Linux环境Hadoop、spark、Kafka搭建流程
服务器名称及IP
- 使⽤vim修改hosts⽂件,vim /etc/hosts,三台服务器均做相同配置
添加
master:192.168.x.X
slaver1:192.168.x.X
slaver2:192.168.x.x
- vim /etc/hostname,需要对三台服务器分别配置为master、slaver1、slaver2
192.168.x.x master
192.168.x.x slaver1
192.168.x.x slaver2
三台电脑免密登录
在每台电脑终端输入:
sudo ssh-keygen -t rsa
将slaver1、slaver2主机上公钥复制到master
scp id_rsa.pub cciip@master:~/.ssh/id_rsa_slaver1.pub
scp id_rsa.pub cciip@master:~/.ssh/id_rsa_slaver2.pub
在master主机上,对三个公匙进⾏注册
cat id_rsa* >> authorized_keys
最后,将master上的authorized_keys分发到slaver1、slaver2上
scp authorized_keys cciip@slaver1:~/.ssh/
scp authorized_keys cciip@slaver2:~/.ssh/
若是各电脑用户名不同时,可以在~/.ssh/中的config添加:
Host master
user name1
Host slaver1
user name2
Host slaver2
user name3
测试是否成功:
ssh master
ssh slaver1
ssh slaver2
安装jdk环境
- 安装Java,三台电脑都需要安装。
下载jdk:
官网地址
我下载的是jdk-8u271-linux-x64.tar.gz
在下载目录下使用终端sudo tar -zxvf jdk-8u271-linux-x64.tar.gz -C /usr/local解压并移动到/usr/local目录下。 - 配置系统环境变量
编辑/etc/profile文件,在文件末尾添加,然后使用source /etc/profile使文件生效
# jdk
export JAVA_HOME=/usr/local/jdk1.8.0_271
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
- 验证jdk安装成功
使用java -version查看Java版本
安装hadoop
1、首先从https://hadoop.apache.org/releases.html下载,选择binary文件进行下载,下载的文件名是hadoop-2.7.7.tar.gz
2、同样将安装包解压并移动到/usr/local目录下
3、进入/usr/local/hadoop-2.7.7/bin目录下,hadoop version判断hadoop版本
4、配置环境变量
编辑/etc/profile文件,在末尾添加
# hadoop-2.7.7
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后source /etc/profile使文件生效
5、在hadoop-2.7.7目录下创建hdfs文件夹,并在hdfs目录下创建tmp, name, data
三个文件夹:
sudo mkdir hdfs
sudo mkdir tmp
sudo mkdir name
sudo mkdir data
6、在/usr/local/hadoop-2.7.7/etc/hadoop目录下有需要配置的文件
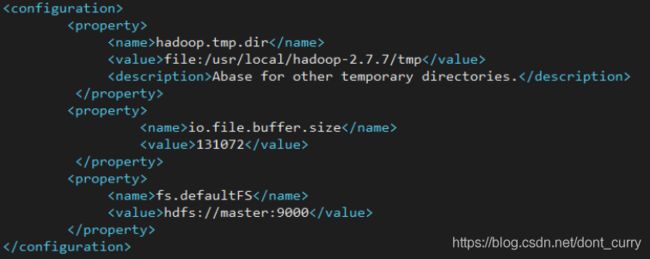
首先配置core-site.xml文件,使用sudo vim core-site.xml打开文件,然后在
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
注意:第一个属性中的value和我们之前创建的/usr/local/hadoop-2.7.7/hdfs/tmp路径要一致。
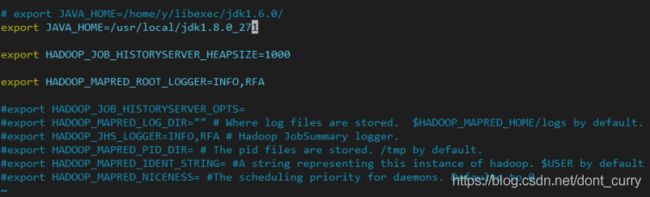
然后配置hadoop-env.sh,用于配置jdk目录,将export JAVA_HOME=${JAVA_HOME}注释掉配置成具体的路径:

同样在mapred-env.sh加入JAVA_HOME:
配置hdfs-site.xml,在
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.7/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.7/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
注意:其中第二个dfs.namenode.name.dir和dfs.datanode.data.dir的value和之前创建的/hdfs/name和/hdfs/data路径一致;由于有两个从主机slave1、slave2,所以dfs.replication设置为2
复制mapred-site.xml.template文件,并命名为mapred-site.xml,编辑mapred-site.xml,在标签
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
最后编辑slaves文件,把原有内容删掉,然后添加:
slaver1
slaver2
7、复制hadoop到其他节点,并放在相同目录
8、启动hadoop
进入安装目录:/usr/local/hadoop-2.7.7,./bin/hdfs namenode -format,成功的话会看到“successfully formated”和“exiting with status 0”
需要对hadoop目录有写权限:sudo chmod -R 777 /usr/local/hadoop-2.7.7
在master上开启hadoop,使用./sbin/start-all.sh 启动。然后⽤jps命令来查看是否启动成功,若成功会看到master上⾯有namenode、secondarynamenode resourcemanager,
worker1和worker2上⾯有datanode、nodemanager
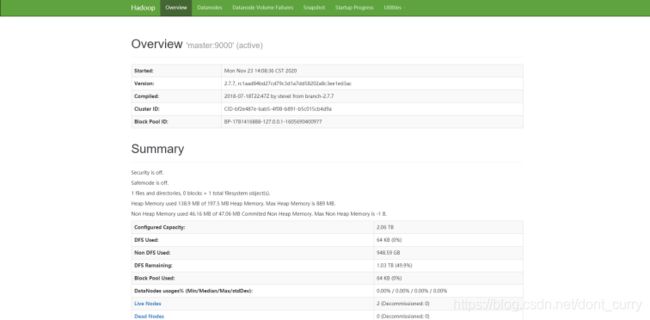
9、通过web查看hadoop集群状态
YARN的web页面,则是在master机器上,然后端口是用yarn-site.xml配置文件中的yarn.resourcemanager.webapp.address指定的,我们配置的是18088,那么在浏览器中输入:http://192.168.x.x:18088即可打开界面,如下图所示:

HDFS界面在master上打开,如果没有更改端口,则默认的端口是50070:http://192.168.1.4:50070,如下图所示:
10、拷贝至其他节点
安装Scala
下载的文件名scala-2.11.12.tgz,解压并移动到/usr/local目录下,打开/etc/profile并编辑,在文件末尾添加:
# scala
export SCALA_HOME=/usr/local/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
运行source /etc/profile使文件生效,检测是否安装成功:scala -version
拷贝至其他节点
安装spark
下载spark-2.4.0-bin-hadoop2.7.tgz解压并移动到/usr/local目录下,同样配置环境变量,在/etc/profile文件末尾添加:
# spark
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH
1、配置slaves文件,进入slaves文件所在目录/usr/local/spark-2.4.0-bin-hadoop2.7/conf,编辑slaves文件,添加:
master
slaver1
slaver2
2、配置spark-env.sh
spark-env.sh主要⽤于配置spark运⾏时核数、内存⼤⼩等,⾸先进⼊到spark-env.sh所在位置/usr/local/spark-2.4.0-bin-hadoop2.7/conf
将spark-env.sh.template⽂件复制⼀份,命名为spark-env.sh,spark运⾏时会进⾏加载。配置spark-env.sh脚本内容如下:
export JAVA_HOME=/usr/local/jdk1.8.0_271
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
export YARN_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
export SCALA_HOME=/usr/local/scala-2.11.12
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export SPARK_MASTER_IP=master
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=20G
export SPARK_EXECUTOR_CORES=4
export SPARK_EXECUTOR_MEMORY=6G
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
3、将配置好的spark-2.4.0-bin-hadoop2.7文件复制给其他节点
4、启动spark集群
在master上进入/usr/local/spark-2.4.0-bin-hadoop2.7/sbin目录,运行start-all.sh和start-slaves.sh脚本。
在master和slaver1、slaver2上运行start-master.sh脚本。在slaver上用jps查看,如果有master和worker进程则说明成功。
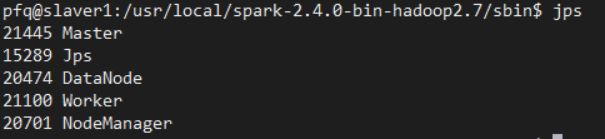
关闭时分别运行
stop-master.sh、stop-slaves.sh、stop-all.sh
7、可通过http://master:8080查看集群情况和运⾏的applications,可看到机器处于active状态。另外,打开http://slaver1:8081可看到机器处于stand by状态。可通过http://master:4040 查看application运⾏的job的具体信息。
运行 spark-shell,可以进入 Spark 的 shell 控制台。
安装Kafka
下载kafka_2.11-2.4.0.tgz解压并移动到/usr/local目录下,我们解压后的kafka 进文件夹,如下目录。我们主要用到的就是bin和config 这两个目录。
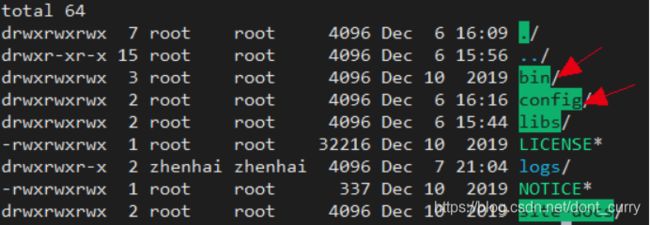
1、config目录
config 里面的文件。我们主要就用到server.propertie 和zookeeper.properties.
![]()
server.propertie 是启动kafka 时加载的配置文件。点击去看看,基本要改的就是下面这两个地方。
每一个broker都需要一个标识符,使用broker.id来表示。它的默认值是0,也可以被设置成任意其它整数。这个值在整个kafka集群里必须是唯一的。这个值可以任意选定。

还有kafka 默认启动服务的默认端口是9092.如果我们想要修改的话,就需要在server.propertie 中加上。
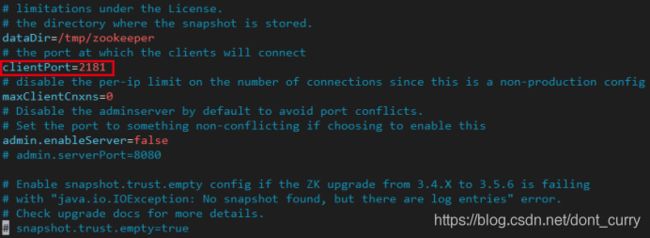
zookeeper.properties 文件是启动kafka 自带的zookeeper 时加载的配置。里面的配置就比较少了,主要是:
libs 文件夹是kafka 运行依赖的jar 包,我们可以不用管,logs是kafka 运行产生的日志,我们排查问题时用到,暂时也不用管。
2、简单操作
kafka 启动要依赖zookeeper服务。所以我们来看zookeeper的命令。
# 启动zookeeper 服务
bin/zookeeper-server-start.sh ./config/zookeeper.properties
# 停止zookeeper 服务
bin/zookeeper-server-stop.sh
启动好zookeeper 后,启动kafka 服务。
bin/kafka-server-start.sh ./config/server.properties
关闭kafka服务:
bin/kafka-server-stop.sh
启动好kafka 服务后,我们就可以创建topic 啦。创建topic的命令:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
这里可以看到创建topic 的命令算是比较复杂的, --zookeeper localhost:2181是指定zookeeper 服务。-replication-factor是指创建分区。
partitions 是创建备份。test1是topic 名称。
我们在创建一个tpoic test2. 然后查看topic 列表,需要指定zookeeper 连接:
bin/kafka-topics.sh --list --zookeeper localhost:2181
创建了topic 。接下来我们可以让生产者推送消息到这个topic 上。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1

生产者生产了消息,接下来就需要消费者消费消息啦。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1 --from-beginning
–bootstrap-server localhost:9092
是连接特定的kafka 服务
–from-beginning 读取历史未消费的数据。

可以看到kafka可以正常使用。