4.9--计算机网络之TCP篇之TCP 重传、滑动窗口、流量控制、拥塞控制--(复习+大总结)---好好沉淀,沉下心来
1.重传机制
TCP 实现可靠传输的方式之一,是通过序列号与确认应答。
在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回一个确认应答消息,表示已收到消息。
TCP 针对数据包丢失的情况,会用重传机制解决
常见的重传机制:
1.超时重传
2.快速重传
3.SACK
4.D-SACK
1.超时重传
在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据
TCP 会在以下两种情况发生超时重传:
1.数据包丢失
2.确认应答丢失
RTT(往返时延):指的是数据发送时刻到接收到确认的时刻的差值,也就是包的往返时间
超时重传时间是以 RTO (超时重传时间)表示:超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
「报文往返 RTT 的值」是经常变化的,超时重传时间 RTO 的值」应该是一个动态变化的值。
如果超时重发的数据,再次超时的时候,又需要重传的时候,TCP 的策略是超时间隔加倍:
每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
超时触发重传存在的问题是:超时周期可能相对较长
2.快速重传
快速重传机制:不以时间为驱动,而是以数据驱动重传
快速重传的工作方式是:
当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
快速重传机制只解决了一个问题,就是超时时间的问题
但是它依然面临着另外一个问题:就是重传的时候,是重传一个,还是重传所有的问题
不管是重传一个报文,还是重传已发送的报文,都存在问题:
1.选择重传 一个报文,那么重传的效率很低
2.选择重传已发送的所有报文,浪费资源
3.SACK 方法
选择性确认
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
4.Duplicate SACK(复制)–D-SACK
使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。
D-SACK 有这么几个好处:
1.可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
2.可以知道是不是「发送方」的数据包被网络延迟了;
3.可以知道网络中是不是把「发送方」的数据包给复制了;
2.滑动窗口
1.窗口大小由哪一方决定?
通常窗口的大小是由接收方的窗口大小来决定的。
2.接收窗口和发送窗口的大小是相等的吗?
并不是完全相等,接收窗口的大小是约等于发送窗口的大小的。
因为滑动窗口并不是一成不变的。比如,当接收方的应用进程读取数据的速度非常快的话,这样的话接收窗口可以很快的就空缺出来。那么新的接收窗口大小,是通过 TCP 报文中的 Windows 字段来告诉发送方。那么这个传输过程是存在时延的,所以接收窗口和发送窗口是约等于的关系
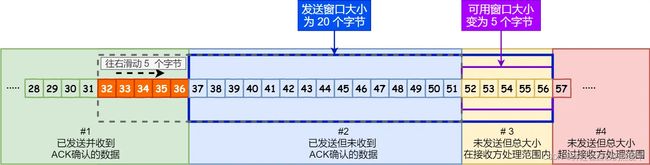
3.程序是如何表示发送方的四个部分的呢?
TCP 滑动窗口方案使用三个指针来跟踪在四个传输类别中的每一个类别中的字节。
其中两个指针是绝对指针(指特定的序列号),一个是相对指针(需要做偏移)。
3.流量控制
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制
4.拥塞控制
1.为什么要有拥塞控制呀,不是有流量控制了吗?
流量控制是避免「发送方」的数据填满「接收方」的缓存,但是并不知道网络的中发生了什么
计算机网络都处在一个共享的环境。因此也有可能会因为其他主机之间的通信使得网络拥堵。
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大
于是,就有了拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络
1.什么是拥塞窗口?和发送窗口有什么关系呢?
拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的。
加入了拥塞窗口的概念后,此时发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值
拥塞窗口 cwnd 变化的规则:
只要网络中没有出现拥塞,cwnd 就会增大;
但网络中出现了拥塞,cwnd 就减少
怎么知道当前网络是否出现了拥塞呢?
只要「发送方」没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
2.拥塞控制有哪些控制算法?
拥塞控制主要是四个算法:
慢启动
拥塞避免
拥塞发生
快速恢复
2.1慢启动
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1
那慢启动到什么时候不增加了呢?
有一个慢启动门限 ssthresh (slow start threshold)状态变量。
当 cwnd < ssthresh 时,使用慢启动算法。
当 cwnd >= ssthresh 时,就会使用「拥塞避免算法」。
2.2拥塞避免算法
进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd
拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度缓慢了一些。
2.3拥塞发生
当网络出现拥塞,也就是会发生数据包重传,重传机制主要有两种:
超时重传
快速重传
2.3.1发生超时重传的拥塞发生算法
ssthresh 和 cwnd 的值会发生变化:
1.ssthresh 设为 cwnd/2
2.cwnd 恢复为 cwnd 初始化值
这种方式太激进了,反应也很强烈,会造成网络卡顿
2.3.2发生快速重传的拥塞发生算法
当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传
ssthresh 和 cwnd 变化如下:
1.cwnd = cwnd/2 ,也就是设置为原来的一半
2.ssthresh = cwnd
3.进入快速恢复算法
2.4快速恢复
快速重传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈
快速恢复算法如下:
1.拥塞窗口 cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了);
2.重传丢失的数据包;
3.如果再收到重复的 ACK,那么 cwnd 增加 1;
4.如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated重复 ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
快速恢复算法过程中,为什么收到新的数据后,cwnd 设置回了 ssthresh ?
1.在快速恢复的过程中,首先 ssthresh = cwnd/2,然后 cwnd = ssthresh + 3,表示网络可能出现了阻塞,所以需要减小 cwnd 以避免,加 3 代表快速重传时已经确认接收到了 3 个重复的数据包;
2.随后继续重传丢失的数据包,如果再收到重复的 ACK,那么 cwnd 增加 1。加 1 代表每个收到的重复的 ACK 包,都已经离开了网络。这个过程的目的是尽快将丢失的数据包发给目标。
3.如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,恢复过程结束。
首先,快速恢复是拥塞发生后慢启动的优化,其首要目的仍然是降低 cwnd 来减缓拥塞,所以必然会出现 cwnd 从大到小的改变。
其次,过程2(cwnd逐渐加1)的存在是为了尽快将丢失的数据包发给目标,从而解决拥塞的根本问题(三次相同的 ACK 导致的快速重传),所以这一过程中 cwnd 反而是逐渐增大的。