python pandas写入数据后保存,python pandas写入和读取数据的基本操作
今天呢开始学习pandas模块啦
一、序
① 基本操作
先简单说说pandas操作excel文件、csv、txt用的都是啥方法
操作excel : pandas里面带有excel的方法一般都是操作excel文件
操作csv和txt:带有csv字样的方法可以操作csv和txt文件
先来新建个excel文件试试(to_excel方法):
import pandas as pd
res = 'E:/python测试数据/demo.xlsx'
mydata = pd.DataFrame()
mydata.to_excel(res)
print('文件创建成功!')
按理说导入了pandas模块,这个时候就新建了一个demo.xlsx文件,但是呢报了以下这个错误:
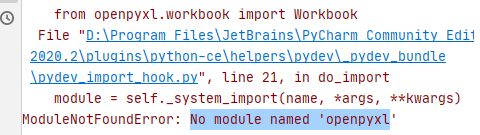
② 导入相应模块
错误提示缺少openpyxl模块,所以咱们照着之前的办法,在pycharm中安装一下:点击pycharm左上角File——Settings——Project:XXX——Python Interpreter——点击最右侧的+号——搜索openpyxl——点击左下角的Install Package。等待几秒就完成啦

安装完后再运行就不会报错了,E盘下面新建好了demo.xlsx文件。
一、pandas写入数据操作
① 写入的数据类型
先看看要写入excel数据,是用什么类型的形式写入:
{'序号':[1,2,3,4,5],'姓名':['张三','李四','王五','赵六','雪清']}
看了一下,操作的EXCEL里面每列数据都是字典的元素。字典的键是EXCEL每列的标题,字典的值以列表格式保存。
import pandas as pd
res = 'E:/python测试数据/demo.xlsx'
mydata = pd.DataFrame({'序号':[1,2,3,4,5],'姓名':['张三','李四','王五','赵六','雪清']})
mydata.to_excel(res)
print('文件创建成功!')
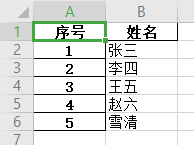
运行完后创建了demo.xlsx,内容如下:

② 去掉默认索引列
我们会发现创建的EXCEL文件中A列多了索引值~如果不需要A列索引的话,加上这么一句就可以:
mydata = pd.DataFrame({'序号':[1,2,3,4,5],'姓名':['张三','李四','王五','赵六','雪清']})
mydata = mydata.set_index('序号')
mydata.to_excel(res)
csv文件和txt文件操作一样这里就不多说啦
二、读取文件相关操作
① pandas读取文件的方法
一般来说数据量较大的话不用xlsx和txt格式,用csv比较多,所以呢读取这些文件的操作如下:
read_csv 默认使用逗号分隔符
read_table 默认用tab制表符作为分隔符
② read_csv基本用法
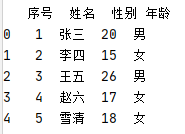
假设新建了个txt文件,里面有这些数据:

读取txt的代码如下:
import pandas as pd
res = 'E:/python测试数据/源数据.txt'
mydata = pd.read_csv(res)
print(mydata)
因为read_csv默认使用逗号分隔,所以数据打印出来后就没有逗号啦
③ read_table基本用法
如果是用read_table进行分隔的话,可以改成下面这句:
mydata = pd.read_table(res,sep=',')
④ read_csv 、read_table 读取部分行数据
当然了,如果数据量太大只需要读取一部分数据的话可以这样,比如读取3行:
import pandas as pd
res = 'E:/python测试数据/源数据.txt'
mydata = pd.read_table(res,sep=',')
print(mydata.head(3))
也可以这样:
import pandas as pd
res = 'E:/python测试数据/源数据.txt'
mydata = pd.read_table(res,sep=',',nrows=3)
print(mydata)
⑤ 输出源数据列
如果需要知道数据有多少列,输出的时候可以这样:
print(mydata.columns)
结果如下:
Index(['序号', '姓名', '性别', '年龄'], dtype='object')
⑥ 输出源数据每列的数据类型
print(mydata.dtypes)
结果如下:
序号 int64
姓名 object
性别 int64
年龄 object
dtype: object
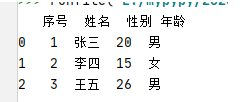
⑦ 读取没表头的数据
假设现在把第一行的数据去掉

要读取的时候可以这样
import pandas as pd
res = 'E:/python测试数据/源数据.txt'
mydata = pd.read_table(res,sep=',',header=None,names=['序号','姓名','性别','年龄'])
print(mydata)
header=None:意思是这个表没有表头
names=['序号','姓名','性别','年龄'] :意思是这个表没有表头咱们设置个啥名字上去(如果不设置的话自动分配01234…)
所以一般header和names一起使用。
输出结果:

⑧ 设置索引列
刚才读取数据的例子上,输出结果前面都有一列 0 1 2…怎么处理呢?
mydata = pd.read_table(res,sep=',',index_col='序号')
⑨ 跳过部分行数
如果需要选择性输出,可以这样:
mydata = pd.read_table(res,sep=',',skiprows=[1,3,5])
三、txt转csv文件
两句搞定,超级简单
import pandas as pd
mydata = pd.read_table('E:/python测试数据/源数据.txt')
mydata.to_csv('E:/python测试数据/源数据.csv')
原文链接:https://blog.csdn.net/Di77HaoWenMing/article/details/108504212