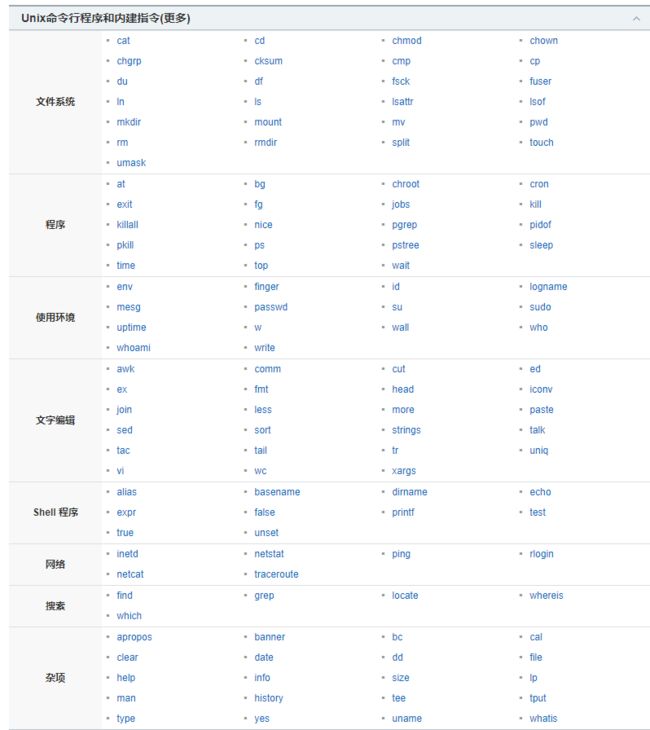
Linux 常用命令与教程
http://c.biancheng.net/view/705.html C语言编程网的教程很好
还有菜鸟教程的
还有这个 https://mp.weixin.qq.com/s/7bSwKiPmtJbs7FtRWZZqpA 讲的也不错
https://baike.baidu.com/item/PS/8850709 百度百科 搜索一个linux命令 会出来这个
〇、序言:命令基本格式
Linux中命令格式为:command [options] [arguments]
中括号代表是可选的,即有些命令不需要选项也不需要参数
登录系统后,第一眼看到的内容是:
[root@localhost ~]#
这就是 Linux 系统的命令提示符。那么,这个提示符的含义是什么呢?
[]:这是提示符的分隔符号,没有特殊含义。
root:显示的是当前的登录用户,笔者现在使用的是 root 用户登录。
@:分隔符号,没有特殊含义。
localhost:当前系统的简写主机名(完整主机名是 localhost.localdomain)。
~:代表用户当前所在的目录,此例中用户当前所在的目录是家目录。
\#:命令提示符,Linux 用这个符号标识登录的用户权限等级。如果是超级用户,提示符就是 #;如果是普通用户,提示符就是 $。
家目录(又称主目录)是什么? Linux 系统是纯字符界面,用户登录后,要有一个初始登录的位置,这个初始登录位置就称为用户的家:
选项:options
选项分为长选项和短选项。
短选项
比如-h,-l,-s等。(- 后面接单个字母)
-
短选项都是使用
-引导,当有多个短选项时,各选项之间使用空格隔开。 -
有些命令的短选项可以组合,比如
-l–h可以组合为–lh -
有些命令的短选项可以不带
-,这通常叫作BSD风格的选项,比如ps aux -
有些短选项需要带选项本身的参数,比如
-L 512M
长选项
比如--help,--list等。(-- 后面接单词)
-
长选面都是完整的单词
-
长选项通常不能组合
-
如果需要参数,长选项的参数通常需要
=,比如--size=1G
参数arguments:
参数是指命令的作用对象。
如ls命令,不加参数的时候显示是当前目录,也可以加参数,如ls /dev, 则输出结果是/dev目录。
参数是传递到脚本中的真实的参数
以上简要说明了选项及参数的区别,但具体Linux中哪条命令有哪些选项及参数,需要我们靠经验积累或者查看Linux的帮助了。
命令尾部描述符的作用
大部分来自 https://huaweicloud.csdn.net/638db1cddacf622b8df8c6fb.html
;
注意:用;号隔开每个命令, 每个命令按照从左到右的顺序执行, 但是彼此之间不关心是否失败, 所有命令都会执行。
()
把多个命令,当做一个整体执行,同时增强了可读性。
单竖线 |
竖线|,在linux中是作为管道符的,将|前面命令的输出作为|后面的输入。举个例子
ps -ef | grep java #使用正则grep命令寻找java进程
实际上似乎可以理解成 grep java (ps -ef)
而且 管道符可以多次使用,如 ps -aux|grep xxxx|grep -v grep可以过滤掉查找进程的自身这条命令;
# 有两条命令
[root@ev003v ~]$ ps -aux|grep python
root 329 0.0 0.0 112828 984 pts/11 S+ 16:06 0:00 grep --color=auto python
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
#只剩下一条了
[root@ev003v ~]$ ps -aux|grep python|grep -v grep
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
双竖线 ||
双竖线||,用双竖线||分割的多条命令,执行的时候遵循如下规则,如果前一条命令为真,则后面的命令不会执行,如果前一条命令为假,则继续执行后面的命令。
[[ 1 -lt 2 ]]||echo b
判断文件是否存在 不存在则创建
[[ -f 1.txt ]] || touch 1.txt
& 和 && 与nohub
&
- 如果放到语句最后 那么代表把命令放到后台去执行
- 同时执行多条命令,不管命令是否执行成功 (实际上是上面那条??)
- 有时代表引用 看下面的 0 1 2 & >那
&&
- 可同时执行多条命令,当碰到执行错误的命令时,将不再执行后面的命令。如果一直没有错误的,则执行完毕。
&和nohub的区别和常见使用场景
nohub的意义
全称 no hangup 即不挂起,即使关掉shell,依然会继续执行。
&代表后台执行,免疫SIGINT信号(Ctrl+C),但是不免疫SIGHUP信号(关闭shell);nohub相反,关闭shell仍会执行,但是Ctrl+C可以中断执行。因此可以将这两个联合使用,让进程既不受Ctrl+C影响,也不受shell关闭影响,类似守护进程。
输入输出重定向 >和>>与<
输出重定向
>把正常信息(剔除错误信息)重定向到另一个文件内
>和>>其实都属于输出重定向,都可以输出内容到指定文件。
那具体的区别是什么呢?
>会覆盖目标的原有内容,当文件存在时,会先删除原文件,再重新创建文件,然后把内容写入该文件,否则直接创建文件。
>>会在目标原有内容后追加内容,当文件存在时直接在文件末尾进行内容追加,不会删除原文件,否则直接创建文件。
# 示例:
# 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里:
cat -n textfile1 > textfile2
| 命令符号格式 | 作用 |
|---|---|
| 命令 > 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,会清空原有数据,再写入新数据。 |
| 命令 2> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,会清空原有数据,再写入新数据。 |
| 命令 >> 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,新数据将写入到原有内容的后面。 |
| 命令 2>> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,新数据将写入到原有内容的后面。 |
| 命令 >> 文件 2>&1 或者 命令 &>> 文件 | 将标准输出或者错误输出写入到指定文件,如果该文件中已包含数据,新数据将写入到原有内容的后面。注意,第一种格式中,最后的 2>&1 是一体的,可以认为是固定写法。 |
后面讲cat命令会更多示例
输入重定向
| 命令符号格式 | 作用 |
|---|---|
| 命令 < 文件 | 将指定文件作为命令的输入设备 |
| 命令 << 分界符 | 表示从标准输入设备(键盘)中读入,直到遇到分界符才停止(读入的数据不包括分界符),这里的分界符其实就是自定义的字符串 |
| 命令 < 文件 1 > 文件 2 | 将文件 1 作为命令的输入设备,该命令的执行结果输出到文件 2 中。 |
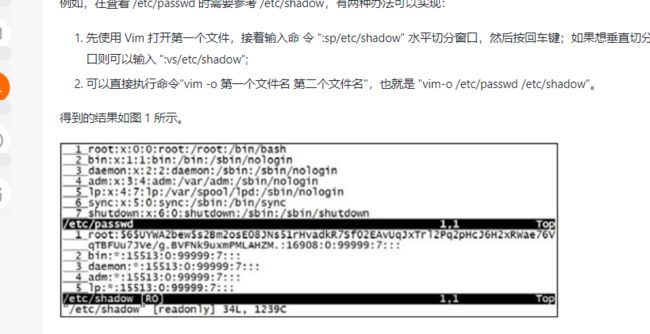
[root@localhost ~]# cat /etc/passwd
#这里省略输出信息,读者可自行查看
[root@localhost ~]# cat < /etc/passwd
#输出结果同上面命令相同
注意,虽然执行结果相同,但第一行代表是以键盘作为输入设备,而第二行代码是以 /etc/passwd 文件作为输入设备。
【例 2】
[root@localhost ~]# cat << 0
\>linuxyz.cn
\>Linux
\>0
linuxyz.cn
Linux
可以看到,当指定了 0 作为分界符之后,只要不输入 0,就可以一直输入数据。
【例 3】
首先,新建文本文件 a.tx,然后执行如下命令:
[root@localhost ~]# cat a.txt
[root@localhost ~]# cat < /etc/passwd > a.txt
[root@localhost ~]# cat a.txt
\#输出了和 /etc/passwd 文件内容相同的数据
可以看到,通过重定向 /etc/passwd 作为输入设备,并输出重定向到 a.txt,最终实现了将 /etc/passwd 文件中内容复制到 a.txt 中。
-
减号- 代表标准输入还是标准输出,视具体命令而定
如果命令是往外输出的,则减号- 代表标准输出stdout
如果命令是等待输入的,则减号- 代表标准输入stdin
以下面复制文件的列子进行讲解
# "-" 代替标准输入stdin 或标准输出stdout,视具体命令而定
# 在输出内容添加一行
cat - file.txt <<< "line num 1"
## <<< 是heredoc,这里"-"接收<<< 的输入,以匿名文件的形式供cat 读取
## cat 将"-"代表的匿名文件和file.txt 的内容连接在一起,执行结果为
### line num 1
### file.txt 第一行内容
### file.txt 第二行内容
### ......
# 只取文件的一列并与另一文件做diff
awk '{ print $1 }' a | diff - b
## 管道"|"左边的输出就是右边的输入,这里管道左边是awk 的输出,管道右边用"-"接收
## "-"再以匿名文件的形式供diff 读取,所以,这里的"-"既有输入也有输出
0 1 2 与& >
nohup python3 /home/main.py 2>&1 &
1 和 2 在 shell 命令中代表什么?

0 是标准输入stdin,一般是从键盘获得输入
1 是标准输出stdout,一般是输出到屏幕了
2 是标准错误输出stderr,一般是输出到屏幕,重定向到文件中后,屏幕就看不到它了
dev 是device
我们平时使用的
echo "hello"> t.log
其实也可以写成
echo "hello”1> t.log
符号的意义
语法: file_descriptor > file_name
所以2>&1代表将标准错误输出重定向到标准输出中,为什么不能用2>1?
答:这代表将错误日志输出到1这个文件中。&可以理解为C语言的指针,加了&1,代表这是一个引用(引用的标准输出)
& 的意义
放在命令最后,代表这条命令放到后台去执行,此时可以执行新的命令了。
2>&1为什么要放最后
分别分析这两行命令的逻辑:
nohup java -jar app.jar >log 2>&1 &
nohup java -jar app.jar 2>&1 >log &
第一条命令的逻辑是:
本来1----->屏幕 (1指向屏幕)
执行>log后, 1----->log (1指向log)
执行2>&1后, 2----->1 (2指向1,而1指向log,因此2也指向了log)
第二条命令的逻辑是
本来1----->屏幕 (1指向屏幕)
执行2>&1后, 2----->1 (2指向1,而1指向屏幕,因此2也指向了屏幕)
执行>log后, 1----->log (1指向log,2还是指向屏幕)
“&>”、“>” 作用和区别
或1> 作用: 仅将正常信息(非异常信息,非报错信息),重定向输出到指定文件;
2>作用:仅将错误信息重定向输出到指定文件中;
&>或2>&1作用:同时将错误信息、普通信息一并重定向输出到指定文件。
[root@CentOs7]# lll
-bash: lll: command not found //由于Linux没有lll这个命令所以会显示错误信息,这个就是stderr输出的错误信息
[root@CentOs7]# lll >test.txt
-bash: lll: command not found //由于这个是错误信息 所以不能使用标准输出>将信息重定向到test.txt文件中
[root@CentOs7]# lll&>test.txt //使用&>重定向 ,会一并把错误信息、正确信息,一并重定向到了test.txt文件
[root@CentOs7]# cat test.txt
-bash: lll: command not found //通过cat命令确实看到了 保存的错误信息
注意:如果每次都是重定向到同一个文件,以上两个命令的效果都是覆盖原文件信息,不是内容追加!
说明:可把错误、异常信息同时输出到两个不同的文件。
make xxx 1> normal.txt 2> error.txt
简而言之,&>和>&的作用相同,都是把标准信息+错误信息重定向到指定位置,它们都是2>&1的简写写法。
但是在日常开发、学习过程中,习惯上更偏向于使用&>。
虽然它们的效果相同,然而在使用上,还是略有差异的,强烈建议直接使用&>即可。
9.2、常用的重定向符号
将正常的信息,重定向到某个文件/设备中(会覆盖文件原有信息)
将正常的信息,重定向到某个文件/设备中(不会覆盖文件原有信息,只会追加)
&> 将正常+异常信息,一并重定向到某个文件/设备中(会覆盖文件原有信息)
&>>将正常+异常信息,一并重定向到某个文件/设备中(不会覆盖文件原有信息,只会追加)
2> 只输出错误信息到某个文件/设备中
还有一些较少会用到的,比较烧脑,n<&- 和>&n以及<&-感兴趣,可以单独去了解一下。
记忆小妙招:
看到有两个尖括号的,代表是内容追加,单个尖括号,之前的内容都会被覆盖!!!
9.3、/dev/null 黑洞
/dev/null 是一个特殊的设备文件,这个文件接收到任何数据都会被丢弃,俗称“黑洞”
它非常等价于一个只写文件,所有写入它的内容都会永远丢失,而尝试从它那儿读取内容则什么也读不到,然而,/dev/null对命令行和脚本都非常的有用。
黑洞的使用场景:
如果不想把正确/错误信息,输出到屏幕时,就可以把这部分信息输出到黑洞中。
1> /dev/null 经将正常信息出入到黑洞
echo “httpd server is running” >> /dev/null #如果不希望将信息打印到屏幕,可以输出到黑洞复制
2> /dev/null意思就是把错误输出到“黑洞” ,不会显示在屏幕上。
脚本示例
CI_ENV=testing;/usr/local/bin/php /home/app/system/xxx/application/script/crontab/xxx.php &>> /tmp/xxx.log
php " . BASEPATH . "../application/script/xxxx.php -w " . $args['w'] . " -> /tmp/xxxxx.txt
停止和挂起
停止是ctrl+c 挂起是 ctrl+z
[root@localhost ~]# find / -name demo.jpg <--在根目录下查找 demo.jpg 文件,比较耗时
#此处省略了该命令的部分输出信息
#按“CTRL+Z”组合键,即可将该进程挂起
[root@localhost ~]# ps <--查看正在运行的进程
PID TTY TIME CMD
2573 pts/0 00:00:00 bash
2587 pts/0 00:00:01 find
2588 pts/0 00:00:00 ps
命令执行过程
Linux命令的执行过程是怎样的?(新手必读)
2022-05-07 228举报
简介: 前面讲过,在 Linux 系统中“一切皆文件”,Linux 命令也不例外。那么,当编辑完成 Linux 命令并回车后,系统底层到底发生了什么事情呢?
前面讲过,在 Linux 系统中“一切皆文件”,Linux 命令也不例外。那么,当编辑完成 Linux 命令并回车后,系统底层到底发生了什么事情呢?
简单来说,Linux 命令的执行过程分为如下 4 个步骤。
-
判断路径
判断用户是否以绝对路径或相对路径的方式输入命令(如 /bin/ls),如果是的话直接执行。 -
检查别名
Linux 系统会检查用户输入的命令是否为“别名命令”。要知道,通过 alias 命令是可以给现有命令自定义别名的,即用一个自定义的命令名称来替换原本的命令名称。
例如,我们经常使用的 rm 命令,其实就是 rm -i 这个整体的别名:
[root@localhost ~]# alias rm
alias rm=‘rm -i’
这使得当使用 rm 命令删除指定文件时,Linux 系统会要求我们再次确认是否执行删除操作。例如:
[root@localhost ~]# rm a.txt <-- 假定当前目录中已经存在 a.txt 文件
rm: remove regular file ‘a.txt’? y <-- 手动输入 y,即确定删除
[root@localhost ~]#
这里可以使用 unalias 命令,将 Linux 系统设置的 rm 别名删除掉,执行命令如下:
[root@localhost ~]# alias rm
alias rm=‘rm -i’
[root@localhost ~]# unalias rm
[root@localhost ~]# rm a.txt
[root@localhost ~]# <–直接删除,不再询问
注意,这里仅是为了演示 unalisa 的用法,建议读者删除 rm 别名之后,再手动添加到系统中,执行如下命令即可再次成功添加:
[root@localhost ~]# alias rm=‘rm -i’
3) 判断是内部命令还是外部命令
Linux命令行解释器(又称为 shell)会判断用户输入的命令是内部命令还是外部命令。其中,内部命令指的是解释器内部的命令,会被直接执行;而用户通常输入的命令都是外部命令,这些命令交给步骤四继续处理。
内部命令由 Shell 自带,会随着系统启动,可以直接从内存中读取;而外部命令仅是在系统中有对应的可执行文件,执行时需要读取该文件。
判断一个命令属于内部命令还是外部命令,可以使用 type 命令实现。例如:
[root@localhost ~]# type pwd
pwd is a shell builtin <-- pwd是内部命令
[root@localhost ~]# type top
top is /usr/bin/top <-- top是外部命令
4) 查找外部命令对应的可执行文件
当用户执行的是外部命令时,系统会在指定的多个路径中查找该命令的可执行文件,而定义这些路径的变量,就称为 PATH 环境变量,其作用就是告诉 Shell 待执行命令的可执行文件可能存放的位置,也就是说,Shell 会在 PATH 变量包含的多个路径中逐个查找,直到找到为止(如果找不到,Shell 会提供用户“找不到此命令”)。
PATH 环境变量的改变,会直接影响 Shell 查找 Linux 命令的过程,有关 PATH 环境变量(是什么、如何查看、如何修改等),可阅读《Linux PATH环境变量》一文做详细了解。
环境变量
Linux 系统中环境变量的名称一般都是大写的,这是一种约定俗成的规范。
我们可以使用 env 命令来查看到 Linux 系统中所有的环境变量,执行命令如下:
[root@localhost ~]# env
ORBIT_SOCKETDIR=/tmp/orbit-root
HOSTNAME=livecd.centos
GIO_LAUNCHED_DESKTOP_FILE_PID=2065
TERM=xterm
shell =/bin/bash
…
Linux 系统能够正常运行并且为用户提供服务,需要数百个环境变量来协同工作,但是,我们没有必要逐一学习每个变量,这里给大家列举了 10 个非常重要的环境变量,如表 1 所示。
环境变量名称 作用
HOME 用户的主目录(也称家目录)
SHELL 用户使用的 Shell 解释器名称
PATH 定义命令行解释器搜索用户执行命令的路径
EDITOR 用户默认的文本解释器
RANDOM 生成一个随机数字
LANG 系统语言、语系名称
HISTSIZE 输出的历史命令记录条数
HISTFILESIZE 保存的历史命令记录条数
PS1 Bash解释器的提示符
MAIL 邮件保存路径
Linux 作为一个多用户多任务的操作系统,能够为每个用户提供独立的、合适的工作运行环境,因此,一个相同的环境变量会因为用户身份的不同而具有不同的值。
例如,使用下述命令来查看 HOME 变量在不同用户身份下都有哪些值:
[root@localhost ~]# echo KaTeX parse error: Expected 'EOF', got '#' at position 30: …ot@localhost ~]#̲ su - user1 <--… echo $HOME
/home/user1
这里的 su 命令可以临时切换用户身份,此命令的具体用法会在后续章节做详细介绍。
其实,环境变量是由固定的变量名与用户或系统设置的变量值两部分组成的,我们完全可以自行创建环境变量来满足工作需求。例如,设置一个名称为 WORKDIR 的环境变量,方便用户更轻松地进入一个层次较深的目录,执行命令如下:
[root@localhost ~]# mkdir /home/work1
[root@localhost ~]# WORKDIR=/home/work1
[root@localhost ~]# cd $WORKDIR
[root@localhost work1]# pwd
/home/work1
但是,这样的环境变量不具有全局性,作用范围也有限,默认情况下不能被其他用户使用。如果工作需要,可以使用 export 命令将其提升为全局环境变量,这样其他用户就可以使用它了:
[root@localhost work1]# su user1 <-- 切换到 user1,发现无法使用 WORKDIR 自定义变量
[user1@localhost ~]$ cd W O R K D I R [ u s e r 1 @ l o c a l h o s t ] WORKDIR [user1@localhost ~] WORKDIR[user1@localhost ] echo $WORKDIR
[user1@localhost ~]$ exit <–退出user1身份
[root@localhost work1]# export WORKDIR
[root@localhost work1]# su user1
[user1@localhost ~]$ cd W O R K D I R [ u s e r 1 @ l o c a l h o s t w o r k 1 ] WORKDIR [user1@localhost work1] WORKDIR[user1@localhostwork1] pwd
/home/work1
path环境变量与which
在讲解 PATH 环境变量之前,首先介绍一下 which 命令,它用于查找某个命令所在的绝对路径。例如:
[root@localhost ~]# which rm
/bin/rm
[root@localhost ~]# which rmdir
/bin/rmdir
[root@localhost ~]# which ls
alias ls=‘ls --color=auto’
/bin/ls
注意,ls 是一个相对特殊的命令,它使用 alias 命令做了别名,也就是说,我们常用的 ls 实际上执行的是 ls --color=auto。
通过使用 which 命令,可以查找各个外部命令(和 shell 内置命令相对)所在的绝对路径。学到这里,读者是否有这样一个疑问,为什么前面在使用 rm、rmdir、ls 等命令时,无论当前位于哪个目录,都可以直接使用,而无需指明命令的执行文件所在的位置(绝对路径)呢?其实,这是 PATH 环境变量在起作用。
首先,执行如下命令:
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin:/root/bin
这里的 echo 命令用来输出 PATH 环境变量的值(这里的 $ 是 PATH 的前缀符号),PATH 环境变量的内容是由一堆目录组成的,各目录之间用冒号“:”隔开。当执行某个命令时,Linux 会依照 PATH 中包含的目录依次搜寻该命令的可执行文件,一旦找到,即正常执行;反之,则提示无法找到该命令。
如果在 PATH 包含的目录中,有多个目录都包含某命令的可执行文件,那么会执行先搜索到的可执行文件。
从执行结果中可以看到,/bin 目录已经包含在 PATH 环境变量中,因此在使用类似 rm、rmdir、ls等命令时,即便直接使用其命令名,Linux 也可以找到该命令。
为了印证以上观点,下面举个反例,如果我们将 ls 命令移动到 /root 目录下,由于 PATH 环境变量中没有包含此目录,所有当直接使用 ls 命令名执行时,Linux 将无法找到此命令的可执行文件,并提示 No such file or directory,示例命令如下:
[root@localhost ~]# mv /bin/ls /root
[root@localhost ~]# ls
bash: /bin/ls: No such file or directory
此时,如果仍想使用 ls 命令,有 2 种方法,一种是直接将 /root 添加到 PATH 环境变量中,例如:
[root@localhost ~]# PATH=$PATH:/root
[root@localhost ~]# echo KaTeX parse error: Expected 'EOF', got '#' at position 95: …ot@localhost ~]#̲ ls Desktop …PATH 就恢复成了默认值。
另一种方法是以绝对路径的方式使用此命令,例如:
[root@localhost ~]# /root/ls
Desktop Downloads Music post-install Public Videos
Documents ls Pictures post-install.org Templates
为了不影响系统的正常使用,强烈建议大家将移动后的 ls 文件还原,命令如下:
[root@localhost ~]# mv /root/ls /bin
注意事项
PS linux复制粘贴可能提示命令不正确 由于乱码 所以可手动敲
好像也有解决方法
一、文档
cat
和vim的区别在于 这个仅仅是打开 而不编辑
-
含义:cat(英文全拼:concatenate)命令用于连接文件并打印到标准输出设备上。
-
语法格式
cat [-AbeEnstTuv] [--help] [--version] fileName
- 参数说明:
-n 或 --number:由 1 开始对所有输出的行数编号。
-b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
-s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
-E 或 --show-ends : 在每行结束处显示 $。
-T 或 --show-tabs: 将 TAB 字符显示为 ^I。
-A, --show-all:等价于 -vET。
-e:等价于"-vE"选项;
-t:等价于"-vT"选项;
- 实例:
# 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里:
cat -n textfile1 > textfile2
#把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)
#之后将内容附加到 textfile3 文档里:
cat -b textfile1 textfile2 >> textfile3
#清空 /etc/test.txt 文档内容:
cat /dev/null > /etc/test.txt
#cat 也可以用来制作镜像文件。
#例如要制作软盘的镜像文件(软盘-》文件),将软盘放好后输入:
cat /dev/fd0 > OUTFILE
#相反的,如果想把 image file 写到软盘(文件-》网盘),输入:
cat IMG_FILE > /dev/fd0

注意,cat 命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到了。不过 Linux 可以使用PgUp+上箭头组合键向上翻页,但是这种翻页是有极限的,如果文件足够长,那么还是无法看全文件的内容。
因此,cat 命令适合查看不太大的文件。当然,在 Linux 中是可以使用其他的命令或方法来查看大文件的,我们以后再来学习。
笔记:dev/null
在类 Unix 系统中,/dev/null 称空设备,是一个特殊的设备文件,它丢弃一切写入其中的数据(但报告写入操作成功),读取它则会立即得到一个 EOF。
而使用 cat $filename > /dev/null 则不会得到任何信息,因为我们将本来该通过标准输出显示的文件信息重定向到了 /dev/null 中。
使用 cat $filename 1 > /dev/null 也会得到同样的效果,因为默认重定向的 1 就是标准输出。 如果你对 shell 脚本或者重定向比较熟悉的话,应该会联想到 2 ,也即标准错误输出。
如果我们不想看到错误输出呢?我们可以禁止标准错误 cat $badname 2 > /dev/null。
grep(文本处理三剑客之一)
介绍
全拼:Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行.
grep 命令的由来可以追溯到 UNIX 诞生的早期,在 UNIX 系统中,搜索的模式(patterns)被称为正则表达式(regular expressions),为了要彻底搜索一个文件,有的用户在要搜索的字符串前加上前缀 global(全面的),一旦找到相匹配的内容,用户就像将其输出(print)到屏幕上,而将这一系列的操作整合到一起就是 global regular expressions print,而这也就是 grep 命令的全称。
格式
grep [options] [pattern] [file ...]
operations
-a --text # 不要忽略二进制数据。
-A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count # 计算符合范本样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F --fixed-regexp # 将范本样式视为固定字符串的列表。
-G --basic-regexp # 将范本样式视为普通的表示法来使用。
-h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i --ignore-case # 忽略字符大小写的差别。
-l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。
-L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。
-n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。
-P --perl-regexp # PATTERN 是一个 Perl 正则表达式
-q --quiet或–silent # 不显示任何信息。
-R/-r --recursive # 此参数的效果和指定“-d recurse”参数相同。
-s --no-messages # 不显示错误信息。
-v --revert-match # 反转查找。
-V --version # 显示版本信息。
-w --word-regexp # 只显示全字符合的列。
-x --line-regexp # 只显示全列符合的列。
-y # 此参数效果跟“-i”相同。
-o # 只输出文件中匹配到的部分。
-m --max-count= # 找到num行结果后停止查找,用来限制匹配行数
patten
详见正则表达式
实例
查找进程
> ps -ef | grep java
root 16934 1 0 Feb25 ? 00:12:23 java -jar demo.jar
root 6891 2151 0 21:42 pts/2 00:00:00 grep --color=auto java
第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。补显示grep本身可使用
ps -ef | grep redis | grep -v grep
# 有两条命令
[root@ev003v ~]$ ps -aux|grep python
root 329 0.0 0.0 112828 984 pts/11 S+ 16:06 0:00 grep --color=auto python
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
#只剩下一条了
[root@ev003v ~]$ ps -aux|grep python|grep -v grep
root 22970 0.0 0.1 586420 13588 ? Ssl 2022 40:20 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
查找进程个数
> ps -ef | grep -c java
10
> ps -ef | grep java -c
10
查找文件关键词
> grep "linux" rumenz.txt
linux123
linuxxxx
// -n 显示行号
> grep -n "linux" rumenz.txt
6:linux123
7:linuxxxx
从文件中读取关键词进行搜索
## k中是要搜寻的关键词
> cat rumenz.txt | grep -f k.txt
redis
linux123
linuxxxx
//显示行号
> cat rumenz.txt | grep -nf k.txt
5:redis
6:linux123
7:linuxxxx
多文件找关键词
> grep "linux" rumenz.txt rumenz123.txt
rumenz.txt:linux123
rumenz.txt:linuxxxx
rumenz123.txt:linux123
rumenz123.txt:linuxxxx
rumenz123.txt:linux100
通配符文件搜索
// 查找当前目录下所有以rumenz开头的文件
> grep "linux" rumenz*
rumenz123.txt:linux123
rumenz123.txt:linuxxxx
rumenz123.txt:linux100
rumenz.txt:linux123
rumenz.txt:linuxxxx
// 查找当前目录下所有以.txt结尾的文件
> grep "linux" *.txt
k.txt:linux
rumenz123.txt:linux123
rumenz123.txt:linuxxxx
rumenz123.txt:linux100
rumenz.txt:linux123
rumenz.txt:linuxxxx
————————————————
版权声明:本文为CSDN博主「入门小站」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_37335761/article/details/122682881
在关键字的显示上,grep可以用—color=auto来将关键字用特殊颜色显示。但是每次使用grep都得加上这个信息很麻烦,于是可以用alias进行一下处理就OK了。
可以在~/.bashrc内加上这一行:alias grep=‘grep –color=auto’。
grep默认显示的似乎是一个段落(回车分割的内容),如果你想搜索,包含a,b的,
可以 xxx |grep a|grep b
more
more和cat有点区别,more用于分屏显示文件内容。可以用空格键向下翻页,b键向上翻页
more 命令可以分页显示文本文件的内容,使用者可以逐页阅读文件中内容,此命令的基本格式如下:
[root@localhost ~]# more [选项] 文件名
more 命令比较简单,一般不用什么选项,对于表 1 中所列的选项,读者只需看到认识即可。
选项 含义
-f 计算行数时,以实际的行数,而不是自动换行过后的行数。
-p 不以卷动的方式显示每一页,而是先清除屏幕后再显示内容。
-c 跟 -p 选项相似,不同的是先显示内容再清除其他旧资料。
-s 当遇到有连续两行以上的空白行时,就替换为一行的空白行。
-u 不显示下引号(根据环境变量 TERM 指定的终端而有所不同)。
+n 从第 n 行开始显示文件内容,n 代表数字。
-n 一次显示的行数,n 代表数字。
more 命令的执行会打开一个交互界面,因此读者有必要了解一些交互命令,常用的交互命令如表 2 所示。
交互指令 功能
h 或 ? 显示 more 命令交互命令帮助。
q 或 Q 退出 more。
v 在当前行启动一个编辑器。
:f 显示当前文件的文件名和行号。
!<命令> 或 :!<命令> 在子Shell中执行指定命令。
回车键 向下移动一行。
空格键 向下移动一页。
Ctrl+l 刷新屏幕。
= 显示当前行的行号。
’ 转到上一次搜索开始的地方。
Ctrf+f 向下滚动一页。
. 重复上次输入的命令。
/ 字符串 搜索指定的字符串。
d 向下移动半页。
b 向上移动一页。
【例 1】用分页的方式显示 anaconda-ks.cfg 文件的内容。
[root@localhost ~]# more anaconda-ks.cfg
# Kickstart file automatically generated by anaconda.
#version=DEVEL
install
cdrom
…省略部分内容…
–More–(69%)
#在这里执行交互命令即可
【例 2】显示文件 anaconda-ks.cfg 的内容,每 10 行显示一屏,同时清楚屏幕,使用以下命令:
[root@localhost ~]# more -c -10 anaconda-ks.cfg
#省略输出内容。
less
和more类似,less用于分行显示
less 命令的作用和 more 十分类似,都用来浏览文本文件中的内容,不同之处在于,使用 more 命令浏览文件内容时,只能不断向后翻看,而使用 less 命令浏览,既可以向后翻看,也可以向前翻看。
不仅如此,为了方面用户浏览文本内容,less 命令还提供了以下几个功能:
使用光标键可以在文本文件中前后(左后)滚屏;
用行号或百分比作为书签浏览文件;
提供更加友好的检索、高亮显示等操作;
兼容常用的字处理程序(如 Vim、Emacs)的键盘操作;
阅读到文件结束时,less 命令不会退出;
屏幕底部的信息提示更容易控制使用,而且提供了更多的信息。
less 命令的基本格式如下:
[root@localhost ~]# less [选项] 文件名
此命令可用的选项以及各自的含义如表 1 所示。
选项 选项含义
-N 显示每行的行号。
-S 行过长时将超出部分舍弃。
-e 当文件显示结束后,自动离开。
-g 只标志最后搜索到的关键同。
-Q 不使用警告音。
-i 忽略搜索时的大小写。
-m 显示类似 more 命令的百分比。
-f 强迫打开特殊文件,比如外围设备代号、目录和二进制文件。
-s 显示连续空行为一行。
-b <缓冲区大小> 设置缓冲区的大小。
-o <文件名> 将 less 输出的内容保存到指定文件中。
-x <数字> 将【Tab】键显示为规定的数字空格。
在使用 less 命令查看文件内容的过程中,和 more 命令一样,也会进入交互界面,因此需要读者掌握一些常用的交互指令,如表 2 所示。
交互指令 功能
/字符串 向下搜索“字符串”的功能。
?字符串 向上搜索“字符串”的功能。
n 重复*前一个搜索(与 / 成 ? 有关)。
N 反向重复前一个搜索(与 / 或 ? 有关)。
b 向上移动一页。
d 向下移动半页。
h 或 H 显示帮助界面。
q 或 Q 退出 less 命令。
y 向上移动一行。
空格键 向下移动一页。
回车键 向下移动一行。
【PgDn】键 向下移动一页。
【PgUp】键 向上移动一页。
Ctrl+f 向下移动一页。
Ctrl+b 向上移动一页。
Ctrl+d 向下移动一页。
Ctrl+u 向上移动半页。
j 向下移动一行。
k 向上移动一行。
G 移动至最后一行。
g 移动到第一行。
ZZ 退出 less 命令。
v 使用配置的编辑器编辑当前文件。
[ 移动到本文档的上一个节点。
] 移动到本文档的下一个节点。
p 移动到同级的上一个节点。
u 向上移动半页。
【例 1】使用 less 命令查看 /boot/grub/grub.cfg 文件中的内容。
[root@localhost ~]# less /boot/grub/grub.cfg
#
#DO NOT EDIT THIS FILE
#
#It is automatically generated by grub-mkconfig using templates from /etc/grub.d and settings from /etc/default/grub
#
### BEGIN /etc/grub.d/00_header ###
if [ -s p r e f i x / g r u b e n v ] ; t h e n s e t h a v e g r u b e n v = t r u e l o a d e n v f i s e t d e f a u l t = " 0 " i f [ " prefix/grubenv ]; then set have_grubenv=true load_env fi set default="0" if [ " prefix/grubenv];thensethavegrubenv=trueloadenvfisetdefault="0"if[" {prev_saved_entry}" ]; then
set saved_entry=“${prev_saved_entry}”
save_env saved_entry
set prev_saved_entry= save_env prev_saved_entry
set boot_once=true
fi
function savedefault {
if [ -z “${boot_once}” ]; then
:
可以看到,less 在屏幕底部显示一个冒号(:),等待用户输入命令,比如说,用户想向下翻一页,可以按空格键;如果想向上翻一页,可以按 b 键。
tail与head
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail [参数] [文件]
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
tail notes.log # 默认显示最后 10 行
tail -f filename #会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
tail -n 100 /etc/cron #显示最后100行数据
tail -n +20 notes.log #显示文件 notes.log 的内容,从第 20 行至文件末尾
tail -fn 100 xx.log #查看最后的100行内容
head 命令可用于查看文件的开头部分的内容,有一个常用的参数 -n 用于显示行数,默认为 10,即显示 10 行的内容。
#显示 notes.log 文件的开头 5 行,请输入以下命令:
head -n 5 runoob_notes.log #不输-n 默认10行
vim
可供选择的编辑器不止一种,例如 Vim、emacs、pico、nano 等,很多人都找到了自己所喜爱的编辑器。综合考虑各种因素,本套 Linux 教程建议初学者学习 Vim 文本编辑器。
Vim文本编辑器,是由 vi 发展演变过来的文本编辑器,因其具有使用简单、功能强大、是 Linux 众多发行版的默认文本编辑器等特点,成功圈住了很多人成为其死忠粉丝。
https://www.runoob.com/linux/linux-vim.html
注意
1vim中 鼠标下滑不一定管用 得键盘上下才能看到全部内容
2 vim直接粘贴可能不全 解决方法搜下
相信大家都使用过带图形界面的操作系统中的文字编辑器,用户可以使用鼠标来选择要操作的文本,非常方便。在 Vim 编辑器中也有类似的功能,但不是通过鼠标,而是通过键盘来选择要操作的文本。
在 Vim 中,如果想选中目标文本,就需要调整 Vim 进入可视化模式,如表 1 所示,通过在 Vim 命令模式下键入不同的键,可以进入不同的可视化模式。
sed-文本处理(三剑客之一)
逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
看到再说 https://developer.aliyun.com/article/910308?spm=a2c6h.13262185.profile.64.6f69961fYrL5Vd
awk(三剑客)
和 sed 命令类似,awk 命令也是逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
awk 命令的基本格式为:
[root@localhost ~]# awk [选项] ‘脚本命令’ 文件名
https://developer.aliyun.com/article/910315?spm=a2c6h.13262185.profile.62.6f69961fYrL5Vd
二、进程管理
操作系统会给每个进程分配一个 ID,称为 PID(进程 ID)。
在操作系统中,所有可以执行的程序与命令都会产生进程。只是有些程序和命令非常简单,如 ls 命令、touch 命令等,它们在执行完后就会结束,相应的进程也就会终结,所以我们很难捕捉到这些进程。但是还有一些程和命令,比如 httpd 进程,启动之后就会一直驻留在系统当中,我们把这样的进程称作常驻内存进程。
某些进程会产生一些新的进程,我们把这些进程称作子进程,而把这个进程本身称作父进程。比如,我们必须正常登录到 Shell 环境中才能执行系统命令,而 Linux 的标准 Shell 是 bash。我们在 bash 当中执行了 ls 命令,那么 bash 就是父进程,而 ls 命令是在 bash 进程中产生的进程,所以 ls 进程是 bash 进程的子进程。也就是说,子进程是依赖父进程而产生的,如果父进程不存在,那么子进程也不存在了。
值得一提的是 一般来说新进程都是由当前 Shell 这个进程产生的,换句话说,是 Shell 创建了新进程,于是称这种关系为进程间的父子关系,其中 Shell 是父进程,新进程是子进程。
值得一提的是,一个父进程可以有多个子进程,通常子进程结束后才能继续父进程;当然,如果是从后台启动,父进程就不用等待子进程了。
我们再来说说僵尸进程。僵尸进程的产生一般是由于进程非正常停止或程序编写错误,导致子进程先于父进程结束,而父进程又没有正确地回收子进程,从而造成子进程一直存在于内存当中,这就是僵尸进程。
僵尸进程会对主机的稳定性产生影响,所以,在产生僵尸进程后,一定要对产生僵尸进程的软件进行优化,避免一直产生僵尸进程;对于已经产生的僵尸进程,可以在查找出来之后强制中止。
启动进程的三种方式
前台启动进程
这是手工启动进程最常用的方式,因为当用户输入一个命令并运行,就已经启动了一个进程,而且是一个前台的进程,此时系统其实已经处于一个多进程的状态(一个是 Shell 进程,另一个是新启动的进程)。
实际上,系统自动时就有许多进程悄悄地在后台运行,不过这里为了方便读者理解,并没有将这些进程包括在内。
假如启动一个比较耗时的进程,然后再把该进程挂起,并使用 ps 命令查看,就会看到该进程在 ps 显示列表中,例如:
[root@localhost ~]# find / -name demo.jpg <--在根目录下查找 demo.jpg 文件,比较耗时
#此处省略了该命令的部分输出信息
#按“CTRL+Z”组合键,即可将该进程挂起
[root@localhost ~]# ps <--查看正在运行的进程
PID TTY TIME CMD
2573 pts/0 00:00:00 bash
2587 pts/0 00:00:01 find
2588 pts/0 00:00:00 ps
将进程挂起,指的是将前台运行的进程放到后台,并且暂停其运行,有关挂起进程和 ps 命令用法,后续章节会做详细介绍。
通过运行 ps 命令查看进程信息,可以看到,刚刚执行的 find 命令的进程号为 2587,同时 ps 进程的进程号为 2588。
后台启动进程
进程直接从后台运行,用的相对较少,除非该进程非常耗时,且用户也不急着需要其运行结果的时候,例如,用户需要启动一个需要长时间运行的格式化文本文件的进程,为了不使整个 Shell 在格式化过程中都处于“被占用”状态,从后台启动这个进程是比较明智的选择。
从后台启动进程,其实就是在命令结尾处添加一个 " &" 符号(注意,& 前面有空格)。输入命令并运行之后,Shell 会提供给我们一个数字,此数字就是该进程的进程号。然后直接就会出现提示符,用户就可以继续完成其他工作,例如:
[root@localhost ~]# find / -name install.log &
[1] 1920
#[1]是工作号,1920是进程号
有关后台启动进程及相关的注意事项,后续章节会做详细介绍。
调度启动
在 Linux 系统中,任务可以被配置在指定的时间、日期或者系统平均负载量低于指定值时自动启动。
例如,Linux 预配置了重要系统任务的运行,以便可以使系统能够实时被更新,系统管理员也可以使用自动化的任务来定期对重要数据进行备份。
实现调度启动进程的方法有很多,例如通过 crontab、at 等命令,有关这些命令的具体用法,本章后续章节会做详细介绍。
进程优先级与nice命令
Linux 是一个多用户、多任务的操作系统,系统中通常运行着非常多的进程。但是 CPU 在一个时钟周期内只能运算一条指令(现在的 CPU 采用了多线程、多核心技术,所以在一个时钟周期内可以运算多条指令。 但是同时运算的指令数也远远小于系统中的进程总数),那问题来了:谁应该先运算,谁应该后运算呢?这就需要由进程的优先级来决定了。
另外,CPU 在运算数据时,不是把一个集成算完成,再进行下一个进程的运算,而是先运算进程 1,再运算进程 2,接下来运算进程 3,然后再运算进程 1,直到进程任务结束。不仅如此,由于进程优先级的存在,进程并不是依次运算的,而是哪个进程的优先级高,哪个进程会在一次运算循环中被更多次地运算。
这样说很难理解,我们换一种说法。假设我现在有 4 个孩子(进程)需要喂饭(运算),我更喜欢孩子 1(进程 1 优先级更高),孩子 2、孩子 3 和孩子 4 一视同仁(进程 2、进程 3 和进程 4 的优先级一致)。现在我开始喂饭了,我不能先把孩子 1 喂饱,再喂其他的孩子,而是需要循环喂饭(CPU 运算时所有进程循环运算)。那么,我在喂饭时(运算),会先喂孩子 1 一口饭,然后再去喂其他孩子。而且在一次循环中,先喂孩子 1 两口饭,因为我更喜欢孩子 1(优先级高),而喂其他的孩子一口饭。这样,孩子 1 会先吃饱(进程 1 运算得更快),因为我更喜欢孩子 1。
在 Linux 系统中,表示进程优先级的有两个参数:Priority 和 Nice。还记得 “ps -le” 命令吗?
[root@localhost ~]# ps -le
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 80 0 - 718 - ? 00:00:01 init
1 S 0 2 0 0 80 0 - 0 - ? 00:00:00 kthreadd
...省略部分输出...
其中,PRI 代表 Priority,NI 代表 Nice。这两个值都表示优先级,数值越小代表该进程越优先被 CPU 处理。不过,PRI值是由内核动态调整的,用户不能直接修改。所以我们只能通过修改 NI 值来影响 PRI 值,间接地调整进程优先级。
PRI 和 NI 的关系如下:
PRI (最终值) = PRI (原始值) + NI
其实,大家只需要记得,我们修改 NI 的值就可以改变进程的优先级即可。NI 值越小,进程的 PRI 就会降低,该进程就越优先被 CPU 处理;反之,NI 值越大,进程的 PRI 值就会増加,该进程就越靠后被 CPU 处理。
修改 NI 值时有几个注意事项:
NI 范围是 -20~19。
普通用户调整 NI 值的范围是 0~19,而且只能调整自己的进程。
普通用户只能调高 NI 值,而不能降低。如原本 NI 值为 0,则只能调整为大于 0。
只有 root 用户才能设定进程 NI 值为负值,而且可以调整任何用户的进程。
PS
ps (英文全拼:process status)命令用于显示当前进程的状态,类似于 windows 的任务管理器。
ps 命令有多种不同的使用方法,这常常给初学者带来困惑。在各种 Linux 论坛上,询问 ps 命令语法的帖子屡见不鲜,而出现这样的情况,还要归咎于 UNIX 悠久的历史和庞大的派系。在不同的 Linux 发行版上,ps 命令的语法各不相同,为此,Linux 采取了一个折中的方法,即融合各种不同的风格,兼顾那些已经习惯了其它系统上使用 ps 命令的用户。
ps 命令的基本格式如下:
#查看系统中所有的进程,使用 BS 操作系统格式
[root@localhost ~]# ps aux
#查看系统中所有的进程,使用 Linux 标准命令格式
[root@localhost ~]# ps -le
ps [options] [--help]
选项:
a:显示一个终端的所有进程,除会话引线外;
u:显示进程的归属用户及内存的使用情况;
x:显示没有控制终端的进程;
-l:长格式显示更加详细的信息;
-e:显示所有进程;
可以看到,ps 命令有些与众不同,它的部分选项不能加入"-“,比如命令"ps aux”,其中"aux"是选项,但是前面不能带“-”。
大家如果执行 “man ps” 命令,则会发现 ps 命令的帮助为了适应不同的类 UNIX 系统,可用格式非常多,不方便记忆。所以,我建议大家记忆几个固定选项即可。比如下面的三个足以
ps 默认显示前台进程
ps aux 可以查看系统中所有的进程;
ps -le 可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级;
ps -l 只能看到当前 Shell(或者说当前登录) 产生的进程;
只用ps 即使加了-a 也不会显示全部进程 要显示全部进程要加-e参数 -f用于显示详细信息(这个不是unix风格 是linux风格的命令吧)
USER PID %CPU %MEM VSZ(虚拟内存占用) RSS(记忆体 物理内存大小) TTY STAT(该行程的状态:) START TIME COMMAND(所执行的指令)
| 表头 | 含义 |
|---|---|
| USER | 该进程是由哪个用户产生的。 |
| PID | 进程的 ID。 |
| %CPU | 该进程占用 CPU 资源的百分比,占用的百分比越高,进程越耗费资源。 |
| %MEM | 该进程占用物理内存的百分比,占用的百分比越高,进程越耗费资源。 |
| VSZ | 该进程占用虚拟内存的大小,单位为 KB。 |
| RSS | 该进程占用实际物理内存的大小,单位为 KB。 |
| TTY | 该进程是在哪个终端运行的。其中,tty1 ~ tty7 代表本地控制台终端(可以通过 Alt+F1 ~ F7 快捷键切换不同的终端),tty1~tty6 是本地的字符界面终端,tty7 是图形终端。pts/0 ~ 255 代表虚拟终端,一般是远程连接的终端,第一个远程连接占用 pts/0,第二个远程连接占用 pts/1,依次増长。 |
| STAT | 进程状态。常见的状态有以下几种:
|
| START | 该进程的启动时间。 |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间。 |
| COMMAND | 产生此进程的命令名。 |
实例
ps -ef | grep 进程关键字 (最后一个进程是grep本身)
显示进程信息 ps -A
ps -u root //显示root进程用户信息
ps -ef //显示所有命令,连带命令行
top
ps 命令可以一次性给出当前系统中进程状态,但使用此方式得到的信息缺乏时效性,并且,如果管理员需要实时监控进程运行情况,就必须不停地执行 ps 命令,这显然是缺乏效率的。
为此,Linux 提供了 top 命令。top 命令可以动态地持续监听进程地运行状态,与此同时,该命令还提供了一个交互界面,用户可以根据需要,人性化地定制自己的输出,进而更清楚地了进程的运行状态。
top 命令的基本格式如下:
[root@localhost ~]#top [选项]
选项:
-d 秒数:指定 top 命令每隔几秒更新。默认是 3 秒;
-b:使用批处理模式输出。一般和"-n"选项合用,用于把 top 命令重定向到文件中;
-n 次数:指定 top 命令执行的次数。一般和"-"选项合用;
-p 进程PID:仅查看指定 ID 的进程;
-s:使 top 命令在安全模式中运行,避免在交互模式中出现错误;
-u 用户名:只监听某个用户的进程;
在 top 命令的显示窗口中,还可以使用如下按键,进行一下交互操作:
? 或 h:显示交互模式的帮助;
P:按照 CPU 的使用率排序,默认就是此选项;
M:按照内存的使用率排序;
N:按照 PID 排序;
T:按照 CPU 的累积运算时间排序,也就是按照 TIME+ 项排序;
k:按照 PID 给予某个进程一个信号。一般用于中止某个进程,信号 9 是强制中止的信号;
r:按照 PID 给某个进程重设优先级(Nice)值;
q:退出 top 命令;
[root@localhost ~]# top
top - 12:26:46 up 1 day, 13:32, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 95 total, 1 running, 94 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.7%id, 0.1%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 625344k total, 571504k used, 53840k free, 65800k buffers
Swap: 524280k total, 0k used, 524280k free, 409280k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
19002 root 20 0 2656 1068 856 R 0.3 0.2 0:01.87 top
1 root 20 0 2872 1416 1200 S 0.0 0.2 0:02.55 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
····
第一部分是前五行,显示的是整个系统的资源使用状况,我们就是通过这些输出来判断服务器的资源使用状态的;
第二部分从第六行开始,显示的是系统中进程的信息
第二行为进程信息
| 内 容 | 说 明 |
|---|---|
| Tasks: 95 total | 系统中的进程总数 |
| 1 running | 正在运行的进程数 |
| 94 sleeping | 睡眠的进程数 |
| 0 stopped | 正在停止的进程数 |
| 0 zombie | 僵尸进程数。如果不是 0,则需要手工检查僵尸进程 |
其他的 比如cpu啥的 看http://c.biancheng.net/view/1065.html
我们通过 top 命令的第一部分就可以判断服务器的健康状态。如果 1 分钟、5 分钟、15 分钟的平均负载高于 1,则证明系统压力较大。如果 CPU 的使用率过高或空闲率过低,则证明系统压力较大。如果物理内存的空闲内存过小,则也证明系统压力较大。
这时,我们就应该判断是什么进程占用了系统资源。如果是不必要的进程,就应该结束这些进程;如果是必需进程,那么我们该増加服务器资源(比如増加虚拟机内存),或者建立集群服务器。
我们还要解释一下缓冲(buffer)和缓存(cache)的区别:
- 缓存(cache)是在读取硬盘中的数据时,把最常用的数据保存在内存的缓存区中,再次读取该数据时,就不去硬盘中读取了,而在缓存中读取。
- 缓冲(buffer)是在向硬盘写入数据时,先把数据放入缓冲区,然后再一起向硬盘写入,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。
实例
top 命令如果不正确退出,则会持续运行。在 top 命令的交互界面中按 “q” 键会退出 top 命令;也可以按 “?” 或 “h” 键得到 top 命令交互界面的帮助信息;还可以按键中止某个进程。
【例 5】如果在操作终端执行 top 命令,则并不能看到系统中所有的进程,默认看到的只是 CPU 占比靠前的进程。如果我们想要看到所有的进程,则可以把 top 命令的执行结果重定向到文件中。不过 top 命令是持续运行的,这时就需要使用 “-b” 和 “-n” 选项了。具体命令如下:
[root@localhost ~]# top -b -n 1 > /root/top.log
#让top命令只执行一次,然后把执行结果保存到top.log文件中,这样就能看到所有的进程了
pstree
pstree 命令是以树形结构显示程序和进程之间的关系(父子等)
lsof
我们知道,通过 ps 命令可以查询到系统中所有的进程,那么,是否可以进一步知道这个进程到底在调用哪些文件吗?当然可以,使用 lsof 命令即可。
lsof 命令,“list opened files”的缩写,直译过来,就是列举系统中已经被打开的文件。通过 lsof 命令,我们就可以根据文件找到对应的进程信息,也可以根据进程信息找到进程打开的文件。
kill与信号量(进程间通信)
这是进程管理中最不常用的手段。当需要停止服务时,会通过正确关闭命令来停止服务(如 apache 服务可以通过 service httpd stop 命令来关闭)。只有在正确终止进程的手段失效的情况下,才会考虑使用 kill 命令杀死进程。
kill [-s <信息名称或编号>][程序] 或 kill [-l <信息编号>]
-l <信息编号> 若不加<信息编号>选项,则 -l 参数会列出全部的信息名称。
-s <信息名称或编号> 指定要送出的信息。
[程序] [程序]可以是程序的PID或是PGID,也可以是工作编号
使用 kill -l 命令列出所有可用信号。
最常用的信号是:
1 (HUP):重新加载进程。
9 (KILL):杀死一个进程。
15 (TERM):正常停止一个进程。
# 杀死进程
kill 12345
#强制杀死进程
kill -KILL 123456
#发送SIGHUP信号,可以使用一下信号
kill -HUP pid
#彻底杀死进程
kill -9 123456
#杀死指定用户所有进程
kill -9 $(ps -ef | grep hnlinux) //方法一 过滤出hnlinux用户进程
kill -u hnlinux //方法二
linux 的 kill 命令是向进程发送信号,kill 不是杀死的意思,-9 表示无条件退出,但由进程自行决定是否退出,这就是为什么 kill -9 终止不了系统进程和守护进程的原因。
killall命令:终止特定的一类进程
killall 也是用于关闭进程的一个命令,但和 kill 不同的是,killall 命令不再依靠 PID 来杀死单个进程,而是通过程序的进程名来杀死一类进程,也正是由于这一点,该命令常与 ps、pstree 等命令配合使用。
killall 命令的基本格式如下:
[root@localhost ~]# killall [选项] [信号] 进程名
注意,此命令的信号类型同 kill 命令一样,因此这里不再赘述,此命令常用的选项有如下 2 个:
-i:交互式,询问是否要杀死某个进程;
-I:忽略进程名的大小写;
接下来,给大家举几个例子。
【例 1】杀死 httpd 进程。
[root@localhost ~]# service httpd start
#启动RPM包默认安装的apache服务
[root@localhost ~]# ps aux | grep “httpd” | grep -v “grep”
root 1600 0.0 0.2 4520 1696? Ss 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1601 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1602 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1603 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1604 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
daemon 1605 0.0 0.1 4520 1188? S 19:42 0:00 /usr/local/apache2/bin/httpd -k start
#查看httpd进程
[root@localhost ~]# killall httpd
#杀死所有进程名是httpd的进程
[root@localhost ~]# ps aux | grep “httpd” | grep -v “grep”
#查询发现所有的httpd进程都消失了
【例 2】交互式杀死 sshd 进程。
[root@localhost ~]# ps aux | grep “sshd” | grep -v “grep”
root 1733 0.0 0.1 8508 1008? Ss 19:47 0:00/usr/sbin/sshd
root 1735 0.1 0.5 11452 3296? Ss 19:47 0:00 sshd: root@pts/0
root 1758 0.1 0.5 11452 3296? Ss 19:47 0:00 sshd: root@pts/1
#查询系统中有3个sshd进程。1733是sshd服务的进程,1735和1758是两个远程连接的进程
[root@localhost ~]# killall -i sshd
#交互式杀死sshd进程
杀死sshd(1733)?(y/N)n
#这个进程是sshd的服务进程,如果杀死,那么所有的sshd连接都不能登陆
杀死 sshd(1735)?(y/N)n
#这是当前登录终端,不能杀死我自己吧
杀死 sshd(1758)?(y/N)y
#杀死另一个sshd登陆终端
pkill命令:终止进程,按终端号踢出用户
后台基本管理原理与命令
工作管理指的是在单个登录终端(也就是登录的 Shell 界面)同时管理多个工作的行为。也就是说,我们登陆了一个终端,已经在执行一个操作,那么是否可以在不关闭当前操作的情况下执行其他操作呢?
当然可以,我们可以再启动一个终端,然后执行其他的操作。不过,是否可以在一个终端执行不同的操作呢?这就需要通过工作管理来实现了。
例如,我在当前终端正在 vi 一个文件,在不停止 vi 的情况下,如果我想在同一个终端执行其他的命令,就应该把 vi 命令放入后台,然后再执行其他命令。把命令放入后台,然后把命令恢复到前台,或者让命令恢复到后台执行,这些管理操作就是工作管理。
后台管理有几个事项需要大家注意:
前台是指当前可以操控和执行命令的这个操作环境;后台是指工作可以自行运行,但是不能直接用 Ctrl+C 快捷键来中止它,只能使用 fg/bg 来调用工作。
当前的登录终端只能管理当前终端的工作,而不能管理其他登录终端的工作。比如 tty1 登录的终端是不能管理 tty2 终端中的工作的。
放入后台的命令必须可以持续运行一段时间,这样我们才能捕捉和操作它。
放入后台执行的命令不能和前台用户有交互或需要前台输入,否则只能放入后台暂停,而不能执行。比如 vi 命令只能放入后台暂停,而不能执行,因为 vi 命令需要前台输入信息;top 命令也不能放入后台执行,而只能放入后台暂停,因为 top 命令需要和前台交互。
命令放入后台运行方法(&和Ctrl+Z)
Linux 命令放入后台的方法有两种,分别介绍如下。
“命令 &”,把命令放入后台执行
第一种把命令放入后台的方法是在命令后面加入 空格 &。使用这种方法放入后台的命令,在后台处于执行状态。
注意,放入后台执行的命令不能与前台有交互,否则这个命令是不能在后台执行的。例如:
[root@localhost ~]#find / -name install.log &
[1] 1920
#[工作号] 进程号
#把find命令放入后台执行,每个后台命令会被分配一个工作号。命令既然可以执行,就会有进程产生,所以也会有进程号
这样,虽然 find 命令在执行,但在当前终端仍然可以执行其他操作。如果在终端上出现如下信息:
[1]+ Done find / -name install.log
则证明后台的这个命令已经完成了。当然,命令如果有执行结果,则也会显示到操作终端上。其中,[1] 是这个命令的工作号,"+"代表这个命令是最近一个被放入后台的。
命令执行过裎中按 Ctrl+Z 快捷键,命令在后台处于暂停状态
使用这种方法放入后台的命令,就算不和前台有交互,能在后台执行,也处于暂停状态,因为 Ctrl+Z 快捷键就是暂停的快捷键。
【例 1】
[root@localhost ~]#top
#在top命令执行的过程中,按下Ctrl+Z快捷键
[1]+ Stopped top
#top命令被放入后台,工作号是1,状态是暂停。而且,虽然top命令没有结束,但也能取得控制台权限
【例 2】
[root@localhost ~]# tar -zcf etc.tar.gz /etc
#压缩一下/etc/目录
tar:从成员名中删除开头的"/"
tar:从硬链接目标中删除开头的"/"
^Z
#在执行过程中,按下Ctrl+Z快捷键
[2]+ Stopped tar-zcf etc.tar.gz/etc
#tar命令被放入后台,工作号是2,状态是暂停
每个被放入后台的命令都会被分配一个工作号。第一个被放入后台的命令,工作号是 1;第二个被放入后台的命令,工作号是 2,以此类推。
jobs命令:查看当前终端放入后台的工作
jobs 命令可以用来查看当前终端放入后台的工作,工作管理的名字也来源于 jobs 命令。
jobs 命令的基本格式如下:
[root@localhost ~]#jobs [选项]
表 1 罗列了 jobs 命令常用的选项及含义。
表 1 jobs 命令常用选项及含义、
| 选项 | 含义 |
|---|---|
| -l | (L 的小写) 列出进程的 PID 号。 |
| -n | 只列出上次发出通知后改变了状态的进程。 |
| -p | 只列出进程的 PID 号。 |
| -r | 只列出运行中的进程。 |
| -s | 只列出已停止的进程。 |
| 例如: |
[root@localhost ~]#jobs -l
[1]- 2023 Stopped top
[2]+ 2034 Stopped tar -zcf etc.tar.gz /etc
可以看到,当前终端有两个后台工作:一个是 top 命令,工作号为 1,状态是暂停,标志是"-“;另一个是 tar 命令,工作号为 2,状态是暂停,标志是”+“。”+“号代表最近一个放入后台的工作,也是工作恢复时默认恢复的工作。”-"号代表倒数第二个放入后台的工作,而第三个以后的工作就没有"±"标志了。
一旦当前的默认工作处理完成,则带减号的工作就会自动成为新的默认工作,换句话说,不管此时有多少正在运行的工作,任何时间都会有且仅有一个带加号的工作和一个带减号的工作。
fg命令:把后台命令恢复在前台执行
前面所讲,都是将工作丢到后台去运行,那么,有没有可以将后台工作拿到前台来执行的办法呢?答案是肯定的,使用 fg 命令即可。
fg 命令用于把后台工作恢复到前台执行,该命令的基本格式如下:
[root@localhost ~]#fg %工作号
注意,在使用此命令时,% 可以省略,但若将% 工作号全部省略,则此命令会将带有 + 号的工作恢复到前台。另外,使用此命令的过程中, % 可有可无。
例如:
[root@localhost ~]#jobs
[1]- Stopped top
[2]+ Stopped tar-zcf etc.tar.gz/etc
[root@localhost ~]# fg
#恢复“+”标志的工作,也就是tar命令
[root@localhost ~]# fg %1
#恢复1号工作,也就是top命令
top 命令是不能在后台执行的,所以,如果要想中止 top 命令,要么把 top 命令恢复到前台,然后正常退出;要么找到 top 命令的 PID,使用 kill 命令杀死这个进程。
bg命令:把后台暂停的工作恢复到后台执行
nohup命令:后台命令脱离终端运行
在前面章节中,我们一直在说进程可以放到后台运行,这里的后台,其实指的是当前登陆终端的后台。这种情况下,当我们以远程管理服务器的方式,在远程终端执行后台命令,如果在命令尚未执行完毕时就退出登陆,那么这个后台命令还会继续执行吗?
当然不会,此命令的执行会被中断。这就引出一个问题,如果我们确实需要在远程终端执行某些后台命令,该如何执行呢?有以下 3 种方法:
把需要在后台执行的命令加入 /etc/rc.local 文件,让系统在启动时执行这个后台程序。这种方法的问题是,服务器是不能随便重启的,如果有临时后台任务,就不能执行了。
使用系统定时任务,让系统在指定的时间执行某个后台命令。这样放入后台的命令与终端无关,是不依赖登录终端的。
使用 nohup 命令。
本节重点讲解 nohup 命令的用法。nohup 命令的作用就是让后台工作在离开操作终端时,也能够正确地在后台执行。此命令的基本格式如下:
[root@localhost ~]# nohup [命令] &
注意,这里的‘&’表示此命令会在终端后台工作;反之,如果没有‘&’,则表示此命令会在终端前台工作。
例如:
[root@localhost ~]# nohup find / -print > /root/file.log &
[3] 2349
#使用find命令,打印/下的所有文件。放入后台执行
[root@localhost ~]# nohup:忽略输入并把输出追加到"nohup.out"
[root@localhost ~]# nohup:忽略输入并把输出追加到"nohup.out"
#有提示信息
接下来的操作要迅速,否则 find 命令就会执行结束。然后我们可以退出登录,重新登录之后,执行“ps aux”命令,会发现 find 命令还在运行。
如果 find 命令执行太快,我们就可以写一个循环脚本,然后使用 nohup 命令执行。例如:
[root@localhost ~]# vi for.sh
#!/bin/bash
for ((i=0;i<=1000;i=i+1))
#循环1000次
do
echo 11 >> /root/for.log
#在for.log文件中写入11
sleep 10s
#每次循环睡眠10秒
done
[root@localhost ~]# chmod 755 for.sh
[root@localhost ~]# nohup /root/for.sh &
[1] 2478
[root@localhost ~]# nohup:忽略输入并把输出追加到"nohup.out"
#执行脚本
接下来退出登录,重新登录之后,这个脚本仍然可以通过“ps aux”命令看到。
others
12.19 Linux定时执行任务(at命令)
12.20 Linux循环执行定时任务(crontab命令)
12.21 Linux检测长期未执行的定时任务(anacron命令)
12.25 Linux查看登陆用户信息(w和who命令)
12.26 Linux查看过去登陆的用户信息(last和lastlog命令)
源码包服务的启动管理
源码包服务的启动管理
源码包服务中所有的文件都会安装到指定目录当中,并且没有任何垃圾文件产生(Linux 的特性),所以服务的管理脚本程序也会安装到指定目录中。源码包服务的启动管理方式就是在服务的安装目录中找到管理脚本,然后执行这个脚本。
问题来了,每个服务的启动脚本都是不一样的,我们怎么确定每个服务的启动脚本呢?还记得在安装源码包服务时,我们强调需要査看每个服务的说明文档吗(一般是 INSTALL 或 READEM)?在这个说明文档中会明确地告诉大家服务的启动脚本是哪个文件。
我们用 apache 服务来举例。一般 apache 服务的安装位置是 /usr/local/apache2/ 目录,那么 apache 服务的启动脚本就是 /usr/local/apache2/bin/apachectl 文件(查询 apache 说明文档得知)。启动命令如下:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start|stop|restart|…
#源码包服务的启动管理
例如:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start
#会启动源码包安装的apache服务
注意,不管是源码包安装的 apache,还是 RPM 包默认安装的 apache,虽然在一台服务器中都可以安装,但是只能启动一因为它们都会占用 80 端口。
源码包服务的启动方法就这一种,比 RPM 包默认安装的服务要简单一些。
源码包服务的自启动管理
源码包服务的白启动管理也不能依靠系统的服务管理命令,而只能把标准启动命令写入 /etc/rc.d/rc.local 文件中。系统在启动过程中读取 /etc/rc.d/rc.local 文件时,就会调用源码包服务的启动脚本,从而让该服务开机自启动。命令如下:
[root@localhost ~]# vi /etc/rc.d/rc.local
#修改自启动文件
#!/bin/sh
#This script will be executed after all the other init scripts.
#You can put your own initialization stuff in here if you don11
#want to do the full Sys V style init stuff.
touch /var/lock/subsys/local /usr/local/apache2/bin/apachectl start
#加入源码包服务的标准启动命令,保存退出,源码包安装的apache服务就被设为自启动了
让源码包服务被服务管理命令识别
在默认情况下,源码包服务是不能被系统的服务管理命令所识别和管理的,但是如果我们做一些设定,则也是可以让源码包服务被系统的服务管理命令所识别和管理的。不过笔者并不推荐大家这样做,因为这会让本来区别很明确的源码包服务和 RPM 包服务变得容易混淆,不利于系统维护和管理。
我们做一个实验,看看如何把源码包安装的 apache 服务变为和 RPM 包默认安装的 apache 服务一样,可以被 service、chkconfig、ntsysv 命令所识别。实验如下:
- 卸载RPM包默认安装的apache服务
[root@localhost ~]# yum -y remove httpd
#卸载RPM包默认安装的apache服务,避免对实验产生影响(在生产服务器上慎用yum卸载,因为这有可能造成服务器崩溃)
[root@localhost ~]# service httpd start httpd:未被识别的服务
#因为服务被卸载,所以service命令不能识别httpd服务 - 安装源码包的apache服务,并启动
#安装源码包的apache服务
[root@localhost ~]# /usr/local/apache2/bin/apachect1 start
[root@localhost ~]# netstat -tlun | grep 80
tcp 0 0 :::80 :: LISTEN
#启动源码包安装的apache服务,查看端口确定已经启动 - 让源码包安装的apache服务能被service命令管理启动
[root@localhost ~]# ln -s /usr/local/apache2/bin/apachectl /etc/±nit.d/apache
#service命令其实只是在/etc/init.d/目录中查找是否有服务的启动脚本,所以我们只需要做一个软链接,把源码包的启动脚本链接到/etc/init.d/目录中,就能被service命令所管理了。为了照顾大家的习惯,我把软链接文件命名为apache,注意这不是RPM包默认安装的apache服务
[root@localhost ~]# service apache restart
#虽然RPM包默认安装的apache服务被卸载了,但是service命令也能够生效 - 让源码包安装的apache服务能被chkconfig命令管理自启动
[root@localhost ~]# vi /etc/init.d/apache
#修改源码包安装的apache服务的启动脚本(注意此文件是软链接,所以修改的还是源码包启动脚本)
#!/bin/sh
#
#chkconfig: 35 86 76
#指定httpd脚本可以被chkconfig命令所管理
#格式是:chkconfig:运行级别 启动顺序 关闭顺序
#这里我们让apache服务在3和5级别中能被chkconfig命令所管理,启动顺序是S86,关闭顺序是K76
#(自定顺序,不要和系统中已有的启动顺序冲突)
#description: source package apache
#说明,内容随意
#以上两句话必须加入,才能被chkconfig命令所识别 …省略部分输出…
[root@localhost ~]# chkconfig --add apache
#让chkconfig命令能够管理源码包安装的apache服务
[root01ocalhost ~]# chkconfig --list | grep apache
apache 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
#很神奇吧,虽然RPM包默认安装的apache服务被删除了,但是chkconfig命令可以管理源码包安装的tapache服务 - 让ntsysv命令可以管理源码包安装的apache服务
#ntsysv 命令其实和 chkconfig 命令使用同样的管理机制,也就是说,ntsysv 已经可以进行源码包安装 apache 服务的自启动管理了,如图 1 所示
img
图 1 ntsysv 命令识别 apache
总结一下,如果想让源码包服务被service命令所识别和管理,则只需做一个软链接把启动脚本链接到 /etc/init.d/ 目录中即可。要想让源码包服务被 chkconfig 命令所是被,除了需要把服务的启动脚本链接到 /etc/init.d/ 目录中,还要修改这个启动脚本,在启动脚本的开头加入如下内容:
#chkconfig:运行级别 启动顺序 关闭
#description:说明
然后需要使用"chkconfig–add 服务名"的方式把服务加入 chkconfig 命令的管理中。命令格式如下:
[root@localhost ~]# chkconfig [选项][服务名]
选项:
-add:把服务加入 chkconfig 命令的管理中;
-del:把服务从 chkconfig 命令的管理中删除;
例如:
[root@localhost ~]# chkconfig -del httpd
#把apache服务从chkconfig命令的管理中删除
文件管理
ls
ls(英文全拼:list files): 列出目录及文件名
选项与参数:
-a :全部的文件,连同隐藏文件( 开头为 . 的文件) 一起列出来(常用)
-d :仅列出目录本身,而不是列出目录内的文件数据(常用)
-l :长数据串列出,包含文件的属性与权限等等数据;(常用)
-h :kb显示文件大小而非字节
| 第一个字符 | 文件类型 |
|---|---|
| - | 普通文件,包括纯文本文件、二进制文件、各种压缩文件等。 |
| d | 目录,类似 Windows 系统中的文件夹。 |
| b | 块设备文件,就是保存大块数据的设备,比如最常见的硬盘。 |
| c | 字符设备文件,例如键盘、鼠标等。 |
| s | 套接字文件,通常用在网络数据连接,可以启动一个程序开监听用户的要求,用户可以通过套接字进行数据通信。 |
| p | 管道文件,其主要作用是解决多个程序同时存取一个文件所造成的错误。 |
| l | 链接文件,类似 Windows 系统中的快捷方式。 |
ll
ll"等同于"ls -l"。
cd
cd(英文全拼:change directory):切换目录
cd ~进入用户主目录cd ~ xiaoming进入小明用户的主目录cd -返回进入此目录之前所在目录cd ..返回上一级目录cd ../..返回上两级目录
/代表着根目录,是树形结构的最上层
.表示当前目录,也可以用./表示;(cd 默认就是这个)
…表示上一级目录,也可以用. ./表示;
…/是相对于当前路径而言的,或者说是前面的路径(而非后面文件的路径)比如脚本的那个例子
pwd
pwd(英文全拼:print work directory):显示目前的目录(绝对路径)
-P :显示出确实的路径,而非使用连结 (link) 路径。
mkdir
mkdir(英文全拼:make directory):创建一个新的目录
-m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~
-p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
mkdir -m 711 test1
mkdir -p /home/test/demo #会帮你创建三个目录 而不用一个一个创建
touch
如果文件不存在,则创建一个新的文件,如果文件已存在,则会修改文件的时间戳。
新建文件可以用touch命令 如touch a.java
虽然touch本来是用来改文件修改日期的
rmdir
这个一般用的比较少
rmdir(英文全拼:remove directory):删除一个空的目录
-p 选项用于递归删除空目录。
【例 1】
[root@localhost ~]#rmdir cangls
就这么简单,命令后面加目录名称即可,但命令执行成功与否,取决于要删除目录是否是空目录,因为 rmdir 命令只能删除空目录。
【例 2】
通过学习 mkdir 命令我们知道,使用 mkdir -p 可以实现递归建立目录,同样地,rmdir 命令可以使用 -p 选项递归删除目录。例如:
[root@localhost ~]# rmdir -p lm/movie/jp/cangls
注意,此方式先删除最低一层地目录(这里先删除 cangls),然后逐层删除上级目录,删除时也需要保证各级目录是空目录。
rm
rm(英文全拼:remove): 删除文件或目录
rm 是强大的删除命令,它可以永久性地删除文件系统中指定的文件或目录。在使用 rm 命令删除文件或目录时,系统不会产生任何提示信息。此命令的基本格式为:
[root@localhost ~]# rm[选项] 文件或目录
选项:
-f:强制删除(force),和 -i 选项相反,使用 -f,系统将不再询问,而是直接删除目标文件或目录。
-i:和 -f 正好相反,在删除文件或目录之前,系统会给出提示信息,使用 -i 可以有效防止不小心删除有用的文件或目录。默认是这个选项
-r:递归删除,主要用于删除目录,可删除指定目录及包含的所有内容,包括所有的子目录和文件。
注意,rm 命令是一个具有破坏性的命令,因为 rm 命令会永久性地删除文件或目录,这就意味着,如果没有对文件或目录进行备份,一旦使用 rm 命令将其删除,将无法恢复,因此,尤其在使用 rm 命令删除目录时,要慎之又慎。
强制删除。
如果要删除的目录中有 1 万个子目录或子文件,那么普通的 rm 删除最少需要确认 1 万次。所以,在真正删除文件的时候,我们会选择强制删除。例如:
[root@localhost ~]# mkdir -p /test/lm/movie/jp
\#重新建立测试目录
[root@localhost ~]# rm -rf /test
\#强制删除,一了百了
cp
cp(英文全拼:copy file): 复制文件或目录
cp [选项] 源文件 目标文件
-a:相当于 -d、-p、-r 选项的集合,这几个选项我们一一介绍;
-d:如果源文件为软链接(对硬链接无效),则复制出的目标文件也为软链接;
-i:询问,如果目标文件已经存在,则会询问是否覆盖;(默认带这个选项)
-l:把目标文件建立为源文件的硬链接文件,而不是复制源文件;
-s:把目标文件建立为源文件的软链接文件,而不是复制源文件;
-p:复制后目标文件保留源文件的属性(包括所有者、所属组、权限和时间);
-r:递归复制,用于复制目录;
-u:若目标文件比源文件有差异,则使用该选项可以更新目标文件,此选项可用于对文件的升级和备用。
#把源文件不改名复制到 /tmp/ 目录下
[root@localhost ~]# cp cangls /tmp/
#改名复制
[root@localhost ~]# cp cangls /tmp/bols
mv 移动与重命名
mv(英文全拼:move file): 移动文件与目录,或修改文件与目录的名称
移动文件:mv 文件名 移动目的地文件名
重命名文件:mv 文件名 修改后的文件名 如果源文件和目标文件在同一目录中,那就是改名。例如: mv bols lmls
-f:强制覆盖,如果目标文件已经存在,则不询问,直接强制覆盖;
-i:交互移动,如果目标文件已经存在,则询问用户是否覆盖(默认选项);
-n:如果目标文件已经存在,则不会覆盖移动,而且不询问用户;
-v:显示文件或目录的移动过程;
-u:若目标文件已经存在,但两者相比,源文件更新,则会对目标文件进行升级;
和 rm、cp 不同的是,mv 移动目录不需要加入 “-r” 选项
查找文件-find以及whereis、locate
find的命令比较复杂 下面几种格式讲的都是一个东西
find [paths] [expression,包含options] [actions]
find [path...] -options [-print / -ecex / -ok]
find path -option [ -print ] [ -exec -ok command ] {} \;
find <指定目录> <指定条件> <指定动作>
find 命令接受一个或多个路径(paths)作为搜索范围,并在该路径下递归地搜索。即检索完指定的目录后,还会对该目录下的子目录进行检索,以及子目录下的子目录……直到到达目录树底部。
默认情况下(不带任何搜索条件),find 命令会返回指定目录下的所有文件,所以常常需要通过特定的 expression 对结果进行筛选。
find 命令默认的 action 是将所有检索结果打印至标准输出。可以通过自定义 action ,让 find 命令对搜索到的结果执行特定的操作。
find还支持and or等逻辑查找符号

这里先不做详细解释,简单地测试下 find 命令:
实例
#如何查找一个文件大小超过5M的文件
find . -type f -size +100M
#如果知道一个文件名称,怎么查这个文件在linux下的哪个目录,
#如:要查找tnsnames.ora文件
find / -name tnsnames.ora
#output
#/opt/app/oracle/product/10.2/network/admin/tnsnames.ora
#/opt/app/oracle/product/10.2/network/admin/samples/tnsnames.ora
#查找小写字母开头的.c文件
find . -name ‘[a-z]*.c‘ -print #支持直接正则表达式
#搜索当前目录(含子目录,以下同)中,所有文件名以my开头的文件。
find . -name 'my*' (必须用引号括起来)
#搜索当前目录中,所有文件名以my开头的文件,并显示它们的详细信息。
$ find . -name 'my*' -ls
# 删除搜索结果
find directory -name file2 -delete
#按照文件特征查找
find / -amin -10 # 查找在系统中最后10分钟访问的文件(access time)
find / -atime -2 # 查找在系统中最后48小时访问的文件
find / -empty # 查找在系统中为空的文件或者文件夹
find / -group cat # 查找在系统中属于 group为cat的文件
find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件(modify time)
find / -mtime -1 #查找在系统中最后24小时里修改过的文件
find / -user fred #查找在系统中属于fred这个用户的文件
find / -size +10000c #查找出大于10000000字节的文件(c:字节,w:双字,k:KB,M:MB,G:GB)
find / -size -1000k #查找出小于1000KB的文件
有如下结构的示例目录 directory
$ tree directory
directory
├── file1
├── file2
├── sub-dir1
│ ├── file1
│ ├── file2
│ └── file3
└── sub-dir2
├── file2
└── sub-subdir1
└── file1
3 directories, 7 files
默认的 find 命令会列出该目录下的所有文件
复制代码
$ find directory
directory
directory/sub-dir1
directory/sub-dir1/file3
directory/sub-dir1/file2
directory/sub-dir1/file1
directory/file2
directory/sub-dir2
directory/sub-dir2/file2
directory/sub-dir2/sub-subdir1
directory/sub-dir2/sub-subdir1/file1
directory/file1
复制代码
为 find 命令指定 expression 以筛选出特定的文件
$ find directory -name file2
directory/sub-dir1/file2
directory/file2
directory/sub-dir2/file2
为 find 命令指定特殊的 action(此处 -delete 表示删除搜索结果)
复制代码
$ find directory -name file2 -delete
$ find directory
directory
directory/sub-dir1
directory/sub-dir1/file3
directory/sub-dir1/file1
directory/sub-dir2
directory/sub-dir2/sub-subdir1
directory/sub-dir2/sub-subdir1/file1
directory/file1
复制代码
二、搜索条件(expression)
- 根据文件名检索
find 命令中的 -name 选项可以根据文件名称进行检索(区分大小写)。如需要忽略文件名中的大小写,可以使用 -iname 选项。
-name 和 -iname 两个选项都支持 wildcards 。如:
? 可以表示任意一个单一的符号
- 可以表示任意数量(包括 0)的未知符号
find /usr -name ‘*.txt’ 查找 /usr 目录下所有文件名以 .txt 结尾的文件
find /usr -name ‘???’ 查找 /usr 目录下所有文件名刚好为 4 个字符的文件
有些时候,你需要在搜索时匹配某个文件或目录的完整路径,而不仅仅是匹配文件名。可以使用 -path 或 -ipath 选项。
如查找 /usr 下所有文件名以 .txt 结尾的文件或目录,且该文件的父目录必须是 src。可以使用以下命令:
find /usr -path ‘/src/.txt’
- 根据文件类型检索
如果只想搜索得到文件或目录,即不想它们同时出现在结果中。可以使用 -type 选项指定文件类型。
-type 选项最常用的参数如下:
f: 文件
d: 目录
l: 符号链接
find /usr -type d -name ‘python*’ 检索 /usr 下所有文件名以 python 开头的目录
- 检索空文件
find 命令支持 -empty 选项用来检索为空的文件或目录。空文件即文件里没有任何内容,空目录即目录中没有任何文件或子目录。
find ~ -type d -empty 检索用户主目录下所有的空目录
- 反义匹配
find 命令也允许用户对当前的匹配条件进行“反义”(类似于逻辑非操作)。
如需要检索 /usr 下所有文件名不以 .txt 为后缀的文件。可以使用以下命令:
find /usr -type f ! -name ‘*.txt’
也可以“翻转”任何其他的筛选条件,如:
find /usr -type f ! -empty 检索 /usr 下所有内容不为空的文件
- 根据文件的所属权检索
为了检索归属于特定用户的文件或目录,可以使用 -user 选项。
find / -type f -user starky 检索根目录下所有属主为 starky 的文件
类似于 -user选项,-group 选项则可以根据文件或目录的属组进行检索。
- 根据时间日期进行检索
有些时候,需要根据文件创建或修改的时间进行检索。
Linux 系统中,与文件相关联的时间参数有以下三种:
修改时间(Modification time):最后一次文件内容有过更改的时间点
访问时间(Access time):最后一次文件有被读取过的时间点
变更时间(Change time):最后一次文件有被变更过的时间点(如内容被修改,或权限等 metadata 被修改)
与此对应的是 find 命令中的 -mtime,-atime 和 -ctime 三个选项。
这三个选项的使用遵循以下示例中的规则:
-mtime 2:该文件 2 天前被修改过
-mtime -2:该文件 2 天以内被修改过
-mtime +2:该文件距离上次修改已经超过 2 天时间
find /usr -type f -mtime 2 检索 /usr 下两天前被修改过的文件
如果觉得 -mtime 等选项以天为单位时间有点长,还可以使用 -mmin,-amin,-cmin 三个选项:
find /usr -type f -mtime +50 -mtime -100 检索 /usr 下 50 到 100 天之前修改过的文件
find /usr -type f -mtime 2 -amin 5 检索 /usr 下两天前被修改过且 5 分钟前又读取过的文件
- 根据文件大小检索
-size 选项允许用户通过文件大小进行搜索(只适用于文件,目录没有大小……)。
表示文件大小的单位由以下字符组成:
c:字节
k:Kb
M:Mb
G:Gb
另外,还可以使用 + 或 - 符号表示大于或小于当前条件。
find / -size +1G 检索文件大小高于 1 GB 的文件
- 根据文件权限检索
find 命令可以使用 -perm 选项以文件权限为依据进行搜索。
使用符号形式
如需要检索 /usr 目录下权限为 rwxr-xr-x 的文件,可以使用以下命令:
find /usr -perm u=rwx,g=rx,o=rx
搜索 /usr 目录下所有权限为 r-xr-xr-x(即系统中的所有用户都只有读写权限)的文件和目录,可以使用以下命令:
find /usr -perm a=rx
很多时候,我们只想匹配文件权限的一个子集。比如,检索可以直接被任何用户执行的文件,即只关心文件的执行权限,而不用管其读写权限是什么。
上述的需求可以通过以下命令实现:find / -type f -perm /a=x
其中 a=x 前面的 / 符号即用来表示只匹配权限的某个子集(执行权限),而不用关心其他权限的具体设置。
使用数字形式
-perm 选项也支持数字形式的文件权限标记。
find /usr -perm 644 搜索 /usr 目录下权限为 644(即 rwxr-xr-x)的文件
- 限制遍历的层数
find 命令默认是以递归的方式检索项目的,这有时候会导致得到的结果数量非常巨大。可以使用 -maxdepth 限制 find 命令递归的层数。
find / -maxdepth 3 搜索时向下递归的层数最大为 3
- 逻辑组合
在之前的例子中有出现多个搜索条件的组合以及对某个搜索条件的反转。
实际上 find 命令支持 “and” 和 “or” 两种逻辑运算,对应的命令选项分别是 -a 和 -o。通过这两个选项可以对搜索条件进行更复杂的组合。
此外还可以使用小括号对搜索条件进行分组。注意 find 命令中的小括号常需要用单引号包裹起来。因小括号在 Shell 中有特殊的含义。
如检索 /usr 下文件名以 python 开头且类型为目录的文件
find /usr -type d -name ‘python*’
该命令等同于:
find /usr -type d -a -name ‘python*’
更复杂的组合形式如:
find / ‘(’ -mmin -5 -o -mtime +50 ‘)’ -a -type f
三、对搜索结果执行命令
- 删除文件
-delete 选项可以用来删除搜索到的文件和目录。
如删除 home 目录下所有的空目录:
find ~ -type d -empty -delete
- 执行自定义命令
-exec 选项可以对搜索到的结果执行特定的命令。
如需要将 home 目录下所有的 MP3 音频文件复制到移动存储设备(假设路径是 /media/MyDrive),可使用下面的命令:
find ~ -type f -name ‘*.mp3’ -exec cp {} /media/MyDrive ‘;’
其中的大括号({})作为检索到的文件的 占位符 ,而分号( ;)作为命令结束的标志。因为分号是 Shell 中有特殊含义的符号,所以需要使用单引号括起来。
每当 find 命令检索到一个符合条件的文件,会使用其完整路径取代命令中的 {},然后执行 -exec 后面的命令一次。
另一个很重要的用法是,在多个文件中检索某个指定的字符串。
如在用户主目录下的所有文件中检索字符串 hello ,可以使用如下命令:
find ~ -type f -exec grep -l hello {} ‘;’
-exec 选项中的 + 符号
创建 Gzip 格式的压缩文件的命令为:tar -czvf filename.tar.gz
现在假设需要将用户主目录下所有的 MP3 文件添加到压缩包 music.tar.gz 中,直观的感觉是,其命令应为如下形式:
find ~ -type f -name ‘*.mp3’ -exec tar -czvf music.tar.gz {} ‘;’
实际情况是,这样得到的 music.tar.gz 其实只包含一个 MP3 文件。
原因是 find 命令每次发现一个音频文件,都会再执行一次 -exec 选项后面的压缩命令。导致先前生成的压缩包被覆盖。
可以先让 find 命令检索出所有符合条件的音频文件,再将得到的文件列表传递给后面的压缩命令。完整的命令如下:
find ~ -type f -name ‘*.mp3’ -exec tar -czvf music.tar.gz {} +
显示文件信息
如果想浏览搜索到的文件(目录)的详细信息(如权限和大小等),可以直接使用 -ls 选项。
find / -type file -size +1G -ls 浏览所有 1G 以上大小的文件的详细信息
还可以通过locate、whereis查找
locate tnsnames.ora
#该指令会在特定目录中查找符合条件的文件。
#这些文件应属于原始代码、二进制文件,或是帮助文件。
whereis nginx
压缩
简而言之
常用的压缩命令
zip:压缩zip文件命令,比如zip test.zip 文件可以把文件压缩成zip文件,如果压缩目录的话则需添加-r选项。
unzip:与zip对应,解压zip文件命令。unzip xxx.zip直接解压,还可以通过-d选项指定解压目录。
图片
gzip:用于压缩.gz后缀文件,gzip命令不能打包目录。需要注意的是直接使用gzip 文件名源文件会消失,如果要保留源文件,可以使用gzip -c 文件名 > xx.gz,解压缩直接使用gzip -d xx.gz
tar:tar常用几个选项,-x解打包,-c打包,-f指定压缩包文件名,-v显示打包文件过程,一般常用tar -cvf xx.tar 文件来打包,解压则使用tar -xvf xx.tar。
Linux的打包和压缩是分开的操作,如果要打包并且压缩的话,按照前面的做法必须先用tar打包,然后再用gzip压缩。当然,还有更好的做法就是-z命令,打包并且压缩。
使用命令tar -zcvf xx.tar.gz 文件来打包压缩,使用命令tar -zxvf xx.tar.gz来解压缩
介绍
归档,也称为打包,指的是一个文件或目录的集合,而这个集合被存储在一个文件中。归档文件没有经过压缩,因此,它占用的空间是其中所有文件和目录的总和。
通常,归档总是会和系统(数据)备份联系在一起,不过,有关数据备份的内容,留到后续章节讲,本章仅学习归档命令的基本使用。
和归档文件类似,压缩文件也是一个文件和目录的集合,且这个集合也被存储在一个文件中,但它们的不同之处在于,压缩文件采用了不同的存储方式,使其所占用的磁盘空间比集合中所有文件大小的总和要小。
压缩是指利用算法将文件进行处理,已达到保留最大文件信息,而让文件体积变小的目的。其基本原理为,通过查找文件内的重复字节,建立一个相同字节的词典文件,并用一个代码表示。比如说,在压缩文件中,有不止一处出现了 “C语言中文网”,那么,在压缩文件时,这个词就会用一个代码表示并写入词典文件,这样就可以实现缩小文件体积的目的。
由于计算机处理的信息是以二进制的形式表示的,因此,压缩软件就是把二进制信息中相同的字符串以特殊字符标记,只要通过合理的数学计算,文件的体积就能够被大大压缩。把一个或者多个文件用压缩软件进行压缩,形成一个文件压缩包,既可以节省存储空间,有方便在网络上传送。
如果你能够理解文件压缩的基本原理,那么很容易就能想到,对文件进行压缩,很可能损坏文件中的内容,因此,压缩又可以分为有损压缩和无损压缩。无损压缩很好理解,指的是压缩数据必须准确无误;有损压缩指的是即便丢失个别的数据,对文件也不会造成太大的影响。有损压缩广泛应用于动画、声音和图像文件中,典型代表就是影碟文件格式 mpeg、音乐文件格式 mp3 以及图像文件格式 jpg。
采用压缩工具对文件进行压缩,生成的文件称为压缩包,该文件的体积通常只有原文件的一半甚至更小。需要注意的是,压缩包中的数据无法直接使用,使用前需要利用压缩工具将文件数据还原,此过程又称解压缩。
Linux 下,常用归档命令有 2 个,分别是 tar 和 dd(相对而言,tar 的使用更为广泛);常用的压缩命令有很多,比如 gzip、zip、bzip2 等。这些命令的详细用法,后续文件会做一一介绍。
tar 打包、解包、压缩为gzip
Linux 系统中,最常用的归档(打包)命令就是 tar,该命令可以将许多文件一起保存到一个单独的磁带或磁盘中进行归档。不仅如此,该命令还可以从归档文件中还原所需文件,也就是打包的反过程,称为解打包。
使用 tar 命令归档的包通常称为 tar 包(tar 包文件都是以“.tar”结尾的)。
tar [选项] 源文件或目录
此命令常用的选项及各自的含义如表 1 所示。
| 选项 | 含义 |
|---|---|
| -c | 将多个文件或目录进行打包。 |
| -A | 追加 tar 文件到归档文件。 |
| -f | 包名 指定包的文件名。包的扩展名是用来给管理员识别格式的,所以一定要正确指定扩展名; |
| -v | 显示打包文件过程; |
需要注意的是,在使用 tar 命令指定选项时可以不在选项前面输入“-”。例如,使用“cvf”选项和 “-cvf”起到的作用一样。
下面给大家举几个例子,一起看看如何使用 tar 命令打包文件和目录。
【例 1】打包文件和目录。
#选项 "-cvf" 一般是习惯用法,记住打包时需要指定打包之后的文件名,而且要用 ".tar" 作为扩展名。
#打包目录也是如此:
[root@localhost ~]# tar -cvf test.txt.tar test.txt #命令后是参数 然后是要打包的文件
#test是我们之前的测试目录 把目录打包为test.tar文件
[root@localhost ~]# tar -cvf test.tar test/
test/
test/test3
test/test2
test/test1
#tar命令也可以打包多个文件或目录,只要用空格分开即可。例如:
#把anaconda-ks.cfg文件和/tmp目录打包成ana.tar文件包
[root@localhost ~]# tar -cvf ana.tar anaconda-ks.cfg /tmp/
【例 2】打包并压缩目录。
首先声明一点,压缩命令不能直接压缩目录,必须先用 tar 命令将目录打包,然后才能用 gzip 命令或 bzip2 命令对打包文件进行压缩。
再强调一下,gzip 命令只能用来压缩文件,不能压缩目录,即便指定了目录,也只能压缩目录内的所有文件。
例如:
[root@localhost ~]#ll -d test test.tar
drwxr-xr-x 2 root root 4096 6月 17 21:09 test
-rw-r--r-- 1 root root 10240 6月 18 01:06 test.tar
\#我们之前已经把test目录打包成test.tar文件
[root@localhost ~]# gzip test.tar
[root@localhost ~]# ll test.tar.gz
-rw-r--r-- 1 root root 176 6月 18 01:06 test.tar.gz
\#gzip命令会把test.tar压缩成test.tar.gz
tar命令做解打包操作
当 tar 命令用于对 tar 包做解打包操作时,该命令的基本格式如下:
[root@localhost ~]#tar [选项] 压缩包
当用于解打包时,常用的选项与含义如表 2 所示。
选项 含义
-x 对 tar 包做解打包操作。
-f 指定要解压的 tar 包的包名。
-t 只查看 tar 包中有哪些文件或目录,不对 tar 包做解打包操作。
-C 目录 指定解打包位置。
-v 显示解打包的具体过程。
其实解打包和打包相比,只是把打包选项 “-cvf” 更换为 “-xvf”。我们来试试:
[root@localhost ~]# tar -xvf anaconda-ks.cfg. tar
#解打包到当前目录下
如果使用 “-xvf” 选项,则会把包中的文件解压到当前目录下。如果想要指定解压位置,则需要使用 “-C(大写)” 选项。例如:
[root@localhost ~]# tar -xvf test.tar -C /tmp
#把文件包test.tar解打包到/tmp/目录下
如果只想查看文件包中有哪些文件,则可以把解打包选项 “-x” 更换为测试选项 “-t”。例如:
[root@localhost ~]# tar -tvf test.tar
drwxr-xr-x root/root 0 2016-06-17 21:09 test/
-rw-r-r- root/root 0 2016-06-17 17:51 test/test3
-rw-r-r- root/root 0 2016-06-17 17:51 test/test2
-rw-r-r- root/root 0 2016-06-17 17:51 test/test1
#会用长格式显示test.tar文件包中文件的详细信息
tar命令做打包压缩(解压缩解打包)操作
你可能会觉得 Linux 实在太不智能了,一个打包压缩,居然还要先打包成 “.tar” 格式,再压缩成 “.tar.gz” 或 “.tar.bz2” 格式。其实 tar 命令是可以同时打包压缩的,前面的讲解之所打包和压缩分开,是为了让大家了解在 Linux 中打包和压缩的不同。
当 tar 命令同时做打包压缩的操作时,其基本格式如下:
[root@localhost ~]#tar [选项] 压缩包 源文件或目录
此处常用的选项有以下 2 个,分别是:
-z:压缩和解压缩 “.tar.gz” 格式;
-j:压缩和解压缩 ".tar.bz2"格式。
【例 1】压缩与解压缩 ".tar.gz"格式。
[root@localhost ~]# tar -zcvf tmp.tar.gz /tmp/
#把/temp/目录直接打包压缩为".tar.gz"格式,通过"-z"来识别格式,"-cvf"和打包选项一致
解压缩也只是在解打包选项 “-xvf” 前面加了一个 “-z” 选项。
[root@localhost ~]# tar -zxvf tmp.tar.gz
#解压缩与解打包".tar.gz"格式
前面讲的选项 “-C” 用于指定解压位置、“-t” 用于查看压缩包内容,在这里同样适用。
【例 2】压缩与解压缩 “.tar.bz2” 格式。
和".tar.gz"格式唯一的不同就是"-zcvf"选项换成了 “-jcvf”,如下所示:
[root@localhost ~]# tar -jcvf tmp.tar.bz2 /tmp/
#打包压缩为".tar.bz2"格式,注意压缩包文件名
[root@localhost ~]# tar -jxvf tmp.tar.bz2
#解压缩与解打包".tar.bz2"格式
把文件直接压缩成".tar.gz"和".tar.bz2"格式,才是 Linux 中最常用的压缩方式,这是大家一定要掌握的压缩和解压缩方法。
tar 命令最初被用来在磁带上创建备份,现在可以在任何设备上创建备份。利用 tar 命令可以把一大堆的文件和目录打包成一个文件,这对于备份文件或是将几个文件组合成为一个文件进行网络传输是非常有用的。
解压gzip看https://developer.aliyun.com/article/910157?spm=a2c6h.13262185.profile.35.4a975082rdjfhs
zip 与 unzip
我们经常会在 Windows 系统上使用 “.zip”格式压缩文件,其实“.zip”格式文件是 Windows 和 Linux 系统都通用的压缩文件类型,属于几种主流的压缩格式(zip、rar等)之一,是一种相当简单的分别压缩每个文件的存储格式,
本节要讲的 zip 命令,类似于 Windows 系统中的 winzip 压缩程序,其基本格式如下:
[root@localhost ~]#zip [选项] 压缩包名 源文件或源目录列表
注意,zip 压缩命令需要手工指定压缩之后的压缩包名,注意写清楚扩展名,以便解压缩时使用。
该命令常用的几个选项及各自的含义如表 1 所示。
选项 含义
-r 递归压缩目录,及将制定目录下的所有文件以及子目录全部压缩。
-m 将文件压缩之后,删除原始文件,相当于把文件移到压缩文件中。
-v 显示详细的压缩过程信息。
-q 在压缩的时候不显示命令的执行过程。
-压缩级别 压缩级别是从 1~9 的数字,-1 代表压缩速度更快,-9 代表压缩效果更好。
-u 更新压缩文件,即往压缩文件中添加新文件。
下面给大家举几个例子。
【例 1】zip 命令的基本使用。
[root@localhost ~]# zip ana.zip anaconda-ks.cfg
adding: anaconda-ks.cfg (deflated 37%)
#压缩
[root@localhost ~]# ll ana.zip
-rw-r–r-- 1 root root 935 6月 1716:00 ana.zip
#压缩文件生成
不仅如此,所有的压缩命令都可以同时压缩多个文件,例如:
[root@localhost ~]# zip test.zip install.log install.log.syslog
adding: install.log (deflated 72%)
adding: install.log.syslog (deflated 85%)
#同时压缩多个文件到test.zip压缩包中
[root@localhost ~]#ll test.zip
-rw-r–r-- 1 root root 8368 6月 1716:03 test.zip
#压缩文件生成
【例 2】使用 zip 命令压缩目录,需要使用“-r”选项,例如:
[root@localhost ~]# mkdir dir1
#建立测试目录
[root@localhost ~]# zip -r dir1.zip dir1
adding: dir1/(stored 0%)
#压缩目录
[root@localhost ~]# ls -dl dir1.zip
-rw-r–r-- 1 root root 160 6月 1716:22 dir1.zip
#压缩文件生成
unzip 命令可以查看和解压缩 zip 文件。该命令的基本格式如下:
[root@localhost ~]# unzip [选项] 压缩包名
此命令常用的选项以及各自的含义如表 1 所示。
选项 含义
-d 目录名 将压缩文件解压到指定目录下。
-n 解压时并不覆盖已经存在的文件。
-o 解压时覆盖已经存在的文件,并且无需用户确认。
-v 查看压缩文件的详细信息,包括压缩文件中包含的文件大小、文件名以及压缩比等,但并不做解压操作。
-t 测试压缩文件有无损坏,但并不解压。
-x 文件列表 解压文件,但不包含文件列表中指定的文件。
【例 1】不论是文件压缩包,还是目录压缩包,都可以直接解压缩,例如:
[root@localhost ~]# unzip dir1.zip
Archive: dir1.zip
creating: dirl/
#解压缩
【例 2】使用 -d 选项手动指定解压缩位置,例如:
[root@localhost ~]# unzip -d /tmp/ ana.zip
Archive: ana.zip
inflating: /tmp/anaconda-ks.cfg
#把压缩包解压到指定位置
文件名自动补全
tab一次匹配 和tab两次显示全部
另外,Shell 还有一套被称作通配符的转用符号(如表 1 所示),这些通配符可以搜索并匹配文件名的一部分,从而大大简化了文件名的输入。
符号 作用
- 匹配任意数量的字符。
? 匹配任意一个字符。
[] 匹配括号内的任意一个字符,甚至 [] 中还可以包含用 -(短横线)连接的字符或数字,表示一定范围内的字符或数字。
系统管理
系统资源的使用情况(vmstat命令)
查看开机信息(dmesg命令)
查看内存使用状态(free命令)
分析系统性能(sar命令)
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。
sar 命令的基本格式如下:
[root@localhost ~]# sar [options] [-o filename] interval [count]
此命令格式中,各个参数的含义如下:
-o filename:其中,filename 为文件名,此选项表示将命令结果以二进制格式存放在文件中;
interval:表示采样间隔时间,该参数必须手动设置;
count:表示采样次数,是可选参数,其默认值为 1;
options:为命令行选项,由于 sar 命令提供的选项很多,这里不再一一介绍,仅列举出常用的一些选项及对应的功能,如表 1 所示。
sar命令选项 功能
-A 显示系统所有资源设备(CPU、内存、磁盘)的运行状况。
-u 显示系统所有 CPU 在采样时间内的负载状态。
-P 显示当前系统中指定 CPU 的使用情况。
-d 显示系统所有硬盘设备在采样时间内的使用状态。
-r 显示系统内存在采样时间内的使用情况。
-b 显示缓冲区在采样时间内的使用情况。
-v 显示 inode 节点、文件和其他内核表的统计信息。
-n 显示网络运行状态,此选项后可跟 DEV(显示网络接口信息)、EDEV(显示网络错误的统计数据)、SOCK(显示套接字信息)和 FULL(等同于使用 DEV、EDEV和SOCK)等,有关更多的选项,可通过执行 man sar 命令查看。
-q 显示运行列表中的进程数、进程大小、系统平均负载等。
-R 显示进程在采样时的活动情况。
-y 显示终端设备在采样时间的活动情况。
-w 显示系统交换活动在采样时间内的状态。
有关 sar 命令更多可用的选项及功能,可通过执行 man sar 命令查看。
【例 1】
如果想要查看系统 CPU 的整理负载状况,每 3 秒统计一次,统计 5 次,可以执行如下命令:
[root@localhost ~]# sar -u 3 5
Linux 2.6.32-431.el6.x86_64 (localhost) 10/25/2019 x86_64 (1 CPU)
06:18:23 AM CPU %user %nice %system %iowait %steal %idle
06:18:26 AM all 12.11 0.00 2.77 3.11 0.00 82.01
06:18:29 AM all 6.55 0.00 2.07 0.00 0.00 91.38
06:18:32 AM all 6.60 0.00 2.08 0.00 0.00 91.32
06:18:35 AM all 10.21 0.00 1.76 0.00 0.00 88.03
06:18:38 AM all 8.71 0.00 1.74 0.00 0.00 89.55
Average: all 8.83 0.00 2.09 0.63 0.00 88.46
此输出结果中,各个列表项的含义分别如下:
%user:用于表示用户模式下消耗的 CPU 时间的比例;
%nice:通过 nice 改变了进程调度优先级的进程,在用户模式下消耗的 CPU 时间的比例;
%system:系统模式下消耗的 CPU 时间的比例;
%iowait:CPU 等待磁盘 I/O 导致空闲状态消耗的时间比例;
%steal:利用 Xen 等操作系统虚拟化技术,等待其它虚拟 CPU 计算占用的时间比例;
%idle:CPU 空闲时间比例。
【例 2】
如果想要查看系统磁盘的读写性能,可执行如下命令:
[root@localhost ~]# sar -d 3 5
Linux 2.6.32-431.el6.x86_64 (localhost) 10/25/2019 x86_64 (1 CPU)
06:36:52 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:36:55 AM dev8-0 3.38 0.00 502.26 148.44 0.08 24.11 4.56 1.54
06:36:55 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:36:58 AM dev8-0 1.49 0.00 29.85 20.00 0.00 1.75 0.75 0.11
06:36:58 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:37:01 AM dev8-0 68.26 6.96 53982.61 790.93 3.22 47.23 3.54 24.17
06:37:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:37:04 AM dev8-0 111.69 3961.29 154.84 36.85 1.05 9.42 3.44 38.43
06:37:04 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:37:07 AM dev8-0 1.67 136.00 2.67 83.20 0.01 6.20 6.00 1.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 34.45 781.10 9601.22 301.36 0.78 22.74 3.50 12.07
此输出结果中,各个列表头的含义如下:
tps:每秒从物理磁盘 I/O 的次数。注意,多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的;
rd_sec/s:每秒读扇区的次数;
wr_sec/s:每秒写扇区的次数;
avgrq-sz:平均每次设备 I/O 操作的数据大小(扇区);
avgqu-sz:磁盘请求队列的平均长度;
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1 秒=1000 毫秒);
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间;
%util:I/O 请求占 CPU 的百分比,比率越大,说明越饱和。
除此之外,如果想要查看系统内存使用情况,可以执行sar -r 5 3命令;如果要想查看网络运行状态,可执行sar -n DEV 5 3命令,等等。有关其它参数的用法,这里不再给出具体实例,有兴趣的读者可自行测试,观察运行结果。
Linux如何查看CPU运行状态?
2022-05-07 170举报
简介: CPU 是影响 Linux 性能的主要因素之一,本节将介绍几个可以用来查看 CPU 性能的命令。
CPU 是影响 Linux 性能的主要因素之一,本节将介绍几个可以用来查看 CPU 性能的命令。
Linux CPU 性能分析:vmstat 命令
vmstat 命令可以显示关于系统各种资源之间相关性能的简要信息,在 《Linux vmstat 命令》一节中,我们已经对此命令的基本格式和用法做了详细的介绍,因此不再赘述,这里主要用它来看 CPU 的一个负载情况。
下面是 vmstat 命令在当前测试系统中的输出结果:
[root@localhost ~]# vmstat 2 3
procs -----------memory---------- —swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 8 247512 39660 394168 0 0 31 8 86 269 0 1 98 1 0
0 0 8 247480 39660 394172 0 0 0 0 96 147 4 0 96 0 0
0 0 8 247484 39660 394172 0 0 0 66 95 141 2 2 96 0 0
通过分析 vmstat 命令的执行结果,可以获得一些与当前 Linux 运行性能相关的信息。比如说:
r 列表示运行和等待 CPU 时间片的进程数,如果这个值长期大于系统 CPU 的个数,就说明 CPU 不足,需要增加 CPU。
swpd 列表示切换到内存交换区的内存数量(以 kB 为单位)。如果 swpd 的值不为 0,或者比较大,而且 si、so 的值长期为 0,那么这种情况下一般不用担心,不用影响系统性能。
cache 列表示缓存的内存数量,一般作为文件系统缓存,频繁访问的文件都会被缓存。如果缓存值较大,就说明缓存的文件数较多,如果此时 I/O 中 bi 比较小,就表明文件系统效率比较好。
一般情况下,si(数据由硬盘调入内存)、so(数据由内存调入硬盘) 的值都为 0,如果 si、so 的值长期不为 0,则表示系统内存不足,需要增加系统内存。
如果 bi+bo 的参考值为 1000 甚至超过 1000,而且 wa 值较大,则表示系统磁盘 I/O 有问题,应该考虑提高磁盘的读写性能。
输出结果中,CPU 项显示了 CPU 的使用状态,其中当 us 列的值较高时,说明用户进程消耗的 CPU 时间多,如果其长期大于 50%,就需要考虑优化程序或算法;sy 列的值较高时,说明内核消耗的 CPU 资源较多。通常情况下,us+sy 的参考值为 80%,如果其值大于 80%,则表明可能存在 CPU 资源不足的情况。
总的来说,vmstat 命令的输出结果中,我们应该重点注意 procs 项中 r 列的值,以及 CPU 项中 us 列、sy 列和 id 列的值。
Linux CPU 性能分析:sar 命令
除了 vmstat 命令,sar 命令也可以用来检查 CPU 性能,它可以对系统的每个方面进行单独的统计。
注意,虽然使用 sar 命令会增加系统开销,不过这些开销是可以评估的,不会对系统性能的统计结果产生很大影响。和 vmstat 命令一样,sar 命令的基本格式和用法已经在 《Linux sar 命令》一节中做了详细的介绍,接下来直接学习如何使用 sar 命令查看 CPU 性能。
下面是 sar 命令对当前测试系统的 CPU 统计输出结果:
[root@localhost ~]# sar -u 3 5
Linux 2.6.32-431.el6.x86_64 (localhost) 10/28/2019 x86_64 (8 CPU)
04:02:46 AM CPU %user %nice %system %iowait %steal %idle
04:02:49 AM all 1.69 0.00 2.03 0.00 0.00 96.27
04:02:52 AM all 1.68 0.00 0.67 0.34 0.00 97.31
04:02:55 AM all 2.36 0.00 1.69 0.00 0.00 95.95
04:02:58 AM all 0.00 0.00 1.68 0.00 0.00 98.32
04:03:01 AM all 0.33 0.00 0.67 0.00 0.00 99.00
Average: all 1.21 0.00 1.35 0.07 0.00 97.37
此输出结果统计的是系统中包含的 8 颗 CPU 的整体运行状况,每项的输出都非常直观,其中最后一行(Average)是汇总行,是对上面统计信息的一个平均值。
需要指出的是,sar 输出结果中第一行包含了 sar 命令本身的统计消耗,因此 %user 列的值会偏高一点,但这并不会对统计结果产生很大影响。
另外,在一个多 CPU 的系统中,如果程序使用了单线程,就会出现“CPU 整体利用率不高,但系统应用响应慢”的现象,造成此现象的原因在于,单线程只使用一个 CPU,该 CPU 占用率为 100%,无法处理其他请求,但除此之外的其他 CPU 却处于闲置状态,进而整体 CPU 使用率并不高。
针对这个问题,可以使用 sar 命令单独查看系统中每个 CPU 的运行状态,例如:
[root@localhost ~]# sar -P 0 3 5
Linux 2.6.32-431.el6.x86_64 (localhost) 10/28/2019 x86_64 (8 CPU)
04:44:57 AM CPU %user %nice %system %iowait %steal %idle
04:45:00 AM 0 8.93 0.00 1.37 0.00 0.00 89.69
04:45:03 AM 0 6.83 0.00 1.02 0.00 0.00 92.15
04:45:06 AM 0 0.67 0.00 0.33 0.33 0.00 98.66
04:45:09 AM 0 0.67 0.00 0.33 0.00 0.00 99.00
04:45:12 AM 0 2.38 0.00 0.34 0.00 0.00 97.28
Average: 0 3.86 0.00 0.68 0.07 0.00 95.39
注意,sar 命令对系统中 CPU 的计数是从数字 0 开始的,因此上面执行的命令表示对系统中第一颗 CPU 的运行状态进行统计。如果想单独统计系统中第 5 颗 CPU 的运行状态,可以执行 sar -P 4 3 5 命令。
Linux CPU 性能分析:iostat 命令
iostat 命令主要用于统计磁盘 I/O 状态,但也能用来查看 CPU 的使用情况,只不过使用此命令仅能显示系统所有 CPU 的平均状态,无法向 sar 命令那样做具体分析。
使用 iostat 命令查看 CPU 运行状态,需要使用该命令提供的 -c 选项,该选项的作用是仅显示系统 CPU 的运行情况。例如:
[root@localhost ~]# iostat -c
Linux 2.6.32-431.el6.x86_64 (localhost) 10/28/2019 x86_64 (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.07 0.00 0.12 0.09 0.00 99.71
可以看到,此输出结果中包含的项和 sar 命令的输出项完全相同。
有关 iostat 命令的基本用法,由于不是本节重点,因为不再详细介绍。
Linux CPU 性能分析:uptime 命令
uptime 命令是监控系统性能最常用的一个命令,主要用来统计系统当前的运行状况。例如:
[root@localhost ~]# uptime
05:38:26 up 1:47, 2 users, load average: 0.12, 0.08, 0.08
该命令的输出结果中,各个数据所代表的含义依次是:系统当前时间、系统运行时长、当前登陆系统的用户数量、系统分别在 1 分钟、5 分钟和 15 分钟内的平均负载。
这里需要注意的是,load average 这 3 个输出值一般不能大于系统 CPU 的个数。例如,本测试系统有 8 个 CPU,如果 load average 中这 3 个值长期大于 8,就说明 CPU 很繁忙,负载很高,系统性能可能会受到影响;如果偶尔大于 8 则不用担心,系统性能一般不会受到影响;如果这 3 个值小于 CPU 的个数(如本例所示),则表示 CPU 是非常空闲的。
总的来说,本节介绍了 4 个可查看 CPU 性能的命令,但这些命令也仅能查看 CPU 是否繁忙、负载是否过大,无法知道造成这种现象的根本原因。因此,在明确判断出系统 CPU 出现问题之后,还要结合 top、ps 等命令,进一步检查出是哪些进程造成的。
另外要知道的是,引发 CPU 资源紧张的原因有多个,可能是应用程序不合理造成的,也可能是硬件资源匮乏引起的。因此,要学会具体问题具体分析,或者优化应用程序,或者增加系统 CPU 资源。
如何查看内存的使用情况?
2022-05-07 138举报
简介: 本节将介绍几个系统命令,通过它们,可以快速查看 Linux 系统中内存的使用状况。
内存的管理和优化,是 Linux 系统性能优化的重要组成部分,换句话说,内存资源是否充足,会直接影响应用系统(包含操作系统和应用程序)的使用性能。
本节将介绍几个系统命令,通过它们,可以快速查看 Linux 系统中内存的使用状况。
Linux 查看内存使用情况:free 命令
free 是监控 Linux 内存使用状况最常用的命令之一,有关该命令的基本用法,已经在《Linux free 命令》一节中做了详细介绍,所以不再赘述,这里重点给大家讲解如何使用 free 命令查看系统内存的使用情况。
下面是 free 命令在当前测试系统中的输出结果:
[root@localhost ~]# free -m
total used free shared buffers cached
Mem: 2004 573 1431 0 47 201
-/+ buffers/cache: 323 1680
Swap: 1983 0 1983
从输出结果可以看到,该系统共 2GB 内存,其中系统空闲内存还有 1431MB,并且 swap 交换分区还未使用,因此可以判断出当前系统的内存资源还非常充足。
除此之外,free 命令还可以实时地监控内存的使用状况,通过使用 -s 选项,可以实现在指定的时间段内不间断地监控内存的使用情况。
例如:
[root@localhost ~]# free -m -s 5
total used free shared buffers cached
Mem: 2004 571 1433 0 47 202
-/+ buffers/cache: 321 1683
Swap: 1983 0 1983
total used free shared buffers cached
Mem: 2004 571 1433 0 47 202
-/+ buffers/cache: 321 1683
Swap: 1983 0 1983
#省略后续输出
要想实现动态地监控内存使用状况,除了使用 free 命令提供的 -s 选项,还可以借助 watch 命令。通过给 watch 命令后面添加需要运行的命令,watch 就会自行重复去运行这个命令(默认 2 秒执行一次),例如:
[root@localhost ~]# watch -n 3 -d free
Every 3.0s: free Tue Oct 29 03:05:43 2019
total used free shared buffers cached
Mem: 2052988 586504 1466484 0 49184 207360
-/+ buffers/cache: 329960 1723028
Swap: 2031608 0 2031608
上面执行的命令中,-n 选项用于执行重复执行的间隔时间,-d 选项用于在显示数据时,高亮显示变动了的数据。
Linux 查看内存使用情况:vmstat 命令
vmstat 命令在监控系统内存方面的功能很强大,有关此命令的基本用法,已经在《Linux vmstat 命令》一节中做了详细介绍,这里重点讲解如何使用此命令查看内存的使用状况。
下面是执行 vmstat 命令的输出结果:
[root@localhost ~]# vmstat 2 3
procs -----------memory---------- —swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 1436128 53004 210744 0 0 7 0 13 14 0 0 100 0 0
1 0 0 1436112 53004 210744 0 0 0 0 128 226 0 0 100 0 0
0 0 0 1435988 53004 210744 0 0 0 0 144 220 1 0 99 0 0
对于内存的监控,我们只需要重点关注 swpd、si 和 so 这 3 列。从此输出结果可以看出,当前系统中,虚拟内存没有使用,硬盘和内存之间没有交换数据,可见内存资源处于空闲状态。
Linux 查看内存使用情况:sar 命令
sar 命令也可以用来监控 Linux 的内存使用状况,通过“sar -r”组合可以查看系统内存和交换空间的使用率。
如下是执行“sar -r”命令的输出结果:
[root@localhost ~]# sar -r 2 3
Linux 2.6.32-431.el6.x86_64 (localhost) 10/29/2019 x86_64 (8 CPU)
04:54:20 AM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit
04:54:22 AM 1218760 834228 40.63 53228 424908 738312 18.08
04:54:24 AM 1218744 834244 40.64 53228 424908 738312 18.08
04:54:26 AM 1218712 834276 40.64 53228 424908 738312 18.08
Average: 1218739 834249 40.64 53228 424908 738312 18.08
此输出结果中,各个参数表示的含义如下:
kbmemfree:表示空闲的物理内存的大小;
kbmemeused:表示已使用的物理内存的大小;
%memused:表示已使用内存占总内存大小的百分比;
kbbuffers:表示缓冲区所使用的物理内存的大小;
kbcached:表示告诉缓存所使用的物理内存的大小;
kbcommit 和 %commit:分别表示当前系统中应用程序使用的内存大小和百分比;
相比 free 命令,sar 命令的输出信息更加人性化,不仅给出了内存使用量,还给出了内存使用的百分比以及统计的平均值。比如说,仅通过 %commit 一项就可以得知,当前系统中的内存资源充足。
如何查看硬盘的读写性能?
2022-05-07 408举报
简介: 除了 CPU 和内存,硬盘读写(I/O)能力也是影响 Linux 系统性能的重要因素之一。本节将介绍几个可用来查看硬盘读写性能的系统命令,并教大家如何通过这些命令的输出结果,判断出当前系统中硬盘是否处于超负荷运转。
除了 CPU 和内存,硬盘读写(I/O)能力也是影响 Linux 系统性能的重要因素之一。本节将介绍几个可用来查看硬盘读写性能的系统命令,并教大家如何通过这些命令的输出结果,判断出当前系统中硬盘是否处于超负荷运转。
Linux 查看硬盘读写性能:sar -d 命令
《Linux sar 命令》一节,已经对 sar 命令的基本用法做了详细的介绍,这里不再赘述,接下来主要讲解如何通过 sar -d 命令分析出硬盘读写的性能。
下面是执行 sar -d 命令的输出结果样例:
[root@localhost ~]# sar -d 3 5
Linux 2.6.32-431.el6.x86_64 (localhost) 10/25/2019 x86_64 (1 CPU)
06:36:52 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:36:55 AM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06:36:55 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:36:58 AM dev8-0 1.00 0.00 12.00 12.00 0.00 0.00 0.00 0.00
06:36:58 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
06:37:01 AM dev8-0 1.99 0.00 47.76 24.00 0.00 0.50 0.25 0.05
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 1.00 0.00 19.97 20.00 0.00 0.33 0.17 0.02
结合以上输出结果,可以遵循如下标准来判断当前硬盘的读写(I/O)性能:
通常情况下 svctm 的大小和硬盘性能有关,其值小于 await。但需要注意的是,CPU、内存的负荷也会对 svctm 的值造成影响,过多的请求也会间接导致 svctm 值的增加。
await 值通常会受到 svctm、I/O 队列长度以及 I/O 请求模式的影响,如果 svctm 的值和 await 很接近,则表示几乎没有 I/O 等待,当前硬盘的性能很好;如果 await 的值远高于 svctm,则表示 I/O 队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util 项也是衡量硬盘 I/O 性能的重要指标,即如果其值接近 100%,就表示硬盘产生的 I/O 请求太多,I/O 系统正在满负荷工作,长期这样会影响系统的性能。必要时,可以优化程序或者更换更大、更快的硬盘来解决这个问题。
Linux 查看硬盘读写性能:iostat -d 命令
通过执行 iostat -d 命令,也可以查看系统中硬盘的使用情况,如下是执行此命令的一个样例输出:
[root@localhost ~]# iostat -d 2 3
Linux 2.6.32-431.el6.x86_64 (localhost) 10/30/2019 x86_64 (8 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 5.29 337.11 9.51 485202 13690
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 1.00 8.00 16.00 16 32
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
此输出结果中,我们重点看后面 4 列,它们各自表示的含义分别是:
Blk_read/s:表示每秒读取的数据块数;
Blk_wrtn/s:表示每秒写入的数据块数;
Blk_read:表示读取的所有块数;
Blk_wrtn:表示写入的所有块数。
注意,此输出结果中,第一次输出的数据是系统从启动以来直到统计时的所有传输信息,从第二次输出的数据开始,才代表在指定检测时间段内系统的传输值。
根据 iostat 命令的输出结果,我们也可以从中判断出当前硬盘的 I/O 性能。比如说,如果 Blk_read/s 的值很大,就表示当前硬盘的读操作很频繁;同样,如果 Blk_wrtn/s 的值很大,就表示当前硬盘的写操作很频繁。对于 Blk_read 和 Blk_wrtn 的大小,没有一个固定的界限,不同的系统应用对应值的范围也不同。但如果长期出现超大的数据读写情况,通常是不正常的,一定程度上会影响系统性能。
不仅如此,iostat 命令还提供了统计指定硬盘 I/O 状况的方法,即使用 -x 选项。例如:
[root@localhost ~]# iostat -x /dev/sda 2 3
Linux 2.6.32-431.el6.x86_64 (localhost) 10/30/2019 x86_64 (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.09 0.00 0.24 0.26 0.00 99.42
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 2.00 0.56 2.92 0.44 206.03 7.98 63.56 0.03 9.99 5.31 1.79
avg-cpu: %user %nice %system %iowait %steal %idle
0.31 0.00 0.06 0.00 0.00 99.62
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.50 0.00 0.06 0.00 0.00 99.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
此输出结果基本和 sar -d 命令的输出结果相同,需要额外说明的几个选项的含义如下:
rrqm/s:表示每秒被合并的读操作数目(文件系统会对读取同一 block 块的请求进行合并)
wrqm/s:表示每秒被合并的写操作数目;
r/s:表示每秒完成读 I/O 设备的次数;
w/s:表示每秒完成写 I/O 设备的次数;
rsec/s:表示每秒读取的扇区数;
wsec/s:表示每秒写入的扇区数;
Linux 查看硬盘读写性能:vmstat -d 命令
使用 vmstat 命令也可以查看有关硬盘的统计数据,例如:
[root@bogon ~]# vmstat -d 3 2
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
sda 6897 4720 485618 71458 1256 1475 21842 9838 0 43
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
sda 6897 4720 485618 71458 1256 1475 21842 9838 0 43
该命令的输出结果显示了硬盘的读(reads)、写(writes)以及 I/O 的使用状态。
以上主要讲解了如何通过命令查看当前系统中硬盘 I/O 的性能,其实影响硬盘 I/O 的因素是多方面的,例如应用程序本身、硬件设计、系统自身配置等等。
要想解决硬盘 I/O 的瓶颈,关键是要提高 I/O 子系统的执行效率。比如说,首先从应用程序上对硬盘读写性能进行优化,能够放到内存中执行的操作尽量别保存到硬盘里(内存读写效率要远高于硬盘读写效率);其次,还可以对硬盘存储方法进行合理规划,选择合适的 RAID 存储方式;最后,选择适合自身应用的文件系统,必要时可以使用裸设备提高硬盘的读写性能。
在裸设备上,数据可以直接读写,不必经过操作系统级别的缓存,还可以避免文件系统级别的维护开销(文件系统需要维护超级块、I-node 块等)以及操作系统的 cache 预读功能(减少了 I/O 请求)。
网络通讯
端口
这么多端口怎么记忆呢?系统给我们提供了服务与端口的对应文件 /etc/services。 查看—下:
[root@localhost ~]#vi /etc/services
…省略部分输出…
ftp-data 20/tcp
ftp-data 20/udp
\# 21 is registered to ftp, but also used by fsp
ftp 21/tcp
ftp 21/udp
fsp fspd
\#FTP服务的端口
…省略部分输出…
网络服务的端口能够修改吗?当然是可以的,不过一旦修改了端口,那么客户机在访问服务器时很难知道服务器对应的端口是什么,也就不能正确地获取服务了。所以,除非在实验环境下,否则不要修改网络服务对应的端口。
查询系统中已经启动的服务
既然每个网络服务对应的端口是固定的,那么是否可以通过查询服务器中开启的端口,来判断当前服务器开启了哪些服务?
当然是可以的。虽然判断服务器中开启的服务还有其他方法(如通过ps命令),但是通过端口的方法查看最为准确。命令格式如下:
[root@localhost ~]# netstat 选项
选项:
-a:列出系统中所有网络连接,包括已经连接的网络服务、监听的网络服务和 Socket 套接字;
-t:列出 TCP 数据;
-u:列出 UDF 数据;
-l:列出正在监听的网络服务(不包含已经连接的网络服务);
-n:用端口号来显示而不用服务名;
-p:列出该服务的进程 ID (PID);
举个例子:
[root@localhost ~]# netstat -tlunp
\#列出系统中所有已经启动的服务(已经监听的端口),但不包含已经连接的网络服务
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:53575 0.0.0.0:*
LISTEN
1200/rpc.statd
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1181/rpcbind
tcp 0 0 0.0.0.0:22 O.O.O.O:* LISTEN 1405/sshd
tcp 0 0127.0.0.1:631 O.O.O.O:* LISTEN 1287/cupsd
tcp 0 0 127.0.0.1:25 O.O.O.O:* LISTEN 1481/master
tcp 0 0 :::57454 :::* LISTEN 1200/rpc.statd
tcp 0 0 :::111 :::* LISTEN 1181/rpcbind
tcp 0 0 :::22 :::* LISTEN 1405/sshd
tcp 0 0 ::1:631 :::* LISTEN 1287/cupsd
tcp 0 0 ::1:25 :::* LISTEN 1481/master
udp 0 0 0.0.0.0:58322 0.0.0.0:* 1276/avahi-daemon
udp 0 0 0.0.0.0:5353 O.O.O.O:* 1276/avahi-daemon
udp 0 0 0.0.0.0:111 O.O.O.O:* 1181/rpcbind
udp 0 0 0.0.0.0:631 O.O.O.O:* 1287/cupsd
udp 0 0 0.0.0.0:56459 0.0.0.0:* 1200/rpc.statd
udp 0 0 0.0.0.0:932 O.O.O.O:* 1181/rpcbind
udp 0 0 0.0.0.0:952 O.O.O.O:* 1200/rpc.statd
udp 0 0 :::111 :::* 1181/rpcbind
udp 0 0 :::47858 :::* 1200/rpc.statd
udp 0 0 :::932 :::* 1181/rpcbind
执行这条命令会看到服务器上所有已经开启的端口,也就是说,通过这些端口就可以知道当前服务器上开启了哪些服务。
解释一下命令的执行结果:
Proto:数据包的协议。分为 TCP 和 UDP 数据包;
Recv-Q:表示收到的数据已经在本地接收缓冲,但是还没有被进程取走的数据包数量;
Send-Q:对方没有收到的数据包数量;或者没有 Ack 回复的,还在本地缓冲区的数据包数量;
Local Address:本地 IP : 端口。通过端口可以知道本机开启了哪些服务;
Foreign Address:远程主机:端口。也就是远程是哪个 IP、使用哪个端口连接到本机。由于这条命令只能查看监听端口,所以没有 IP 连接到到本机;
State:连接状态。主要有已经建立连接(ESTABLISED)和监听(LISTEN)两种状态,当前只能查看监听状态;
PID/Program name:进程 ID 和进程命令;
文件传输
scp : 命令用于 Linux 之间复制文件和目录。可以用来作为下载文件到本地的一种方式。scp 是 secure copy 的缩写, scp 是 linux 系统下基于 ssh 登陆进行安全的远程文件拷贝命令。
打开本地系统服务 文件 远程登入 允许访问 所有用户
输入:scp heap.hprof [email protected]:/Users/aobing/Downloads
输入本机电脑登入密码即可,就能显示当前在下载的进度了
扩展:举一个用法的例子,假设用我自己当前电脑作为演示,怎么去把我们跳板机中的dump文件下载到我们本地,以便于我们自己来分析堆栈呢?
这个是比较常用的方法,可以有其他的用法,就因个人而已吧
备份压缩
推荐把各种出了配置 home etc这些文件夹外的 需要存的数据 都放data目录下!
我个人认为,需要备份的文件大致可分为 2 类,分别是系统级配置文件和用户级配置文件。
系统级配置文件
系统配置文件主要指的是系统全局的一些配置信息,比如说:
/root/ 目录:/root/ 目录是管理员的家目录,很多管理员会习惯在这个目录中保存一些相关数据,那么,当进行数据备份时,需要备份此目录。
/home/ 目录:/home/ 目录是普通用户的家目录。如果是生产服务器,那么这个目录中也会保存大量的重要数据,应该备份。
/var/spool/mail/ 目录:在默认情况下,所有的用户未读的邮件会保存在 /var/spool/mail/ 目录下和用户名相同的邮箱文件中,已读的邮件会保存在用户家目录下的 mbox 文件中(mail 命令默认如此保存,不过如果使用了 hold 命令,那么不管邮件是否已读,都保存在 /var/spool/mail/ 目录中。可以使用 mbox 命令恢复已读邮件保存在“~/mbox”文件中)。一般情况下,用户的邮件也是需要备份的重要数据。
/etc/ 目录:系统重要的配置文件保存目录,当然需要备份。
其他目录:根据系统的具体情况,备份你认为重要的目录。比如,我们的系统中有重要的日志,或者安装了 RPM 包的 MySQL 服务器(RPM 包安装的 mysql 服务,数据库保存在 /var/lib/mysql/ 目录中),那么 /var/ 目录就需要备份;如果我们的服务器中安装了多个操作系统,或编译过新的内核,那么 /boot/ 目录就需要备份。
以上这些目录对系统的运行至关重要,并且针对不同的系统应用,其设置也不尽相同。如果丢失的这些文件,即使新的操作系统能很快安装完毕,对系统也要重新配置,花费的时间会更长。
用户级配置文件
用户级配置文件,也就是用户业务应用与系统相关的配置文件,这些文件是运行业务应用必不可少的,一旦丢失,应用将无法启动。
我们的 Linux 服务器中会安装各种各样的应用程序,每种应用程序到底应该备份什么数据也不尽相同,要具体情况具体对待。这里拿最常见的 apache 服务和 mysql 服务来举例。
apache 服务需要备份如下内容:
配置文件:RPM 包安装的 apache 需要备份 /etc/httpd/conf/httpd.conf;源码包安装的 apache 则需要备份 /usr/local/apache2/conf/httpd.conf。
网页主目录:RPM 包安装的 apache 需要备份 /var/www/html/ 目录中所有的数据;源码包安装的 apache 需要备份 /usr/local/apache2/htdocs/ 目录中所有的数据。
日志文件:RPM 包安装的 apache 需要备份 /var/log/httpd/ 目录中所有的日志;源码包安装的 apache 需要备份 /usr/local/apache2/logs/ 目录中所有的日志。
其实,对源码包安装的 apache 来讲,只要备份 /usr/local/apache2/ 目录中所有的数据即可,因为源码包安装的服务的所有数据都会保存到指定目录中。但如果是 RPM 包安装的服务,就需要单独记忆和指定了。
mysql 服务需要备份如下内容:
对于源码包安装的 mysql 服务,数据库默认安装到 /usr/local/mysql/data/ 目录中,只需备份此目录即可。
对于RPM包安装的 mysql 服务,数据库默认安装到 /var/lib/mysql/ 目录中,只需备份此目录即可。
如果是源码包安装的服务,则可以直接备份 /usr/local/ 目录,因为一般源码包服务都会安装到 /usr/local/ 目录中。如果是 RPM 包安装的服务,则需要具体服务具体对待,备份正确的数据。
以上重要的文件和目录,是必须要备份的,那么,不需要备份的目录有哪些呢?比如 /dev 目录、/proc 目录、/mnt 目录以及 /tmp 目录等,这些目录是不需要备份的,因为这些目录中,要么是内存数据,要么是临时文件,没有重要的数据。
备份策略
累计增量备份
在一个数据量很大的业务应用中,每天对 Linux 系统进行完全备份是不现实的,这就需要用到增量备份策略。
累计增量备份是指先进行一次完全备份,服务器运行一段时间之后,比较当前系统和完全备份的备份数据之间的差异,只备份有差异的数据。服务器继续运行,再经过一段时间,进行第二次增量备份。在进行第二次增量备份时,当前系统和第一次增量备份的数据进行比较,也是只备份有差异的数据。第三次增量备份是和第二次增量备份的数据进行比较,以此类推。
因此,累计增量备份就是只备份每天增加或者变化的数据,而不备份系统中没有变动的数据。我们画一张示意图,如图 1 所示。
差异增量备份
差异增量备份(后续简称差异备份)也要先进行一次完全备份,但是和累计增量备份不同的是,每次差异备份都备份和原始的完全备份不同的数据。也就是说,差异备份每次备份的参照物都是原始的完全备份,而不是上一次的差异备份。我们也画一张示意图,如图 2 所示。
- Linux数据备份与恢复
图 2 差异增量备份
假设我们在第一天也进行一次完全备份。第二天差异备份时,会备份第二天和第一天之间的差异数据,而第二天的备份数据是完全备份加第一次差异备份的数据。第三天进行差异备份时,仍和第一天的原始数据进行对比,把第二天和第三天所有的数据都备份在第二次差异备份中,第三天的备份数据是完全备份加第二次差异备份的数据。第四天进行差异备份时,仍和第一天的原始数据进行对比,把第二天、第三天和第四天所有的不同数据都备份到第三次差异备份中,第四天的备份数据是完全备份加第三次差异备份的数据。
相比较而言,差异备份既不像完全备份一样把所有数据都进行备份,也不像增量备份在进行数据恢复时那么麻烦,只要先恢复完全备份的数据,再恢复差异备份的数据即可。不过,随着时间的增加,和完全备份相比,变动的数据越来越多,那么差异备份也可能会变得数据量庞大、备份速度缓慢、占用空间较大。
一个比较的备份策略是,对于数据量不大,并且每天数据量增加不多的系统,优先选择完全备份;对于数据量巨大,每天新增数据也很多的系统,视情况选择差异备份或者增量备份。
备份脚本示例与tar命令
作为 Linux 系统管理员,最经常使用的备份工具就是 tar 和 cpio 命令。前面在介绍备份介质时,已经使用了 tar 命令,此命令其实是一个文件打包命令,经常在备份文件的场合中使用。
使用 cpio 命令进行数据备份,请阅读《Linux提取RPM包文件(cpio命令)》。
有关 tar 命令的基本用法,请阅读《Linux tar压缩命令》一节,这里不再过多赘述。下面通过 tar 命令做的一个 Web 服务器的备份脚本,详细了解 tar 命令作为备份工具时的具体用法。
以下是一个有关 Web 服务器的备份脚本:
#!/bin/sh
BAKDATE=date +%y%m%d
DATA3=date -d "3 days ago" +%y%m%d
osdata=/disk1
userdata=/disk2
echo “backup OS data starting”
tar -zcvf /KaTeX parse error: Expected group after '_' at position 20: …ta/etc.data/etc_̲BAKDATE.tar.gz /etc
tar -zcvf /KaTeX parse error: Expected group after '_' at position 22: …/boot.data/boot_̲BAKDATE.tar.gz /boot
tar -zcvf /KaTeX parse error: Expected group after '_' at position 22: …/home.data/home_̲BAKDATE.tar.gz /home
tar -zcvf /KaTeX parse error: Expected group after '_' at position 22: …/root.data/root_̲BAKDATE.tar.gz /root
tar -zcvf /KaTeX parse error: Expected group after '_' at position 27: …r_data/usrlocal_̲BAKDATE.tar.gz /usr/local
tar -zcvf /KaTeX parse error: Expected group after '_' at position 21: …ata/var_www/www_̲BAKDATE.tar.gz /var/www
cp -r / o s d a t a / ∗ / osdata/* / osdata/∗/userdata
cp -r / u s e r d a t a / ∗ / userdata/* / userdata/∗/osdata
echo “Backup OS data complete!”
echo “delete OS data 3 days ago”
rm -rf /KaTeX parse error: Expected group after '_' at position 20: …ta/etc.data/etc_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 22: …/boot.data/boot_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 22: …/home.data/home_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 22: …/root.data/root_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 25: …r_data/usrlocal_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 19: …ata/var_www/www_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 22: …ta/etc.data/etc_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 24: …/boot.data/boot_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 24: …/home.data/home_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 24: …/root.data/root_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 27: …r_data/usrlocal_̲DATA3.tar.gz
rm -rf /KaTeX parse error: Expected group after '_' at position 21: …ata/var_www/www_̲DATA3.tar.gz
echo “delete cws ok!”
上面这段脚本完成的工作是,将系统和用户的备份数据分别保存在两个不同的本地磁盘 disk1 和 disk2 中,并且保留最近 3 天的数据,3 天前的数据自动删除。主要备份的数据有 /etc 目录、/boot 目录、/home 目录、/root 目录、/usr/local 目录和 /var/www 目录。当然这里只是举个例子,凡是存放数据的重要目录,都需要进行备份。
更多命令
13.6 Linux dump
13.7 Linux restore
13.8 Linux dd
13.9 Linux rsync命令:支持本地备份和远程备份
- ll 或者 ls –l 命令来显示一个文件的属性以及文件所属的用户和组
- chown (change ownerp) : 修改所属用户与组。
- chmod (change mode) : 修改用户的权限。
chgrp [-R] 属组名 文件名
参数选项
-R:递归更改文件属组,就是在更改某个目录文件的属组时,如果加上-R的参数,那么该目录下的所有文件的属组都会更改。
你可以使用 man [命令] 来查看各个命令的使用文档,如 :man cp。
查看日志
5.如何查看测试项目的日志
一般测试的项目里面,有个logs的目录文件,会存放日志文件,有个xxx.out的文件,可以用tail -f 动态实时查看后端日志
先cd 到logs目录(里面有xx.out文件)
tail -f xx.out
这时屏幕上会动态实时显示当前的日志,ctr+c停止
6.如何查看最近1000行日志
tail -1000 xx.out
查看端口
7.LINUX中如何查看某个端口是否被占用
netstat -anp | grep 端口号
图中主要看监控状态为LISTEN表示已经被占用,最后一列显示被服务mysqld占用,查看具体端口号,只要有如图这一行就表示被占用了
查看82端口的使用情况,如图
netstat -anp |grep 82
可以看出并没有LISTEN那一行,所以就表示没有被占用。此处注意,图中显示的LISTENING并不表示端口被占用,不要和LISTEN混淆哦,查看具体端口时候,必须要看到tcp,端口号,LISTEN那一行,才表示端口被占用了
查看当前所有已经使用的端口情况,如图:
netstat -nultp(此处不用加端口号)
tree 查看当前的目录树
安装软件
源码包与二进制包、rpm
Linux源码包
实际上,源码包就是一大堆源代码程序,是由程序员按照特定的格式和语法编写出来的。
我们都知道,计算机只能识别机器语言,也就是二进制语言,所以源码包的安装需要一名“翻译官”将“abcd”翻译成二进制语言,这名“翻译官”通常被称为编译器。
“编译”指的是从源代码到直接被计算机(或虚拟机)执行的目标代码的翻译过程,编译器的功能就是把源代码翻译为二进制代码,让计算机识别并运行。
虽然源码包免费开源,但用户不会编程怎么办?一大堆源代码程序不会使用怎么办?源码包容易安装吗?等等这些都是使用源码包安装方式无法解答的问题。
另外,由于源码包的安装需要把源代码编译为二进制代码,因此安装时间较长。比如,大家应该都在 Windows下安装过 QQ,QQ 功能较多,程序相对较大(有 70 MB左右),但由于其并非是以源码包的形式发布,而是编译后才发布的,因此只需几分钟(经过简单的配置)即可安装成功。但如果我们以源码包安装的方式在 Linux 中安装一个 MySQL 数据库,即便此软件的压缩包仅有 23 MB左右,也需要 30 分钟左右的时间(根据硬件配置不同,略有差异)。
通过对比你会发现,源码包的编译是很费时间的,况且绝多大数用户并不熟悉程序语言,在安装过程中我们只能祈祷程序不要报错,否则初学者很难解决。
为了解决使用源码包安装方式的这些问题,Linux 软件包的安装出现了使用二进制包的安装方式。
Linux二进制包
二进制包,也就是源码包经过成功编译之后产生的包。由于二进制包在发布之前就已经完成了编译的工作,因此用户安装软件的速度较快(同 Windows下安装软件速度相当),且安装过程报错几率大大减小。
二进制包是 Linux 下默认的软件安装包,因此二进制包又被称为默认安装软件包。目前主要有以下 2 大主流的二进制包管理系统:
RPM 包管理系统:功能强大,安装、升级、査询和卸载非常简单方便,因此很多 Linux 发行版都默认使用此机制作为软件安装的管理方式,例如 Fedora、CentOS、SuSE 等。
DPKG 包管理系统:由 Debian Linux 所开发的包管理机制,通过 DPKG 包,Debian Linux 就可以进行软件包管理,主要应用在 Debian 和 Ubuntu 中。
RPM 包管理系统和 DPKG 管理系统的原理和形式大同小异,可以触类旁通。由于本教程使用的是 CentOS 6.x 版本,因此本节主要讲解 RPM 二进制包。
源码包 VS RPM二进制包
源码包一般包含多个文件,为了方便发布,通常会将源码包做打包压缩处理,Linux 中最常用的打包压缩格式为“tar.gz”,因此源码包又被称为 Tarball。
Tarball 是 Linux 系统的一款打包工具,可以对源码包进行打包压缩处理,人们习惯上将最终得到的打包压缩文件称为 Tarball 文件。
源码包需要我们自己去软件官方网站进行下载,包中通常包含以下内容:
源代码文件。
配置和检测程序(如 configure 或 config 等)。
软件安装说明和软件说明(如 INSTALL 或 README)。
总的来说,使用源码包安装软件具有以下几点好处:
开源。如果你有足够的能力,则可以修改源代码。
可以自由选择所需的功能。
因为软件是编译安装的,所以更加适合自己的系统,更加稳定,效率也更高。
卸载方便。
但同时,使用源码包安装软件也有几点不足:
安装过程步骤较多,尤其是在安装较大的软件集合时(如 LAMP 环境搭建),容易出现拼写错误。
编译时间较长,所以安装时间比二进制安装要长。
因为软件是编译安装的,所以在安装过程中一旦报错,新手很难解决。
相比源码包,二进制包是在软件发布时已经进行过编译的软件包,所以安装速度比源码包快得多(和 Windows 下软件安装速度相当)。也正是因为已经进行通译,大家无法看到软件的源代码。
使用 RMP 包安装软件具有以下 2 点好处:
包管理系统简单,只通过几个命令就可以实现包的安装、升级、査询和卸载。
安装速度比源码包安装快得多。
与此同时,使用 RMP 包安装软件有如下不足:
经过编译,不能在看到源代码。
功能选择不如源码包灵活。
依赖性。有时我们会发现,在安装软件包 a 时需要先安装 b 和 c,而在安装 b 时需要先安装 d 和 e。这就需要先安装 d 和 e,再安装 b 和 c,最后才能安装 a。比如,我买了一个漂亮的灯具,打算安装在客厅里,可是在安装灯具之前,客厅需要有顶棚,并且顶棚需要刷好油漆。安装软件和装修及其类似,需要有一定的顺序,但是有时依赖性会非常强。
如何选择
通过源码包和 RMP 二进制包的对比,在 Linux 进行软件安装时,我们应该使用哪种软件包呢?
为了更好的区别两种软件包,这里举个例子。假设我们想做一套家具,源码包就像所有的家具完全由自己动手手工打造(手工编译),想要什么样的板材、油漆、颜色和样式都由自己决定(功能自定义,甚至可以修改源代码)。想想就觉得爽,完全不用被黑心的厂商所左右,而且不用担心质量问题(软件更适合自己的系统,效率更高,更加稳定)。但是,所花费的时间大大超过了买一套家具的时间(编译浪费时间),而且自己真的有做木工这个能力吗(需要对源代码非常了解)?就算请别人定制好的家具,再由自己组装,万一哪个部件不匹配(报错很难解决),怎么办?
那么二进制包呢?也是我们需要一套家具,去商场买了一套(安装简单),家具都是现成的,不会有哪个部件不匹配,除非因为自身问题没有量好尺寸而导致放不下(报错很少)。但是我们完全不知道这套家具用的是什么材料、油漆是否合格,而且家具的样式不能随意选择(软件基本不能自定义功能)。
源码安装
源码的安装一般由这三个步骤:
- 配置(configure)
- 编译(make)
- 安装(make install)
其实./configure、make、make install这三个命令,我们可以用&&来把命令连接起来执行,表示当前一条命令正常结束后,后面的命令才会执行,这个办法很好,既节省时间,又可以防止发生错误。例:
./configure && make && make install ##install可能要sudo
安装成功的源码就是所谓的可执行文件,在你不需要的时候,也是可以删除/卸载(remove/uninstall)的。下面就逐个进行分析:
准备工作
Linux 系统中,绝大多数软件的源代码都是用 C 语言编写的,少部分用 C++(或其他语言)编写。因此要想安装源码包,必须安装 gcc 编译器(如果涉及 C++ 源码程序,还需要安装 gcc-c++)。
安装 gcc 之前,可先使用如下命令看看是否已经安装:
[root@localhost ~]# rpm -q gcc
gcc-4.4.6-4.el6.i686
如果未安装,考虑到安装 gcc 所依赖的软件包太多,推荐大家使用 yum 安装 gcc。具体安装方式可阅读《Linux yum命令》一节。
除了安装编译器,还需要安装 make 编译命令。要知道,编译源码包可不像编译一个 hello.c 文件那样轻松,包中含大量的源码文件,且文件之间有着非常复杂的关联,直接决定着各文件编译的先后顺序,因此手动编译费时费力,而使用 make 命令可以完成对源码包的自动编译。
同样,在安装 make 命令之前,可使用如下命令查看其是否已经安装:
[root@localhost yum. repos.d]# rpm -q make
make-3.81-20.el6.i686
如果未安装,可使用 yum -y install make 命令直接安装 make。
安装好了 gcc 编译器和 make 编译工具,接下来学习使用源码包安装软件。
源码的配置
配置命令就是configure命令。一般来说,configure文件是位于源码根目录下的一个可执行的脚本文件,它有很多选项,而且不同软件的选项都不完全一致。可以在待安装的源码目录下使用命令:./configure --help输出详细的选项列表。
./configure --prefix=/usr/local/
其中有一个通用的选项,叫做–prefix选项,目的是配置安装的路径。
如果不配置该选项,安装后:
- 可执行文件默认放在/usr/local/bin,
- 库文件默认放在/usr/local/lib,
- 配置文件默认放在/usr/local/etc,
- 其他的资源文件放在/usr/local/share,比较分散。
为了便于集中管理某个软件的各种文件,想指定到某个路径下,可以配置 --prefix,如:
./configure --prefix=/usr/local/proj4
那么,安装后的所有资源文件都会被放在/usr/local/proj4目录中,不会分散到其他目录。
用了 --prefix选项的另一个好处是卸载软件或者移植软件更方便。当某个安装的软件不再需要时,只须删除该安装目录,就可以把软件卸载的干干净净。
源码的编译
配置完毕之后,一般都会提示你,直接运行make命令进行编译。此时你照做就好,程序就会开始自动编译。
有一个要注意的就是,考虑到目前的计算机一般都是多核的,如果你想人工加快程序的编译速度,可以手工指定一个make命令的一个参数“-j8”或者“-j16”,后面的数字表示的就是用几个核进行编译,数字越大,编译速度越快。当然,要说明的是,这里的编译速度与内核的个数,并不是成正比的。而且,具体多少个任务同时执行为佳,还需要根据具体的机器配置,任务数太多,反而效果不好。
例如:对一个linux内核的编译过程的测试,使用不同的参数编译的时间如下:
用 make:大约40分钟;
用 make -j4:大约23分钟;
用 make -j8:接近23分钟。
另外,这个方案不是完全没有弊端的,如果项目的Makefile不规范,没有正确的设置好依赖关系,并行编译的结果就是编译不能正常进行。如果依赖关系设置过于保守,则可能本身编译的可并行度就下降了,也不能取得最佳的效果。
程序的安装
编译完成之后,就是安装。这里的安装,其实就是把编译出来的可执行文件,以及一堆的头文件和依赖库,以及文档资料等,按照linux系统约定的规则,拷贝到你事先指定的目录下去。所以,与其叫安装,其实就是一个拷贝的过程。
同样,这里也有一点要说明的是,很多时候,手册或者提示信息里都只是告诉你,执行make install命令来进行安装。然而,你执行了这个命令之后,往往会遇到一些错误的提示。经过一番排查之后,你会发现,就是因为权限不够,导致文件拷贝失败。所以,最好养成一个习惯,每次make install的命令前加上sudo的权限,如下:
$ sudo make install
程序的卸载
当然,要卸载程序,也可以在原来的make目录下用一次make uninstall,但前提是Makefile文件有uninstall命令。
而如果你安装时没有配置–prefix选项,源码包也没有提供make uninstall命令,则可以通过以下方式来卸载:
找到make install之后产生的这个文件install_manifest.txt
里面有安装的所有东西的路径,使用下述命令逐个删除它们即可。
$ cat install_manifest.txt | sudo xargs rm
打补丁升级等略过
总结
- ./configure的作用是检测系统配置,生成makefile文件,以便可以用make和make install来编译和安装程序。
- ./configure是源代码安装的第一步,主要的作用是对即将安装的软件进行配置,检查当前的环境是否满足要安装软件的依赖关系,但并不是所有的tar包都是源代码的包。
- 可以先ls,查看有没有configure或者makefile文件。
- 如果有configure,就./configure,有很多参数。如果系统环境合适,就会生成makefile,否则会报错。
- 如果有makefile,就直接make,然后make install。
- 还可以用rpm或者deb包来安装。而且现在的发行版都有自己的包管理器,比如apt或yum,一个命令就可以从源下载软件,还可以自动解决依赖问题。
rpm方式
Linux RPM包统一命名规则
简介: RPM 二进制包的命名需遵守统一的命名规则,用户通过名称就可以直接获取这类包的版本、适用平台等信息。
RPM 二进制包的命名需遵守统一的命名规则,用户通过名称就可以直接获取这类包的版本、适用平台等信息。
RPM 二进制包命名的一般格式如下:
包名-版本号-发布次数-发行商-Linux平台-适合的硬件平台-包扩展名
例如,RPM 包的名称是httpd-2.2.15-15.el6.centos.1.i686.rpm,其中:
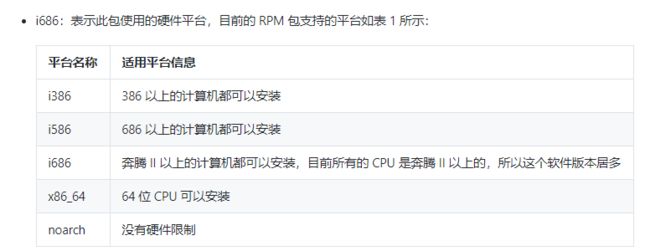
RPM包安装、卸载和升级
本节讲解如何使用 rpm 命令对 RPM 二进制包进行安装、卸载和升级操作。
我们以安装 apache 程序为例。因为后续章节还会介绍使用源码包的方式安装 apache 程序,读者可以直观地感受到源码包和 RPM 包的区别。
RPM包默认安装路径
通常情况下,RPM 包采用系统默认的安装路径,所有安装文件会按照类别分散安装到表 1 所示的目录中。
安装路径 含 义
/etc/ 配置文件安装目录
/usr/bin/ 可执行的命令安装目录
/usr/lib/ 程序所使用的函数库保存位置
/usr/share/doc/ 基本的软件使用手册保存位置
/usr/share/man/ 帮助文件保存位置
RPM 包的默认安装路径是可以通过命令查询的。
除此之外,RPM 包也支持手动指定安装路径,但此方式并不推荐。因为一旦手动指定安装路径,所有的安装文件会集中安装到指定位置,且系统中用来查询安装路径的命令也无法使用(需要进行手工配置才能被系统识别),得不偿失。
与 RPM 包不同,源码包的安装通常采用手动指定安装路径(习惯安装到 /usr/local/ 中)的方式。既然安装路径不同,同一 apache 程序的源码包和 RPM 包就可以安装到一台 Linux 服务器上(但同一时间只能开启一个,因为它们需要占用同一个 80 端口)。
实际情况中,一台服务器几乎不会同时包含两个 apache 程序,管理员不好管理,还会占用过多的服务器磁盘空间。
RPM 包的安装
安装 RPM 的命令格式为:
[root@localhost ~]# rpm -ivh 包全名
注意一定是包全名。涉及到包全名的命令,一定要注意路径,可能软件包在光盘中,因此需提前做好设备的挂载工作。
此命令中各选项参数的含义为:
-i:安装(install);
-v:显示更详细的信息(verbose);
-h:打印 #,显示安装进度(hash);
例如,使用此命令安装 apache 软件包,如下所示:
[root@localhost ~]# rpm -ivh
/mnt/cdrom/Packages/httpd-2.2.15-15.el6.centos.1.i686.rpm
Preparing…
####################
[100%]
1:httpd
####################
[100%]
注意,直到出现两个 100% 才是真正的安装成功,第一个 100% 仅表示完成了安装准备工作。
此命令还可以一次性安装多个软件包,仅需将包全名用空格分开即可,如下所示:
[root@localhost ~]# rpm -ivh a.rpm b.rpm c.rpm
如果还有其他安装要求(比如强制安装某软件而不管它是否有依赖性),可以通过以下选项进行调整:
-nodeps:不检测依赖性安装。软件安装时会检测依赖性,确定所需的底层软件是否安装,如果没有安装则会报错。如果不管依赖性,想强制安装,则可以使用这个选项。注意,这样不检测依赖性安装的软件基本上是不能使用的,所以不建议这样做。
-replacefiles:替换文件安装。如果要安装软件包,但是包中的部分文件已经存在,那么在正常安装时会报"某个文件已经存在"的错误,从而导致软件无法安装。使用这个选项可以忽略这个报错而覆盖安装。
-replacepkgs:替换软件包安装。如果软件包已经安装,那么此选项可以把软件包重复安装一遍。
-force:强制安装。不管是否已经安装,都重新安装。也就是 -replacefiles 和 -replacepkgs 的综合。
-test:测试安装。不会实际安装,只是检测一下依赖性。
-prefix:指定安装路径。为安装软件指定安装路径,而不使用默认安装路径。
apache 服务安装完成后,可以尝试启动:
[root@localhost ~]# service 服务名 start|stop|restart|status
各参数含义:
start:启动服务;
stop:停止服务;
restart:重启服务;
status: 查看服务状态;
例如:
[root@localhost ~]# service httpd start #启动apache服务
RPM包的升级
使用如下命令即可实现 RPM 包的升级:
[root@localhost ~]# rpm -Uvh 包全名
-U(大写)选项的含义是:如果该软件没安装过则直接安装;若没安装则升级至最新版本。
[root@localhost ~]# rpm -Fvh 包全名
-F(大写)选项的含义是:如果该软件没有安装,则不会安装,必须安装有较低版本才能升级。
RPM包的卸载
RPM 软件包的卸载要考虑包之间的依赖性。例如,我们先安装的 httpd 软件包,后安装 httpd 的功能模块 mod_ssl 包,那么在卸载时,就必须先卸载 mod_ssl,然后卸载 httpd,否则会报错。
软件包卸载和拆除大楼是一样的,本来先盖的 2 楼,后盖的 3 楼,那么拆楼时一定要先拆除 3 楼。
如果卸载 RPM 软件不考虑依赖性,执行卸载命令会包依赖性错误,例如:
[root@localhost ~]# rpm -e httpd
error: Failed dependencies:
httpd-mmn = 20051115 is needed by (installed) mod_wsgi-3.2-1.el6.i686
httpd-mmn = 20051115 is needed by (installed) php-5.3.3-3.el6_2.8.i686
httpd-mmn = 20051115 is needed by (installed) mod_ssl-1:2.2.15-15.el6.
centos.1.i686
httpd-mmn = 20051115 is needed by (installed) mod_perl-2.0.4-10.el6.i686
httpd = 2.2.15-15.el6.centos.1 is needed by (installed) httpd-manual-2.2.
15-15.el6.centos.1 .noarch
httpd is needed by (installed) webalizer-2.21_02-3.3.el6.i686
httpd is needed by (installed) mod_ssl-1:2.2.15-15.el6.centos.1.i686
httpd=0:2.2.15-15.el6.centos.1 is needed by(installed)mod_ssl-1:2.2.15-15.el6.centos.1.i686
RPM 软件包的卸载很简单,使用如下命令即可:
[root@localhost ~]# rpm -e 包名
-e 选项表示卸载,也就是 erase 的首字母。
RPM 软件包的卸载命令支持使用“-nocteps”选项,即可以不检测依赖性直接卸载,但此方式不推荐大家使用,因为此操作很可能导致其他软件也无法征程使用。
rpm查询
rpm -q:查询软件包是否安装
用 rpm 查询软件包是否安装的命令格式为:
[root@localhost ~]# rpm -q 包名
-q 表示查询,是 query 的首字母。
例如,查看 Linux 系统中是否安装 apache,rpm 查询命令应写成:
[root@localhost ~]# rpm -q httpd
httpd-2.2.15-15.el6.centos.1.i686
注意这里使用的是包名,而不是包全名。因为已安装的软件包只需给出包名,系统就可以成功识别(使用包全名反而无法识别)。
rpm -qa:查询系统中所有安装的软件包
使用 rpm 查询 Linux 系统中所有已安装软件包的命令为:
[root@localhost ~]# rpm -qa
libsamplerate-0.1.7-2.1.el6.i686
startup-notification-0.10-2.1.el6.i686
gnome-themes-2.28.1-6.el6.noarch
fontpackages-filesystem-1.41-1.1.el6.noarch
gdm-libs-2.30.4-33.el6_2.i686
gstreamer-0.10.29-1.el6.i686
redhat-lsb-graphics-4.0-3.el6.centos.i686
…省略部分输出…
此外,这里还可以使用管道符查找出需要的内容,比如:
[root@localhost ~]# rpm -qa | grep httpd
httpd-devel-2.2.15-15.el6.centos.1.i686
httpd-tools-2.2.15-15.el6.centos.1.i686
httpd-manual-2.2.15-15.el6.centos.1.noarch
httpd-2.2.15-15.el6.centos.1.i686
相比rpm -q 包名命令,采用这种方式可以找到含有包名的所有软件包。
rpm -qi:查询软件包的详细信息
通过 rpm 命令可以查询软件包的详细信息,命令格式如下:
[root@localhost ~]# rpm -qi 包名
-i 选项表示查询软件信息,是 information 的首字母。
例如,想查看 apache 包的详细信息,可以使用如下命令:
[root@localhost ~]# rpm -qi httpd
Name : httpd Relocations:(not relocatable)
#包名
Version : 2.2.15 Vendor:CentOS
#版本和厂商
Release : 15.el6.centos.1 Build Date: 2012年02月14日星期二 06时27分1秒
#发行版本和建立时间
Install Date: 2013年01月07日星期一19时22分43秒
Build Host:
c6b18n2.bsys.dev.centos.org
#安装时间
Group : System Environment/Daemons Source RPM:
httpd-2.2.15-15.el6.centos.1.src.rpm
#组和源RPM包文件名
Size : 2896132 License: ASL 2.0
#软件包大小和许可协议
Signature :RSA/SHA1,2012年02月14日星期二 19时11分00秒,Key ID
0946fca2c105b9de
#数字签名
Packager:CentOS BuildSystem http://bugs.centos.org
URL : http://httpd.apache.org/
#厂商网址
Summary : Apache HTTP Server
#软件包说明
Description:
The Apache HTTP Server is a powerful, efficient, and extensible web server.
#描述
除此之外,还可以查询未安装软件包的详细信息,命令格式为:
[root@localhost ~]# rpm -qip 包全名
-p 选项表示查询未安装的软件包,是 package 的首字母。
注意,这里用的是包全名,且未安装的软件包需使用“绝对路径+包全名”的方式才能确定包。
rpm -ql:命令查询软件包的文件列表
通过前面的学习我们知道,rpm 软件包通常采用默认路径安装,各安装文件会分门别类安放在适当的目录文件下。使用 rpm 命令可以查询到已安装软件包中包含的所有文件及各自安装路径,命令格式为:
[root@localhost ~]# rpm -ql 包名
-l 选项表示列出软件包所有文件的安装目录。
例如,查看 apache 软件包中所有文件以及各自的安装位置,可使用如下命令:
[root@localhost ~]# rpm -ql httpd
/etc/httpd
/etc/httpd/conf
/etc/httpd/conf.d
/etc/httpd/conf.d/README
/etc/httpd/conf.d/welcome.conf
/etc/httpd/conf/httpd.conf
/etc/httpd/conf/magic
…省略部分输出…
同时,rpm 命令还可以查询未安装软件包中包含的所有文件以及打算安装的路径,命令格式如下:
[root@localhost ~]# rpm -qlp 包全名
-p 选项表示查询未安装的软件包信息,是 package 的首字母。
注意,由于软件包还未安装,因此需要使用“绝对路径+包全名”的方式才能确定包。
比如,我们想查看 bing 软件包(未安装,绝对路径为:/mnt/cdrom/Packages/bind-9.8.2-0.10.rc1.el6.i686.rpm)中的所有文件及各自打算安装的位置,可以执行如下命令:
[root@localhost ~]# rpm -qlp /mnt/cdrom/Packages/bind-9.8.2-0.10.rc1.el6.i686.rpm
/etc/NetworkManager/dispatcher.d/13-named
/etc/logrotate.d/named
/etc/named
/etc/named.conf
/etc/named.iscdlv.key
/etc/named.rfc1912.zones
…省略部分输出…
rpm -qf:命令查询系统文件属于哪个RPM包
rpm -ql 命令是通过软件包查询所含文件的安装路径,rpm 还支持反向查询,即查询某系统文件所属哪个 RPM 软件包。其命令格式如下:
[root@localhost ~]# rpm -qf 系统文件名
-f 选项的含义是查询系统文件所属哪个软件包,是 file 的首字母。
注意,只有使用 RPM 包安装的文件才能使用该命令,手动方式建立的文件无法使用此命令。
例如,查询 ls 命令所属的软件包,可以执行如下命令:
[root@localhost ~]# rpm -qf /bin/ls
coreutils-8.4-19.el6.i686
rpm -qR:查询软件包的依赖关系
使用 rpm 命令安装 RPM 包,需考虑与其他 RPM 包的依赖关系。rpm -qR 命令就用来查询某已安装软件包依赖的其他包,该命令的格式为:
[root@localhost ~]# rpm -qR 包名
-R(大写)选项的含义是查询软件包的依赖性,是 requires 的首字母。
例如,查询 apache 软件包的依赖性,可执行以下命令:
[root@localhost ~]# rpm -qR httpd
/bin/bash
/bin/sh
/etc/mime.types
/usr/sbin/useradd
apr-util-ldap
chkconfig
config(httpd) = 2.2.15-15.el6.centos.1
httpd-tods = 2.2.15-15.el6.centos.1
initscripts >= 8.36
…省略部分输出…
同样,在此命令的基础上增加 -p 选项,即可实现查找未安装软件包的依赖性。
例如,bind 软件包尚未安装(绝对路径为: /mnt/cdrom/Packages/bind-9.8.2-0.10.rc1.el6.i686.rpm),查看此软件包的依赖性可执行如下命令:
[root@localhost ~]# rpm -qRp /mnt/cdrom/Packages/bind-9.8.2-0.10.rc1.el6.i686.rpm
/bin/bash
/bin/sh
bind-libs = 32:9.8.2-0.10.rc1.el6
chkconfig
chkconfig
config(bind) = 32:9.8.2-0.10.rc1.el6
grep
libbind9.so.80
libc.so.6
libc.so.6(GLIBC_2.0)
libc.so.6(GLIBC_2.1)
…省略部分输出…
注意,这里使用的也是“绝对路径+包全名”的方式。
rmp校验
Linux RPM包验证和数字证书
2022-05-07 110举报
简介: 执行 rpm -qa 命令可以看到,Linux 系统中装有大量的 RPM 包,且每个包都含有大量的安装文件。因此,为了能够及时发现文件误删、误修改文件数据、恶意篡改文件内容等问题,Linux 提供了以下两种监控(检测)方式:
执行 rpm -qa 命令可以看到,Linux 系统中装有大量的 RPM 包,且每个包都含有大量的安装文件。因此,为了能够及时发现文件误删、误修改文件数据、恶意篡改文件内容等问题,Linux 提供了以下两种监控(检测)方式:
RPM 包校验:其实就是将已安装文件和 /var/lib/rpm/ 目录下的数据库内容进行比较,确定文件内容是否被修改。
RPM 包数字证书校验:用来校验 RPM 包本身是否被修改。
更多看https://developer.aliyun.com/article/910323?spm=a2c6h.13262185.profile.56.6f69961fYrL5Vd
srmp
https://developer.aliyun.com/article/910325?spm=a2c6h.13262185.profile.55.6f69961fYrL5Vd
yum -RPM包的依赖性及其解决方案
RPM 软件包(包含 SRPM 包)的依赖性主要体现在 RPM 包安装与卸载的过程中。
例如,如果采用最基础的方式(基础服务器方式)安装Linux 系统,则 gcc 这个软件是没有安装的,需要自己手工安装。当你使用 rpm 命令安装 gcc 软件的 RPM 包,就会发生依赖性错误,错误提示信息如下所示:
[root@localhost ~]# rpm -ivh /mnt/cdrom/Packages/ gcc-4.4.6-4.el6.i686.rpm
error: Failed dependencies: <―依赖性错误
cloog-ppi >= 0.15 is needed by gcc-4.4.6-4.el6.i686
cpp = 4.4.6-4.el6 is needed by gcc-4.4.6-4.el6.i686
glibc-devel >= 2.2.90-12 is needed by gcc-4.4.6-4.el6.i686
报错信息提示我们,如果要安装 gcc,需要先安装 cloog-ppl、cpp 和 glibc-devel 三个软件,这体现的就是 RPM 包的依赖性。
除此之外,报错信息中还会明确给出各个依赖软件的版本要求:
“>=”:表示版本要大于或等于所显示版本;
“<=”:表示版本要小于或等于所显示版本;
“=”:表示版本要等于所显示版本;
Linux 系统中,RPM 包之间的依赖关系大致可分为以下 3 种:
树形依赖(A-B-C-D):要想安装软件 A,必须先安装 B,而安装 B 需要先安装 C…….解决此类型依赖的方法是从后往前安装,即先安装 D,再安装 C,然后安装 B,最后安装软件 A。
环形依赖(A-B-C-D-A):各个软件安装的依赖关系构成“环状”。解决此类型依赖的方法是用一条命令同时安装所有软件包,即使用 rpm -ivh 软件包A 软件包B …。
模型依赖:软件包的安装需要借助其他软件包的某些文件(比如库文件),解决模块依赖最直接的方式是通过 http://www.linuxyz.cn//file/20211225/vivnwls0anx.net 网站找到包含此文件的软件包,安装即可。
以上 3 种 RPM 包的依赖关系,给出的解决方案都是手动安装,比较麻烦。在后续的章节中,我们将系统学习使用 yum 命令查询、安装、升级和卸载软件包的方法。
yum,全称"Yellow dog Updater,Modified",CentOS 系统上的软件包管理器,它能够自动下载 RPM 包并安装,更重要的是,它可以自动处理软件包之间的依赖性关系,一次性安装所有依赖的软件包,无需一个个安装。
常用命令
yum查询命令
使用 yum 对软件包执行查询操作,常用命令可分为以下几种:
yum list:查询所有已安装和可安装的软件包。例如:
[root@localhost yum.repos.d]# yum list
#查询所有可用软件包列表
Installed Packages
#已经安装的软件包
ConsdeKit.i686 0.4.1-3.el6
@anaconda-CentOS-201207051201 J386/6.3
ConsdeKit-libs.i686 0.4.1-3.el6 @anaconda-CentOS-201207051201 J386/6.3
…省略部分输出…
Available Packages
#还可以安装的软件包
389-ds-base.i686 1.2.10.2-15.el6 c6-media
389-ds-base-devel.i686 1.2.10.2-15.el6 c6-media
#软件名 版本 所在位置(光盘)
…省略部分输出…
yum list 包名:查询执行软件包的安装情况。例如:
[root@localhost yum.repos.d]# yum list samba
Available Packages samba.i686 3.5.10-125.el6 c6-media
#查询 samba 软件包的安装情况
yum search 关键字:从 yum 源服务器上查找与关键字相关的所有软件包。例如:
[root@localhost yum.repos.d]# yum search samba
#搜索服务器上所有和samba相关的软件包
========================N/S Matched:
samba =============================
samba-client.i686:Samba client programs
samba-common.i686:Files used by both Samba servers and clients
samba-doc.i686: Documentation for the Samba suite
…省略部分输出…
Name and summary matches only, use"search all" for everything.
yum info 包名:查询执行软件包的详细信息。例如:
[root@localhost yum.repos.d]# yum info samba
#查询samba软件包的信息
Available Packages <-没有安装
Name : samba <-包名
Arch : i686 <-适合的硬件平台
Version : 3.5.10 <―版本
Release : 125.el6 <—发布版本
Size : 4.9M <—大小
Repo : c6-media <-在光盘上
…省略部分输出…
yum安装命令
yum 安装软件包的命令基本格式为:
[root@localhost yum.repos.d]# yum -y install 包名
其中:
install:表示安装软件包。
-y:自动回答 yes。如果不加 -y,那么每个安装的软件都需要手工回答 yes;
例如使用此 yum 命令安装 gcc:
[root@localhost yum jepos.d]#yum -y install gcc
#使用yum自动安装gcc
gcc 是 C 语言的编译器,鉴于该软件包涉及到的依赖包较多,建议使用 yum 命令安装。
yum 升级命令
使用 yum 升级软件包,需确保 yum 源服务器中软件包的版本比本机安装的软件包版本高。
yum 升级软件包常用命令如下:
yum -y update:升级所有软件包。不过考虑到服务器强调稳定性,因此该命令并不常用。
yum -y update 包名:升级特定的软件包。
yum 卸载命令
使用 yum 卸载软件包时,会同时卸载所有与该包有依赖关系的其他软件包,即便有依赖包属于系统运行必备文件,也会被 yum 无情卸载,带来的直接后果就是使系统崩溃。
除非你能确定卸载此包以及它的所有依赖包不会对系统产生影响,否则不要使用 yum 卸载软件包。
yum 卸载命令的基本格式如下:
[root@localhost yum.repos.d]# yum remove 包名
#卸载指定的软件包
例如,使用 yum 卸载 samba 软件包的命令如下:
[root@localhost yum.repos.d]# yum remove samba
#卸载samba软件包
yum软件组
yum查询软件组包含的软件
既然是软件包组,说明包含不只一个软件包,通过 yum 命令可以查询某软件包组中具体包含的软件包,命令格式如下:
[root@localhost ~]#yum groupinfo 软件组名
#查询软件组中包含的软件
例如,查询 Web Server 软件包组中包含的软件包,可使用如下命令:
[root@localhost ~]#yum groupinfo “Web Server”
#查询软件组"Webserver"中包含的软件
yum安装软件组
使用 yum 安装软件包组的命令格式如下:
[root@localhost ~]#yum groupinstall 软件组名
#安装指定软件组,组名可以由grouplist查询出来
例如,安装 Web Server 软件包组可使用如下命令:
[root@localhost ~]#yum groupinstall “Web Server”
#安装网页服务软件组
yum命令卸载软件组
yum 卸载软件包组的命令格式如下:
[root@localhost ~]# yum groupremove 软件组名
#卸载指定软件组
yum 软件包组管理命令更适合安装功能相对集中的软件包集合。例如,在初始安装 Linux 时没有安装图形界面,但后来发现需要图形界面的支持,这时可以手工安装图形界面软件组(X Window System 和 Desktop),就可以使用图形界面了。
Linux函数库(静态函数库和动态函数库)及其安装过程
简介: Linux 系统中存在大量的函数库。简单来讲,函数库就是一些函数的集合,每个函数都具有独立的功能且能被外界调用。我们在编写代码时,有些功能根本不需要自己实现,直接调用函数库中的函数即可。
Linux 系统中存在大量的函数库。简单来讲,函数库就是一些函数的集合,每个函数都具有独立的功能且能被外界调用。我们在编写代码时,有些功能根本不需要自己实现,直接调用函数库中的函数即可。
需要注意的是,函数库中的函数并不是以源代码的形式存在的,而是经过编译后生成的二进制文件,这些文件无法独立运行,只有链接到我们编写的程序中才可以运行。
Linux 系统中的函数库分为 2 种,分别是静态函数库(简称静态库)和动态函数库(也称为共享函数库,简称动态库或共享库),两者的主要区别在于,程序调用函数时,将函数整合到程序中的时机不同:
静态函数库在程序编译时就会整合到程序中,换句话说,程序运行前函数库就已经被加载。这样做的好处是程序运行时不再需要调用外部函数库,可直接执行;缺点也很明显,所有内容都整合到程序中,编译文件会比较大,且一旦静态函数库改变,程序就需要重新编译。
动态函数库在程序运行时才被加载(如图 1 所示),程序中只保存对函数库的指向(程序编译仅对其做简单的引用)。
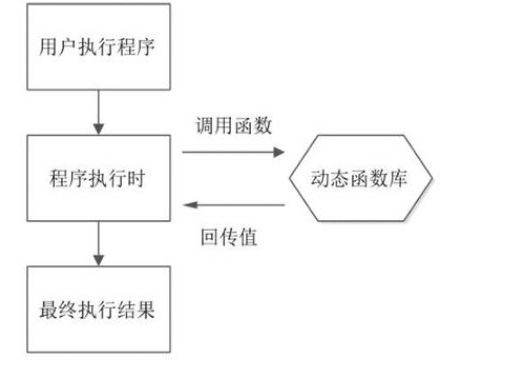
图 1 函数库调用
使用动态函数库的好处是,程序生成的可执行程序体积比较小,且升级函数库时无需对整个程序重新编译;缺点是,如果程序执行时函数库出现问题,则程序将不能正确运行。
Linux 系统中,静态函数库文件扩展名是 “.a”,文件通常命令为 libxxx.a(xxx 为文件名);动态函数库扩展名为 “.so”,文件通常命令为 libxxx.so.major.minor(xxx 为文件名,major 为主版本号,minor 为副版本号)。
目前,Linux 系统中大多数都是动态函数库(主要考虑到软件的升级方便),其中被系统程序调用的函数库主要存放在 “/usr/lib” 和 “/lib” 中;Linux 内核所调用的函数库主要存放在 “/lib/modules” 中。
注意,函数库(尤其是动态函数库)的存放位置非常重要,轻易不要做更改。
Linux 函数库的安装
Linux 发行版众多,不同 Linux 版本安装函数库的方式不同。CentOS 中,安装函数库可直接使用 yum 命令。
例如,安装 curses 函数库命令如下:
[root@Linux ~]# yum install ncurses-devel
正常情况下,函数库安装完成后就可以直接被系统识别,但凡事都有万一。这里先想一个问题,如何查看可执行程序调用了哪些函数库呢?通过以下命令即可:
[root@localhost ~]# ldd -v 可执行文件名
-v 选项的含义是显示详细版本信息(不是必须使用)。
例如,查看 ls 命令调用了哪些函数库,命令如下:
[root@localhost ~]# ldd /bin/ls
linux-gate.so.1 => (0x00d56000)
libselinux.so.1 =>/lib/libselinux.so.1 (0x00cc8000)
librt.so.1 =>/lib/librt.so.1 (0x00cb8000)
libcap.so.2 => /lib/libcap.so.2 (0x00160000)
libacl.so.1 => /lib/libacl.so.1 (0x00140000)
libc.so.6 => /lib/libc.so.6 (0x00ab8000)
libdl.so.2 => /lib/libdl.so.2 (0x00ab0000)
/lib/ld-linux.so.2 (0x00a88000)
libpthread.so.0 => /lib/libpthread.so.0 (0x00c50000)
libattr.so.1 =>/lib/libattr.so.1 (0x00158000)
如果函数库安装后仍无法使用(运行程序时会提示找不到某个函数库),这时就需要对函数库的配置文件进行手动调整,也很简单,只需进行如下操作:
将函数库文件放入指定位置(通常放在 “/usr/lib” 或 “/lib” 中),然后把函数库所在目录写入 “/etc/ld.so.conf” 文件。例如:
[root@localhost ~]# cp .so /usr/lib/
#把函数库复制到/usr/lib/目录中
[root@localhost ~]# vi /etc/ld.so.conf
#修改函数库配置文件
include ld.so.conf.d/.conf
/usr/lib
#写入函数库所在目录(其实/usr/lib/目录默认已经被识别)
注意,这里写入的是函数库所在的目录,而不单单是函数库的文件名。另外,如果自己在其他目录中创建了函数库文件,这里也可以直接在 “/etc/ld.so.conf” 文件中写入函数库文件所在的完整目录。
使用 ldconfig 命令重新读取 /etc/ld.so.conf 文件,把新函数库读入缓存。命令如下:
[root@localhost ~]# ldconfig
#从/etc/ld.so.conf文件中把函数库读入缓存
[root@localhost ~]# ldconfig -p
#列出系统缓存中所有识别的函数库
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Linux脚本程序包及安装方法详解(以webmin为例)
2022-05-07 127举报
简介: 脚本程序并不多见,所以在软件包分类中并没有把它列为一类。它更加类似于 Windows 下的程序安装,有一个可执行的安装程序,只要运行安装程序,然后进行简单的功能定制选择(比如指定安装目录等),就可以安装成功,只不过是在字符界面完成的。
脚本程序并不多见,所以在软件包分类中并没有把它列为一类。它更加类似于 Windows 下的程序安装,有一个可执行的安装程序,只要运行安装程序,然后进行简单的功能定制选择(比如指定安装目录等),就可以安装成功,只不过是在字符界面完成的。
目前常见的脚本程序以各类硬件的驱动居多,我们需要学习一下这类软件的安装方式,以备将来不时之需。
我们来看看脚本程序如何安装和使用。安装一个叫作 Webmin 的工具软件,Webmin 是一个基于 Web 的系统管理界面,借助任何支持表格和表单的浏览器(和 File Manager 模块所需要的Java),你就可以设置用户账号、apache、DNS、文件共享等。
Webmin 包括一个简单的 Web 服务器和许多 CGI 程序,这些程序可以直接修改系统文件,比如 /etc/inetd.conf 和 /etc/passwd。Web 服务器和所有的 CGI 程序都是用 Perl 5 编写的,没有使用任何非标准 Perl 模块。也就是说,Webmin 是一个用 Perl 语言写的、可以通过浏览器管理 Linux 的软件。
webmin安装步骤
首先下载 Webmin 软件,这里下载的是 webmin-1.610.tar.gz。
接下来解压缩软件,命令如下:
[root@localhost ~]# tar -zxvf webmin-1.610.tar.gz
进入解压目录,命令如下:
[root@localhost ~]# cd webmin-1.610
执行安装程序 setup.sh,并指定功能选项,命令如下:
[root@localhost webmin-1.610]# ./setup.sh
* Welcome to the Webmin setup script,version 1.610 *
Webmin is a web-based interface that allows Unix-like operating
systems and common Unix services to be easily administered.
Installing Webmin in /root/webmin-1.610…
Webmin uses separate directories for configuration files and log files.
Unless you want to run multiple versions of Webmin at the same time
you can just accept the defaults.
Config file directory [/etc/webmin]:
#选择安装位置,默认安装在/etc/webmin目录下。
如果安装到默认位置,则直接回车
Log file directory [/var/webmin]:
#日志文件保存位置,直接回车,选择默认位置
Webmin is written entirely in Perl.Please enter the full path to the
Perl 5 interpreter on your system.
Full path to peri (default /usr/bin/perl):
#指定Perl语言的安装位置,直接回车,选择默认位置,Perl默认就安装这里
Testing Perl…
Perl seems to be installed ok
Operating system name: CentOS Linux Operating system version: 6.3
Webmin uses its own password protected web server to provide access to the administration programs.
The setup script needs to know:
-What port to run the web server on.There must not be another web server already using this port.
-The login name required to access the web server.
-The password required to access the web server.
-If the Webserver should use SSL (if your system supports it).
-Whether to start webmin at boot time.
Web server port (default 10000):
#指定Webmin监听的端口,直接回车,默认选定 10000
Login name (default admin):admin #输入登录Webmin的用户名
Login password:
Password again:
#输入登陆密码
The Perl SSLeay library is not installed.SSL not available.
#apache默认没有启动SSl功能,所以SSl没有被激活
Start Webmin at boot time (y/n):y
#是否在开机的同时启动Webmin
…安装过程省略…
Webmin has been installed and started successfully.Use your web browser to go to
http://localhost:10000/
and login with the name and password you entered previously.
#安装完成
用户管理
忘记root密码怎么办
很多新手当面对“忘记 root 账户密码导致无法登陆系统”这个问题时,直接选择重新系统。其实大可不必,我只需要进入 emergency mode(单用户模式)更新 root 账户的密码即可。
Linux 的单用户模式有些类似 Windows 的安全模式,只启动最少的程序用于系统修复。在单用户模式(运行级别为 1)中,Linux 引导进入根 Shell,网络被禁用,只有少数进程运行。
单用户模式可以用来修改文件系统损坏、还原配置文件、移动用户数据等。
破解密码这么简单,Linux是安全的操作系统吗?
很多人看到系统修复模式这节内容时,都会有所感慨:Linux 的密码破解太容易了,这样的操作系统还安全吗?Linux 不是以安全性著称的吗?
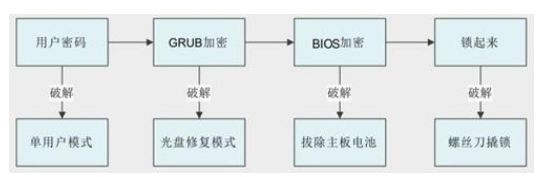
本节,我们结合图 1 解释一下类似的问题。
我们一开始始为了安全,给用户设定密码,但是这样密码可以很容易地被单用户模式破解。我们又想到,进入单用户模式,需要在 GRUB 启动界面上按"e"键,那么我们就给 GRUB 加密,必须输入正确的 GRUB 密码,才能进入 GRUB 的编辑界面,这样就保证了用户密码的安全。
不过,GRUB 加密是可以通过进入光盘修复模式,直接删除 GRUB 配置文件中的 password 行而被破解的。接着我们又想到,进入光盘修复模式,是需要通过光盘启动系统的,那么我们给 BIOS 加密,这样就必须输入正确的 BIOS 密码,才能修改光盘的启动顺序。但是 BIOS 加密是可以通过拔除主板电池而删除的。那我们只能把服务器机箱锁起来,但只是一把锁而已,完全可以被螺丝刀撬开!
其实,这里是大家对概念的理解有误。任何一个需要密码的设备,不论是 Windows、Linux、交换机、路由器,还是一个需要密码的软件,都必须留有破解密码的漏洞。如果我们的计算机没有破解密码的方法,那么万一忘记了计算机的密码,难道要重新买一台吗(如果忘记了 BIOS 密码,又不能破解,当然不能重新安装系统了)?
当然不能是这样的,所以这些漏洞是必须预留的。这些漏洞是不会影响系统安全的,因为我们可以拿到计算机本身。如果我们能够拿到计算机,就认为我们对这台计算机拥有所有权。我们所说的安全性主要是指在对计算机没有所有权时要保证绝对安全。
而且大家要注意,如果 root 没有密码,那么本机登录是没有任何问题的,但是不可能远程登录。所以我们所说的安全性主要针对的是网络安全。
添加用户
useradd <username>
eg: useradd xiaoli
在添加 Linux 用户之前,可以先列出现有用户,来保证不添加有冲突的用户名:
cat /etc/passwd | cut -d : -f 1
更多用法
useradd testuser # 创建新用户 testuser
useradd -d /home/mytest testuser # -d 参数可以自定义主目录。默认情况下将在/home路径中创建一个与用户名同名的家目录
useradd -u 567 testuser # -u 参数可以指定新用户的用户ID(UID)。默认情况下用户ID从500开始,并在添加新用户后递增
useradd -g 0 testuser # -g 参数可以指定新用户的用户组ID。默认情况下,将分配新的用户组ID,该ID从1000开始
useradd -G group1,group2,group3 testuser # -G 参数可以将新用户添加到多个用户组
useradd -M testuser # -M 参数将添加没有主目录的新用户
useradd -e 2023-02-28 testuser # -e 参数可以设置新用户的账户过期日期
chage -l testuser # 在添加了具有帐户过期日期的用户后,可以使用chage命令检查该日期
useradd -e 2023-02-28 -f 60 testuser # -f 参数可以设置新用户的密码过期时间。如果值设为-1,密码将永不过期
useradd -c "18811372815" testuser # -c 参数可以设置新用户的注释信息,例如添加全名、电话号码等
设置用户密码
passwd <username>
#然后就会提示输入两次密码
切换用户
su <username>
su 是 switch user 的缩写,表示用户切换 。
- su 命令在不加参数时,默认切换到 root 用户,输入 root 的密码后切换到 root 身份,使用 exit 退出。注意这里虽然切换到 root,但实际上并没有自动切换家目录。
- su 命令加上一个
-参数,可以切换成 root 身份,同时应用 root 的环境(进入对应目录)。 - su 命令加上
-参数,可以切换成 - 选项表示在切换用户身份的同时,连当前使用的环境变量也切换成指定用户的。我们知道,环境变量是用来定义操作系统环境的,因此如果系统环境没有随用户身份切换,很多命令无法正确执行。
举个例子,普通用户 lamp 通过 su 命令切换成 root 用户,但没有使用 - 选项,这样情况下,虽然看似是 root 用户,但系统中的 $PATH 环境变量依然是 lamp 的(而不是 root 的),因此当前工作环境中,并不包含 /sbin、/usr/sbin等超级用户命令的保存路径,这就导致很多管理员命令根本无法使用。不仅如此,当 root 用户接受邮件时,会发现收到的是 lamp 用户的邮件,因为环境变量 $MAIL 也没有切换。
初学者可以这样理解它们之间的区别,即有 - 选项,切换用户身份更彻底;反之,只切换了一部分,这会导致某些命令运行出现问题或错误(例如无法使用 service 命令)。
root用su至其他用户无须密码;但非root用户切换时需要密码
su 是最简单的用户切换命令,通过该命令可以实现任何身份的切换,包括从普通用户切换为 root 用户、从 root 用户切换为普通用户以及普通用户之间的切换。
普通用户之间切换以及普通用户切换至 root 用户,都需要知晓对方的密码,只有正确输入密码,才能实现切换;从 root 用户切换至其他用户,无需知晓对方密码,直接可切换成功。
删除用户(还怪麻烦的……用到再搜吧)
userdel
- 检查登录
首先查看用户是否真正登录,以及他正在处理多少个会话。使用 who 命令列出活动会话。
- 查看用户进程
使用 ps 命令可以列出用户正在运行的进程。
ps -u
使用 top 命令可以看到正在运行的进程的更多信息。top 也具有 -U 选项,可以输出单个用户拥有的进程。注意这里 U 是大写的。
top -U
- 锁定账户
在终止进程前,先锁定账户。因为在终止进程时将注销用户。
加密的用户密码存储在 /etc/shadow 文件中。使用 awk 命令分析该文件中的字段并有选择地对其进行操作。使用 -F 选项来告诉 awk 该文件使用冒号 ”:“ 分隔字段。搜索其中带有 test 字段的行,并对匹配的行打印第一个和第二个字段,分别为账户名和加密的密码:
sudo awk -F: ‘/test/ {print $1,$2}’ /etc/shadow
使用 passwd -l 命令锁定账户。
再次检查 /etc/shadow 文件:
加密密码的开头添加了感叹号,这样就可以阻止登录该账户。
- 杀死进程
使用 pkill 命令查找并杀死进程。
sudo pkill -KILL -u
这样用户 test 的会话没有了。接下来进行其余的清理工作。
- 归档用户的主目录
使用 tar 命令归档用户的主目录。使用的选项有:
c:创建一个存档目录
f:使用指定的文件名作为存档名称
j:使用 bzip2 压缩
v:在创建归档文件时提供详细的输出
sudo tar cfjv test-20220328.tar.bz /home/test
————————————————
版权声明:本文为CSDN博主「夢的点滴」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_50836306/article/details/123709646
bashrc等用户设置文件
介绍
在linux系统普通用户目录(cd /home/xxx)或root用户目录(cd /root)下,用指令ls -al可以看到4个隐藏文件,
- .bash_history 记录之前输入的命令
- .bash_logout 当你退出时执行的命令
- .bash_profile 当你登入shell时执行
- .bashrc 当你登入shell时执行
请注意后两个的区别:.bash_profile只在会话开始时被读取一次,而.bashrc则每次打开新的终端时,都要被读取。
这些文件是每一位用户对终端功能和属性设置,修改.bashrc可以改变环境变量PATH、别名alias和提示符。具体如何修改会在下面做介绍。
除了可以修改用户目录下的.bashrc文件外,还可以修改如“/etc/profile”文件、“/etc/bashrc”文件及目录“/etc /profile.d”下的文件。但是修改/etc路径下的配置文件将会应用到整个系统,属于系统级的配置,而修改用户目录下的.bashrc则只是限制在用户应用上,属于用户级设置。两者在应用范围上有所区别,建议如需修改的话,修改用户目录下的.bashrc,即无需root权限,也不会影响其他用户。
bashrc的应用
PATH环境变量修改
PATH变量决定了shell 将到哪些目录中寻找命令或程序。如果要执行的命令的目录在 PATH 中,您就不必输入这个命令的完整路径,直接输入命令就可以了。
-
首先,作为惯例,所有环境变量名都是大写。由于 Linux 区分大小写,这点您要留意。
-
第二点是变量名有时候以
$开头,但有时又不是。当设置一个变量时,直接用名称,而不需要加$,如
PATH=/usr/bin:/usr/local/bin:/bin
假如要获取变量值的话,就要在变量名前加’$’:
echo $PATH
则会显示当前设置的PATH变量“/usr/bin:/usr/local/bin:/bin”
否则的话,变量名就会被当作普通文本了:
echo PATH
显示“PATH” -
处理 $PATH 变量要注意的第三点是:您不能只替换变量,而是要将新的字符串添加到原来的值中。在大多数情况下,您不能用
PATH=/some /directory,因为这将删除$PATH中其他的所有目录,这样您在该终端运行程序时,就不得不给出完整路径。所以,只能作添加:PATH=$PATH:/some/directory,假如你要添加/usr/local/arm/3.4.1/bin交叉编译命令,则操作为PATH=$PATH:/usr/local/arm/3.4.1/bin
这样,PATH 被设成当前的值(以$PATH来表示)+新添的目录。
到目前为止,你只为当前终端设置了新的 $PATH 变量。如果您打开一个新的终端,运行 echo $PATH ,将显示旧的 $PATH 值,而看不到你刚才添加的新目录。因为你先前定义的是一个局部环境变量(仅限于当前的终端)。
要定义一个全局变量,使在以后打开的终端中生效,您需要将局部变量输出(export),可以用”export”命令:export PATH=$PATH:/some/directory
现在如果打开一个新的终端,输入 echo $PATH ,也能看到新设置的$PATH 了。请注意,命令export只能改变当前终端及以后运行的终端里的变量。对于已经运行的终端没有作用。
为了将目录永久添加到 $PATH ,只要将export的那行添加到.bashrc或/etc/bashrc文件中。
alias别名
一般在.bashrc或/etc/bashrc文件里有几句话
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
有了这几句话,当在终端中输入“mv test.c led.c”实际上输入的是“mv -i test.c led.c”,所以说alias是一个别名。你可以在该配置文件中添加自己风格的别名,如“alias ll=’ls -l’”,只需要在终端中输入“ll”就实现了“ls -l”的功能。还可以添加其他语句,随自己喜好。
提示符
当打开一个控制台(console) 时,最先看到的就是提示符(prompt),如:[root@localhost ~]#
在默认设置下,提示符将显示用户名、主机名(默认是localhost)、当前所在目录(在 Unix 中,~表示您的 home 目录)。
按照传统,最后一个字符可以标识普通用户($),还是root(#)。
可以通过 $PS1 变量来设置提示符。
命令echo $PS1,将显示当前的设定。其中可用字符的含义在 man bash 的PROMPTING部分有说明。
如何才能完成理想的设置呢?对于健忘的初学者来讲,默认设定有些不友好,因为提示符只显示当前目录的最后一部分。如果你看到象这样的提示符
[wsf@localhost bin]$
则当前目录可能是/bin、/usr/bin、/usr/local/bin及/usr/X11R6/bin。当然,你可以用
pwd (输出当前目录,print working directory)
能不能叫 shell 自动告诉你当前目录呢?
当然可以。这里我将提到的设定,包括提示符,大都包含在文件/etc/bashrc中。您可以通过编辑各自 home 目录下的.bash_profile和.bashrc来改变设置。
在 man bash 中的’PROMPTING’部分,对这些参数(parameter)有详细说明。您可以加入一些小玩意,如不同格式的当前时间,命令的历史记录号,甚至不同的颜色。
一种更适当的设定:
PS1=”[\u: \w]$ ”
这样,提示符就变成:
[wsf: /usr/bin]$
你可以通过命令 export 来测试不同的设置(比如,export PS1=”\u: \w$ “)。如果找到了适合的提示符,就将设置放到您的’.bashrc”中。这样,每次打开控制台或终端窗口时,都会生效。
举例,生效方式
这个文件主要保存个人的一些个性化设置,如命令别名、路径等。下面是个例子:
# User specific aliases and functions
PATH="/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin"
LANG=zh_CN.GBK
export PATH LANG
alias rm='rm -i'
alias ls='/bin/ls -F --color=tty --show-control-chars'
例子中定义了路径,语言,命令别名(使用rm删除命令时总是加上-i参数需要
用户确认,使用ls命令列出文件列表时加上颜色显示)。
每次修改.bashrc后,使用source ~/.bashrc(或者 . ~/.bashrc)
就可以立刻加载修改后的设置,使之生效。
一般会在.bash_profile文件中显式调用.bashrc。登陆linux启动bash时首先会
去读取/.bash_profile文件,这样/.bashrc也就得到执行了,你的个性化设置也就生效了。
别忘了source应用设置项
1、source命令是什么?
source命令也称为“点命令”,也就是一个点符号(.),是bash的内部命令。
注意:该命令通常用命令“.”来替代
2、source命令 功能(能干什么)?
source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。因为linux所有的操作都会变成文件的格式存在。
示例:
当我修改了/etc/profile文件,我想让它立刻生效,而不用重新登录;这时就想到用source命令,如:source /etc/profile
用法
Linux系统中,source命令通常用.来代替,是一个点命令,与一般的命令有所不同。
source
source filename
作用是在当前bash环境下读取并执行Filename中的命令。由于该命令可以用“.”来替代,例如
source filename
. filename
source cmd.txt #可以将txt的当作shell执行
source命令的一个妙用
在编译核心时,常常要反复输入一长串命令,如
make mrproper
make menuconfig
make dep
make clean
make bzImage
这些命令既长,又繁琐。而且有时候容易输错,浪费你的时间和精力。如果把这些命令做成一个文件,让它自动按顺序执行,对于需要多次反复编译核心的用户来说,会很方便。
用source命令可以办到这一点。它的作用就是把一个文件的内容当成是shell来执行。
先在/usr/src/linux-2.4.20目录下建立一个文件,取名为make_command,在其中输入如下内容:
make mrproper &&
make menuconfig &&
make dep &&
make clean &&
make bzImage &&
make modules &&
make modules_install &&
cp arch/i386/boot/bzImge /boot/vmlinuz_new &&
cp System.map /boot &&
vi /etc/lilo.conf &&
lilo -v
文件建立好之后,以后每次编译核心,只需要在/usr/src/linux-2.4.20下输入source make_command 就行了。这个文件也完全可以做成脚本,只需稍加改动即可。
shell编程中的命令有时和C语言是一样的。&&表示与,||表示或。把两个命令用&&联接起来,如 make mrproper && make menuconfig,表示要第一个命令执行成功才能执行第二个命令。对执行顺序有要求的命令能保证一旦有错误发生,下面的命令不会盲目地继续执行。
source filename 与 sh filename 及./filename执行脚本的区别
当shell脚本具有可执行权限时,用sh filename与./filename执行脚本是没有区别得。./filename是因为当前目录没有在PATH中,所有”.”是用来表示当前目录的。
sh filename 重新建立一个子shell,在子shell中执行脚本里面的语句,该子shell继承父shell的环境变量,但子shell新建的、改变的变量不会被带回父shell。
source filename:这个命令其实只是简单地读取脚本里面的语句依次在当前shell里面执行,没有建立新的子shell。那么脚本里面所有新建、改变变量的语句都会保存在当前shell里面。
source 以及 . 直接在当前的进程中读取脚本的配置,不会开一个新的进程!
source会将脚本的内容直接影响到父进程的(因为它不开辟新线程,可以说是直接在当前进程中加入脚本的执行内容)。所以你source之后,里面配置的变量都会加入到当前环境中,你可以在该shell中调用脚本中的变量!
而./xx.sh 以及 sh xx.sh
是在当前进程下新开一个子shell进程运行这个脚本,当脚本运行完毕了,sh中设置的变量和子进程一起被销毁了!(该子shell继承了父进程的shell的环境变量,子shell结束了变量将被销毁,如果使用了export可以将子shell的变量反馈到父级别的shell中)
sudo
sudo是linux系统管理指令,是允许系统管理员让普通用户执行一些或者全部的root命令的一个工具,如halt,reboot,su等等。这样不仅减少了root用户的登录 和管理时间,同样也提高了安全性。sudo不是对shell的一个代替,它是面向每个命令的。(百度百科)
- sudo 能够授权指定用户在指定主机上运行某些命令。 如果未授权用户尝试使用 sudo,会提示联系管理员。
- sudo 可以提供日志,记录每个用户使用sudo操作,以便于日后审计。
- sudo 为系统管理员提供配置文件,允许系统管理员集中地管理用户的使用权限和使用的主机。
- sudo 默认存活期为5分钟。
配置文件: /etc/sudoers, /etc/sudoers.d/
时间戳文件: /var/db/sudo
日志文件: /var/log/secure
详细怎么配置 以后用到再看
sudo命令
sudo -u centos 切换身份
-V 显示版本信息等配置信息
-u user 默认为root
-l 列出当前用户可以使用的所有sudo命令
-v 再延长密码有效期限5分钟,更新时间戳
-k 认证信息失效,清除时间戳(1970-01-01),下次需要重新输密码
-b 在后台执行指令
su : 切换到某某用户模式,提示输入密码时该密码为切换后账户的密码,用法为“su 账户名称”。如果后面不加账户时系统默认为root账户,密码也为超级账户的密码。没有时间限制。
-i: 为了频繁的执行某些只有超级用户才能执行的权限,而不用每次输入密码,可以使用该命令。提示输入密码时该密码为当前账户的密码。没有时间限制。执行该命令后提示符变为“#”而不是“$”。想退回普通账户时可以执行“exit”或“logout” 。 要求执行该命令的用户必须在sudoers中才可以。
su方式切换是须要输入目标用户的password。而sudo仅仅须要输入自己的password,所以sudo能够保护目标用户的password不对外泄漏。
- sudo授权时passwd,su,sudo,sudoedit,visudo等具有特殊意义的命令时,务必要考虑全面(例如禁止修改root用户的密码等操作)。
sudo su 与 sudo su - 区别
sudo su 切换root身份,不携带当前用户环境变量。
sudo su - 切换root身份,携带当前用户环境变量
sudo -i root与sudo - root、sudo -i ,sudo - ,sudo root效果相同,都是切换到root用户。输入的是当前用户的密码。但是su -i,也是切换到root用户,输入的是root的用户名密码。
故,常用sudo -命令。可以通过输入当前用户密码,具备root用户权限。
我们知道,使用 su 命令可以让普通用户切换到 root 身份去执行某些特权命令,但存在一些问题,比如说:
仅仅为了一个特权操作就直接赋予普通用户控制系统的完整权限;
当多人使用同一台主机时,如果大家都要使用 su 命令切换到 root 身份,那势必就需要 root 的密码,这就导致很多人都知道 root 的密码;
考虑到使用 su 命令可能对系统安装造成的隐患,最常见的解决方法是使用 sudo 命令,此命令也可以让你切换至其他用户的身份去执行命令。
相对于使用 su 命令还需要新切换用户的密码,sudo 命令的运行只需要知道自己的密码即可,甚至于,我们可以通过手动修改 sudo 的配置文件,使其无需任何密码即可运行。
sudo 命令默认只有 root 用户可以运行,该命令的基本格式为:
[root@localhost ~]# sudo [-b] [-u 新使用者账号] 要执行的命令
常用的选项与参数:
-b :将后续的命令放到背景中让系统自行运行,不对当前的 shell 环境产生影响。
-u :后面可以接欲切换的用户名,若无此项则代表切换身份为 root 。
-l:此选项的用法为 sudo -l,用于显示当前用户可以用 sudo 执行那些命令。
【例 1】
[root@localhost ~]# grep sshd /etc/passwd
sshd❌74:74:privilege-separated SSH:/var/empty/sshd:/sbin.nologin
[root@localhost ~]# sudo -u sshd touch /tmp/mysshd
[root@localhost ~]# ll /tmp/mysshd
-rw-r–r-- 1 sshd sshd 0 Feb 28 17:42 /tmp/mysshd
本例中,无法使用 su - sshd 的方式成功切换到 sshd 账户中,因为此用户的默认 Shell 是 /sbin/nologin。这时就显现出 sudo 的优势,我们可以使用 sudo 以 sshd 的身份在 /tmp 目录下创建 mysshd 文件,可以看到,新创建的 mysshd 文件的所有者确实是 sshd。
【例 2】
[root@localhost ~]# sudo -u vbird1 sh -c “mkdir ~vbird1/www; cd ~vbird1/www;
> echo ‘This is index.html file’ > index.html”
[root@localhost ~]# ll -a ~vbird1/www
drwxr-xr-x 2 vbird1 vbird1 4096 Feb 28 17:51 .
drwx------ 5 vbird1 vbird1 4096 Feb 28 17:51 …
-rw-r–r-- 1 vbird1 vbird1 24 Feb 28 17:51 index.html
这个例子中,使用 sudo 命令切换至 vbird1 身份,并运行 sh -c 的方式来运行一连串的命令。
前面说过,默认情况下 sudo 命令只有 root 身份可以使用,那么,如何让普通用户也能使用它呢?
解决这个问题之前,先给大家分析一下 sudo 命令的执行过程。sudo命令的运行,需经历如下几步:
当用户运行 sudo 命令时,系统会先通过 /etc/sudoers 文件,验证该用户是否有运行 sudo 的权限;
确定用户具有使用 sudo 命令的权限后,还要让用户输入自己的密码进行确认。出于对系统安全性的考虑,如果用户在默认时间内(默认是 5 分钟)不使用 sudo 命令,此后使用时需要再次输入密码;
密码输入成功后,才会执行 sudo 命令后接的命令。
显然,能否使用 sudo 命令,取决于对 /etc/sudoers 文件的配置(默认情况下,此文件中只配置有 root 用户)。所以接下来,我们学习对 /etc/sudoers 文件进行合理的修改。
sudo命令的配置文件/etc/sudoers
修改 /etc/sudoers,不建议直接使用 vim,而是使用 visudo。因为修改 /etc/sudoers 文件需遵循一定的语法规则,使用 visudo 的好处就在于,当修改完毕 /etc/sudoers 文件,离开修改页面时,系统会自行检验 /etc/sudoers 文件的语法。
因此,修改 /etc/sudoers 文件的命令如下:
[root@localhost ~]# visudo
…省略部分输出…
root ALL=(ALL) ALL <–大约 76 行的位置
# %wheel ALL=(ALL) ALL <–大约84行的位置
#这两行是系统为我们提供的模板,我们参照它写自己的就可以了
…省略部分输出…
通过 visudo 命令,我们就打开了 /etc/sudoers 文件,可以看到如上显示的 2 行信息,这是系统给我们提供的 2 个模板,分别用于添加用户和群组,使其能够使用 sudo 命令。
这两行模板的含义分为是:
root ALL=(ALL) ALL
#用户名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径)
#%wheel ALL=(ALL) ALL
#%组名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径)
表 1 对以上 2 个模板的各部分进行详细的说明。
模块 含义
用户名或群组名 表示系统中的那个用户或群组,可以使用 sudo 这个命令。
被管理主机的地址 用户可以管理指定 IP 地址的服务器。这里如果写 ALL,则代表用户可以管理任何主机;如果写固定 IP,则代表用户可以管理指定的服务器。如果我们在这里写本机的 IP 地址,不代表只允许本机的用户使用指定命令,而是代表指定的用户可以从任何 IP 地址来管理当前服务器。
可使用的身份 就是把来源用户切换成什么身份使用,(ALL)代表可以切换成任意身份。这个字段可以省略。
授权命令 表示 root 把什么命令命令授权给用户,换句话说,可以用切换的身份执行什么命令。需要注意的是,此命令必须使用绝对路径写。默认值是 ALL,表示可以执行任何命令。
【例 3】
授权用户 lamp 可以重启服务器,由 root 用户添加,可以在 /etc/sudoers 模板下添加如下语句:
[root@localhost ~]# visudo
lamp ALL=/sbin/shutdown -r now
注意,这里也可以写多个授权命令,之间用逗号分隔。用户 lamp 可以使用 sudo -l 查看授权的命令列表:
[root@localhost ~]# su - lamp
#切换成lamp用户
[lamp@localhost ~]$ sudo -l
[sudo] password for lamp:
#需要输入lamp用户的密码
User lamp may run the following commands on this host:
(root) /sbin/shutdown -r now
可以看到,lamp 用户拥有了 shutdown -r now 的权限。这时,lamp 用户就可以使用 sudo 执行如下命令重启服务器:
[lamp@localhost ~]$ sudo /sbin/shutdown -r now
再次强调,授权命令要使用绝对路径(或者把 /sbin 路径导入普通用户 PATH 路径中,不推荐使用此方式),否则无法执行。
【例 4】
假设现在有 pro1,pro2,pro3 这 3 个用户,还有一个 group 群组,我们可以通过在 /etc/sudoers 文件配置 wheel 群组信息,令这 3 个用户同时拥有管理系统的权限。
首先,向 /etc/sudoers 文件中添加群组配置信息:
[root@localhost ~]# visudo
…(前面省略)…
%group ALL=(ALL) ALL
#在 84 行#wheel这一行后面写入
此配置信息表示,group 这个群组中的所有用户都能够使用 sudo 切换任何身份,执行任何命令。接下来,我们使用 usermod 命令将 pro1 加入 group 群组,看看有什么效果:
[root@localhost ~]# usermod -a -G group pro1
[pro1@localhost ~]# sudo tail -n 1 /etc/shadow <==注意身份是 pro1
…(前面省略)…
Password: <==输入 pro1 的口令喔!
pro3: 1 1 1GfinyJgZ$9J8IdrBXXMwZIauANg7tW0:14302:0:99999:7:::
[pro2@localhost ~]# sudo tail -n 1 /etc/shadow <==注意身份是 pro2
Password:
pro2 is not in the sudoers file. This incident will be reported.
#此错误信息表示 pro2 不在 /etc/sudoers 的配置中。
可以看到,由于 pro1 加入到了 group 群组,因此 pro1 就可以使用 sudo 命令,而 pro2 不行。同样的道理,如果我们想让 pro3 也可以使用 sudo 命令,不用再修改 /etc/sudoers 文件,只需要将 pro3 加入 group 群组即可。
SELinux-加强权限管理
SELinux是什么
2022-05-08 78举报
简介: SELinux,Security Enhanced Linux 的缩写,也就是安全强化的 Linux,是由美国国家安全局(NSA)联合其他安全机构(比如 SCC 公司)共同开发的,旨在增强传统 Linux 操作系统的安全性,解决传统 Linux 系统中自主访问控制(DAC)系统中的各种权限问题(如 root 权限过高等)。
SELinux,Security Enhanced Linux 的缩写,也就是安全强化的 Linux,是由美国国家安全局(NSA)联合其他安全机构(比如 SCC 公司)共同开发的,旨在增强传统 Linux 操作系统的安全性,解决传统 Linux 系统中自主访问控制(DAC)系统中的各种权限问题(如 root 权限过高等)。
SELinux 项目在 2000 年以 GPL 协议的形式开源,当 Red Hat 在其 Linux 发行版本中包括了 SELinux 之后,SELinux 才逐步变得流行起来。现在,SELinux 已经被许多组织广泛使用,几乎所有的 Linux 内核 2.6 以上版本,都集成了 SELinux 功能。
对于 SELinux,初学者可以这么理解,它是部署在 Linux 上用于增强系统安全的功能模块。
我们知道,传统的 Linux 系统中,默认权限是对文件或目录的所有者、所属组和其他人的读、写和执行权限进行控制,这种控制方式称为自主访问控制(DAC)方式;而在 SELinux 中,采用的是强制访问控制(MAC)系统,也就是控制一个进程对具体文件系统上面的文件或目录是否拥有访问权限,而判断进程是否可以访问文件或目录的依据,取决于 SELinux 中设定的很多策略规则。
说到这里,读者有必要详细地了解一下这两个访问控制系统的特点:
自主访问控制系统(Discretionary Access Control,DAC)
是 Linux 的默认访问控制方式,也就是依据用户的身份和该身份对文件及目录的 rwx 权限来判断是否可以访问。不过,在 DAC 访问控制的实际使用中我们也发现了一些问题:
root 权限过高,rwx 权限对 root 用户并不生效,一旦 root 用户被窃取或者 root 用户本身的误操作,都是对 Linux 系统的致命威胁。
Linux 默认权限过于简单,只有所有者、所属组和其他人的身份,权限也只有读、写和执行权限,并不利于权限细分与设定。
不合理权限的分配会导致严重后果,比如给系统敏感文件或目录设定 777 权限,或给敏感文件设定特殊权限——SetUID 权限等。
强制访问控制(Mandatory Access Control,MAC)是通过 SELinux 的默认策略规则来控制特定的进程对系统的文件资源的访问。也就是说,即使你是 root 用户,但是当你访问文件资源时,如果使用了不正确的进程,那么也是不能访问这个文件资源的。
这样一来,SELinux 控制的就不单单只是用户及权限,还有进程。每个进程能够访问哪个文件资源,以及每个文件资源可以被哪些进程访问,都靠 SELinux 的规则策略来确定。
注意,在 SELinux 中,Linux 的默认权限还是有作用的,也就是说,一个用户要能访问一个文件,既要求这个用户的权限符合 rwx 权限,也要求这个用户的进程符合 SELinux 的规定。
不过,系统中有这么多的进程,也有这么多的文件,如果手工来进行分配和指定,那么工作量过大。所以 SELinux 提供了很多的默认策略规则,这些策略规则已经设定得比较完善,我们稍后再来学习如何查看和管理这些策略规则。
为了使读者清楚地了解 SELinux 所扮演的角色,这里举一个例子,假设 apache 上发现了一个漏洞,使得某个远程用户可以访问系统的敏感文件(如 /etc/shadow)。如果我们的 Linux 中启用了 SELinux,那么,因为 apache 服务的进程并不具备访问 /etc/shadow 的权限,所以这个远程用户通过 apache 访问 /etc/shadow文件就会被 SELinux 所阻挡,起到保护 Linux 系统的作用。
组管理
Linux 是多用户多任务操作系统,换句话说,Linux 系统支持多个用户在同一时间内登陆,不同用户可以执行不同的任务,并且互不影响。
例如,某台 Linux 服务器上有 4 个用户,分别是 root、www、ftp 和 mysql,在同一时间内,root 用户可能在查看系统日志、管理维护系统;www 用户可能在修改自己的网页程序;ftp 用户可能在上传软件到服务器;mysql 用户可能在执行自己的 SQL 查询,每个用户互不干扰,有条不紊地进行着自己的工作。与此同时,每个用户之间不能越权访问,比如 www 用户不能执行 mysql 用户的 SQL 查询操作,ftp 用户也不能修改 www 用户的网页程序。
不同用户具有不问的权限,毎个用户在权限允许的范围内完成不间的任务,Linux 正是通过这种权限的划分与管理,实现了多用户多任务的运行机制。
因此,如果要使用 Linux 系统的资源,就必须向系统管理员申请一个账户,然后通过这个账户进入系统(账户和用户是一个概念)。通过建立不同属性的用户,一方面可以合理地利用和控制系统资源,另一方面也可以帮助用户组织文件,提供对用户文件的安全性保护。
每个用户都有唯一的用户名和密码。在登录系统时,只有正确输入用户名和密码,才能进入系统和自己的主目录。
用户组是具有相同特征用户的逻辑集合。简单的理解,有时我们需要让多个用户具有相同的权限,比如查看、修改某一个文件的权限,一种方法是分别对多个用户进行文件访问授权,如果有 10 个用户的话,就需要授权 10 次,那如果有 100、1000 甚至更多的用户呢?
显然,这种方法不太合理。最好的方式是建立一个组,让这个组具有查看、修改此文件的权限,然后将所有需要访问此文件的用户放入这个组中。那么,所有用户就具有了和组一样的权限,这就是用户组。
将用户分组是 Linux 系统中对用户进行管理及控制访问权限的一种手段,通过定义用户组,很多程序上简化了对用户的管理工作。
UID和GID
简介: 登陆 Linux 系统时,虽然输入的是自己的用户名和密码,但其实 Linux 并不认识你的用户名称,它只认识用户名对应的 ID 号(也就是一串数字)。Linux 系统将所有用户的名称与 ID 的对应关系都存储在 /etc/passwd 文件中。
登陆 Linux 系统时,虽然输入的是自己的用户名和密码,但其实 Linux 并不认识你的用户名称,它只认识用户名对应的 ID 号(也就是一串数字)。Linux 系统将所有用户的名称与 ID 的对应关系都存储在 /etc/passwd 文件中。
说白了,用户名并无实际作用,仅是为了方便用户的记忆而已。
要论证 “Linux系统不认识用户名” 也很简单,在前面章节,我们曾经在网络上下载过 “.tar.gz” 或 “.tar.bz2” 格式的文件,在解压缩之后的文件中,你会发现文件拥有者的属性显示的是一串数字,这很正常,就是因为系统只认识代表你身份的 ID,这串数字就是用户的 ID(UID)号。
Linux 系统中,每个用户的 ID 细分为 2 种,分别是用户 ID(User ID,简称 UID)和组 ID(Group ID,简称 GID)
/etc/passwd
简介: Linux 系统中的 /etc/passwd 文件,是系统用户配置文件,存储了系统中所有用户的基本信息,并且所有用户都可以对此文件执行读操作。
Linux 系统中的 /etc/passwd 文件,是系统用户配置文件,存储了系统中所有用户的基本信息,并且所有用户都可以对此文件执行读操作。
首先我们来打开这个文件,看看到底包含哪些内容,执行命令如下:
[root@localhost ~]# vi /etc/passwd
#查看一下文件内容
root❌0:0:root:/root:/bin/bash
bin❌1:1:bin:/bin:/sbin/nologin
daemon❌2:2:daemon:/sbin:/sbin/nologin
adm❌3:4:adm:/var/adm:/sbin/nologin
…省略部分输出…
可以看到,/etc/passwd 文件中的内容非常规律,每行记录对应一个用户。
读者可能会问,Linux 系统中默认怎么会有这么多的用户?这些用户中的绝大多数是系统或服务正常运行所必需的用户,这种用户通常称为系统用户或伪用户。系统用户无法用来登录系统,但也不能删除,因为一旦删除,依赖这些用户运行的服务或程序就不能正常执行,会导致系统问题。
不仅如此,每行用户信息都以 “:” 作为分隔符,划分为 7 个字段,每个字段所表示的含义如下:
用户名:密码:UID(用户ID):GID(组ID):描述性信息:主目录:默认Shell
接下来,给大家逐个介绍这些字段。
用户名
用户名,就是一串代表用户身份的字符串。
前面讲过,用户名仅是为了方便用户记忆,Linux 系统是通过 UID 来识别用户身份,分配用户权限的。/etc/passwd 文件中就定义了用户名和 UID 之间的对应关系。
密码
“x” 表示此用户设有密码,但不是真正的密码,真正的密码保存在 /etc/shadow 文件中(下一节做详细介绍)。
在早期的 UNIX 中,这里保存的就是真正的加密密码串,但由于所有程序都能读取此文件,非常容易造成用户数据被窃取。
虽然密码是加密的,但是采用暴力破解的方式也是能够进行破解的。
因此,现在 Linux 系统把真正的加密密码串放置在 /etc/shadow 文件中,此文件只有 root 用户可以浏览和操作,这样就最大限度地保证了密码的安全。
需要注意的是,虽然 “x” 并不表示真正的密码,但也不能删除,如果删除了 “x”,那么系统会认为这个用户没有密码,从而导致只输入用户名而不用输入密码就可以登陆(只能在使用无密码登录,远程是不可以的),除非特殊情况(如破解用户密码),这当然是不可行的。
UID
UID,也就是用户 ID。每个用户都有唯一的一个 UID,Linux 系统通过 UID 来识别不同的用户。
实际上,UID 就是一个 0~65535 之间的数,不同范围的数字表示不同的用户身份,具体如表 1 所示。
UID 范围 用户身份
0 超级用户。UID 为 0 就代表这个账号是管理员账号。在 Linux 中,如何把普通用户升级成管理员呢?只需把其他用户的 UID 修改为 0 就可以了,这一点和 Windows 是不同的。不过不建议建立多个管理员账号。
1~499 系统用户(伪用户)。也就是说,此范围的 UID 保留给系统使用。其中,1~99 用于系统自行创建的账号;100~499 分配给有系统账号需求的用户。 其实,除了 0 之外,其他的 UID 并无不同,这里只是默认 500 以下的数字给系统作为保留账户,只是一个公认的习惯而已。
500~65535 普通用户。通常这些 UID 已经足够用户使用了。但不够用也没关系,2.6.x 内核之后的 Linux 系统已经可以支持 232 个 UID 了。
GID
全称“Group ID”,简称“组ID”,表示用户初始组的组 ID 号。这里需要解释一下初始组和附加组的概念。
初始组,指用户登陆时就拥有这个用户组的相关权限。每个用户的初始组只能有一个,通常就是将和此用户的用户名相同的组名作为该用户的初始组。比如说,我们手工添加用户 lamp,在建立用户 lamp 的同时,就会建立 lamp 组作为 lamp 用户的初始组。
附加组,指用户可以加入多个其他的用户组,并拥有这些组的权限。每个用户只能有一个初始组,除初始组外,用户再加入其他的用户组,这些用户组就是这个用户的附加组。附加组可以有多个,而且用户可以有这些附加组的权限。
举例来说,刚刚的 lamp 用户除属于初始组 lamp 外,我又把它加入了 users 组,那么 lamp 用户同时属于 lamp 组和 users 组,其中 lamp 是初始组,users 是附加组。
当然,初始组和附加组的身份是可以修改的,但是我们在工作中不修改初始组,只修改附加组,因为修改了初始组有时会让管理员逻辑混乱。
需要注意的是,在 /etc/passwd 文件的第四个字段中看到的 ID 是这个用户的初始组。
描述性信息
这个字段并没有什么重要的用途,只是用来解释这个用户的意义而已。
主目录
也就是用户登录后有操作权限的访问目录,通常称为用户的主目录。
例如,root 超级管理员账户的主目录为 /root,普通用户的主目录为 /home/yourIDname,即在 /home/ 目录下建立和用户名相同的目录作为主目录,如 lamp 用户的主目录就是 /home/lamp/ 目录。
默认的Shell
Shell 就是 Linux 的命令解释器,是用户和 Linux 内核之间沟通的桥梁。
我们知道,用户登陆 Linux 系统后,通过使用 Linux 命令完成操作任务,但系统只认识类似 0101 的机器语言,这里就需要使用命令解释器。也就是说,Shell 命令解释器的功能就是将用户输入的命令转换成系统可以识别的机器语言。
通常情况下,Linux 系统默认使用的命令解释器是 bash(/bin/bash),当然还有其他命令解释器,例如 sh、csh 等。
在 /etc/passwd 文件中,大家可以把这个字段理解为用户登录之后所拥有的权限。如果这里使用的是 bash 命令解释器,就代表这个用户拥有权限范围内的所有权限。例如:
[root@localhost ~]# vi /etc/passwd
lamp❌502:502::/home/lamp:/bin/bash
我手工添加了 lamp 用户,它使用的是 bash 命令解释器,那么这个用户就可以使用普通用户的所有权限。
如果我把 lamp 用户的 Shell 命令解释器修改为 /sbin/nologin,那么,这个用户就不能登录了,例如:
[root@localhost ~]# vi /etc/passwd
lamp❌502:502::/home/lamp:/sbin/nologin
因为 /sbin/nologin 就是禁止登录的 Shell。同样,如果我在这里放入的系统命令,如 /usr/bin/passwd,例如:
[root@localhost ~]#vi /etc/passwd
lamp❌502:502::/home/lamp:/usr/bin/passwd
那么这个用户可以登录,但登录之后就只能修改自己的密码。但是,这里不能随便写入和登陆没有关系的命令(如 ls),系统不会识别这些命令,同时也就意味着这个用户不能登录。
/etc/shadow
2022-05-07 56举报
简介: /etc/shadow 文件,用于存储 Linux 系统中用户的密码信息,又称为“影子文件”。
/etc/shadow 文件,用于存储 Linux 系统中用户的密码信息,又称为“影子文件”。
前面介绍了 /etc/passwd 文件,由于该文件允许所有用户读取,易导致用户密码泄露,因此 Linux 系统将用户的密码信息从 /etc/passwd 文件中分离出来,并单独放到了此文件中。
/etc/shadow 文件只有 root 用户拥有读权限,其他用户没有任何权限,这样就保证了用户密码的安全性。
注意,如果这个文件的权限发生了改变,则需要注意是否是恶意攻击。
介绍此文件之前,我们先打开看看,执行如下命令:
[root@localhost ~]#vim /etc/shadow
root: $6$9w5Td6lg
$bgpsy3olsq9WwWvS5Sst2W3ZiJpuCGDY.4w4MRk3ob/i85fl38RH15wzVoom ff9isV1 PzdcXmixzhnMVhMxbvO:15775:0:99999:7:::
bin::15513:0:99999:7:::
daemon::15513:0:99999:7:::
…省略部分输出…
同 /etc/passwd 文件一样,文件中每行代表一个用户,同样使用 “:” 作为分隔符,不同之处在于,每行用户信息被划分为 9 个字段。每个字段的含义如下:
用户名:加密密码:最后一次修改时间:最小修改时间间隔:密码有效期:密码需要变更前的警告天数:密码过期后的宽限时间:账号失效时间:保留字段
接下来,给大家分别介绍这 9 个字段。
用户名
同 /etc/passwd 文件的用户名有相同的含义。
加密密码
这里保存的是真正加密的密码。目前 Linux 的密码采用的是 SHA512 散列加密算法,原来采用的是 MD5 或 DES 加密算法。SHA512 散列加密算法的加密等级更高,也更加安全。
注意,这串密码产生的乱码不能手工修改,如果手工修改,系统将无法识别密码,导致密码失效。很多软件透过这个功能,在密码串前加上 “!”、“*” 或 “x” 使密码暂时失效。
所有伪用户的密码都是 “!!” 或 “*”,代表没有密码是不能登录的。当然,新创建的用户如果不设定密码,那么它的密码项也是 “!!”,代表这个用户没有密码,不能登录。
最后一次修改时间
此字段表示最后一次修改密码的时间,可是,为什么 root 用户显示的是 15775 呢?
这是因为,Linux 计算日期的时间是以 1970 年 1 月 1 日作为 1 不断累加得到的时间,到 1971 年 1 月 1 日,则为 366 天。这里显示 15775 天,也就是说,此 root 账号在 1970 年 1 月 1 日之后的第 15775 天修改的 root 用户密码。
那么,到底 15775 代表的是哪一天呢?可以使用如下命令进行换算:
[root@localhost ~]# date -d “1970-01-01 15775 days”
2013年03月11日 星期一 00:00:00 CST
可以看到,通过以上命令,即可将其换算为我们习惯的系统日期。
最小修改时间间隔
最小修改间隔时间,也就是说,该字段规定了从第 3 字段(最后一次修改密码的日期)起,多长时间之内不能修改密码。如果是 0,则密码可以随时修改;如果是 10,则代表密码修改后 10 天之内不能再次修改密码。
此字段是为了针对某些人频繁更改账户密码而设计的。
密码有效期
经常变更密码是个好习惯,为了强制要求用户变更密码,这个字段可以指定距离第 3 字段(最后一次更改密码)多长时间内需要再次变更密码,否则该账户密码进行过期阶段。
该字段的默认值为 99999,也就是 273 年,可认为是永久生效。如果改为 90,则表示密码被修改 90 天之后必须再次修改,否则该用户即将过期。管理服务器时,通过这个字段强制用户定期修改密码。
密码需要变更前的警告天数
与第 5 字段相比较,当账户密码有效期快到时,系统会发出警告信息给此账户,提醒用户 “再过 n 天你的密码就要过期了,请尽快重新设置你的密码!”。
该字段的默认值是 7,也就是说,距离密码有效期的第 7 天开始,每次登录系统都会向该账户发出 “修改密码” 的警告信息。
密码过期后的宽限天数
也称为“口令失效日”,简单理解就是,在密码过期后,用户如果还是没有修改密码,则在此字段规定的宽限天数内,用户还是可以登录系统的;如果过了宽限天数,系统将不再让此账户登陆,也不会提示账户过期,是完全禁用。
比如说,此字段规定的宽限天数是 10,则代表密码过期 10 天后失效;如果是 0,则代表密码过期后立即失效;如果是 -1,则代表密码永远不会失效。
账号失效时间
同第 3 个字段一样,使用自 1970 年 1 月 1 日以来的总天数作为账户的失效时间。该字段表示,账号在此字段规定的时间之外,不论你的密码是否过期,都将无法使用!
该字段通常被使用在具有收费服务的系统中。
保留
这个字段目前没有使用,等待新功能的加入。
忘记密码怎么办
经常有读者会忘记自己的账户密码,该怎么处理呢?
对于普通账户的密码遗失,可以通过 root 账户解决,它会重新给你配置好指定账户的密码,而不需知道你原有的密码(利用 root 的身份使用 passwd 命令即可)。
如果 root 账号的密码遗失,则需要重新启动进入单用户模式,系统会提供 root 权限的 bash 接口,此时可以用 passwd 命令修改账户密码;也可以通过挂载根目录,修改 /etc/shadow,将账户的 root 密码清空的方法,此方式可使用 root 无法密码即可登陆,建议登陆后使用 passwd 命令配置 root 密码。
/etc/group
2022-05-07 33举报
简介: /ect/group 文件是用户组配置文件,即用户组的所有信息都存放在此文件中。
/ect/group 文件是用户组配置文件,即用户组的所有信息都存放在此文件中。
此文件是记录组 ID(GID)和组名相对应的文件。前面讲过,etc/passwd 文件中每行用户信息的第四个字段记录的是用户的初始组 ID,那么,此 GID 的组名到底是什么呢?就要从 /etc/group 文件中查找。
/etc/group 文件的内容可以通过 Vim 看到:
[root@localhost ~]#vim /etc/group
root❌0:
bin❌1:bin,daemon
daemon❌2:bin,daemon
…省略部分输出…
lamp❌502:
可以看到,此文件中每一行各代表一个用户组。在前面章节中,我们曾创建 lamp 用户,系统默认生成一个 lamp 用户组,在此可以看到,此用户组的 GID 为 502,目前它仅作为 lamp 用户的初始组。
各用户组中,还是以 “:” 作为字段之间的分隔符,分为 4 个字段,每个字段对应的含义为:
组名:密码:GID:该用户组中的用户列表
接下来,分别介绍各个字段具体的含义。
组名
也就是是用户组的名称,有字母或数字构成。同 /etc/passwd 中的用户名一样,组名也不能重复。
组密码
和 /etc/passwd 文件一样,这里的 “x” 仅仅是密码标识,真正加密后的组密码默认保存在 /etc/gshadow 文件中。
不过,用户设置密码是为了验证用户的身份,那用户组设置密码是用来做什么的呢?用户组密码主要是用来指定组管理员的,由于系统中的账号可能会非常多,root 用户可能没有时间进行用户的组调整,这时可以给用户组指定组管理员,如果有用户需要加入或退出某用户组,可以由该组的组管理员替代 root 进行管理。但是这项功能目前很少使用,我们也很少设置组密码。如果需要赋予某用户调整某个用户组的权限,则可以使用 sudo 命令代替。
组ID (GID)
就是群组的 ID 号,Linux 系统就是通过 GID 来区分用户组的,同用户名一样,组名也只是为了便于管理员记忆。
这里的组 GID 与 /etc/passwd 文件中第 4 个字段的 GID 相对应,实际上,/etc/passwd 文件中使用 GID 对应的群组名,就是通过此文件对应得到的。
组中的用户
此字段列出每个群组包含的所有用户。需要注意的是,如果该用户组是这个用户的初始组,则该用户不会写入这个字段,可以这么理解,该字段显示的用户都是这个用户组的附加用户。
举个例子,lamp 组的组信息为 “lamp❌502:”,可以看到,第四个字段没有写入 lamp 用户,因为 lamp 组是 lamp 用户的初始组。如果要查询这些用户的初始组,则需要先到 /etc/passwd 文件中查看 GID(第四个字段),然后到 /etc/group 文件中比对组名。
每个用户都可以加入多个附加组,但是只能属于一个初始组。所以我们在实际工作中,如果需要把用户加入其他组,则需要以附加组的形式添加。例如,我们想让 lamp 也加入 root 这个群组,那么只需要在第一行的最后一个字段加入 lamp,即 root❌0:lamp 就可以了。
一般情况下,用户的初始组就是在建立用户的同时建立的和用户名相同的组。
到此,我们已经学习了/etc/passwd、/etc/shadow、/etc/group,它们之间的关系可以这样理解,即先在 /etc/group 文件中查询用户组的 GID 和组名;然后在 /etc/passwd 文件中查找该 GID 是哪个用户的初始组,同时提取这个用户的用户名和 UID;最后通过 UID 到 /etc/shadow 文件中提取和这个用户相匹配的密码。
/etc/gshadow
2022-05-07 54举报
简介: 前面讲过,/etc/passwd 文件存储用户基本信息,同时考虑到账户的安全性,将用户的密码信息存放另一个文件 /etc/shadow 中。本节要将的 /etc/gshadow 文件也是如此,组用户信息存储在 /etc/group 文件中,而将组用户的密码信息存储在 /etc/gshadow 文件中。
前面讲过,/etc/passwd 文件存储用户基本信息,同时考虑到账户的安全性,将用户的密码信息存放另一个文件 /etc/shadow 中。本节要将的 /etc/gshadow 文件也是如此,组用户信息存储在 /etc/group 文件中,而将组用户的密码信息存储在 /etc/gshadow 文件中。
首先,我们借助 Vim 命令查看一下此文件中的内容:
[root@localhost ~]#vim /etc/gshadow
root:::
bin:::bin, daemon
daemon:::bin, daemon
…省略部分输出…
lamp:!::
文件中,每行代表一个组用户的密码信息,各行信息用 “:” 作为分隔符分为 4 个字段,每个字段的含义如下:
组名:加密密码:组管理员:组附加用户列表
组名
同 /etc/group 文件中的组名相对应。
组密码
对于大多数用户来说,通常不设置组密码,因此该字段常为空,但有时为 “!”,指的是该群组没有组密码,也不设有群组管理员。
组管理员
从系统管理员的角度来说,该文件最大的功能就是创建群组管理员。那么,什么是群组管理员呢?
考虑到 Linux 系统中账号太多,而超级管理员 root 可能比较忙碌,因此当有用户想要加入某群组时,root 或许不能及时作出回应。这种情况下,如果有群组管理员,那么他就能将用户加入自己管理的群组中,也就免去麻烦 root 了。
不过,由于目前有 sudo 之类的工具,因此群组管理员的这个功能已经很少使用了。
组中的附加用户
该字段显示这个用户组中有哪些附加用户,和 /etc/group 文件中附加组显示内容相同。
Linux初始组和附加组
2022-05-07 65举报
简介: 通过学习用户和群组我们知道,群组可以让多个用户具有相同的权限,同时也可以这样理解,一个用户可以所属多个群组,并同时拥有这些群组的权限,这就引出了初始组(有时也称主组)和附加组。
通过学习用户和群组我们知道,群组可以让多个用户具有相同的权限,同时也可以这样理解,一个用户可以所属多个群组,并同时拥有这些群组的权限,这就引出了初始组(有时也称主组)和附加组。
《Linux /etc/passwd》一节中,已经对用户所属初始组和附加组的概念进行了简单介绍,本节对初始组和附加组做更详细的介绍。
/etc/passwd 文件中每个用户信息分为 7 个字段,其中第 4 字段(GID)指的就是每个用户所属的初始组,也就是说,当用户一登陆系统,立刻就会拥有这个群组的相关权限。
举个例子,我们新建一个用户 lamp,并将其加入 users 群组中,执行命令如下:
[root@localhost ~]# useradd lamp <–添加新用户
[root@localhost ~]# groupadd users <–添加新群组
[root@localhost ~]# usermod -G users lamp <–将用户lamp加入 users群组
[root@localhost ~]# grep “lamp” /etc/passwd /etc/group /etc/gshadow
/etc/passwd:lamp❌501:501::/home/lamp:/bin/bash
/etc/group:users❌100:lamp
/etc/group:lamp❌501:
/etc/gshadow:users:::lamp
/etc/gshadow:lamp:!::
useradd 和 groupadd 分别是添加用户和群组的命令,后续章节会做详细讲解。
可以看到,在 etc/passwd 文件中,lamp 用户所属的 GID(群组 ID)为 501,通过搜索 /etc/group 文件得知,对应此 GID 的是 lamp 群组,也就是说,lamp 群组是 lamp 用户的初始组。
lamp 群组是添加 lamp 用户时默认创建的群组,在 root 管理员使用 useradd 命令创建新用户时,若未明确指定该命令所属的初始组,useradd 命令会默认创建一个同用户名相同的群组,作为该用户的初始组。
正因为 lamp 群组是 lamp 用户的初始组,该用户一登陆就会自动获取相应权限,因此不需要在 /etc/group 的第 4 个字段额外标注。
但是,附加组就不一样了,从例子中可以看到,我们将 lamp 用户加入 users 群组中,由于 users 这个群组并不是 lamp 的初始组,因此必须要在 /etc/group 这个文件中找到 users 那一行,将 lamp 这个用户加入第 4 段中(群组包含的所有用户),这样 lamp 用户才算是真正加入到 users 这个群组中。
在这个例子中,因为 lamp 用户同时属于 lamp 和users 两个群组,所在,在读取\写入\运行文件时,只要是 user 和 lamp 群组拥有的功能,lamp 用户都拥有。
一个用户可以所属多个附加组,但只能有一个初始组。那么,如何知道某用户所属哪些群组呢?使用 groups 命令即可。
例如,我们现在以 lamp 用户的身份登录系统,通过执行如下命令即可知晓当前用户所属的全部群组:
[root@localhost ~]# groups
lamp users
通过以上输出信息可以得知,lamp 用户同时属于 lamp 群组和 users 群组,而且,第一个出现的为用户的初始组,后面的都是附加组,所以 lamp 用户的初始组为 lamp 群组,附加组为 users 群组。
/etc/login.defs
2022-05-07 98举报
简介: /etc/login.defs 文件用于在创建用户时,对用户的一些基本属性做默认设置,例如指定用户 UID 和 GID 的范围,用户的过期时间,密码的最大长度,等等。
/etc/login.defs 文件用于在创建用户时,对用户的一些基本属性做默认设置,例如指定用户 UID 和 GID 的范围,用户的过期时间,密码的最大长度,等等。
需要注意的是,该文件的用户默认配置对 root 用户无效。并且,当此文件中的配置与 /etc/passwd 和 /etc/shadow 文件中的用户信息有冲突时,系统会以/etc/passwd 和 /etc/shadow 为准。
读者可自行使用 vim /etc/login.defs 命令查看该文件中的内容,表 1 中对文件中的各个选项做出了具体的解释。
设置项 含义
MAIL_DIR /var/spool/mail 创建用户时,系统会在目录 /var/spool/mail 中创建一个用户邮箱,比如 lamp 用户的邮箱是 /var/spool/mail/lamp。
PASS_MAX_DAYS 99999 密码有效期,99999 是自 1970 年 1 月 1 日起密码有效的天数,相当于 273 年,可理解为密码始终有效。
PASS_MIN_DAYS 0 表示自上次修改密码以来,最少隔多少天后用户才能再次修改密码,默认值是 0。
PASS_MIN_LEN 5 指定密码的最小长度,默认不小于 5 位,但是现在用户登录时验证已经被 PAM 模块取代,所以这个选项并不生效。
PASS_WARN_AGE 7 指定在密码到期前多少天,系统就开始通过用户密码即将到期,默认为 7 天。
UID_MIN 500 指定最小 UID 为 500,也就是说,添加用户时,默认 UID 从 500 开始。注意,如果手工指定了一个用户的 UID 是 550,那么下一个创建的用户的 UID 就会从 551 开始,哪怕 500~549 之间的 UID 没有使用。
UID_MAX 60000 指定用户最大的 UID 为 60000。
GID_MIN 500 指定最小 GID 为 500,也就是在添加组时,组的 GID 从 500 开始。
GID_MAX 60000 用户 GID 最大为 60000。
CREATE_HOME yes 指定在创建用户时,是否同时创建用户主目录,yes 表示创建,no 则不创建,默认是 yes。
UMASK 077 用户主目录的权限默认设置为 077。
USERGROUPS_ENAB yes 指定删除用户的时候是否同时删除用户组,准备地说,这里指的是删除用户的初始组,此项的默认值为 yes。
ENCRYPT_METHOD SHA512 指定用户密码采用的加密规则,默认采用 SHA512,这是新的密码加密模式,原先的 Linux 只能用 DES 或 MD5 加密。
强制系统用户登陆时修改密码(chage命令)
2022-05-07 195举报
简介: 除了 passwd -S 命令可以查看用户的密码信息外,还可以利用 chage 命令,它可以显示更加详细的用户密码信息,并且和 passwd 命令一样,提供了修改用户密码信息的功能。
除了 passwd -S 命令可以查看用户的密码信息外,还可以利用 chage 命令,它可以显示更加详细的用户密码信息,并且和 passwd 命令一样,提供了修改用户密码信息的功能。
如果你要修改用户的密码信息,我个人建议,还是直接修改 /etc/shadow 文件更加方便。
首先,我们来看 chage 命令的基本格式:
[root@localhost ~]#chage [选项] 用户名
选项:
-l:列出用户的详细密码状态;
-d 日期:修改 /etc/shadow 文件中指定用户密码信息的第 3 个字段,也就是最后一次修改密码的日期,格式为 YYYY-MM-DD;
-m 天数:修改密码最短保留的天数,也就是 /etc/shadow 文件中的第 4 个字段;
-M 天数:修改密码的有效期,也就是 /etc/shadow 文件中的第 5 个字段;
-W 天数:修改密码到期前的警告天数,也就是 /etc/shadow 文件中的第 6 个字段;
-i 天数:修改密码过期后的宽限天数,也就是 /etc/shadow 文件中的第 7 个字段;
-E 日期:修改账号失效日期,格式为 YYYY-MM-DD,也就是 /etc/shadow 文件中的第 8 个字段。
【例 1】
#查看一下用户密码状态
[root@localhost ~]# chage -l lamp
Last password change:Jan 06, 2013
Password expires:never
Password inactive :never
Account expires :never
Minimum number of days between password change :0
Maximum number of days between password change :99999
Number of days of warning before password expires :7
读者可能会问,既然直接修改用户密码文件更方便,为什么还要讲解 chage 命令呢?因为 chage 命令除了修改密码信息的功能外,还可以强制用户在第一次登录后,必须先修改密码,并利用新密码重新登陆系统,此用户才能正常使用。
例如,我们创建 lamp 用户,并让其首次登陆系统后立即修改密码,执行命令如下:
#创建新用户 lamp
[root@localhost ~]#useradd lamp
#设置用户初始密码为 lamp
[root@localhost ~]#echo “lamp” | passwd --stdin lamp
#通过chage命令设置此账号密码创建的日期为 1970 年 1 月 1 日(0 就表示这一天),这样用户登陆后就必须修改密码
[root@localhost ~]#chage -d 0 lamp
这样修改完 lamp 用户后,我们尝试用 lamp 用户登陆系统(初始密码也是 lamp):
local host login:lamp
Password: <–输入密码登陆
You are required to change your password immediately (root enforced)
changing password for lamp. <–有一些提示,就是说明 root 强制你登录后修改密码
(current)UNIX password:
#输入旧密码
New password:
Retype new password:
#输入两次新密码
chage 的这个功能常和 passwd 批量初始化用户密码功能合用,且对学校老师帮助比较大,因为老师不想知道学生账号的密码,他们在初次上课时就使用与学号相同的账号和密码给学生,让他们登陆时自行设置他们的密码。这样一来,既能避免学生之间随意使用别人的账号,也能保证学生知道如何修改自己的密码。
ACL 对单独用户设置权限
图 1 的根目录中有一个 /project 目录,这是班级的项目目录。班级中的每个学员都可以访问和修改这个目录,老师需要拥有对该目录的最高权限,其他班级的学员当然不能访问这个目录。
需要怎么规划这个目录的权限呢?应该这样,老师使用 root 用户,作为这个目录的属主,权限为 rwx;班级所有的学员都加入 tgroup 组,使 tgroup 组作为 /project 目录的属组,权限是 rwx;其他人的权限设定为 0(也就是 —)。这样一来,访问此目录的权限就符合我们的要求了。
有一天,班里来了一位试听的学员 st,她必须能够访问 /project 目录,所以必须对这个目录拥有 r 和 x 权限;但是她又没有学习过以前的课程,所以不能赋予她 w 权限,怕她改错了目录中的内容,所以学员 st 的权限就是 r-x。可是如何分配她的身份呢?变为属主?当然不行,要不 root 该放哪里?加入 tgroup 组?也不行,因为 tgroup 组的权限是 rwx,而我们要求学员 st 的权限是 r-x。如果把其他人的权限改为 r-x 呢?这样一来,其他班级的所有学员都可以访问 /project 目录了。
显然,普通权限的三种身份不够用了,无法实现对某个单独的用户设定访问权限,这种情况下,就需要使用 ACL 访问控制权限。
ACL,是 Access Control List(访问控制列表)的缩写,在 Linux 系统中, ACL 可实现对单一用户设定访问文件的权限。也可以这么说,设定文件的访问权限,除了用传统方式(3 种身份搭配 3 种权限),还可以使用 ACL 进行设定。拿本例中的 st 学员来说,既然赋予它传统的 3 种身份,无法解决问题,就可以考虑使用 ACL 权限控制的方式,直接对 st 用户设定访问文件的 r-x 权限。
其他
service
启动一些程序服务的时候,有
时候直接去
程序的bin目录下去执行命令,有时候利用service启动。
比如启动mysql服务时,大部分喜欢执行service mysqld start。当然也可以去mysql下执行bin命令带上几个参数什么的。
那么service是啥呢?linux可以man一下,看出来就是去/etc/init.d下执行了可执行的shell脚本。
service执行的服务脚本都是在/etc/init.d目录下,各个程序下脚本里执行的命令仍然是在各个bin下。
在linux想要运行启动一个服务有两种方法:
1,运行/etc/init.d/目录下的shell脚本,还可以有快捷方式,service *** start/ stop/restart /status,
2,直接运行/usr/bin目录下的服务文件;
第一种方法启动的程序可以通过service命令来管理,比如说查看状态 service --status-all
查看/etc/init.d目录,发现下面都是shell脚本,脚本里面运行的程序最终还是指向了/usr/bin下面的程序,只不过在shell脚本中可能直接对程序的一些运行参数继续进行了设置;
第二种方法,直接运行/usr/bin/****,如果运行时有配置文件的话,需要加上 --config *****,用这种方法启动程序后,不能用service命令查看状态;
/etc/init.d/crond 和/usr/sbin/crond /etc/init.d/crontd是一个软链接!就像WINXP里删除桌面快捷方式。
service和systemctl
Linux 服务管理两种方式service和systemctl。
systemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动。
systemd是Linux系统最新的初始化系统,对应的进程管理命令是systemctl。
systemctl命令兼容了service,即systemctl也会去/etc/init.d目录下,查看,执行相关程序。
systemctl实际上将 service 和 chkconfig 这两个命令组合到一起。
Systemd 默认从目录/etc/systemd/system/读取配置文件。但是,里面存放的大部分文件都是符号链接,指向目录/usr/lib/systemd/system/,真正的配置文件存放在/usr/lib/systemd/system/目录。
systemctl enable命令用于设置开机自启,原理其实就是在上面两个目录之间,建立符号链接关系。即会在/etc/systemd/system/multi-user.target.wants/目录下新建一个/usr/lib/systemd/system/docker.service 文件的链接。
systemctl命令脚本存放在/usr/lib/systemd/目录下,也兼容了service, 即也会去/etc/init.d目录下查看执行相关程序,所以systemctl命令会查看两个目录。
systemctl两个主要目录:
/usr/lib/systemd/system/firstrun.service:service目录
/usr/lib/systemd/firstrun:一般放置真实的启动脚本
启动http服务:systemctl start httpd
设置开机自启:systemctl enable httpd
————————————————
版权声明:本文为CSDN博主「小魏的博客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/w2009211777/article/details/125489179
当系统引入 systemctl 命令之后,service本质上就是对 systemctl 进行了一次包装,实际都是执行这个命令来调用.service配置文件(位于 /usr/lib/systemd/system )进行控制操作,这一点 Ubuntu20.04 和 CentOS8.3 很像,不像 CentOS6.5 ,脚本中是直接与应用二进制文件打交道。
所以对服务的操控可以有两种写法(后者直接使用了 systemctl 命令调用 .service 配置文件)
service apache2 start
2.systemctl start apache2.service
service的控制单元是一个个的 .service 配置文件,每个 .service 文件对应一个服务的控制操作,.service文件的书写有一定的规范,下面是 Ubuntu20.04下 apac
作者:量U移动广告归因
链接:https://www.jianshu.com/p/8ae3c6f5601f
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
shell
https://mp.weixin.qq.com/s/dP8AJbvGgvYIXDy3zeXCRg 可参考
other
super
im /etc/supervisord.d/xxx.ini 是配置文件
文字原理部分
免费与开源的作用
首先,开源软件和免费软件是两个概念:
开源软件是指公开源代码的软件。开源软件在发行的时候会附上软件的源代码,并授权允许用户更改、传播或者二次开发。
免费软件就是免费提供给用户使用的软件,但是在免费的同时,通常也会有一些限制,比如源代码不公开,用户不能随意修改、不能二次发布等。
免费软件的例子比比皆是,QQ、微信、迅雷、酷狗、360 等都是免费软件,你可以随意使用,尽情蹂躏;但是,如果你嫌弃它们复杂,自己删除了一些无用的功能,然后在网上发布了一个精简版本供大家下载,那么你就离法院的传票不远了。
linux使用脚本语言而非C语言
说到在 Linux 下的编程,很多人会想到用C语言,Linux 的内核、shell、基础命令程序,也的确是用C语言编写的,这首先证明了一点,C语言很强很通用。
到目前为止,C语言依然垄断着计算机工业中几乎所有的系统编程,而且也正因为是C语言,才使得 Unix 以及后来的 Linux 能够这么广泛地被人们去研究、去改进、去制作自己的分支,以至于我们能在各种硬件平台上使用它们。
但是细心的人会发现,Linux 启动过程中所涉及的各种程序,很少有C语言的痕迹。它们大多是脚本程序。不单单在启动过程中是这样,那些用于安装软件的工具 yum、apt-get,甚至是 configure 和 Makefile 也都是脚本程序。而且你可能还没注意到,那些用于系统管理的工具,如配置 ADSL 拨号上网的工具、配置守护进程的工具等,很多也都是脚本程序。
大量使用脚本程序,是所有类 Unix 系统不同于其他系统的一个显著特征,催生人们在 Linux 中大量使用脚本来编写程序,并不仅仅是因为脚本对人直观、容易修改这种显著特性所决定的。另外一个主要的原因就是 Linux 所支持的脚本语言种类十分丰富。
所有类 Unix 系统所必备的 shell,其本身就是一个强大的脚本解释器。所以从 shell 诞生的那一天起,shell 就是那些不懂 C 语言,又必须在 Unix 上编写程序的用户们的首选工具。
这就给了人们一种新的选择,使用 shell 编程不用去理会让人头晕的指针;shell 程序可以直接利用系统命令来完成一些需要用大量 C 代码的功能;shell 编程不用去理会数据类型,不用考虑烦人的数值和字符数据的转换问题;shell 程序同样提供顺序、选择分支和循环这三种能够构建任意算法的基础设施。因此,shell 很快就能够被非专业用户所接受、掌握,并编写出非常实用的程序。
随着时间的推移,这些非专业用户想往更高的方向发展,遇到了一些 shell 处理起来会很“蹩脚”的问题,比如分析文本和修改文本(别忘了“万般皆文本”)。这个时候他们会发现 有 awk 和 sed。也只需要写几行脚本就能将这些问题处理得很好。而且它们也跟 shell 配合得天衣无缝。或许这个时候会觉得加入了 awk 和 sed 的 shell 脚本有些难看,不过没关系,还有 Perl 和 TCL。Perl 天生就是为处理文本而存在的,TCL 也不含糊。
如果觉得这些语言都太老气了,有些过时了,不要紧,还有 Python、Ruby 等这些现代脚本语言,它们除了不能写操作系统内核之外,几乎什么都能干,而且还是面向对象的。
不管怎样,在 Linux 下能够选择的脚本语言都是极其丰富的。它们最大的特点就是简单、好学且资料丰富。简单就意味着容易维护,好学就容易吸引用户,资料丰富就不会在解决 bug 上出现障碍。即便是专业的程序员,也会因为这些特点而特别偏好脚本语言,导致的一个结果就是脚本程序在 Linux 中的大爆发。
有读者可能会问,为什么不选择 C 语言呢?
C语言并不是最佳选择
C语言是 Unix 的母语,这是毋庸罝疑的。前面也说过,正是因为有了C语言,才使得 Unix 有了今天的成就。但为什么在 Linux 中有这么多程序,甚至是关键程序,不用C语言编写呢?
脚本程序由于是解释执行的,在执行效率上自然是会有很大损失的。并且大家都知道,C语言所编写的程序又是以效率著称的。但是C语言是一种编译型语言,要想让C语言的程序能够运行,必须经过编译和链接这两个步骤。
要知道,能够将由几十个源代码文件构成的C语言程序,有条不紊地编译完成并能最终链接成一个可执行程序,本身就是一件费时又费力的事情,如果一旦程序有问题,还必须使用专门的调试工具一点点地去跟踪判断,修正之后再重复那些复杂的编译和链接步骤,这又是一个极需技巧的事情。积累并掌握技巧又是一件费时又费力的事情。
在早些年,计算机性能不佳的时候,这些付出或许是值得的。但是放到现在,处理器的速度至少快了几千倍,内存大了几千倍,硬盘甚至大了几万倍,而价格却更低了。从经济角度分析,机器的时间成本早己远远低于人的时间成本了。那么C语言在机器效率上的优势根本没有任何意义。脚本程序能够给人节省下来的时间成本,则更具经济效益。
要论机器效率,汇编语言比C语言要好上几十倍,但是目前还有谁在用汇编语言编程呢?
C语言在设计的时候,最主要的一个目标就是能够让程序员自己处理内存管理的问题。这使得C语言很强大但又太过于灵活,导致了很多陷阱的出现。稍微一不注意,程序中就会存在难以发觉的 Bug,甚至是严重的安全漏洞。程序员们大多是要以时间或失败为代价去积累经验,才能尽量避免这些问题的发生。而且效率在大多数应用中根本就不是问题,首要的是正确。脚本程序的简单和直观正是正确的起点,C语言的灵活却是错误的根源。
但是,C语言并不是一无是处,也是 Unix 的精华。C语言作为通用程序设计语言是所向无敌的。C语言本身也非常简洁和紧凑,资料丰富且容易学习。C语言之后的少数语言设计,为了不被C语言所吞并,不得不进行大的改动,比如引进垃圾回收机制等,以和C语言能够在功能上保持足够距离。也正是因为这样,C语言始终没有消失,只是它的光辉在 Linux 中稍稍地被脚本程序所遮挡了一下。
脚本语言也有不足
虽然效率并不是脚本程序的缺点,但是种类过于丰富却是一个极大不足。编写一个复杂的应用,往往很难使用一种脚本语言包杆到底,因为脚本语言都有自己适用的场景,为了能够快速有效地完成某个应用,就需扬长避短,利用多种脚本语言混合编程。
多脚本语言的混合编程是一种知识密集型的编程方法,但不是编码密集型的(这是能够被普遍接受的原因)。为了能够良好地使用这种方法,就要求程序员不仅仅要具备相当数量的多种语言知识,还必须具备能够判断这些语言的适用场景、以及如何将它们有效地组合在一起的经验。
实际上,混合编程并不是脚本语言的专利,任何编程语言都行,只要你能找准那些语言的特点。比如笔者就曾经使用过 Basic 和 C 进行混合编程,去完成一个 DOS 版万年历程序。为了支持鼠标点击操作,用 C 完成了鼠标中断的处理。余下的部分都用 Basic 来完成。
在 Linux 中大量应用脚本程序的场景,好多都是这种混合编程的典范。比如 Linux 的启动过程,主程序 init 是用 C 语言写的,具体到启动流程的各个环节则是 shell 脚本程序。
与windows的几个明显区别
Linux 严格区分大小写
和 Windows 不同,Linux 是严格区分大小写的,包括文件名和目录名、命令、命令选项、配置文件设置选项等。
例如,Windows 系统桌面上有一个名为 Demo 的文件夹,当我们在桌面上再新建一个名为 demo 的文件夹时,系统会提示文件夹命名冲突;而 Linux 系统不会,Linux 系统认为 Demo 文件和 demo 文件不是同一个文件,因此在 Linux 系统中,Demo 文件和 demo 文件可以位于同一目录下。
因此,初学者在操作 Linux 系统时要注意区分大小写的不同。
Windows 下的程序不能直接在 Linux 中使用
Linux 和 Windows 是不同的操作系统,两者的安装软件不能混用。例如,Windows 系统上的 QQ 软件安装包无法直接放到 Linux 上使用。
系统之间存在的这一差异,有弊也有利。弊端很明显,就是所有的软件要想安装在 Linux 系统上,必须单独开发针对 Linux 系统的版本(也可以依赖模拟器软件运行);好处则是能感染 Windows 系统的病毒(或木马)对 Linux 无效。
由于系统间存在差异,很多软件会同时推出针对 Windows 和 Linux 的版本,如大家熟悉的即时通信软件 QQ,既有 Windows 系统下的 QQ 版本,也有适用于 Linux 系统的 QQ for Linux 版本。
Linux 不靠扩展名区分文件类型
我们都知道,Windows 是依赖扩展名区分文件类型的,比如,“.txt” 是文本文件、“.exe” 是执行文件、“.ini” 是配置文件、“.mp4” 是小电影等。但 Linux 不是。
Linux 系统通过权限位标识来确定文件类型,且文件类型的种类也不像 Windows 下那么多,常见的文件类型只有普通文件、目录、链接文件、块设备文件、字符设备文件等几种。Linux 的可执行文件不过就是普通文件被赋予了可执行权限而已。
Linux 中的一些特殊文件还是要求写 “扩展名” 的,但大家小心,并不是 Linux 一定要靠扩展名来识别文件类型,写这些扩展名是为了帮助管理员来区分不同的文件类型。这样的文件扩展名主要有以下几种:
压缩包:Linux 下常见的压缩文件名有 .gz、.bz2、.zip、.tar.gz、.tar.bz2、.tgz 等。为什么压缩包一定要写扩展名呢?很简单,如果不写清楚扩展名,那么管理员不容易判断压缩包的格式,虽然有命令可以帮助判断,但是直观一点更加方便。另外,就算没写扩展名,在 Linux 中一样可以解压缩,不影响使用。
二进制软件包:CentOS 中所使用的二进制安装包是 RPM 包,所有的 RPM 包都用".rpm"扩展名结尾,目的同样是让管理员一目了然。
程序文件:shell 脚本一般用 “.sh” 扩展名结尾,其他还有用 “.c” 扩展名结尾的 C 语言文件等。
网页文件:网页文件一般使用 “*.php” 等结尾,不过这是网页服务器的要求,而不是 Linux 的要求。
在此不一一列举了,还有如日常使用较多的图片文件、视频文件、Office 文件等,也是如此。
Linux 中所有内容(包括硬件设备)以文件形式保存
Linux 中所有内容都是以文件的形式保存和管理的(硬件设备也是文件),这和 Windows 完全不同,Windows 是通过设备管理器来管理硬件的。比如说,Linux 的设备文件保存在 /dev/ 目录中,硬盘文件是 /dev/sd[a-p],光盘文件是 /dev/hdc 等。
彻底搞明白“Linux一切皆文件”,请阅读《Linux一切皆文件》一文。
套接字、文件目录也是文件
Linux中所有存储设备都必须在挂载之后才能使用
Linux 中所有的存储设备都有自己的设备文件名,这些设备文件必须在挂载之后才能使用,包括硬盘、U 盘和光盘。
挂载其实就是给这些存储设备分配盘符,只不过 Windows 中的盘符用英文字母表示,而 Linux 中的盘符则是一个已经建立的空目录。我们把这些空目录叫作挂载点(可以理解为 Windows 的盘符),把设备文件(如 /dev/sdb)和挂载点(已经建立的空目录)连接的过程叫作挂载。这个过程是通过挂载命令实现的,具体的挂载命令后续会讲。
Linux四种远程管理协议
2022-05-07 111举报
简介: 提到远程管理,通常指的是远程管理服务器,而非个人计算机。个人计算机可以随时拿来用,服务器通常放置在机房中,用户无法直接接触到服务器硬件,只能采用远程管理的方式。
提到远程管理,通常指的是远程管理服务器,而非个人计算机。个人计算机可以随时拿来用,服务器通常放置在机房中,用户无法直接接触到服务器硬件,只能采用远程管理的方式。
远程管理,实际上就是计算机(服务器)之间通过网络进行数据传输(信息交换)的过程,与浏览器需要 HTTP 协议(超文本传输协议)浏览网页一样,远程管理同样需要远程管理协议的支持。
目前,常用的远程管理协议有以下 4 种:
RDP(remote desktop protocol)协议:远程桌面协议,大部分 Windows 系统都默认支持此协议,Windows 系统中的远程桌面管理就基于该协议。
RFB(Remote FrameBuffer)协议:图形化远程管理协议,VNC 远程管理工具就基于此协议。
Telnet:命令行界面远程管理协议,几乎所有的操作系统都默认支持此协议。此协议的特点是,在进行数据传送时使用明文传输的方式,也就是不对数据进行加密。
SSH(Secure Shell)协议:命令行界面远程管理协议,几乎所有操作系统都默认支持此协议。和 Telnet 不同,该协议在数据传输时会对数据进行加密并压缩,因此使用此协议传输数据既安全速度又快。
RDP 对比 RFB
RDP 协议和 RFB 协议都允许用户通过图形用户界面访问远程系统,但 RFB 协议倾向于传输图像,RDP 协议倾向于传输指令:
RFB 协议会在服务器端将窗口在显存中画好,然后将图像传给客户端,客户端只需要将得到的图像解码显示即可;
RDP 会将画图的工作交给客户端,服务器端需要根据客户端的显示能力做适当的调整。
因此,完成相同的操作,使用 RFB 协议传输的数据量会比 RDP 大,而 RDP 对客户端的要求比 RFB 更苛刻,RFB 适用于瘦客户端,而 RDP 适用于低速网络。
瘦客户端是相对于胖客户端而言的,比如,人们使用 QQ,需要下载客户端,这属于“胖客户”;反之,通过浏览器就可查阅网络上各种资料,无需再下载其他任何软件,这属于“瘦客户”。简单理解,瘦客户端指的是最大可能减轻客户端的负担,多数工作由服务器端完成;胖客户端则相反。
Telnet 对比 SSH
Telnet 协议和 SSH 协议都是命令行远程管理协议,有共同的应用领域,常用于远程访问服务器。
相比 Telnet 协议,SSH 协议在发送数据时会对数据进行加密操作,数据传输更安全,因此 SSH 协议几乎在所有应用领域代替了 Telnet 协议。
在一些测试、无需加密的场合(如局域网),Telnet协议仍常被使用。
Linux远程管理软件
基于以上 4 种远程管理协议,Linux 远程管理服务器的软件可分为以下 3 种:
类似于 VNC(基于 RFB 协议)的图形远程管理软件,如 Xmanager、VNC VIEWER 以及 TightVNC 等;
基于 SSH 协议的命令行操作管理;
类似 Webmin 的基于浏览器的远程管理,此种管理方式只提供简单的管理窗口,可用的管理功能有限;
介于安全性和稳定性的考虑,大部分的服务器都舍弃图形管理界面而选择命令行界面,因此远程管理 Linux 服务器常使用基于 SSH 协议的命令行管理方式。
目前,基于 SSH 协议常用的远程管理工具有 PuTTY、SecureCRT、WinSCP 等,这些管理工具的具体使用下节给大家详细介绍。
Linux中一切皆文件[包含优缺点]
2022-05-07 156举报
简介: Linux 中所有内容都是以文件的形式保存和管理的,即一切皆文件,普通文件是文件,目录(Windows 下称为文件夹)是文件,硬件设备(键盘、监视器、硬盘、打印机)是文件,就连套接字(socket)、网络通信等资源也都是文件。
Linux 中所有内容都是以文件的形式保存和管理的,即一切皆文件,普通文件是文件,目录(Windows 下称为文件夹)是文件,硬件设备(键盘、监视器、硬盘、打印机)是文件,就连套接字(socket)、网络通信等资源也都是文件。
Linux系统中,文件具体可分为以下几种类型:
-
普通文件
类似 mp4、pdf、html 这样,可直接拿来使用的文件都属于普通文件,Linux 用户根据访问权限的不同可以对这些文件进行查看、删除以及更改操作。 -
目录文件
对于用惯 Windows 系统的用户来说,目录是文件可能不太好理解。
Linux 系统中,目录文件包含了此目录中各个文件的文件名以及指向这些文件的指针,打开目录等同于打开目录文件,只要你有权限,可以随意访问目录中的任何文件。
注意,目录文件的访问权限,同普通文件的执行权限,是一个意思。
- 字符设备文件和块设备文件
这些文件通常隐藏在 /dev/ 目录下,当进行设备读取或外设交互时才会被使用。
例如,磁盘光驱属于块设备文件,串口设备则属于字符设备文件。
Linux 系统中的所有设备,要么是块设备文件,要么是字符设备文件。
-
套接字文件(socket)
套接字文件一般隐藏在 /var/run/ 目录下,用于进程间的网络通信。 -
符号链接文件(symbolic link)
类似与 Windows 中的快捷方式,是指向另一文件的简介指针(也就是软链接)。 -
管道文件(pipe)
主要用于进程间通信。例如,使用 mkfifo 命令创建一个 FIFO 文件,与此同时,启用进程 A 从 FIFO文件读数据,启用进程 B 从 FIFO文件中写数据,随写随读。
一切皆文件的利弊
和 Windows 系统不同,Linux 系统没有 C 盘、D 盘、E 盘那么多的盘符,只有一个根目录(/),所有的文件(资源)都存储在以根目录(/)为树根的树形目录结构中。
这样做最明显的好处是,开发者仅需要使用一套 API 和开发工具即可调取 Linux 系统中绝大部分的资源。举个简单的例子,Linux 中几乎所有读(读文件,读系统状态,读 socket,读 PIPE)的操作都可以用 read 函数来进行;几乎所有更改(更改文件,更改系统参数,写 socket,写 PIPE)的操作都可以用 write 函数来进行。
不利之处在于,使用任何硬件设备都必须与根目录下某一目录执行挂载操作,否则无法使用。我们知道,本身 Linux 具有一个以根目录为树根的文件目录结构,每个设备也同样如此,它们是相互独立的。如果我们想通过 Linux 上的根目录找到设备文件的目录结构,就必须将这两个文件系统目录合二为一,这就是挂载的真正含义。
有关 Linux 挂载的具体知识,后续文章将会详细介绍。
| 硬件设备 | 文件名称 |
|---|---|
| IDE设备 | /dev/hd[a-d],现在的 IDE设备已经很少见了,因此一般的硬盘设备会以 /dev/sd 开头。 |
| SCSI/SATA/U盘 | /dev/sd[a-p],一台主机可以有多块硬盘,因此系统采用 a~p 代表 16 块不同的硬盘。 |
| 软驱 | /dev/fd[0-1] |
| 打印机 | /dev/lp[0-15] |
| 光驱 | /dev/cdrom |
| 鼠标 | /dev/mouse |
| 磁带机 | /dev/st0 或 /dev/ht0 |
和 Windows 系统不同,Linux 系统没有 C 盘、D 盘、E 盘那么多的盘符,只有一个根目录(/),所有的文件(资源)都存储在以根目录(/)为树根的树形目录结构中。
这样做最明显的好处是,开发者仅需要使用一套 API 和开发工具即可调取 Linux 系统中绝大部分的资源。举个简单的例子,Linux 中几乎所有读(读文件,读系统状态,读 socket,读 PIPE)的操作都可以用 read 函数来进行;几乎所有更改(更改文件,更改系统参数,写 socket,写 PIPE)的操作都可以用 write 函数来进行。
不利之处在于,使用任何硬件设备都必须与根目录下某一目录执行挂载操作,否则无法使用。我们知道,本身 Linux 具有一个以根目录为树根的文件目录结构,每个设备也同样如此,它们是相互独立的。如果我们想通过 Linux 上的根目录找到设备文件的目录结构,就必须将这两个文件系统目录合二为一,这就是挂载的真正含义。
————————————————
版权声明:本文为CSDN博主「富士康质检员张全蛋」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_34556414/article/details/79081693
硬盘分区
硬盘分区
硬盘分区是硬盘结合到文件体系的第一步,本质是「硬盘」这个物理概念转换成「区」这个逻辑概念,为下一步格式化做准备。
所以分本身并不是必须的,你完全可以把一整块硬盘作为一个区。但从数据的安全性以及系统性能角度来看,分区还是有很多用处的,所以一般都会对硬盘进行分区。
讲分区就不得不先提每块硬盘上最重要的第一扇区,这个扇区中有硬盘主引导记录(Master boot record, MBR) 及分区表(partition table), 其中 MBR 占有 446 bytes,而分区表占有 64 bytes。硬盘主引导记录放有最基本的引导加载程序,是系统开机启动的关键环节,在附录中有更详细的说明。而分区表则跟分区有关,它记录了硬盘分区的相关信息,但因分区表仅有 64bytes , 所以最多只能记彔四块分区(分区本身其实就是对分区表进行设置)。
只能分四个区实在太少了,于是就有了扩展分区的概念,既然第一个扇区所在的分区表只能记录四条数据, 那我可否利用额外的扇区来记录更多的分区信息。
把普通可以访问的分区称为主分区,扩展分区不同于主分区,它本身并没有内容,它是为进一步逻辑分区提供空间的。在某块分区指定为扩展分区后,就可以对这块扩展分区进一步分成多个逻辑分区。操作系统规定:
四块分区每块都可以是主分区或扩展分区
扩展分区最多只能有一个(也没必要有多个)
扩展分区可以进一步分割为多个逻辑分区
扩展分区只是逻辑概念,本身不能被访问,也就是不能被格式化后作为数据访问的分区,能够作为数据访问的分区只有主分区和逻辑分区
逻辑分区的数量依操作系统而不同,在 Linux 系统中,IDE 硬盘最多有 59 个逻辑分区(5 号到 63 号), SATA 硬盘则有 11 个逻辑分区(5 号到 15 号)
一般给硬盘进行分区时,一个主分区一个扩展分区,然后把扩展分区划分为N个逻辑分区是最好的
是否可以不要主分区呢?不知道,但好像不用管,你创建分区的时候会自动给你配置类型
特殊的,你最好单独分一个swap区(内存置换空间),它独为一类,功能是:当有数据被存放在物理内存里面,但是这些数据又不是常被 CPU 所取用时,那么这些不常被使用的程序将会被丢到硬盘的 swap 置换空间当中, 而将速度较快的物理内存空间释放出来给真正需要的程序使用
Linux挂载详解
2022-05-07 78举报
简介: 前面讲过,Linux 系统中“一切皆文件”,所有文件都放置在以根目录为树根的树形目录结构中。在 Linux 看来,任何硬件设备也都是文件,它们各有自己的一套文件系统(文件目录结构)。
前面讲过,Linux 系统中“一切皆文件”,所有文件都放置在以根目录为树根的树形目录结构中。在 Linux 看来,任何硬件设备也都是文件,它们各有自己的一套文件系统(文件目录结构)。
因此产生的问题是,当在 Linux 系统中使用这些硬件设备时,只有将Linux本身的文件目录与硬件设备的文件目录合二为一,硬件设备才能为我们所用。合二为一的过程称为“挂载”。
如果不挂载,通过Linux系统中的图形界面系统可以查看找到硬件设备,但命令行方式无法找到。
挂载,指的就是将设备文件中的顶级目录连接到 Linux 根目录下的某一目录(最好是空目录),访问此目录就等同于访问设备文件。
纠正一个误区,并不是根目录下任何一个目录都可以作为挂载点,由于挂载操作会使得原有目录中文件被隐藏,因此根目录以及系统原有目录都不要作为挂载点,会造成系统异常甚至崩溃,挂载点最好是新建的空目录。
举个例子,我们想通过命令行访问某个 U 盘中的数据,图 1 所示为 U 盘文件目录结构和 Linux 系统中的文件目录结构。
U 盘和 Linux 系统文件目录结构
图 1 U 盘和 Linux 系统文件目录结构
图 1 中可以看到,目前 U 盘和 Linux 系统文件分属两个文件系统,还无法使用命令行找到 U 盘文件,需要将两个文件系统进行挂载。
接下来,我们在根目录下新建一个目录 /sdb-u,通过挂载命令将 U 盘文件系统挂载到此目录,挂载效果如图 2 所示。
文件系统挂载
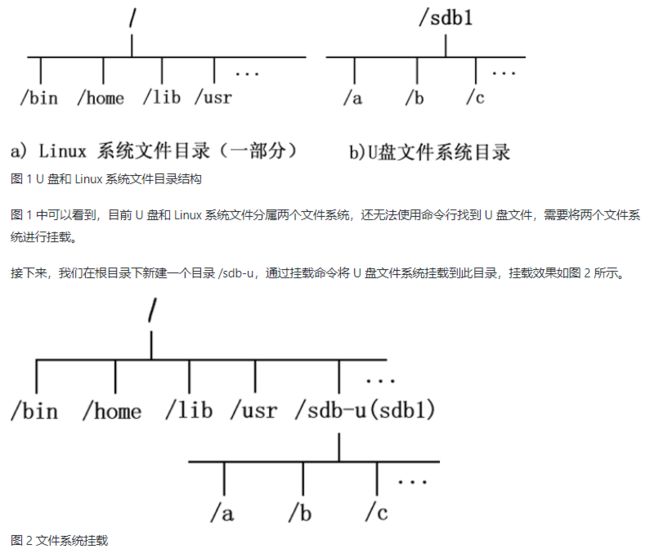
可以看到,U 盘文件系统已经成为 Linux 文件系统目录的一部分,此时访问 /sdb-u/ 就等同于访问 U 盘。
前面讲过,根目录下的 /dev/ 目录文件负责所有的硬件设备文件,事实上,当 U 盘插入 Linux 后,系统也确实会给 U 盘分配一个目录文件(比如 sdb1),就位于 /dev/ 目录下(/dev/sdb1),但无法通过 /dev/sdb1/ 直接访问 U 盘数据,访问此目录只会提供给你此设备的一些基本信息(比如容量)。
总之,Linux 系统使用任何硬件设备,都必须将设备文件与已有目录文件进行挂载。
具体的挂载以及卸载指令后续章节会详细介绍。
在一个区被格式化为一个文件系统之后,它就可以被Linux操作系统使用了,只是这个时候Linux操作系统还找不到它,所以我们还需要把这个文件系统「注册」进Linux操作系统的文件体系里,这个操作就叫「挂载」 (mount)。
挂载是利用一个目录当成进入点(类似选一个现成的目录作为代理),将文件系统放置在该目录下,也就是说,进入该目录就可以读取该文件系统的内容,类似整个文件系统只是目录树的一个文件夹(目录)。
这个进入点的目录我们称为「挂载点」。
由于整个 Linux 系统最重要的是根目录,因此根目录一定需要挂载到某个分区。 而其他的目录则可依用户自己的需求来给予挂载到不同的分去。
到这里Linux的文件体系的构建过程其实已经大体讲完了,总结一下就是:硬盘经过分区和格式化,每个区都成为了一个文件系统,挂载这个文件系统后就可以让Linux操作系统通过VFS访问硬盘时跟访问一个普通文件夹一样。这里通过一个在目录树中读取文件的实际例子来细讲一下目录文件和普通文件。
与windows内核差距
计算机是由各种外部硬件设备组成的,比如内存、cpu、硬盘等,如果每个应用都要和这些硬件设备对接通信协议,那这样太累了。
所以,这个中间人就由内核来负责,让内核作为应用连接硬件设备的桥梁,应用程序只需关心与内核交互,不用关心硬件的细节。
对于内核的架构一般有这三种类型:
宏内核,包含多个模块,整个内核像一个完整的程序;
微内核,有一个最小版本的内核,一些模块和服务则由用户态管理;
混合内核,是宏内核和微内核的结合体,内核中抽象出了微内核的概念,也就是内核中会有一个小型的内核,其他模块就在这个基础上搭建,整个内核是个完整的程序;
Linux 的内核设计是采用了宏内核,Windows 的内核设计则是采用了混合内核。
这两个操作系统的可执行文件格式也不一样, Linux 可执行文件格式叫作 ELF,Windows 可执行文件格式叫作 PE。
常见面试题
CPU负载和CPU利用率的区别是什么?
首先,我们可以通过uptime,w或者top命令看到CPU的平均负载。
Load Average :负载的3个数字,比如上图的4.86,5.28,5.00,分别代表系统在过去的1分钟,5分钟,15分钟内的系统平均负载。他代表的是当前系统正在运行的和处于等待运行的进程数之和。也指的是处于可运行状态和不可中断状态的平均进程数。
如果单核CPU的话,负载达到1就代表CPU已经达到满负荷的状态了,超过1,后面的进行就需要排队等待处理了。
如果是是多核多CPU的话,假设现在服务器是2个CPU,每个CPU2个核,那么总负载不超过4都没什么问题。
怎么查看CPU有多少核呢?
通过命令cat /proc/cpuinfo | grep "model name"查看CPU的情况。
通过cat /proc/cpuinfo | grep "cpu cores"查看CPU的核数
CPU 利用率:和负载不同,CPU利用率指的是当前正在运行的进程实时占用CPU的百分比,他是对一段时间内CPU使用状况的统计。
我举个栗子:
假设你们公司厕所有1个坑位,有一个人占了坑位,这时候负载就是1,如果还有一个人在排队,那么负载就是2。
如果在1个小时内,A上厕所花了10分钟,B上厕所花了20分钟,剩下30分钟厕所都没人使用,那么这一个小时内利用率就是50%。
那如果CPU负载很高,利用率却很低该怎么办?
CPU负载很高,利用率却很低,说明处于等待状态的任务很多,负载越高,代表可能很多僵死的进程。通常这种情况是IO密集型的任务,大量请求在请求相同的IO,导致任务队列堆积。
同样,可以先通过top命令观察(截图只是示意,不代表真实情况),假设发现现在确实是高负载低使用率。
然后,再通过命令ps -axjf查看是否存在状态为D+状态的进程,这个状态指的就是不可中断的睡眠状态的进程。处于这个状态的进程无法终止,也无法自行退出,只能通过恢复其依赖的资源或者重启系统来解决。(对不起,我截不到D+的状态)
那如果负载很低,利用率却很高呢?
如果你的公司只有一个厕所,外面没人排队,却有一个人在里面上了大半个小时,这说明什么?
两种可能:他没带纸,或者一些奇怪的事情发生了?
这表示CPU的任务并不多,但是任务执行的时间很长,大概率就是你写的代码本身有问题,通常是计算密集型任务,生成了大量耗时短的计算任务。
怎么排查?直接top命令找到使用率最高的任务,定位到去看看就行了。如果代码没有问题,那么过段时间CPU使用率就会下降的。
那如果CPU使用率达到100%呢?怎么排查?
通过top找到占用率高的进程。
通过top -Hp pid找到占用CPU高的线程ID。这里找到958的线程ID
再把线程ID转化为16进制,printf “0x%x\n” 958,得到线程ID0x3be
通过命令jstack 163 | grep ‘0x3be’ -C5 --color 或者 jstack 163|vim +/0x3be - 找到有问题的代码
Arthas
说到dump内存,常见的可能就是使用jmap 命令来处理,但是这里跟大家分享一个新的阿里开源的工具Arthas。
Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪Java代码;实时监控JVM状态。
我个人觉得也确实是蛮好用的。官方文档:https://arthas.aliyun.com/doc/arthas-tutorials.html?language=cn