多线程(六):多线程案例
多线程最最经典案例就是上一章的单例设计模式。
当然除了单例设计模式,还有其他的案例。
本章就 一一 来介绍。
阻塞队列
这里是第一次提到阻塞队列这个东西,简单介绍一下,什么是阻塞队列:
阻塞队列(BlockingQueue) 是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者消费者模式:
生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
这个先不管,等会就详细介绍。
那么我们在网上查一查有哪些阻塞队列呢?
- ArrayBlockingQueue : 一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue : 一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue : 一个支持优先级排序的无界阻塞队列。
等等....;
这个东西非常有用,尤其是实现多线程时,多线程之间进行数据交互。
可以使用阻塞队列来简化代码编写。
并且它是线程安全的。
那我们先来看看生产者——消费者模式。
生产者——消费者模式
比如我们引入一个生活中的例子:
比如家里逢年过节的包饺子,假设有四个滑稽老铁,在包饺子,假设有一个擀面杖,一个用了擀面杖,其他人就要等待。

那么我们想要提高效率,多几个擀面杖不行吗?
可以的,就算多了几个擀面杖,四个滑稽老铁仍然需要 擀个饺子皮,包一个饺子。
所以我们可以引入这样的模式来加快效率:
一个老铁负责生产饺子皮,另外三个老铁取消费饺子皮。
这样比起来效率相对会加快。
既然我们引进了生产者——消费者模式,那为啥我们要引进这样的模式呢?有啥有用的呢?
当然不只是增加效率拉。
1.让代码块之间解耦合
之前总是听说,高耦合低内聚,高内聚低耦合,啥啥啥的,从来没明白过。
这里来解释一下,啥叫耦合,啥叫内聚。
耦合:影响性强弱
内聚:关联性强弱
内聚就是功能一样的代码放在一起,举个例子,衣服要分门别类的放,就是相同的一类的要放在一起
高内聚低耦合:关联性强,相互影响性弱; 高耦合低内聚:关联性弱,相互影响性高。
我们来举个栗子()
有两个服务器相互交互数据:
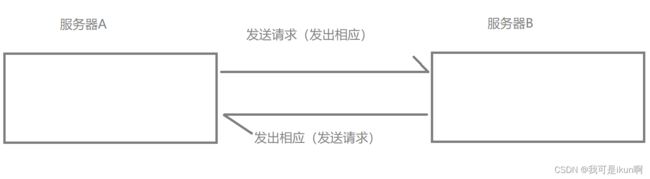
正常情况下,二者相安无事,突然有一天,我们某个服务器崩了,假设 A 崩了,那么 B 发出的请求,得不到相应了。
那么此时 他们两个就是 耦合性高了。
所以我们需要降低耦合性。
这么降低呢?
我们就要用到阻塞队列。
我们在此基础上加上一个 阻塞队列, A 和 B 两个队列不再直接交互,二者通过 阻塞队列这个中转站来完成交互。
如下图:

如果这个时候,A崩了,B 不会受直接影响,阻塞队列中还有数据,还可以维持一段时间,可以给了程序员维修的时间 。
当然拉,阻塞队列也是可以崩的,只是可能性很小,并且之前提到了,它是线程安全的,没有 A 和 B 崩的那么容易。
这个是好处 1 ;还有好处 2
2.削峰填谷
啥叫削峰填谷呢?峰其实很好理解,就像那么大城市,赶早高峰,这就是个峰,这个点人很多啊,交通容易堵;那么同样,我们 服务器之前的通信也同理。
如果某个时间点,突然的,请求多了,那就容易照成堵塞。
我们再举个栗子()
还是两个服务器,A 向 B 发出请求。

正常情况下,两者没有太大问题。
但是突然有个时间点,大量的数据涌入,假如平时是 1w 个请求,那么这个突然就是 10w 个请求,那么服务器A 还能不能顶得住呢?
这得打个问号,具体还是得看服务器性能的(万一顶得住呢)。
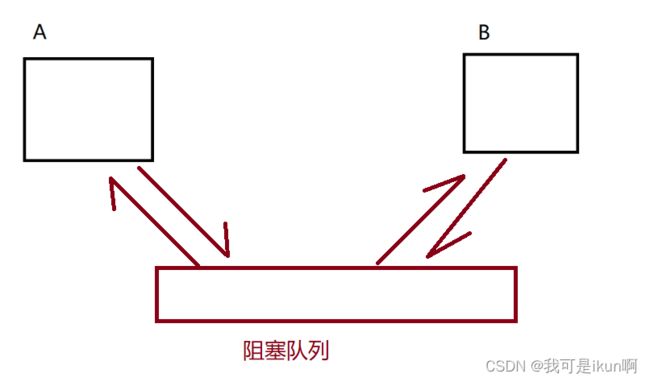
但是我们添加一个阻塞队列,那么就会在突然爆发式的请求下,极大的缓解了 B 服务器的压力。
以上就是 " 削峰 "
那么" 填谷 " 也是类似道理。
某个时间点,突然的服务器请求降低了,为了防止服务器 B 的性能下降 那么引入阻塞队列就会:
阻塞队列会自动调节,当 请求量突然骤减,阻塞队列会拿出之前积压的请求分配给B,这就是填谷 。
我们来模拟一个阻塞队列:
代码:
public class ArrayBlockingQueue {
private int[] items = new int[1000];
// 规定有效长度在 [head,tail) 中有效
volatile private int head; // 通篇都在读,为了防止内存可见性和指令重排序,需要加上 volatile
volatile private int tail;
volatile private int usedSize;
// 入队列 (全文都在修改所以,为了放置出现线程安全问题直接给方法加上synchronized)
synchronized public void put(int elem) throws InterruptedException {
// 队列满了,阻塞
if (usedSize == items.length) {
//return;
//队列满了,需要出队列才能被唤醒,所以 notify 在 出队列中
this.wait();
}
// 存元素
items[tail] = elem;
tail++;
// tail到了数组的尾部,数组没满,tail = 0
if (tail == items.length) {
tail = 0;
}
usedSize++;
this.notify();
}
// 出队列
synchronized public int take() throws InterruptedException {
if (usedSize == 0) { //实现阻塞
//return 0;
this.wait();
}
int ret = items[head];
head++;
if (head == items.length) {
head = 0;
}
usedSize--;
this.notify();
return ret;
}
public synchronized int size() {
return usedSize;
}
}

只有 队列不为空且 队列不满的情况下才可以正常运行,否则线程阻塞等待,直到被唤醒。
虽然说我们阻塞队列可以使用 wait — notify 来操作,但是Java官方文档并不支持。

像下图:
很有可能在其他代码种插入了 interrupt 方法,提前将 wait 唤醒,明明条件还没有满足,队列不为空,但是代码还是继续执行下去了。(目前代码没有插入 interrupt 方法,但是其他项目情况下可能存在该问题)。
所以我们还需要对其进行修改,在 wait 被唤醒以后,再次比较一次条件:
将if 语句改为 while 语句,那么wait 被唤醒以后,再次判断条件是否满足,如果不满足还可以再次 wait。
定时器
定时器也是软件开发中的一个重要组件. 类似于一个 "闹钟". 达到一个设定的时间之后, 就执行某个指定好的代码。
例如:Map 中某个数据 5s 后过期删除。
标准库中的定时器
- 标准库中提供了一个 Timer 类. Timer 类的核心方法为 schedule .
- schedule 包含两个参数. 第一个参数指定即将要执行的任务代码, 第二个参数指定多长时间之后执行 (单位为毫秒)
举例:
import java.util.Timer;
import java.util.TimerTask;
public class Main {
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println(1);
}
},2000);
}
}代码解释:
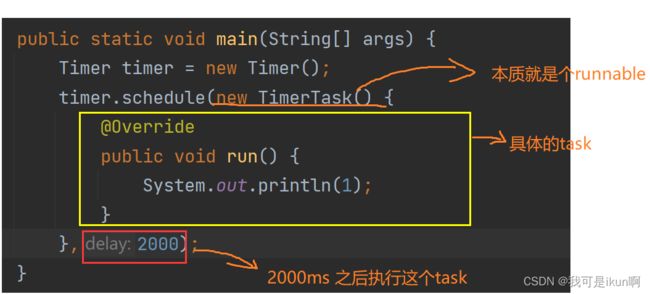
我们来看看schedule 的源码:
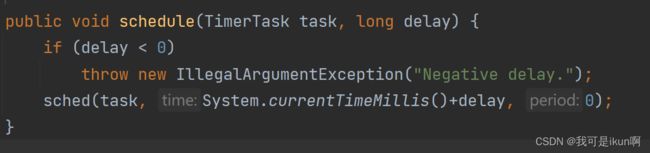
底层调用的是:
System.currentTimeMillis()+delay
调用一个时间戳 加上一个 delay 再去执行代码。
我们跑一跑代码:
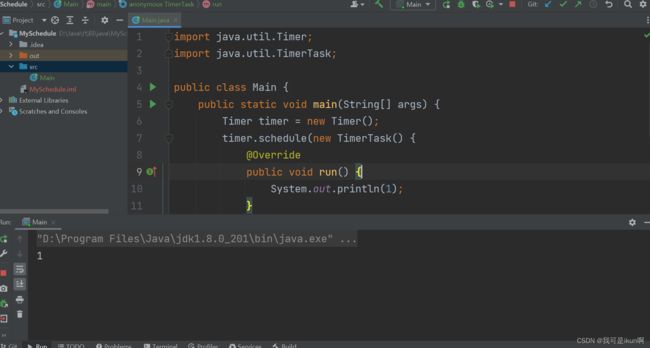
我们发现,并没有直接结束执行。
这是为嘛?

可以看见这个 TimerTask 实现了一个 Runnable 。
Timer 内置了其他线程,而且还是个前台线程,这就会阻止线程结束。
为什么要这么设计呢?
我们计时器应用很多,尤其是网络编程中;当我们在浏览 浏览器时,过长时间没有相应就会弹出提示,那么此时的线程同样没有结束,可以结束等待(刷新、等等),也可以死等。
实现定时器
定时器的构成:
- 一个带优先级的阻塞队列。
为什么我们需要使用这样一个带优先级的阻塞队列呢?
定时器内部管理的任务,很多时候不仅仅只是一个,有可能有多个,假设有 1000 个呢,我们不可能去设定 1000 个线程;
虽然任务很多,但是每个任务实现 出发的时间是不一样的,那么我们可以根据这个不一样的时间去设计 一个/ 一组 工作线程,每次找到这个任务中 找到最先到达的任务。
每次执行完最早的在去执行剩下线程中 时间最早的.......
所以我们需要用到这个带优先级的阻塞队列。
jdk 提供了一个类(带优先级的阻塞队列):PriorityQueue<>()
模拟实现:
我们需要手动封装一个类,该类的作用主要有两个,
- 执行的任务是啥
- 啥时候执行这个任务
MyTask:
class MyTask {
public Runnable runnable;
// 为了方便后续判定, 使用绝对的时间戳.
public long time;
public MyTask(Runnable runnable, long delay) {
this.runnable = runnable;
// 取当前时刻的时间戳 + delay, 作为该任务实际执行的时间戳
this.time = System.currentTimeMillis() + delay;
}
}这里的时间戳,就是上面提到的 schedule 的底层源码。
MyTimer:
// 在这里构造线程, 负责执行具体任务了.
public MyTimer() {
Thread t = new Thread(() -> {
while (true) {
try {
synchronized (locker) {
// 阻塞队列, 只有阻塞的入队列和阻塞的出队列, 没有阻塞的查看队首元素.
while (queue.isEmpty()) {
locker.wait();
}
MyTask myTask = queue.peek();
long curTime = System.currentTimeMillis();
if (curTime >= myTask.time) {
// 时间到了, 可以执行任务了
queue.poll();
myTask.runnable.run();
} else {
// 时间还没到
locker.wait(myTask.time - curTime);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}ok,写到这,我们来测试一个看看代码能不能运行:
public class ImplementMyTimer {
public static void main(String[] args) {
MyTimer myTimer = new MyTimer();
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello4");
}
}, 4000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello3");
}
}, 3000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello2");
}
}, 2000);
myTimer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("hello1");
}
}, 1000);
System.out.println("hello0");
}
}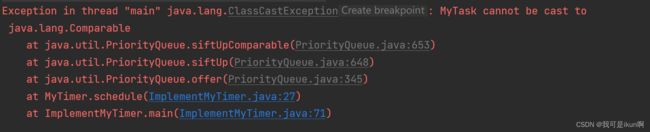
我们发现这个代码出错了,错在不能进行比较。
所以需要加个 比较方法器

修改过后再次执行:

那么多线程的经典案例就到这里,下一章还有一个经典案例:线程池,留在后面将吧。