mysql explain 执行计划详解
文章目录
-
- mysql outline
- 简介
- 先了解一下MySQL整个查询过程
- Explain分析示例
-
- 重点关注的列:type key rows filtered extra
- id列
- select_type列
- table列
- type列
- possible keys列
- key列
- rows列
- key_len列
- filtered 列
- extra列
- 什么情况下索引会失效?
- sql 语句优化实战
mysql outline
mysql outline
简介
我们写的sql语句,怎么才能知道它是否是慢SQL呢?是根据网上的一些现成的调优语句吗?
不是根据网上现成的调优语句,而是根据以下2种常用的方案:
第一种是开启本地MySQL的慢查询日志,通过explain关键字生成查询计划,然后分析查询计划,进而来优化我们的慢sql语句;另一种是阿里云提供的RDS(第三方部署的MySQL服务器),其中它提供了查询慢SQL的功能。这里只介绍第一张方案
先了解一下MySQL整个查询过程

简单来说:
- 客户端向 MySQL 服务器发送一条查询请求
- 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
- 服务器进行 SQL 解析、预处理、再由优化器生成对应的执行计划
- MySQL 根据执行计划,调用存储引擎的 API 来执行查询
- 将结果返回给客户端,同时缓存查询结果
注意:只有在8.x之前才有查询缓存,8.x之后查询缓存被干掉了
Explain分析示例
explain select * from student;
当使用关键字explain 查看某条sql语句的执行计划后,mysql会反馈给我们一些字段,如下图,只有了解这些字段是什么意思,才能调优慢sql

| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 8 | 100 | NULL |
重点关注的列:type key rows filtered extra

id列
-
id 值相同时被视为一组,然后从上向下依次执行
-
如果有子查询,子查询id 值会递增,id 值越高,优先级越高
不用纠结具体的字段,只需要关注大致的逻辑即可

3. id为NULL则该表最后执行
select_type列

- simple:不包含子查询的简单的查询

- primary:最外部的select查询,被标记为primary

- derived:子查询只要在from后面,就会生成一张衍生表。该衍生表的查询类型被标记为 derived
不用纠结语句表示具体的什么意思,看逻辑即可

- subquery:在select之后,from之前的子查询,被标记为subquery
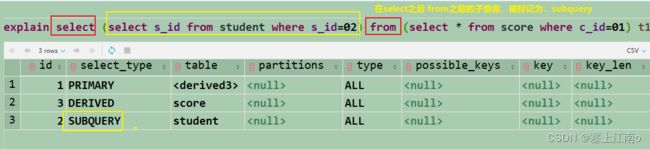
- union:
使用union进行的联合查询的类型
table列
当前查询正在查哪张表

type列
- type列可以直观的判断出当前的sql语句的性能,type的取值和性能的优劣顺序如下
- 对于SQL优化来说,要尽量保证type列的值是属于range及以上级别
null > system > const > eq_ref > ref > range > index > all

- null:通常是对索引列使用了聚合函数
因结果直接从索引树获取即可,所以性能最好
- system
很少见
表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
-
const:使用主键索引或唯一索引和常量进行比较,这种性能非常好
-
eq_ref:在进行多表join时,在关联条件
on中使用了主键
# 假设 student .s_id.s_id 是主键索引
explain select * from student left join score on student .s_id = score .s_id
- ref
使用了普通索引扫描或唯一索引前缀扫描
- 简单查询:
# 假设 student.s_id 是普通索引或者是唯一索引的前缀
explain select * from student where s_id='01'
# 上述查询条件s_id是普通列索引,那么类型为ref
- 关联查询:
# 假设 student.s_id 是普通索引或者是唯一索引的前缀
explain select * from student left join score on student .s_id = score .s_id
# 上述查询条件s_id是普通列索引,那么类型为ref
- range: 使用索引进行了范围扫描
# 假设 student.s_id是索引列
explain select * from student where s_id>'02'
- index
索引扫描(列中数据可以直接从索引树上获取,换句话说该列是索引列)
- all
没有走索引,进行了全表扫描
# 一般情况下,一个表当中索引列不可能全覆盖,换句话说有普通字段
explain select * from student
possible keys列
本次查询可能会用到的索引。具体来说就是,mysql内部优化器会进行判断,如果这一次查询走索引的性能比全表扫描的性能要差,那么内部优化器就让此次查询进行全表扫描,这样的判断依据我们可以通过trace工具来查看
# 假设student 表中的数据共有20行,s_id从1到20
explain select * from student where s_id like '%1%' # 查询s_id中包含1的数据有哪些
# 数据共有20行,s_id中包含1的数据有一半,这时候走索引合适,还是全表扫描合适呢?
key列
查询真正使用到的索引
rows列
该sql语句可能要查询的数据条数
key_len列
键的长度,通过这一列可以让我们知道当前命中了联合索引中的哪几列
filtered 列
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了
这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数
extra列
extra列提供了额外的信息,这些信息能够帮助我们判断当前sql是否使用了覆盖索引、文件排序、或者是是否使用了索引列进行了条件查询等等
- using index:使用了覆盖索引
所谓的覆盖索引,指的是当前查询的所有数据字段都是索引列,这就意味着可以直接从索引列中获取数据,而不需要进行查表
覆盖索引是sql优化经常要用到的
# 假设book_id,author_id都是索引列
explain select book_id,author_id from tb_book_author where book_id = 1 -- 覆盖索引
# 假设tb_book_author 表有3个字段,分别为 book_id,author_id,remark,其中book_id,author_id都是索引列,remakr是普通字段
explain select * from tb_book_author where book_id = 1 -- 没有使用覆盖索引
- using where
无法直接通过索引查找来查询到符合条件的数据,需要回表去查询所需的数据
# 假设 name 为普通索引列
explain select * from tb_author where name > 'a'
- using index condition
查询结果没有使用覆盖索引(没有使用到字段remark),建议可以使用覆盖索引来优化
# 假设tb_book_author 表有3个字段,分别为 book_id,author_id,remark,其中book_id,author_id都是索引列,remakr是普通字段
explain select * from tb_book_author where book_id > 1
- using temporary
使用了临时表保存中间结果,性能特别差,需要重点优化
# 假设当前name 列没有索引
explain select distinct name from tb_author
# 在非索引列name上进行去重操作时,系统会使用一张临时表来实现,性能非常差
- using filesort
排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
# name 普通列
explain select * from tb_author order by name
# 使用了磁盘+内存的方式进行了文件排序
- Select tables optimized away
直接在索引列上进行聚合函数的操作,没有进行任何的表的操作
# id为主键索引列
explain select min(id) from tb_book
什么情况下索引会失效?
- 不遵循最左前缀法则书写sql语句
- 业务条件允许的情况下不想办法去给待查询字段使用覆盖索引
- 涉及in和exists的范围查询
- 索引列上参与计算会导致索引失效
- 模糊查询中是以 % 开头
- 查询询条件使用了 or
sql 语句优化实战
sql 语句优化实战