YOLO | 用YOLOv7训练自己的数据集(超详细版)
一、环境设置
本文环境设置:Ubuntu (docker) pytorch-gpu
1.远程Ubuntu新建一个新的docker 容器
以下命令是创建一个名称为torch_yolo的gpu容器。如果没有docker可省略。
docker run -it -e /home/elena/workspace:/home/elena/workspace --gpus all --ipc host --net host --name torch_yolo pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel /bin/bash更新并安装git,wget命令
apt-get update
apt-get install git
apt-get install wget
apt-get update2.(可选择)在Ubuntu上直接运行
省略docker的部分,就是Ubuntu上运行的操作(下载的库与docker稍微有些差异)。
3.(可选择)在Windows上运行
在github上下载压缩包,然后解压,配置数据集然后训练。(可参考我之前做过的YOLOv5流程)
二.克隆项目配置库
git clone https://github.com/WongKinYiu/yolov7打开项目下载要求的库:
cd yolov7
pip install -r requirements.txt
安装docker版本的OpenCV,直接安装pip install opencv-python会出错
pip install opencv-python-headless
下载YOLOV7的权重
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
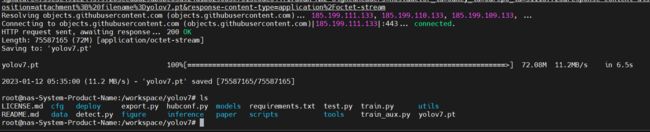
下载YOLOV7的训练权重
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7_training.pt
新建一个权重文件夹,把上述文件移到权重文件夹下
mkdir weights
cp yolov7.pt weights/
cp yolov7_training.pt weights/ 下载好了之后,得到两个权重文件。接下来,就是直接进行测试了。现在我们在./yolov7/这个工作路径下,输入如下命令.
检测代码
python detect.py --weights weights/yolov7.pt --source inference/images(如果出错,可参考【PS3】)
结果
如果得到如下的运行结果,则说明运行成功,预测的图片被保存在了/runs/detect/exp/文件夹下

参数说明
--weights weight/yolov7.pt # 这个参数是把已经训练好的模型路径传进去,就是刚刚下载的文件
--source inference/images # 传进去要预测的图片
输出的结果如上图~就配置好环境啦!!!
三、训练自己的数据集超详细设置
1. 准备工作
在data文件夹下新建datasets文件夹,把自己的数据都放进这个文件夹里进行统一管理。训练数据用的是yolo数据格式,不过多了.txt文件,是每个图片的路径,后面会具体介绍。
2. 准备yolo格式的数据
2.1. 创建文件夹
mkdir datasets得到如下的结果

2.2. 准备yolo格式数据集
自己的数据集可能格式不同操作不同。
我的数据集是一个文件夹下,子目录文件名是类别名,一个类别名下有放照片,一个类别名json名下放照片对应的json文件。遍历文件夹,移动代码
#move jsonfiles
#OriPath = '/workspace/data/train' #需要遍历的文件夹
OriPath="/workspace/data/val"
key='json'
for root, dirs, files in os.walk(OriPath, topdown=False):
for name in files:
#print(os.path.join(root, name))
filepath=os.path.join(root, name)
path1="/workspace/data/jsonfile" #存放文件的文件夹
#path1="/workspace/data/val" #存放文件的文件夹
movepath=os.path.join(path1,name)
if key in name:
#shutil.copyfile(filepath,movepath)
shutil.move(filepath,movepath)
#move images
OriPath = '/workspace/data/train' #需要遍历的文件夹
#OriPath="/workspace/data/tests"
key='.jpg'
for root, dirs, files in os.walk(OriPath, topdown=False):
for name in files:
#print(os.path.join(root, name))
filepath=os.path.join(root, name)
path1="/workspace/data/images" #存放文件的文件夹
movepath=os.path.join(path1,name)
if key in name:
#shutil.copyfile(filepath,movepath)
shutil.move(filepath,movepath)
*只需要修改路径名称,注意为了节省空间是移动,不是复制,移动后原文件夹下的文件就为空。
我的处理方法是,遍历文件夹下所有照片移动到image文件夹,遍历文件夹下所有json文件到label文件夹。
现在label下全部是批量.json文件,需要将json文件提取yolo所需要的四点信息,代码如下
json2txt.py
import json
import os
import time
from pathlib import Path
def json2txt(path_json, path_txt):
with open(path_json, 'r', encoding='utf-8') as path_json:
jsonx = json.load(path_json)
filename = path_txt.split(os.sep)[-1]
with open(path_txt, 'w+') as ftxt:
for shape in jsonx:
try:
x = shape['Point(x,y)'].split(',')[0]
y = shape['Point(x,y)'].split(',')[1]
label = shape["Label"]
w = shape["W"]
h = shape["H"]
strxy = ' '
ftxt.writelines(str(label) + strxy + str(x)+ strxy + str(y) + strxy + str(w) + strxy + str(h) + "\n")
except:
print(path_json)
continue
# Input json file path
jpath = Path('/workspace/yolo/data/dataset/f001json')
# Output txt file path
dir_txt = '/workspace/yolo/data/dataset/labels/'
if not os.path.exists(dir_txt):
os.makedirs(dir_txt)
for p in jpath.rglob("*.json"):
path_txt = dir_txt + os.sep + str(p).split(os.sep)[-1].replace('.json', '.txt')
json2txt(p, path_txt)
*需要注意的是自己json文件内的数值是归一化后的值还是没做归一化的值!我的代码是x,y,w,h是归一化后的值。
其中images和labels的名称需要一一对应,labels为.txt文件
label格式为五个归一化的数据:label、x_center、y_center、width、height
label_index :为标签名称在标签数组中的索引,下标从 0 开始。
x_center:标记框中心点的 x 坐标,数值是原始中心点 x 坐标除以 图宽 后的结果。
y_center:标记框中心点的 y 坐标,数值是原始中心点 y 坐标除以 图高 后的结果。
width:标记框的 宽,数值为 原始标记框的 宽 除以 图宽 后的结果。
height:标记框的 高,数值为 原始标记框的 高 除以 图高 后的结果。
输出后txt文件示例如图

2.3.分割为train,val和test文件夹,并生成自己文件的train.txt,val.txt和test.txt
YOLO需要的格式如图:自己的数据集分割,数据处理后得到yolo格式数据集,存放格式如下。

接下来,就是生成 train.txt,test.txt和val.txt。train.txt存放了所有训练图片的路径,val.txt则是存放了所有验证图片的路径,test.txt存放了所有测试图片的路径,(代码统计原数据集的长度,按照比例进行分割)
# insanena
import shutil
import random
import os
# 原始路径
image_original_path = "/workspace/yolo/data/dataset/food38img/"
label_original_path = "/workspace/yolo/data/dataset/labels/"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/images/train/")
train_label_path = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/images/val/")
val_label_path = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/images/test/")
test_label_path = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/train.txt")
list_val = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/val.txt")
list_test = os.path.join(cur_path, "/workspace/yolo/data/dataset/food38yolo/test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("TrainNum:{}, ValNum:{}, TestNum:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpg'
srcLabel = label_original_path + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
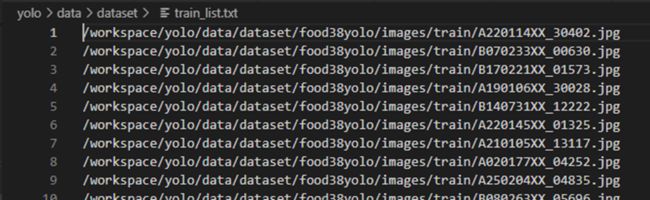
main()train.txt文件存放的是图片路径
2.4.制作自己的配置文件
一共修改俩个配置文件
一个是yolov7-mydataset.yaml,位置在项目yolov7/cfg/training下,然后复制yolov7.yaml改为yolov7-mydataset.yaml,然后修改类别数,就得到一个新的属于自己的配置文件。
(在这里我的数据集是food38,类别数是38个)
如图所示
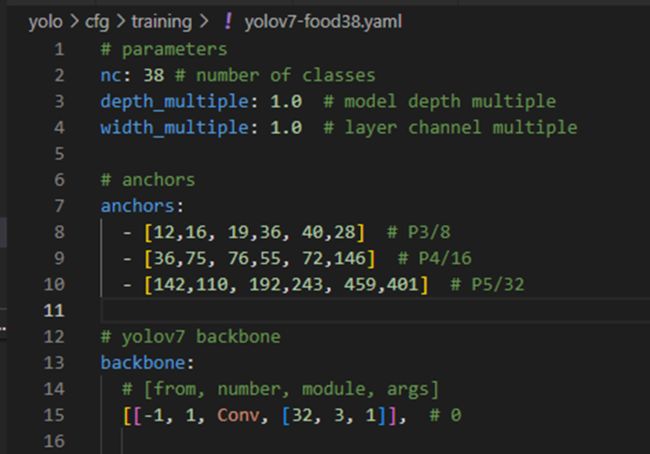
代码如下(可以直接复制)
# parameters
nc: 38 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
*只改变nc的数,也就是自己数据集的类别数(标签数)
另外一个是mydataset.yaml,位置在项目yolov7/data/mydataset下,内容如下
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /workspace/yolo/data/dataset/food38yolo/train.txt
val: /workspace/yolo/data/dataset/food38yolo/val.txt
test: /workspace/yolo/data/dataset/food38yolo/test.txt
# number of classes
nc: 38
#标签名称
names: ["#我有38个,这里省略"]
3. 准备训练
(我中间一共训练了俩个数据集,所以代码可能会有一点点区别,但是把修改后的文件在train.py中改下名称就可以)
train常用参数有:
--weights: 预训练路径,填写'' 表示不使用预训练权重
--cfg : 参数路径(./cfg/training中新建的yolov7-mydataset.yaml文件,见上文②)
--data : 数据集路径(./data中新建的mydayaset.yaml文件,见上文①)
--epochs : 训练轮数
--batch-size : batch大小
--device : 训练设备,cpu-->用cpu训练,0-->用GPU训练,0,1,2,3-->用多核GPU训练
--workers: maximum number of dataloader workers
--name : save to project/name需要修改的train.py位置
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/kf-data/dataset/food38.yaml', help='data.yaml path')
指定参数的训练命令
python train.py --workers 8 --device 0 --batch-size 32 --data data/dataset/data.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights 'yolov7_training.pt' --name yolov7-custom --hyp data/hyp.scratch.custom.yaml开始训练

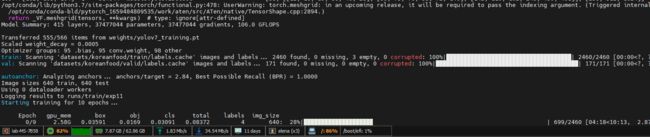
4.训练结果
输出训练目录
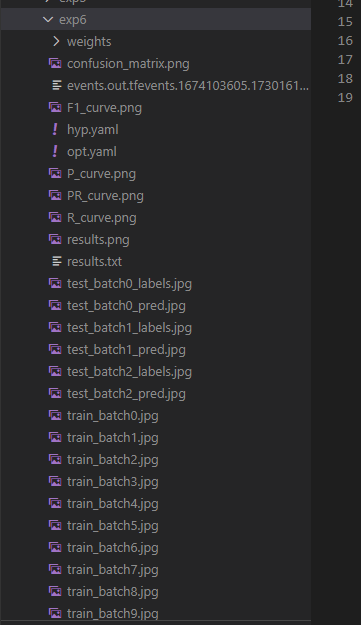
参数详解
confusion_matrix.png 混淆矩阵图
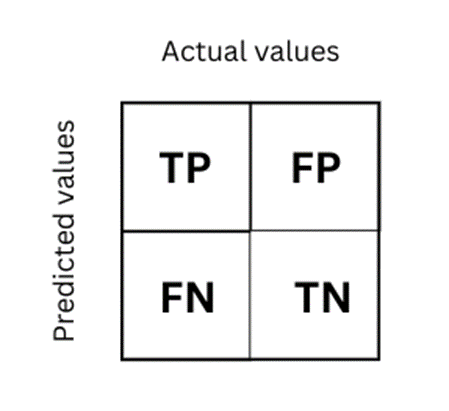
混淆矩阵以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
TP(True Positive): 将正类预测为正类数 即正确预测,真实为0,预测也为0
FN (False Negative):将正类预测为负类 即错误预测,真实为0,预测为1
FP(False Positive):将负类预测为正类数 即错误预测, 真实为1,预测为0
TN (True Negative):将负类预测为负类数,即正确预测,真实为1,预测也为1
精确率和召回率的计算方法
精确率Precision=TP / (TP+FP), 在预测是Positive所有结果中,预测正确的比重
召回率recall=TP / (TP+FN), 在真实值为Positive的所有结果中,预测正确的比重
F1_curve.png

F1分数,它被定义为查准率和召回率的调和平均数
一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
F1-Score的值是从0到1的,1是最好,0是最差。
hyp.yaml 训练时的超参数
opt.yaml train.py中间的参数
P_curve.png 准确率precision和置信度confidence的关系图
PR_curve.png
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map.
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
Precision和Recall往往是一对矛盾的性能度量指标;及一个的值越高另一个就低一点;
提高Precision <==> 提高二分类器预测正例门槛 <==> 使得二分类器预测的正例尽可能是真实正例;
提高Recall <==> 降低二分类器预测正例门槛 <== >使得二分类器尽可能将真实的正例挑选
R_curve.png 召回率recall和置信度confidence之间的关系
results.png
Box:Box推测为GIoU损失函数均值,越小方框越准
Objectness:推测为目标检测loss均值,越小目标检测越准
Classification:推测为分类loss均值,越小分类越准
Precision:精度(找对的正类/所有找到的正类)
Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少)。
Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
val BOX: 验证集bounding box损失
val Objectness:验证集目标检测loss均值
val classification:验证集分类loss均值,本实验为一类所以为0
mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
[email protected]:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
[email protected]:表示阈值大于0.5的平均mAP
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
然后观察[email protected] & [email protected]:0.95 评价训练结果。
results.txt 分别的含义是训练次数、GPU消耗、训练集边界框损失、训练集目标检测损失、训练集分类损失、训练集总损失、targets目标、输入图片大小、Precision、Recall、[email protected]、[email protected]:.95、验证集边界框损失、验证集目标检测损失、验证机分类损失
train_batch
设置的batch_size为多少,所以一次读多少张图片
test_batchx_labels
验证集第一轮的实际标签(只有完全训练完后才会出现test)
如果运行tensorboard
activate yolov7(自己所配的环境名称)
tensorboard --logdir=训练结果所在的文件夹【总结】
第一次训练时,在ymal文件中未设置train_list.txt和val_list.txt,可以训练,未提示错误,yaml文件如下,数据是从roboflow网站上上下载好的格式(不是自己的数据集),大家有需要的可以在网站上找到需要的数据集,而且可以直接下载想要的格式。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /workspace/yolov7/data/dataset/f001yolo/train/
val: /workspace/yolov7/data/dataset/f001yolo/val/
# test: /workspace/yolov7/data/dataset/f001yolo/test/
# number of classes
nc: 38
# class names
names: [#这里省略]
个人认为默认指向路径下的图片,具体原因还在研究中。。。
yolov7训练时的出来labels指的是什么,为什么每一个epoch的标签数都不同?
3.yaml配置文件如何进行配置?
yaml文件通常也是用于保存参数,在主函数中用来调用,yaml文件是一个层级结构,以字典形式调用 yaml文件,在yolov7中我们一共修改了俩个ymal文件,一个是网络结构,一个是数据集的类别数和类别名,还有数据传入路径。
在读取yaml文件时,先将yaml文件里面的内容全部用系统函数读入,然后用yaml.safe_load进行加载,转换成一个字典,返回字典供后续使用,调用的时候就根据yaml文件里面的结构层次按键值对进行调用。在yolo中,yaml与argparse混合使用,
yaml首先可以将全部参数都设置一个默认值,比如网络的层数,激活函数用哪个等等,大多是模型内相关的参数以及train和test使用的数据的地址。
argparse通常设置几个train和test时经常更改的参数,比如训练的epoch,batch_size,learning_rate...
argparse接收的是命令行的输入,所以优先级应该是会高一些;假如argparse和yaml文件中都有相同的参数,如果命令行指定了参数,那么代码运行时使用的参数是命令行输入的参数。
过程中遇到的问题及解决PS
[PS1]来自守护进程的错误响应,创建shim任务失败
OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: 自动检测模式为'legacy'。
nvidia-container-cli:初始化错误:nvml错误:驱动程序未加载:未知
错误:未能启动容器
原因分析:开始是好用的,在服务器上设置可视化后不好使,可能是nvidia原因

是存在的。
解决办法:重新设置了nvidia后就好使啦~
[PS2]RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERROR

尝试方法:
调小batchsize
查看gpu设置数量(默认为2个)
尝试
CUDA_VISIBLE_DEVICES=1 python train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7-koreanfood.yaml --data koreanfood.yaml --device 0 --epoch 10[PS3]OSError: [Errno 28] No space left on device: 'runs/train/exp9'
在Linux服务器运行程序的时候,运行完一个epoch后就会出现这个报错OSError: [Errno 28] No space left on device就是说系统的空间不足。
训练过一次后出现的磁盘占用问题,应该是缓存区满,清除缓存
查看系统空间的使用情况:
df -h
overlay:
可以看到其中有一个文件夹已经占用100%了,所以提示空间不足。
解决办法就是删除掉文件夹内的一些东西即可。
查看当前目录空间的占用:
du -sh /workspace/* |grep G
查看各目录的占用空间情况,可以删除掉一些高占用且不使用的文件,释放空间:
du -h -x --max-depth=1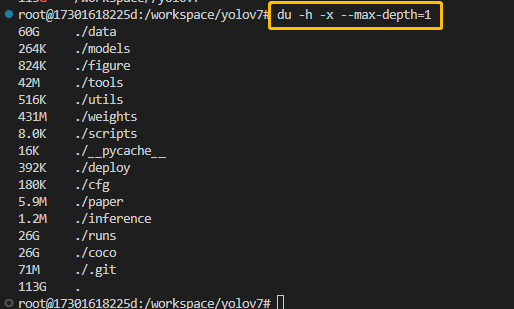
data文件夹下占用最多
再进入data下,看看哪些文件夹占用比较多:
这些都是在运行过程中保存的一些权重文件和过程文件,导致程序运行次数过多,产生的过程文件就越多,因而占用了较多的空间,删除掉一些不需要的文件夹即可。
也可以使用命令删除不需要的文件夹:
rm -rf ./coco*因为我是在容器内运行的环境,容器默认框架为ubuntu,默认空间为
*上述命令是删除文件夹下的所有文件,

删除后./coco下所有文件都不存在。
深度模型运行时,占用的是磁盘还是内存还是上面?
[PS4] RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
利用训练好新的权重,拿新的照片用来用来推理时出现错误,可能是直接用保存的模型出错。
原因
模型训练的时候pytorch版本与目前使用的pytorch版本不一致,不能很好的兼容。
原来模型损坏。
解决办法
用目前版本的pytorch重新训练模型。
重新复制一份模型。
[PS5] AttributeError: partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline' (most likely due to a circular import)
版本问题,降低版本,安装
pip install opencv-python-headless==4.5.5.64然后就好使啦~(*我是docker容器环境,不是利用原服务器跑的)
[PS6] 图片标签不显示中文/韩语

依次点击utils->plots.py
找到画框位置源代码(大约在71行附近)
def plot_one_box_PIL(box, img, color=None, label=None, line_thickness=None):
img = Image.fromarray(img)
draw = ImageDraw.Draw(img)
line_thickness = line_thickness or max(int(min(img.size) / 200), 2)
draw.rectangle(box, width=line_thickness, outline=tuple(color)) # plot
if label:
fontsize = max(round(max(img.size) / 40), 12)
font = ImageFont.truetype("Arial.ttf", fontsize)
txt_width, txt_height = font.getsize(label)
draw.rectangle([box[0], box[1] - txt_height + 4, box[0] + txt_width, box[1]], fill=tuple(color))
draw.text((box[0], box[1] - txt_height + 1), label, fill=(255, 255, 255), font=font)
return np.asarray(img)修改font = ImageFont.truetype("Arial.ttf", fontsize)为
font = ImageFont.truetype("FONT_PATH", fontsize) 不管用
修改
matplotlib.rc('axes', **{'size': 11})不管用
在plots.py添加如下代码(位置随意)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False添加后图片上是问号,终端输出文字正常~
[PS7]_pickle.UnpicklingError: STACK_GLOBAL requires str
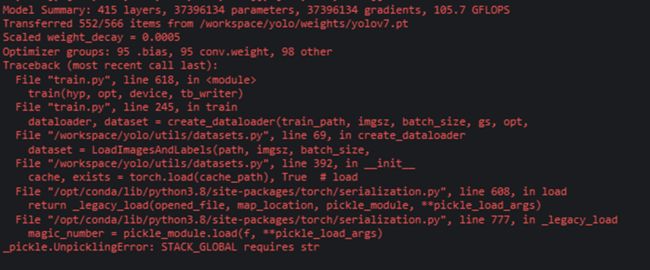
产生原因:在过去对当前数据集进行过训练,导致在数据集文件夹中生成了.cache的缓存文件
解决办法:找到数据集文件夹中的全部.cache文件,并将他们全部删除

如图的 train.cache和val.cache
注意:.cache文件也有可能在数据集的images和labels文件夹中,要注意仔细查找
如果是在Linux下操作可以尝试如下命令:
cd 数据集文件夹
rm *.cache
批量删除全部缓存文件。
[PS8]RuntimeError: CUDA out of memory. Tried to allocate 26.00 MiB (GPU 0; 23.65 GiB total capacity; 4.35 GiB already allocated; 14.44 MiB free; 4.40 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
错误描述:深度学习训练突然停止了,所以关掉训练,再次训练后出现以上错误。
查看GPU使用,指令 nvidia-smi 查看如下
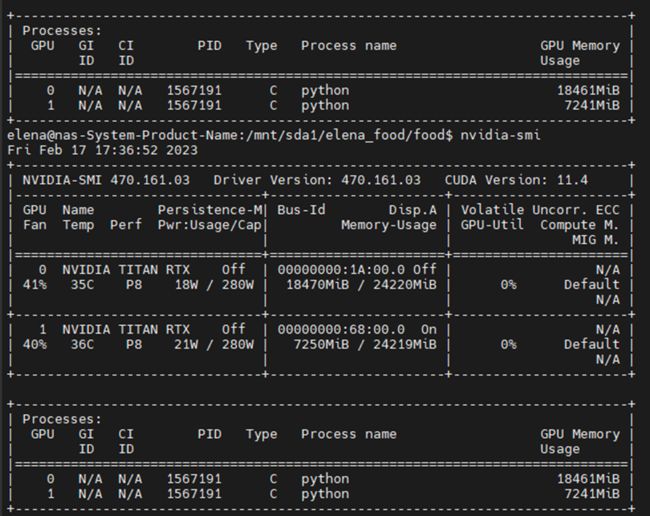
GPU显示一直占用。
解决办法:杀死进程指令 kill -9 (pid如图我的是1567191)
因为我不是root,所以 sudo kill -9 1567191

然后就可以啦~
附录
从创建容器到训练的所有代码
#创建容器 yolov7
nvidia-docker run --name yolov7 -it -v /home/elena/workspace:/workspace/ --shm-size=64g nvcr.io/nvidia/pytorch:21.08-py3
#(可选择)创建容器 gan_pro
docker run --name gan_pro --gpus all -it -v /home/elena/workspace:/workspace/ --shm-size=64g nvcr.io/nvidia/pytorch:21.08-py3
apt update
apt install -y zip htop screen libgl1-mesa-glx
pip install seaborn thop
git clone https://github.com/WongKinYiu/yolov7
cd yolov7
pip install -r requirements.txt
#卸载一般的OpenCV
pip uninstall opencv-python
#安装docker版本OpenCV
pip install opencv-python-headless==4.5.5.64
apt-get install build-essential cmake
apt-get install libgtk-3-dev
apt-get install libboost-all-dev
pip install dlib
pip install pkg-config
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source
#下载 cocodata ,并进行测试(会比较慢)
python test.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights yolov7.pt --name yolov7_640_val
#如果用自己的数据集训练的情况
#新建一个存放权重文件夹
mkdir weights
#下载训练预训练模型
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7_training.pt
#修改超参数设置
#训练自己的数据集
python train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7-kf.yaml --data data/kf-data/kf.yaml --device 0,1 --batch-size 32 --epoch 10
#用训练后的权重再次训练
python train.py --weights weights/best.pt --cfg cfg/training/yolov7-kf.yaml --data data/kf-data/kf.yaml --device 0,1 --batch-size 32 --epoch 300
#推理,记得更换训练后权重
python detect.py --weights weights/best.pt --source inference/food

/mnt/sda1/건강관리를 위한 음식 이미지/Training
docker cp [라벨]음식001_Tra_json.zip yolov7:/workspace/yolov7/data/dataset/
docker cp [원천]음식001_Tra.zip yolov7:/workspace/yolov7/data/dataset/
unzip f001json.zip -d f001json
修改2个ymal文件,一个指向数据集的照片位置,一个指向数据集的标签位置
需要修改的超参数位置
parser.add_argument('--weights', type=str, default='weights/yolo7.pt', help='initial weights path')
parser.add_argument('--data', type=str, default='data/kf-data/data.yaml', help='data.yaml path')
参考文献
[1]【小白教学】如何用YOLOv7训练自己的数据集 - 知乎 (zhihu.com)
[2]【YOLOv5 数据集划分】训练和验证、训练验证和测试(train、val)(train、val、test)_daybrek的博客-CSDN博客
[3]yolov7模型训练结果分析以及如何评估yolov7模型训练的效果_yolo训练结果_把爱留给SCI的博客-CSDN博客
[4]YOLOv7中的数据集处理【代码分析】_爱吃肉的鹏的博客-CSDN博客
[5]YoloV7训练最强操作教程._魔鬼面具的博客-CSDN博客_yolov7教程