MySQL执行计划explain的详解
一、如何查看SQL执行计划:
在MySQL中生成执行计划的方法很简单,在SQL语句前面加explain既可。
explain可以作用于SELECT/INSERT/UPDATE/DELETE和REPLACE语句。
本文举例中涉及的表和数据都在第三部分测试数据准备脚本。
二、执行计划输出列解读:
当使用explain时,输出中包含的列为:
id,select_type,table,type,possible_keys,key,key_len,ref,rows,filtered, Extra
0、总览
举例如下:
explain select student.sname, sc.score from student, sc, teacher
where student.s_id = sc.s_id and sc.t_id = teacher.t_id
and teacher.tname = 'tname16';1、ID
包含一组数字,表示select查询的序列号,标识执行的顺序。
id相同,执行顺序由上至下;
id不同,id 值越大优先级越高,越先被执行
id为NULL的类型为union result,
子查询改写成join查询的情况,ID值不会增加。
--子查询举例
explain select * from teacher where t_id =
(select t_id from teacher where tname = 'name16');
--union查询举例
explain
select sname from student where sno = 100
union all
select sname from student where sno = 200
union all
select sname from student where sno = 300;
--id为NULL的类型为union result
explain
select sname from student where sno = 100
union
select sname from student where sno = 200--子查询改写成join查询的情况,ID值不会增加
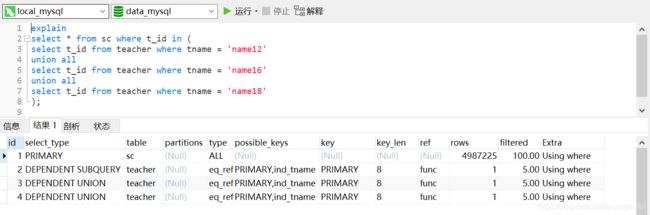
explain
select c_id from sc where t_id in (select t_id from teacher where tname = 'name18');
2、SELECT_TYPE
SELECT查询的类型,主要是区别普通查询、联合查询、子查询之类的复杂查询。
SIMPLE:
简单的select查询,查询中不包含子查询或者union查询。
PRIMARY:
查询中包含任何复杂的子部分(子查询或者union查询),最外层查询则被标记为primary。
SUBQUERY:
在select 或 where列表中包含的子查询,子查询内层查询的第一个SELECT,结果不依赖于外部查询结果集。
DEPENDENT SUBQUERY:
子查询中内层的第一个SELECT,依赖于外部查询的结果集(子查询的结果集*外部查询结果);
UNCACHEABLE SUBQUERY:
结果集无法缓存的子查询,对于外部查询中的每一行都必须重新计算(动态计算,耗时操作)。
DERIVED:
在from列表中包含的子查询被标记为derived(衍生查询),mysql或递归执行这些子查询,把结果放在临时表里。
UNION:
UNION语句中第二个SELECT开始的后面所有SELECT,第一个SELECT为PRIMARY;若union包含在from子句的子查询中,外层select将被标记为derived。
DEPENDENT UNION:
子查询中的UNION,且为UNION 中从第二个SELECT 开始的后面所有SELECT,同样依赖于外部查询的结果集;
UNION RESULT:
UNION中的合并结果,id列为null,table列显示了是由哪几个查询的结果做的union。
MATERIALIZED:
物化子查询,可以当作一个临时表,存储子查询的结果。
关于dependent subquery和uncacheable subquery,官方文档是这样解释的:
DEPENDENT SUBQUERY evaluation differs from UNCACHEABLE SUBQUERY evaluation. For DEPENDENT SUBQUERY, the subquery is re-evaluated only once for each set of different values of the variables from its outer context. For UNCACHEABLE SUBQUERY, the subquery is re-evaluated for each row of the outer context.
翻译如下:
dependent subquery评估和uncacheable subquery评估不同。dependent subquery对于外部查询中的不同的值只计算一次。
而uncacheable subquery对于外部查询中的每一行都重新评估一次。(由此可见两者的执行效率完全不同,极端情况下能差好几个数量级)



3、TABLE
查询结果出自哪张表。可以是具体的表名或表的别名,也可以是以下的值:
union M,N:id为M和N的查询结果做union
derivedN:参考id为N的查询的衍生查询
subqueryN:参考id为N的物化子查询

4、TYPE
表连接类型,访问方式。
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。

system :表中只有一行数据(=system table),是const类型的特殊情况。
const :表中最多只有一行符合条件的行,该行在查询一开始就会被读取。因为只有一行,所以优化器可以把这一值看做常数。const连接类型速度非常快,因为只读取一次。经常用在在主键或者唯一索引上做等值查询。

eq_ref:可以理解为利用主键或者唯一非空索引做等值唯一连接。从表里取出一行来,与从之前的表里取出的行做连接。不同于system和const,这个是最常用的连接方式。
这是用在索引的全部都用来做连接,并且该索引为主键或唯一非空索引时。eq_ref用在索引列做等值连接。与之相比较的值可以是常数,或者与之前表的列有关的表达式。
ref:可以理解为非唯一性索引扫描。从索引中将对应值的行取出来,跟之前表中取出的数据做连接。如果只使用了索引的左前缀,或者非主键非唯一索引做链接时,用ref。(换句话说,对于给定的值,返回的行数不止一行。)如果给定的值只返回很少的行,这是个很好的连接方式。ref可以用于在索引列上做=或>=,<=操作。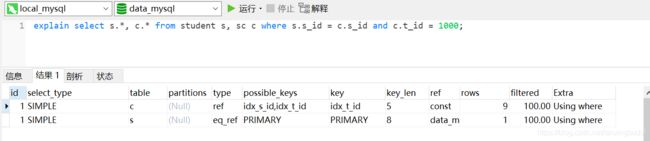
fulltext:全文索引。
ref_or_null:连接方式跟ref相似,但是增加了一个额外的搜索条件,包含null值。这种连接方式优化大多用于解决子查询问题。

index merge:这种连接方式表明使用了index merge优化,查询使用到了一个表中多个索引。在这种情况下,explain输出的列中,key列包含用到的索引的列表,key_len列包含用到的列的最大长度的列表。
unique_subquery:这种方式用于在使用in关键字进行子查询时,代替ref连接方式。
unique_subquery是一个索引查询方法,用来代替子查询以提供更好的效率。
index_subquery:这种连接方式类似于unique_subquery,代替了IN方式的子查询,但是用于非唯一索引的子查询。
range:索引范围查询。利用索引查询,返回给定范围内的行。在explain的输出中,key列显示使用了哪个索引,key_len列显示使用到的列的最长部分,在这种情况下,ref列为null。range用于key列与常数作比较,操作符可以是 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, 或者 IN。

index:index: 连接类型跟 all 一样,不同的是它只扫描索引树。
有两种情况:
(1)如果索引是覆盖索引,所有需要的数据都可以从索引中获得,此时只扫描索引。在这种情况下,explain命令的输出中,Extra列显示 Using index。它通常会比 all快点,因为索引文件通常比数据文件小。
(2)通过查询索引,以索引的排列顺序做全表扫描。在这种情况下,Extra列不会显示using index。

all:全表扫描。

5、possible_keys
指 mysql在搜索表记录时可能使用哪个索引。
possible_keys里面所包含的索引可能在实际的使用中没用到。如果这个字段的值是null,就表示没有索引被用到。
这种情况下,就可以检查 where子句中哪些字段那些字段适合增加索引以提高查询的性能。
6、key
key字段显示了mysql实际上要用的索引。
当没有任何索引被用到的时候,这个字段的值就是null。
想要让mysql强行使用或者忽略在 possible_keys字段中的索引列表,可以在查询语句中使用关键字force index, use index,或 ignore index。
如果是 myisam 和 bdb 类型表,可以使用 analyzetable 来帮助分析使用使用哪个索引更好。
如果是 myisam类型表,运行命令 myisamchk –analyze也是一样的效果。
7、key_len
显示MySQL决定使用的键长度。表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。如果键是NULL,长度就是NULL。文档提示特别注意这个值可以得出一个多重主键里mysql实际使用了哪一部分。可以告诉你在联合索引中mysql会真正使用了哪些索引。
注:key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
计算方式:
字符串类型,要考虑字符串的长度和是否为空;
数字类型、时间日期类型。
8、ref
ref 字段显示了哪些字段或者常量被用来和 key配合从表中查询记录出来。
9、rows
rows 字段显示了mysql认为在查询中应该检索的记录数。 表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,在innodb上可能是不准确的。
10、extra列包含了mysql处理sql的一些附加信息。
如果你想让查询速度尽可能的快,那么就要注意Extra列中值为using filesort和using temporary。
Using filesort
mysql需要额外的做一遍从而以排好的顺序取得记录。排序程序根据连接的类型遍历所有的记录,并且将所有符合 where条件的记录的要排序的键和指向记录的指针存储起来。这些键已经排完序了,对应的记录也会按照排好的顺序取出来。

Using index
字段的信息直接从索引树中的信息取得,而不再去扫描实际的记录。这种策略用于查询时的字段是一个独立索引的一部分。
如果extra列中同时还有using where,意思是这个索引时用来查找键值,然后回表。
如果没有using where,优化器可能是为了避免回表。
例如,如果索引时覆盖索引,优化器扫描索引,而不是用索引来回表。
对于有聚集索引的表,即使extra列中没有using index,也可以使用索引。这适用于type列是index,key列是primary的情况。
Using index condition
ICP优化相关,将数据过滤条件从server层面下推到存储引擎层,在存储引擎层根据索引元祖过滤数据,避免不符合条件的数据传给server。(非翻译,整理自网络。)

Using index for group-by
与using index类似,using index for group-by表明mysql找到一个索引,该索引可以返回所有group-by或distinct查询所需的列,不需要回表。
Using join buffer (Block Nested Loop), Using join buffer (Batched Key Access)
做连接时,当前表之前的表被分多次读入join buffer中,然后join buffer中的表再跟当前表做join。(Block Nested Loop) 表明使用BNL算法。 (Batched Key Access)表明使用BKA算法。explain中,上一行的keys会被读入buffer,然后当前表的相应的行会被分批获取。(具体什么意思,再查!)
Using MRR
MRR优化方式,具体再查。
Using sort_union(…), Using union(…), Using intersect(…)
Using temporary
mysql需要创建临时表存储结果以完成查询。这种情况通常发生在查询时包含了group by 和 order by 子句,它以不同的方式列出了各个字段。
Using where
过滤符合条件的行。
当extra列中没有using where并且表连接类型为all或者index时,你可能执行了错误的查询,除非你要获取或检查所有的行。
Using where with pushed condition
仅适用于NDB。从各个节点过滤数据。
no matching row in const table: 对一个有join的查询,包含一个空表或者没有数据满足一个唯一索引条件。
最后补充:
partitions列显示查询涉及到的分区;
filtered,它指返回结果的行占需要读到的行(rows列的值)的百分比。按说 filtered是个非常有用的值,因为对于join操作,前一个表的结果集大小直接影响了循环的次数。但是我的环境下测试的结果却是, filtered的值一直是100%,也就是说失去了意义。
三、数据准备:
--以下内容为student、course、sc、teacher四张表的建表语句以及插入测试数据的函数语句。
--学生表student的建表语句和插入测试数据的函数。
drop table if exists student;
create table student
(
s_id bigint unsigned not null auto_increment,
sno int,
sname varchar(50),
sage int,
ssex varchar(8),
father_id int,
mather_id int,
note varchar(500),
primary key uk_sid(s_id)
);
truncate table student;
delimiter $$
drop function if exists insert_student_data $$
create function insert_student_data()
returns int deterministic
begin
declare i int;
set i = 1;
while i <= 5000000 do
insert into student values(i, i, concat('name', i), i, case when floor(rand()*10%2) = 0 then 'f' else 'm' end,
floor(rand()*100000),floor(rand()*10000),concat('note',i));
set i = i + 1;
end while;
return 1;
end $$
delimiter ;
select insert_student_data(); --执行插入测试数据的函数,500万条数据大约300秒。
select count(*) from student;
--课程表course的建表语句和插入测试数据的函数。
drop table if exists course;
create table course
(
c_id bigint unsigned not null auto_increment,
cname varchar(50),
note varchar(500),
primary key (c_id)
);
truncate table course;
delimiter $$
drop function if exists insert_course_data $$
create function insert_course_data()
returns int deterministic
begin
declare i int;
set i = 1;
while i <= 1000 do
insert into course values (i, concat('course', i), floor(rand() * 1000));
set i = i + 1;
end while;
return 1;
end$$
delimiter ;
select insert_course_data();
select count(*) from course;
--分数表sc的建表语句和插入测试数据的函数。
drop table if exists sc;
create table sc
(
s_id int,
c_id int,
t_id int,
score int
);
truncate table sc;
delimiter $$
drop function if exists insert_sc_data $$
create function insert_sc_data()
returns int deterministic
begin
declare i int;
set i = 1;
while i <= 5000000 do
insert into sc values (i, floor(rand()*1000), floor(rand()* 100000), floor(rand()*800));
set i = i + 1;
end while;
return 1;
end $$
delimiter ;
select insert_sc_data();
create index ind_s_id on sc(s_id);
create index ind_t_id on sc(t_id);
create index ind_c_id on sc(c_id);
select count(*) from sc;
--教师表teacher的建表语句和插入测试数据的函数。
drop table if exists teacher;
create table teacher
(
t_id bigint unsigned not null auto_increment,
tname varchar(50),
note varchar(500),
primary key (t_id)
);
truncate table teacher;
delimiter $$
drop function if exists insert_teacher_data $$
create function insert_teacher_data()
returns int deterministic
begin
declare i int;
set i = 1;
while i <= 1000000 do
insert into teacher values (i, concat('name',i), concat('note', i));
set i = i + 1;
end while;
return 1;
end $$
delimiter ;
select insert_teacher_data();
commit;
create index ind_tname on teacher(tname);
select count(*) from teacher;文章来源博客:mysql explain 输出详解_lijingkuan的博客-CSDN博客