LightGBM 的优点(相较于XGBoost) + 细节操作 讲解 (二)单边梯度采样 和 互斥特征捆绑
这里是LightGBM优势讲解第二篇,主要包含LightGBM的优势,以及LightGBM中 单边梯度采样 Gradient-based One-Side Sampling(GOSS) 和 互斥特征捆绑 Exclusive Feature Bundling (EFB) 。
第一篇链接:主要讲解LightGBM优势 + Leaf-Level 叶子生成策略 + 直方图算法LightGBM 的优点(相较于XGBoost) + 细节操作 讲解 (一)_云从天上来的博客-CSDN博客
1. 单边梯度采样(Gradient-based One-Side Sampling,GOSS)
单边梯度采样本质上是一个样本采样算法,核心作用是对训练集样本采样进行优化,它将排除大部分小梯度样本,用剩余的样本计算信息增益,是一种在减少数据量和保证精度的平衡的算法。
核心原理:根据信息增益的定义,梯度大的样本对信息增益影响更大,因此GOSS在进行数据采样时,保留了梯度较大的样本,但是如果直接将所有梯度较小的样本丢失,必然会导致采样后的数据分布与原始数据总体分布有较大差异。所以,在具体操作中首先保留所有梯度较大的样本A,然后对梯度较小的部分以一定的采样率随机抽样得到集合B,接着对集合B乘以一个权重系数得到C,最后使用集合(A + C)计算信息增益。
算法描述:
输入:训练样本I,迭代步数d,大梯度样本采样率a%,小梯度样本采样率b%;权重系数
(1 - a) / b ;
(1)根据模型进行预测,得到样本预测值preds;进一步计算loss和样本梯度;
(2)计算样本梯度值,并根据梯度的绝对值进行降序排序;得到sorted,是样本的索引数组
(3)对排序后的结果,选取前a%,构建大梯度样本子集A,即前(sample_num * a %)个;
(4)对剩余样本,随机采样(sample_num *b%)个,构建小梯度样本子集B;
(5)将大梯度样本A 和 小梯度样本B 合并,得到usedSet,索引数组,
size大小(a% + b%) * sample_num
(6)对子集B中每个样本的权重,统一乘以权重系数(1 - a) / b,更新子集B的样本权重(避免样本分布不一致),即w[randSet] = w[B];
(7)根据usedSet索引上样本 I,梯度 g,权重 w,训练得到新的弱学习期newModel;
(8)将newModel,加入总模型(LightGBM和XGB都是加法模型)。

2. 互斥特征捆绑 Exclusive Feature Bundling (EFB)
互斥特征捆绑,是从降低特征维度的角度出发,进一步特征个数,提高训练速度。
那么这里就存在两个问题:什么样的特征可以进行合并?如何合并?
2.1 如何判定哪些特征应该捆绑在一起
理想情况下,被捆绑的特征都是互斥的(即特征不同时为非空 or 非零值,像one-hot,一个样本只有某一维度 or 某一个特征为1,其余均为0),这样特征捆绑后不会丢失信息。
在实际中,不同时 + 非空(简单理解为不同时为1)的特征组合很少,因此LightGBM使用一种基于图着色的 + 近似贪心的 特征捆绑策略;
图着色问题:首先构图(build graph),将特征作为节点,将非互斥的特征连接起来。
近似贪心:图着色问题是一个NP-hard问题,不可能在多项式时间内找到最优解。因此EFB允许特征之间存在少数样本不互斥(简单理解为某一特征在对应样本间同时为1),这里体现为设定一个最大冲突阈值K。近似的概念,允许特征簇之间存在一定程度的冲突,进一步的增加可捆绑的特征对 + 降低特征的维度,K 的选取也用来平衡准确度和训练效率。
EFB算法描述:
(1)构图:将特征作为图的顶点,将非互斥的特征进行相连(存在同时不为空 or 零值的样本),边权重设置为特征同时不为0的样本数目;
(2)根据顶点的度对特征进行降序排序,度越大表明特征与其他特征的冲突越大(越不太可能与其他特征进行捆绑);
(3)设置最大冲突阈值K,外层 i 循环遍历每一个特征(排序后);内层 j 循环遍历已有的特征捆绑簇,如果当前特征加入到该特征簇中的冲突数没有超过最大阈值 K,则特征捆绑入该簇中,并跳出循环;否则新建一个特征簇,并将该特征加入到新簇中。
注意:上述算法是朴素版本,是EFB中判定哪些特征可以捆绑在一起,构成簇的算法。
上述算法复杂度 O(n2),n为特征数目。算法主要由两部分组成 构图(包括计算互斥程度 / 边权)+ 特征捆绑。
构图是最耗时的部分,同样需要两层for循环计算两两特征间的互斥程度。
为了提高效率,取消构图环节,将特征直接按照非零值个数排序,然后将特征非零值个数作为节点的度,进一步来衡量冲突程度(特征非零值很多,意味着引起冲突的概率更大)。
这里改进版的算法,只取消了构图 + 改进了排序策略,计算某个特征属于哪个特征簇的循环部分没有变。

2.2 如何将特征捆绑在一起
特征合并算法,关键在于原始特征能从合并的特征中分离出来,即绑定到同一个bundle里面的特征的原始值(未绑定前的原始特征值)可以在bundle中识别 or 分离出,这样方便使用。
由于 LightGBM 基于直方图计算,当多个特征捆绑到一起时,EFB算法只需要为不同的特征重新分配不重叠的取值空间(bin值)即可,具体操作引入了一个偏移常量(offset)来解决。
举个例子1,绑定两个特征A和B,A取值范围为[0, 10),B取值范围为[0, 20)。则我们可以加入一个偏移常量10,即将B的取值范围变为[10,30),然后合并后的特征范围就是[0, 30),并且能很好的分离出原始特征~
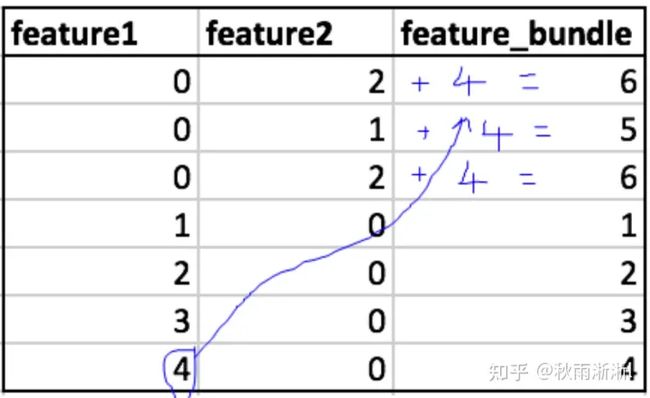
举个例子2,feature1的取值范围是[0, 5),fearure2的取值范围是[0, 3),将特征2中所有值统一加上特征1取值范围的最大值,此时feature2的取值范围变为[4,7),合并后的bundle范围是[0,7)。

最后:下一篇 LightGBM讲解(三) 将会讲述 直接支持类别特征(Categorical Feature)的工程操作 和 高效并行的工程操作;