤(3)获取数据库用户名、用户密码、数据库标示等信息一样,都是解析json文件提取数据不再赘述。
这里只说下连接redis数据库即可
//redis 服务器ip、端口
char redis_ip[30] = {0};
char redis_port[10] = {0};
uint16_t port = atoi(redis_port);
redisContext *conn = NULL;
conn = redisConnect(redis_ip, port);
对于token的生成,本程序采用随机数+base64+md5 生成的:
随机数如下:
//产生4个1000以内的随机数
int rand_num[4] = {0};
int i = 0;
//设置随机种子
srand((unsigned int)time(NULL));
for(i = 0; i < 4; ++i)
{
rand_num[i] = rand()%1000;//随机数
}
char tmp[1024] = {0};
sprintf(tmp, "%s%d%d%d%d", username, rand_num[0], rand_num[1], rand_num[2], rand_num[3]); // token唯一性
//加密
#define USER_PASSWORD_KEY "abcd1234"
char enc_tmp[1024*2] = {0};
int enc_len = 0;
int rv;
unsigned char *padDate = NULL;
unsigned int padDateLen = 0;
CW_dataPadAdd(0, tmp, (unsigned int )strlen(tmp), &padDate, &padDateLen);
rv = myic_DESEncrypt((unsigned char *)USER_PASSWORD_KEY, strlen(USER_PASSWORD_KEY),
padDate, (int)padDateLen, enc_tmp, &enc_len);
base64编码 防止不可见字符,代码不贴出了,网上一搜就有太常见了
这里主要展示先,是怎么设置token的有效时间的(通过 redis 的 key超时机制实现)
redisReply *reply = NULL;
reply = redisCommand(conn, "setex %s %u %s", key, seconds, value);
返回前端情况:
cJSON *root = cJSON_CreateObject(); //创建json项目
cJSON_AddStringToObject(root, "token", token);// {"token":"token"}
cJSON_Delete(root);
四、上传文件
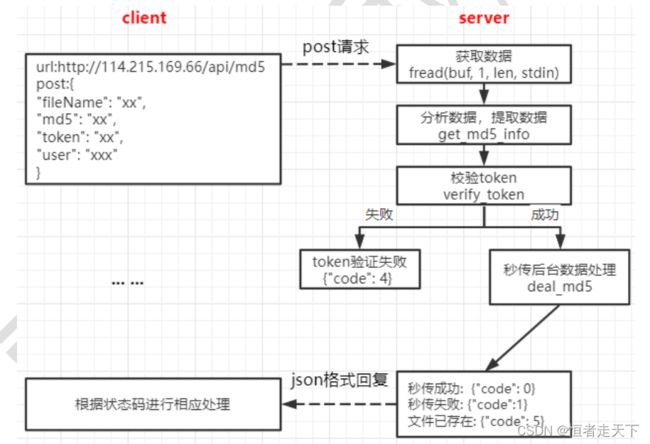
秒传文件
秒传文件功能的实现的逻辑如下图所示:
通过fastCGI接口来调用解析,以及对接收到的数据请求进行获取与注册功能的实现一样,这里就不在赘述。
(2)获取用户登录信息
解析JSON数据包,获得用户登录信息
//读取内容
char buf[4*1024] = {0};
int ret = 0;
ret = fread(buf, 1, len, stdin); //从标准输入(web服务器)读取内容
//解析json数据包
/*
{
user:xxxx,
token: xxxx,
md5:xxx,
fileName: xxx
}
*/
char user[128] = {0};
char md5[256] = {0};
char token[256] = {0};
char filename[128] = {0};
cJSON * root = cJSON_Parse(buf);
//用户
cJSON *child1 = cJSON_GetObjectItem(root, "user");
strcpy(user, child1->valuestring); //拷贝内容
//MD5
cJSON *child2 = cJSON_GetObjectItem(root, "md5");
strcpy(md5, child2->valuestring); //拷贝内容
/*其他一样不再赘述*/
(3)验证token登陆
需要首先连接redis数据库,这里就不在赘述了,在登录用户的时候,储存token时,已经展示了。
连接了redis数据库之后,需要根据user键读取value(token)进行比较
//获取user对应的value
ret = rop_get_string(redis_conn, user, tmp_token);
if(ret == 0)
{
if( strcmp(token, tmp_token) != 0 ) //token不相等
{
ret = -1;
}
}
(4)秒传文件
这里先说下思路:每个文件都有一个唯一的 MD5 值(比如 2bf8170b42cc7124b04a8886c83a9c6f),就好比每个人的指纹都是唯一的一样,效验 MD5 就是用来确保文件在传输过程中未被修改过。
(1)客户端在上传文件之前将文件的 MD5 码上传到服务器
(2)服务器端判断是否已存在此 MD5 码,如果存在,说明该文件已存在,则此文件无需再上传,
在此文件的计数器加 1,说明此文件多了一个用户共用。
file_info count
插入用户文件列表
用户文件计数+1
向mysql数据库查询此文件的md5值,判断文件是否存在,存在获取count。向数据库中查询信息,这与注册功能的步骤(4)连接数据库,查看用户信息是否存在一样,只不过此处需要保存查询的值(count)。如果能查到说明此时服务器已经存在此文件
服务器存在此文件的情况下,实现秒传功能。
(1)查看此用户是否已经有了此文件,通过SQL语句向数据库查询
这里只把sql语句的代码贴出来,操作数据库查询信息的代码和上面一样就不贴了
//查看此用户是否已经有此文件,如果存在说明此文件已上传,无需再上传
sprintf(sql_cmd, "select * from user_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
如果此用户有文件了,直接返回即可
(2)查询到此用户没有文件
1.更新此文件的引用计数(count)使其加一(此方法的使用和智能指针的实现类似)
//1、修改file_info中的count字段,+1 (count 文件引用计数)
sprintf(sql_cmd, "update file_info set count = %d where md5 = '%s'", ++count, md5);//前置++
mysql_query(conn, sql_cmd);
2.向该用户对应的列表插入拥有该文件的信息
//当前时间戳
struct timeval tv;
struct tm* ptm;
char time_str[128];
//使用函数gettimeofday()函数来得到时间。它的精度可以达到微妙
gettimeofday(&tv, NULL);
ptm = localtime(&tv.tv_sec);//把从1970-1-1零点零分到当前时间系统所偏移的秒数时间转换为本地时间
//strftime() 函数根据区域设置格式化本地时间/日期,函数的功能将时间格式化,或者说格式化一个时间字符串
strftime(time_str, sizeof(time_str), "%Y-%m-%d %H:%M:%S", ptm);
//插入
sprintf(sql_cmd, "insert into user_file_list(user, md5, create_time, file_name, shared_status, pv) values ('%s', '%s', '%s', '%s', %d, %d)", user, md5, time_str, filename, 0, 0);
mysql_query(conn, sql_cmd)
3.更新user_file_count 用户文件数量
如果此用户文件数量为0(就是此用户之前没有文件,表里记录为0),则插入一条即可。
如果之前有更新下+1即可
//数据库插入此记录
sprintf(sql_cmd, " insert into user_file_count (user, count) values('%s', %d)", user, 1);
//更新用户文件数量count字段
count = atoi(tmp);
sprintf(sql_cmd, "update user_file_count set count = %d where user = '%s'", count+1, user);
mysql_query(conn, sql_cmd)
如果服务器没有存在此文件,则直接秒传失败。秒传其实就是用到了引用计数的功能(不用频繁的创建对象),不用重新上传。秒传其实就是没传
上传文件
上传文件功能的实现的逻辑如下图所示:

首先要获得mysql数据库的配置信息,已经用过很多次,这里不再赘述
"mysql":
{
"ip": "127.0.0.1",
"port": "3306",
"database": "0voice_tuchuang",
"user": "root",
"password": "123456"
},
(2)得到上传文件并保存在本地
首先要做发送的post的请求中解析出来,post请求如下:
------WebKitFormBoundary88asdgewtgewx\r\n
Content-Disposition: form-data; user = "milo"; filename = "xxx.jpg"; md5 = "xxxx"; size = 1024\r\n
Content-Type: application/octet-stream\r\n
\r\n
真正的文件内容\r\n
------WebKitFormBoundary88asdgewtgewx
提取出文件内容的代码如下:
/* 存储变量的定义*/
int ret = 0;
char *file_buf = NULL; //数据信息的存储
char *buf_end = NULL;
char *begin = NULL;
char *p1, *p2, *p3, *p4, *p5, *p6, *end;
char *p, *q, *k;
char *file_start = NULL; // 文件内容的起始位置
char *file_end = NULL; // 文件内容的结束位置
char size_text[64+1] = {0}; //文件头部信息
char boundary[TEMP_BUF_MAX_LEN] = {0}; //分界线信息
//==========> 开辟存放文件的 内存 <===========
file_buf = (char *)malloc(len);
int ret2 = fread(file_buf, 1, len, stdin); //从标准输入(web服务器)读取内容(post请求)
begin = file_buf; //内存起点
buf_end = file_buf + len;
p = begin;
// 1. 跳过分界线
p1 = strstr(begin, "\r\n"); // 作用是返回字符串中首次出现子串的地址
//拷贝分界线
strncpy(boundary, begin, p1-begin); // 缓存分界线, 比如:WebKitFormBoundary88asdgewtgewx
boundary[p1-begin] = '\0'; //字符串结束符
// 文件内容在Content-Type: image/jpeg 之后
file_start = strstr(begin, "Content-Type:");
file_start = strstr(file_start, "\r\n"); /// 得到文件的起始位置
file_start += strlen("\r\n"); // 跳过Content-Type:所在行
file_start += strlen("\r\n"); // 文件内容前还有空白换行
file_end = strstr(file_start, boundary); // 得到文件的结束位置, 文件太大遍历有问题?
//遍历得到文件的末位置
//得到文件的长度
for (i = 0; i <= total_len - seplen; i++)
{
if (memcmp(buf + from , sep, seplen) == 0)
break;
++from;
}
file_end -= strlen("\r\n"); // 要减去换行的长度
/*到此已经获得了上传文件的起始位置和末尾位置*/
接下来提取post请求传来的user filename md5 size
Content-Disposition: form-data; user = "milo"; filename = "xxx.jpg"; md5 = "xxxx"; size = 1024\r\n
方法都一样都是移动指针而已,展示一个就行了,不一一展示了,快恶心坏啊
p2 = strstr(p1, "filename="); // 查找到filename=起始位置
p2 += strlen("filename=\""); // 跳过filename=" ,获取到p2的起始位置。
LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC,"%s %d\n", __FUNCTION__, __LINE__);
end = strstr(p2, "\""); // 查到filename="test-animal1.jpg"的"的结束位置
strncpy(filename, p2, end-p2);
filename[end-p2] = '\0';
将文件在本地保存
fd = open(filename, O_CREAT|O_WRONLY, 0644); //可见文件是保存在本地服务器上的(这里是要优化的点)
//ftruncate会将参数fd指定的文件大小改为参数length指定的大小
ftruncate(fd, file_end - file_start);
write(fd, file_start, file_end - file_start);
close(fd);
(3)将这个本地文件上传到 后台分布式文件系统(fastdfs)中
流程如下图所示:

通过多进程的方式,子进程通过execlp()进程替换执行fastdfs写的的客户端上传文件的程序
fdfs_upload_file 客户端的配置文件(/etc/fdfs/client.conf) 要上传的文件
该函数返回文件的id
结果字符串: group1/M00/00/00/wKj3h1vC-PuAJ09iAAAHT1YnUNE31352.c
通过管道,返回给父进程
代码逻辑如下:
//子进程
if(pid == 0)
{
//关闭读端
close(fd[0]);
//此时就是把该进程的printf输出到fd[1]文件里,其实该进程打印到终端的就是group1/M00/00/00/wKj3h1vC-PuAJ09iAAAHT1YnUNE31352.c(类似这东西)
//将标准输出 重定向 写管道
dup2(fd[1], STDOUT_FILENO); // 往标准输出写的东西都会重定向到fd所指向的文件, 当fileid产生时输出到管道fd[1]
//读取fdfs client 配置文件的路径
char fdfs_cli_conf_path[256] = {0};
get_cfg_value(CFG_PATH, "dfs_path", "client", fdfs_cli_conf_path);
// fdfs_upload_file /etc/fdfs/client.conf 123.txt
LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC, "fdfs_upload_file %s %s\n", fdfs_cli_conf_path, filename);
//通过execlp执行fdfs_upload_file 如果函数调用成功,进程自己的执行代码就会变成加载程序的代码,execlp()后边的代码也就不会执行了.
execlp("fdfs_upload_file", "fdfs_upload_file", fdfs_cli_conf_path, filename, NULL);
//或者使用下面这种方式条用
//int temp = upload_to_dstorage_1(filename, fdfs_cli_conf_path, fileid);
//LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC, "ret:%d!\n", temp);
//执行失败
LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC, "execlp fdfs_upload_file error\n");
close(fd[1]);
}
//父进程
else
{
//关闭写端
close(fd[1]);
//从管道中去读数据
read(fd[0], fileid, TEMP_BUF_MAX_LEN); // 等待管道写入然后读取
//去掉一个字符串两边的空白字符
trim_space(fileid);
if (strlen(fileid) == 0)
{
LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC,"[upload FAILED!]\n");
ret = -1;
goto END;
}
LOG(UPLOAD_LOG_MODULE, UPLOAD_LOG_PROC, "get [%s] succ!\n", fileid);
wait(NULL); //等待子进程结束,回收其资源
close(fd[0]);
}
(4)删除本地临时存放的上传文件
定义函数:int unlink(const char * pathname);
函数说明:unlink()会删除参数pathname 指定的文件. 如果该文件名为最后连接点, 但有其他进程打开了此文件, 则在所有关于此文件的文件描述词皆关闭后才会删除. 如果参数pathname 为一符号连接, 则此连接会被删除。
返回值:成功则返回0, 失败返回-1, 错误原因存于errno
unlink(filename);
(5)得到文件所存放storage的host_name,并拼接出完整的http地址
代码实现逻辑和把文件上传到fastdfs系统一样,都是多进程加管道通信
/*读取存储文件的信息文件,利用fastdfs自带的fdfs_file_info进程*/
//使用“fdfs_file_info”可以查看到文件的详细存储信息,也是跟上客户端的配置文件以及储服务器返回给我们的文件的路径
execlp("fdfs_file_info", "fdfs_file_info", fdfs_cli_conf_path, fileid, NULL);
/*从输出的文件信息提取出完整的url:http://host_name/group1/M00/00/00/D12313123232312.png*/
//还是从输出的字符串中截取字符串,不再展示了,很繁琐
(6)把文件信息存储到数据库
更新对数据库的操作:分别是对数据库中的两个表的插入操作
/*
-- =============================================== 文件信息表
-- md5 文件md5
-- file_id 文件id
-- url 文件url
-- size 文件大小, 以字节为单位
-- type 文件类型: png, zip, mp4……
-- count 文件引用计数, 默认为1, 每增加一个用户拥有此文件,此计数器+1
*/
/*
-- =============================================== 用户文件列表
-- user 文件所属用户
-- md5 文件md5
-- create_time 文件创建时间
-- file_name 文件名字
-- shared_status 共享状态, 0为没有共享, 1为共享
-- pv 文件下载量,默认值为0,下载一次加1
*/
不再展示内容比较简单。
五、获取用户文件列表
获取用户文件列表功能的实现的逻辑如下图所示:
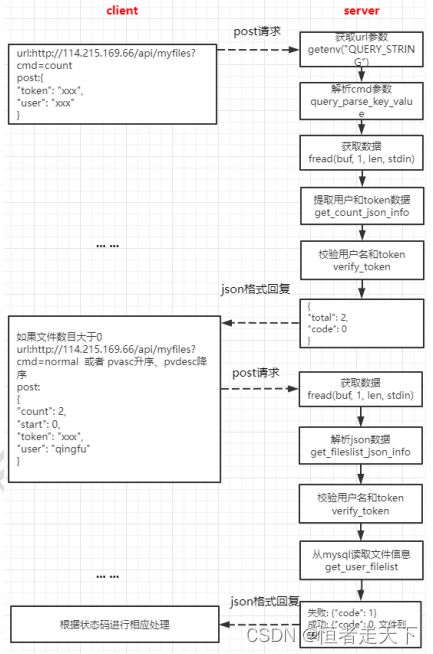
?后面的内容cmd,其实是为了判断要做什么处理的
分批量请求,分批量处理
(2)获取URL地址 “?” 后面的cmd
因为cmd的内容不同,执行的操作不同,例如:
获取用户文件个数 http://127.0.0.1:80/myfiles?cmd=count
获取用户文件信息 http://127.0.0.1:80/myfiles?cmd=normal
按下载量升序 http://127.0.0.1:80/myfiles?cmd=pvasc
按下载量降序 http://127.0.0.1:80/myfiles?cmd=pvdesc
代码如下:
char cmd[20];
// 获取URL地址 "?" 后面的内容
char *query = getenv("QUERY_STRING");
//解析命令
char *temp = NULL;
char *end = NULL;
int value_len =0;
//找到是否有cmd
temp = strstr(query, "cmd");
temp += strlen("cmd");//=
temp++;//cmd
//get value
end = temp;
while ('\0' != *end && '#' != *end && '&' != *end )
{
end++;
}
value_len = end-temp;
strncpy(cmd, temp, value_len);
cmd[value_len] ='\0';
(3)根据cmd的不同内容执行不同的操作
1.count 获取用户文件个数
(1)首先要是有token验证用户登录
先获取post中的token
/*解析收到的post*/
//格式如下
//{ "user": "kevin", "token": "xxxx" }
//解析json包
cJSON *root = cJSON_Parse(buf);
cJSON *child1 = cJSON_GetObjectItem(root, "user");
strcpy(user, child1->valuestring); //拷贝内容
cJSON *child2 = cJSON_GetObjectItem(root, "token");
strcpy(token, child2->valuestring); //拷贝内容
进行token验证
/*先获得redis中存储的user的token*/
redisReply *reply = NULL;
reply = redisCommand(conn, "get %s", key);
strncpy(value, reply->str, reply->len);
value[reply->len] = '\0'; //字符串结束符
freeReplyObject(reply);
/*进行比较*/
strcmp(token, value);
(2)获取用户文件个数
/*连接数据库进行获取*/
sprintf(sql_cmd, "select count from user_file_count where user='%s'", user);
process_result_one(conn, sql_cmd, tmp); //指向sql语句
line = atol(tmp); //字符串转长整形
/*把情况返回给前端*/
cJSON *root = cJSON_CreateObject(); //创建json项目
cJSON_AddItemToObject(root, "code", cJSON_CreateNumber(ret_code));
cJSON_AddItemToObject(root, "total", cJSON_CreateNumber(total));
out = cJSON_Print(root); // cJSON to string(char *)
cJSON_Delete(root);
printf(out); //给前端反馈信息
free(out); //记得释放
2.获取用户文件信息 127.0.0.1:80/myfiles&cmd=normal
按下载量升序 127.0.0.1:80/myfiles?cmd=pvasc
按下载量降序127.0.0.1:80/myfiles?cmd=pvdesc
(1)首先要是有token验证用户登录
因与1一样,不再赘述(只不过此时post不一样而已,post数据{ “user”: “yoyo” , “token”: “xxxx”, “start”: 0, “count”: 10 })
(2)获取用户文件列表
//不同的cmd执行不同的查询语句
//多表指定行范围查询
if (strcmp(cmd, "normal") == 0) //获取用户文件信息
{
// sql语句
sprintf(sql_cmd, "select user_file_list.*, file_info.url, file_info.size, file_info.type from file_info, user_file_list where user = '%s' and file_info.md5 = user_file_list.md5 limit %d, %d", user, start, count);
}
else if (strcmp(cmd, "pvasc") == 0) //按下载量升序
{
// sql语句
sprintf(sql_cmd, "select user_file_list.*, file_info.url, file_info.size, file_info.type from file_info, user_file_list where user = '%s' and file_info.md5 = user_file_list.md5 order by pv asc limit %d, %d", user, start, count);
}
else if (strcmp(cmd, "pvdesc") == 0) //按下载量降序
{
// sql语句
sprintf(sql_cmd, "select user_file_list.*, file_info.url, file_info.size, file_info.type from file_info, user_file_list where user = '%s' and file_info.md5 = user_file_list.md5 order by pv desc limit %d, %d", user, start, count);
}
mysql_query(conn, sql_cmd);
res_set = mysql_store_result(conn); /*生成结果集*/
int line = 0;
// mysql_num_rows接受由mysql_store_result返回的结果结构集,并返回结构集中的行数
line = mysql_num_rows(res_set);
(3)把查到的结果返回给前端
通过创建json文件返回给前端
cJSON *root = NULL;
root = cJSON_CreateObject();
cJSON *array = NULL;
array = cJSON_CreateArray();
// mysql_fetch_row从使用mysql_store_result得到的结果结构中提取一行,并把它放到一个行结构中。
// 当数据用完或发生错误时返回NULL.
while ((row = mysql_fetch_row(res_set)) != NULL)
{
// array[i]:
cJSON *item = cJSON_CreateObject();
int column_index = 1;
//-- user 文件所属用户
if (row[column_index] != NULL)
{
cJSON_AddStringToObject(item, "user", row[column_index]);
}
column_index++;
//-- md5 文件md5
if (row[column_index] != NULL)
{
cJSON_AddStringToObject(item, "md5", row[column_index]);
}
column_index++;
//-- createtime 文件创建时间
if (row[column_index] != NULL)
{
cJSON_AddStringToObject(item, "create_time", row[column_index]);
}
column_index++;
//-- filename 文件名字
if (row[column_index] != NULL)
{
cJSON_AddStringToObject(item, "file_name", row[column_index]);
}
column_index++;
//-- shared_status 共享状态, 0为没有共享, 1为共享
if (row[column_index] != NULL)
{
cJSON_AddNumberToObject(item, "share_status", atoi(row[column_index]));
}
column_index++;
//-- pv 文件下载量,默认值为0,下载一次加1
if (row[column_index] != NULL)
{
cJSON_AddNumberToObject(item, "pv", atol(row[column_index]));
}
column_index++;
//-- url 文件url
if (row[column_index] != NULL)
{
cJSON_AddStringToObject(item, "url", row[column_index]);
}
column_index++;
//-- size 文件大小, 以字节为单位
if (row[column_index] != NULL)
{
cJSON_AddNumberToObject(item, "size", atol(row[column_index]));
}
column_index++;
//-- type 文件类型: png, zip, mp4……
if (row[column_index] != NULL)
{
cJSON_AddStringToObject(item, "type", row[column_index]);
}
cJSON_AddItemToArray(array, item);
}
cJSON_AddItemToObject(root, "files", array);
cJSON_AddItemToObject(root, "count", cJSON_CreateNumber(line));
cJSON_AddItemToObject(root, "total", cJSON_CreateNumber(total));
out = cJSON_Print(root);
printf(out);
返回给前端的json包如下:

六、获取共享文件或下载榜
获取共享文件或下载榜功能的实现的逻辑如下图所示:
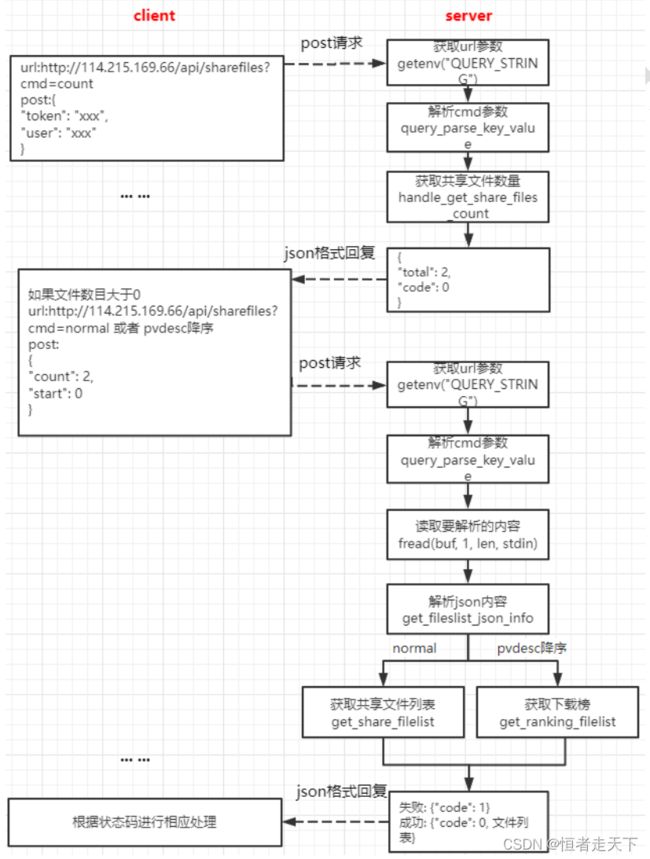
这一逻辑功能的实现类似,根据url的?的cmd的不同内容,来判断要做什么处理
获取共享文件个数 http://114.215.169.66/api/sharefiles?cmd=count
获取共享文件列表 http://114.215.169.66/api/sharefiles?cmd=normal
获取共享文件下载排行榜 http://114.215.169.66/api/sharefiles?cmd=pvdesc
解析命令来求出cmd,这一操作,和上面一样不再赘述
(2)获取共享文件个数
这里先展示下第一个,当cmd=“count”,获取共享文件个数的逻辑代码:
/*首先向数据库中进行获得count*/
sprintf(sql_cmd, "select count from user_file_count where user='%s'", "xxx_share_xxx_file_xxx_list_xxx_count_xxx");
char tmp[512] = {0};
mysql_query(conn, sql_cmd);
res_set = mysql_store_result(conn);//生成结果集
//mysql_fetch_row从结果结构中提取一行,并把它放到一个行结构中。当数据用完或发生错误时返回NULL.
row = mysql_fetch_row(res_set);
strcpy(tmp, row[0]);
/*生成json文件返回给前端*/
line = atol(tmp); //字符串转长整形
cJSON *root = cJSON_CreateObject(); //创建json项目
cJSON_AddItemToObject(root, "code", cJSON_CreateNumber(HTTP_RESP_OK));
cJSON_AddItemToObject(root, "total", cJSON_CreateNumber(line));
out = cJSON_Print(root); // cJSON to string(char *)
printf("%s", out); //给前端反馈的信息
cJSON_Delete(root);
if(out)
free(out);
对于其他请求的处理:
(3)解析JSON包获取文件起点和文件请求个数
cJSON *root = cJSON_Parse(buf);
//文件起点
cJSON *child2 = cJSON_GetObjectItem(root, "start");
int *p_start=child2->valueint;
//文件请求个数
cJSON *child3 = cJSON_GetObjectItem(root, "count");
int *p_count= child3->valueint;
(4)获取共享文件列表
此时cmd=“normal”
/*向数据库执行查询操作*/
// sql语句
sprintf(sql_cmd, "select share_file_list.*, file_info.url, file_info.size, file_info.type from file_info, share_file_list where file_info.md5 = share_file_list.md5 limit %d, %d", start, count);
mysql_query(conn, sql_cmd);
MYSQL_RES *res_set =mysql_store_result(conn); /*生成结果集*/
// mysql_num_rows接受由mysql_store_result返回的结果结构集,并返回结构集中的行数
int line = mysql_num_rows(res_set);
/*写入到json文件中,并返回*/
cJSON *root = NULL;
cJSON *array = NULL;
root = cJSON_CreateObject();
array = cJSON_CreateArray();
MYSQL_ROW row;
// mysql_fetch_row从使用mysql_store_result得到的结果结构中提取一行,并把它放到一个行结构中。
// 当数据用完或发生错误时返回NULL.
/*与获取用户列表操作一样不再展示*/
(5)获取共享文件排行榜
具体步骤如下:
(1) mysql共享文件数量和redis共享文件数量对比,判断是否相等
(2)如果不相等,清空redis数据,从mysql中导入数据到redis (mysql和redis交互)
(3)从redis读取数据,给前端反馈相应信息
首先要连接mysql,redis 数据库。这里不再讲述,上面都有其操作
1.接下来获取mysql的共享文件数量
sprintf(sql_cmd, "select count from user_file_count where user='%s'", "xxx_share_xxx_file_xxx_list_xxx_count_xxx");
MYSQL_RES *res_set =mysql_store_result(conn);//生成结果集
MYSQL_ROW row=mysql_fetch_row(res_set);
char tmp[512] = {0};
strcpy(tmp, row[0]);
int sql_num = atoi(tmp); //字符串转长整形
2.获取redis的共享文件数量
redisReply *reply = NULL;
reply = redisCommand(conn, "ZCARD %s", "FILE_PUBLIC_ZSET");
int cnt =reply->integer;
freeReplyObject(reply);
3.mysql共享文件数量和redis共享文件数量对比,判断是否相等。如果不相等,清空redis数据,重新从mysql中导入数据到redis (mysql和redis交互)
if (redis_num != sql_num)
{
//清空redis有序数据
redisReply *reply = NULL;
reply = redisCommand(conn, "DEL %s","FILE_PUBLIC_ZSET");
reply =redisCommand(conn, "DEL %s","FILE_NAME_HASH");
freeReplyObject(reply);
//从mysql中导入数据到redis
strcpy(sql_cmd, "select md5, file_name, pv from share_file_list order by pv desc");
mysql_query(conn, sql_cmd);
res_set = mysql_store_result(conn); /*生成结果集*/
MYSQL_ROW row;
// mysql_fetch_row从使用mysql_store_result得到的结果结构中提取一行,并把它放到一个行结构中。
// 当数据用完或发生错误时返回NULL.
while ((row = mysql_fetch_row(res_set)) != NULL)
{
char fileid[1024] = {0};
sprintf(fileid, "%s%s", row[0], row[1]); //文件标示,md5+文件名
//增加有序集合成员
reply = redisCommand(conn, "ZADD %s %ld %s","FILE_PUBLIC_ZSET", atoi(row[2]), fileid);
//增加hash记录
reply = redisCommand(conn, "hset %s %s %s","FILE_NAME_HASH", fileid, row[1]);
}
}
4.从redis读取数据,给前端反馈相应信息
七、删除文件
删除文件功能的实现的逻辑如下图所示:
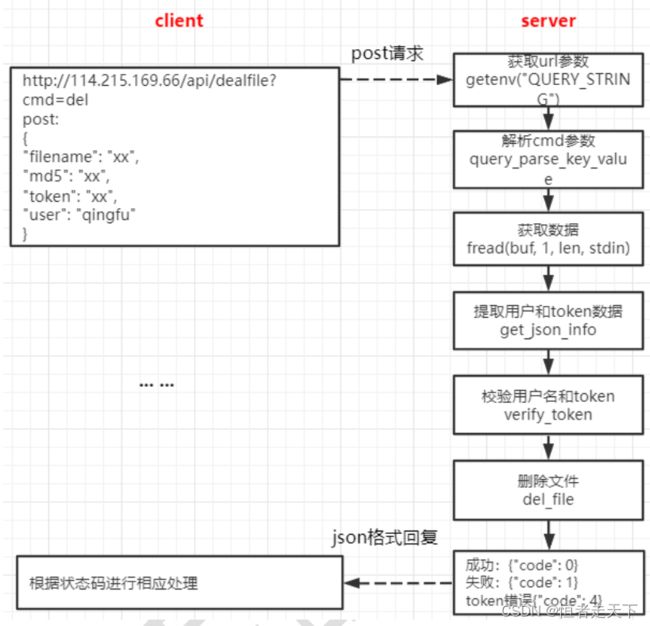
提取url的cmd的值,验证是删除操作,解析JSON包获取user, token, md5, filename的值以及发送token验证登录。这里都不在赘述,前面的代码已经展现很多遍了。代码都是一样的。
这里主要说下删除文件的操作。
具体步骤如下:
(1) 先判断此文件是否已经分享
//===1、先判断此文件是否已经分享,判断集合有没有这个文件,如果有,说明别人已经分享此文件
//文件标示,md5+文件名
sprintf(fileid, "%s%s", md5, filename);
redisReply *reply= redisCommand(conn, "zlexcount %s [%s [%s","FILE_PUBLIC_ZSET", fileid, fileid);
int retn = reply->integer;
freeReplyObject(reply);
if(retn == 1) //存在
{
share = 1; //共享标志
flag = 1; //redis有记录
}
else if(retn == 0) //不存在
{
//2、如果集合没有此元素,可能因为redis中没有记录,再从mysql中查询,如果mysql也没有,说明真没有(mysql操作)
//查看该文件是否已经分享了
sprintf(sql_cmd, "select shared_status from user_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
/*向mysql的查询操作,已经用了很多遍,也不再赘述了*/
}
(2)若此文件被分享,删除分享列表(share_file_list)的数据
if(share == 1)
{
/*分别删除mysql中的分享列表的数据和共享文件数量减1*/
/*这里只把对应的sql语句贴出了,不贴对应的操作了,已经展示很多遍了*/
//删除在共享列表的数据
sprintf(sql_cmd, "delete from share_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
//共享文件的数量-1
sprintf(sql_cmd, "update user_file_count set count = %d where user = '%s'", count-1, "xxx_share_xxx_file_xxx_list_xxx_count_xxx");
/*接下来判断Redis中是否有对应的存储记录*/
if(1 == flag)
{
reply = redisCommand(conn, "ZREM %s %s","FILE_PUBLIC_ZSET", fileid);
//从hash移除相应记录
redisCommand(conn, "hdel %s %s", "FILE_NAME_HASH", field);
}
}
(3)删除用户文件列表的数据并使用户文件数量-1
/*这里也只展示对应的sql操作*/
//查询用户文件数量
sprintf(sql_cmd, "select count from user_file_count where user = '%s'", user);
if(count >= 1)
{
sprintf(sql_cmd, "update user_file_count set count = %d where user = '%s'", count-1, user);
}
//删除用户文件列表数据
sprintf(sql_cmd, "delete from user_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
//文件信息表(file_info)的文件引用计数count,减去1
//查看该文件文件引用计数
sprintf(sql_cmd, "select count from file_info where md5 = '%s'", md5);
sprintf(sql_cmd, "update file_info set count=%d where md5 = '%s'", count-1, md5);
(4)当文件引用计数为0时,在storage删除此文件
if(count == 0) //说明没有用户引用此文件,需要在storage删除此文件
{
//查询文件的id
sprintf(sql_cmd, "select file_id from file_info where md5 = '%s'", md5);
//删除文件信息表中该文件的信息
sprintf(sql_cmd, "delete from file_info where md5 = '%s'", md5);
//删除storage的文件
char cmd[1024*2] = {0};
sprintf(cmd, "fdfs_delete_file %s %s", fdfs_cli_conf_path, fileid);
}
八、分享文件
分享文件功能的实现的逻辑如下图所示:

这里也是主要展示下分享文件的代码逻辑:
(1)先判断此文件是否已经分享,判断集合有没有这个文件,如果有,说明别人已经分享此文件,中断操作(redis操作),直接返回前端信息
就是一个redis数据库的查询操作,不再展示了,麻了已经
(2)若redis没记录,mysql中有记录,
则先更新redis,再返回前端信息
(3)如果mysql中也没有此操作
则代表文件没有被分享
(4)共享操作
更新数据库,不展示了
九、更新文件下载计数
更新文件下载计数功能的实现的逻辑如下图所示: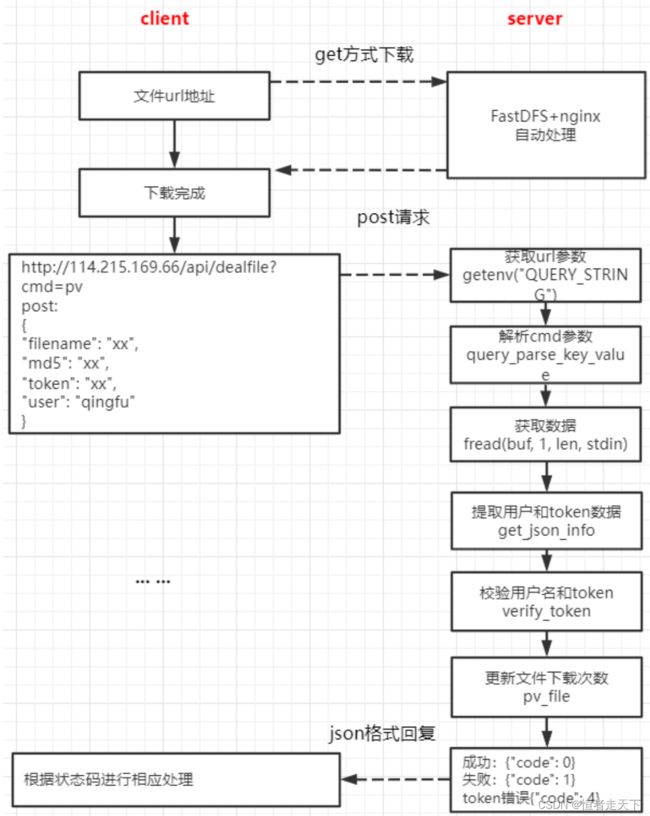
主要操作就是更新下user_file_list 用户个人文件列表的pv下载量
//查看该文件的pv字段
sprintf(sql_cmd, "select pv from user_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
//更新该文件pv字段,+1
sprintf(sql_cmd, "update user_file_list set pv = %d where user = '%s' and md5 = '%s' and file_name = '%s'", pv+1, user, md5, filename);
十、处理分享文件
功能逻辑图如下所示:
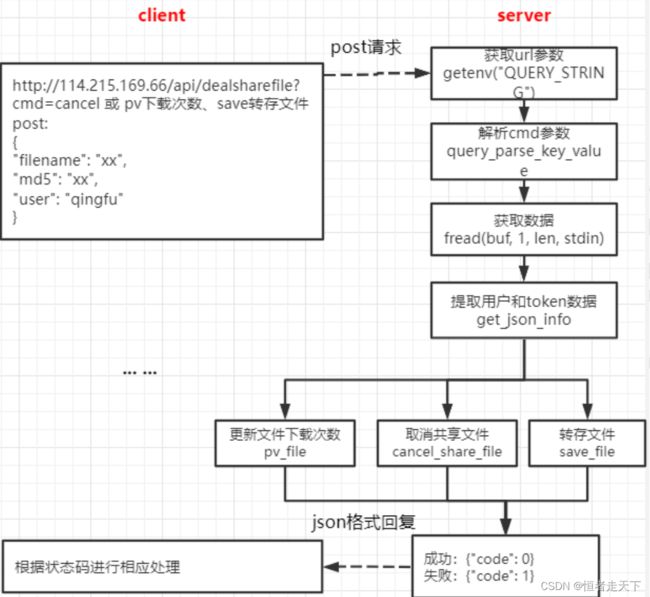
此模块主要包括三个功能:取消分享文件、转存文件、下载共享文件
取消分享文件
1.查询共享文件的数量 user_file_count
2.如果共享文件数量为 1 则删除共享文件数量对应的行
3.如果共享文件数量>1,则更新共享文件数量-1
4.将文件从 share_file_list 删除
5.将文件从 FILE_PUBLIC_ZSET 排行榜删除
代码如下:
/*这里只显示下sql语句的操作,对于操作数据库就不展示了,前面赘述太多了*/
//改变分享状态
sprintf(sql_cmd, "update user_file_list set shared_status = 0 where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
//查询共享文件数量
sprintf(sql_cmd, "select count from user_file_count where user = '%s'", "xxx_share_xxx_file_xxx_list_xxx_count_xxx");
if(count == 1)
{
//删除数据
sprintf(sql_cmd, "delete from user_file_count where user = '%s'", "xxx_share_xxx_file_xxx_list_xxx_count_xxx");
}
else
{
sprintf(sql_cmd, "update user_file_count set count = %d where user = '%s'", count-1, "xxx_share_xxx_file_xxx_list_xxx_count_xxx");
}
//删除在共享列表的数据
sprintf(sql_cmd, "delete from share_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
/*删除在redis中的操作*/
ret = rop_zset_zrem(redis_conn, FILE_PUBLIC_ZSET, fileid);
ret = rop_hash_del(redis_conn, FILE_NAME_HASH, fileid);
转载文件
1.查询在个人文件列表中是否已经存在该文件
2.增加 file_info 表的 count 计数,表示多一个人保存了该文件。
3.个人的 user_file_list 增加一条文件记录
4.更新个人的 user_file_count
//查看此用户,文件名和md5是否存在,如果存在说明此文件存在
sprintf(sql_cmd, "select * from user_file_list where user = '%s' and md5 = '%s' and file_name = '%s'", user, md5, filename);
//文件信息表,查找该文件的计数器
sprintf(sql_cmd, "select count from file_info where md5 = '%s'", md5);
//1、修改file_info中的count字段,+1 (count 文件引用计数)
sprintf(sql_cmd, "update file_info set count = %d where md5 = '%s'", count+1, md5);
//用户文件列表
sprintf(sql_cmd, "insert into user_file_list(user, md5, create_time, file_name, shared_status, pv) values ('%s', '%s', '%s', '%s', %d, %d)", user, md5, time_str, filename, 0, 0);
下载共享文件
1.更新 share_file_list 的 pv 值
2.更新 redis 里的 FILE_PUBLIC_ZSET,用作排行榜
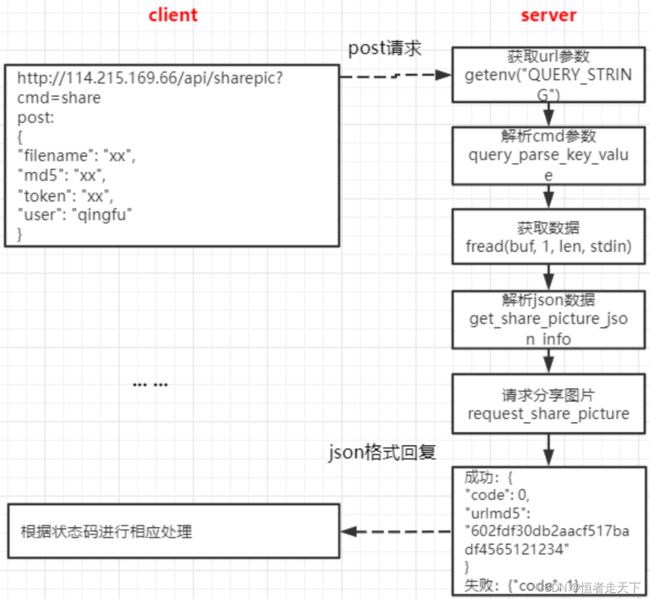
十一、图床分享图片
图片分享
功能逻辑图如下所示: