一次联合索引优化引发的思考
问题描述
DBA在群里报产线DB有故障,数据库所在机器的CPU使用率高达95%, 短时间内报了500+条慢查询,其中出现最多的是下面一条SQL语句:

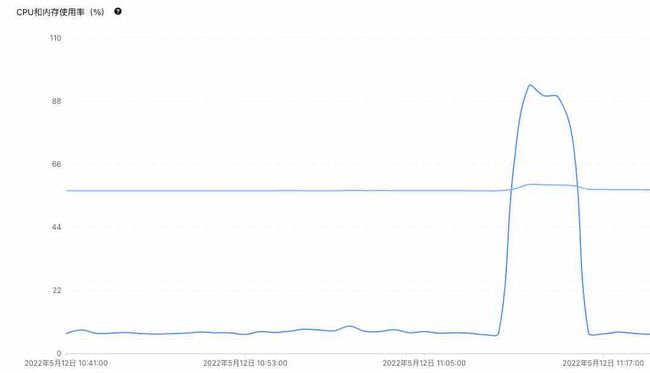
产线出故障时,运维同学一般都是描述现象,一个现象要转换为可以具体排查的问题,往往需要做一些信息的确认和提取工作的。
就这个问题来说,CPU占用率高是现象,DBA帮我们做了第一步的信息提取:发现一条慢SQL。
但是这个问题还不够具体,比如:究竟是不是这条慢SQL导致了CPU高是需要确认的,另外这个慢SQL究竟有多慢也不知道,所以研发还需要做进一步的信息提取。
在我们的追问下,DBA又给出数据库系统记录的慢查询具体信息:
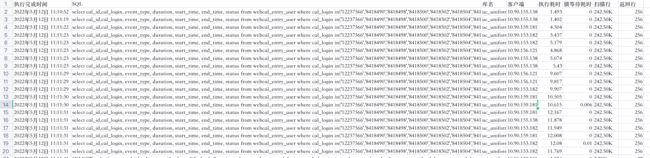
从截图上可以看出,这条SQL扫描了24万行记录,最终返回的结果只用到了256行,执行时间1~10s不等。
SQL中访问的唯一一张表webcal_entry_user, 是日程业务中的参会人信息表,表中有2000多万条数据,表和索引结构如下:

可以说,这条SQL结构并不复杂,没有联表,没有排序,唯一需要看的是索引的命中情况和是否命中最优索引,通过explain来分析下(下图是从beta截出来的,除了扫描行数与产线不一样,其它都相同):
![]()
从分析的结果来看只有一个条件过滤cal_login in (xxx)命中的了索引,这个字段的区分度并不差,可惜的是要查300用户,并且数年积累下来共计有24万条参会记录。
换句话说,用索引筛选完后,还有24万条记录需要从DB加载到内存用where条件再来筛一遍,扫描行数太多是慢的根因。
解决方案
先说结论,最终给DBA发了一条索引变更语句,产线变更后,扫描行数也下降到了1000行左右,常规执行时间下降到了34ms。
ALTER TABLE `webcal_entry_user` DROP INDEX `idx_cal_login`, ADD INDEX `idx_cal_login` (`cal_login`,`end_time`);
![]()
对于产线故障来说,最终的解法往往都比较简单,复杂的地方在思考方案过程中所运用的知识和原理。对于联合索引来说,可能涉及到的知识点例如:
- 用什么字段建联合索引?
- 联合索引中多个字段的顺序选择,哪个字段放前边,哪个字段放后边?
- 索引字段中等值查询与范围查询的区别
- 既有where条件又有order by语句时如何选择索引字段?
背后的知识和思考
用什么字段建立联合索引?
索引的目的是为了快速过滤出业务需要的最小数据集合,如果任何一个单列索引过滤效果都不明显,就会考虑是不是再加一个过滤条件让最终结果的数据小一些。
**知识点:**用索引筛掉的数据越多,需要从磁盘加载到内存的数据集就越小。不过索引本身也是有开销的,所以创建索引时需要取一个权衡:能够解决问题的最小索引。
就以这个问题为例,cal_login字段过滤完后,还有24万条数据,就必须再找一个筛选效率好的条件来作为第2个索引字段,分析过程是:
- cal_status in(‘A’,‘W’) :表示参会人接受会议邀请的状态,A(Accept)和 W(Wait)是绝大部分参会人的状态,此条件有和无对最终的扫描行数几乎没有区别;
- status != 0 :表示会议状态为0(取消)以外的任何状态,同上,没有什么过滤效果;
- start_time < 1652344200:表示会议开始时间小于2022-05-12 16:30:00的记录
- end_time > 1652340600:表示会议结束时间大于2022-05-12 15:30:00的记录
为什么最终我们添加end_time字段作为索引而不用start_time呢?
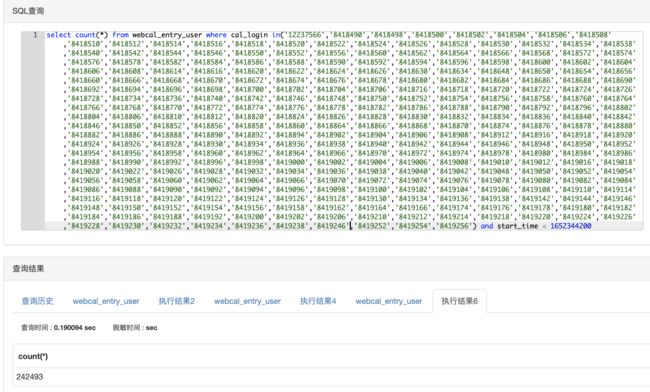
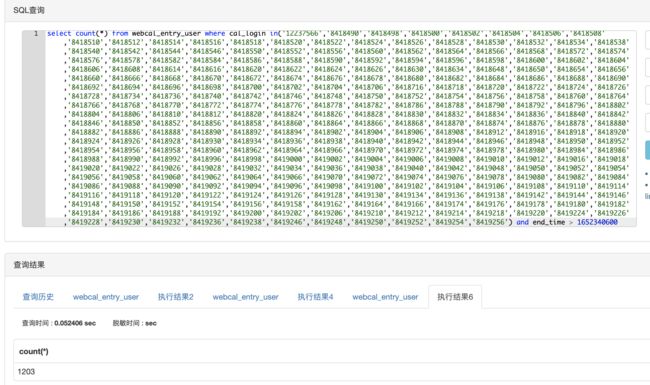
基于对业务的理解来判断:
- 这条SQL是用来获取参会人指定时间段内忙闲状态的,只有预约会议时才会调用;
- 预约会议选的基本都是将来的时间,并且这个时间段跨度不会太大,常规可选的也就是0~24小时;
- end_time > 1652340600可以理解为筛选指定时间段之后未召开的会议,start_time < 1652344200表示筛选指定时间段之前的历史会议,未召开的会肯定比历史的会数量少;
所以做技术的人,理解业务很重要。
那为什么我们是建立(cal_login,end_time)的联合索引,而不是(end_time,cal_login)的联合索引呢?
最左原则
**知识点:**多个字段建立的索引是有顺序的,只有左边的字段命中了索引,右边的字段才可能命中索引。
假如我们对(a, b)字段建立了索引,
Case1: 当where条件为下面的两种时
a = 1
a = 1 and b = 2
都是可以命中索引的。
Case2: 当where条件为
b= 2 and a =1
也是可以命中索引的。不是我们写的对,而是Mysql优化器帮我们做了调整,调整后按 a = 1 and b = 2 来执行去匹配索引中的字段顺序(a, b)。
Case3: 如果执行 b = 2 就命中不了索引了,这就是索引的最左匹配原则。
那为什么会这样呢?
索引能够加快查找的原理在于:索引字段是有顺序的,通过二分查找能够快速匹配目标数据。
而对于(a, b) 这类联合索引来说,B+树的结构大概如下:
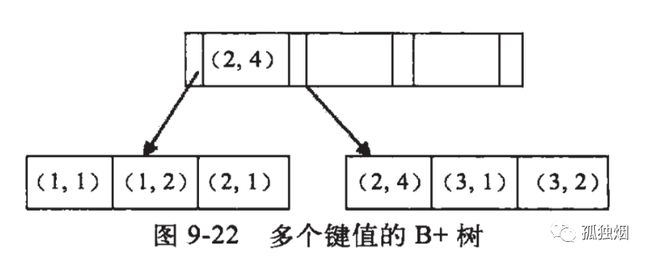
可以看出,第一个字段a是顺序递增的(1,1,2,2,3,3),而第二个字段b总体上却没有明显的顺序(1,2,1,4,1,2),只是局部有序(a固定的时候b是递增的)。
- 正是由于字段b整体无序,所以前面提到的直接执行b=2单个条件是无法使用索引的;
- 因为a确定的时候b字段局部有序,所以
a = 1 and b = 2这个组合条件中的b字段可以使用索引;
**有的小伙伴还会抛出一个疑问:**如果只考虑 a=1 and b=2 这种组合条件,创建联合索引时该创建(a, b) 还是(b,a)呢?
对于等值查询来说,一般是把区分度高的字段放在前面,像姓别、状态这类区分度很低的字段放后面。用show index from [table_name]可以查看:
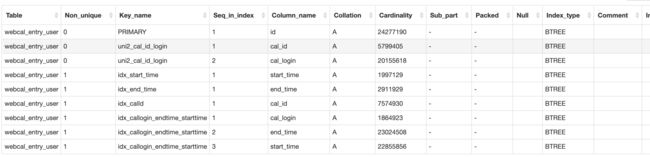
这里限定了条件是等值查询,对于(>、<)这类范围查询,索引字段顺序的考量是有些区别的。
范围查询
**知识点:**范围查询右边的所有列都无法使用索引,在创建索引时应当将范围查询条件放在靠后的位置。
还是之前的(a, b)联合索引,例如这个组合条件:a > 1 and b = 2 , a > 1可以命中索引,但 b=2却无法命中索引。
原因在于:a>1是一个模糊的范围,在这个模糊的范围里,数据结构上b字段是无序的(1,4,1,2)。
那回到我们这次遇到的情况,对于
cal_login in ('8418760','8418764','8418766')and end_time > 1652340600
这类组合条件,后面的end_time > 1652340600 肯定是范围查询,那前者呢?
说到这里,挺惭愧,自认为对索引还算有一定程度的了解,但在遇到这次的问题之前,这个Case我的理解一直是错的。
SQL里的 in 这种语法,看着像范围查询,但是实际动手在线下环境操作去创建一个(cal_login,end_time)这种联合索引,上面组合条件中的end_time是可以使用索引的,应该是SQL优化器做了专门的优化。
按照目前网上大部分文章的说法,能确定是范围查询的语法包括这几个 (>、<、between、like)。
order by / group by
一般创建联合索引还会面临的一个选择是如何让分组/排序这种语法命中索引。实际工作中用explain分析慢查询时会遇到这类问题:

extra一栏中的filesort表明使用内存排序,temporary表明由于要排序的记录太多,使用了磁盘临时文件。两种都比较耗资源,后者更甚,一旦使用了磁盘临时文件,这个SQL基本会成为慢查询的常客。
最好的情况是让order by 语句命中索引,相关知识点:
- order by、group by使用索引的前提条件:相关字段在where条件中出现并在where条件执行的时候使用了索引;
- 对于联合索引(a, b), 如果where条件中字段a是等值查询,则order by中的字段b可以使用索引排序;
- 对于联合索引(a, b), 如果where条件中的字段a是in/or查询,则order by 中的字段b无法使用索引排序,因为order by 要求是全局有序才能排,而联合索引中的b只能做到局部有序;
例1, 适合给(a, b)建立联合索引,a=1的时候b相对有序:
SELECT * FROM `table` WHERE a = 1 ORDER BY b;
例2, 带范围查询又带order by 语句的SQL:
SELECT * FROM `table` WHERE a = 1 AND b IN (1,2,3) AND c > 3 ORDER BY c;
假如索引是(a, b, c), 由于b不确定,所以order by c是无法使用索引的,不过c > 3条件可以使用索引。
总结
- 产线报故障时,首先要想想能获取哪些现场信息,一个具体的现场信息能帮我们快速锁定问题;
- 做技术一定要关心业务,清楚的知道自己业务中哪些数据量大,哪些数据量小,哪些是低頻请求,哪些是高频请求,哪些情况会发生,哪些情况不会发生;
- 建联合索引遵循最左原则,只有左边字段命中索引,右边字段才可能命中索引;
- 范围查询字段始终放到联合索引的最后。
参考资料
- https://www.cnblogs.com/rjzheng/p/12557314.html
本文由博客一文多发平台 OpenWrite 发布!