【关于Linux中----生产消费模型】
文章目录
- 一、生产消费模型
-
- 1.1概念的引入
- 1.2 321原则
- 二、条件变量
-
- 2.1概念的引入
- 2.2理解条件变量
- 2.3条件变量的使用
- 三、基于BlockingQueue的生产者消费者模型
-
- 3.1BlockingQueue的介绍
- 3.2C++ queue模拟阻塞队列的生产消费模型
- 3.3对生产消费任务的模拟封装
- 四、遗留问题
一、生产消费模型
1.1概念的引入
众所周知,在多线程环境里,避免不了会出现多个执行流访问同一块共享资源的情况。但是,如果一个执行流长时间地持有锁,或者它抢占锁的能力更强,就很有可能导致其他执行流出现饥饿问题。所以,我们急切地需要一种模式来尽可能地平衡多个执行流访问公共资源的公平性,于是就出现了“生产消费模型”。
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
1.2 321原则
生产消费模型中的“交易场所”(阻塞队列)就是一块共享资源。既然是共享资源,就有可能同时被多个执行流访问,所以就必须想办法将其保护起来。
首先要知道生产者和生产者之间是互斥(竞争)关系,消费者和消费者之间也是如此,生产者和消费者之间j既有互斥关系(为了保证数据安全)又有同步关系(为了保证双方效率)。
以上内容可以总结为321原则:
3种关系:生产者和生产者(互斥),消费者和消费者(互斥)生产者和消费者(互斥&&同步)
2中角色:生产者线程和消费者线程
1个交易场所:一段特定结构的缓冲区
所以,生产消费模型本质上就是维护好321原则,也就保证了共享资源的安全性和双方的效率。
由此也可以总结出生产消费模型特点:
- 解耦----生产消费双方都通过共享资源提供和使用数据
- 支持生产消费忙闲不均----共享资源具有缓存数据的能力
- 提高效率
虽然共享资源具有缓存数据的能力,但是当生产者没有向缓冲区中写入数据时,消费者就只能等待数据;同样的道理,当缓冲区已经存满时,生产者就只能等消费者取走数据。所以,生产消费模型的所谓“提高效率”的特点到底体现在哪里?(这个问题下文中解释)
二、条件变量
2.1概念的引入
由于需要保证生产消费模型中个共享资源的安全,所以生产消费者之间一定有互斥关系,所以二者在访问共享资源时一定要持有锁,并且判断可不可以向其中写入或读取数据,然后再解锁。
所以,当生产者将数据放入缓冲区,直至缓冲区被填满,它下一次在向其中放入数据时就会先申请锁,再判断可不可以放入数据,不能放入数据,最后解锁离开。但是由于生产者申请锁的能力较强,就会一直先于消费者去访问共享资源,这就又导致了消费者的饥饿问题。
为了解决这个问题,就必须使用条件变量(一种数据类型):
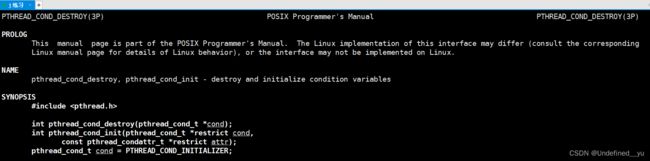
跟互斥锁的接口很相像,使用前要先定义一个条件变量,再初始化,使用完之后释放条件变量,当然也可以直接将其定义为全局的。
下面再回到上面说的“导致消费者饥饿”的问题,我们可以加一个条件变量,让生产者和消费者都在满足条件的时候,才可以访问公共资源,这里就要用到一个接口:
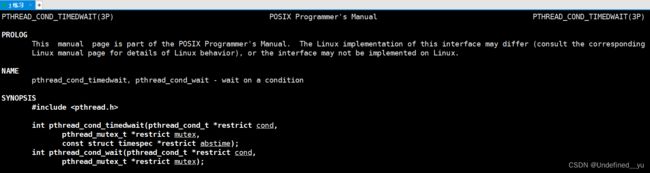
这个接口的作用是,在不满足条件时,将某一线程挂起。
既然有挂起,当然需要另一个接口在线程满足条件时,将其唤醒:
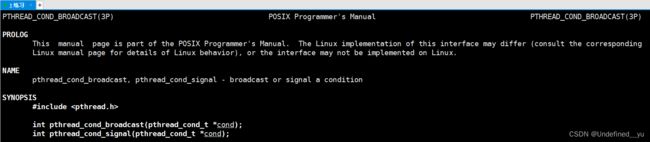
2.2理解条件变量
还是使用上文中的例子,多个线程访问资源时,可能会出现一个线程频繁访问,而其他线程从未得到过访问机会的情况。
为了解决这个问题,需要设置一个条件变量,对访问资源的线程要做出限制,只有满足条件的线程才能访问资源。
也就是说,当条件不满足时,线程必须去某些定义好的条件变量上进行等待。
其中,当线程不满足条件时,会调用==pthread_cond_wait()这个接口,将自己放在该条件变量的等待队列中排队;当满足条件时,会调用pthread_cond_signal()==这个接口,将自己唤醒去访问资源。
2.3条件变量的使用
先来模拟一个场景:
两个线程进行抢票(不包含主线程),抢票过程暂时忽略,主线程每隔两秒唤醒一个条件变量下等待的线程。使用到的锁和条件变量直接使用默认初始值,并将其定义为全局变量。
那么,当程序运行起来时,一定会看到两个线程在抢票,并且一定会有先后顺序(虽然我们现在并不清楚谁先谁后),模拟代码如下:
#include Makefile内容如下:
Cond:Cond.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f Cond
运行结果如下:
[sny@VM-8-12-centos threadcon]$ ./Cond
main thread weakup one thread...thread 2->
1000
main thread weakup one thread...
thread 1->999
main thread weakup one thread...
thread 2->998
main thread weakup one thread...
thread 1->997
main thread weakup one thread...
thread 2->996
^C
可以看到,两个线程抢票时,是由明显的先后顺序的,因为两个线程在条件变量下是时刻在排队的。各位读者也可以复制粘贴代码自己运行一下试试。
上述唤醒线程是一个线程,当然上图中还有可以唤醒某一条件变量下的所有线程的接口,读者们可以自己试试。
三、基于BlockingQueue的生产者消费者模型
3.1BlockingQueue的介绍
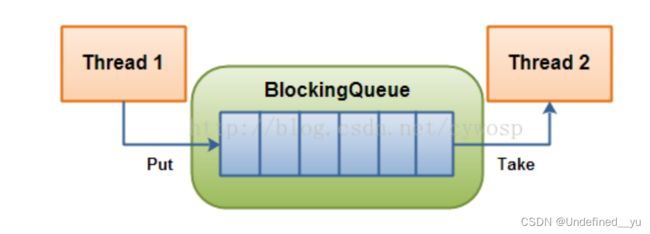
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)
3.2C++ queue模拟阻塞队列的生产消费模型
阻塞队列封装之后的代码如下:
#pragma once
#include 模拟生产消费场景额代码如下:
#include "BlockQueue.hpp"
#include Makefile内容如下:
MainCp:MainCp.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f MainCp
需要注意,在代码中,我们设置生产者每生产一个数据就休眠一秒,而对消费者不做限制。所以,如果最后的执行结果是“消费者每一次消费的数据都是生产者最后一次生产的数据”的话,就证明了二者的共享资源是一个阻塞队列!
运行结果如下:
[sny@VM-8-12-centos blockqueue]$ ./MainCp
生产数据: 10
消费数据: 10
生产数据: 6
消费数据: 6
生产数据: 1
消费数据: 1
^C
可见,结果和预测相同!
下面对代码中的几个细节做出解释:
①调用pthread_cond_wait()接口时,第二个参数一定是正在使用的互斥锁
这是因为,某一个线程因为不满足条件时,要将自己挂起等待。但是不能影响其他线程申请锁,所以,这个接口会以原子性的方式将锁释放,并将该线程挂起。
②pthread_cond_wait()这个函数在被唤醒返回的时候,会自动重新获取线程所传入的锁,以便可以继续向下执行。
③判断是否满足条件时,不应该用if,而应该用while。
因为当多个线程同时被唤醒,但最终只有一个线程可以访问资源时,就会存在异常或伪唤醒的情况,所以先后才能醒来之后,必须再判断一次是否满足条件。
所以,要对上面的代码稍作改动:
void push(const T& in)
{
pthread_mutex_lock(&_mutex);
//1.判断
while(is_full())
{//生产条件不满足,无法生产,生产者进行等待
pthread_cond_wait(&_pcond,&_mutex);
}
//2.这里一定没有满
_q.push(in);
//3.走到这里,阻塞队列里一定有数据了
pthread_cond_signal(&_ccond);//唤醒消费者
pthread_mutex_unlock(&_mutex);
}
判空的时候亦是如此!
④pthread_cond_signal()可以放在临界资源内部,也可以放在外部,只要能线程被唤醒即可。
3.3对生产消费任务的模拟封装
生产者和消费者的任务是不确定的,可能是各种各样的“业务”,所以,两者的任务应该是各种类型的。
接下来,就模拟一个小小的任务(包括加减乘除取模四种运算),新增一个Task.hpp文件,内容如下:
#pragma once
#include 将MainCp中代码稍作修改,如下:
#include "BlockQueue.hpp"
#include "Task.hpp"
#include 最终执行结果如下:
[sny@VM-8-12-centos blockqueue]$ ./MainCp
生产任务: 6 + 1 = ?
消费任务: 6 + 1 = 7
生产任务: 9 % 0 = ?
mod zero error!
消费任务: 9 % 0 = -1
生产任务: 1 % 1 = ?
消费任务: 1 % 1 = 0
^C
四、遗留问题
下面来回答一下上文中没有回答的问题
创建多个生产者和消费者的意义是什么?生产消费模型的高效体现在哪里?
首先,我们需要知道,对于生产者而言,它的任务可能来自于各个地方,包括数据库、网络等等,它获取任务和构建任务都是需要花费时间的。
其次,对于消费者而言,它从任务队列中取出任务,后续还要执行任务,也是需要花费时间的。
而生产消费模型可以让消费者在执行任务的时候,生产者也在生产任务。也可以保证一个消费者或生产者在执行或生成任务时,其他的生产者或消费者也可以进行同样的操作。可以实现在生产之前,消费之后,让线程并发执行。
以上就是生产消费模型的左右内容!
本篇完,青山不改,绿水长流!