关于主从复制的超详细解析(全)
目录
- 前言
- 1. 主从复制
-
- 1.1 方式
- 2. Mysql的主从复制
-
- 2.1 一主一从
-
- 2.1.1 window和linux通讯
- 2.1.2 linux和linux的通讯
- 2.2 双主双从
- 3. Redis的主从复制
-
- 3.1 哨兵模式
- 3.2 java代码结合
前言
主要介绍mysql的主从复制以及redis的主从复制
能由浅入深的明白原理以及如何操作
再者,在面试中能道道如来
主要参考了一些书籍,以及自我的理解
还有众多博客的学习链接等
关于mysql以及redis的一些知识点可看我之前的文章进行查询
java框架零基础从入门到精通的学习路线(超全)
redis在开头上主从复制,而mycat在接入点上主从复制,所以缺点是会导致延时性问题
1. 主从复制
指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点
关于主从复制的原理对应什么框架,在正文中有提及,此处就不提及
对于主从复制的优缺点如下:
优点:
做数据的热备。(主数据库宕机,从数据库可继续工作,避免数据的丢失),更好的实现了负载均衡。降低磁盘I/O访问的频率,提高单个机器的I/O性能读写分离,使数据库能支持更大的并发。
(补充一下数据库的报表定义,来源于百度:“数据库报表就是通过对原始数据的分析整合,将结果(表现表式为文字\表格\图形等)反馈给企业客户的一种形式。 这种报表因为能够实时读取数据库,所以每次运行看到的都是最新的统计报表。”)
确保数据的安全(主从复制),提高了性能(主机宕机之后,从机也可以继续工作)
1.1 方式
同步复制
master的变化,必须等待slave-1,slave-2,…,slave-n完成后才能返回(比如在WEB前端页面上,用户增加了条记录,需要等待很长时间)
异步复制
如同AJAX请求一样。master只需要完成自己的数据库操作即可。不用理slaves是否收到二进制日志以及完成操作。(MYSQL的默认设置)。这种类似网络传输的udp
半同步复制
master只保证slaves中的一个操作成功,就返回,其他slave不管(由google为MYSQL引入)
关于增量复制和全量复制主要涉及到redis的框架:
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。(刚开始从机连接主机,主机一次给)
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步 (主机修改了数据会给予从机修改的数据同步,叫做增量复制)
2. Mysql的主从复制
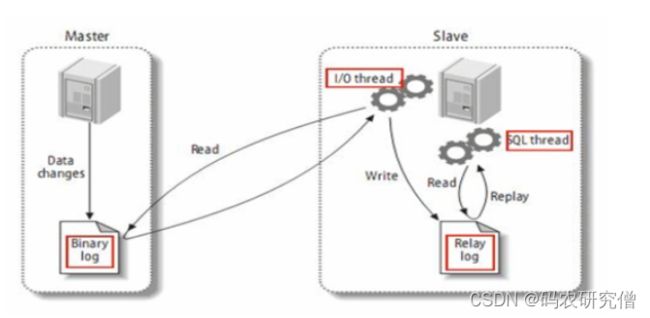
- master将改变记录到
二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events; - slave将master的binary log events拷贝到它的
中继日志(relay log) ; - slave重做中继日志中的事件,将改变应用到自己的数据库中
。MySQL复制是异步的且串行化的,这样从节点不用一直访问主服务器来更新自己的数据
关于主从复制的详细原理如下:
-
master将
数据的改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events;当数据发生改变时,则将其改变写入二进制日志中; -
slave会在一定时间间隔内对master二进制日志进行
探测其是否发生改变,如果发生改变,则开始一个I/OThread请求master二进制事件 -
同时
主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒。
总的来说:
- 从库会生成两个线程,
一个I/O线程,一个SQL线程; - I/O线程会去
请求主库的binlog。主库会生成一个log dump线程,用来给从库I/O线程传binlog。并将得到的binlog写到本地的relay-log(中继日志)文件中; - SQL线程,会读取
relay log文件中的日志,并解析成sql语句逐一执行;
复制的原则主要有:
- 每个slave只有一个master
- 每个slave只能有一个唯一的服务器ID
- 每个master可以有多个salve
关于mysql的主从复制的缺点
主要是延时
通过上面的机制,可以保证主从数据库数据一致,但是时间上肯定有延迟,即从机数据是滞后的。
由于sql thread也是单线程的,当主库的并发较高时,产生的DML数量超过slave的SQL thread所能处理的速度等的延时
解决方案如下:
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力
2.单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库
3.服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力
2.1 一主一从
2.1.1 window和linux通讯
主从都配置在[mysqld]结点下,都是小写
具体的配置文件在window上是这么修改,主机修改my.ini
-
server-id=1[必须]主服务器唯一ID -
log-bin=自己本地的路径/mysqlbin[必须]启用二进制日志 -
log-err=自己本地的路径/mysqlerr[可选]启用错误日志 -
basedir=“自己本地路径”[可选]根目录 -
tmpdir=“自己本地路径”[可选]临时目录 -
datadir=“自己本地路径/Data/”[可选]数据目录 -
binlog-ignore-db=mysql[可选]设置不要复制的数据库 -
binlog-do-db=需要复制的主数据库名字[可选]设置需要复制的数据库
linux上作为从机,从机修改my.cnf配置文件
- [必须]从服务器唯一ID
- [可选]启用二进制日志
在windows上授权 linux,只需要给予服务器ip等
GRANT REPLICATION SLAVE ON *.* TO ‘zhangsan’@‘从机器数据库IP’ IDENTIFIED BY ‘123456’;
show master status;- 记录下File和Position的值
在linux中授权window的IP地址
CHANGE MASTER TO MASTER_HOST=’主机
IP’, MASTER_USER=‘zhangsan’, MASTER_PASSWORD=’123456’, MASTER_LOG_FILE='File名字’, MASTER_LOG_POS=Position数字;
start slave;启动服务器的slaveshow slave status\Gstop slave;停止
2.1.2 linux和linux的通讯
如果主从都在linux上,具体详细配置如下:
- 主机配置
- 主机的设置
修改配置文件:gedit或者vim /etc/my.cnf
在后面添加如下
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
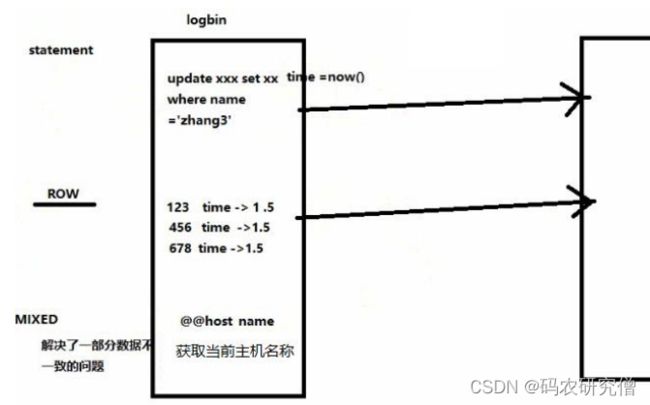
关于下面设置日志的格式
具体主要有三种
binlog_format=statement,master写入执行的SQL语句到binlog中,从库读取这些SQL语句并执行,主机和从机的时间不一样,导致执行某些函数时可能造成主从不一致的情况binlog_format=row,一行一句的复制,缺点执行 100 万次更新,会记录一百万次,效率更低binlog_format=mixed, 它记录日志取决于修改的类型,选择合适的格式来记录该修改,缺点识别不了特定的名称[系统变量] 如@@host name
从机的配置如下
# 从机服务器唯一 ID
server-id=2
# 启用中继日志
relay-log=mysql-relay
修改配置文件之后是要重启才可以使用
通过命令 service mysqld start或者systemctl等命令,以及关闭防火墙
查看其防火墙的状态 systemctl status firewalld
具体可看我防火墙这篇文章
- ubuntu:防火墙配置详细讲解(全)
- linux之防火墙命令firewall、iptable以及端口号等详解诠释(全)
主机的设置
主机上面创建一个用户,给从机,专门让从机来负责主从复制的权限
创建一个主从复制的权限 给slave用户,并且指定密码
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123';
查询master的状态,show master status;
显示日日志名称,接入点的位置开始复制,需要复制的数据库,以及不需要复制的数据库

从机配置
再从机输入的时候
如果之前有主从的一些,可以通过重新配置主从stop slave;进行关闭服务器的复制,以及reset master;重置主机
通过主机的配置,再从机中输入
主要是配置日志名称以及它的接入点位置等
CHANGE MASTER TO MASTER_HOST='主机的IP地址',
MASTER_USER='slave',
MASTER_PASSWORD='123123',
MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;
启动从服务器复制功能 start slave;
查看从服务器状态 show slave status\G;,字段太多,可以通过列管理\G的参数
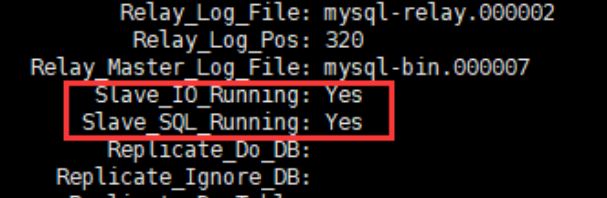
有这两个参数代表成功了
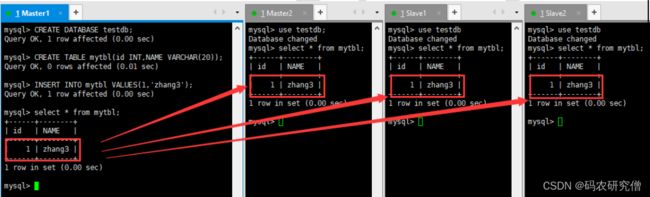
主机增删改表格,从机可以查询到表格等信息
停止从服务复制功能 stop slave;
2.2 双主双从
一个主机 m1 用于处理所有写请求,它的从机 s1 和另一台主机 m2 还有它的从机 s2 负责所有读请
求。当 m1 主机宕机后,m2 主机负责写请求,m1、m2 互为备机
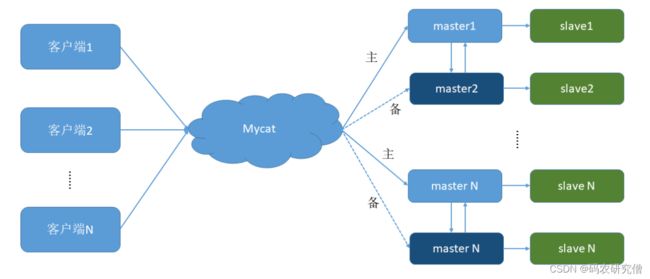
双主机的一个配置
- log-slave-updates 配置这个主要是因为主机可能成为从机,所以要配置
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=1
第二个备份主机
#主服务器唯一ID
server-id=3 #启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=2
从机的配置
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
第二个从机的配置
#从服务器唯一ID
server-id=4 #启用中继日志
relay-log=mysql-relay
之后重启mysql的服务以及关闭防火墙的基本操作
在两台主机上建立帐户并授权 slave
执行sql的命令GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123';
展示其状态,主要给从机使用以及备份的主机使用show master status;
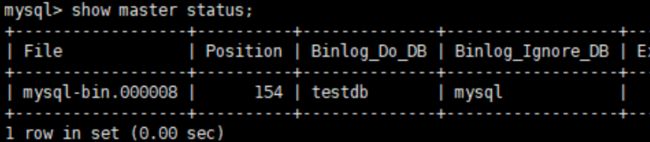
第二个主机的查询状态同理
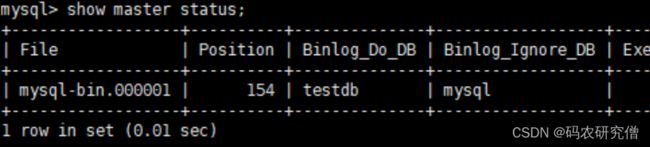
从机复制第一个主机的信息,第二个从机复制第二个主机的信息
CHANGE MASTER TO MASTER_HOST='主机的IP地址',
MASTER_USER='slave',
MASTER_PASSWORD='123123',
MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;
之后分别启动两个主机的复制功能start slave;
查看服务器的状态show slave status\G;,出现俩个yes的状态代表已经可以实现
两个主机如何备份,和上面一样,主机复制备份主机的信息,备份主机输入主机的信息
start slave;以及查看从服务器状态show slave status\G;
本身是testdb的数据库
所以建立这个数据库
3. Redis的主从复制
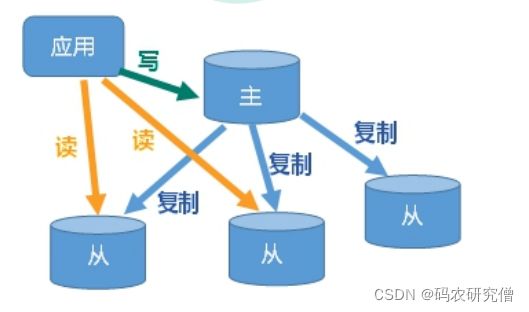
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
主要的功能有:
- 读写分离,性能扩展
- 容灾快速恢复
具体主从的复制原理:
从机主动发送
- Slave启动成功连接到master后,从机slave会发送一个sync命令
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。(刚开始从机连接主机,主机一次给)
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步 (主机修改了数据会给予从机修改的数据同步,叫做增量复制)
断开之后重新连接,只要是重新连接master,一次完全同步(全量复制)将被自动执行,rdb的数据就会给从机。
主机负责写,从机负责读
具体如何搭建
redis.conf文件
本身redis.conf文件中就有include的代码模块
所以在命令行中直接输入include 绝对路径,就可引入
具体文件的内容修改如下
开启daemonize yes 后台启动
Appendonly 关掉或者换名字,也就是不要AOF的追加,只要RDB持久化
实现一主两从
步骤如下:
也就是3个配置文件
- 新建一个
redis6379.conf文件
代码格式如下
include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
其他两个文件同理,只需要修改其pid进程号以及端口号,生成的rdb文件名
-
启动三台服务器
分别是redis-server 配置文件
以及登录进入redis-cli -p 端口号 -
登录进入之后,查看其主机运行的情况:
info replication
其都是主机,而没有从机 -
为了显示一主两从
再登录进入的从机上输入:slaveof
在6380和6381上执行:slaveof 127.0.0.1 6379
情况1:一主两仆
主机挂掉,执行shutdown
从机info replication还是显示其主机是挂掉的哪个
如果从机挂掉,执行shutdown
主机开始写数据,从机在开启的时候,恢复数据的时候是从主机从头开始追加的
情况2:薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他 slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
从机的大哥是另一台从机的意思
用 slaveof ,中途变更转向:会清除之前的数据,重新建立拷贝最新的
风险是一旦某个slave宕机,后面的slave都没法备份
主机挂了,从机还是从机,无法写数据了
情况3:反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改
可以使用命令:slaveof no one 将从机变为主机
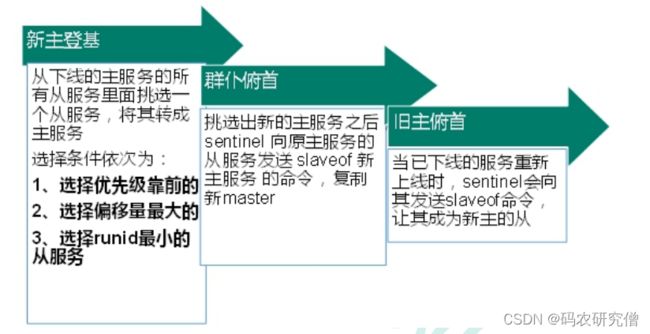
3.1 哨兵模式
主要是为了监控主机宕机之后,从机可以立马变为主机,就和上面的反客为主一样,不用手动设置
能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库

再目录中新建一个文件sentinel.conf,文件格式不能出错
文件内容为
sentinel monitor mymaster 127.0.0.1 6379 1
代码的含义为 sentinel哨兵,监控,一个id(别名),ip加端口号
其中mymaster为监控对象起的服务器名称, 1 为至少有多少个哨兵同意迁移的数量。
启动哨兵模式通过redis的bin目录下
命令如下:redis-sentinel /sentinel.conf
具体哪个从机会变成主机
其判定规则主要为
(顺序依次往下,优先级》偏移量》runid)
- 优先级在redis.conf中默认:slave-priority 100,值越小优先级越高
- 偏移量是指获得原主机数据最全的,也就是数据越多,变主机的机会越大
- 每个redis实例启动后都会随机生成一个40位的runid
在这里也有个缺点就是复制会有延时
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
3.2 java代码结合
主要是ip端口号的连接
以及主机名称new JedisSentinelPool("mymaster",sentinelSet,jedisPoolConfig);
private static JedisSentinelPool jedisSentinelPool=null;
public static Jedis getJedisFromSentinel(){
if(jedisSentinelPool==null){
Set<String> sentinelSet=new HashSet<>();
sentinelSet.add("192.168.11.103:26379");
JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10); //最大可用连接数
jedisPoolConfig.setMaxIdle(5); //最大闲置连接数
jedisPoolConfig.setMinIdle(5); //最小闲置连接数
jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待
jedisPoolConfig.setMaxWaitMillis(2000); //等待时间
jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong
jedisSentinelPool=new JedisSentinelPool("mymaster",sentinelSet,jedisPoolConfig);
return jedisSentinelPool.getResource();
}else{
return jedisSentinelPool.getResource();
}
}