AI in Finance<量化交易&人工智能&金融投资>(上)
投资有风险,操作需谨慎!!!! 本文为个人笔记,请审核通过,谢谢
不管多么优秀的统计模型都有局限,风险控制永远都要放到第一位!
分散化不要把鸡蛋放在一个篮子里!高抛低吸!
AI in Finance
- 1 金融基础
-
- 1.1 金融产品
-
- 1.1.1 股票
- 1.1.2 基金
- 1.1.3 债券
- 1.1.4 期货
- 1.1.5 期权
- 1.1.6 ETF
- 1.1.7 外汇
- 1.2 技术指标
-
- 1.2.1 K线 (日本蜡烛图)
- 1.2.2 MA、SMA、WMA、EMA
-
- 1.2.3 MACD指标和KDJ指标
- 1.2.4 BOLL指标
- 1.3 金融模型
- 2 量化交易简介
-
- 2.1 量化交易开发流程
- 2.2 量化交易分类
-
- 2.2.1 按交易产品分类
- 2.2.2 按盈利模式分类
- 2.2.3 按策略信号分类
- 2.3 股票投资
-
- 2.3.1 行业分类的作用
- 2.3.2 股价影响因素
- 2.3.3 量化名词解释
- 2.3.4 财务知识
- 2.3.5 选股
- 2.3.6 择时
- 2.4 量化平台
- 2.5 量化投资(选股+择时)
- 2.6 从量化角度重新认识指标
- 3 股价分析基础(Numpy\Pandas\Matpolt)
-
- 3.1 股价分析指标
- 3.2 股价均线
- 3.3 股票时间序列
- 3.4 K线图
- 3.5 MACD
- 3.6 KDJ指数
- 4 聚宽量化实战
-
- 4.1 量化交易策略基本框架
- 4.2 常用下单函数API
- 4.3 读取Context中的数据!!!(重要)
-
- 4.3.1 Context对象(策略信息)
- 4.3.2 Position对象(持仓信息)
- 4.3.3 Portfolio账户对象(账户信息)
- 4.3 多股票策略
- 4.4 数据获取
-
- 4.4.1 Pandas.DataFrame数据格式
- 4.4.2 获取成分股
- 4.4.3 获取行情数据
- 4.4.4 获取财务数据
- 4.4.5 获取标的(产品)信息
- 4.4.6 本地获取聚宽数据-JQData
- 4.5 策略实战
- 4.6 策略评价
-
- 4.6.1 回测
- 4.6.2 模拟交易
- 4.7 投资研究功能
- 5 经典量化策略(选股)
-
- 5.1 多因子策略
-
- 4.1 基本面因子介绍
-
- 4.1.1 成长类因子选股 indicator
- 4.1.2 规模类因子选股 valuation
- 4.1.3 价值类因子选股 valuation
- 4.1.4 质量类因子选股 indicator
- 4.1 技术面因子介绍
- 5.2 市场中性策略
- 5.3 套利策略
- 5.4 指数增强策略
- 5.5 CAT策略
- 6 高频交易HFT
-
- 6.1 高频交易简介——速度的游戏
- 6.2 高频交易案例
1 金融基础
金融工程:金融产品与衍生产品进行组合与分解、解决方案的设计、金融产品的定价与风险管理。
1.1 金融产品
5大金融产品:股票、债券、基金、期货、期权。
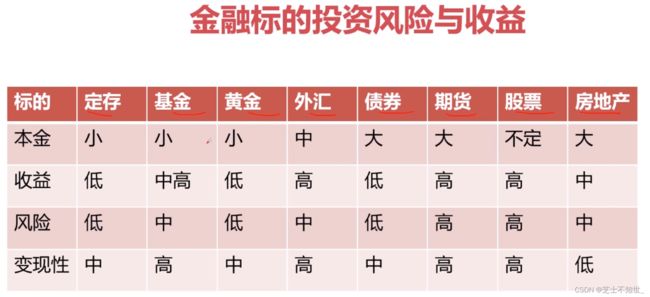
量化入门推荐做股票和ETF(风险低),不推荐直接做期货、期权(高风险)。
1.1.1 股票
本质:股票的本质是公司的部分所有权,属于权益类投资。股票是一种有价证券,有价证券除股票外,还包括国家债券、公司债券、不动产抵押债券等等。(低杠杆)

投资策略:持有股票要不断跟踪公司具体情况,公司近期经营情况、业绩情况、远期规划、战略目标、管理层的规划和执行等等,要像公司老板一样,对公司情况一清二楚。
股票策略非常多,相对而言,价值投资策略对普通人更容易一些,建议采取价值投资策略:在价格远远低于价值时再考虑买进并持有直到价格回归价值。
股票类别:
①按照上市的地点进行划分,可以分为a股,b股,h股,s股,n股。
a股(普通股票),被称为人民币普通股票,是指那些在中国大陆注册上市的股票,必须以人民币购买和交易的股票。
b股(特种股票),被称为人民币的特种股票,是指在中国大陆注册、上市的特种股票是以人民币来标明股票的面值,只能用外币认购和交易的股票。
h股(国企股),这种股票被称为国企股,指的是在香港上市的企业股票。
s股,是指那些的主要业务在中国大陆生产或者经营,但是企业的注册地在新加坡。
n股,是指那些的主要业务在中国大陆生产或者经营,但在纽约上市企业的股票。
②按照公司的业绩,可以分为绩优股,绩差股,蓝筹股,垃圾股。
绩优股:公司经营很好,业绩很好。
绩差股:公司经营不好,业绩不好。
蓝筹股:股票市场上,那些在其所属行业内占有重要支配性地位业绩优良,成交活跃、红利优厚的大公司股票。
垃圾股:经营亏损或违规的公司的股票。

·东方财富网分析股票:公司基本资料、财务数据、分析新闻公告及重大事项、行业分析、技术分析。
1.1.2 基金
本质:主动型基金的本质是专业的基金经理给你挑选的一篮子的(股票+债券+期货),被动型基金的本质是跟随某些指数,尽量完美复制指数走势。
投资策略:基金是最适合一般投资者的类别(分散不容易爆雷),基金是由专业人士进行分析市场并操作的,但是基金不一定稳赚,主动型基金需要关注基金投资方向、内容、理念还有基金经理的历史和能力,被动型基金需要关注基金所跟随着指数的内容和趋势。
基金可以采取长期定投策略,设置定期投入一定金额的资金,长期投资。在低估值时定投沪深300、中证500,到高估值时卖出,长期来看有不错的收益,甚至能击败很多基金经理。
基金分类:主动型基金、被动型基金。
1.1.3 债券
本质:债券的本质是借钱给发债对象,属于固定收益类投资。但是个人投资者能直接购买的债券有限,大部分债券都是面对机构的,一般个人投资者只能通过机构间接的购买,例如债券型基金、通过ETF来购买债券。
投资策略:债券策略建议参考美林时钟,分析宏观经济环境,在经济下行,通胀下行时债券表现更好,此时可以考虑投资债券型基金来间接投资债券。
从历史来看,债券与股票有一定负相关,有股债跷跷板现象,如果判断股票市场没有什么机会,或许债券市场是更好的选择,不过长期看来,股票能带来的年均回报率远高于债券,所以,大部分时间应该投资股票,某些特别的时期才考虑投资债券。
债券分类:
按发行主体划分:政府债券、金融债券、公司(企业 ) 债券;
按财产担保划分:抵押债券信用债券;
按债券形态分类:实物债券凭证式债券、信用债券;
按是否可转换划分:可转换债券、不可转换债券;
按付息的方式划分:零息债券、定息债券、浮息债券;
按能否提前偿还划分:可赎回债券、不可赎回债券
按债券是否记名分类:记名债券、不记名债券。
1.1.4 期货
本质:期货的本质是标准化合同,即在未来某一时间对某一品种进行指定成交数量和价格的合同,属于金融衍生品。(高杠杆)

投资策略:期货中最关键的是对未来商品价格的判断,在交割日期货价格会走向现货价格趋于一致(否则有套利空间,价差会被发现而被抹平)。某一商品价格变动最根本原因是供需关系,如果持有期货合约,要跟踪分析商品的供需情况,尤其需要对时间敏感,因为期货合约受时间影响很大。
期货有明确的成交时间,因此,不适合以年为单位持有同一份合约,如果到成交日期还未平仓,你是真的需要到实地去领商品或者卖商品的,否则违法会受到更大惩罚,所以如果做某个商品的品种,需要定期对同一个品种更换更新的一份合约。
非100%保证金的情况下,期货有爆仓风险(有的甚至还可能有穿仓风险,亏光而且还倒欠钱),在亏损达到一定程度时会触发强行平仓,因此,期货必须设置止损,必须防止因为特殊情况大波动而被强制平仓导致巨大亏损的情况。
期货与股票截然不同,股票里可以逆向投资,寻找便宜低估的公司。期货里一定要顺势而为,不能逆势,否则会遭遇重大亏损。股票有内在价值,内在价值源于公司,收益来源于分红和价差,期货只能投机,收益来源于买卖价差,是零和博弈(如果算上手续费,还是负和博弈)。
股票里可以不止损,只要公司确实是好公司,终究会价值回归,期货里一定要设置止损,否则一旦出错就会造成重大亏损
期货最好形成自己的交易系统,更注重对技术分析的运用,内含止损止盈、各种情况的概率,并且需要在实践中不断调整改善。
期货分类:
商品期货:农产品期货、金属期货、能源期货。
金融期货:股指期货。
利率期货:利率期货是指以债券类证券为标定物的期货合约,它可以避免利率波动所引起的证券价格变动的风险。
外汇期货:又称为货币期货,是一种在最终交易日按照当时的汇率将一种货币兑换成另外一种货币的期货合约。
1.1.5 期权
本质:期权与期货一样,本质是一种合约。期权买方 向 卖方支付一定代价后,有权在某一特定日期或该日之前的任何时间以固定价格购进或售出一种资产的权利。
简单的说,期权(选择权)就是使买方能获得权力,在某个日期或之前(美式期权)以某一价格买进或卖出相对应的资产。
相对的,期权合约的另一方,卖方, 在买方决定行使自己的权利时,有义务卖出或买进相对应的资产。买方为了这份期权合约将支付一定的费用,称作权益金(premium)。而卖方将收取这份费用。
投资策略:
保护性看跌期权:股票加看跌期权组合,是指购买1股股票,同时购买该股票的1股看跌期权。
抛补看涨期权:股票加空头看涨期权组合,是指购买1股股票,同时出售该股票的1股看涨期权。
多头对敲:是指同时买进一只股票的看涨期权和看跌期权,它们的执行价格、到期日都相同。
空头对敲:同时出售一只股票的看涨期权和看跌期权,它们的执行价格、到期日都相同。
1.1.6 ETF
交易型开放式指数证券投资基金ETF,跟踪“标的指数”变化、且在证券交易所上市交易的基金。投资人可以如买卖股票那么简单地去买卖“标的指数”的ETF,可以获得与该指数基本相同的报酬率。(低杠杆)
ETF通常由基金管理公司管理,基金资产为一篮子股票组合,组合中的股票种类与某一特定指数(如上证50指数)包含的成份股票相同,股票数量比例与该指数的成份股构成比例一致。
资产类型或运作模式不同,分为股票ETF、债券ETF、跨境ETF、商品ETF、交易型货币基金几类。
1.1.7 外汇
外汇 是货币行政当局以银行存款、财政部库券、长短期政府证券等形式保有的在国际收支逆差时可以使用的债权。包括外国货币、外币存款、外币有价证券(政府公债、国库券、公司债券、股票等)、外币支付凭证(票据、银行存款凭证、邮政储蓄凭证等)。
1.2 技术指标
K线图与技术指标的关系:将技术指标和K线图进行综合利用,利用历史数据,推测未来趋势,双向思考,作为分析的辅助工具。
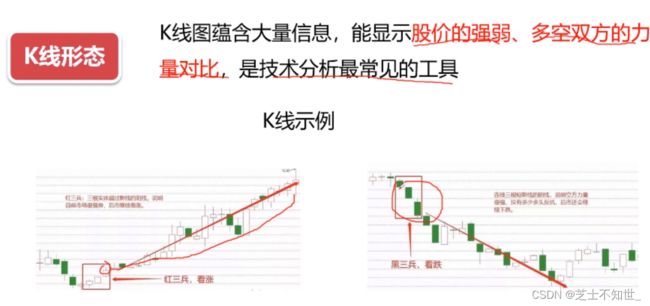
1.2.1 K线 (日本蜡烛图)
每个蜡烛包含4个关键的价格:开盘价、收盘价、最高价、最低价。反映大势的状况和价格信息。如果把每日的K线图放在一张纸上,就能得到日K线图,同样也可画出周K线图、月K线图。
阳线:价格上涨↑(牛市)。
阴线:价格下跌↓(熊市)。
字线:开盘价=收盘价,价格未来反转的信号!
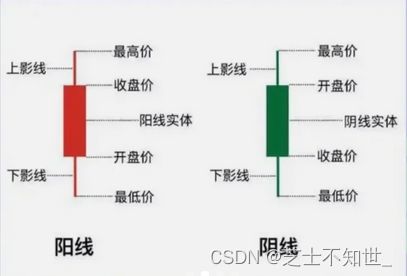
K线图的独到之处在于,利用单日的K线形态即可初步判断市场的强弱:
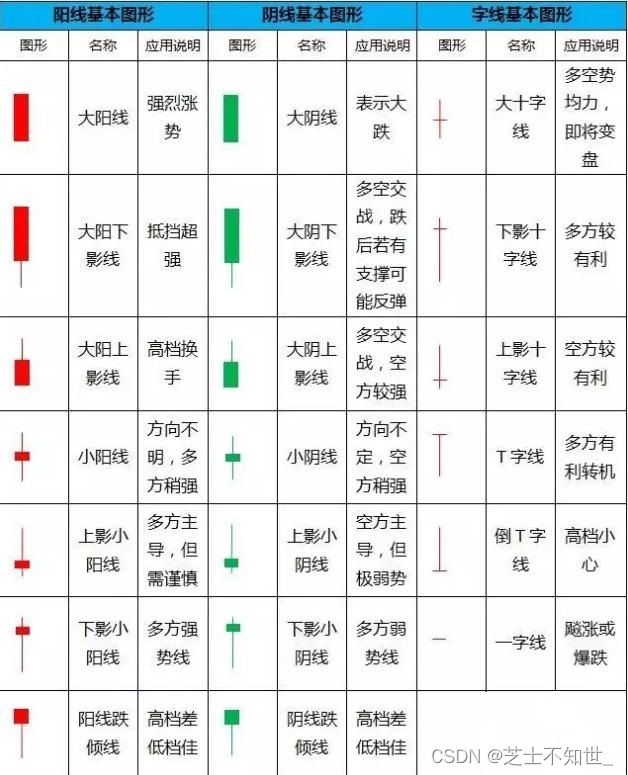
多方(多头):指看好股市而做多的一方,也就是看好而大量买股票推高股价的一方。多方有利=价格将涨。k线的实体部分越长,说明多头力量越强,后市上涨的概率越大。
空方(空头):就是对股市的未来不看好而卖出股票打压股票价格使得股票价格下挫的一方。空方有利=价格将跌。k线的实体部分越短,说明空头力量越强,后市下跌的的概率就越大。
高档是指股价的高位,一般指高价的集聚区。
低档是指股价的低位,一般是指低价的集聚区。
低挡超强(高档差低档佳):当股价调整到均线附近/前期整理平台/在价格较低的位置时,会遇到很强的支撑,股价会上涨。
高档换手(高档小心):当股价上升到一定高度是,成交量放大,换手率大增,股价很高了,小心随时卖出。这里有两种情况,一种是新庄换老庄,股价还会上涨,一种是散户换庄家,股价将下跌。
1.2.2 MA、SMA、WMA、EMA
①MA是移动平均线。
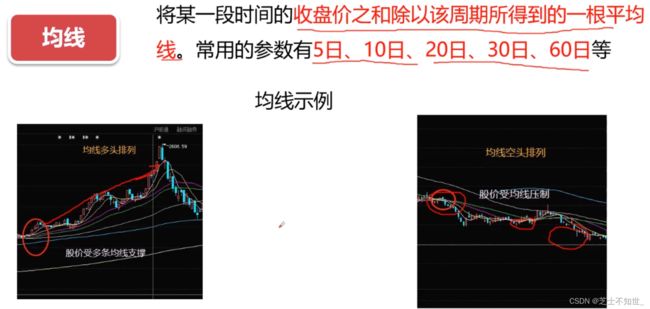
②SMA是简单移动平均线,简称均线。它是将某一段时间的收盘价之和除以该周期。比如日线MA5指5天内的收盘价除以5。
S M A ( n ) = c 1 + c 2 + . . . + c n n , ( c i 为第 i 天的收盘价 c l o s e ) SMA(n)=\frac{c_1+c_2+...+c_n}{n} , (c_i为第i天的收盘价close) SMA(n)=nc1+c2+...+cn,(ci为第i天的收盘价close)
价格(K线)在SMA线之上是呈上升趋势,价格(K线)在SMA线之下是呈下降趋势,
投资者可以根据均线理论中多头排列、空头排列来判断股票未来的走势。根据一些重要的均线来寻找支撑点、压力点,或者买入点、卖出点。比如,当股价跌破5日均线时,短线投资者可以进行卖出操作;当股价向下跌触碰5日均线之后,出现反弹向上运行的迹象,投资者可以进行买入操作。
③WMA是加权移动平均线,离今天越近的收盘价越重要,所以权重越高。
S M A ( n ) = c 1 w 1 + c 2 w 2 . . . + c n w 3 , ( c i 为第 i 天的收盘价 c l o s e , w i 为第 i 天的权重 ) SMA(n)=\frac{c_1}{w_1} + \frac{c_2}{w_2} ...+\frac{c_n}{w_3}, (c_i为第i天的收盘价close, w_i为第i天的权重) SMA(n)=w1c1+w2c2...+w3cn,(ci为第i天的收盘价close,wi为第i天的权重)
④EMA是指数平滑移动平均线
⑤VAR适应性移动平均线
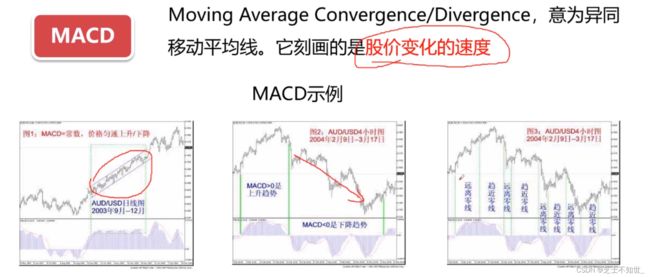
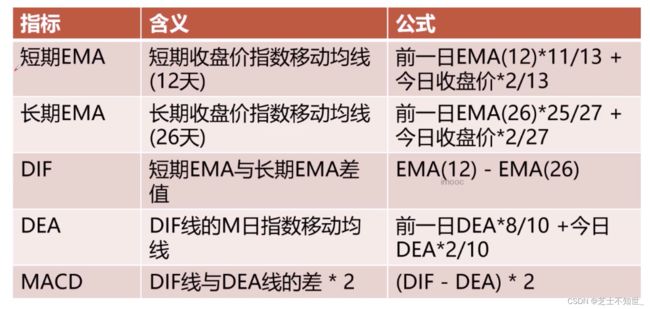
1.2.3 MACD指标和KDJ指标
MACD又称为指数平滑异同移动平均线,是从双移动平均线发展而来的。它是利用短期移动平均线(常用为12日)与长期移动平均线(常用为26日)之间的聚合与分离状况,对买进、卖出时机作出研判的技术指标。当MACD从负数转为正数,是买入的信号。当MACD从正数转为负数,是卖出的信号。当MACD以大角度变化,表示快的移动平均线和慢的移动平均线的差距迅速拉开,表达了一个市场大趋势的转变。
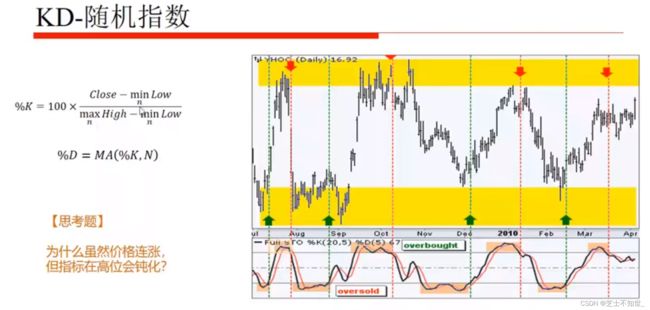
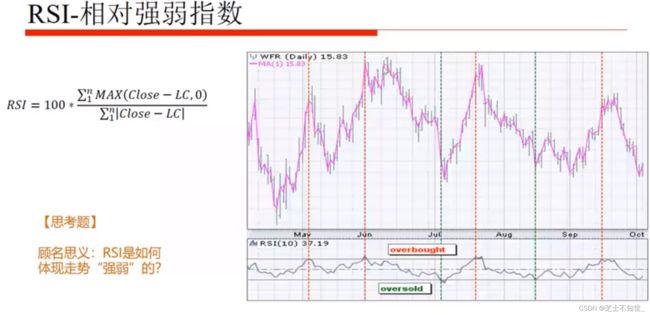
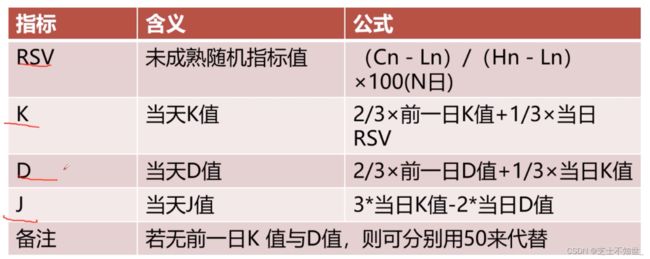
随机指标KDJ一般是用于股票分析的统计体系,根据统计学原理,通过一个特定的周期(常为9日、9周等)内出现过的最高价、最低价及最后一个计算周期的收盘价及这三者之间的比例关系,来计算最后一个计算周期的未成熟随机值RSV,然后根据平滑移动平均线的方法来计算K值、D值与J值,并绘成曲线图来研判股票走势。
当个股的MACD指标或者KDJ指标出现低位金叉时,投资者可以进行适当的买入操作;当MACD指标或者KDJ 指标出现高位死叉时,投资者可以进行适当的卖出操作。
1.2.4 BOLL指标
布林线BOLL指标,求出股价的标准差及其信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的安全高低价位,因而也被称为布林带。其上下限范围不固定,随股价的滚动而变化。
BOLL指标中的上、中、下三条轨道比较重要,当股价从上轨的上方往下运行时,投资者可以进行抛出操作;当股价受到下轨的支撑,往上运行时,可以进行建仓操作,突破中轨时,可以进行适当的加仓操作。
1.3 金融模型

.
.
2 量化交易简介
交易类型:每个人都有自己的交易风格(类型)。

量化交易:主要研究股票的客观交易(低杠杆)。

所谓量化交易,就是你总结一套股票规律(历史数据),把这套规律转化成程序可以执行的策略(模型),根据策略实现自动下单,在历史数据上进行回测优化,再在模拟盘进行回测优化,最后投入市场进行验证。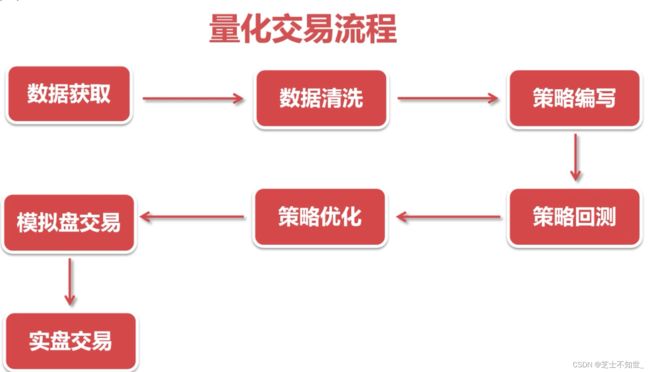
量化交易 = 核心量化策略 + 交易系统开发
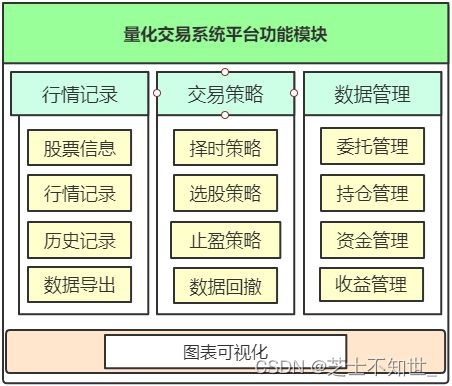

2.1 量化交易开发流程
1.数据获取
内容:行情数据、财务数据、宏观数据、舆情数据
方式:网站下载、三方API、客户端、爬虫
2.数据清洗
场景:垃圾数据清除、格式转换、空值填充、数据对齐
类库:numpy、pandas
3.策略编写(选股+择时)
信号捕捉->交易->建仓(买入)/平仓(卖出)
基本的检验策略方法有回测和模拟交易两种方法,回测是用历史数据模拟,模拟交易使用实际的实时行情来模拟执行策略的。
4.策略回测
回测是让计算机能根据一段时间的历史数据模拟执行该策略,根据结果评价并改进策略。
回测参数设置->策略实例化->历史数据载入->回测执行->计算盈亏->计算统计指标->生成回测报告
5.策略优化
重视交易费、重视风险及时退出、优化无止境。
6.模拟盘交易
模拟交易是让计算机能根据未来实际数据模拟执行该策略一段时间,根据结果评价并改进策略。
过去表现不代表未来结果(泛化性)、至少半年以上、收益至少100%以上再实盘。
7.实盘交易
实盘交易就是让计算机能自动根据实际行情,用真金白银自动执行策略,进行下单交易。
做好第一年会亏的准备、不要急于扩大投资(降低杠杆)。
量化交易平台介绍:
量化交易平台:可为量化交易研发人员提供所需的量化数据、策略框架回测框架、交易接口等功能,极大提高量化交易初学者的研发效率。常见有:聚宽、掘金量化、BigQuant、米花。我们选择聚宽平台进行量化开发。
聚宽(JoinQuant)量化交易平台:是为量化爱好者(宽客)量身打造的云平台,提供精准回测功能、高速实盘交易接口、易用的API文档、由易入难的策略库便于量化研发人员快速实现、使用自己的量化交易策略。
2.2 量化交易分类
2.2.1 按交易产品分类

1.股票策略盈利模式:股票是股份公司为筹集资金而发行给各个股东作为持股凭证,并借以取得股息和红利的一种有价证券。通过股价波动盈利(低买高卖)。
2.期权策略盈利模式:期权是一种选择权,是一种能在未来某特定时间以特定价格买卖一定数量的某种特定商品的权利。通过期权合约差价盈利(低买高卖)。
3.CTA策略盈利模式:期货是一种标准化合约,期货交易所统一制定的、约定在未来的某一个确定的日期和地点按照约定的条件买卖一定数量和质量的标的资产的标准化合约。关注价格趋势获取利差(期货与现货差价)。
4.FOF策略盈利模式:FOF基金中的基金,是一种专门投资于其他投资基金的基金。通过资产配置来分散风险、平滑波动、改善组合收益风险比,从而优化投资者的持有体验尤其是在震荡的市场背景下,FOF产品的优势尤其明显。
2.2.2 按盈利模式分类
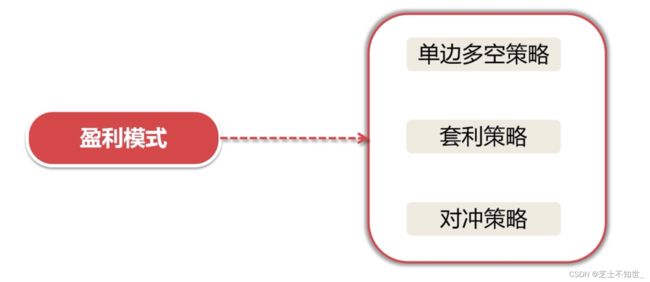 1.单边多空策略:股票
1.单边多空策略:股票低价买进,待股价出现高价单边下跌时卖出,赚取利差
2.套利策略:追求无风险套利,在金融市场利用某些金融产品价格与收益率暂时不一致的机会获得收益的策略。
3.对冲策略:对冲指特意减低另一项投资风险的投资。同时进行两笔行情相关、方向相反、数量相当、盈亏相抵的交易。对冲策略是在期货股票市场和股票市场同时进行等量反向交易,以锁定既得利润(或成本),通过抵消两个市场的损益来规避股票市场的系统性风险。做多的同时做空,市场向上时,赚钱; 市场向下时,赚钱或少亏钱。
2.2.3 按策略信号分类
量化策略:信号捕捉->交易->建仓(买入)/平仓(卖出)
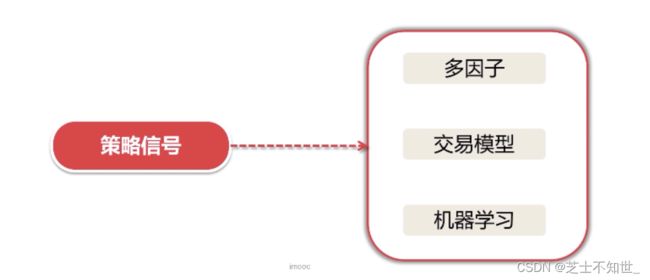
策略信号:交易信号,买入或卖出的一系列特征。
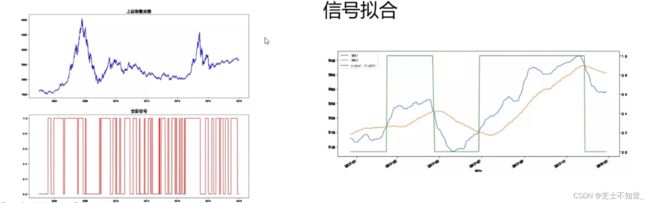
1.多因子策略:找到某些和收益率最相关的多个指标,并根据该指标,建一个股票组合,期望该组合在未来的一段时间跑赢指数(做多/建仓/买入) 或 跑输指数(做空/平仓/卖出)。
2.交易模型:基于现代多学科众多理论,以及多种金融技术分析理论,具有普遍性,可盈利可量化可执行交易系统,市场趋势符合交易模型即可盈利。
3.机器学习:从大量数据中找到某种规律,包括但不局限于文本数据nlp、图像数据cv等,找到可盈利,可量化,可执行的策略信号。区别于传统金融量化策略,从更丰富的数据维度中识别策略信号。
2.3 股票投资
2.3.1 行业分类的作用

股价:股票的交易价格,与股票的价值是相对的概念。
股票价值:是企业资产价值。而股价的价值就等于每股收益乘以市盈率。
2.3.2 股价影响因素
经济因素:主要指经济周期因素,经济衰退,股价随之下跌;经济繁荣,股价也随之上涨。
政治因素:外交的改善会使有关跨国公司股价上升;战争使各国政治经济不稳,股价下跌,但会使军工行业股价上升。
行业因素:行业在国民经济中地位的变更,发展前景和发展潜力,新兴行业的冲击等都会影响相关股票的价格。
企业因素:企业的经营业绩水平、本身的资产信用、股息红利的设定外来的发展前景等等都可以影响该企业股票价格变动。
市场因素:主要指市场交易状况、其他金融投资产品的表现、交易因素、供求关系等因素。
2.3.3 量化名词解释
标的: 靶子,就是你买卖的对象,如股票、期货、期权等金融产品。
多头: 指买方,也就是看好某个股票(或者证券)未来走势,买入或者持有该股票的一方。
空头: 就是对某个股票未来行情走势看跌,卖出或者不看好该股票的一方。
建仓: 建仓一般是指初次买入,建仓通常在投资标的价格较低时进行。
平仓: 指将账户中的有价证券全部卖出,平仓的止盈策略,在高点卖出,平仓的止损策略,防止大盘继续下跌而卖出。
滑点: 指客户下单交易点位与实际交易点位有差别的现象。订单成交需要一定时间,当下单时,价格可能会发生变化,从而导致交易者以高于或低于预期的价格进行交易。
复权: 指对股价和成交量进行了权息修复后,开始绘制股票最真实股价变动的趋势图,同时还将成交量调到相同的股本口径。复权主要是分成了向前复权和向后复权。
指数: 是指一个选股的规则,它是按照某个规则挑选出一系列的股票,根据这些挑选出来的股票进行统计的结果。指数可以反映这些股票的平均走势。每一个指数都有一个指数点数,指数点数反映的是指数背后股票的平均股价。如上证指数和深证指数等。
指数基金: 指数基金是以特定指数为跟踪标的/股票,通过复制指数成份券追求与标的指数同步的收益率的基金。
指标: 指能用具体数据来体现的指标,以一定范围内线性变换的数据反映自然界或社会的状态。
交易时间:周一至周五(法定节假日除外)上午9:30~ 11:30 下午13:00~15:00 价格优先,时间优先。
竞价成交:上午9:15~ 9:25 开盘集合竞价(成交量最大的价格),上午9:30~ 11:30 下午13:00~ 14:57 连续竞价,下午14:57~15:00收盘集合竞价(成交量最大的价格)。
交易单位:报价单位股,交易单位手,100股=1手,股价变动单位最小为0.01元。
庄家与散户:庄家:能够影响金融证券市场行情的大户投资者散户;股市中投入股市资金量较小的个人投资者。
换手率:某段时期内的成交量/发行总股数,表征该股票交易的活跃程度,10~50%非常活跃,低于1%非常不活跃。
PE市盈率:(每股市场价格)/(每股税后利润),PE越高,该企业越被高估(泡沫越大); 反之,该企业越被低估。
2.3.4 财务知识
财报:ROE净资产收益率、净利润、营业利润率增长率、净利润增长率越高越好

2.3.5 选股
选股:通过某种手段方式,提供给投资者判断个股的依据,帮助投资者选定个股的方法,选股是股票投资的第一步。选股的好坏决定了能否赚到钱。
选股方法:基本面选股:基本面是通过分析一家上市公司在发展过程中所面临的外部因素(经济增长、财政政策、利率变化)以及自身因素(经营状况、行业地位、财务状况),来预测其未来的发展前景,并以此来判断该上市公司的股票是否值得买入。
股票估值:基本面分析的核心。

每股收益:越高越好,代表公司的盈利水平。
市盈率PE::同行业市盈率越低越好、14~30倍正常、大于30属于高估、50倍以上存在泡沫。
毛利率:越高越好、毛利率大于50%属于很不错的公司。
净资产收益率:代表公司盈利能力、ROE长期保持在20%以上就是白马股。
资产负债率:适中为好,最好在10%~40%,过高容易暴雷,过低发展保守。
净利润增速:代表公司未来成长能力,近3年平均增速在20%以上属于优质企业,大约50%属于成长股。
2.3.6 择时
择时:股票买入和卖出的时机。
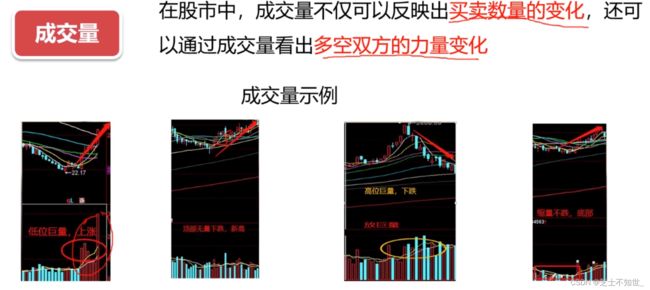
择时方法:技术分析:从K线形态、成交量、均线、布林带、MACD与KDJ等技术指标出发分析,它们是反映股价变化的指标。


2.4 量化平台
做期货,学TB
做股票,学聚款
做定制化交易框架,学VNPY


2.5 量化投资(选股+择时)
对于股票市场,量化投资主要包括量化选股、量化择时、算法交易、股票组合配置、资金或仓位管理、风险控制等。
第一阶段:选股
选股的目标是从市场上所有可交易的股票中,选出股票组合(避免单股重仓),通常称为“股票池”,并可根据自己的操作周期或市场行情变化,不定时地调整该股票池,作为下一阶段择时或调仓的基础。
量化选股的依据可以是基本面选股(分析公司的外部/内部因素),也可以是技术面选股(利用各种理论/指标预测股价),或二者的结合。常用的量化选股模型举例如下:
1、多因子模型
多因子模型:采用一系列的“因子”作为选股标准,满足这些因子的股票将作为候选放入股票池,否则将被移出股票池。这些因子可以是一些基本面指标,如 PB、PE、EPS 增长率等,也可以是一些技术面指标,如动量、换手率、波动率等,或者是其它指标,如预期收益增长、分析师一致预期变化、宏观经济变量等。多因子模型相对来说比较稳定,因为在不同市场条件下,总有一些因子会发生作用。
2、板块轮动模型
板块轮动模型:一种被称作风格轮动,它是根据市场风格特征进行投资,比如有时市场偏好中小盘股,有时偏好大盘股,如果在风格转换的初期介入,则可以获得较大的超额收益;另一种被称作行业轮动,即由于经济周期的原因,总有一些行业先启动行情,另有一些(比如处于产业链上下游的)行业会跟随。在经济周期过程中,依次对这些轮动的行业进行配置,比单纯的买入持有策略有更好的效果。
3、一致性预期模型
一致性预期模型:指市场上的投资者可能会对某些信息产生一致的看法,比如大多数分析师看好某一只股票,可能这个股票在未来一段时间会上涨;如果大多数分析师看空某一只股票,可能这个股票在未来一段时间会下跌。一致性预期策略就是利用大多数分析师的看法来进行股票的买入卖出操作。
与此类似的思路还有基于股吧、论坛、新闻媒体等对特定股票提及的舆情热度或偏正面/负面的消息等作为依据。还有一种思路是反向操作,回避羊群效应(物极必反),避免在市场狂热时落入主力资金出货的陷阱。
4、资金流模型
资金流模型:其基本思想是根据主力资金的流向来判断股票的涨跌,如果资金持续流入,则股票应该会上涨,如果资金持续流出,则股票应该下跌。所以可将资金流入流出情况编制成指标,利用该指标来预测未来一段时间内股票的涨跌情况,作为选股依据。
例. 简单的 白马股选股策略(每隔refresh_rate天调整持仓,无择时策略)
# 一:筛选条件:
# 1.总市值>50亿(市值较大的公司,流动性好,竞争力强)
# 2.上市天数>750(抛开3年以内的次新)
# 3.流通盘比例>95%(要全流通,避免解禁压力)
# 4.销售毛利率>20%(毛利率要高)
# 5.扣非净资产收益率>20%(ROE要高)
# 二:排名条件:
# 1.总市值从大到小排列
import datetime
from jqdata import *
## 初始化函数,设定要操作的股票、基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000300.XSHG')
# True为开启动态复权模式,使用真实价格交易
set_option('use_real_price', True)
# 设定成交量比例
set_option('order_volume_ratio', 1)
# 股票类交易手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
set_order_cost(OrderCost(open_tax=0, close_tax=0.001, \
open_commission=0.0003, close_commission=0.0003,\
close_today_commission=0, min_commission=5), type='stock')
# 持仓数量
g.stocknum = 20
# 交易日计时器
g.days = 0
# 调仓频率
g.refresh_rate = 100
# 运行函数
run_daily(trade, 'every_bar')
## 选股函数,返回股票列表
def check_stocks(context):
# 设定查询条件
q = query(
indicator.code,
valuation.capitalization,
indicator.roe,
indicator.gross_profit_margin,
).filter(
valuation.capitalization > 50,#1.总市值>50亿
valuation.circulating_market_cap > valuation.market_cap*0.95,#3.流通盘比例>95%
indicator.gross_profit_margin > 20,#4.销售毛利率>20%
indicator.roe > 20,#5.扣非净资产收益率>20%
).order_by(
valuation.market_cap.desc()
).limit(
100
)
df = get_fundamentals(q, statDate=str(context.current_dt)[:4])
buylist = list(df['code'])
#上市天数>750(抛开3年以内的次新)
buylist = delect_stock(buylist, context.current_dt, 750)
buylist = filter_paused_stock(buylist)[:20]
return buylist
# 过滤停牌股票
def filter_paused_stock(stock_list):
current_data = get_current_data()
return [stock for stock in stock_list if not current_data[stock].paused]
#排除次新
def delect_stock(stocks,beginDate,n=180):
#去除上市距beginDate不足6个月的股票
stockList = []
for stock in stocks:
start_date = get_security_info(stock).start_date
if start_date < (beginDate-timedelta(days = n)).date():
stockList.append(stock)
return stockList
## 交易函数,进行选股+择时交易
def trade(context):
# 每refresh_rate天调整一次持仓
if g.days%g.refresh_rate == 0:
# 选当天的白马股
stock_list = check_stocks(context)
# 获取持仓列表
sell_list = list(context.portfolio.positions.keys())
# 获取当前持仓 但不是白马股的股票列表sells
sells = list( set(sell_list).difference(set(stock_list)) )
# 先卖再买
# 卖出sells
for stock in sells:
order_target_value(stock, 0)
# 若持仓的股票数未达到stocknum ,分配资金,为每个股票均分当前资金
if len(context.portfolio.positions) < g.stocknum :
num = g.stocknum - len(context.portfolio.positions)
cash = context.portfolio.cash/num
else:
cash = 0
# 为每个白马股买入相等的cash
for stock in stock_list:
if len(context.portfolio.positions) < g.stocknum \
and stock not in context.portfolio.positions:
order_value(stock, cash)
# 天计数加一
g.days = 1
else:
g.days += 1
第二阶段:择时
择时的目标是确定股票的具体买卖时机,其依据主要是技术面。取决于投资周期或风格(例如中长线、短线,或超短线),择时策略可以从比较粗略的对股票价位相对高低位置的判断,到依据更精确的技术指标或事件消息等作为信号来触发交易动作。
一般来说,择时动作的产生可以基于日K线(或周K线),也可以基于日内的小时或分钟级别K线,甚至 tick级的分时图 等。具体的量化择时策略可以分为如下几种:
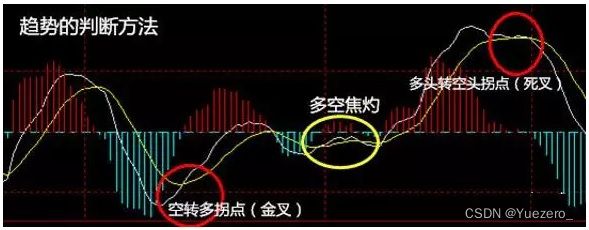
1、趋势跟踪型
趋势跟踪型策略适用于单边上升或单边下降(如果可做空的话)的行情——当大盘或个股出现一定程度的上涨和一定程度的下跌,则认为价格走势会进一步上涨或下跌而做出相应操作(买入->持有->加仓->继续持有->卖出)。

常见的趋势跟踪型策略有:短时移动均线交叉策略和长时移动均线交叉策略,均线多头排列和空头排列入场出场策略,MACD的DIFF和DEA线交叉策略等。如下图所示:
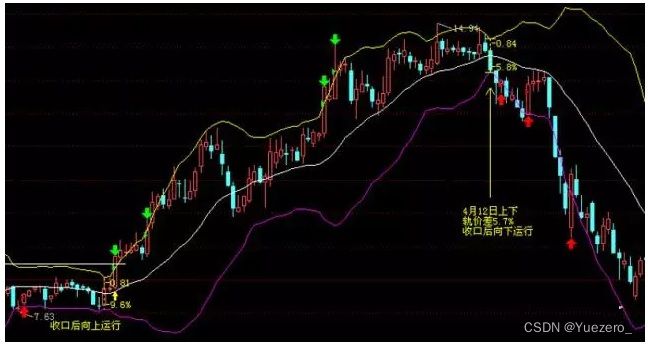
2、高抛低吸型
高抛低吸型:高抛低吸型策略适用于震荡行情——当价格走势在一定范围的交易区间(箱形整理)或价格通道(平行上升或下降通道)的上下轨之间波动时,反复地在下轨附近买入,在上轨附近卖出,赚取波段差价利润(下轨买入->上轨卖出->下轨买入->上轨卖出->…)。

常见的高抛低吸型策略一般通过震荡类技术指标,如KDJ、RSI、CCI等,来判断价格走势的超卖或超卖状态,或通过MACD红绿柱或量能指标与价格走势间的背离现象,来预测波动区间拐点的出现。如下图所示:
3、横盘突破型
横盘突破型:价格走势可能在一定区间范围内长时间震荡,总有一天或某一时刻走出该震荡区间,或者向上突破价格上轨(如吸筹阶段结束开始拉升),或者向下突破价格下轨(如主力出货完毕,或向下一目标价位跌落以寻找有效支撑),此时行情走势变得明朗。
横盘突破型策略就是要抓住这一突破震荡区间的时机果断开多或开空,以期用最有利价位和最小风险入场,获得后续利润(空仓或持仓等待机会->突破上轨则买入或平空/突破下轨则卖出或做空)。
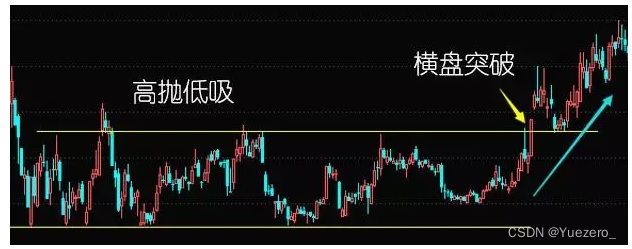
常见的横盘突破策略包括布林带上下轨突破、高低价通道突破、Hans-123、四周法则等。如下图所示:
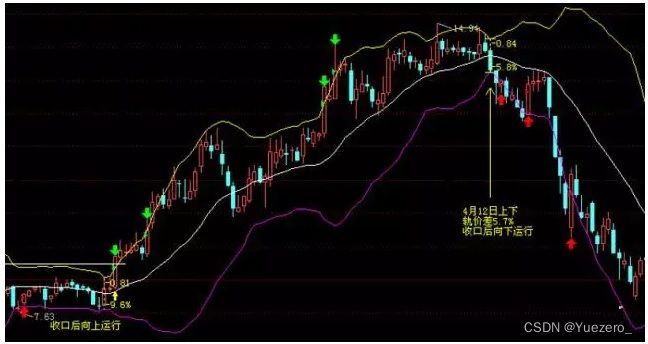
必须要强调的是,趋势跟踪型策略和高抛低吸型策略适用于完全不同的市场行情阶段——如果在单边趋势中做高抛低吸,或是在震荡行情中做趋势跟踪,则可能会造成很大亏损。
因此,对这二者的使用,最关键的是,第一要尽量准确地判断当前行情类型,第二是要时刻做好止损保护(止亏和止盈)。
此外,还有一些组合策略,先通过DMI、ATR等指标判断当前是单边牛市或熊市,还是震荡行情,然后相应地选用趋势跟踪型或高抛低吸型策略,从而得到更稳健的收益。
2.6 从量化角度重新认识指标
指标分类: 指标的作用不是一成不变的,要根据自己的理解和市场的行情,对指标进行改进。(这些指标已经是半个世纪以前的产物,因为利益相关,最先进指标并不会被公开,所以要结合自己的思考,不要当韭菜)
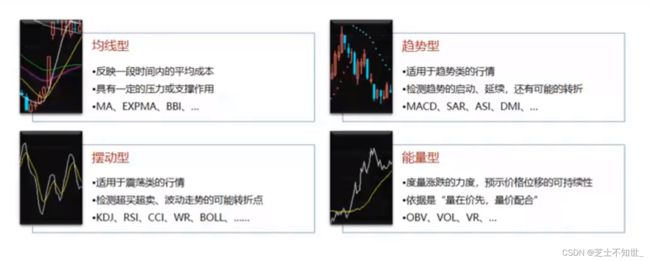
指标的编程实现:
从市场的角度,理解指标公式的含义与计算方法 -> 选择语言/平台(如下东方财富/python/TB/MC) -> 编码实现
指标的市场理解:
MA:连续几天的收盘价平均值,移动平均线MA代表市场的平均持仓成本。K线收盘价在均线之上,往往是多头趋势,价格可能进一步走高;K线收盘价在均线之下,往往是空头趋势,价格可能进一步下跌。

MACD:反映市场价格的走势,正向MACD表示上行势头较强,而负向则表明下行势头较强。


KD:
RSI:
.
.
3 股价分析基础(Numpy\Pandas\Matpolt)
数据样本格式:
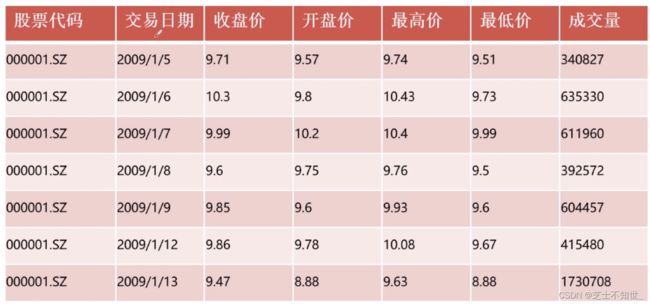
3.1 股价分析指标


实战代码:
import numpy as np
from unittest import TestCase
class TestNumpyStock(TestCase):
""" 读取指定列
numpy.loadtxt需要传入4个关键字参数:
1.fname是文件名,数据类型为字符串str;
2.delimiter是分隔符,数据类型为字符串str;
3.usecols是读取的列数,数据类型为元组tuple, 其中元素个数有多少个,则选出多少列;
4.unpack是是否解包,数据类型为布尔bool。
#"""
def testReadFile(self):
file_name = "./demo.csv"
end_price, volumn = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(2, 6),
unpack=True
)
print(end_price)
print(volumn)
# 计算最大值与最小值
def testMaxAndMin(self):
file_name = "./demo.csv"
high_price, low_price = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(4, 5),
unpack=True
)
print("max_price = {}".format(high_price.max()))
print("min_price = {}".format(low_price.min()))
# 计算极差
# 计算股价近期最高价的最大值和最小值的差值 和 计算股价近期最低价的最大值和最小值的差值
def testPtp(self):
file_name = "./demo.csv"
high_price, low_price = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(4, 5),
unpack=True
)
print("max - min of high price : {}".format(np.ptp(high_price)))
print("max - min of low price : {}".format(np.ptp(low_price)))
# 计算成交量加权平均价格
# 成交量加权平均价格,英文名VWAP(Volume-Weighted Average Price,成交量加权平均价格)是一个非常重要的经济学量,代表着金融资产的“平均”价格
def testAVG(self):
file_name = "./demo.csv"
end_price, volumn = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(2, 6),
unpack=True
)
print("avg_price = {}".format(np.average(end_price)))
# 成交量加权平均价格:成交量做为收盘价的权重
print("VWAP = {}".format(np.average(end_price, weights=volumn)))
# 计算中位数
# 收盘价的中位数
def testMedian(self):
file_name = "./demo.csv"
end_price, volumn = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(2, 6),
unpack=True
)
print("median = {}".format(np.median(end_price)))
# 计算方差
# 收盘价的方差
def testVar(self):
file_name = "./demo.csv"
end_price, volumn = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(2, 6),
unpack=True
)
print("var = {}".format(np.var(end_price)))
print("var = {}".format(end_price.var()))
# 计算股票对数收益率、年波动率及月波动率
# 波动率是对价格变动的一种度量,历史波动率可以根据历史价格数据计算得出。计算历史波动率时,需要用到对数收益率
# 年波动率等于对数收益率的标准差除以其均值,再乘以交易日的平方根,通常交易日取250天
# 月波动率等于对数收益率的标准差除以其均值,再乘以交易月的平方根。通常交易月取12月
def testVolatility(self):
file_name = "./demo.csv"
end_price, volumn = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(2, 6),
unpack=True
)
# 对数收益率,diff取差
log_return = np.diff(np.log(end_price))
# 年波动率:对数收益率的std / 对数收益率的标准差的mean * 根号下250
annual_volatility = log_return.std() / log_return.mean() * np.sqrt(250)
# 月波动率:对数收益率的std / 对数收益率的标准差的mean * 根号下12
monthly_volatility = log_return.std() / log_return.mean() * np.sqrt(12)
print("log_return = {}".format(log_return))
print("annual_volatility = {}".format(annual_volatility))
print("monthly_volatility = {}".format(monthly_volatility))
3.2 股价均线
numpy卷积:np.convolve(weights, end_price)[N - 1:-N + 1]

简单移动均线SMA:计算股价与等权重指示函数卷积的股价线。
指数移动均线EMA:根据时间把权重衰减的 股价权重卷积的股价线。
import numpy as np
import matplotlib.pyplot as plt
from unittest import TestCase
class TestNumpyMA(TestCase):
def testSMA(self):
file_name = "./demo.csv"
end_price = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=2,
unpack=True
)
print(end_price)
N = 5
# 设置卷积核为1x5大小,权重全为0.2
weights = np.ones(N) / N
print(weights)
sma = np.convolve(weights, end_price)[N - 1:-N + 1]
print(sma)
plt.plot(sma, linewidth=5)
plt.show()
def testEXP(self):
x = np.arange(5)
y = np.arange(10)
print("x", x) # exp 函数可以计算出每个数组元素的指数
print("y", y)
print("""Exp x : {}""".format(np.exp(x)))
print("""Exp y : {}""".format(np.exp(y)))
print("""Linespace : {}""".format(np.linspace(-1, 0, 5)))
def testEMA(self):
file_name = "./demo.csv"
end_price = np.loadtxt(
fname=file_name,
delimiter=',',
usecols=(2),
unpack=True
)
print(end_price)
N = 5
# 线性衰减weight
weighs = np.exp(np.linspace(-1, 0, N))
# 归一化
weighs /= weighs.sum()
print(weighs)
ema = np.convolve(weighs, end_price)[N - 1:-N + 1]
print(ema)
t = np.arange(N - 1, len(end_price))
plt.plot(t, end_price[N - 1:], lw=1.0)
plt.plot(t, ema, lw=2.0)
plt.show()
3.3 股票时间序列
时间序列:股价、汇率等数据的时间序列数据。
趋势分析:分析某时间序列在某一方向上持续运动,构建时间序列模型,预测未来股价变化,并阐述交易信号。
序列相关性:以投资品的收益序列为例,我们会观察到一段时间的收益率之间存在正相关或负相关,即收益率与时间相关。
pandas时间序列函数:
datetime():方便各种时间类型运算。
loc():对DtaeFrame进行筛选的函数,相当于SQL的select where。
groupby():对数据分组函数,相当于SSQL的GroupBy。
DataFrame:pands的基本类型DataFrame是一个csv表格的类,包含行索引index和列索引colums。pd.read_csv读入的就是一个DataFrame对象。
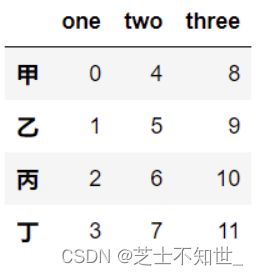
import numpy as np
# 实例化
df = pd.DataFrame(np.arange(12).reshape(3,4),columns = list('甲乙丙丁'),
index = ["one","two","three"])
# 转置
df.T
# 取行索引index:即每行名称
df.index
# 取列索引colums:即每列名称
df.columns
# 删除列
del df["甲"]
# 增加列
df["戊"] = np.arange(3)
# 增加four行
df.loc["four"] = [1,2,3,4]
代码实战:
import matplotlib.pyplot as plt
import pandas as pd
from unittest import TestCase
class TestPandasStock(TestCase):
# 读取文件
def testReadFile(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
print(df.info())
print("-------------")
print(df.describe())
# 时间处理
def testTime(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df["date"] = pd.to_datetime(df["date"])
df["year"] = df["date"].dt.year
df["month"] = df["date"].dt.month
print(df)
# 最低收盘价
def testCloseMin(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
print("""close min : {}""".format(df["close"].min()))
print("""close min index : {}""".format(df["close"].idxmin()))
print("""close min frame : {}""".format(df.loc[df["close"].idxmin()]))
# 每月平均收盘价与开盘价
def testMean(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df["date"] = pd.to_datetime(df["date"])
df["month"] = df["date"].dt.month
print("""month close mean : {}""".format(df.groupby("month")["close"].mean()))
print("""month open mean : {}""".format(df.groupby("month")["open"].mean()))
# 计算涨跌幅
# 涨跌幅今日收盘价减去昨日收盘价
def testRipples_ratio(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df["date"] = pd.to_datetime(df["date"])
df["rise"] = df["close"].diff()
df["rise_ratio"] = df["rise"] / df.shift(-1)["close"]
print(df)
# 计算股价移动平均
def testMA(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df['ma_5'] = df.close.rolling(window=5).mean()
df['ma_10'] = df.close.rolling(window=10).mean()
df = df.fillna(0)
print(df)
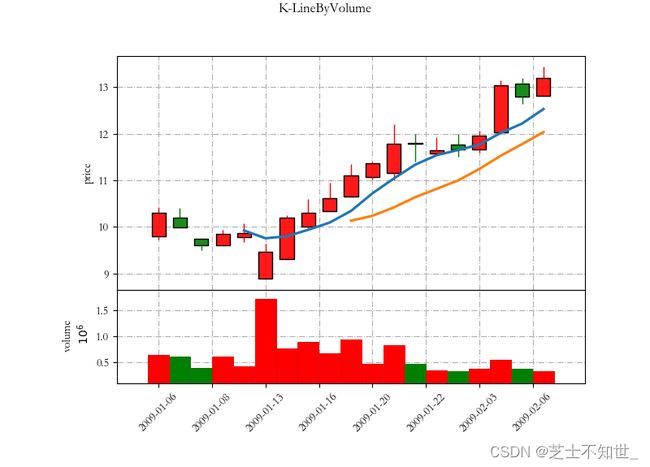
3.4 K线图

使用matplotlib和mpl_finance库绘制K线图。
import matplotlib.pyplot as plt
import pandas as pd
from mpl_finance import candlestick2_ochl
import mplfinance as mpf
from unittest import TestCase
class TestPandasKline(TestCase):
# 读取股票数据,画出K线图
def testKLineChart(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
fig = plt.figure()
axes = fig.add_subplot(111)
candlestick2_ochl(ax=axes, opens=df["open"].values, closes=df["close"].values, highs=df["high"].values,
lows=df["low"].values, width=0.75, colorup='red', colordown='green')
plt.xticks(range(len(df.index.values)), df.index.values, rotation=30)
axes.grid(True)
plt.title("K-Line")
plt.show()
# K线图带交易量
def testKLineByVolume(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df = df[["date", "close", "open", "high", "low", "volume"]]
df["date"] = pd.to_datetime(df["date"])
df = df.set_index('date')
my_color = mpf.make_marketcolors(
up='red',
down='green',
wick='i',
volume={'up': 'red', 'down': 'green'},
ohlc='i'
)
my_style = mpf.make_mpf_style(
marketcolors=my_color,
gridaxis='both',
gridstyle='-.',
rc={'font.family': 'STSong'}
)
mpf.plot(
df,
type='candle',
title='K-LineByVolume',
ylabel='price',
style=my_style,
show_nontrading=False,
volume=True,
ylabel_lower='volume',
datetime_format='%Y-%m-%d',
xrotation=45,
linecolor='#00ff00',
tight_layout=False
)
# K线图带交易量及均线
def testKLineByMA(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df = df[["date", "close", "open", "high", "low", "volume"]]
df["date"] = pd.to_datetime(df["date"])
df = df.set_index('date')
my_color = mpf.make_marketcolors(
up='red',
down='green',
wick='i',
volume={'up': 'red', 'down': 'green'},
ohlc='i'
)
my_style = mpf.make_mpf_style(
marketcolors=my_color,
gridaxis='both',
gridstyle='-.',
rc={'font.family': 'STSong'}
)
mpf.plot(
df,
type='candle',
mav=[5, 10],
title='K-LineByVolume',
ylabel='price',
style=my_style,
show_nontrading=False,
volume=True,
ylabel_lower='volume',
datetime_format='%Y-%m-%d',
xrotation=45,
linecolor='#00ff00',
tight_layout=False
)
3.5 MACD
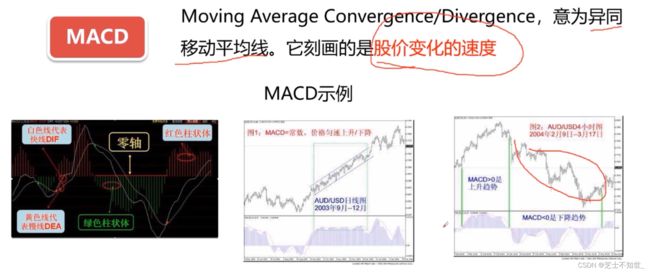
异同移动平均线 MACD 算法:
MACD实现使用的pandas函数:

代码实战:

import pandas as pd
import matplotlib.pyplot as plt
from unittest import TestCase
class TestMACD(TestCase):
# 计算MACD
def cal_macd(self, df, fastperiod=12, slowperiod=26, signalperiod=9):
ewma12 = df['close'].ewm(span=fastperiod, adjust=False).mean()
ewma26 = df['close'].ewm(span=slowperiod, adjust=False).mean()
df['dif'] = ewma12 - ewma26
df['dea'] = df['dif'].ewm(span=signalperiod, adjust=False).mean()
df['bar'] = (df['dif'] - df['dea']) * 2
return df
# 画图
def test_MACD(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df = df[["date", "close", "open", "high", "low", "volume"]]
df["date"] = pd.to_datetime(df["date"])
df_macd = self.cal_macd(df)
print(df_macd)
plt.figure()
df_macd['dea'].plot(color="red", label='dea')
df_macd['dif'].plot(color="blue", label='dif')
plt.legend(loc='best')
pos_bar = []
pos_index = []
neg_bar = []
neg_index = []
for index, row in df_macd.iterrows():
if (row['bar'] > 0):
pos_bar.append(row['bar'])
pos_index.append(index)
else:
neg_bar.append(row['bar'])
neg_index.append(index)
# 大于0用红色表示
plt.bar(pos_index, pos_bar, width=0.5, color='red')
# 小于等于0则用绿色表示
plt.bar(neg_index, neg_bar, width=0.5, color='green')
major_index = df_macd.index[df_macd.index]
major_xtics = df_macd['date'][df_macd.index]
plt.xticks(major_index, major_xtics)
plt.setp(plt.gca().get_xticklabels(), rotation=30)
plt.grid(linestyle='-.')
plt.title('000001平安银行MACD图')
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.show()
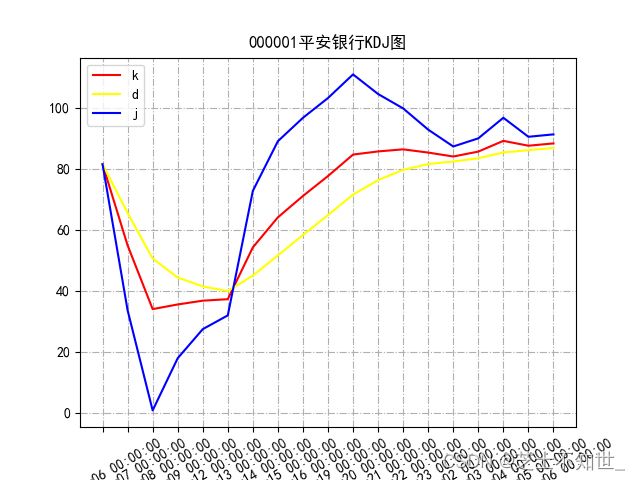
3.6 KDJ指数
K、D、J算法实现:
KDJ实现使用的pandas函数:

import pandas as pd
import matplotlib.pyplot as plt
from unittest import TestCase
class TestKDJ(TestCase):
def cal_kdj(self, df):
# 计算ln
low_list = df['low'].rolling(9, min_periods=9).min()
low_list.fillna(value=df['low'].expanding().min(), inplace=True)
# 计算hn
high_list = df['high'].rolling(9, min_periods=9).max()
high_list.fillna(value=df['high'].expanding().max(), inplace=True)
rsv = (df['close'] - low_list) / (high_list - low_list) * 100
df['k'] = pd.DataFrame(rsv).ewm(com=2).mean()
df['d'] = df['k'].ewm(com=2).mean()
df['j'] = 3 * df['k'] - 2 * df['d']
return df
def test_KDJ(self):
file_name = "./demo.csv"
df = pd.read_csv(file_name)
df.columns = ["stock_id", "date", "close", "open", "high", "low", "volume"]
df = df[["date", "close", "open", "high", "low", "volume"]]
df["date"] = pd.to_datetime(df["date"])
df_kdj = self.cal_kdj(df)
print(df_kdj)
plt.figure()
df_kdj['k'].plot(color="red", label='k')
df_kdj['d'].plot(color="yellow", label='d')
df_kdj['j'].plot(color="blue", label='j')
plt.legend(loc='best')
major_index = df_kdj.index[df_kdj.index]
major_xtics = df_kdj['date'][df_kdj.index]
plt.xticks(major_index, major_xtics)
plt.setp(plt.gca().get_xticklabels(), rotation=30)
plt.grid(linestyle='-.')
plt.title('000001平安银行KDJ图')
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.show()
def testBoll(self):
import numpy as np
from matplotlib.pyplot import plot
from matplotlib.pyplot import show
# 绘制布林带
N = 5
weights = np.ones(N) / N
print("Weights", weights)
c = np.loadtxt('demo.csv', delimiter=',', usecols=(2,), unpack=True)
sma = np.convolve(weights, c)[N - 1:-N + 1]
deviation = []
C = len(c)
for i in range(N - 1, C):
if i + N < C:
dev = c[i: i + N]
else:
dev = c[-N:]
averages = np.zeros(N)
averages.fill(sma[i - N - 1])
dev = dev - averages
dev = dev ** 2
dev = np.sqrt(np.mean(dev))
deviation.append(dev)
deviation = 2 * np.array(deviation)
print(len(deviation), len(sma))
upperBB = sma + deviation
lowerBB = sma - deviation
c_slice = c[N - 1:]
between_bands = np.where((c_slice < upperBB) & (c_slice > lowerBB))
print(lowerBB[between_bands])
print(c[between_bands])
print(upperBB[between_bands])
between_bands = len(np.ravel(between_bands))
print("Ratio between bands", float(between_bands) / len(c_slice))
t = np.arange(N - 1, C)
plot(t, c_slice, lw=1.0)
plot(t, sma, lw=2.0)
plot(t, upperBB, lw=3.0)
plot(t, lowerBB, lw=4.0)
show()
.
.
4 聚宽量化实战
4.1 量化交易策略基本框架


(基于聚宽API)
完整策略框架 = 初始化函数 + 策略函数 ( 循环执行 ) 完整策略框架 = 初始化函数 + 策略函数(循环执行) 完整策略框架=初始化函数+策略函数(循环执行)
初始化函数:通过初始化函数设置要操作的股票、基准等。初始化函数在整个回测或者实盘操作过程中只被运行一次,用于初始化全局变量。
def initialize(context): # context: Context对象,存放有当前的账户/股票持仓信息
# g为全局变量
g.security ="000001.XSHE" # 标的股票代码设定标的股票为深交所的平安银行
set_benchmark(security) # 基准:策略的业绩比较基准。在实际投资中,很多基金都使用一些核心宽基指数作为业绩基准,如沪深300、中证500指数等。
set order_cost(cost, type='stock', ref=None) # 佣金/印花税:股票类每笔交易时的手续费为:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税
set slippage(object, type='stock', ref=None) # 滑点:真实的成交价格 与 下单时预期的价格的偏差
set option('order volume ratio', value) # 成交量比例:根据实际行情 限制 每个订单的成交量
set option('use real price', value) # 动态复权模式:设置真实价格,建议开启!
# 分别为不同的策略函数设置允许时间与频率
run_daily(before_trading_start,time='9:00')
run_daily(after_trading_end,time='15:00')
run_daily(period,time='9:30') # 定时运行函数:第一个参数(策略函数名 如handle_data),第二个参数(运行频率,根据单根K线bar的频率计算,Bar就是时间维度上,价格在空间维度上变化构成的数据单元,如day天、min分钟及tick服务器刷新频率)
策略函数:策略开始后,每个周期要做的事,随着时间周期(天、分钟、月、年)重复执行你的交易策略。如果策略频率为天,是每个交易日开始生效,从9:30直到15:00(从股市开市到收市),所以例子中是每个交易日9:30开市循环就开始,一天一次地循环执行买入股票的操作。如果策略频率为分钟,是每个分钟开始时执行,所以例子中的买入股票的操作是每个交易日从9:30:00开始,然后9:31:00,直到14:59:00。接着下一天9:30:00,如此一分钟一次地循环执行的。
# 盘中运行
def period(context):
# 如果当前股票持股,就下单
if g.security not in context.portfolio.positions:
order(g.security, 1000) # 下单一千股
else:
order(g.security, -800) # 卖出八百股
# 开盘前(9:00)运行,非必要
def before_trading_start(context):
inout_cash(1000,pindex=0)
log.info("""当前仓位可用资金:{}""".format{context.portfolio.availiable_cash})
# 收盘后(15:00后半小时内)运行,非必要
def after_trading_end(context):
# 查询收盘后未完成的订单,并撤单
orders = get_open_orders()
for order in orders:
# log.info输出日志
log.info("""未完成订单:{}""".format(order))
cancel_order(order)
# 查询收盘后成功的订单
trades = get_trades()
for trade in trades:
# log.info输出日志
log.info("""成功交易订单:{}""".format(trade ))
初始化就是已存在人脑的交易思想与知识,周期循环就是每天或每分钟地查看行情、判断、下单等行为。
定时运行函数:设置您的策略什么时候运行,主要由设置策略频率(天、分钟或者tick)run_monthly/run_weekly/run_daily(func函数名, time运行时间)
time:具体执行时间,一个字符串格式的时间,有两种方式:(1) 24小时内的任意时间,例如"10:00", “01:00”;在tick频率的策略中,可以精确到秒。(2)time=“every_bar”,只能在 run_daily 中调用,运行时间和您设置的频率一致,按天会在交易日的开盘时调用一次,按分钟会在交易时间每分钟运行。
使用方法:
## func是您自己实现的策略函数
# 每分钟运行
run_daily(func, time='every_bar')
# 每天11:00定时运行
run_daily(func, time='11:00')
# 每天14:00定时运行
run_daily(func, time='14:00')
# 每天14:50定时运行
run_daily(func, time='14:50')
# 每月第一天09:30运行
run_monthly(fun, monthday=1, time='09:30')
# 每周第一天09:30运行
run_weekly(fun, weekday=1, time='09:30')
两种聚宽策略框架: 一个策略中尽量不要同时使用run_daily和handle_data,更不能使用run_daily(handle_data, “xx:xx”)!!!
框架1(老框架):API不再支持老框架的data
def initialize(context):
# 这里是用来写初始化代码的地方,例子中就是选定要交易的股票为平安银行
g.security ="000001.XSHE # g为全局变量,设定标的股票为深交所的平安银行
def handle_data(context,data):
# 这里是用来写周期循环代码的地方,例子中就是买卖平安银行的股票
if g.security not in context.portfolio.positions:
order(g.security, 1000) # 下单一千股
else:
order(g.security, -800) # 卖出八百股
框架2(新框架):推荐!
def initialize(context):
# 这里是用来写初始化代码的地方,例子中就是选定要交易的股票为平安银行
run_daily(period,time='every_bar')
g.security = '000001.XSHE'
def period(context):
# 这里是用来写周期循环代码的地方,例子中就是买100股的平安银行
order(g.security, 100)
4.2 常用下单函数API
函数order( security,amount,[style],[side],[pindex] ) ,如果创建订单成功, 则返回Order对象, 失败则返回None。函数参数说明:style,side,pindex这三个参数基本用不上。
security:标的代码string类型,比如股票、基金、期货、指数的代码。股票代码:在平时使用的股票代码+后缀,深交所(深交所股票0开头)股票代码后缀为.XSHE,如000001.XSHE,上交所股票代码(上交所股票6开头)后缀为.XSHG 如600000.XSHG。
amount:交易数量, amount>0表示买入, amount<0表示卖出。
style:订单类型,决定下的订单是市价单还是限价单,默认是None代表市价单。市价单是指投资者在交易个股时,以市场的价格成交,而限价单一般是指个股的市场价格,达到投资者指定的价格时才成交。
side:short空头/long多头。决定是开空单还是多单,默认为多单,股票只能多单,股指期货等其他品类可以开空单。
pindex:仓位号,默认为0,是在多资金仓位时选择资金仓位的,股票一般用不到。
①order(security, amount),买卖一定amount数量(单位:股)股票。security是股票代码,amount是数量,amount为负数时就是代表卖出了,国内股票买入最小单位是1手即100股。
②order_target(security, amount),通过买卖,将股票仓位调整至一定amount数量(单位:股)。security是股票代码,amount是数量,目前持股数量低于amount就买入,高于就是卖出,不高不低就不动。
③order_value(security, value),买卖一定value价值量(单位:元)股票。security是股票代码,value是价值量。value为负数时就是代表卖出了。
④order_target_value(security, value),通过买卖,将股票仓位调整至一定value价值量(单位:元)。security是股票代码,value是价值量。
其他函数:查询订单、撤单、存取金额
查询成交订单:get_orders(order id=None,security=None,status=None)
查询未完成订单:get_open_orders()
撤单函数:cancel_order(order)
账户出入金:inout_cash(cash, pindex=0)
# 向账户增加10000元
inout cash(10000,pindex=0) # cash:(浮点数,负数表示出金),pindex:(仓位号,默认为0)
# 在每天交易结束之后对未完成订单进行撤单
def after market close(context):orders=get open orders()
for _order in orders.values():
cancel order( order)
Order对象:订单对象,每个订单未必成功,由order()系列函数返回,通过ordr对象的成员属性可以访问订单信息。

Trade对象:成交的订单对象,交易后,由get_trades()函数返回。

4.3 读取Context中的数据!!!(重要)
使用 log.info("信息:{ }".format(属性名)) 输出Context和Position和Portfolio对象的信息
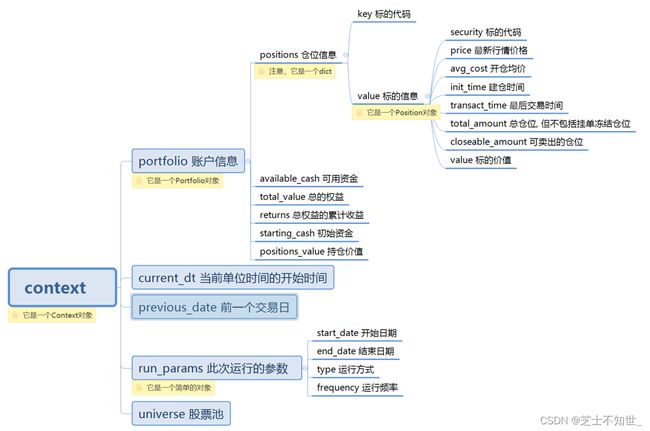
4.3.1 Context对象(策略信息)
Context保存策略信息总览,是一个回测系统建立的Context类型的对象,其中存储了如时间信息、账户信息、所持有的股票、数量、持仓成本等数据。
context内常用属性集:

常用的context数据写法如下:
-时间信息:
当前时间 context.current_dt
当前时间的“年-月-日”的字符串格式 context.current_dt.strftime("%Y-%m-%d")
前一个交易日 context.previous_date
-账户信息:
仓位subportfolios[0]可用资金 context.portfolio.subportfolios[0].available_cash
持仓金额 context.portfolio.positions_value
累计收益 context.portfolio.returns
账户总资产 context.portfolio.total_value
-持仓信息:
当前持有股票的代码 context.portfolio.positions.keys()
当前持有的某股票的开仓均价 context.portfolio.positions['xxxxxx.xxxx'].avg_cost
当前持有的某股票的可卖持仓量 context.portfolio.positions['xxxxxx.xxxx'].closeable_amount
4.3.2 Position对象(持仓信息)
Position保存持有的标的(股票)的信息,使用context.portfolio.position访问,是一个dict字典对象。
position内常用属性集:

4.3.3 Portfolio账户对象(账户信息)
Portfolio总账户信息,SubPortfolio子账户信息。
Portfolio总账户常用属性: 使用context.portfolio访问。 SubPortfolio子账户常用属性:使用
SubPortfolio子账户常用属性:使用context.SubPortfolio[0]访问。
止损:狭义的止损是指当亏损达到一定幅度后下单卖出该股票的操作,目的是减少进一步的亏损。广义则指在狭义的思路上衍生的复杂的减少亏损的方法。更多的情况下指狭义的止损。
止盈:见好就收,不要盈到最高,防止暴跌,错过最佳出售时机。
4.3 多股票策略
多股票策略:在一个策略中操作多个股票。(initialize用list数据类型存储多个股票,period用for循环操作多个股票)
def initialize(context):
run_daily(period,time='every_bar')
# 把两个股票代码作为list存入g.security中
g.security = ['000001.XSHE','000002.XSHE']
def period(context):
# 每个股票买100股
for stk in g.security:
order(stk,100)
4.4 数据获取
聚宽平台集成好的各大类数据,但实际上可能有些数据要在API文档里才比较容易能找到,比如龙虎榜数据等。这时用ctrl+f进行网页搜索可以快速搜索需要的数据。
(1)JQData和jqdatasdk是同一个产品不同的名称,是一个Python库(或模块),是聚宽提供的数据接口,在您自己搭建的本地环境中使用(可以脱离官网和客户端独立使用),具体方法见JQData的API;
(2)jqdata是官网的数据产品,主要在官网及客户端使用,具体使用方法见官网的API;
(3)jqdata和jqdatasdk中的获取数据的函数及使用方法稍微不同,使用对应的API就没问题。
4.4.1 Pandas.DataFrame数据格式
dataframe是一种二维表结构的数据类型,常用于数据处理与分析。包括index(行标签、索引)、columns(列标签)、values(值)三个部分。
# 一个dataframe类型的例子
w=attribute_history(security='000001.XSHE',count=3, fields=['money','high','open'])
print(w)
# 结果如下:
# money high open
# 2016-08-30 5.618541e+08 9.33 9.29
# 2016-08-31 4.638758e+08 9.36 9.32
# 2016-09-01 4.548486e+08 9.38 9.35
# dataframe 行列转置
print(w.T)
# 结果如下
# 2016-08-29 2016-08-30 2016-08-31
# money 5.322954e+08 5.618541e+08 4.638758e+08
# high 9.310000e+00 9.330000e+00 9.360000e+00
# open 9.280000e+00 9.290000e+00 9.320000e+00
访问方法:list(w.index)、list(w.columns)、list(w.values)
# 获取index
print(w.index)
# 结果如下,是datatimeindex类型,很特殊,不常用,建议新手回避。
# DatetimeIndex(['2016-08-30', '2016-08-31', '2016-09-01'], dtype='datetime64[ns]', freq=None, tz=None)
# 获取columns
print(w.columns)
# 结果如下,是index类型
# Index([u'money', u'high', u'open'], dtype='object')
# 可以用list()将其转成list
print(list(w.columns))
# 结果如下
# ['money', 'high', 'open']
# 获取values
print(w.values)
# 结果如下,是一个嵌套的list
# [[ 5.61854066e+08 9.33000000e+00 9.29000000e+00]
# [ 4.63875763e+08 9.36000000e+00 9.32000000e+00]
# [ 4.54848634e+08 9.38000000e+00 9.35000000e+00]]
l o c [ 行条件 , 列条件 ] loc[行条件, 列条件] loc[行条件,列条件]
选择dataframe某几列:locloc[ : , 列条件] = SQL中的select where
# 按标签获取某几列.loc[:,[列标签名,...]] 按列名
print(w.loc[:,['open','high']])
# 结果如下
# open high
# 2016-08-29 9.28 9.31
# 2016-08-30 9.29 9.33
# 2016-08-31 9.32 9.36
# 按位置获取某几列.iloc[:,[位置,...]],位置的含义是第几个,从0开始。下文同。 按下标
print(w.iloc[:,[0,2]])
# 结果如下
# money open
# 2016-08-29 5.322954e+08 9.28
# 2016-08-30 5.618541e+08 9.29
# 2016-08-31 4.638758e+08 9.32
# : 即冒号,可以代表全部,iloc或loc都可以。
print(w.iloc[:,:])
# 结果如下
# money high open
# 2016-08-29 5.322954e+08 9.31 9.28
# 2016-08-30 5.618541e+08 9.33 9.29
# 2016-08-31 4.638758e+08 9.36 9.32
# 选择后的数据依然是dataframe类型,用.values可以获取数据。对后文的行情况也成立。 按值
print(w.iloc[:,[0,2]].values)
# 结果如下,是个list
# [[ 5.61854066e+08 9.29000000e+00]
# [ 4.63875763e+08 9.32000000e+00]
# [ 4.54848634e+08 9.35000000e+00]]
选择dataframe某几行:loc[行条件, : ] = SQL中的select where
# 按标签获取某几行.loc[[行标签名,...],:]
print(w.loc[['2016-08-29','2016-08-31'],:])
# 此处这样写会报错,原因是当前的行标签类型是DatetimeIndex,不是字符串,所以使用标签名时要注意数据类型。而时间类型的数据处理往往非常麻烦,因此行或列标签名是日期情况下建议新手回避,改使用位置获取。
# 按位置获取某几行.iloc[[位置,...],:]
print(w.iloc[[0,2],:])
# 结果如下
# money high open
# 2016-08-29 5.322954e+08 9.31 9.28
# 2016-08-31 4.638758e+08 9.36 9.32
# : 即冒号,行情况下依然可以代表全部
print(w.loc[:,:])
# 结果如下
# money high open
# 2016-08-29 5.322954e+08 9.31 9.28
# 2016-08-30 5.618541e+08 9.33 9.29
# 2016-08-31 4.638758e+08 9.36 9.32
4.4.2 获取成分股
①指数成分股:一类股票 对应 一个指数,为了衡量股市中某一大类股票整体的涨跌情况,通常会用这一类的股票加权平均编制出一个指数,而这些股票则叫做该指数的成分股,一般指数的成分股选取会变动。比如上证指数是用所有上交所的股票编制而成,可以衡量上交所股票整体的涨跌情况,有的股票退市了也就会被剔除成分股。比较常见的指数有上证指数、深证综指、创业板指、沪深300指数、中证500指数、上证50指数等。
get_index_stocks(index_symbol, date=None):获取一个指数在给定日期在平台可交易的成分股列表,index_symbol: 指数代码,date: 查询日期,返回成分股票的代码list。
# 获取所有沪深300的股票
stocks = get_index_stocks('000300.XSHG')
log.info(stocks)
②指数成分股:查询指定日期,指定行业的所有股票。get_industy_stocks(industy_code, date=None): industy_code行业编码,date日期,返回成分股票的代码list。
# 获取所有行业编码为164的股票
stocks = et_industy_stocks('164')
log.info(stocks)
③概念成分股:查询指定日期,和指定概念板块(概念板块指金融概念,如5G)有关的所有股票。
get_concept_stocks(concept_code, date=None): concept_code概念板块编码,date日期,返回成分股票的代码list。
# 获取所有概念板块编码为164的股票
stocks = et_industy_stocks('sc0084')
log.info(stocks)
4.4.3 获取行情数据
股票行情数据:一个单位时间内的股票的数据。①可用SecurityUnitData的属性访问,②history和attribute_history函数获取各种field的数据(推荐)。
open: 时间段开始时价格
close: 时间段结束时价格
low: 最低价
high: 最高价
volume: 成交的股票数量
money: 成交的金额
factor: 前复权因子
avg: 这段时间的平均价
pre_close: 前一个单位时间结束时的价格
paused: 这只股票是否停牌,是则为1,否则为0
①history:获取历史数据,可查询多个股票的单个数据字段,返回数据格式为 DataFrame 。
history(count, unit='1d', field='avg', security_list=None, df=True, skip_paused=False, fq='pre')
count: 数量, 返回的结果集的行数,返回count个unit的field数据。
unit: 单位时间长度, 几天或者几分钟, 现在支持’Xd’,‘Xm’, X是一个正整数, 分别表示X天和X分钟
field: 要获取的数据类型, 包含:[‘open’, ’ close’, ‘low’, ‘high’, ‘volume’, ‘money’, ‘factor’, ‘high_limit’,’ low_limit’, ‘avg’, ’ pre_close’, ‘paused’],只能选一个!
security_list:要获取数据的股票列表,None 表示查询 context.universe 中所有股票的数据
df: 若是True, 返回[pandas.DataFrame], 否则返回一个dict。默认为True
skip_paused: 是否跳过不交易日期(包括停牌, 未上市或者退市后的日期).默认为 False
fq: 复权选项(对股票/基金的价格字段、成交量字段及factor字段生效)
# 例子 df=True,返回dataframe类型
w=history(count=3, field='money', security_list=['000001.XSHE','000002.XSHE'])
print(w)
# 结果如下:
# 000001.XSHE 000002.XSHE
# 2016-08-29 5.322954e+08 1.796321e+09
# 2016-08-30 5.618541e+08 2.072873e+09
# 2016-08-31 4.638758e+08 5.748581e+09
②attribute_history:获取一个股票的多个数据字段。
(security, count, unit='1d', fields=['open', 'close', 'high', 'low', 'volume', 'money'], skip_paused=True, df=True, fq='pre')
security:要获取数据的股票代码,None 表示查询。只能为一个!
field: 要获取的数据类型, 包含:[‘open’, ’ close’, ‘low’, ‘high’, ‘volume’, ‘money’, ‘factor’, ‘high_limit’,’ low_limit’, ‘avg’, ’ pre_close’, ‘paused’],可以选多个!
4.4.4 获取财务数据
股票财务数据 指发股票的公司发布的财务报表中的数据。财务报表简称财报,是用来向股东汇报企业经营情况的,上市公司必须按季度公布财报,一年有四季所以财报依发布次序一季报、半年报(也称中报)、三季报、年报,年报要求年度结束四个月内披露,半年报是上半年结束后两个月内,一季报与三季报是季度结束后一个月内。特别的是像总市值、市盈率这种跟股价挂钩的市值数据是每天更新的。
get_fundamentals(query_object, date=None, statDate=None)
返回一个表 [pandas.DataFrame], 每一行对应数据库返回的每一行(可能是几个表的联合查询结果的一行), 列索引是你查询的所有字段
-
query_object参数是要求传入一个Query对象用于查询表中所需数据,格式:query(表.字段).filter(条件1 and/or 条件2).order_by(排序条件).limit(返回数量上限).groupby(分组条件), query_object详细使用教程。 -
传入date时,查询指定日期date 所能看到的最近的数据。 格式类似’2015-01-15’的字符串。
-
传入statDate时, 查询 statDate 指定的季度(例如’2015q1’、 ‘2013q4’的字符串)或者年份(如’2015’、'2013’的字符串)的财务数据。
日期date和statDate参数只能传入一个: 当 date 和 statDate 都不传入时,相当于使用 date 参数,date 的默认值会为回测日期的前一天。
# 例子
# 获取 市值表.股票代码,资产负债表.未分配利润
q=query(valuation.code,balance.retained_profit
# 筛选 市值大于100 并且 市盈率小于10
).filter(valuation.market_cap>100,valuation.pe_ratio < 10
# 排序 按市值从大到小排
).order_by(valuation.market_cap.desc()
# 数量 上限10条数据
).limit(10)
w=get_fundamentals(q)
print(w)
# 结果如下:
# code retained_profit
# 0 601398.XSHG 8.566400e+11
# 1 601939.XSHG 7.400340e+11
# 2 601288.XSHG 4.644490e+11
# 3 601988.XSHG 5.267460e+11
# 4 600036.XSHG 1.816520e+11
# 5 601328.XSHG 9.208500e+10
# 6 600000.XSHG 1.037620e+11
# 7 600016.XSHG 1.277570e+11
# 8 601166.XSHG 1.573490e+11
# 9 601998.XSHG 1.298680e+11
4.4.5 获取标的(产品)信息
获取所有标的信息:获取平台支持的所有股票、基金、指数、期货、期权信息。get_all_securities(types=[], date=None)
types: 标的security种类,list类型。支持: stock,fund,index,futures等。date:获取一个字符串(格式类似2015-10-15或者datetime对象。返回:返回dataframe对象。
获取单个标的信息:返回包括中文名称,简称,上市日期退市日期,标的种类等等get_security_info(code, date=None)
code: 证券代码。date:获取一个字符串(格式类似2015-10-15)或者datetime对象。返回:返回Security(code)对象。
4.4.6 本地获取聚宽数据-JQData
申请地址: https://www.joinquant.com/default/index/sdk?f=home&m=banner
安装方法: https://www.joinquant.com/post/12479
调用方法:
from jqdatasdk import *
import jqdatasdk as jq
jq.auth('手机号', '密码')
df = jq.get_price("000001.XSHE")
print(df)
JQData使用方法
https://www.joinquant.com/data/dict/jqDataSdk
JQData提供哪些数据及数据更新频率
https://www.joinquant.com/help/api/help?name=JQData#JQData提供哪些数据及数据更新频率
JQData,jqdatasdk和jqdata的关系
https://www.joinquant.com/help/api/help?name=faq#JQDatajqdatasdk和jqdata的关系
4.5 策略实战
创建自己的显式策略:把主观灵感程序化,写成策略做回测。
如. 你觉得小市值股票过去很长一段时间内收益特别好,但最近不太行了,想验证一下:
灵感细化:
设定好要交易的股票数量stocksnum
每天找出市值排名最小的前stocksnum只股票作为要买入的股票。
若已持有的股票的市值已经不够小而不在要买入的股票中,则卖出这些股票。
买入要买入的股票,买入金额为当前可用资金的stocksnum分之一。
代码实现:
def initialize(context):
run_daily(period,time='every_bar')
# 设定好要交易的股票数量
g.stocksnum = 7
# 设定交易周期
g.period = 13
# 记录策略进行天数
g.days = 0
def period(context):
# 判断策略进行天数是否能被轮动频率整除余1
if g.days % g.period == 0:
# 代码:找出市值排名最小的前stocksnum只股票作为要买入的股票
# 获取当天的股票列表
scu = get_all_securities(date= context.current_dt).index.tolist()
# 选出在scu内的市值排名最小的前stocksnum只股票
q=query(valuation.code
).filter(
valuation.code.in_(scu)
).order_by(
valuation.market_cap.asc()
).limit(g.stocksnum)
df = get_fundamentals(q)
# 选取股票代码并转为list
buylist=list(df['code'])
# 代码:若已持有的股票的市值已经不够小而不在要买入的股票中,则卖出这些股票。
# 对于每个当下持有的股票进行判断:现在是否已经不在buylist里,如果是则卖出
for stock in context.portfolio.positions:
if stock not in buylist: #如果stock不在buylist
order_target(stock, 0) #调整stock的持仓为0,即卖出
# 代码:买入要买入的股票,买入金额为可用资金的stocksnum分之一
# 将资金分成g.stocksnum份
position_per_stk = context.portfolio.cash/g.stocksnum
# 用position_per_stk大小的g.stocksnum份资金去买buylist中的股票
for stock in buylist:
order_value(stock, position_per_stk)
# 策略进行天数增加1
g.days = g.days + 1
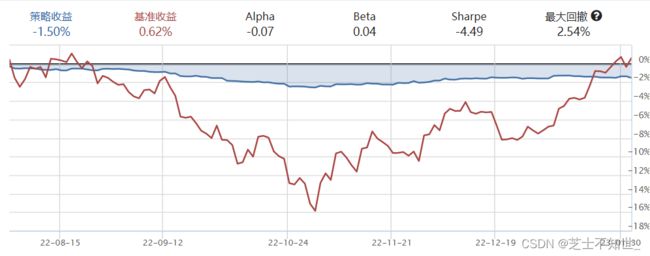
回测结果:
策略初步写完,把g.period设为13,g.stocksnum设为7,初始资金设为100000,频率为天,回测起止日期为20150101-20180627,然后进行回测。

可见15年到16年该策略表现貌似不错,但随后17年至今则表现平平。
4.6 策略评价
4.6.1 回测
回测指标:
策略收益。这是最基础的指标,衡量回测期间策略收益率的。
基准收益。基准benchmark默认是沪深300指数,所以此指标是回测期间基准benchmark的收益率。一般来说,基准收益代表市场整体的收益情况,所以如果策略收益长期低于基准收益,往往意味着策略是失败的。通过set_benchmark()这个API可以在初始化时自定义基准。
年化收益率。年化收益率是平均每年的收益率,越大越好。刚刚讲的策略收益这个指标是和回测时间长短强相关的,比如一个普通策略运行10年肯定比优秀的策略跑半年策略收益高,但这样就不利于比较策略的盈利能力。因此,通过数学方法,把策略收益统一互相化归为一年时间的收益率,比如10年的变为平均每年的收益率,半年的变为以这半年盈利能力运行一年的收益率,如此一来,让策略盈利能力在比较时有了一个大致等同的时间标准。
最大回撤率。最大回撤率是一个衡量策略风险的重要指标,越小越好。比如,你现在要实盘用真钱去跟一个策略操作,而你现在是知道这个策略的过去一段时间的历史收益曲线的,你觉得你的最大亏损率估计是多少?既然我们还在拿历史数据做回测,说明我们应当还是相信历史对未来有指导意义的,那么我现在实盘用真钱去跟策略操作,接下来我们假设策略收益的未来走势应当是跟历史走势相当的,历史走势有一直涨的时候,也有一直跌的时候,那么我实盘跟策略最大亏损率应该就是,我刚开始跟策略就开始走的跟历史走势中一直跌的那一段那样,而且是一直跌且跌的最多的那段,那么历史走势中一直跌且跌的最多的那段跌跌了多少呢?用人眼一般很容易找到是哪段,而且聚宽的回测图中也标出了。
M a x D r a w d o w n = M a x ( ( P x − P y ) / P x ) , [ 其中 P x , P y = 策略某日股票和现金的总价值, y > x ] Max Drawdown=Max((Px−Py)/Px) ,[其中Px,Py=策略某日股票和现金的总价值,y>x] MaxDrawdown=Max((Px−Py)/Px),[其中Px,Py=策略某日股票和现金的总价值,y>x]
交易次数。交易次数其实是一个可以初步衡量策略回测结果是否可靠的指标,过少往往意味着回测结果不可靠。目前,回测结果中不能直接看到交易次数了,可以通过回测结果页面的其他指标中的盈利次数与亏损次数相加得到,也可以通过回测结果图表下面的每日买卖大致看出。
Alpha(阿尔法)与Beta(贝塔)。在资本资产定价模型(CAPM)中,投资组合的收益被分为和市场系统风险相关与和市场系统风险无关的两部分,而Beta与Alpha这两个希腊字母则是该模型中的两个重要系数,分别代表这相关部分与无关部分。其实策略持有的股票可以看成一个投资组合,基准收益作为市场系统收益,Beta则是代表相关部分的策略收益相对市场波动的倍率,如Beta为2则代表市场涨1%,相关部分的策略收益波动涨大概2%(统计意义上并非实时精确),beta为负数代表与市场反向变动。而Alpha则代表独立于市场波动不受其影响的无关部分的策略收益,越大越好,所以如果策略年化收益为负但Alpha为正而且很大,说明策略有超过市场的盈利能力,不过策略整体盈利被与市场相关部分拉下来了。
夏普比率(Sharpe Ratio)。代表所承担的单位风险所带来的收益,越大越好。

4.6.2 模拟交易
回测是用历史数据模拟执行策略,模拟交易是用未来的实际行情模拟执行策略。
模拟交易面临的问题:
(1)未来函数:即指策略利用了历史当时无法得到的信息,造成回测结果极大失真。
未来函数排查方法:①一般是人工查看,重点看一切跟时间有关的地方,尤其注意各个API关于时间的默认处理方法。②当然有时未来函数隐藏的很隐蔽,而更好但稍花时间的方法是用策略建立模拟交易,一般让模拟交易运行几天,多数未来函数问题都能被发现,因为模拟交易是不可能引入未来数据的,所以往往引入未来函数的策略无法成功运行模拟交易。③一条判断策略引入未来函数的经验法则是,当你发现策略回测收益极高,回撤又极低,而且各个时间段表现都特别好,感觉自己发现了自动印钞机式的交易策略时,则此策略大概率是引入未来函数了。
(2)运行过慢:计算量会很大,极端时可能会造成交易延迟,延误买股票的时机。
解决办法:把enable_profile()这行代码复制粘贴放到策略代码的第一行。然后你成功回测后可以在回测详情页面查看性能分析的结果,从而可以查看哪行代码耗时比较多,从而有目的性的去改进。

(3)过拟合:策略(模型)一般都有一些参数(权重),如持股数量、交易频率等,选择不同的参数,固定的一份历史数据下,策略的回测结果好坏也不同。模型在训练集(回测)上好,在验证机或测试集(模拟或实盘)上不好。
解决办法:选择并优化策略的参数时,要考虑参数的鲁棒性。控制参数数量,多测几组参数大致看下参数变化对策略的影响,另外考虑进行样本外测试,即用一份样本数据回测挑选参数,用另一份样本数据回测看选择的参数在样本外情况下表现如何。
(4)策略失效:策略十分完善,并且模拟效果理想,实盘效果也很理想,但策略运行中出现历史上罕见的情形,如最大回撤创历史新高,策略收益率不再增加甚至减少等。
产生原因:策略生效的逻辑基础不再成立。比如策略的有效性是建立在涨跌停制度下的、或是建立在某行业不断成长前提下的、或是建立在全球某资源持续稀缺前提下的等,当这些制度或前提不再成立,如制度调整、新政发布、科技进步等,那么策略自然也就失效了。因此,理解策略有效的逻辑是十分重要的。操作资金量过大。更大的操作资金,会导致更大的冲击成本,即使买入时价更高、卖出时价更低,而当操作资金过大使市场流动性不足承载时,冲击成本会极大的变高,大大降低利润,甚至导致亏损。所以策略是有资金容量的,建议逐步增大策略操作资金量。市场上运行的相似策略过多。同类相似的策略都想赚市场上的同一份钱,然而这份钱是有限的,所以这些策略彼此间会竞争,导致策略赚钱变难,甚至完全失效赚不到钱。具体的表现可能是要买的股票买不到、想卖的股票卖不到理想价位等。因此,交易行业是非常注意保密且不适合分享的行业,而有志者则要注重培养自学能力。市场出现了寄生策略。当你的策略被发现市场中的有心人发现并足够程度的监测时,他可以写出一个针对你策略的策略,从而寄生在你的策略上,比如在比你买之前买入,在你买后拉升股价后卖。这种针对你策略的寄生策略,往往会压缩你策略的盈利空间,使策略失效。
(5)收益与风险的取舍: 往往策略的收益能力与抗风险能力是互相制约不能兼顾的.
取舍建议:达到基本的收益能力后,极力追求低风险,理由是盈利水平往往可以通过增加资金量来提高。具体的讲就是,策略a是一个年化收益率300%,最大回撤率50%的策略,策略b是一个年化收益率30%,最大回撤率5%的策略,只要给策略b提供相当于策略a的10倍的资金量,两者盈利能力就是一样的,但很难让策略a有像策略b一样的抗风险能力。
4.7 投资研究功能
投资研究功能就是一个Jupyter Notebook——独立空间的python环境,意思是不光是做量化交易,python支持做的事这里几乎都可以做,比如统计分析、数据可视化、数据预处理、机器学习等。
https://www.joinquant.com/view/community/detail/f31ee5245576f602bebcdc847844edfe
https://www.joinquant.com/view/community/detail/6281e8d7c5a9c58cb5d27d8bd080695d
至此,基础知识基本讲完了,但你的自学之路才刚刚开始,量化交易是不适合分享的行业,自学必不可少,有价值的内容很难会被公之于众,所以不要幻想会有特别有价值的系统的学习资源等着你去学,或是指望能把别人公开的东西直接搬来就能赚到钱。绝大多数情况都是大浪淘金式的在各种资讯中寻找着思索着只言片语。
接下来,你需要大量学习,带着批判性思维,阅读别人的博客、论文、研报和代码,多看应用案例,你会感觉到自己对数学、编程、金融知识的缺乏,可能需要你去搜索、去阅读、去询问,可能你会感觉很难搜、很难读、很少有答复,但一个基本的模式是,有一个灵感,然后去研究与实现,在过程中学习新知识,战胜新挑战,最后或成或败都获得新的认识,继续下一个灵感,从而不断前进。当然,你在前进,你渴望的答案可能也在动,就像市场一样不断变动,或向你走来,或离你远去。
5 经典量化策略(选股)
总体分为3类:
①市场中性策略:通过发现alpha因⼦赚取额外收益,收益更稳定,容量更⼤,风险更低。Alpha:投资组合的超额收益(超过市场/大盘的收益),体现管理者的能⼒。Beta:市场风险,最初主要指股票市场的系统性风险或收益(跟随市场/大盘的收益)。换句话说,跑赢⼤盘的就叫Alpha,跟着⼤盘起伏就叫Beta。适合计算机专业出身,擅长编程、机器学习、数据挖掘(量化分析)等。
主要策略:alpha策略 ( α ) (\alpha) (α)、指数增长策略 ( α + β ) (\alpha+\beta) (α+β)、多因子策略 ( α + S m a r t β ) (\alpha+Smart \beta) (α+Smartβ)、统计套利策略。
alpha策略包括:量化选股、量化择时、Alpha对冲。
统计套利策略:当两个具有相关性的不同合约之间的价差偏离其合理区间时,可以通过在期货市场同时买⼊低估值合约和卖出⾼估值合约,在价差回归后进⾏反向平仓的⽅式来进⾏跨期套利的交易。
②趋势交易策略:适合⼀些主观交易⾼⼿。主要是利⽤技术指标进⾏交易,⽐如:利⽤MACD、KDJ等等,通过这些指标来构建模型进⾏交易。适合⾦融专业出身的,对⾦融市场⾮常熟悉,⽐如:基⾦经理、交易员等。
主要策略:期货CTA策略(即属于另类投资的范畴,主要采⽤趋势跟随为主。 主要有:海龟策略、凯特那通道、布林轨等)
③⾼频交易策略:在极短的时间内进⾏,频繁的买进卖出完成⼤量的交易,对于硬件和算法都有极⾼的要求。 适合精通数学算法,及硬件编程,或者计算机较为底层的编程技能(主要开发语⾔是C/C++),适合基⾦级别的公司来操作,个⼈难度系数⽐较⾼。
量化多策略:多种量化策略共同使用。
总结:对于个人投资者,如果你做股票,那么涉及市场中性策略(alpha策略)⽐较多,涉及趋势交易⽐较少;如果你做期货,主要涉及趋势交易策略(CTA策略)、统计套利,而市场中性策略(alpha策略)涉及量⽐较⼩。
.
.
5.1 多因子策略

因子:选股的因子(股票好不好),择时的因子(好股票什么时候买)。择时往往跟技术指标关系紧密。
因子分类:
基本面因子:估值和资本结构因子valuation、成长因子indicator
技术面因子:技术因子
多因子模型表现稳定:因为在不同的市场情况下,总有一些因子发挥作用。
经典模型:套利定价理论APT模型、资本资产定价模型CAPM+套利定价理论APT的多因子模型、Fama-French三因子模型、Fama-French五因子模型
建模步骤:
(1)生成或选取因子:采集原始数据生成因子。例如我们采集15分钟周期上的MA移动平均线的数值,作为技术因子。因子的生成依据是:因子和收益率在逻辑上存在相关性,而不是凭空捏造。
(2)处理数据:因为极端值的存在会干扰我们发现数据的规律,所以对数据的一些异常值处理,包括去除空值、去极值和标准化。
(3)识别有效因子:目的是找到确实有用的因子。我们要确定因子确实和收益率存在明显的相关性,同时计算因子可能获得收益的大小。用收益率检验因子可能获得收益的大小,用IC检验因子和收益率的线性相关程度。IC告诉我们因子和收益率有没有关系,收益率检验告诉我们因子能带来多大收益。①收益率检验: 先来看因子能获得收益率的大小,barra文档里的标准做法是把因子作为自变量,下一期的收益率作为因变量,构建回归方程(这里是wls加权最小二乘法回归),回归得到的系数就是因子的收益率。②因子IC值: 接下来看因子和收益率的相关性,IC检验是常见的检验相关性的做法。学术解释:因子 IC 值反映的是下期收益率和本期因子暴露度的线性相关程度。(现在A股的因子挖掘非常残酷,常见的能想到的因子都已经被挖掘出来了。 自己挖掘因子,可以参考聚宽的因子分析https://www.joinquant.com/help/api/help#name:factor。不建议新手自己挖因子,太漫长了)
4.1 基本面因子介绍
基本面因子:评价公司的财务状况,通常包括成长类因子,规模类因子,价值类因子以及质量类因子。
成长类因子:在财务因子选股中,常用的方法是选用成长类因子进行选股。成长类因子包括营收因子(营业收入同比增长率、营业收入环比增长率、营业总收入)与利润因子(净利润同比增长率、净利润环比增长率、营业利润率、销售净利润、销售毛利率)。
规模类因子:规模类因子反映公司规模情况,主要用于体现市值大小对投资收益的影响。规模类因子包括总市值,流通市值,总股本,流通股本。
价值类因子:价值投资是一个久经考验的投资策略,惯例是购买那种相对低价的股票,转换成在基本面标准度量股息账面价值、利润、现金流或其他公司价值的方法。价值类因子包括市净率,市销率,以及市盈率。
质量类因子:质量类因子指与股票的财务质量、资本结构相关的因子。质量类因子包括净资产收益率,以及总资产净利率。
4.1.1 成长类因子选股 indicator
营业收入同比增长率:(当期营业收入-上期营业收入) /上期营业收入*100%,上期营业收入:一般指 上一年度/季度/月度同期营业收入,此处指上一年度的同期营业收入。
get_fundamentals(
query(
indicator.inc_revenue_year_on_year
).filter(查询条件)
,date=查询日期
)
# 打印 营业收入同比增长率 大于300的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.inc_revenue_year_on_year
).filter(
indicator.inc_revenue_year_on_year>300
).order_by(indicator.inc_revenue_year_on_year.desc())
,date='2022-09-01')
print(df)
# 根据以上查询出的股票代码,获取它们近5日的每日最高价
df_new=history(5,unit='1d',field='high_limit',security_list=df['code'],df=True)
print(df_new)
营业收入环比增长率:(本期营业收入的值-上一期营业收入的值) /上一期营业收入的值*100%,环比增长率是针对上一期的,而同比增长率是相对于一年度同一期的。
get_fundamentals(
query(
indicatorinc_revenue_annual
).filter(查询条件)
,date=(查询日期)
)
# 打印营业收入环比增长率大于900的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.inc_revenue_annual
).filter(
indicator.inc_revenue_annual>900
).order_by(indicator.inc_revenue_year_on_year.desc())
,date='2022-09-01')
print(df)
营收总收入:主营业务收入+其他业务收入
get_fundamentals(
query(
indicator.net_profit_to_total_revenue
).filter(查询条件)
,date=查询日期
)
# 营业总收入降序排序
df=get_fundamentals(
query(
indicator.code,
indicator.net_profit_to_total_revenue
).order_by(
indicator.net_profit_to_total_revenue.desc())
,date='2022-09-01')
print(df)
净利润同比增长率:净利润指企业的税后利润,(当期净利润-上期净利润) /上期净利润绝对值*100%,上期净利润指上一年度的同期净利润。
get_fundamentals(
query(
indicator.inc_net_profit_year_on_year
).filter(查询条件)
,date=查询日期
)
# 打印净利润同比增长率大于300的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.inc_net_profit_year_on_year
).filter(
indicator.inc_net_profit_year_on_year>300
).order_by(indicator.inc_net_profit_year_on_year.desc())
,date='2022-09-01')
print(df)
净利润环比增长率:(本期净利润-上一期净利润) /上一期净利润*100%,环比增长率是针对上一期的,而同比增长率是相对于上一年度同一期的。
get_fundamentals(
query(
indicator.inc_net_profit_annual
).filter(查询条件)
,date=查询日期
)
# 打印净利润环比增长率大于500的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.inc_net_profit_annual
).filter(
indicator.inc_net_profit_annual>500
).order_by(indicator.inc_net_profit_annual.desc())
,date='2022-09-01')
print(df[:5])
营业利润率:指经营所得的营业利润占销售净额的百分比,或占投入资本额的百分比, 营业利润/全部业务收入*100%。
get_fundamentals(
query(
indicator.operation_profit_to_total_revenue
).filter(查询条件)
,date=查询日期
)
# 打印营业利润率大于200的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.operation_profit_to_total_revenue
).filter(
indicator.operation_profit_to_total_revenue>200
).order_by(indicator.operation_profit_to_total_revenue.desc())
,date='2022-09-01')
print(df[:5])
销售净利润:指企业实现净利润与销售收入的对比关系,用以衡量企业在一定时期的销售收入获取的能力(扣税),净利润/销售收入*100%。
get_fundamentals(
query(
indicator.net_profit_margin
).filter(查询条件)
,date=查询日期
)
# 打印销售净利润最高的五个股票代码
df=get_fundamentals(
query(
indicator.code,
indicator.net_profit_margin
).order_by(indicator.net_profit_margin.desc())
,date='2022-09-01')
print(df[:5])
销售毛利率:毛利是销售净收入与产品成本的差,销售毛利率是毛利占销售净值的百分比(不扣税)。(销售净收入-产品成本) /销售净收入
get_fundamentals(
query(
indicator.gross_profit_margin
).filter(查询条件)
,date=查询日期
)
# 打印销售毛利润最高的五个股票代码
df=get_fundamentals(
query(
indicator.code,
indicator.gross_profit_margin
).
order_by(indicator.gross_profit_margin.desc())
,date='2022-09-01')
print(df[:5])
4.1.2 规模类因子选股 valuation
规模类因子:反映公司规模情况,主要用于体现市值大小对投资收益的影响。
总市值:在某特定时间内股票总价值,总股本数*股价,总市值用来表示个股权重大小或大盘的规模大小。
get_fundamentals(
query(
valuation.market_cap
).filter(查询条件)
,date=查询日期
)
# 打印总市值大于10000亿的股票代码,并降序排列
df=get_fundamentals(
query(
valuation.code,
valuation.market_cap
).filter(
valuation.market_cap>10000)
.order_by(valuation.market_cap.desc())
,date='2022-09-01')
print(df[:5])
流通市值:在某特定时间内当时可交易流通股票总价值,可交易的流通股股数*股价,流通市值占总市值的比重(流通盘比例)越大,说明股票的市场价格越能反应出公司的真实价值。
get_fundamentals(
query(
valuation.circulating_market_cap
).filter(查询条件)
,date=查询日期
)
# 打印流通市值大于5000亿的股票代码,并降序排列
df=get_fundamentals(
query(
valuation.code,
valuation.circulating_market_cap
).filter(
valuation.circulating_market_cap>5000)
.order_by(valuation.circulating_market_cap.desc())
,date='2022-09-01')
print(df[:5])
总股本:指公司已发行的普通股股份总份数 (包含A股、B股和H股的总股本),单位万股。
get_fundamentals(
query(
valuation.capitalization
).filter(查询条件)
,date=查询日期
)
# 打印总股本大于1000亿股、总市值大于8000亿的股票代码,并降序排列
df=get_fundamentals(
query(
valuation.code,
valuation.market_cap,
valuation.capitalization
).filter(
valuation.market_cap>8000,
valuation.capitalization>10000000
)
.order_by(valuation.capitalization.desc())
,date='2022-09-01')
print(df[:5])
流通股本:指公司已发行的境内上市流通的股份总份数,即A股市场的流通股本,单位万股。
get_fundamentals(
query(
valuation.circulating_cap
).filter(查询条件)
,date=查询日期
)
# 打印流通股本大于1000亿股、流通市值大于5000亿的股票代码,并降序排列
df=get_fundamentals(
query(
valuation.code,
valuation.circulating_market_cap,
valuation.circulating_cap,
).filter(
valuation.circulating_market_cap>5000,
valuation.circulating_cap>10000000)
.order_by(valuation.circulating_cap.desc())
,date='2022-09-01')
print(df[:5])
4.1.3 价值类因子选股 valuation
价值投资,是一种久经考验的投资策略。通过购买那种相对低价的股票,转换成在基本面标准度量股息账面价值、利润、现金流或其他公司价值的方法。
市净率:每股市价/每股净资产,市净率可用于股票投资分析,一般来说市净率较低的股票,投资价值较高,相反,则投资价值较低。在判断投资价值时还要考虑当时的市场环境以及公司经营情况、赢利能力等因素。
get_fundamentals(
query(
valuation.pb_ratio
).filter(查询条件)
,date=查询日期
)
# 打印市净率小于1.5、总市值大于8000亿的股票代码,并升序排列
df=get_fundamentals(
query(
valuation.code,
valuation.pb_ratio,
valuation.market_cap
).filter(
valuation.market_cap>8000,
valuation.pb_ratio<1.5)
.order_by(valuation.pb_ratio.asc())
,date='2022-09-01')
print(df[:5])
市销率:股价/每股销售额,在国内证券市场,运用这一指标来选股可以剔除那些市盈率很低但主营业务没有核心竞争力而主要是依靠非经营性损益而增加利润的股票(上市公司)。该项指标既有助于考察公司收益基础的稳定性和可靠性,又能有效把握其收益的质量水平。
get_fundamentals(
query(
valuation.ps_ratio
).filter(查询条件)
,date=查询日期
)
# 打印市净率小于1.5、市销率小于0.5的股票代码,并升序排列
df=get_fundamentals(
query(
valuation.code,
valuation.pb_ratio,
valuation.ps_ratio
).filter(
valuation.pb_ratio<1.5,
valuation.ps_ratio<0.5)
.order_by(valuation.ps_ratio.asc())
,date='2022-09-01')
print(df[:5])
(动态/静态)市盈率:动态市盈率是指还没有真正实现的下一年度的预测利润的市盈率。静态市盈率(即广泛意义上的市盈率)表示该公司需要累积多少年的盈利才能达到如今的市价水平。市盈率指标数值越小说明投资回收期越短,风险越小。
get_fundamentals(
query(
valuation.pcf_ratio # 动态
valuation.pe_ratio # 静态
).filter(查询条件)
,date=查询日期
)
# 打印动态市盈率小于6,市销率小于0.5,静态市盈率在3-5之间的股票函数,并按照静态市盈率升序排列
df=get_fundamentals(
query(
valuation.code,
valuation.pcf_ratio,
valuation.pe_ratio,
valuation.ps_ratio,
).filter(
valuation.ps_ratio<0.5,
valuation.pcf_ratio<6,
valuation.pe_ratio>3,
valuation.pe_ratio<5,)
.order_by(valuation.pe_ratio.asc())
,date='2022-09-01')
print(df[:5])
4.1.4 质量类因子选股 indicator
质量类因子指与股票的财务质量、资本结构相关的因子。影响质量因子的因素大致包括:公司的盈利能力、盈利稳定性、资本结构成长性、会计质量、派息 摊薄、投资能力等。
净资产收益率:税后利润/所有者权益x100%,净资产收益率是企业税后利润除以净资产得到的百分比率,该指标反映股东权益的收益水平,用以衡量企业运用自有资本的效率。指标值越高,说明投资带来的收益越高。(投资回报率)
# 打印净资产收益率大于50的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.roe
).filter(
indicator.roe>50
).order_by(indicator.roe.desc())
)
print(df[:10])
总资产净利率:净利润/平均资产总额x100%,总资产净利率反映的是公司运用全部资产所获得利润的水平,即公司每占用1元的资产平均能获得多少元的利润。总资产净利率越高,表明公司投入产出水平越高,资产运营越有效,成本费用的控制水平越高。
# 打印总资产净利率大于10的股票代码,并降序排列
df=get_fundamentals(
query(
indicator.code,
indicator.roa
).filter(
indicator.roa> 10
).order_by(indicator.roa.desc())
)
print(df[:10])
4.1 技术面因子介绍
技术分析指标大全
技术因子:由技术指标转化而来。一般而言,技术因子的提出是对立于成长因子而言。不同于成长因子结合财务数据等基本面指标,技术因子侧重于根据市场行情中股价和换手率等指标反映市场行为反映,用以推断价格变动趋势。
动量( Momentum ):动量指的是一段时期内证券价格向某一方向持续变动的趋势。以动量因子为主的单因子策略一般被定义为动量策略(Momentum Strategy)。在上一个观测的窗口期计算回报率(一般为观测期最后一天和第一天的收盘价差值再除以前一天的收盘价),然后计算排序,通过排序选择回报率最高的几只股票并持有。实际使用的动量指标为收盘价格在窗口期的增长率。
换手率 TR:换手率指在一定时间内市场中股票转手买卖的频率,是反映股票流通性强弱的指标之一。换手率的计算方式是一个时间窗口内(一个月)的股票交易数量除以期末的的流通股票数量。最明显的现象就是,如果一支股票的换手率较高,说明这支股票表现的比较活跃,投资者对它的参与(关注)度的较高。
换手率变动 TRC:换手率变动使用上一期的换手率减去当期换手率,如果 TRC 越大表示一个月期间换手率下降越多,相反如果 TRC 越小表明一个月中换手率增长越大。
波动率 Volatility:波动率是过去的一个月中股票的日收益率的方差,其中日收益率为当前收盘价除以上一个交易日收盘价后减 1 ,或者表述为当前收盘价与前一天收盘价之差除以前一天收盘价。需要注意的是,这里使用的是收益率而不是股票价格,收益率的好处就是可以排除股票价格本身的影响。
方差变动 VARC:方差变动( VARC )这个因子表示股票两期收益率方差的变动,是日收益率方差的变动,表述为价格变动的变动的变动。
5.2 市场中性策略
市场中性策略。其实是相对于多空而言的,看涨称为多头,看跌称为空头。那么同时持有多头和空头,我们称之为对冲。几乎所有以对冲为主的交易模式都可以称为市场中性。
5.3 套利策略
5.4 指数增强策略
5.5 CAT策略
.
.
6 高频交易HFT
6.1 高频交易简介——速度的游戏
高频交易:更准确的是超高速、低延迟low latency、持仓时间极短的交易,达到微秒us/纳秒ns级别的交易,依赖强大的硬件。区别于普通的自动化超短线交易。
高频交易策略:
流动性交易策略
(高频的低买高卖,赚取极小的差价,也增加了市场流动性)
市场微观结构交易策略(对即时的盘口数据进行搜集,根据短时间内买卖订单流的不平衡进行超短交易的策略)
事件交易策略(不断扫描各种新闻事件等消息源,及时进场买入和出场止损)
统计套利策略(寻找具有长期统计关系的证券资产,在两者价差发生偏差时进行套利)


6.2 高频交易案例








.
.