初识C++之map和set
目录
一、关联式容器
二、键值对
三、set
1.set部分接口查看
1.1 类型
1.2 insert()插入
1.3 find()查找函数
1.4 count()查找一个数出现的次数
四、map
1.map中部分接口的查看
1.1类型
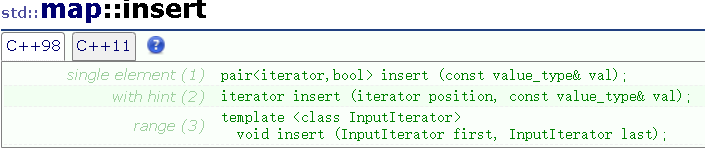
1.2 pair类
1.3 insert()插入函数
1.4 pair存在原因
1.5 运算符[]重载
2.multimap
五、set和map的模拟实现
1.修改红黑树
2.set和map的插入
2.1set
2.2 map
3.set和map的迭代器
3.1 红黑树的迭代器
3.2 set和map的迭代器
一、关联式容器
在我们以前所接触的STL中的部分容器,比如vector、list、deque等,都被称为序列式容器,因为它们底层为线性序列的数据结构,里面存储的是元素本身。与序列式容器相比,还有一种关联式容器。
关联式容器也是用来存储数据的,但与序列式容器不同的是,它里面存储的是键值对,在数据检索是比序列式容器效率更高。
但是,在序列式容器中,除非特殊限制,如deque,你可以在任意你想的位置插入数据。而关联时容器中,所有的数据都是按照一定规则进行排列分布的,不能随意修改。
二、键值对
键值对是用来标识具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value。key代表键值,value表示与key相对应的信息。比如在一个英汉互译的词典中,英文单词与其对应的中文含义就是一一对应的关系,可以通过该单词找到词典中对应的中文含义,这就是一种键值对。
三、set
set的底层就是一个平衡二叉搜索树,这也就意味着它的时间复杂度可以被看为O(longN)。查找效率非常高。
1.set部分接口查看
1.1 类型

set对象的类模板中,T为要插入的数据的类型,而less
1.2 insert()插入

与vector、list等不同,set的插入就不再使用push了,而是使用insert()来插入。
注意,set在插入时,会做两个工作,一个是排序,另一个则是去重。set的insert()在使用时,会默认按照从小到大的顺序构建一颗二叉搜索树;同时,在插入的时候还会判断树中是否存在相同元素,如果存在,则不插入;不存在,则插入。
因此大家看insert()的第一个接口就可以发现,它的返回值是“pair
1.3 find()查找函数
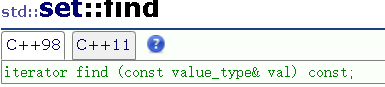
在set中,是默认提供了一个find()函数的。大家知道,在
原因就在于,库中提供的find()函数是采用暴力查找的方式搜索的,时间复杂度为O(N)。而set的底层是一个平衡二叉搜索树,因此可以根据这一特性,自行实现一个find()函数,其时间复杂度为O(longN)。
1.4 count()查找一个数出现的次数

count()函数可以用于返回一个数出现的次数。有人可能认为这个函数比较多余,因为在set中,是不允许键值冗余的,因此一个数在set中只会有0或1两种状态。既然如此,那么直接使用find()函数也可以达到相同的作用,这就显得count()很多余。
其实这一接口存在的原因并不是set,而是在“multiset”中。

在multiset中,是允许键值冗余的。因此,在这一容器中,一个数就可能存在多个,需要提供count()接口。而set和multiset又存在于同一头文件中,且其底层和set其实也是一样的,都是用的平衡二叉搜索树。为了保持这两个容器接口的一致性,便在set中也提供了count()。
注意,在 multiset中,因为它的查找顺序是中序查找,因此,当要删除一个multiset中的数据时,也是先删除的中序查找到的第一个数据,而不是层序遍历中最上层的那个数据。
其他的接口因为使用起来都很简单,所以就不再一一赘述。
四、map
map和set的底层其实都是平衡二叉搜素树,但是map和set不同,set的对象中只有一个key值,即二叉搜索树中的K模型;而map则是一个kv结构,即二叉搜索树中的kv模型。可以用一个键值来标识指定的内容
1.map中部分接口的查看
1.1类型

map的类型中的参数就和set不同,多了一个T。这个T其实就是value。
1.2 pair类

pair类其实就是一个封装好的kv模型的类,这个类里面有两个成员变量,分别是first和second。
![]()
这两个成员变量都是public修饰的,这个类的主要作用就是提供kv模型。一般我们喜欢让first代表key,second代表value。库中的平衡二叉搜索树中就是使用了这一kv模型。
1.3 insert()插入函数
因为map中的值是以kv模型来插入的,所以insert()在使用时,就与其他容器有所不同。在insert()传值中,必须要构造一个pair对象, 然后将这个对象作为参数传给insert():
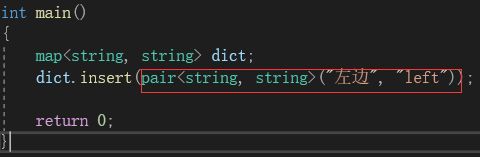
一般都是通过构造临时对象完成传值。但是,这种方法使用起来很麻烦。所以,在实际中,更喜欢使用make_pair()来完成构造传值::
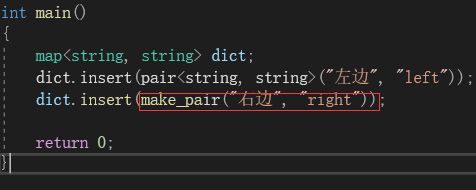
make_pair()的本质就是一个函数模板:

它的返回值就是一个构造好的pair对象。通过这种方式,就不需要显式的传入类型,而是让编译器根据传入的值自己进行推导构造。
1.4 pair存在原因
有人此时就会觉得奇怪,既然使用pair后使得map的插入使用起来很麻烦,那为什么不直接在类里面分别定义一个key和value,而要用一个类封装起来呢?
这其实是因为kv模型的主要作用就是通过键值找到队形的内容,例如用键值“左边”找到它对应的值“right”。如果不封装起来,在返回时因为只能有一个返回值的原因,就无法同时返回这两个值的内容,要返回就依然需要在返回时临时构造一个pair对象。既然如此,那为什么不一开始就用pair封装起来呢。而通过封装pair的方式,也能使树中对应的数据更容易读写。
1.5 运算符[]重载
在vector中,我们可以使用“[]”来找到指定位置上的数据。其实在map中,也是支持使用"[]"来查找某个数据的:
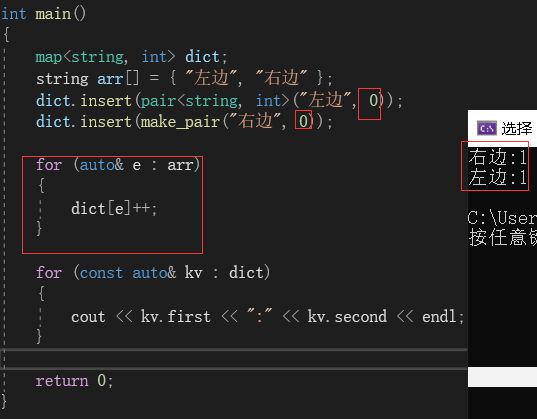
在上图的程序中,有一条“dict[e]++”语句,该语句使得在map中“左边”和“右边”两个键值所对应的内容都被修改了。修改逻辑很简单,首先map是支持使用[]的,而[]内要填的值就是键值,而arr[0]的值为“左边”,所以此时代码可以看为dict["左边"]++,而“左边”这一键值对应的就是0,0再经过++就变成了1。
那map是如何实现这一机制的呢?我们先来看看文档中关于map的运算符[]重载的描述:
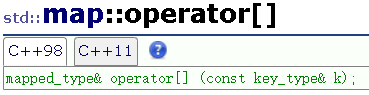
这样看可能不太能看明白,因为这里的mapped_type和key_type都是经过封装后的类型。因此再来看文档重载实现:
![]()
将函数名和重载实现结合起来,就可以看成是如下图所示:

通过上图中可以看到,在[]的重载中,其实是调用了insert()函数的。所以我们再将insert()函数拿出来和[]重载放在一起:

有了insert(),我们再来逐步解读[]重载的返回值。先从最里面看,"this->insert(make_pair(k, mapped_type())”,其实就是在向对象中插入一个值,它的key为k,value为mapped_type()。
![]()
大家可能不知道mapped_type是什么,查看文档,可以看到,它其实就是一个T,标识传入的数据类型。所以mapped_type()就是value类型的匿名对象。
再来看insert()的返回值:

它返回的是pair类,参数分别为iterator和bool。当插入成功时,insert()会返回一个pair类,其中的iterator就是插入的值的迭代器,bool为1;当插入失败时,iterator就是在map中与插入的key值相同的节点的迭代器,bool被设置为-1。
这个返回值就为我们理解[]重载的返回值提供了重要依据。
[]重载最内部是一个插入函数,且返回值为pair
再次简写内容为“*(iterator)”,这里就是一个解引用,获取迭代器位置上的值。而map的迭代器解引用后获取的是一个pair

分解过程可以看成如上图所示。
运算符[]重载通过调用insert()函数的方式,就实现了3个功能。
(1)查找
因为inset()函数的返回值为pair
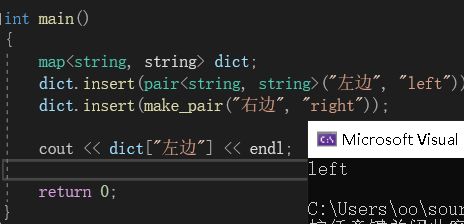
(2)插入
既然底层调用的是insert(),这就说明,当输入传入的值在map中不存在时,就可能导致这个数据被插入到map中:
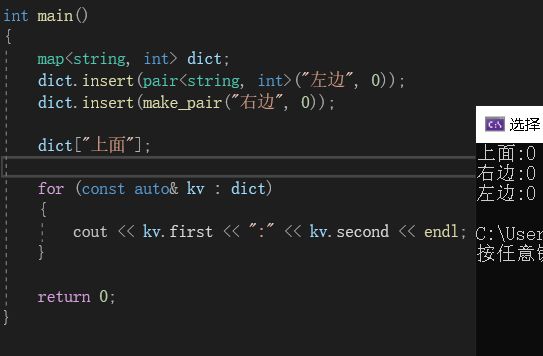
在上面的程序中,我们并没有向dict中插入“上面”,仅仅是调用了“dict[“上面”]”,但是在打印中就可以发现,此时上面已经被插入到dict中了。
有人可能会疑惑,我们的确用dict[“上面”]进行了插入,但是插入的仅仅是key值啊, 并没有插入value值,它的value值是哪里来的呢?在返回值中的insert()中的value传入的是一个mapped_type(),即一个匿名对象。所以当用这种方式插入数据时,如果插入的是内置类型,就调用它的匿名对象的默认值;如果是自定义类型,就去调它的默认构造。这里因为value的类型是int,它的匿名对象默认值为0。但如果你将int改为string,则会插入空:

(3)修改
因为运算符[]重载最终获取的是map中对应key值的value的引用,所以也可以对value进行修改:
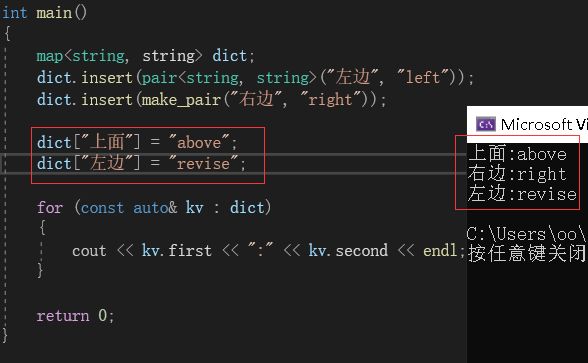
其他的接口因为使用起来都很简单,所以就不再一一赘述。
2.multimap

map和set一样,是不允许键值冗余的。如果想要使用map的同时,又插入相同的键值对应不同的value,就可以使用multimap,该容器允许键值冗余。
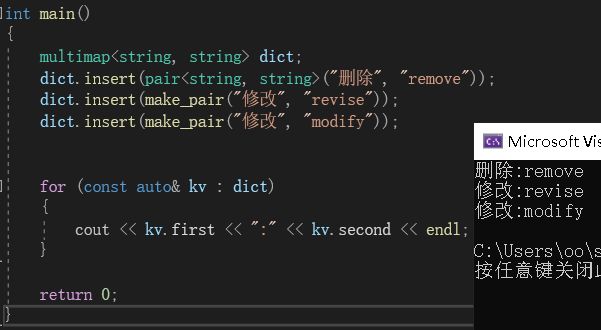
当然,也因为允许键值冗余,所以multimap不再支持运算符[]重载。避免出现二义性。
五、set和map的模拟实现
首先我们要知道,set和map的底层都是用二叉搜索树来实现的,更准确来说,是用红黑树来实现的。set和map就是对红黑树的一层封装。因此,要模拟实现set和map,首先要先实现一棵二叉树的插入。如果没有实现,可以参考上一篇文章“初识C++之红黑树”,其中就有构建红黑树的代码实现。
在模拟实现set和map之前,先来看看库中的实现。当然,为了方便更清楚的看到库中对应的实现,下面的图中都删除掉了库中一些与当前内容无关的代码后的结果:
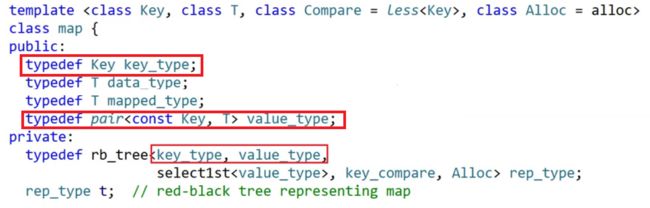
map:
set:
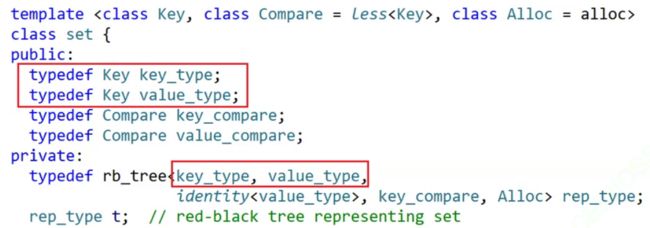
从上面的图中我们可以看到,set和map的成员变量中,都定义了同一个变量“rb_tree
但是这里有另一个问题,我们知道,set是K模型的二叉搜索树,而map则是KV模型的二叉搜索树。因此,在map中,它使用红黑树时传入key_type作为键值,value_type作为对应内容很合理;但是,从上面的图中可以发现,set传给红黑树的也是key_type和value_type两个参数。这就很奇怪了,set明明是k模型,怎么会传两个参数给红黑树呢?
由此,我们再来看看库中红黑树的实现逻辑:
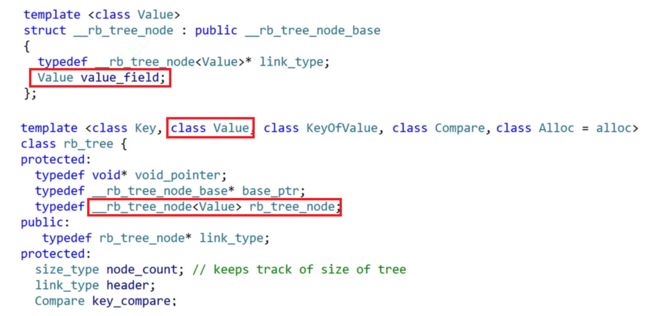
库中的实现逻辑和我们的自己写的实现逻辑有一点差别,但是大方向是一样的。这里就直接看它的实现。经过观察可以发现,库中的红黑树中有一个参数“Value”,类中还有一个“typedef _rb_tree_node
由此,就可以知道,set和map在底层其实使用的是同一个红黑树,该红黑树通过传过来的value类型的不同变为不同的红黑树。
再次观察set和map的底层实现,就可以发现,在set中,对K进行了两次重命名,分别为Key_type和Value_type。而map中则是用K和pair
由此,库中的红黑树就可以根据传入的value的不同分别实现k模型和kv模型:
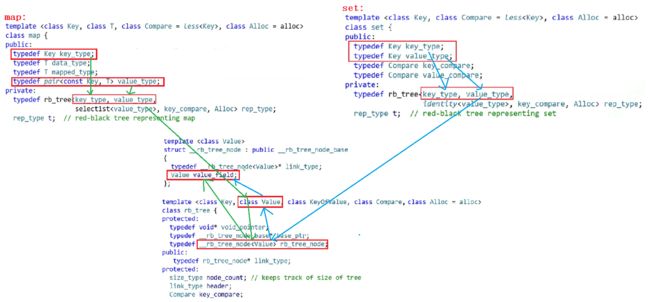
看到这里,大家可能会有一个问题。既然可以用value来让红黑树实现k模型和kv模型,那为什么在传值给红黑树时,还要传一个key呢?原因很简单,因为红黑树不仅需要被用来插入,还需要用来查找,实现迭代器等功能。而这些功能都是通过key来完成的。如果只有一个pair
1.修改红黑树
在模拟实现set和map之前,我们先将红黑树修改如下:
template
struct RBTreeNode
{
T _data;//kv模型
RBTreeNode* _left;//左子结点
RBTreeNode* _right;//右子节点
RBTreeNode* _parent;//父节点
Colour _col;//节点颜色
RBTreeNode(const T& data)//构造函数
: _data(data)
, _left(nullptr)
, _right(nullptr)
, _parent(nullptr)
, _col(RED)//节点颜色默认给红色
{}
};
template//K为键值;T为传进来的数据类型;KeyOfT是数据的值,用于pair
class RBTree
{
typedef RBTreeNode Node; 上面的代码仅仅是展示了红黑树的结构体定义中的修改。其中将RBTree和RBTreeNode的模板参数V修改为T,表示传入的数据类型。
在RBTreeNode中新增一个“T _data”变量,用于存储数据和修改红黑树的结构。
在RBTree的模板中新加入一个“KeyOfT”参数,该参数用于获取传入的数据的key(键值)。因为当传入的是pair
2.set和map的插入
2.1set
namespace MySet
{
template
class set
{
struct SetKeyOfT//仿函数,返回key
{
const K& operator()(const K& key)
{
return key;
}
};
public:
bool insert(const K& k)
{
return _t.insert(k);
}
private:
MyRBTree::RBTree _t;
};
} 2.2 map
namespace MyMap
{
template
class map
{
struct MapKeyOfT
{
const K& operator()(const pair& kv)
{
return kv.first;
}
};
public:
bool insert(const pair& kv)//插入函数
{
return _t.insert(kv);
}
private:
MyRBTree::RBTree, MapKeyOfT> _t;
};
} 可以看到,set和map的插入实现几乎是一模一样的。不同的是,set传给红黑树的value是K,而map传给红黑树的是pair
3.set和map的迭代器
set和map的迭代器其实是比较简单的,它们都是在红黑树的基础上进行了一层封装。所以首先要将红黑树的迭代器写出来。
3.1 红黑树的迭代器
template
struct _RBTreeIterator//迭代器类
{
typedef RBTreeNode Node;
typedef _RBTreeIterator Self;
typedef _RBTreeIterator iterator;//用于将普通迭代器构造const迭代器
Node* _node;
_RBTreeIterator(Node* node)//构造函数
:_node(node)
{}
_RBTreeIterator(const iterator& s)//传进来的是普通迭代器,它就是拷贝构造
:_node(s._node) //传进来的是const迭代器,构造,支持用普通迭代器构造const迭代器
{}
Ref operator* ()//解引用重载
{
return _node->_data;
}
Ptr operator->()//->重载
{
return &_node->_data;
}
Self& operator++()//前置++
{
if (_node->_right)//如果传进来的节点的右子节点,就去找它的右子树的最左子节点
{
Node* min = _node->_right;
while (min->_left)
{
min = min->_left;
}
_node = min;
}
else
{
Node* cur = _node;
Node* parent = cur->_parent;
while (cur && parent && cur == parent->_right)//当cur不是parent的右节点时,说明找到中序的下一个位置
{
cur = parent;
parent = cur->_parent;
}
_node = parent;
}
return *this;
}
Self& operator--()//前置--
{
if (_node->_left)
{
Node* min = _node->_left;
while (min->_right)//找左子树的最大节点
{
min = min->_right;
}
_node = min;
}
else
{
Node* cur = _node;
Node* parent = cur->_parent;
while (parent && cur == parent->_left)
{
cur = parent;
parent = cur->_parent;
}
_node = parent;
}
return *this;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}
bool operator ==(const Self& s) const
{
return _node != s._node;
}
};
红黑树中的对迭代器的封装/
typedef _RBTreeIterator iterator;//迭代器
typedef _RBTreeIterator const_iterator;//const迭代器
iterator begin()
{
Node* left = _root;
while (left && left->_left)
left = left->_left;
return iterator(left);
}
iterator end()//可以用,但可能会有点小问题
{
return iterator(nullptr);
}
const_iterator begin() const
{
Node* left = _root;
while (left && left->_left)
left = left->_left;
return const_iterator(left);
}
const_iterator end() const//可以用,但可能会有点小问题
{
return const_iterator(nullptr);
} 在库中的红黑树的结构上其实比这里写的红黑树要多一个head节点,这个节点的父指针指向根节点,左指针指向红黑树的最左子节点,有指针指向空。就是为了方便实现迭代器。这里我们并没有实现这个head节点,就自己手动找即可。
3.2 set和map的迭代器
有了红黑树的迭代器,set和map就很简单了,直接进行一层封装即可。
set:
typedef typename MyRBTree::RBTree::cosnt_iterator iterator;
typedef typename MyRBTree::RBTree::cosnt_iterator const_iterator;
//底层用的都是红黑树的const迭代器,无论是此处的普通迭代器还是const迭代器所指向的值都无法被修改
pair insert(const K& k)
{
//ret调用的是红黑树中的insert,而红黑树中的红黑树此时会返回一个包含普通迭代器的pair,与我们需要的const
//迭代器不符,需要接收pair后,重新用这个pair构造一个包含const迭代器的piar返回
pair::iterator, bool> ret = _t.insert(k);
return pair(ret.first, ret.second);
}
iterator begin() const//加const是因为set的普通迭代器和const迭代器都是用的红黑树的const迭代器
{
return _t.begin();
}
iterator end() const
{
return _t.end();
} map:
//这里重命名时要加上typename,因为类模板此时没有实例化,
//编译器无法分清iterator究竟是一个静态变量还是一个类型,用typename告诉编译器这是类型
typedef typename MyRBTree::RBTree, MapKeyOfT>::iterator iterator;
typedef typename MyRBTree::RBTree, MapKeyOfT>::const_iterator const_iterator;
pair insert(const pair& kv)//插入函数
{
return _t.insert(kv);
}
iterator begin()
{
return _t.begin();
}
iterator end()
{
return _t.end();
}
const_iterator begin() const
{
return _t.begin();
}
const_iterator end() const
{
return _t.end();
}
V& operator[](const K& key)//运算符[]重载
{
pair ret = insert(make_pair(key, V()));
return ret.first->second;
} 注意,在set和map这里,在类型名前要加上typename告诉编译器这是一个类型。因为这个写法和类对象调用一样,但是这里并没有实例化出对应的类。因此编译器可能错误的将它识别为一个变量,导致报错。手动加一个typename告诉编译器这是一个类型即可解决问题。
要实现map支持[],就需要再次修改红黑树中的insert()的返回值,让它返回一个pair:
![]()
其中的iterator是数据的位置,当红黑树中有这个数据时,返回它的位置;没有,则插入并返回插入后的位置。