堆(二叉堆)-优先队列-数据结构和算法(Java)
文章目录
-
- 1 概述
-
- 1.1 定义
- 1.2 二叉堆表示法
- 2 API
- 3 堆相关算法
-
- 3.1 上浮(由下至上的堆有序化)
- 3.2 下沉(由上至下的堆有序化)
- 3.3 插入元素
- 3.4 删除最大元素
- 4 实现
- 5 性能和分析
-
- 5.1 调整数组的大小
- 5.2 元素的不可变性
- 6 简单测试
- 6 后记
1 概述
1.1 定义
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
堆是非线性数据结构,相当于一维数组,有两个直接后继。
堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。
k i ≤ k 2 i 且 k i ≤ k 2 i + 1 或 者 k i ≥ k 2 i 且 k i ≥ k 2 i + 1 , i = [ 1 , n 2 ] k_i\le k_{2i}且k_i\le k_{2i+1}或者k_i\ge k_{2i}且k_i\ge k_{2i+1},i=[1,\frac{n}{2}] ki≤k2i且ki≤k2i+1或者ki≥k2i且ki≥k2i+1,i=[1,2n]
若将和此次序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。由此,若序列{k1,k2,…,kn}是堆,则堆顶元素(或完全二叉树的根)必为序列中n个元素的最小值(或最大值)。
1.2 二叉堆表示法
一个堆有序的完全二叉堆,如下图1.2-1所示: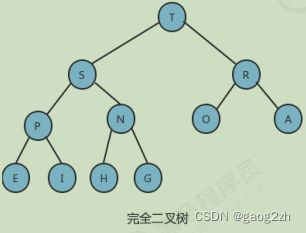
它通常用数组实现,用数组表示与堆的对应关系,如下图1.2-2所示: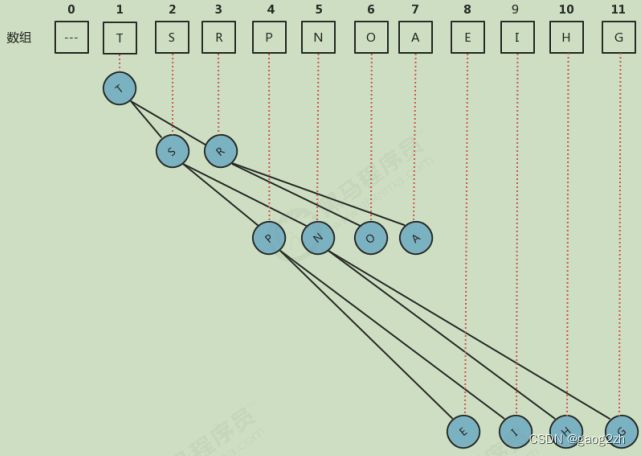
在一个堆中,位置 k k k的结点的父结点的位置为 k 2 \frac{k}{2} 2k,而它的左子结点和右子结点位置分别为 2 k 和 2 k + 1 2k和2k+1 2k和2k+1。这样在不使用指针的情况下我们可以通过计算数组的索引在树中移动:从 a [ k ] a[k] a[k]向上一层令 k = k 2 k=\frac{k}{2} k=2k,向下一层令 k = 2 k 或 者 2 k + 1 k=2k或者2k+1 k=2k或者2k+1。
命题P:一棵大小为N的完全二叉树的高度为 ⌊ lg N ⌋ \lfloor \lg N\rfloor ⌊lgN⌋。
证明:通过归纳法很容易证明,切当N为2的幂时,高度+1。
2 API
public class HeapPriorityQueue<E extends Comparable<E>> implements Queue<E>, Serializable
继续沿用了队列接口API,类新增方法和成员变量如下:
-
成员变量
访问修饰和类型 名称 描述 private final E[] table 存放元素容器 private int size 元素个数 private final Comparator comparator 比较器 -
方法
访问修饰和返回类型 名称 描述 public HeapPriorityQueue(int) 构造器 public HeapPriorityQueue(int, Comparator ) 构造器 private void exch(int,int) 交换元素位置 private boolean less(int, int) 比较指定位置2个元素的大小 private void swim(int k) 指定位置的元素上浮 private void sink(int) 指定位置的元素下沉
3 堆相关算法
我们用size+1的私有数组table表示一个大小为size的堆,不使用table[0],堆元素存放在[1,size]中。在排序算法中,使用less()和exch()来访问数组元素,通过传递索引而不是数组作为参数。堆的某些操作可能打破堆的状态,我们需要按照堆的性质将堆恢复,这个过程称为堆的有序化。
在有序化的过程中可能遇到两种情况。当某个结点的优先级上升(或者堆底加入一个新元素)时,我们需要由下至上恢复堆的顺序。当某个结点的优先级下降(或者根结点替换为一个较小的元素)时,我们需要由上至下恢复堆的顺序。
3.1 上浮(由下至上的堆有序化)
如果堆的有序状态因为某个结点变得比它的父结点大而打破,我们需要通过交换它和它的父结点的位置来修复堆。交换后,这个结点比它的两个子结点都大(一个是曾经的父结点,一个是曾经的父结点的子节点)。一遍遍重复这个操作,直至该结点不再大于它的父结点或者到堆顶。代码如下:
/**
* 上浮
* @param k 上浮元素索引
*/
private void swim(int k) {
while (k > 1 && less(k / 2, k)) {
exch(k / 2, k);
k = k / 2;
}
}
动态颜色图如下3.1-1所示:
3.2 下沉(由上至下的堆有序化)
如果堆的有序状态因为某个结点变得比它的任一子结点小而打破,我们需要通过交换它和它的较大的结点的位置来修复堆。交换后,这个结点的父结点比它的两个子结点都大。一遍遍重复这个操作,直至该结点的子结点都比它小或者到底堆底。代码如下:
/**
* 下沉
* @param k 下沉元素索引
*/
private void sink(int k) {
while (2 * k <= size) {
int j = 2 * k;
if (j < size && less(j, j + 1)) j++;
if (!less(k, j)) break;
exch(k, j);
k = j;
}
}
动态图如下3.2-1所示: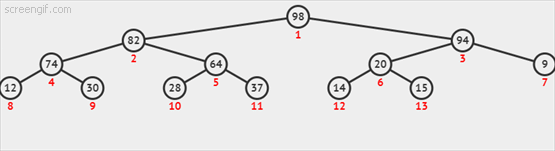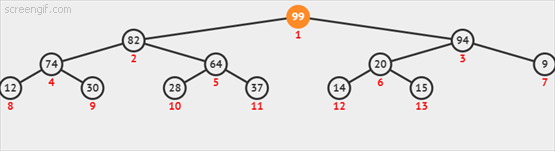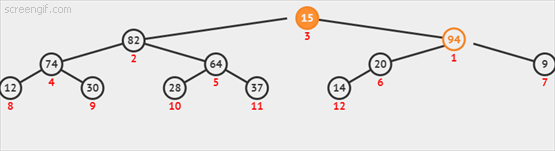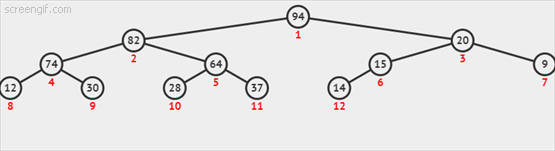
3.3 插入元素
我们把新元素添加到数组末尾,增加堆的大小并让它上浮到合适位置。
3.4 删除最大元素
我们从数组顶端删去最大元素并将数组最后一个元素放到顶端,减小堆的大小并让这个元素下沉到合适位置。
4 实现
完整代码如下4-1所示:
import java.io.Serializable;
import java.util.Comparator;
import java.util.Iterator;
import java.util.NoSuchElementException;
/**
* 堆
* 根据传入比较器,判断是最大堆还是最小堆
* 默认为最大堆
* (o1,o2) -> {o2.compareTo(o1)} 最小堆
*
* @author Administrator
* @date 2022-12-03 20:41
*/
public class HeapPriorityQueue<E extends Comparable<E>> implements Queue<E>, Serializable {
/**
* 存放元素容器
*/
private final E[] table;
/**
* 元素个数
*/
private int size;
/**
* 比较器
*/
private final Comparator<E> comparator;
/**
* 构造器
* @param initialCapacity 初始容量
*/
public HeapPriorityQueue(int initialCapacity) {
if (initialCapacity <= 0) {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
table = (E[]) new Comparable[initialCapacity + 1];
comparator = Comparable::compareTo;
}
/**
* 构造器
* @param initialCapacity 初始容量
* @param comparator 比较器
*/
public HeapPriorityQueue(int initialCapacity, Comparator<E> comparator) {
if (initialCapacity <= 0) {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
table = (E[]) new Comparable[initialCapacity + 1];
this.comparator = comparator == null ? Comparable::compareTo: comparator;
}
/**
* 插入元素
* @param e 元素
*/
@Override
public void offer(E e) {
if (size + 1 > table.length - 1) {
throw new IndexOutOfBoundsException();
}
table[++size] = e;
swim(size);
}
/**
* 返回堆顶元素
* @return 堆顶元素
*/
@Override
public E peek() {
return table[1];
}
/**
* 弹出堆顶元素
* @return 堆顶元素
*/
@Override
public E poll() {
if (size <= 0) {
throw new NoSuchElementException("堆为空");
}
E e = table[1];
table[1] = table[size--];
table[size + 1] = null;
sink(1);
return e;
}
/**
* 判断堆是否为空
* @return
*/
@Override
public boolean isEmpty() {
return size == 0;
}
/**
* 获取堆中元素个数
* @return 堆中元素个数
*/
@Override
public int size() {
return size;
}
/**
* 暂时不做实现
* @return
*/
@Override
public Iterator<E> iterator() {
return null;
}
/**
* 比较所有i,j出元素大小
* @param i 所有i
* @param j 索引j
* @return 所有i处元素小于索引j处元素返回true;否则返回false
*/
private boolean less(int i, int j) {
return comparator.compare(table[i], table[j]) < 0;
}
/**
* 交换元素
* @param i 索引i
* @param j 索引j
*/
private void exch(int i, int j) {
E t = table[i];
table[i] = table[j];
table[j] = t;
}
/**
* 上浮
* @param k 上浮元素索引
*/
private void swim(int k) {
while (k > 1 && less(k / 2, k)) {
exch(k / 2, k);
k = k / 2;
}
}
/**
* 下沉
* @param k 下沉元素索引
*/
private void sink(int k) {
while (2 * k <= size) {
int j = 2 * k;
if (j < size && less(j, j + 1)) j++;
if (!less(k, j)) break;
exch(k, j);
k = j;
}
}
}
5 性能和分析
命题Q:对于含有N个元素的基于堆的优先队列,插入元素只需要不超过 ( lg N + 1 ) (\lg N +1) (lgN+1)次比较,删除最大元素的操作需要不超过 2 lg N 2\lg N 2lgN次比较。
证明:有命题P可知,两种操作都需要在堆顶和堆顶之间移动元素,而路径的长度不超过 lg N \lg N lgN。对于路径上的每个结点,删除最大元素需要两次比较(除了堆底元素),一次用来找比较大的子结点,一次用来确定该子结点是否需要上浮。
5.1 调整数组的大小
我们可以在offer()中判断如果堆大小达到数组容量上限,根据一定的策略增大数组的容量;在poll()删除堆顶元素时,通过判断小于一定的值来缩减数组的容量。这样我们无需关注大小限制。同样低,命题Q指出的对数时间复杂度上限只是针对一般性的队列长度N而言了。
5.2 元素的不可变性
堆存储了用例创建的对象,但同时加锁用例代码不会修改它们。我们可以将这个假设转化为强制条件,但程序员一般不会这么做,因为增加代码的复杂性会降低性能。
6 简单测试
代码如下:
/**
* @author Administrator
* @date 2022-12-04 20:10
*/
public class HeapPQTest {
public static void main(String[] args) {
// 最大堆
// HeapPriorityQueue hpq = new HeapPriorityQueue<>(10);
// 最小堆
HeapPriorityQueue<Integer> hpq = new HeapPriorityQueue<>(10, (o1, o2) -> o2.compareTo(o1));
hpq.offer(3);
// System.out.println(hpq.isEmpty());
// System.out.println(hpq.size());
// System.out.println(hpq.peek());
hpq.offer(4);
hpq.offer(1);
hpq.offer(5);
hpq.offer(8);
hpq.offer(6);
hpq.offer(9);
int size = hpq.size();
System.out.println(size);
// System.out.println(hpq.peek());
for (int i = 0; i < size; i++) {
System.out.println(hpq.poll());
}
}
}
可以自己根据需要随意测试代码,如果发现bug最好。
6 后记
如果小伙伴什么问题或者指教,欢迎交流。
❓QQ:806797785
⭐️源代码仓库地址:https://gitee.com/gaogzhen/algorithm
[1][美]Robert Sedgewich,[美]Kevin Wayne著;谢路云译.算法:第4版[M].北京:人民邮电出版社,2012.10