Spark搭建/Hadoop集群
一、Spark概述.
Spark于2009年诞生于美国加州大学伯克利分校的AMP实验室,它是一个可应用于大规模数据处理的统一分析引擎。Spark不仅计算速度快,而且内置了丰富的API,使得我们能够更加容易编写程序。
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。

图1-1

图1-2

图1-3

图1-4
二、Spark特点.
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
1、速度快.
根据官方数据统计,与Hadoop相比,Spark基于内存的运算效率要快100倍以上,基于硬盘的运算效率也要快10倍以上。Spark实现了高效的DAG执行引擎,能够通过内存计算高效地处理数据流。
2、易用性.
Spark编程支持Java、Python、Scala及R语言,并且还拥有超过80种高级算法,除此之外,Spark还支持交互式的Shell操作,开发人员可以方便地在Shell客户端中使用Spark集群解决问题。
3、通用性.
Spark提供了统一的解决方案,适用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLIib)和图计算(GraphX),它们可以在同一个应用程序中无缝地结合使用,大大减少大数据开发和维护的人力成本和部署平台的物力成本。
4、兼容性.
Spark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,并且还可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等。
三、Spark应用场景.
如下图1-5、1-6.

图1-5

图1-6
四、Spark与Hadoop对比.
1、编程方式.
Hadoop的MapReduce计算数据时,要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
2、数据存储.
Hadoop的MapReduce进行计算时,每次产生的中间结果都存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
3、数据处理.
Hadoop在每次执行数据处理时,都要从磁盘中加载数据,导致磁盘IO开销较大;而Spark在执行数据处理时,要将数据加载到内存中,直接在内存中加载中间结果数据集,减少了磁盘的IO开销。
4、数据容错.
MapReduce计算的中间结果数据,保存在磁盘中,Hadoop底层实现了备份机制,从而保证了数据容错;Spark RDD实现了基于Lineage的容错机制和设置检查点方式的容错机制,弥补数据在内存处理时,因断电导致数据丢失的问题。
五、搭建Spark开发环境.
由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。
注:安装Spark集群之前,需要安装Hadoop环境,采用如下配置环境:
○ Linux系统:CentOS_6.7版本;
○ Hadoop:2.7.4版本;
○ JDK:1.8版本;
○ Spark:2.3.2版本。
1、Spark部署方式有三种:
(1)Standalone模式:
·Standalone模式被称为集群单机模式。
·该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
(2)Mesos模式:
·Mesos模式被称为Spark on Mesos模式。
·Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
(3)Yarn模式:
·Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。
·由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
2、Spark集群安装部署.
(1)安装Scala.
①下载Scala安装包.
进入下载网站(All Available Versions | The Scala Programming Language (scala-lang.org))并选择版本下载(图1-7),进入选择版本下滑找到(图1-8)下载对应的版本。
1、Spark部署方式有三种:
(1)Standalone模式:
·Standalone模式被称为集群单机模式。
·该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
(2)Mesos模式:
·Mesos模式被称为Spark on Mesos模式。
·Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
(3)Yarn模式:
·Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。
·由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
2、Spark集群安装部署.
(1)安装Scala.
①下载Scala安装包.
进入下载网站(All Available Versions | The Scala Programming Language (scala-lang.org))并选择版本下载(图1-7),进入选择版本下滑找到(图1-8)下载对应的版本。
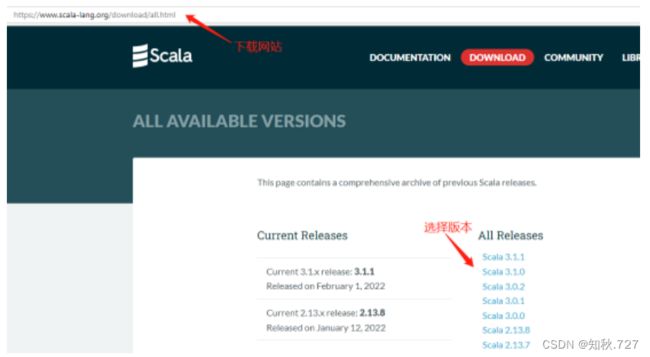
图1-7

图1-8
②解压Scala安装包.
使用CRT连接虚拟机linux,将安装包拉入目录,并使用指令解压Scala安装包。(图1-9)
指令:tar -zxvf /opt/software/scala-2.11.8.tgz -C /opt/module/
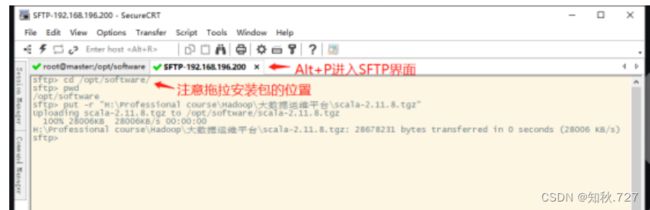
图1-9
③重命名Scala.
在解压目录,将解压的scala-2.11.8.tgz重命名为scala。(图2-1)
指令:mv scala-2.11.8/ scala

图2-1
④配置Scala环境变量.
进入(/etc/profile)配置scala的环境变量,保存并生效。(图2-2)
配置内容:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
生效指令:source /etc/profile

图2-2
⑤修改hadoop权限并分发文件到各个节点.
修改scala目录的权限为Hadoop(图2-3),并分发文件给slave1,slave2,再到各个节点修改scala目录的权限为Hadoop,配置环境变量并使环境变量生效。(图2-4)
修改权限指令:
chown -R hadoop:hadoop /opt/
分发文件scala指令:
scp -r /opt/module/scala/ slave1:/opt/module/
scp -r /opt/module/scala/ slave2:/opt/module/
配置内容:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
生效指令:source /etc/profile

图2-3

图2-4
⑥启动Scala.
在master节点上启动Scala。
指令:scala -version
(2)安装Spark.
①下载Spark安装包.
进入Spark下载(图2-5)页面(Downloads | Apache Spark),选择基于对应的版本下载。(图2-6)
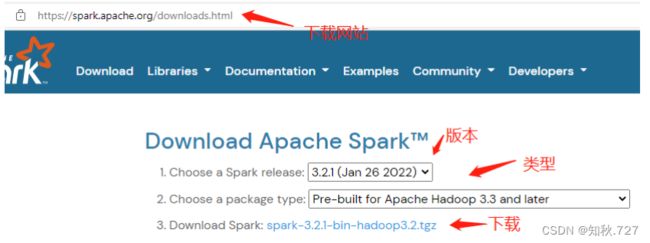
图2-5

图2-6
②解压Spark安装包.
使用CRT连接虚拟机linux,将安装包拉入目录,并使用指令解压Spark安装包。(图2-7)
指令:tar -zxvf /opt/software/spark-2.0.0-bin-hadoop2.6.tgz -C /opt/module/

图2-7
③重命名Spark.
在解压目录,将解压的spark-2.0.0-bin-hadoop2.6重命名为spark。
指令:mv spark-2.0.0-bin-hadoop2.6/ spark
④修改Spark配置文件.
进入spark/conf目录修改配置文件,将spark-env.sh.template修改成spark-env.sh并配置.(图2-8)
复制指令:cp spark-env.sh.template spark-env.sh
修改文件添加内容:
export JAVA_HOME=/opt/module/java
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
复制slaves.template文件,命名为slaves,并编辑slaves配置文件配置。
指令:cp slaves.template slaves
配置内容:
slave1
slave2
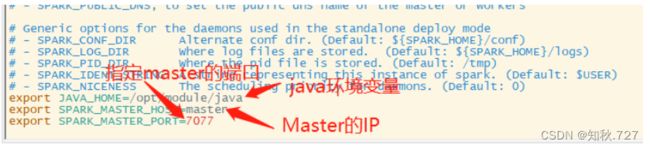
图2-8
⑤分发文件到各个节点.
修改Spark目录的权限为Hadoop,并分发文件给slave1,slave2,再到各个节点修改Spark目录的权限为Hadoop。(图2-9)
修改权限指令:
chown -R hadoop:hadoop /opt/
分发文件scala指令:
scp -r /opt/module/spark/ slave1:/opt/module/
scp -r /opt/module/spark/ slave2:/opt/module/
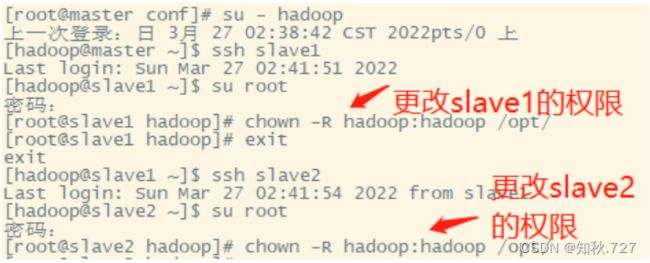
图2-9
⑥启动Spark.
在Spark目录下执行或者直接使用Spark/sbin/start-all.sh脚本命令。(图3-1)
指令:sbin/start-all.sh

图3-1