探索Apache Hudi核心概念 (2) - File Sizing
在本系列的上一篇文章中,我们通过Notebook探索了COW表和MOR表的文件布局,在数据的持续写入与更新过程中,Hudi严格控制着文件的大小,以确保它们始终处于合理的区间范围内,从而避免大量小文件的出现,Hudi的这部分机制就称作“File Sizing”。本文,我们就针对COW表和MOR表的File Sizing进行一次深度探索。本文地址:https://laurence.blog.csdn.net/article/details/129922424,转载请注明出处!
1. 运行 Notebook
本文将继续使用《Apache Hudi Core Conceptions (2) - COW: File Layouts & File Sizing》和《Apache Hudi Core Conceptions (3) - MOR: File Layouts & File Sizing》两个Notebook,对应文件分别是:2-cow-file-layouts-file-sizing.ipynb 和 3-mor-file-layouts-file-sizing.ipynb。运行前,请先修改Notebook中的环境变量S3_BUCKET,将其设为您自己的S3桶,并确保用于数据准备的Notebook:《Apache Hudi Core Conceptions (1) - Data Preparation》已经至少执行过一次。Notebook使用的Hudi版本是0.12.1,Spark集群建议配置:32 vCore / 128 GB及以上。
2. COW表的File Sizing
2.1. 关键配置
《Apache Hudi Core Conceptions (2) - COW: File Layouts & File Sizing》的第1个测试用例展示了COW表是如何控制文件大小的。测试用的数据表有三个关键配置项:
| 配置项 | 默认值 | 设定值 |
|---|---|---|
| hoodie.parquet.max.file.size | 125829120 ( 120MB ) | Default Value |
| hoodie.parquet.small.file.limit | 104857600 ( 100MB ) | Default Value |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
我们知道,在Hudi中有“大文件”和“小文件”之说,它们就来自于hoodie.parquet.max.file.size(默认值120MB)和hoodie.parquet.small.file.limit(默认值100MB)这两项配置。简单地说,在默认情况下:小于100MB的是小文件,100MB ~ 120MB 之间的是大文件,大文件的大小不一,但都不会超过120MB1。
当磁盘上有小于100MB(即hoodie.parquet.small.file.limit规定的默认值)的文件时,Hudi会将其视为“小文件”,在下次写入数据时,Hudi会优先选择复制小文件的数据,然后与输入数据一起合并写入到新文件中(即Copy On Write操作),如果一个文件超过了100MB,则它将不再参与新输入数据的Copy On Write操作。当磁盘上没有小文件的时候,Hudi就会创建新的File Group承接新数据。
不管是上述的Copy On Write操作还是新开File Group写入新数据,单一Parquet文件的体积是有最大值限制的,这个最大值就是120MB(即hoodie.parquet.max.file.size规定的默认值),如果单次写入的数据量超过了120MB,Hudi会保证单一文件最多写满120MB,超出的部分会建新的File Group写入。
回到reviews_cow_layouts_sizing_1表的配置,我们并没有修改小文件和文件上限的阈值,只是特意拿出来解释一下它们的作用,表中唯一一项修改值是hoodie.copyonwrite.record.size.estimate,在我们这个测试用例中,它是一项很有必要的配置,至于其具体作用,我们放到后面解释。
2.2. 测试计划
在该测试用例中, 我们会先后插入四批数据,然后重点观察过程中文件大小的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
|---|---|---|---|
| 1 | Insert | 96MB | +1 Small File |
| 2 | Insert | 14.6MB | +1 Big File |
| 3 | Insert | 3.7MB | +1 Small File |
| 4 | Insert | 188.5MB | +1 Max File, +1 Small File |
提示:我们将使用色块标识当前批次的Instant和对应存储文件,每一种颜色代表一个独立的File Group。
2.3. 第1批次
第1批次单分区写入了96MB数据,Hudi将其写入到一个Parquet文件中,第一个File Group随之产生。

2.4. 第2批次
第2批次单分区写入了14MB数据,由于上一批次创建的96MB文件尚未超过100MB的阈值,所以它被判定为了“小文件”,Hudi会将这个文件中的96MB数据与新插入的14MB数据合并写入到一个新的File Group中。值得注意的是:新文件的fileId并没有变,两个Parquet文件是同一个File Group的新旧两个版本。

2.5. 第3批次
第3批次单分区只写入了3.7MB,它没有和上一批次生成的那个110M的文件合并生成一个113.7MB的文件,而是“独享”了一个新文件,一个新的File Group,因为它的文件名是一个新的UUID。这一批次的写入印证了:“超过100MB后,大文件将不再参与COW操作的论断”,即上一批次生成的那个110M的文件再也不会和任何数据合并写入到新文件中了。

2.6. 第4批次
第4批次单分区写入188.5MB,我们要通过这一批次观察:当单次写入超过120MB数据时,Hudi如何分裂文件。通过输出的文件布局可以清晰地看到:首先,上一批次生成的3.7MB小文件必然会参与到这一轮的COW操作中,Hudi会根据记录的平均大小和输入数据的条数估算出输入数据的体积,将其中约116.3MB的数据(实际是按条数切分的)与3.7MB的小文件数据一起合并写入到一个120MB的文件,将剩余66MB数据(实际是按条数切分的)写入到了一个新的File Group中(实际是预先划分好,并行写入,但由于较大的文件(例如本例中的120MB文件)写入长间更长,所以文件显示的最后更新时间也往往较晚)。由于此次操作更新了一个File Group又新建了一个File Group,所以下图使用了两个色块。

2.7. 复盘
最后,让我们将此前的全部操作汇总在一起,重新看一下整体的时间线和最后的文件布局:

备注:在本节演示中,我们只使用了Insert操作来演示COW的核心逻辑,读者可以在Notebook的基础上自行尝试Update,Delete和Merge操作,会观察到Hudi更全面的行为逻辑
3. MOR表的File Sizing
3.1. 关键配置
《Apache Hudi Core Conceptions (3) - MOR: File Layouts & File Sizing》的第1个测试用例展示了MOR表是如何控制文件大小的。测试用的数据表有一个关键配置项:
| 配置项 | 默认值 | 设定值 |
|---|---|---|
| hoodie.logfile.max.size | 1073741824 ( 1GB ) | 262144000 ( 250MB ) |
与COW中的Parquet文件有所不同,MOR中的Log File只有最大值限制(默认1GB),没有所谓的“小文件”阈值,即:Log File不检查小文件,原因也不难理解,因为Log File可以看作是一种存在时间不会太长的临时文件,它们最终都会被Compact到Parquet文件中,所以不会累积大量的小文件。
此外,Log File也没有类似Parquet文件的hoodie.copyonwrite.record.size.estimate配置项,Log File的记录平均大小只能由Hudi根据上次提交的元数据进行估算,所以在后面的测试用例中,我们会看到Hudi对Log File的切分没有Parquet文件那么精准。注意,这里不是说Hudi对于Parquet和Log文件的File Sizing有什么差异,Hudi对文件大小的切分都是基于估算的,只是对于Parquet文件来说由于多了一个hoodie.copyonwrite.record.size.estimate配置项,在我们的测试用例里可以看到非常精准的文件切割(因为我们的测试数据每条记录基本都是一样大的),而Log文件没有类似配置项的支持。
3.2. 测试计划
在该测试用例中, 我们会先后插入或更新四批数据,然后重点观察过程中文件大小的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
|---|---|---|---|
| 1 | Insert | 96MB | +1 Base File |
| 2 | Update | 804KB | +1 Log File |
| 3 | Update | 1.2MB | +1 Log File +1 Base File |
| 4 | Update | 307MB | +1 Log File +1 Max Log File |
提示:我们将使用色块标识当前批次的Instant和对应存储文件,每一种颜色代表一个独立的File Slice(不是File Group,请注意和上一节的差别)。
3.3. 第1批次
第1批次单分区写入96MB数据,Hudi将其写入到一个Parquet文件中,第一个File Group随之产生,它也是后续 Log File的Base File。需要注意的一个细节是:对于MOR表来说,只有进行Compaction的那次提交才会被称为“commit”,在Compaction之前的历次提交都被称作“deltacommit”,即使对于新建Base File写入数据的那次提交也是如此,就如同这里一样。
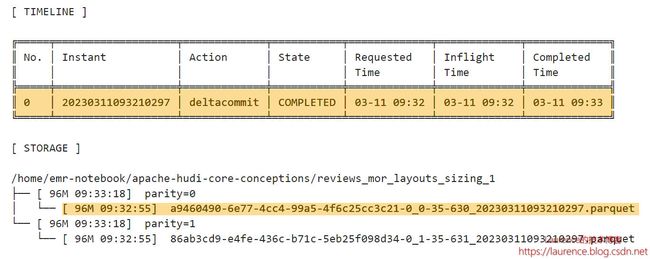
3.4. 第2批次
第2批次更新了一小部分数据,Hudi将更新数据写入到了Log文件中,大小804KB,fileVersion是1,它从属于上一步生成的Parquet文件,即Parquet文件是它的Base File ,这个Log文件的fileId和尾部的时间戳(baseCommitTime)与Parquet文件是一样的。当前的Parquet文件和Log文件组成了一个File Slice。
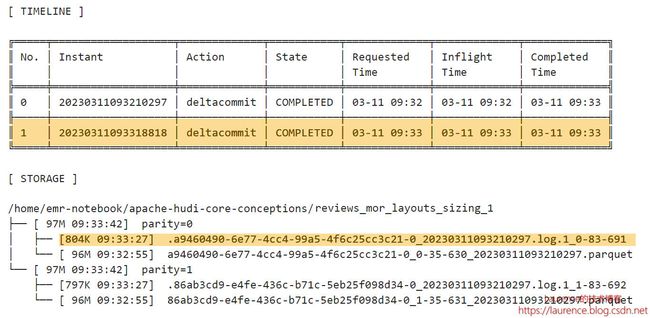
3.5. 第3批次
第3批次再次更新了一小部分数据,Hudi将更新数据又写入到一个Log文件中,大小1.2MB,fileVersion是2。与上一个Log文件一样,fileId和尾部的时间戳(baseCommitTime)与Parquet文件一致,所以它也是Parquet文件的Delta Log,且按Timeline排在上一个Log文件之后。当前的File Slice多了一个新的Log文件。
但是,不同于第2批次,第3批次的故事到这里还没有结束,在该测试用例中,当前测试表的设置是:每三次Deltacommit会触发一次Compaction,因此,第3次更新操作后就触发了第1次的Compaction操作。于是,在Timeline上出现了一个commit(No.3)。同时,在文件系统上,生成了一个新的96MB的Parquet文件,它是第一个Parquet文件连同它的两个Log文件重新压缩后得到的,这个新的Parquet文件fileId没变,但是instantTime变成了Compaction对应的commit时间,于是,在当前File Group里,第二个File Slice产生了,目前它还只有一个Base File,没有Log File。
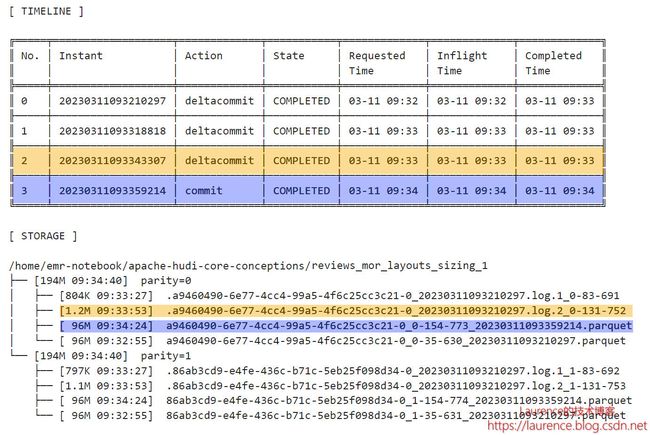
3.6. 第4批次
第4批次更新了全部数据,总的更新数据量达到了307MB2,由于当前测试表的Log File体积上限被设定为250MB,于是,Hudi需要将这批更新数据分拆成两个Log File写入,其中一个大小会在250MB上下,另一个就应该在57MB上下,最终落地的文件一个是268MB,另一个是39MB,产生偏差的原因就是我们在3.1节解释的,这是Hudi的估算结果,无法做到精准切分,这种偏差不会有什么影响。两个Log File的fileId和尾部的时间戳(baseCommitTime)与第二个Parquet文件一致,它们属于第二个File Slice,

3.7. 复盘
最后,让我们将此前的全部操作汇总在一起,重新看一下整体的时间线和最后的文件布局:

备注:在本节演示中,我们主要使用了Update操作来演示MOR的核心逻辑,读者可以在Notebook的基础上自行尝试Insert,Delete和Merge操作,会观察到Hudi更全面的行为逻辑
4. 揭秘默认行为
相信应该有不少读者都做过向Hudi表中插入数据然后观察文件变化的实验,如果你使用的都是默认配置,那么大概率是无法复现像第2节那样“教科书式”的行为的,特别是在初始的几轮操作中,Hudi的表现让人“琢磨不透”。在《Apache Hudi Core Conceptions (2) - COW: File Layouts & File Sizing》 的第2个测试用例中,我们就使用了全默认配置观察COW表的File Sizing行为,当第1批数据插入时,情形就已经很“迷惑”了,因为你将看到这样的结果:

第1批单分区插入了99MB数据,按照我们此前的理解,此时应该生成一个99MB的Parquet文件才对,而现在的状况是:Hudi一次就创建了5个Parquet文件,分属5个File Group,且每个文件都不超过21MB,好像此前建立起来的秩序瞬间“崩塌”了。
是的,一定是哪里还有我们没掌握的知识盲区。此前我们一直留着一个配置项没有解释,如果对比一下:《Apache Hudi Core Conceptions (2) - COW: File Layouts & File Sizing》的第1和第2测试用例的Hudi配置,你就会发现,其实它们就差了一个配置项:hoodie.copyonwrite.record.size.estimate,正是前文没有解释的那项配置。该项配置用于指定记录的平均大小,Hudi会利用该值和输入记录的条数计算落地文件可能的大小,以便提前对输入数据进行切分,保证落地的文件不会超过设定的阈值。如果用户没有显式地配置该项,在第1次插入时,Hudi会使用默认值1024(即1KB)作为记录的平均大小进行估算,进而决定如何切分文件。
现在,我们来推导一下上一步默认配置下发生的“故事”: 初始插入的是2003年的全年数据,总计1155127条,划分到单分区是577564条,由于没有给出记录平均大小的参考值,且是第一次提交,没有历史数据可以借鉴,所以Hudi只能按默认的1KB进行估算,由于单个文件的体积上限是120MB,所以单个文件最多只能写入120MB ÷ 1KB = 122880条记录,因此单分区的577564条记录需要划分成5份写入5个文件中,其中4份是122880条记录,第5份是577564 - 122880 * 4 = 86044条记录,以上就是Hudi基于记录平均大小为1KB的前提计算出的文件切分方案,如果记录的平均大小真得是1KB,则插入后单分区应该出现4个120MB和1个84MB的文件,但我们测试数据的平均大小实际只有175个字节,是估算值1KB的17%,因此实际落地的文件体积也“缩水”成了估算值的17%,所以最终大家看到的是4个21MB和1个15MB的文件。
实际上,hoodie.copyonwrite.record.size.estimate并不是一个非常重要的配置项,因为如果不显式地配置它,Hudi会根据上次提交的元数据动态计算记录的平均大小,这一点在我们第2个测试用例的第2步就显现出来了:

在第2步测试中,我们向单分区插入了417MB的数据,正常情况下,这些数据应该能填充3个Max File(120MB)和一个Small File,从实际的输出结果来看,Hudi较第一次的“迷惑”行为“理性”了很多,它确实生成了3个116MB的大文件和1个68MB的小文件。这次行为看上去合理很多的原因在于:由于此前已经进行了一次提交,所以Hudi可以从前一次提交的元数据中估算出纪录的平均大小,这个估算值要比一开始使用的默认值1024“靠谱”的多,所以整体行为也合理了许多,至于为什么没有写到120MB是因为估算总会一定的误差,在实际系统中,我们很少能看到正正好好的120MB文件。
关于作者:耿立超,架构师,著有 《大数据平台架构与原型实现:数据中台建设实战》一书,多年IT系统开发和架构经验,对大数据、企业级应用架构、SaaS、分布式存储和领域驱动设计有丰富的实践经验,个人技术博客:https://laurence.blog.csdn.net
有多种特殊情况会使得数据文件突破120MB的限制,例如使用了SIMPLE HASHING的BUCKET INDEX,启用了Clustering等,此外,一个值得记录的情况是:如果在COW表里更新一个已经是大文件里的数据,在COW和索引机制的共同作用下,更新数据和原有数据(已经超过100BM)会继续合并写入新文件,此时文件体积可能会突破120MB ↩︎
相同的记录数量下,Log文件的体积往往要比Parquet文件大很多,这和Log文件的结构以及使用的AVRO格式有关。所以在这个Case里,单分区下存储全部数据的Parquet文件只有96MB,而存储全部数据的Log文件却达到了307MB ↩︎