【Linux】进程地址空间
目录
一、前言
二、进程地址空间
三、扩展内容
1、地址空间存在的必要性
1.1、保护物理内存
1.2、进程与内存的解耦
2、重新理解地址空间
四、总结
一、前言
我们在以往的学习过程中,所知道的内存分布大概如下图所示:
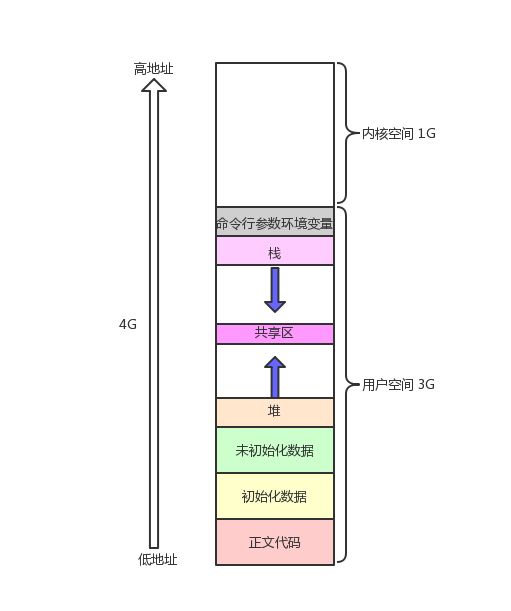
但事实上,我们所学的这张图其实不是内存,而是程序地址空间。
为了证明这种说法,我们可以编写如下代码观察结果:
#include
#include
#include
int g_value = 100;
int main()
{
pid_t id = fork();
assert(id >= 0);
if(id == 0)
{
g_value = 0;
printf("子进程,id: %d, pid: %d, g_value: %d, &g_value: %p\n", getpid(), getppid(), g_value, &g_value);
sleep(1);
}
else
{
printf("父进程,id: %d, pid: %d, g_value: %d, &g_value: %p\n", getpid(), getppid(), g_value, &g_value);
sleep(1);
}
return 0;
}
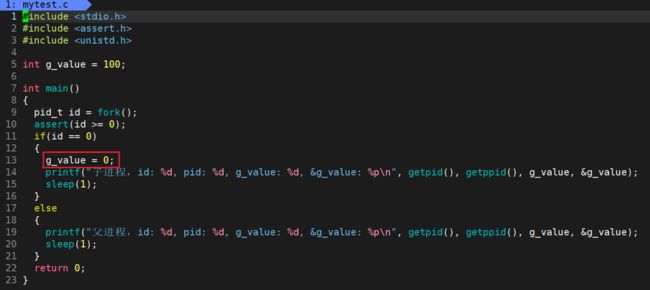

父子进程全局变量 g_value 的地址是相同的,但是值却不同。在之前的文章中,我们说过,进程具有独立性。而进程 = 内核数据结构 + 代码和数据,因此我们需要保证不同进程之间的数据互相不会影响,OS是通过写时拷贝的做法来实现这个目的的。这就可以解释为什么在子进程修改了 g_value 的值后,父进程中的值没有被影响。
能得出如下结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明,该地址绝对不是物理地址!
- 在Linux地址下,这种地址叫做 虚拟地址
- 我们在语言层面所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理,OS必须负责将 虚拟地址 转化成 物理地址 。
二、进程地址空间
地址空间大致的结构图如下:
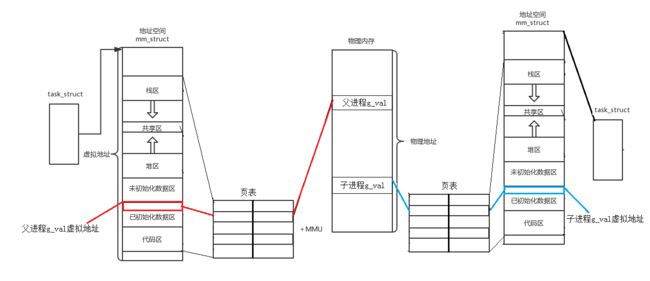
每一个进程在内核中都有一个地址空间结构体,名为 mm_struct ,并且在该进程的 task_struct 中有一个指针指向这个结构体 mm_struct 。我们观察到虚拟地址空间中包含:代码区、数据区、堆区等等区域,这叫做区域划分,通过对线性区域进行指定 start 和 end 即可完成区域的划分:
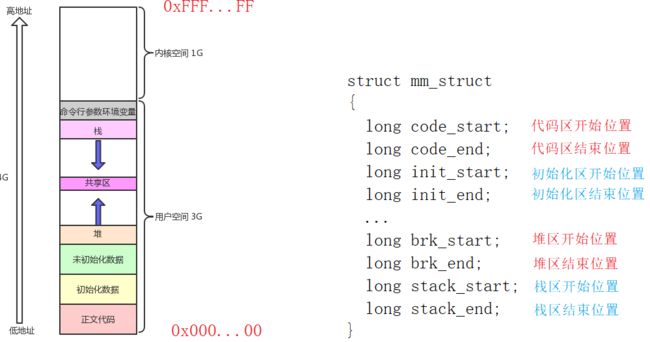
划分完区域后,比如 brk_start 的值为 1000 , brk_end 的值为 5000 。那么 [1000,5000] 之间的区域就叫做虚拟地址或线性地址。对于区域的扩大或缩小操作,只需要改变 start 与 end 的数值就可以了。
由于我们未来在访问地址时,只能访问虚拟地址空间,而数据是被存放在物理内存中的,所以为了将虚拟地址转化为物理地址,OS为该进程创建了页表:
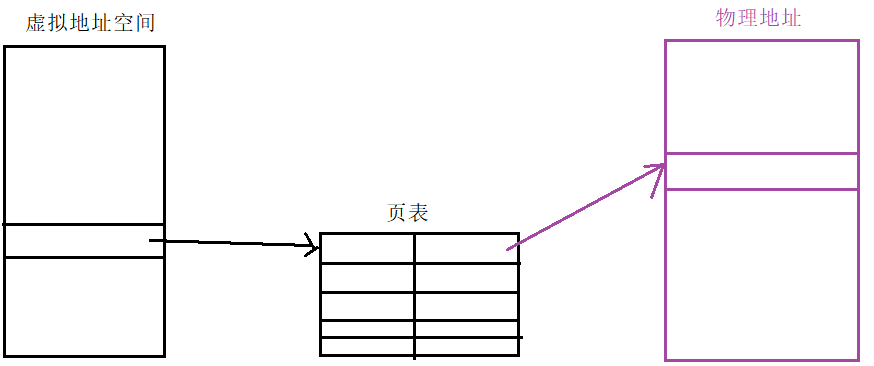
大家可以简单的把页表理解为一个 kv 的映射,其左侧是应用时填充的虚拟地址,右侧是该虚拟地址对应的物理地址,通过页表,我们就可以由虚拟地址找到相应的物理地址了。
当我们创建子进程后,OS以父进程的PCB为模板创建了子进程的PCB结构。所以子进程也拥有自己的 mm_struct ,且在同样的位置存在与父进程相同的虚拟地址:
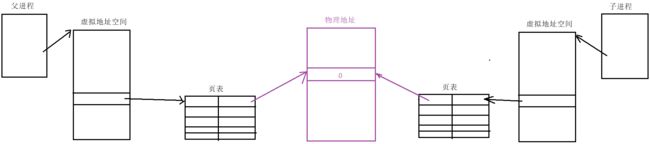
当我们对子进程或父进程的数据不做修改的时候,父子进程读取的变量数据与变量地址都是相同的。而当我们修改父进程或子进程的数据时,先修改哪一个,哪一个就会发生写时拷贝,即在物理内存中另外再开辟一块空间,并修改页表的映射关系,使之映射到新空间:
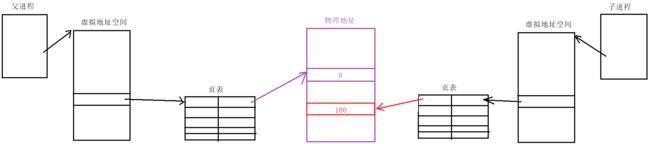
我们所观测到的结果就是该变量的虚拟地址不变,但是其实已经被映射到了物理内存的另一处空间,所以读取到的数据也就不同了。即地址相同,但内容不同。
总结:同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
三、扩展内容
1、地址空间存在的必要性
1.1、保护物理内存
如果没有虚拟地址空间,直接使用物理内存地址的话,那么当多个进程同时被加载到内存中后,如果在cpu执行其中一个进程时,因为我们自己写的代码出错等等原因,导致写入数据的时候,写入到了另一个进程所在的地址中去,就可能导致另一个进程出错,不能保证进程的独立性了。
而有了虚拟地址空间与页表之后,任何一个被 cpu 读进来的数据进行访问的时候,必须要通过地址空间结合页表进行映射,才能够访问对应的物理内存。而在映射的时候,OS会对访问进行检查,如果出现越界的行为,OS会对操作进行拦截,通过添加软件层的方式,来保证在映射过程中,在访问之前对物理空间进行保护。
举个例子,比如下面代码:
char* str = "hello world";
*str = 'H';之所以会报错,就是因为C格式字符串被存放在代码区,而代码区是只读的,我们在使用指针解引用修改时,经过页表映射,被检测到了,所以会报错。
因此虚拟地址空间存在的第一个意义是防止地址随意访问,保护物理内存与其他进程。
1.2、进程与内存的解耦
在向操作系统申请空间时,操作系统并不是立刻就把空间交给我们,而是在需要使用的时候才交给我们的。这是因为操作系统一般不允许任何的浪费和不高效。
我们一般在写代码时,常常会先在前面 malloc 一块空间,可能在进程执行到一半甚至快结束时,才会真正使用这块空间。如果没有虚拟地址空间,在我们申请成功之后,使用之前,这段时间内这块空间都是没有被正常使用且别人也用不了的。这不符合操作系统不允许浪费和不高效的标准。
所以在我们申请空间时,OS只需要在虚拟地址空间上给我们申请空间,即改变 start 或 end 的值,而并没有在物理内存上开辟空间,当我们真正需要使用这块空间时,才会在物理内存上开辟空间,并在页表上建立映射关系。我们把这种机制称为缺页中断。
因此我们并不关心我们所使用的物理地址空间是哪一段,我们只关心虚拟地址空间就可以了,操作系统会通过页表映射自己找到对应的位置。
2、重新理解地址空间
当程序被编译、还没有被加载到内存时,就已经有地址了。当程序被加载到内存中时,会分批次的把代码段、已初始化全局数据段、未初始化全局数据段等等字段加载到地址空间中。换句话说,源代码被编译的时候,就已经按照虚拟地址空间的方式对代码和数据编好了对应的地址。虚拟地址的策略不仅会影响OS,还让编译器也遵守这样的规则。在Linux中,程序被编译后的格式称为 ELF 格式。
程序运行时,操作系统会把程序加载到内存中,cpu以固定的入口地址(比如我们熟知的main函数),通过虚拟地址空间结合页表映射到物理地址,开始执行第一条指令,把第一条指令加载到 cpu 里,而指令里涵盖的都是程序编译时早以生成的虚拟地址,所以又再一次通过虚拟地址空间结合页表映射到物理地址,开始执行第二条指令,以此类推,不断的运行下去。
四、总结
经过上面的学习,我们能够回答下面三个问题:地址空间是什么,为什么有地址空间,以及如何使用地址空间。
虚拟地址空间是在操作系统内部为进程创建出来的一种具体的数据结构对象,让进程能够以统一的视角看待物理内存。因为有了虚拟地址空间的存在,可以让进程管理与内存管理独立开,降低耦合性。
存在地址空间有两点重要的意义,其一是保护物理内存,其二是实现进程与内存的解耦。
地址空间使用是通过在内核中定义一个 mm_struct 数据结构,该数据结构里存在大量的 strat 与 end 划分的区域,并通过页表映射到物理地址。
补充:
进程的代码和数据并不是一直存在于内存中,是通过虚拟地址空间,在需要的时候才在物理内存上开辟空间,并把对应的代码和数据加载到内存中的。
关于进程地址空间的相关内容就讲到这里,希望同学们多多支持,如果有不对的地方欢迎大佬指正,谢谢!