零样本参考图像分割 Zero-shot Referring Image Segmentation with Global-Local Context Features 论文笔记
零样本参考图像分割 Zero-shot Referring Image Segmentation with Global-Local Context Features 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 零样本迁移
- 零样本密度预测任务
- 参考图像分割
- 四、方法
-
- 4.1 框架总览
- 4.2 Mask 引导的全局-局部视觉特征
-
- 全局上下文视觉特征
- 局部上下文视觉特征
- 全局-局部上下文视觉特征
- 4.3 全局-局部文本特征
- 五、实施细节
-
- 5.1 全局-局部视觉编码器中的掩码
-
- ResNet 中的掩码注意力池化
- ViT 中的 Token 掩码
- 六、实验
-
- 6.1 数据集和指标
- 6.2 Baselines
- 6.3 结果
-
- 主要结果
- 未知域上的零样本评估
- 在少样本设置下与有监督方法的比较
- 6.4 消融实验
-
- 掩码质量的效果
- 全局-局部上下文特征的效果
- 定性分析
- 七、结论
- 补充材料 A:全局-局部上下文特征的分析
-
- 数据集统计
- 全局-局部上下文特征的有效性
- 采用 SpaCY 的目标名词短语提取
- 补充材料 B:超参数 α \alpha α、 β \beta β 的分析
- 补充材料 C:ViT 中 Token 掩码的消融研究
- 补充材料 D:附加的定量结果
-
- 更多的定量结果
- 对定量结果的定量支持
写在前面
新的一周开始了,冲冲冲~
- 最近 Segment Anything 爆火,感觉一些方向可能就此终结了,比如少样本、零样本以及视频领域,但是新的方向也应该会源源不断涌出,切勿悲观~
- 论文地址:Zero-shot Referring Image Segmentation with Global-Local Context Features
- 代码地址:https://github.com/Seonghoon-Yu/Zero-shot-RIS
- 收录于:CVPR 2023
一、Abstract
首先给出参考图像分割 Referring Image Segmentation (RIS) 的定义,指出数据收集的困难。于是本文通过 CLIP 模型提出零样本的 RIS。建立 mask 引导的视觉编码器,用于捕捉全局和局部的上下文信息。利用离线 mask 生成技术得到输入图像中每个实例的 mask。引入一个全局-局部文本编码器编码整个句子的语义和目标名词短语的局部特征。实验表明效果很好甚至超过一些弱监督 RIS 方法。
二、引言
引出 CLIP,点明零样本能力强,但不能直接用于稠密预测任务,如目标检测和实例分割。有一些任务尝试微调,但是成本大。
RIS 同样需要的大量的标注,于是最近出现了弱监督 RIS 方法,但同样需要高质量的图像-文本对标注,并且性能很差。于是本文提出从预训练的 CLIP 中执行零样本迁移到 RIS。
接下来是对 RIS 任务的难点介绍,以及一些零样本视觉方法不能直接迁移的原因。

本文提出采用预训练的 CLIP 模型执行零样本 RIS,其中图像和文本表示采用同一种方法进行全局和局部上下文信息的提取。具体来说:提出 mask 引导的视觉编码器捕捉图像中给定 mask 的全局和局部上下文信息,提出全局-局部上下文编码器捕捉整个句子中的全局上下文信息和名词短语中的局部上下文信息。
主要贡献如下:
- 第一个提出基于 CLIP 的零样本 RIS 方法;
- 提出的视觉和文本编码器以同一样式分别整合图像和文本的全局和局部的上下文信息;
- 提出的全局-局部上下文特征充分利用了 CLIP 模型的优势来捕捉目标语义及视觉文本之间的关系。
- 实验效果很牛。
三、相关工作
零样本迁移
传统的零样本学习的定义,早期的方法的介绍,最近的方法:CLIP、ALIGN。还有一些方法直接应用 CLIP 的编码器进行语义分割和参考表达式理解,短语定位、目标定位等,本文重点关注 RIS。
零样本密度预测任务
最近 CLIP 模型在目标检测、实例分割上大范围应用。但主要问题在于 CLIP 学习的是图像级别特征。于是有一些方法在尝试解决这一问题:ViLD 先裁剪后提取特征进行分类,Adapting CLIP 使用超像素产生高分辨率的空间特征图,MaskCLIP 修改 CLIP 的结构。而本文关注 CLIP 的全局-局部上下文视觉特征的提取。
参考图像分割
RIS 的目的,早期的方法,最近两分支的方法、基于注意力的编码器融合、基于 Transformer 解码器的跨模态解码器融合,基于 CLIP 的方法。然而这些全监督方法需要稠密的标注和大量的语言描述。TSEG 提出一种弱监督 RIS 方法,但仍需要高质量的参考表达式标注,因此,本文提出一种无须训练或者监督的零样本 RIS。
【TSEG】Robin Strudel, Ivan Laptev, and Cordelia Schmid. Weaklysupervised segmentation of referring expressions. arXiv preprint arXiv:2205.04725, 2022. 1, 3, 6, 7
四、方法

4.1 框架总览
RIS 的关键:在同一个共享的 embedding 空间内学习图像和文本表示。
如图 2 所示,框架由两部分组成:全局-局部视觉编码器 + 全局-局部自然语言编码器。
首先通过一个无监督的 mask 生成器产生一组 mask proposals,然后为每个 mask proposal 提取两组视觉的全局上下文和局部上下文特征。全局上下文特征表示 mask 及其周围区域,而局部上下文视觉特征捕捉特定 mask 区域内的局部上下文特征。
对于参考表达式,首先通过 CLIP 文本编码器提取全局的文本表示,然后利用一个依赖分析器 spaCy 从句子中提取关键名词短语,然后将全局特征和名字短语特征结合。
由于 CLIP 模型中的视觉和文本特征在同一 embedding 空间上,因此零样本 RIS 任务表述如下:
给定输入图像 I I I,参考表达式 T T T,旨在找到所有 mask proposl 的视觉特征和文本特征中有着最大相似度的那一个:
m ^ = arg max m ∈ M ( I ) sim ( t , f m ) \hat{m}=\arg\max\limits_{m\in M(I)}{\text{sim}}(\mathbf{t},\mathbf{f}_m) m^=argm∈M(I)maxsim(t,fm)其中 sim ( ⋅ , ⋅ ) {\text{sim}(\cdot,\cdot)} sim(⋅,⋅) 为 cosine 相似度, t \mathbf{t} t 为参考表达式 T T T 的全局-局部文本特征, f \mathbf{f} f 为 mask 引导的全局-局部视觉特征, M ( I ) M(I) M(I) 为图像 I I I 的 mask proposals 集合。
4.2 Mask 引导的全局-局部视觉特征
CLIP 旨在学习图像水平的表示,因此并不适合像素级别的稠密预测任务。于是将 RIS 分解为两个子任务:mask proposal 生成以及 mask 图像-文本匹配。
采用离线的、无监督的,实例级别的 mask 生成器提取 mask proposals。通过显式地使用 mask proposals,提出的方法能够利用 CLIP 解决细粒度的实例分割问题。
全局上下文视觉特征
对于每个 mask proposal,首先利用 CLIP 提取全局上下文的视觉特征。
CLIP 有两种类型的视觉编码器 ResNet 和 ViT。对于 ResNet,将不含池化层的视觉特征提取器记为 ϕ f \phi_\mathbf{f} ϕf,对应的注意力池化层为 ϕ a t t \phi_{att} ϕatt,这两个组合成 CLIP 中的视觉编码器 ϕ CLIP \phi_\text{CLIP} ϕCLIP,表示如下:
f = ϕ CLIP ( I ) = ϕ att ( ϕ f ( I ) ) \mathbf{f}=\phi_{\text{CLIP}}(I)=\phi_{\text{att}}(\phi_\mathbf{f}(I)) f=ϕCLIP(I)=ϕatt(ϕf(I))ViT 有着多个多头注意力层,于是将视觉编码器划分为两部分:最后 k k k 层和其它层,前者记为 ϕ att \phi_{\text{{att}}} ϕatt,后者记为 ϕ f \phi_f ϕf。
给定图像 I I I 和一个 mask m m m,全局上下文视觉特征定义为:
f m G = ϕ a t t ( ϕ f ( I ) ⊙ m ˉ ) \mathbf{f}_m^G=\phi_\mathrm{att}(\phi_\mathbf{f}(I)\odot\bar m) fmG=ϕatt(ϕf(I)⊙mˉ)其中 m ˉ \bar m mˉ 为调整尺寸为特征图大小后的 mask, ⊙ \odot ⊙ 为 Hadamard 乘积。
局部上下文视觉特征
首先裁剪出图像中的 mask 区域,然后送入 CLIP 视觉编码器得到局部上下文特征 f m L \mathbf{f}^L_m fmL:
f m L = ϕ CLIP ( T crop ( I ⊙ m ) ) \mathbf{f}^L_m=\phi_{\text{CLIP}}(\mathcal{T}_{\text{crop}}(I\odot m)) fmL=ϕCLIP(Tcrop(I⊙m))其中 T crop ( ⋅ ) \mathcal{T}_{\text{crop}}(\cdot) Tcrop(⋅) 为裁剪操作。
全局-局部上下文视觉特征
全局局部上下文视觉特征计算如下:
f m = α f m G + ( 1 − α ) f m L \mathbf f_m=\alpha\mathbf f_m^G+(1-\alpha)\mathbf f_m^L fm=αfmG+(1−α)fmL其中 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1] 为常数, m m m 为 mask proposal, f G \mathbf f^G fG、 f L \mathbf f^L fL 分别为 全局上下文和局部上下文特征。于是每个 mask proposal 的得分可以通过计算 f m \mathbf f_m fm 和文本表达式的特征相似度得到。
4.3 全局-局部文本特征
给定参考表达式 T T T,利用 CLIP 文本编码器 ψ CLIP \psi_{\text{CLIP}} ψCLIP 提取全局句子特征 t G \mathbf{t}^G tG:
t G = ψ CLIP ( T ) \mathbf{t}^G=\psi_{\text{CLIP}}(T) tG=ψCLIP(T)
由于参考表达式通常包含多个线索,使得文本特征很难关注表达式中的特定名词,于是利用依赖分析 spaCy 找到目标名词短语 NP ( T ) {\text{NP}}(T) NP(T)。
首先在表达式中找到所有的名词短语,然后选择组成句子根名词的目标名词短语。之后采用 CLIP 的文本编码器提取局部上下文文本特征:
t L = ψ C L P ( N P ( T ) ) \mathbf{t}^L=\psi_{\mathrm{CLP}}(\mathrm{NP}(T)) tL=ψCLP(NP(T))最后通过对全局和局部上下文特征加权求和得到全局-局部上下文特征:
t = β t G + ( 1 − β ) t L \mathbf{t}=\beta\mathbf{t}^G+(1-\beta)\mathbf{t}^L t=βtG+(1−β)tL其中 β ∈ [ 0 , 1 ] \beta\in[0,1] β∈[0,1] 为常数, t G \mathbf{t}^G tG、 t L \mathbf{t}^L tL 分别为全局句子和局部短语文本特征。
五、实施细节
采用无监督的实例分割方法:FreeSOLO,得到 mask proposal,输入图像短边调整为 800 800 800,CLIP 的输入图像尺寸为 224 × 224 224\times224 224×224,ViT 中 masking 层数 3 3 3, α = 0.85 \alpha=0.85 α=0.85 对于 RefCOCOg, α = 0.95 \alpha=0.95 α=0.95 对于 RefCOCO、RefCOCO+, β = 0.5 \beta=0.5 β=0.5 对于所有数据集。
【FreeSOLO】Xinlong Wang, Zhiding Yu, Shalini De Mello, Jan Kautz, Anima Anandkumar, Chunhua Shen, and Jose M Alvarez. Freesolo: Learning to segment objects without annotations. In CVPR, 2022. 3, 4, 5, 6, 7
5.1 全局-局部视觉编码器中的掩码
ReseNet-50 和 ViT-B/32 作为 CLIP 的视觉编码器。
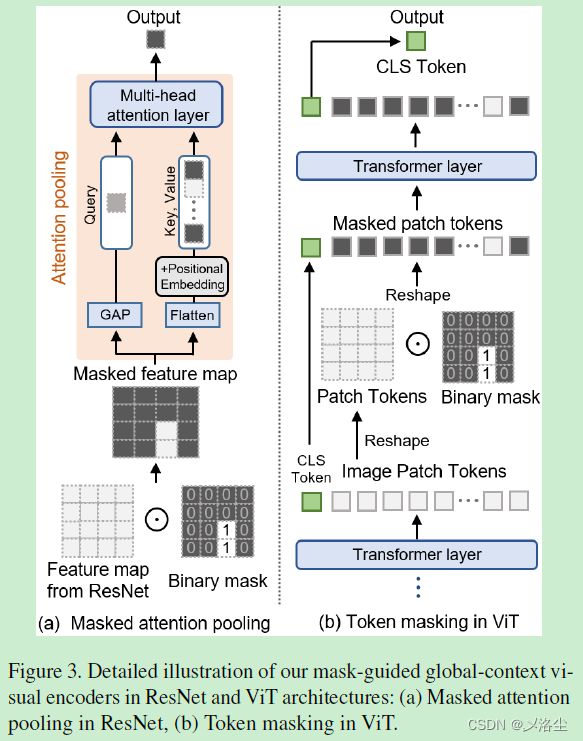
ResNet 中的掩码注意力池化
在 ResNet 中,用注意力池化层代替全局平均池化。这里的池化层和 Transformer 中的多头注意力结构一样, q u e r y query query 为 ResNet 提取的特征图送入全局平均池化的结果, k e y key key、 v a l u e value value 为展平后的特征图。流程:首先利用给定的 mask 遮住特征图,然后进行 q u e r y query query、 k e y key key、 v a l u e value value 以及多头注意力的计算。
ViT 中的 Token 掩码
首先将图像划分为网格 patches,然后利用线性层 embedding,并加入位置 embedding 得到 tokens,接着送入一系列的 Transformer 层。注意:为捕捉图像的全局上下文,仅在 Transformer 的最后 k k k 个层 mask 掉 tokens,然后对这些 tokens 调整尺寸,并通过给定的 mask proposal 遮住,展平后送入后续的 Transformer 层。ViT 中有个分类 token (CLS),从最后输出的特征中取出 CLS {\text{CLS}} CLS 作为全局上下文视觉表示。实验中只在视觉编码器的最后 3 层应用 token masking。
六、实验
6.1 数据集和指标
- 数据集:RefCOCO、Ref-COCO+ 、RefCOCOg;
- 指标:整体 Intersection over Union(oIoU)、平均 Intersection over Union(mIoU)。
6.2 Baselines
- Grad-CAM
- Score Map:MaskCLIP
- Region Token in ViT:Adapting CLIP
- Cropping
6.3 结果
主要结果
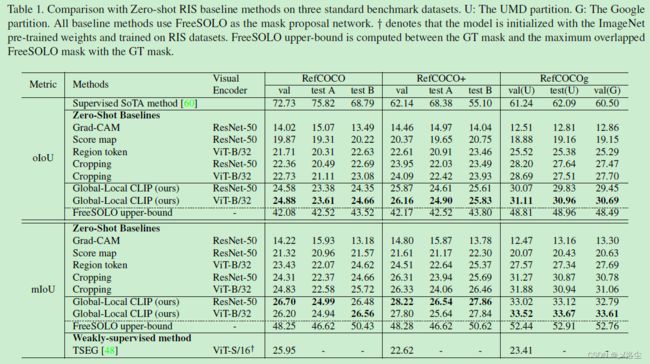
未知域上的零样本评估

在少样本设置下与有监督方法的比较
图 4 右侧。
6.4 消融实验
掩码质量的效果

全局-局部上下文特征的效果

定性分析



七、结论
利用 CLIP 中图像-文本跨模态表示,提出零样本 RIS 方法,提出全局-局部上下文编码来计算图像和表达式的相似度,实验表明方法有效。
补充材料 A:全局-局部上下文特征的分析
数据集统计

全局-局部上下文特征的有效性
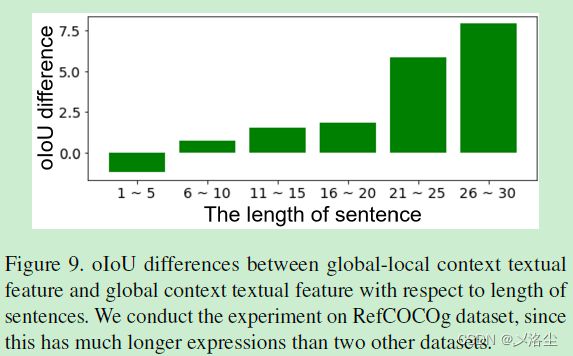
采用 SpaCY 的目标名词短语提取

补充材料 B:超参数 α \alpha α、 β \beta β 的分析

补充材料 C:ViT 中 Token 掩码的消融研究

补充材料 D:附加的定量结果

更多的定量结果


对定量结果的定量支持

写在后面
这篇文章实验充足,创新点足够,框架也比较简单,能打动审稿人的应该是在另外一个数据集上的实验。写作手法值得借鉴,是篇不错的零样本 Baseline。