软考中级-嵌入式系统设计师(一)
第一章 嵌入式系统基础、系统软件和操作系统
1、嵌入式微处理器结构

2、计算机硬件组成
基本的计算机硬件系统组成:运算器、控制器、存储器、输入设备和输出设备。

程序计数器(PC):在程序开始执行前,将程序的起始地址送入PC,该地址在程序加载到内存时确定,因此PC的内容是程序第一条指令的地址。执行指令时,CPU自动修改PC的内容,以便使其保存的总是将要执行的下一条指令的地址。由于大多数指令都是按顺序执行的,修改的过程只是对PC加1。
寄存器组:专用寄存器和通用寄存器。运算器和控制器的寄存器是专用寄存器,作用是固定的。通用寄存器用途广法并可由程序员规定其用途,其数目因处理器不同而差异。
CPU依据指令周期的不同阶段来区分二进制的指令和数据,因为在指令周期的不同阶段,指令会命令CPU分别去取指令或者数据。
3、数据的表示
十进制和二进制互转(下午题考察)
例如十进制数175.71875转换为二进制数。计算步骤分两步。
第一步只看整数位,175/2=87..1 87/2=43..1 43/2=21..1 21/2=10..1 10/2=5..0 5/2=2..1 2/2=1..0 1/2=0..1 二进制采取余数表示,并且顺序是反着的,为10101111。
第二部只看小数位,0.71875*2=1.4375 0.4375*2=0.875 0.875*2=1.75 0.75*2=1.5 0.5*2=1 二进制采取整数表示,并且顺序是正着的,为10111。
即十进制数175.71875转换为二进制数为10101111.10111。
二进制转换为十进制如下:
10101111.10111=2^7+2^5+2^3+2^2+2^1+2^0+2^-1+2^-3+2^-4+2^-5=175.71875
八进制和十进制互换也类似。
八进制和二进制互转、十六进制和二进制互转(下午题考察)
3个二进制位组成1个八进制位,4个二进制位组成1个十六进制位。
例如将二进制数10101111.10111转换为八进制和十六进制。
10101111.10111 = 010 101 111 . 101 110 = 257.56
10101111.10111 = 1010 1111 . 1011 1000 = AF.B8
原码、反码、补码和移码
如果机器字长为n,则最高位是符号位,0正1负。其余的n-1位表示数值的绝对值。
正数的原码和反码、补码相同。
负数的反码是,除符号位外,n-1位取反。以原码作为参照。
负数的补码是,除符号位外,原码加1。正负零的补码相同。当符号位为1而数值位全为0时,表示整数-2^(n-1),即符号位的1既表示负数也表示数值。
正数、负数的移码是,将补码的符号位取反。移码常用来表示浮点数中的阶码。
定点数:表示数据时小数点的位置固定不变
定点整数:纯整数,小数点在最低有效数值位之后。
定点小数:纯小数,小数点在最高有效数值位之前。
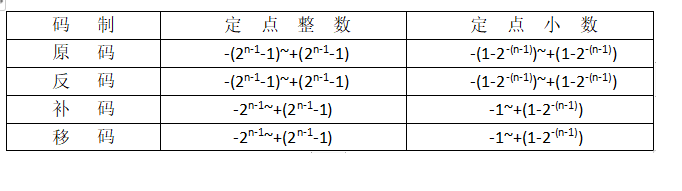
浮点数:表示数据时小数点位置不固定

异或:同0非1
3、校验码
码距:两个码组对应位上数字不同的个数。例如00110和00100码距为1,12345和13344码距为2,Caus和Daun码距为2。
码距越大越利于纠错和检错。
奇偶校验码:编码中加0、1使1的个数为奇数(奇校验)或偶数(偶校验),从而使码距变为2。
对于奇偶校验,它可以检测代码中奇数位出错的编码,但不能发现偶数位出错的情况。
循环冗余校验码(CRC编码-可以检错但不能纠错):利用生成多项式为k个数据为产生r个校验位来进行编码,其编码长度为k+r。广泛应用于数据通信领域和磁介质存储系统中。

海明码:在数据位之间的特定位置插入k个校验位,通过扩大码距来实现检错和纠错。
本质是使用奇偶校验方式校验。海明码需满足关系:2^k>=n+k+1,n代表数据位,k代表校验位。

4、计算机指令基本信息
计算机指令组成:操作码+操作数
计算机指令执行过程:取指令-分析指令-执行指令
指令寻址方式:顺序寻址方式、跳跃寻址方式。
指令操作数寻址方式:


5、指令系统CISC和RISC
RISC(Reduced Instruction Set Computer):精简指令系统计算机。
CISC(Complex Instruction Set Computer):复杂指令系统计算机。
RISC编译器的子程序库通常要比CISC的子程序库大得多。
RISC比CISC更加适合VLSI工艺的规整性要求。
CISC系统中的指令可以对主存单元中的数据直接进行处理,其执行速度较慢。目前使用的绝大多数计算机都属于CISC类型。
RISC的关键技术:重叠寄存器窗口技术、优化编译技术、超流水及超标量技术、硬布线逻辑与微程序相结合在微程序技术中。
RISC中采用的流水技术:超流水线技术、超标量技术、超长指令字技术(VLIW)。

6、指令流水线处理
RISC的流水线技术

流水线冒险
由于各种原因导致指令流水线执行时阻塞并延期,可能出现的问题有执行结果错误或流水线可能会出现停顿,从而降低流水线的实际效率和加速比。

流水线周期(▲t):指令段中执行时间最长的。
流水线总执行时间(t):t = t1 +(n-1)▲t,一条指令总执行时间+(总指令条数-1)*流水线周期。
流水线吞吐率=n/t(单位时间)。
流水线加速比=不使用流水线执行时间/使用流水线执行时间。
7、中断原理(下午题填空)

8、存储系统

计算机采用分级存储体系的主要目的是解决存储容量、成本和速度之间的矛盾问题。
两级存储映像:cache-主存、主存-辅存。
随机存储器:访问任意存储单元所用时间相同。
顺序存储器:顺序访问,如磁带。
直接存储器:磁道的寻址随机,磁道内寻址顺序。如磁盘。
高速cache:控制部分+存储器
内容是主存内存的副本拷贝,对于程序员来说是透明的。
控制部分判断CPU要访问的数据是否在cache中,在则命中,不在则依据一定的算法从主存中替换。
9、Cache地址映射方法
由硬件自动完成映射。
直接映像:块与块固定对应。
全相联映像:块与块任意对应。
组组相联映像:先分块,再分组。块直接映像,组全相联映像。
按照Cache地址映像的快冲突概率,从高到低排列的是:直接映像-组相联映像-全相联映像。
Cache容量越大,则命中率越高,随着Cache容量的增加,其命中率接近100%,非线性增长。但增加Cache容量意味着增加Cache的成本和增加Cache的命中时间。
提高Cache命中率的方法主要有选择适当的块容量、提高Cache的容量和提高Cache的相联度等。
现代CPU中Cache分位多个层级。

在多级Cache的计算机中,Cache分为一级(L1 Cache)、二级(L2 Cache)、三级(L3 Cache)等,CPU访存时首先查找L1 Cache,如果不命中,则访问L2 Cache,直到所有级别的Cache都不命中,才访问主存。通常要求L1 Cache的速度足够快,以赶上CPU的主频。如果Cache为两级,则L1 Cache的容量一般都比较小,为几千字节到几十千字节;L2 Cache则具有较高的容量,一般为几百字节到几兆字节,以使高速缓存具有足够高的命中率。
CPU与主存之间的数据交互,内存会先将数据拷贝到cache中,若cache的数据被循环执行,则不用每次都去内存中读取数据,会加快CPU的工作效率。

10、IO端口的地址编址
I/O独立编址:I/O端口编址和存储器编址分开设置,相互独立。不占用内存空间、程序清晰、译码电路简单,但只能用专门的I/O指令。
存储器统一编址:从存储空间划出一部分地址给I/O端口。

大端模式:高位数据存低位内存地址。
小端模式:高位数据存高位内存地址。
常见的电脑PC机一般采用小端模式。
11、总线

总线事务:从请求总线到完成总线使用的操作序列。
它是在一个总线周期中发生的一系列活动。总线完成一次传输,分四个阶段:总线裁决、寻址阶段、数据传输阶段、结束阶段。
12、性能和可靠性
可靠性指标
平均无故障时间MTTF=1/失效率
平均故障修复时间MTTR=1/修复率
平均故障间隔时间MTBF=MTTF+MTTR
系统可用性=(MTTF/MTBF)*100%
串并联系统可靠性计算

计算机系统的性能指标
可靠性或可用性:计算机系统能正常工作的时间,其指标可以是能够持续工作的时间长度(例如,平均无故障时间),也可以是在一段时间内,能正常工作的时间所占的百分比。
处理能力或效率:
第一类指标是吞吐率(系统在单位时间内能处理正常作业的个数)
第二类指标是响应时间(从系统得到输入到给出输出之间的时间)
第三类指标是资源利用率,即在给定的时间区间中,各种部件(包括硬件设备和软件系统)被使用的时间与整个事件之比。
计算机硬件性能指标
指令周期:取出并执行一条指令的时间。
指令周期 = n*总线周期 = n*m*时钟周期
MIPS用于衡量标量机性能。
13、嵌入式软件基础

14、嵌入式操作系统
嵌入式实时系统中,要求系统在投入运行之前即具有确定性和可预测性。主要特点是及时响应和高可靠性。
硬实时要求在规定的时间内必须完成操作;
软实时只要按照任务优先级,尽可能快地完成操作即可。
15、进程与线程
17、外存储器
外存储器存放暂时不用的程序和数据,并且以文件的形式存储。CPU不能直接访问外存中的程序和数据,只能将其以文件为单位调入主存才可访问。
包括磁盘存储器、光盘存储器、固态硬盘。
DVD-RAM和DVD-RW是DVD技术所支持的两种不同的可多次擦除重写的DVD光盘格式。
CD-R指一次性可写(刻录)CD光盘,而CD-RW指可多次擦除重写的CD光盘。
19、输入输出控制
IO设备:块设备、字符设备
块设备可寻址,例如磁盘、USB闪存、CD-ROM等。字符设备不可寻址,例如打印机、网卡、鼠标键盘。
程序控制IO方式:无条件传送、程序查询方式。
无条件传送:外设总是准备好的,它可以无条件地随时接收CPU发来的输出数据,也能够无条件地随时向CPU提高需要输入地数据。
程序查询方式:通过CPU执行程序来查询外设的状态,判断外设是否准备好接收数据或准备好了向CPU输入的数据。
中断
当系统与外设交换数据时,CPU无需等待也不必去查询I/O设备的设备,而是处理其他任务。当I/O设备准备好以后,就发出中断请求信号通知CPU,CPU接到中断请求信号后,保存正在执行程序的现场,转入I/O中断服务程序的执行,完成与I/O系统的数据交换,然后再返回被打断的程序继续执行。与程序控制方式相比,中断方式因为无需CPU等待而提高了效率。
系统具有多个中断源时,常用中断处理方法:多中断信号线法、中断软件查询法、菊花链法、总线仲裁法和中断向量表法等。
DMA方式
在计算机与外设交换数据的过程中,无论是无条件传送、程序查询方式传送还是中断传送,都需要由CPU通过执行程序来实现,这就限制了数据的传送速度。
在内存与IO设备间传送一个数据块的过程中,不需要CPU的任何干涉(整个系统总线完全交给了DMA控制器DMAC,由它控制系统总线完成数据传送),只需要CPU在过程开始启动与过程结束时的处理,实际操作由DMA硬件直接执行完成,CPU在此传送过程中可做别的事情。在DMA传送数据期间,CPU不能使用总线。
输入/输出处理机
DMA方式的出现减轻了CPU对I/O操作的控制,使得CPU的效率显著提高,而输入/输出处理机的出现进一步提高了CPU的效率。
20、计算机体系结构
按处理机数量分类:单处理系统、并行处理与多处理系统、分布式处理系统。
按并行程度分类:Flynn分类法、冯泽云分类法、Handler分类法、Kuck分类法。
Flynn分类法:根据指令流和数据流分类。
单指令流单数据流机器(SISD)。所有的指令都是串行执行,并且在某个时钟周期内,CPU只能处理一个数据流。早期的计算机都是 SISD 机器。
单指令流多数据流机器(SIMD)。SIMD采用了资源重复的措施开发并行性。现在用的单核计算机基本上都属于SIMD机器。
多指令流单数据流机器(MISD)。在实际情况中,MISD 只是作为理论模型出现,没有实际应用。
多指令流多数据流机器(MIMD)。最新的多核计算平台就属于MIMD的范畴,例如Intel 和 AMD 的双核处理器。

冯泽云分类法:按并行度分类。
字串行位串行计算机(WSBS)、字并行位串行计算机(WPBS)、字串行位并行计算机(WSBP)、字并行位并行计算机(WPBP)。
Handler分类法:基于硬件并行程度计算并行度。
处理机级、每个处理机中的算逻单元级、每个算逻单元中的逻辑门电路级。
Kuck分类法:根据指令流和执行流分类。
单指令流单执行流机器(SISE)、单指令流多执行流机器(SIME)、多指令流单执行流机器(MISE)、多指令流多执行流机器(MIME)。