大数据之路读书笔记-04离线数据开发
大数据之路读书笔记-04离线数据开发
从采集系统中收集了大量的原始数据后,数据只有被整合和计算,才能被用于洞察商业规律,挖掘潜在信息,从而实现大数据价值,达到赋能于商业和创造价值的目的。面对海量的数据和复杂的计算,阿里巴巴的数据计算层包括两大体系:数据存储及计算平台 (离线计算平MaxCompute 实时计算平台 StreamCompute 、数据整合及管理体系( OneData)
本章主要介绍 MaxCompute 和阿里巴巴内部基于 MaxCompute的大数据开发套件,并对在数据开发过程中经常遇到的问题和相关解决方案进行介绍。
文章目录
- 大数据之路读书笔记-04离线数据开发
-
- 4.1 数据开发平台
-
- 4.1.1 统一计算平台
- 4.1.2 统一开发平台
- 4.2 任务调度系统
-
- 4.2.1 背景
- 4.2.2 介绍
- 4.2.3 特点及应用
4.1 数据开发平台
阿里数据研发岗位的工作大致可以概括为:了解需求→模型设计→ETL 开发→测试→发布上线→日常运维→任务下线。与传统的数据仓库开发( ETL )相比,阿里数据研发有如下几个特点:
●业务变更频繁一一业务发展非常快 ,业务需求多且变更频繁。
●需要快速交付一一业务驱动 ,需要快速给出结果。
●频繁发布上线一一迭代周期以天为单位,每天需要发布数次。
●运维任务多一一在集团公共层平均每个开发人员负责 500 多个任务。
●系统环境复杂一一阿里平台系统多为自研,且为了保证业务的发展,平台系统的迭代速度较快,平台的稳定性压力较大。
通过统一的计算平台( MaxCompute )、统一的开发平台( D2 等相关平 台和工具)、统一的数据模型规范和统一的数据研发规范,可以在一定程度上解决数据研发的痛点。
4.1.1 统一计算平台
阿里离线数据仓库的存储和计算都是在阿里云大数据计算服务MaxComput 上完成的。
大数据计算服务 MaxCompute 是由阿里云自主研发的海量数据处理平台,主要服务于海量数据的存储和计算 ,提供完善的数据导人方案,以及多种经典的分布式计算模型,提供海量数据仓库的解决方案,能够更快速地解决用户的海量数据计算问题,有效降低企业成本,并保障数据安全。
MaxCompute 采用抽象的作业处理框架 ,将不同场景的各种计算任务统一在同一个平台之上,共享安全、存储 、数据管理和资源调度,为自不同用户需求的各种数据处理任务提供统 的编程接口和界面。它提供数据上传/下载通道、 SQL MapReduce 、机器学习算法 图编程模和流式计算模型多种计算分析服务,并且提供完善的安全解决方案。
1 . MaxCompute 的体系架
Max Compute 的体系架构如图 4.1 所示。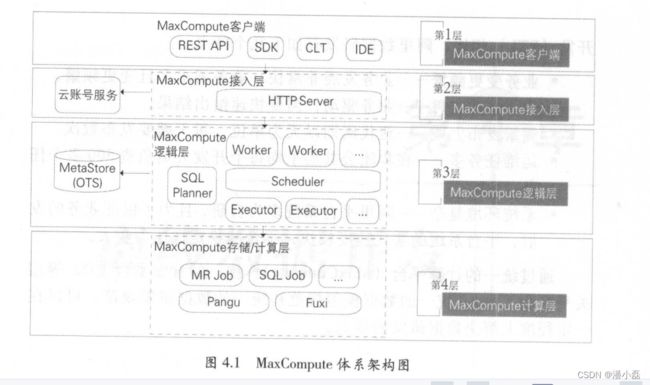
MaxCompute 由四部分组成,分别是客户端( MaxCompute Client )、接人层( MaxCompute Front End )、逻辑层( MaxCompt Server)及存储与计算层( Apsara Core )。
Max Compute 户端有以下几种形式:
●Web :以 RESTful API 的方式提供离线数据处理服务。
● SDK :对 RESTful API 的封装,目前有 Java 等版本的实现。
●CLT (Command Line Tool ): 运行在 Windows/Linux 下的客户端工具,通过 CLT 可以提交命令完成 Project 管理、 DDL DML等操作。
● IDE :上层可视化 ETL/BI 工具, 即阿里内部名称是在云端(D2 ) , 用户可以基于在云端完成数据同步、任务调度、报表生成等常见操作。
接入层提供 HTTP 服务、 Cache 、负载均衡,实现用户认证和服务层面的访问控制。
逻辑层又称作控制层,是 MaxCompute 的核心部分,实现用户空间和对象的管理、命令的解析与执行逻辑、数据对象的访问控制与授权等功能。在逻辑层有 Worker Scheduler Executor 三个角色.
• Worker 处理所有的RESTful 请求,包括用户空间( Project )管理操作、资源( Resource 管理操作、作业管理等,对于 SQLDML MR 等需要启动 MapReduce 的作业,会生成 MaxCompute Instance (类似于 Hive 中的 JoB),提交给 cheduler 一步处理。
• Scheduler MaxCompute Instance 的调度和拆解,并向计算层的计算集群询问资源占用情况以进行流控。
• Executor 负责 MaxCompute Instance 的执行,向计算层的计算集群提交真正的计算任务。
计算层就是飞天内核( Apsara Core ),运行在和控制层相互独立的计算集群上 ,它包括 Pangu (分布式文件系统)、Fuxi (资源调度系统)Nuwa/ZK(Namespace 务) Shennong (监控模块)等。 MaxCompute 中的元数据存储在阿里云计算 的另 个开放服务 OTS (Open Table Service ,开放结构化数据服务) 中,元数据内容主要包括用户空间元数据、 Table Partition Schema ACL Job 元数据、安全体系等。
2 . MaxCompute 的特点
(1 )计算性能高且更加普惠
2016年 11月11 日, Sort Benchmark 在官方网站公布了2 016 年排序竞赛 Cloud Sort 项目的最终成绩。阿里云以$1.44 /TB 的成绩获得 Indy(专用目的 序)和 Daytona (通用目的排序)两个子项的世界冠军,打破了AWS 2014 年保持的纪录$4.51/TB 。这意味着阿里云将世界顶级的计算能力,变成普惠科技云产品。 CloudSort 又被称为“云计算效率之争”,这项目赛 比拼的是完成 100TB 数据排序谁的花费更少,也是Sort Benchmark 的各项比赛当中最具现实意义的项目之一。
(2 )集群规模大且稳定性高
Max Compute 平台共有几万台机器、存储近 1000PB ,支撑着阿里巴巴的很多业务系统,包括数据仓库、 BI 分析和决策支持、信用评估和无担保贷款风险控制、广告业务、每天几十亿流的搜索和推荐相关性分析等,系统运行非常稳定。同时, MaxCompute 能保证数据的正确性,如对数据的准确性要求非常高的蚂蚁金服小额贷款业务,就运行于Max Compute 平台之上。
(3 )功能组件非常强大
• MaxCompute SQL :标准 SQL 的语法,提供各类操作和函数来处理数据。
• MaxCompute MapReduce :提供 Java MapReduce 编程模型,通过接口编写 MR 程序处理 MaxCompute 中的数据。还提供基于MapReduce 的扩展模型 MR2 ,在该模型下,一个Map 函数后可以接入连续多个 Reduce 函数,执行效率比普通的 MapReduce性能高。
• MaxCompute Graph :面向迭代的图计算处理框架,典型应用有PageRank 、单源最短距离算法、 K均值聚类算法。
• Spark :使用 Spark 接口编程处理存储在 Max Compute 中的数据
• RMaxCompute :使用 处理 MaxCompute 中的数据。
• Volume: MaxCompute Vo lume 形式支持文件,管理非二维表数据。
(4 )安全性高
Max Compute 提供功能强大的安全服务,为用户的数据安全提供保护。 MaxCompute 采用多租户数据安全体系,实现用户认证、项目的用户与授权管理、跨项目空间的资源分享,以及项目间的数据保护如支付宝数据,符合银行监管的安全性要求,支持各种授权鉴权审“最小访问权限”原则,确保数据安全。
4.1.2 统一开发平台
阿里数据开发平台集成了多个子系统来解决实际生产中的各种痛点。围绕MaxCompute 计算平台,从任务开发、调试、测试、发布、监控、 到运维管理,形成了一整套工具和产品,既提高了开发效率,又保证了数据质量,并且在确保数据产出时效的同时,能对数据进行有效管理。
数据研发人员完成需求了解和模型设计之后,进入开发环节,开发工作流如图 4.2 所示。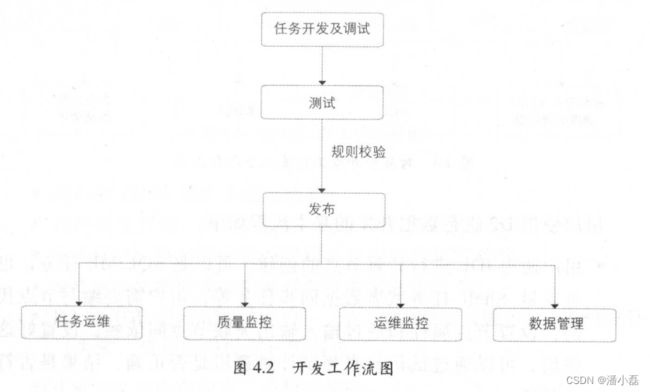
对应于开发工作流的产品和工具 4.3 ,我们将对其功能进行简要介绍。
1.在云端( D2)
D2是集成任务开发、调试及发布,生产任务调度及大数据运维.数据权限申请及管理等功能的一站式数据开发平台 并能承担数据分析工作台的功能。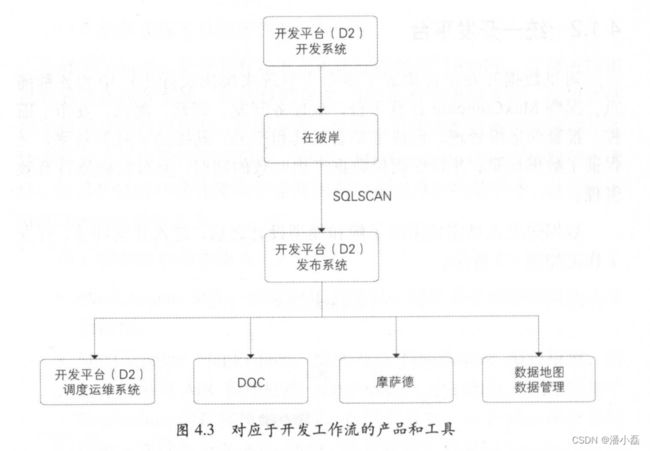
用户使用 D2 进行数据开发的基本流程如下:
●用户使用 IDE进行计算节点的创建,可以是 SQL/MR 任务,也可以是Shell 务或者数据同步任务等,用户需要编写节点代码、设置节点属性和通过输入输出关联节点间依赖。设置好这些后,可以通过试运行来测试计算逻辑是否正确、结果是否合预期。
●用户点击提交,节点进入开发环境中,并成为某个工作流的其中一个节点。整个工作流可以被触发调度,这种触发可以是人为的(称之为“临时工作流”),也可以是系统自动的(称之为“日常工作流”)。当某个节点满足所有触发条件后,会被下发到调度系统的执行引擎Alisa 中, 完成资源分配和执行的整个过程。
●如果节点在开发环境中运行无误,用户可以点击发布,将该节正式提交到生产环境中,成为线上生产链路的 个环节。
2. SQLSCAN
SQLSCAN 将在任务开发中遇到的各种问题,如用户编写的质量差、性能低、不遵守规范等,总结后形成规则,并通过系统及研发流程保障,事前解决故障隐患,避免事后处理。
SQLSCAN与D2 进行结合,嵌入到开发流程中,用户在提交代码时会触发 SQLSCAN 检查。 SQLSCAN 工作流程如图 4.4 所示。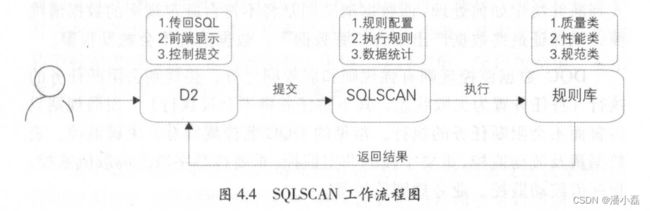
●用户在 D2 IDE 中编写代码。
●用户提交代码, D2 将代码、调度等信息传到SQLSCAN
●SQLSCAN 根据所配置的规则执行相应的规则校验。
● SQLSCAN 将检查成功或者失败的信息传回D2
● D2的IDE 显示 OK (成功)、 WARNNING (警告)、 FAILE(失败,禁止用户提交)等消息。
SQLSCAN 主要有如下三类规则校验:
●代码规范类规则,如表命名规范、生命周期设置、表注释等。
●代码质量类规则,如调度参数使用检查、分母为0提醒、 NULL值参与计算影响结果提醒、插入字段顺序错误等。
●代码性能类规则,如分区裁剪失效、扫描大表提醒、重复计算检测等。
SQLSCAN 规则有强规则和弱规则两类。触发强规则后,任务的提交会被阻断,必须修复代码后才能再次提交而触发弱规则,则只会显示违反规则的提示,用户可以继续提交任务。
3. DQC
DQC (Data Quality Center ,数据质量中心)主要关注数据质量,通过配置数据质量校验规则,自动在数据处理任务过程中进行数据质量方面的监控。
DQC 主要有数据监控和数据清洗两大功能。数据监控,顾名思义,能监控数据质量并报警,其本身不对数据产出进行处理,需要报警接收人判断并决定如何处理;而数据清洗则是将不符合既定规则的数据清洗掉,以保证最终数据产出不含“脏数据”,数据清洗不会触发报警。
DQC 数据监控规则有强规则和弱规则之分,强规则会阻断任务的执行(将任务置为失败状态,其下游任务将不会被执行);而弱规则只告警而不会阻断任务的执行。常见的 DQC 监控规则有:主键监控、表数据量及波动监控、重要字段的非空监控、重要枚举宇段的离散值监控、指标值波动监控、业务规则监控等。
阿里数据仓库的数据清洗采用非侵人式的清洗策略,在数据同步过程中不进行数据清洗,避免影响数据同步的效率,其过程在数据进入ODS 层之后执行。对于需要清洗的表,首先在 DQC 置清洗规则;对于离线任务,每隔固定的时间间隔,数据入仓之后,启动清洗任务,调DQC 配置的清洗规则,将符合清洗规则的数据清洗掉,并保存至DIRTY 表归档。如果清洗掉的数据量大于预设的阈值,则阻断任务的执行否则不会阻断。
DQC 工作流程如图 4.5 所示。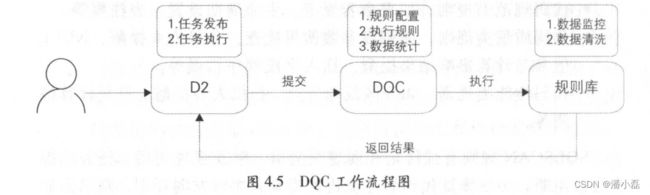
4. 在彼岸
数据测试的典型测试方法是功能测试,主要验证目标数据是否符合预期。其主要有如下场景:
(1 )新增业务需求
新增产品经理、运营、 BI 等的报表、应用或产品需求 需要开发新的ETL 务,此时应对上线前的 ETL 任务进行测试,确保目标数据符合业务预期,避免业务方根据错误数据做出决策。其主要对目标数据和源数据进行对比,包括数据量、主键、字段空值 、字段枚举值、复杂逻辑(如 UDF 、多路分支)等的测试。
(2 )数据迁移、重构和修改
由于数据仓库系统迁移、源系统业务变化、业务需求变更或重构等,需要对现有的代码逻辑进行修改 ,为保证数据质量需要对修改前后的数据进行对比,包括数据量差异、宇段值差异对比等,保证逻辑变更正确。为了严格保证数据质量,对于优先级(优先级的定义见“数据质量章节)大于某个阈值的任务,强制要求必须使用在彼岸进行回归测试,在彼岸回归测试通过之后,才允许进入发布流程。
在彼岸则是用于解决上述测试问题而开发的大数据系统的自动化测试平台,将通用的、重复性的操作沉淀在测试平台中,避免被“人肉”,提高测试效率。
在彼岸主要包含如下组件,除满足数据测试的数据对比组件之外,还有数据分布和数据脱敏组件。
●数据对比:支持不同集群、异构数据库的表做数据对比。表级对比规则主要包括数据量和全文对比;字段级对比规则主要包括字段的统计值(如 SUM VG MAX MIN 等)、枚举值、空值、去重数、长度值等。
●数据分布:提取表和字段的 些特征值 ,并将这些特征值与预期值进行比对。表级数据特征提取主要包括数据量、主键等;字段级数据特征提取主要包括字段枚举值分布、空值分布、统计值(如SUM AVG MAX MIN 等)、去重数、长度值等。
●数据脱敏:将敏感数据模糊化。在数据安全的大前提下,实现线上数据脱敏,在保证数据安全的同时又保持数据形态的分布,以便业务联调、数据调研和数据交换。
使用在彼岸进行回归测试的流程如图 4.6 所示。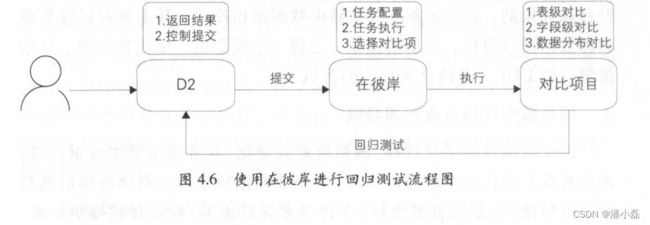
4.2 任务调度系统
4.2.1 背景
现代信息化条件下的战争,从太空的卫星到空中的各类作战飞机,从地面的导弹到坦克火炮,从水面的大小舰艇到水下的潜艇,还有诸如网络、电磁环境等多种方式、多种维度的作战空间,各种武器装备、人员、作战环境纷繁复杂,如何能够准确、合理地调配这些资源,组织有序、高效的攻防体系赢得胜利,最关键的是需要有 个强大的指挥系统。在云计算大数据时代,调度系统无疑是整个大数据体系的指挥中枢
如图 4.7 所示,调度系统中的各类任务互相依赖,形成一个典型的有向无环图。在传统的数据仓库系统中,很多是依靠 Crontab 定时任务功能进行任务调度处理的。这种方式有很多弊端:①各任务之间的依赖基于执行时间实现,容易造成前面的任务未结束或失败而后面的任务已经运行;②任务难以并发执行,增加了整体的处理时间:③无法设置任务优先级;④任务的管理维护很不方便,无法进行执行效果分析等。
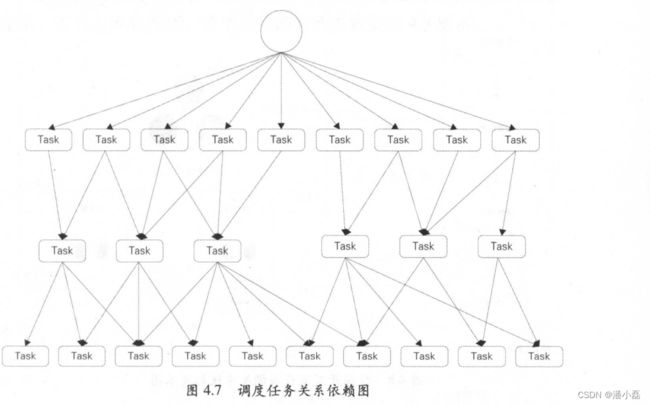
而在大数据环境下,每天需要处理海量的任务,多的可以达到几十上百万。另外,任务的类型也很繁杂,有 MapReduce Hive SQLSpark Java Shell Python Perl 、虚拟节点等,任务之间互相依赖且需要不同的运行环境。为了解决以上问题,阿里巴巴的大数据调度系统应运而生。
4.2.2 介绍
1 数据开发流程与调度系统的关系
数据开发流程与调度系统的关系如图 4.8 所示。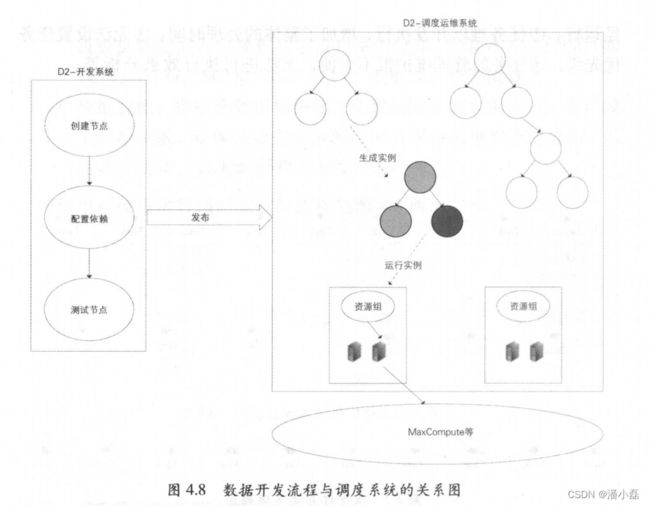
用户通过D2平台提交、发布的任务节点,需要通过调度系统,按照任务的运行顺序调度运行。
2.调度系统的核心设计模型
整个调度系统共有两个核心模块:调度引擎( Phoenix Engine )和执行引擎 Alisa)。简单来说,调度引擎的作用是根据任务节点属性及依赖关系进行实例化, 生成各类参数的实值,并生成调度树;执行引擎的作用是根据调度引擎生成的具体任务实例和配置信息,分配 CPU内存、运行节点等资源 在任务对应的执行环境中运行节点代码。
在介绍调度引擎设计之前 我们先来了解两个模型:任务状态机模型和工作流状态机模型。
3.任务状态机模型
任务状态机模型是针对数据任务节点在整个运行生命周期的状态定义 ,总共有6种状态,状态之间的转换逻辑如图 4.9 所示。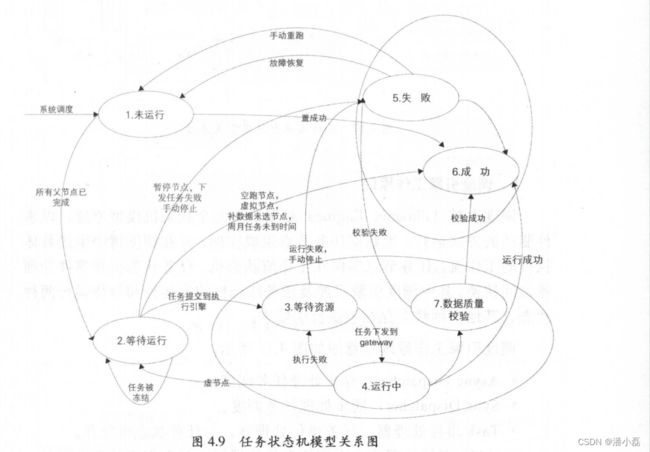
4. 工作流状态机模型
工作流状态机模型是针对数据任务节点在调度树中生成的工作流运行的不同状态定义,共有5种状态,其关系如图 4.10 所示。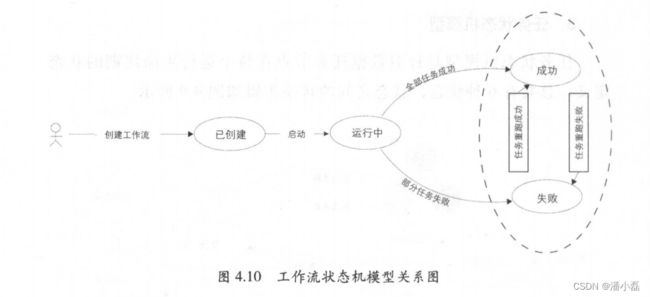
5. 调度引擎工作原理
调度引擎( Phoenix Engine )基于以上两个状态机模型原理,以事件驱动的方式运行,为数据任务节点生成实例,并在调度树中生成具体执行的工作流。任务节点实例在工作流状态机、任务状态机和事件处器之间转换,其中调度引擎只涉及任务状态机的未运行和 待运行两种状态,其他5种状态存在于执行引擎中。
调度引擎工作原理示意图如图 4.1 所示。
● Async Dispatcher :异步处理任务调度。
● Sync Dispatcher :同步处理任务调度。
● Task 事件处理器:任务事件处理器,与任务状态机
● DAG 事件处理器:工作流事件处理器,与工作流状态机交互。一个DAG 事件处理器包含若干个 Task 件处理器
6. 执行引擎工作原理
首先来看看执行引擎( Alisa )的逻辑架构,如图 4.12 示。
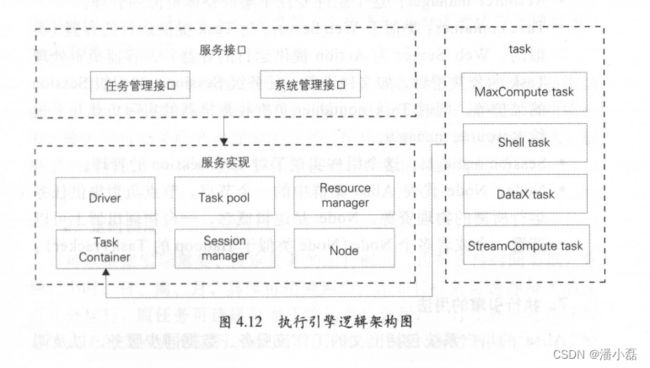
●任务管理接口:供用户系统向 Alisa 中提交、查询和操作离线任务,并获得异步通知。
●系统管理接口 供系统管理员进行后台管理,包括为集群增加新的机器、划分资源组、查看集群资源和负载、追踪任务状态等。
●Driver: Alisa 的调度器, Driver 中实现了任务管理接口和系统管理接口;负责任务的调度策略、集群容灾和伸缩、任务失效备援、负载均衡实现。 Drive 的任务调度策略是可插拔替换的,以满不同的使用场景。 Driver 使用 Resourcemanager 管理整个集群的负载。 (我们可以把 Driver 理解为 Hadoop Job Tracker 。)
●Task pool: Driver 也将已经提交的全部任务都放入到 Task pool 中管理,包括等待资源、数据质量检测、运行中、运行成功和失败的所有任务。直到任务运行完成(不论成功或者失败),并且用户确实获取到了关于这个状态的通知, Driver 将任务从Task pool 中移除。 Driver Node 通过 Task pool 提供的事件机制进行可靠的通信。整个系统全部状态(除了与运行无关的部分管理信息外)都保存在 Task pool 中,这样系统的其他部分很容易实现高可用性和伸缩性。而 Task pool 本身采用 Zookeeper实现,这样它本身也是具备高可用能力的。
● Resource manager :这个组件专注于集群整体资源的管理。
● Task container :类似于 Web Server ,为 Task 提供运行的容器(类似的, Web Server 为Action 提供运行的容器)。容器负责处理Task 的公共逻辑,如文件下载,任务级 Session 、流程级 Session的维护等。同时 Task container 负责收集机器的实际负载并上报Resource manager
●Session manager :这个组件实现了对 Task session 的管理。
● Node: Node 代表 Alisa 集群中的 个节点。节点负责提供任务运行所需的物理资源。 Node 是逻辑概念, 每台物理机器上可部署一个或者多个 Node (Node 类似于 Hadoop TaskTracker)
7. 执行引擎的用法
Alisa 的用户系统包括上文的工作流服务、数据同步服务,以及调度引擎生成的各类数据处理任务的调度服务。这样系统将任务提交到Alisa 中后,就不需要关心任务应该在哪里执行以及如何被执行了,于是大大降低了系统本身的复杂度。同时其任务可以共享同一个物理集群资源,提高了资源的利用效率。如果 Alisa 中的任务是一个 MaxCompute 任务,计算实际会被提交到 MaxCompute 集群中, Alisa 中仅仅运行Max Compute Client ;同样,流计算任务等会被提交到对应的目标系统中运行;而Shell 任务、离线数据同步任务、实时同步任务( TT )等将直接运行在 lisa 集群上。
4.2.3 特点及应用
当前的调度系统支持阿里巴巴大数据系统日常应用的各种场景,其主要具有如下特点和应用场景。
1 调度配置
常见的调度配置方式是对具体任务手工配置依赖的上游任务,此方式基本可以满足调度系统的正常运行。这种方式存在两个问题 一是配置上较麻烦,需要知道上游依赖表的产出任务;二是上游任务修改不再产出依赖表或本身任务不再依赖某上游任务时,对调度依赖不做修改,导致依赖配置错误。
阿里巴巴的调度配置方式采用的是输入输出配置和自动识别相结合的方式。任务提交时, SQL 解析引擎自动识别此任务的输入表和输出表,输入表自动关联产出此表的任务 ,输出表亦然。通过此种方式,解决了上述问题,可以自动调整任务依赖,避免依赖配置错误。
2.定时调度
可以根据实际需要,设定任务的运行时间,共有5种时间类型:分钟、小时、日、周、月,具体可精确到秒。 比如日任务可选择每天的几点几分运行,周任务可选择每周几的几点几分运行,月任务也可选择每月第几天的几点几分运行。对于周任务和月任务 ,通常选择定时调度的方式。
3.周期调度
可按照小时、日等时间周期运行任务,与定时调度的区别是无须指定具体的开始运行时间。比如离线数据处理的大多数日任务就是这种类型,任务根据依赖关系,按照调度树的顺序从上依次向下运行,每个周期的具体运行时间随着每天资源和上游依赖任务运行的总体情况会有所不同。
4.手动运行
当生产环境需要做一些数据修复或其他一次性的临时数据操作时,可以选择手动运行的任务类型,在开发环境( IDE )中写好脚本后发布到生产环境,再通过手动触发运行。
5.补数据
在完成数据开发的发布以后,有些表需要进行数据初始化,比如有些日增量表要补齐最近三年的历史数据,这时就需要用到补数据任务了。可以设定需要补的时间区间,并圈定需要运行的任务节点,从而生成一个补数据的工作流,同时还能选择并行的运行方式以节约时间。
6. 基线管理
基于充分利用计算资源,保证重点业务数据优先产出,合理安排各类优先级任务的运行,调度系统引人了按优先级分类管理的方法。优先级分类从1-9 ,数字越大代表优先级越高,系统会先保障高优先级任务的运行资源。对于同一类优先级的任务,放到同一条基线中,这样可以实现按优先级不同进行分层的统一管理,并可对基线的运行时间进行预测估计,以监控是否能在规定的时间内完成。基线运行监控如表4.1所示。
7.监控报警
调度系统有一套完整的监控报警体系,包括针对出错的节点、运行超时未完成的节点,以及可能超时的基线等,设置电话、短信、邮件等不同的告警方式,实现了日常数据运维的自动化。具体产品介绍请参考“数据质量”章节。
阿里巴巴的大数据调度系统经过几年的迭代研发和实际运行,目前已经很好地支撑阿里系各个数据团队各类数据处理任务的日常运行和维护,每天在系统上运行的各类数据处理任务多达数十万个,日处理数据量达PB级,在性能、成本控制、稳定性等方面取得了良好的效果。