大数据-Hadoop-云服务器的搭建
一. 云服务器的购买及其设置
1. 服务器的选择及购买
(略)
【狂神说Java】服务器购买及宝塔部署环境说明_哔哩哔哩_bilibili
2. 配置安全组规则(开放端口)
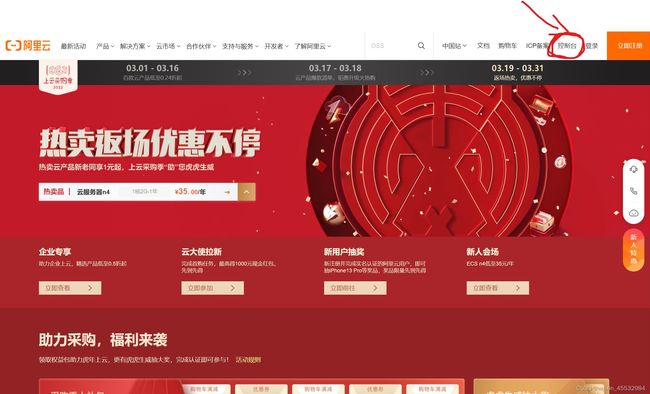
(1)阿里云官网登录控制台
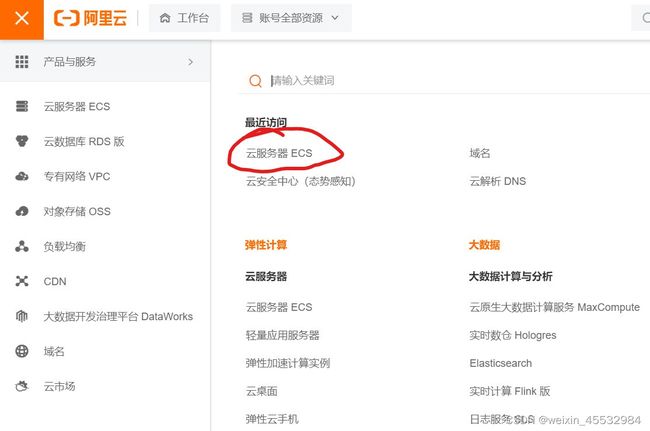
(2)云服务器ECS
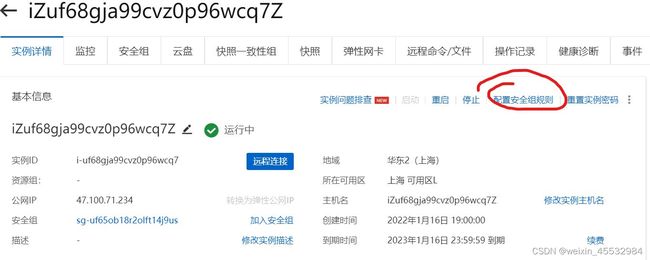
(3)选择下面的实例,i-uf68gja99cvz0p96wcq7

(4)安全组规则
(5)添加安全组规则
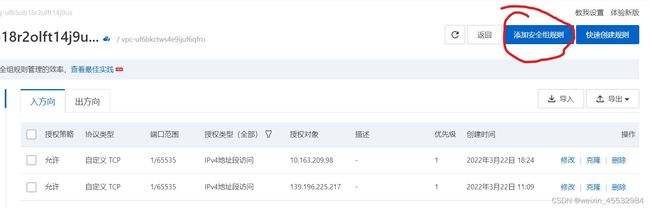
(6)把三个实例相互之间全部打通,全部坦诚相见,下面那个填写对方的ip

3. xshell登录,服务器之间的无密登录
(1)首次登录xshell需要用户名和密码,填写root和对应的密码,记得把记住用户名和记住密码勾选上
(2)首次登录没有公钥私钥要创建
创建密钥:
ssh-keygen -t rsa把公钥送给另外两台服务器
ssh-copy-id 139.196.225.217然后会填写相应的密码,送钥完成
(3)检查是否配置成功
ssh 116.62.26.19能连上相应的服务器代表成功
4. hosts映射
(1)进入根目录
vim /etc/hosts(2)添加图片对应的映射
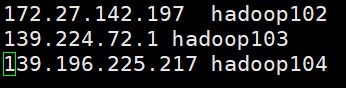
重要:在第一台服务器中,也就是hadoop102中,填写自己的私网,访问别人的填写公网
二. Hadoop及JDK安装
1. Hadoop以及JDK版本选择
(1)jdk:1.8.0_212
(2)hadoop:3.1.3
2. Hadoop以及JDK上传云端
(1)进入到 /opt目录下创建两个文件夹,一个放压缩包,另外一个放软件
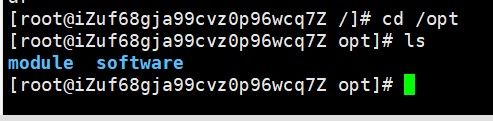
(2)用xshell软件的xftp工具把两个包扔进去

3. scp命令, sync命令以及集群分发脚本xsync
(1)(scp)拷贝,服务器慢的话这个命令也慢
(2)(sync)同步,后续用这个命令
(3)(sxync)集群分发脚本,以后都用这个,仍在 /root/bin/下面,没有目录创建一个
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in 47.100.71.234 139.224.72.1 139.196.225.217
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
4. 文件解压缩以及相应的环境变量
(1)在/profile.d/下面编写一个环境变量的sh文件
vim /etc/profile.d/my_env.sh (2)xsync分发给另外两台服务器
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
5. 安装完成后的校验
(1)jdk的检查,至少要在根目录下
java -version
(2)hadoop的检查
hadoop version

三. Hadoop配置文件
0. 总体安装分配
| hadoop102 |
hadoop103 |
hadoop104 |
|
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
之后进行素质五连,然后记得分发脚本 xsync,把etc目录下的都分发出去

1. core-site.xml
fs.defaultFS
hdfs://hadoop102:8020
hadoop.tmp.dir
/opt/module/hadoop-3.1.3/data
2. hdfs-site.xml
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.secondary.http-address
hadoop104:9868
3. yarn-site.xml(这部分有所更改看五-4-(3))
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
4. mapred-site.xml
mapreduce.framework.name
yarn
vim
5. workers
hadoop102
hadoop103
hadoop104
四. Hadoop集群的启动以及测试
0. 初始化
hdfs namenode -format1. 启动HDFS
sbin/start-dfs.sh2. 启动YARN
sbin/start-yarn.sh3. jps命令检查启动的所有东西每个服务器都要检查
正常是这样的
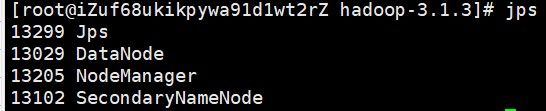

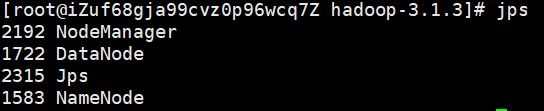
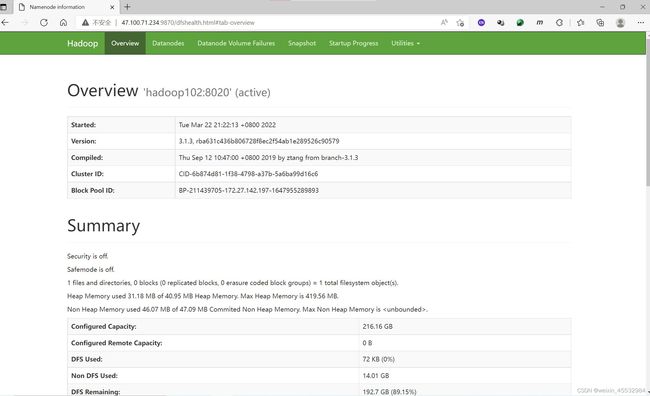
jps4. 查看HDFS信息
(1)进到hadoop102对应的公网的地址
(2)进入到Utilities中
(3)进入到 Browse the file system中

(4)创建一个新的文件夹,output是执行成功后出来的,本来没有(wcinput和input是一样的,但是图片没了,就代替了一下,本质是一样的)
hadoop fs -mkdir /input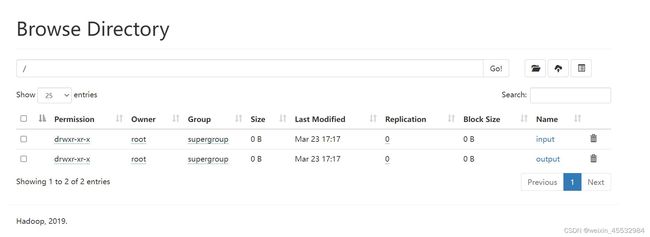
刷新过后有文件产生,Bingo!
(5)上传一个文件
fs -put $HADOOP_HOME/wcinput/word.txt /wcinput检查文件

5 . 查看YARN信息
1. 浏览器输入,也就是hadoop103的公网地址
http://139.224.72.1:8088/cluster2.弹出的页面(没有弹出来还是去控制台把对应的安全组规则配置一下)
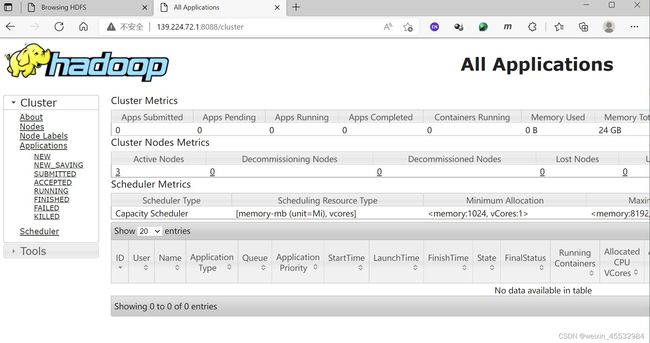
6. 执行官方的wordcount案例
(1)执行案例,输出的文件夹要不存在才行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output(2)查看hdfs情况,这里的output(相当于wcoutput,图片找不到了,代替一下)
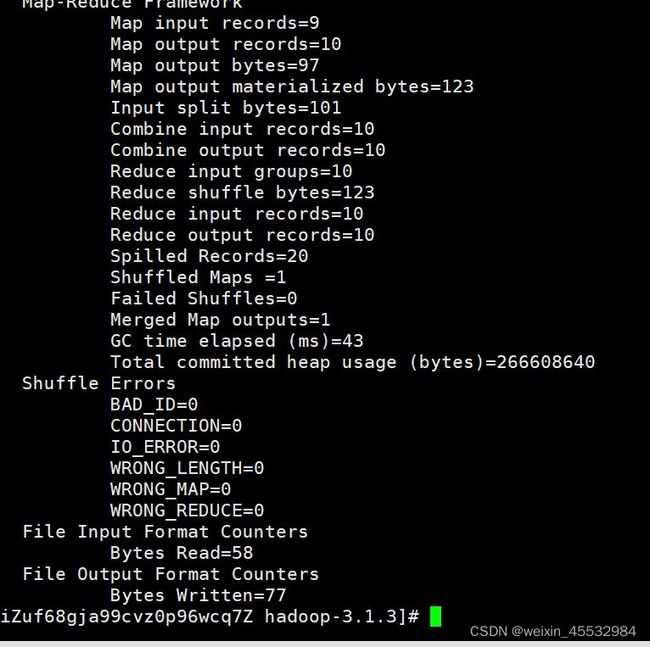
(3)查看yarn情况,有进度条(这次是失败的情况,可以看到最后状态FinalState是Failed,下面是成功的情况,此张图片为了展示yarn界面的样子)

(4)运行成功!
(6)查看执行出来的文件
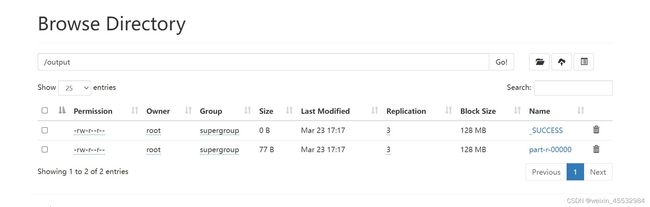
Success代表成功,执行出来的文件是part-r-00000,下载下来,把后缀名改成txt查看,不能下载的可以看五-3.
(7)改成txt格式的最后显示。

五. 常见Bug及其解决方法
1. 三台服务器DataNode启动了,namenode和secondarynamenode都没启动
答:在根目录 /etc/hosts 文件中,相对于自己的地址填写私网地址,服务器有公网私网,涉及到自己的部分一定是自己的私网地址。详见一.4。
2. web访问页面的Yarn(hadoop103:8088)和hadoop102:9870进不去
答:在服务器的安全组配置规则中,开放这部分端口,Yarn的是8088(也就是hadoop103:8080),在hadoop102上开放端口9870。以防万一建议开启服务器相互之间所有的端口以及对外需要展示的所有的端口。
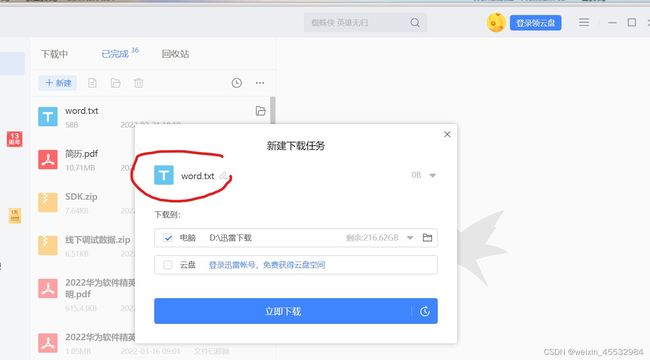
3. Browse Directory :Couldn't preview the file ,也不能下载,File contents显示[object Object]
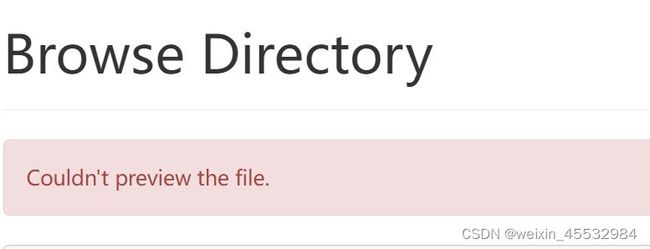
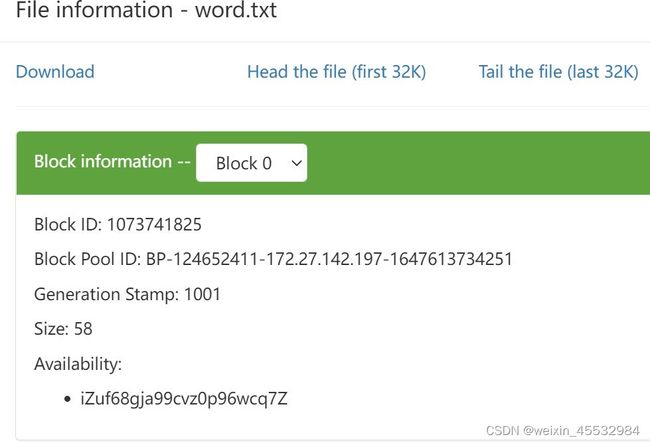
答:(1)检查开放的端口,不行在这一步对外暴露所有的端口(1-65535),然后进行下载测试,也可以查看本机的ip,在安全组配置规则中对本机ip暴露所有的端口(1-65535)
(2)检查Blocdk Pool ID:BP-XXXXXX-熟悉的服务器地址-XXXXXXX,“熟悉的服务器地址”如果是服务器的私网地址,我们想要浏览的话,只需要把Download的地址新开一个页面,把其中的私网地址换成对应的公网地址就可以下载了(治标不治本)
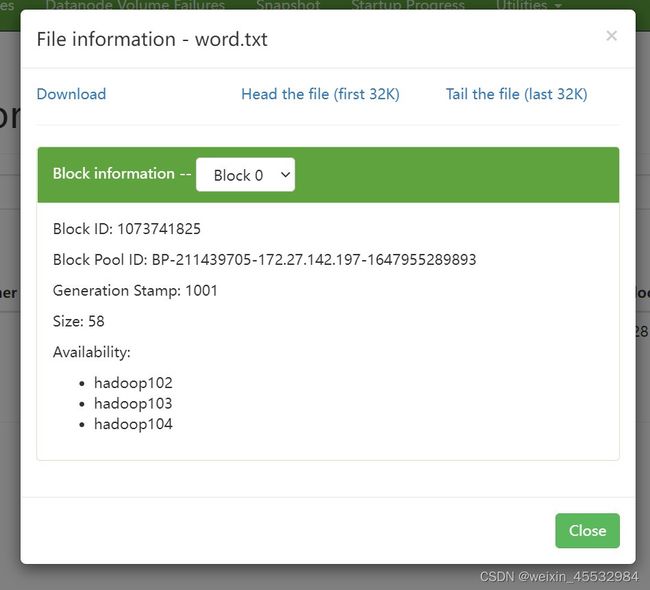
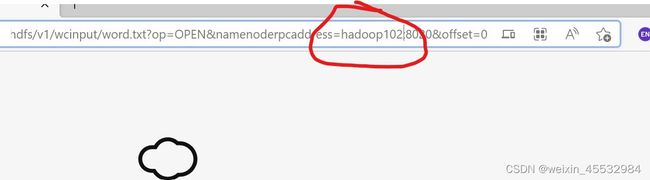
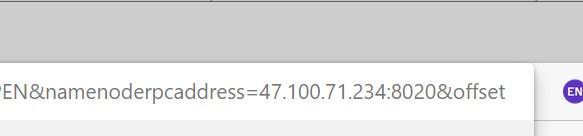
4. INFO mapreduce.Job: Running job
答:(-1)把Yarn运行的内存搞成8g,4g也行,如果是开的虚拟机,这个好办,如果是用云服务器搭建的,那就换个运存大点的服务器,不想换那就参照(0),CSDN上最吊的。
(0)CSDN最迪吊解决办法,涉及到本质,其他都是不让MapReduce运行在Yran上,这个是真正修改了Yran与逆行所需要的内存包括物理内存和虚拟内存
Hadoop提交MapReduce任务后卡在mapreduce.Job: Running job_阿团团的博客-CSDN博客
(1)查看所有的结点的NodeManager开启情况
典型代表:
hadoop3 任务卡在map 0% reduce 0%的解决方案_Akari0216的博客-CSDN博客
(2)查看所有workers情况
典型代表:mapreduce.Job: Running job: job_1553100392548_0001_chunguang.yao的博客-CSDN博客
(3)配置yarn-site-xml中的8030 8031 和8032(这三个地址要配置在部署yarn的那台上)
典型代表:MapReduce执行任务时卡在mapreduce.Job: Running Job这一步该如何解决_sinat_33769106的博客-CSDN博客
(4)配置yarn的虚拟内存等
典型代表:
MapReduce执行任务时卡在mapreduce.Job: Running Job这一步该如何解决_sinat_33769106的博客-CSDN博客
(5)把mapred-site-xml中的运行在yarn去掉(治标不治本,此项会把yarn运行情况弄没)
hadoop执行mapreduce一直卡在mapreduce.Job: Running Job_日京的博客-CSDN博客
解决Hadoop运行jar包时一直卡在: INFO mapreduce.Job: Running job位置的问题_风之子Fight的博客-CSDN博客
【Hadoop】Hadoop运行Mapreduce程序一直卡在mapreduce.Job: Running job: job_1617678192164_0001_飝鱻.的博客-CSDN博客
mapreduce任务卡在INFO mapreduce.Job: Running job_bigtiger1648的博客-CSDN博客
日常问题——hadoop 任务运行到running job就卡住了 INFO mapreduce.Job: Running job: job_1595222530661_0003_栗筝i的博客-CSDN博客hadoop 任务运行到running job就卡住了 INFO mapreduce.Job: Running job: job_XXXXXXX_行思坐忆,志凌云的博客-CSDN博客
(6)修改Yarn的内存,原理同(4),但是只修改一项
hadoop运行任务时一直卡在:INFO mapreduce.Job: Running job_20boy发愤图强想当功城狮的博客-CSDN博客错误(为解决):yarn的wordcount任务卡在INFO mapreduce.Job: Running job: job_1541084101495_0003_RayBreslin的博客-CSDN博客