浅谈CompCert:经过形式化验证的可信编译器
前言:当前,复杂而泛在的软件架构支撑着全球经济,编译器和计算机高级语言正是这些软件的基石。编译器作为产生代码的工具,在加强计算机安全方面扮演着至关重要的角色。对于安全关键领域的系统软件而言,必须考虑编译器引入的错误,否则高成本的源程序级验证工作可能在目标程序级失效[1]。
保证编译器正确性的传统方法是进行大量的测试,但测试用例覆盖范围的不完全性使得编译器中的错误可能被遗漏,且无法保证编译器自身的正确性。对编译器的正确性进行验证是解决问题的根本途径,其中最为严格的验证手段莫过于采用形式化方法。经过形式化验证的CompCert编译器正是可信编译器的杰出代表。
CompCert可用于编译“生命关键型”和“任务关键型”软件,几乎完全支持ISOC 2011,ISOC 1999和ANSIC语言标准,支持PowerPC、ARM、x86和RISC-V架构,性能优于GCC(-O1)。
CompCert编译器的源语言为CompCert C,是C语言的大子集(几乎是完整的ISO C99)。与其他编译器的不同之处在于,CompCert编译器通过机器辅助的数学证明,验证了自身不存在误编译问题。换句话说,其产生的可执行代码与C语言源码语义指定的行为完全一致。
使用CompCert编译器是对在源代码级应用形式化验证技术(静态分析、程序证明、模型检查等)的自然补充:CompCert编译器的正确性证明保证了所生成的可执行代码同样具备源代码上验证的所有安全属性。
01.你的编译器可信吗?
通常来讲,编译器是实现精细算法的复杂软件,确实可能存在bug,并可能导致一个正确的源程序中悄无声息地生成错误可执行代码。换句话说,一个有bug的编译器可能在其所编译的程序中插入bug——这种现象被称为“误编译”。
一些实证研究表明,许多编译器都存在误编译问题。1995年Nullstone C一致性测试套件官网中就曾提到:

2005年学者E. Eide和J. Regehr的报告中也曾提及C编译器出现的类似问题——易失性内存访问:

2011年的《Finding and understanding bugs in C compilers》对C编译器的测试情况进行了总结,再次发现了许多误编译问题:

对于非安全关键的“日常”软件来说,误编译可能不算是大问题:与源程序中已存在的错误相比,编译器引入的错误可以忽略不计。然而,对于安全关键型软件来说,情况则大不相同:此类软件往往与生命安全、关键基础设施或高敏信息息息相关,如存在误编译问题则可能导致难以承担的后果,必须通过复杂且成本高昂的验证工作来解决——例如对生成的汇编码进行额外的测试和代码审查。
除了安全问题外,误编译还会削弱使用工具对源程序进行辅助验证的有效性。越来越多软件的开发过程开始使用到如静态分析工具和模型检查工具等形式化验证工具,尽管高级的验证工具能够自动建立有价值的程序安全属性(如无数组访问越界问题、无算术溢出等运行时错误),但这些工具大多是在C语言源代码上运行的。一个存在bug的编译器可能使源码级形式化验证提供的安全保障失效,产生不正确的可执行文件,从而导致经过形式化验证的源程序崩溃或出现错误。
02.编译器的形式化验证
CompCert项目为误编译问题提出了一个基于数学的根本性解决方案:对编译器本身进行形式化、经工具辅助的验证。通过对编译器的源代码应用程序证明技术,可以用数学层面的确定性证明编译器产生的可执行代码的行为完全符合C语言源程序的语义规定,从而排除所有误编译的风险。
历史上对编译器进行验证的探索早已开始:第一个编译器正确性证明(用于将算术表达式转换为堆栈机)发布于1967年,自那时起,编译器验证便一直是许多学术研究的主题。CompCert项目一直致力于提供一个用于生产安全关键领域嵌入式系统软件的完整、可实现的、经过优化的编译器。
1.语义保持
CompCert的形式化验证包括证明以下定理:
对于所有源程序S 和编译器生成的代码C,如编译器应用于源程序S ,产生代码C且未报告编译错误,则C的可观察行为(observable behaviors)就翻译了一个S 允许的可观察行为,即“语义保持”。
2.什么是可观察行为?
简而言之,可观察行为包括程序的用户或其执行所在的物理世界能“看到”的关于程序行为的一切(除执行时间和内存消耗之外)。更准确地说,CompCert遵循的是ISO C标准,具体可见下列应用CompCert时出现的情况:
程序存在终止、执行两种状态:终止状态有正常终止(从主函数返回)、错误终止(遇到未定义行为,如整数除以0)。
所有对执行输入/输出的标准库函数的调用,如printf()或getchar()。
所有对volatile全局变量的读写访问。这些变量应用于内存映射的硬件设备,因此对其的任何读/写都被视为输入/输出操作。
因此,程序的可观察行为是对其所执行的所有输入/输出和易失性操作的跟踪,和其是否终止及如何终止(正常或发生错误时)的指示。
3.关于源码级验证,语义保持告诉了我们什么?
语义保持定理的一个简单推论如下:
- 假设Σ是一组可接受行为,表征了程序所需的安全或活性;
- 假设源程序S满足Σ:S所有可能的可观察行为都在Σ中;
- 进一步假设编译器应用于源程序S,生成代码C;
- 编译后的代码C满足Σ:C的可观察行为都在Σ中。
可靠的源码级验证工具的目的在于建立一个规范Σ(对源程序S所有可能的执行都适用)。这个规范可以由用户定义,例如作为前置条件和后置条件;或者由工具确定,例如不存在运行时错误。因此,一个经过形式化验证的编译器能够保证:如果一个可靠的源码级验证工具确认程序满足所用规范,那么真正执行的编译代码也满足这个规范。
换句话说,只要在源程序上建立的“保证”延续到最后实际执行的编译代码,使用经过形式化验证的编译器就可以证明对源码级的验证是正确的。
4.如何进行语义保持的证明?
由于优化编译器固有的复杂性,其语义保持的证明是一项重大工作:
将其分成15个独立的语义保持证明,每一个都在CompCert编译器中进行验证。最终的语义保持定理来自这些单独证明的组合。对于每一次遍历,必须证明对【所有可能的输入程序】和【输入程序所有可能的执行】都保持语义不变(根据输入操作的不可预测结果,可能存在许多这样的执行)。
为此,需要考虑程序执行过程中每一个可能的可达状态,以及形式语义下该状态可执行的每一个转换。语义保持的证明利用了编程语言的归纳结构:例如,为证明复合表达式a+b被正确编译,通过归纳假设,假定两个较小的子表达式a和b被正确编译,然后将这些结果基于“+”运算符相结合。
以上过程如果用纸笔来进行编译证明,可能要写几百页——极少有数学家愿意进行验证,而现今可以利用计算机的强大功能:CompCert最突出的特点就是其大部分实现是在证明辅助器Coq环境中完成的,并且除词法分析和某些预处理过程外,各个翻译阶段均在Coq中实现了正确性证明[1]。
5.形式化编译器验证的有效性如何?
CompCert工作目前仍在进行中,还未实现完整的、端到端的形式化验证:目前,约90%的编译器算法(包括所有优化和代码生成算法)已在Coq中被证明是正确的,但其余10%(包括精化、预处理、汇编和链接)还未得到验证,将在未来得到改善。尽管如此,与普通编译器相比,这种不完全的形式化验证已经显示出了正确性上的重大改进。《Finding and understanding bugs in C compilers》中提到:

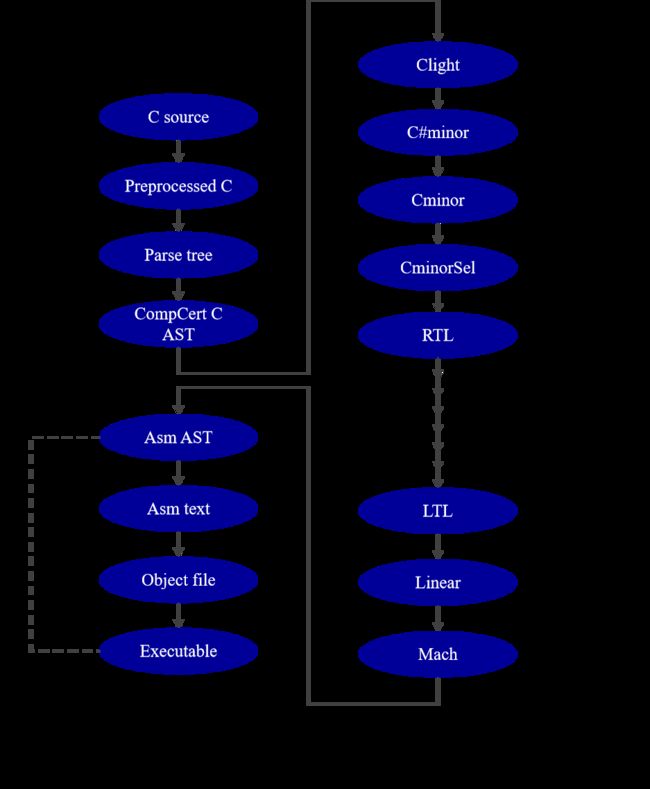
▲CompCert编译器架构
03.CompCert在实践中的应用
1.CompCert提供下列架构的代码生成器
- 32位和64位的PowerPC;
- 32位ARM v6、v7和v8,带VFP协处理器;
- 64位ARM v8(AArch64架构);
- 32位和64位的x86(IA32/AMD64),在32位模式下需要SSE2扩展;
- 32位和64位的RISC-V,分别采用ILP32D和LP64D的调用约定。
注:CompCert在某些情况下可能会使用浮点寄存器,除非指定选项-fno-fpu。
每个架构支持的应用二进制接口(ABI)和操作系统情况如下:

2.CompCert具备良好的代码生成性能

▲在Power7处理器上CompCert与GCC 4.1.2生成的代码性能比较
注:线条越短代表性能越强。基线(蓝色)为未经优化的GCC,红色为CompCert。
04.总结
近年来,有关编译器形式化验证的研究工作已取得长足的进步,达到了实用化水平,为未来制定新的工业标准奠定了强有力的基础。CompCert编译器作为经过形式化验证的可信编译器杰出代表,达到了人们所能期望的最高可信程度。关于Csmith的研究工作表明:CompCert在正确性方面的表现明显优于常用的开源或商用C语言编译器。
L2C可信编译器的开发始于2010年9月,采用类似于CompCert编译器的方法,以扩展的Lustre语言作为源语言, 以CompCert的Clight作为目标语言, 验证方面与CompCert完全对接。
建模仿真与代码生成软件ModelCoder采用L2C可信编译器,支持基于模型的嵌入式系统设计、仿真与可信代码自动生成,用户在开发早期便可基于虚拟模型进行持续测试和验证,适用于无线通信、电力电子、控制系统、信号处理等领域。
参考链接
[1] 杨萍,王生原. CompCert编译器目标代码生成机制分析[J]. 计算机科学, 2020, 47(9):7.
[2] https://compcert.org/man/manual001.html
[3] https://blog.csdn.net/xsx_6361/article/details/117519601