反反爬策略(一) Scrapy添加User-Agent池
鉴于爬虫的高效率以及无差别性,在获取一些网站的内容时,会对服务器造成巨大的压力,以至于网站管理者为了保持服务器的平衡,会做一些反爬虫的措施,阻止爬虫的前进。
道高一尺魔高一丈。为了应对这些反爬措施,虫子们也有自己的方法。对此,希望能分享一点经验,最主要的是能够做好学习笔记,方便日后的查看。
NO.1 添加User-Agent池
User-Agent是headers中的一个属性,表示当前访问服务器的身份信息。简单来说,就是告诉服务器,谁在浏览信息。也是反反爬策略中最简单的一项。
同一个身份过于频繁的访问服务器,会被识别为机器身份,遭到反爬的打击。所以需要频繁的更改User-Agent信息。
经过大量的验证以及实验之后,终于成功的实现了每次请求都是不同的身份。话不多说,燥起来吧,上代码。
第一步
Scrapy 发送请求获取响应的流程是,request对象从调度器中提取出来,交给下载器进行请求。过程中必须经过下载器中间件downloadmiddleware,下载器中间件中的主要方法process_request()是在request对象进入下载器之前进行处理,需要添加的user-agent就在这个方法中实现;process_response()是在下载器将请求到的响应返回给引擎时,对响应resoonse进行处理。这里主要介绍process_request().
添加User-Agent池
在scrapy中的middlewares.py中间件管理文件中添加一个useragent的类。
from fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
"""设置一个随机更换的userAgent池"""
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
# 若settings中没有设置RANDOM_UA_TYPE的值默认值为random,
# 从settings中获取RANDOM_UA_TYPE变量,值可以是 random ie chrome firefox safari opera msie
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', 'random')
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
print("********Current UserAgent:%s************" % self.ua.random)
def get_ua():
'''根据settings的RANDOM_UA_TYPE变量设置每次请求的User-Agent'''
return getattr(self.ua, self.ua_type)
ua = get_ua()
request.headers.setdefault('User-Agent', get_ua())
2019.6.6 新增修改:
设置随机ua池,还有更加简单的方法。
完整代码如下:
class RandomUAMiddleware():
def __init__(self):
self.ua = UserAgent()
def process_request(self, request, spider):
print("更换ua和cookie")
print(self.ua.random)
# request.headers.setdefault('User-Agent', self.ua.random)
request.headers['User-Agent'] = self.ua.random
return None
今天测试时,发现setdefault方法失效了,无法修改user-agent的值。所以还是用回最简单的赋值方式。
request.headers[‘User-Agent’] = self.ua.random
其中fake_useragent是python的第三方库,用于随机生成一个user-agent。
pip install fake_useragent
ua = UserAgent() 生成的是一个FakeUserAgent对象。
ua.浏览器名就可以生成一个对应浏览器的useragent,每次都不一样。


例如ua.chrome生成的都是谷歌浏览器useragent,ua.ie,ua.firefox,
ua.random可以生成一个随机浏览器的useragent。
代码中get_ua()方法
暂时无法理解,不过加上这个方法,爬虫的效率会提高3秒左右。
settings.py
在scrapy中的配置文件settings中打开下载器中间件。
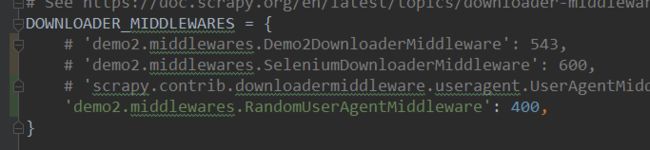
这里有一个坑,看了某些帖子后尝试着修改settings中的配置,结果只能发送一次请求。
苦思冥想后发现是给headers设置了默认值。
所以后面的童鞋检查是否开启了settings配置中的headers,如果开启就请关闭后再尝试吧。
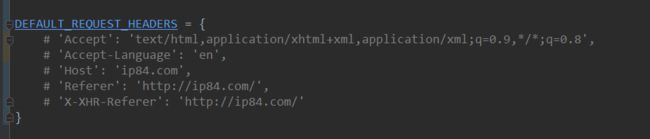
好了,到这里,useragent池子已经能顺利的跑通了。
又是元气满满的一天