io_uring简单了解
当我们进行一个系统调用,用户层的应用程序调用内核,它在内核空间中复制数据。在内核完成执行之后,它将结果复制回用户空间缓冲区。然后它返回。在这段时间内,系统调用仍然被阻塞
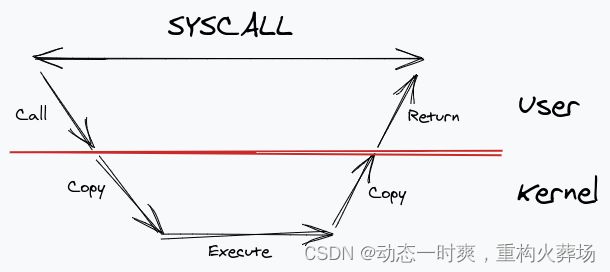
那么如何解决多次复制和同步问题呢
- 复制:解决多次复制的关键在于可以使用mmap在内核和用户空间之间共享内存
- 同步:当我们将问题看作是用户和内核之间的“通信”看作是生产者消费者问题时,便可以采用ring buffer。这允许在生产者和消费者之间进行高效的同步,而且不需要加锁
由此便引出了io_uring
io_uring是2019年Linux5.1内核首次引入的高性能异步IO框架,能显著带来加速IO密集型应用的性能
但相比正确使用的AIO可能最多只有5%的提升
io_uring来自于Jens Axboe的观察——随着设备越来越快,中断驱动效率已经低于轮训模式。io_uring基本逻辑与AIO一致,提供两个接口,一个将IO请求提交到内核,一个从内核接收完成时间
相比于libaio/KAIO主要特性在于
- 在进行缓存IO的时候也保留了异步行为
- 可以选择通过轮询方式工作
- 易于使用
- 更少的用户空间/内核系统调用模式切换导致了更低的CPU开销(由于spectre/meltdown的影响,这是最近的一件大事)
- 可以预先注册文件描述符和缓冲区,以节省映射/解除映射的时间
- 更快(可以实现更高的总体吞吐量,IO具有更低的延迟)
- 链接模式可以表达(>=5.3kernel)
- 可以使用基于套接字的I/O (recvmsg()/sendmsg()从>=5.3支持)
- 支持尝试取消排队的I/O (>=5.5)
- 支持读写以外的异步操作
- Less bookkeeping space overhead per I/O
与glibc的POSIX AIO相比,io_uring具有以下优点:
- 更快、更高效(上面提到的低开销好处在这里更适用)
- 接口是由内核支持的,不使用用户空间线程池
- 在进行缓冲I/O时,数据的副本更少
- 不要和信号较劲
- Glibc的POSIX AIO不能在一个文件描述符上运行多个I/O,而io_uring可以!
direct IO就是无缓存IO,不会经过OS Cache。通常用于数据库,因为数据库有自己的cache
原理
每个io_uring都有提交、完成两个环形队列,在内核和应用之间共享。其中CQ其实包含了cqe,而SQ中值其实是包含保存SQE项真实数据的指针
额外的SQEs是为了方便通过环形缓冲区提交内存上不连续的请求。SQ和CQ中每个节点保存的都是SQEs数组的索引,而不是实际的请求,实际的请求只保存在SQEs数组中。这样在提交请求时,就可以批量提交一组SQEs上不连续的请求。
SQE包含
- Opcode:描述要进行的系统调用的操作码。由于我们对读取文件感兴趣,我们将使用readv系统调用,该系统调用映射到操作码IORING_OP_READV。
- Flags:修饰符,可以通过任何请求传递
- Fd:要读取的文件描述符
- Address:对于我们的readv调用,它创建了一个缓冲区(或向量)数组来读入数据。因此,address字段包含了该数组的地址。
- Length:向量数组的长度。
- User Data:当请求从完成队列中出来时,用来关联SQE、CQE请求的标识符。请记住,并不能保证完成结果与SQEs的顺序相同。这样就违背了异步API的初衷。因此,我们需要一些东西来识别我们发出的请求。这可以达到这个目的。通常这是一个指针,指向一些结构体,其中保存了请求的元数据。
CQE包含
- Result:readv系统调用的返回值。如果成功,就会有读取的字节数;否则它将有一个错误代码。
- User Data:我们在SQE中传递的标识符。
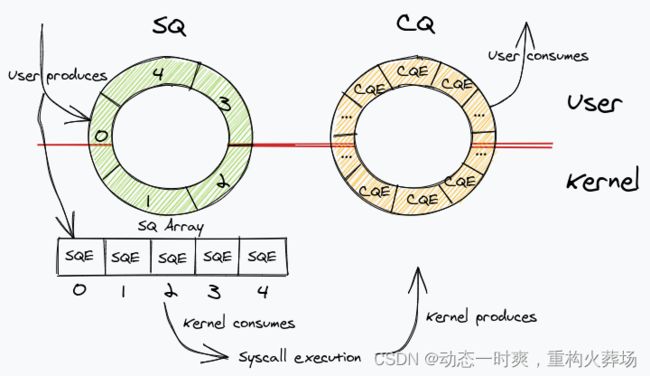
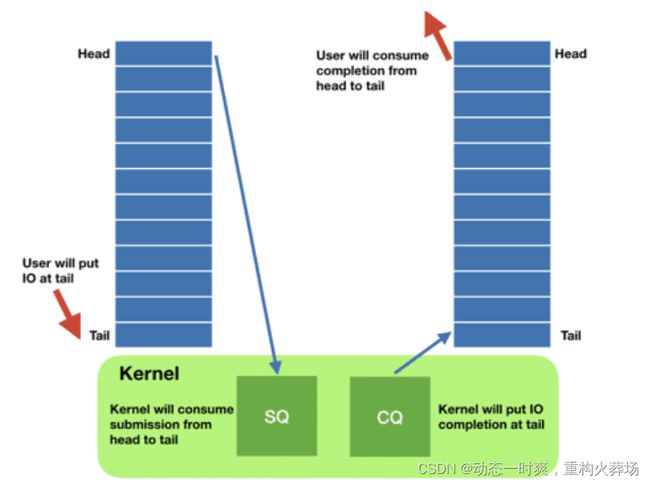
这两个队列都是单生产者、单消费者,size是2的幂。并且提供了无锁接口,内部使用内存屏障做同步
使用方式
- 请求
- 应用创建SQ entries(SQE),更新SQ tail
- 内核消费SQE,更新SQ head
- 完成
- 内核为完成的一个或多个请求创建CQ entries(CQE),更新CQ tail
- 应用消费CQE,更新CQ head
- 消费CQE无需切换到内核态
工作模式
-
中断驱动模式
默认模式。可通过io_uring_enter()提交IO请求,然后检查CQ状态判断是否完成
-
轮询模式。
需要文件系统和块设备支持。相比中断驱动,延迟更低,但可能会消耗更多CPU资源
-
内核轮询模式。
创建内核线程执行SQ轮询。当前应用更新 SQ ring 并填充一个新的 sqe,内核线程 sqthread 会自动完成提交,这样应用无需每次调用 io_uring_enter() 系统调用来提交 IO。应用可通过
IORING_SETUP_SQ_AFF和 sq_thread_cpu 绑定特定的 CPU。 同时,为了节省无 IO 场景的 CPU 开销,该内核线程会在一段时间空闲后自动睡眠。应用在下发新的 IO 时,通过IORING_ENTER_SQ_WAKEUP唤醒该内核线程,用户态可以通过 sqring 的 flags 变量获取 SQ 线程的状态。
中断是硬件机制,可以理解为中断是处理器对外开放的实时受控接口。可以看作是硬件轮询,也就是CPU会通过读取外部信号来判断CPU的下一步状态
轮询是一种CPU如何提供周边设备服务的方式
流程
- 初始化
- 获取SQ中空闲的SQE,将具体请求设置到该SQE
- 将SQE索引放至SQ中
- 提交请求
- 通过非阻塞式io_uring_peek_cqe、阻塞式io_uring_wait_cqe获取请求完成。默认情况下,完成的IO请求还会存在内部队列,需要通过io_uring_cqe_seen标记完成操作
- io_uring_queue_exit资源清理
使用
系统调用
初始化
// 创建拥有entries个请求的SQ(entries个)、CQ(2*entries个),通过mmap将内存区域映射到用户空间,并且返回文件描述符用于后续操作
//
int io_uring_setup(u32 entries, struct io_uring_params *p);
struct io_uring_params {
// 输出参数。告诉应用该ring支持多少sqe
__u32 sq_entries;
// 输出参数。告诉应用该ring CQ有多大
__u32 cq_entries;
// 用来设置当前整个io_uring标志。决定是否启动sq_thread,是否采用iopoll模式等等
__u32 flags;
// 指定io_sq_thread内核线程CPU
__u32 sq_thread_cpu;
// 指定io_sq_thread内核线程idle时间
__u32 sq_thread_idle;
// 描述当前内核支持特性
__u32 features;
__u32 wq_fd;
// 保留字段
__u32 resv[3];
// 内核和用户态约定,分别描述SQ、CQ指针在mmap中的offset
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
/*
* io_uring_params->features flags
*/
// 一次mmap完成SQ、CQ内存映射
#define IORING_FEAT_SINGLE_MMAP (1U << 0)
#define IORING_FEAT_NODROP (1U << 1)
#define IORING_FEAT_SUBMIT_STABLE (1U << 2)
#define IORING_FEAT_RW_CUR_POS (1U << 3)
#define IORING_FEAT_CUR_PERSONALITY (1U << 4)
#define IORING_FEAT_FAST_POLL (1U << 5)
#define IORING_FEAT_POLL_32BITS (1U << 6)
IO提交
// 初始化完成之后,可以使用sq队列添加io请求。当请求都加入sq后,就可以提交io请求公司内核
// 具体的实现是找到一个空闲的SQE,根据请求设置SQE,并将这个SQE的索引放到SQ中。SQ是一个典型的ring buffer,有head,tail两个成员,如果head == tail,意味着队列为空。SQE设置完成后,需要修改SQ的tail,以表示向ring buffer中插入了一个请求。
int io_uring_enter(unsigned int fd, // io_uring_setup返回的fd
unsigned int to_submit, // 提交待消费数量
unsigned int min_complete, // 若已完成io数量小于min_complete,请求会堵塞
unsigned int flags,
sigset_t *sig);
注册
// 注册文件或用户缓冲区,允许内核获取内部数据结构的长期引用,或创建应用程序内存的长期映射,大大减少了per-I/O开销。
// 将fd中数据结构映射到共享内存,从而进一步减少用户IO提交到uring队列开销
int io_uring_register(unsigned int fd, unsigned int opcode,
void *arg, unsigned int nr_args);
小demo
#include "liburing.h"
#define QD 4 // io_uring 队列长度
int main(int argc, char *argv[]) {
int i, fd, pending, done;
void *buf;
// 1. 初始化io_uring
struct io_uring ring;
// QD 队列长度
// &ring io_ring实例
// 0 flags,代表使用中断驱动模式
ret = io_uring_queue_init(QD, &ring, 0);
// 2. 打开输入文件,注意这里指定了 O_DIRECT flag,内核轮询模式需要这个 flag
fd = open(argv[1], O_RDONLY | O_DIRECT);
struct stat sb;
fstat(fd, &sb); // 获取文件信息,例如文件长度,后面会用到
// 3. 初始化 4 个读缓冲区
ssize_t fsize = 0; // 程序的最大读取长度
struct iovec *iovecs = calloc(QD, sizeof(struct iovec));
for (i = 0; i < QD; i++) {
if (posix_memalign(&buf, 4096, 4096))
return 1;
iovecs[i].iov_base = buf; // 起始地址
iovecs[i].iov_len = 4096; // 缓冲区大小
fsize += 4096;
}
// 4. 准备4个sqe读请求,并将读取数据写入读缓冲区
struct io_uring_sqe *sqe;
offset = 0;
i = 0;
do {
// 获取可用的sqe
sqe = io_uring_get_sqe(&ring);
// sqe 用该sqe准备一个待提交的read操作
// fd 从fd打开的文件读取数据
// &iovecs[i] iovec地址,读到的数据写入iovec缓存区
// 1 iovec数量
// offset 读取操作的开始偏移量
io_uring_prep_readv(sqe, fd, &iovecs[i], 1, offset);
// 更新偏移量
offset += iovecs[i].iov_len;
i++;
if (offset>sb.st_size)
{
break;
}
}while (1);
// 5. 提交sqe读请求
ret = io_uring_submit(&ring); // 4个SQE一次提交,返回提交成功的SQE数量
if (ret < 0) {
fprintf(stderr, "io_uring_submit: %s\n", strerror(-ret));
return 1;
} else if (ret != i) {
fprintf(stderr, "io_uring_submit submitted less %d\n", ret);
return 1;
}
// 6. 等待读请求完成
struct io_uring_cqe *cqe;
done = 0;
pending = ret;
fsize = 0;
for (i = 0; i < pending; i++)
{
io_uring_wait_cqe(&ring,&cqe);
done++;
if (cqe->res!=4096 && cqe->res+fsize!=sb.st_size)
{
fprintf(stderr, "ret=%d, wanted 4096\n", cqe->res);
}
fsize += cqe->res;
io_uring_cqe_seen(&ring, cqe); // 更新 io_uring 实例的完成队列
}
// 7. 打印统计信息
printf("Submitted=%d, completed=%d, bytes=%lu\n", pending, done, (unsigned long) fsize);
// 8. 清理工作
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
在高IOPS时频繁建立、取消内存映射会造成比较大的开销,因此可以将iovec数组提前注册到iouring实例,建立相关内存映射。只有当主动取消注册或 io_uring 实例销毁时,才会取消内存映射。
Ref
- https://zhuanlan.zhihu.com/p/361955546
- https://arthurchiao.art/blog/intro-to-io-uring-zh/
- https://developers.mattermost.com/blog/hands-on-iouring-go/
- https://yanhang.me/post/2020-11-27-io_uring/
- http://icebergu.com/archives/go-iouring#TsHDwbEw
- https://cloud.tencent.com/developer/article/1668831
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/5/html/global_file_system/s1-manage-direct-io
- https://zhuanlan.zhihu.com/p/334658432
- https://man.archlinux.org/man/io_uring_register.2.en
- https://zhuanlan.zhihu.com/p/374627461
- https://blog.csdn.net/Z_Stand/article/details/120235413