从零开始带你了解商业数据分析模型——2.逻辑回归模型
-
摘要
在上一篇文章里,我们着重讲解了线性回归。既如何探索不同的影响因素(或自变量)与一个连续型变量的的线性关系。但在现实生活中,我们关心的往往是分类型的问题。比如生物学家会去探究不同的生活习惯和遗传基因是否会导致相应的癌症,比如汽车厂商会去探究不同的驾驶行为和行驶路况是否会导致汽车的部件提前损坏,再比如银行信贷部会去探究不同的客户背景和历史还款情况是否会导致借贷人下次逾期还款。类似的分类决策型问题在企业运作中比比皆是。
本章的内容旨在为大家介绍最常见的分类型预测模型 – 逻辑回归。当然,能做分类型预测的模型还有很多,比如决策树,随机森林,支持向量机,深度学习等等。我们也会在接下来的章节里为大家一一介绍。
- 逻辑回归
2.1. 逻辑回归和线性回归
作为最常见的两种回归预测模型,逻辑回归和线性回归其实存在着很多共性。比如他们都有很类似的问题结构和很类似的分析流程。但他们最大的区别在:
• 线性回归的预测结果通常是一个连续型变量;
• 逻辑回归的预测结果通常是一个类别型变量,其中又以二元变量的预测为主。既“是”或“否”型的决策判断问题。
理论上来说,任何的线性回归都可以视为逻辑回归。比如,我们想要建立一个线性回归模型来预测不同人的寿命长短。线性回归模型的结果可能是会返还一个范围在65岁到110岁间的预测数值。从逻辑回归的角度来看,我们可以将65岁到110岁视为46个不同的预测类别。对于每一个待预测的样本,逻辑回归的预测结果是该样本分别落在这46个不同的预测类别里的不同概率,通常我们会选择概率最好的那个类别来作为该样本的预测年龄。不过这样的转换会使得我们的预测模型过于复杂,因此逻辑回归最常见的用途还是用来讨论二元变量的预测问题。

2.2. 逻辑回归的定义
既然逻辑回归和线性回归有如此多的共性,大家有没有去试着思考,我们如何用线性回归的思维去解决逻辑回归的问题?我们知道逻辑回归是在关注一个取值为“1”或“0”的变量,而线性回归则是在关注一个取值为实数域的变量。套用相同方法的关键,就在于我们能否将一个0与1的二元变量映射到一个从负无穷到正无穷的连续型变量的取值区间?
我们可以通过一下操作实现这个转换:
• 定义 p(x) : 固定自变量的取值情况,因变量得“1”的概率。原本因变量只能取值0或者1,但是通过这一步转换,p(x) 的取值范围拓展到了0到1这个连续区间;
• 定义
![]()
p(x) 代表了因变量取“1” 的概率,1-p(x)则代表了因变量取 “0” 的概率。他两相除则代表的是:给定自变量取值的情况下,因变量取值为1的几率。通过这一步转换,我们成功将odds的取值范围拓展到了0到正无穷这个连续区间;
• 定义
![]()
: 最后一步的转换是我们将odds取对数。终于,我们成功的将取值范围拓展到了负无穷到正无穷的这个实数域区间。
做完了上述的转换,我们最终得到了下面的公式:
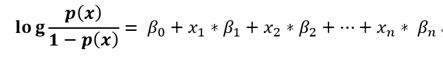
如果将公式左边的式子看作一个整体 y,
是不是就变成了上一章节讲解到的线性回归的样子。之后我们通过训练数据依次求出β0, β1, β2,…, βn.
随后我们化简上述上述公式,即可求得:

当然算出的p(x)仍然会是一个0到1的连续型变量。通常来说,当p(x)>=0.5时,我们视预测结果为1;当p(x)<0.5时,我们则会视预测结果为0.

2.3. 逻辑回归的简单案例
上面的公式可能会把大家看的头晕。下面,我们会借助一个简单的例子解释这些转换过程。
比如说,我们现在想要探究的是篮球爱好者的身高和他们罚球命中率的关系。我们收集到了以下的10个数据点。
![]()
基于上个小结中的转换公式,我们可以求出以下数值:
• P(罚球命中|身高为170cm):身高170cm的爱好者,他们罚球命中的概率是 2/5= 40%
• Odds:身高170cm的爱好者,他们罚球命中的几率40%/(1-40%)= 0.66
• Logit Transformation: log (odds) = -0.18。这是针对于身高170cm的爱好者
• 同样的针对与身高180cm的爱好者,我们可以算出他们的log(odds)为0.176
当根据不同的身高,得出了它们相对应log(odds)的转换值后,我们可以套用下面的公式得出β0 与β1的参数值:

最后我们只需套用下面的公式,即可得出不同身高的爱好者,罚球命中的概率:

如果这个概率值 >= 0.5,
我们则判定这位爱好者可以命中罚球。反之不行。
希望通过这个例子,大家可以更清晰的了解到逻辑回归的计算过程。当然我们所举的这个例子过于简单。通常一个逻辑回归问题,它的自变量远远不止一个,且自变量取值的组合情况极为复杂。
2.4. 逻辑回归的优劣分析
终于到了最后的优劣分析。随着越来越多的预测模型,先进技术的出现,了解清楚他们的优劣情况,适用案例和数据类型也变得极为重要。
作为一种传统的,适用范围最广的分类型预测模型。选择使用逻辑回归主要有以下几个原因:
• 模型理论简单,相对透明,模型结果易于解释
• 模型计算简单高效,可扩展到大数据处理
• 多重共线性问题易于解决,解决过拟合的方法也有很多
• 在行业实际应用中表现良好,且实施难度很低
与这些优点相对的,就是一些我们需要考虑的逻辑回归的缺点:
• 当自变量数目过大时,逻辑回归的计算性能,结果表现不是太好
• 容易欠拟合,最终导致结果精度不太高
• 逻辑回归本质还是一个线性分类器,很难处理线性不可分的样本
-
如何在Altair KnowledgeStudio平台应用线性回归
3.1. 演示数据简介
在接下来的软件操作环节,我们会使用到下面这个名为“Census“的数据集。
该数据集记录了16000位不同客户针对某金融公司营销广告的反馈情况。我们想要通过逻辑回归这个模型,帮助这家公司找到他们的目标客群,从而达到精准营销的效果。
在这个数据集中,我们主要关心的变量有:
• “Response“ – 因变量: 该客户是否对此条营销广告做出了正面积极响应;
• 客户的基本信息 – 自变量:比如年龄,工种行业,家庭关系,婚姻状况,性别等;
• 客户的历史理财情况 – 自变量:比如理财收益或理财损失。

3.2. 软件操作演示
3.2.1. 数据预处理
任何一个数据分析项目都躲不掉繁重的数据预处理工作,比如数据画像,数据清洗,数据集成,数据变换等等。通常从业人员会花费70%的时间在这一项工作中。
因为在上一篇文章中,我们已经粗略介绍了Altair
KnowledgeStudio的数据预处理功能。这里我们便不再做过多的赘述。希望了解更多的读者可以私信我们,或翻阅往期文章。
我们已经事先处理好了该数据,并将之分成了训练集“census3_train2“和测试集”census3_test“。随后我们会在训练集上建立逻辑回归模型。

3.2.2. 逻辑回归节点使用
双击点开逻辑回归节点,我们可以在第一个操作界面中设置结果模型名称以及确认建模使用的数据。随后点击下一步进行深入的参数设置。

第二个界面主要包含了变量选择的相关参数。比如:
• 界面的最上方,我们需要设定清楚我们的因变量是什么;
• 界面的中间,我们可以设定不同的变量选择算法和相应的算法停止条件;
• 界面的最下方,我们可以进一步约束自变量选择。比如哪些自变量应该被模型考虑,哪些自变量一定要包含在最终的模型之中。
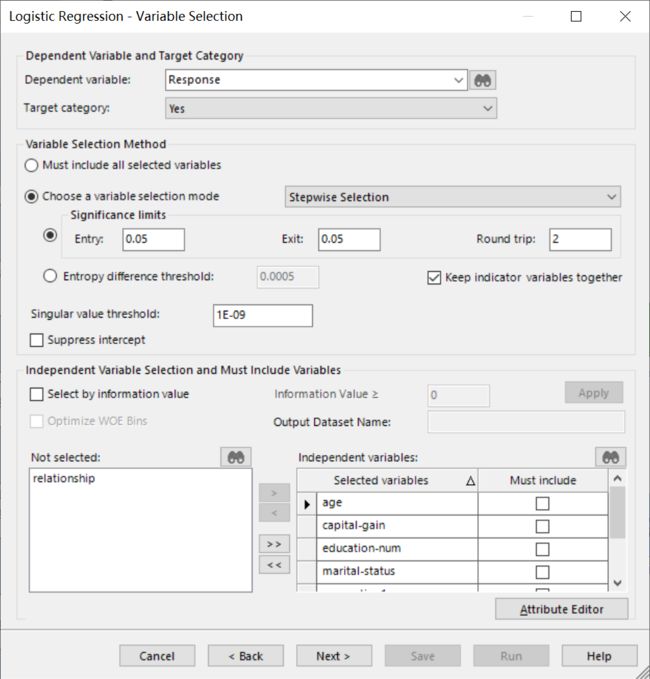
在最后一个界面中,我们可以设置迭代次数、优势比的置信水平、优化方法等等。
当确认完毕一切相关参数后,我们可以选择运行模型。

3.2.3. 模型结果解读
等待模型建立完毕后,我们可以双击模型节点,得到模型的结果报告。
在Model Overview的选项卡中,可以看到最终模型选中的变量及其模型的训练效果。如下图所示:为预测客户对营销方案的反馈情况,模型中的自变量主要涵盖了年龄,教育,婚姻状况,职业,性别等信息,而训练模型的正确预测约为84.4%。

更多的模型拟合参数,我们需要跳转进下一张选项卡中。如下图所示,我们可以找到:
• 评价整理模型有效性的度量值: 如p-value,Chi-square等;
• 评价模型准确度的测量值:如Entropy Explained, Generalized R^2等;
• 评价模型复杂度的测量值:如AIC,BIC等;
• 更多的相关参数解释可以在软件内置的帮助手册中找到。

除了模型的整体参数表,下图所示的模型系数表也至关重要。
比如可以通过p-value来判断各自变量的系数是否显著,比如我们可以通过odds的值来判定自变量的影响几率,比如我们还可以找到相应参数的置信区间等等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nx6QvFPC-1589467646962)( https://note.youdao.com/yws/api/personal/file/95A45ABCAF0442EAA41AD570EA9C1F88?method=download&shareKey=2238b0022fe3f08211bf443931bbf200)]
最后我们可以用下面的式子来表达该逻辑回归模型的最终表达式:
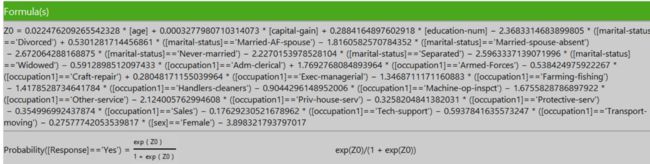
3.2.4. 建模之后
当上述模型建立完之后,我们还有很多工作需要做。
• 比如我们需要去使用测试数据集来验证模型是否存在过拟合;
• 比如我们需要去重新调整训练数据集,模型参数来提升模型精准度;
• 比如我们需要建立别的并行模型,来探究不同解决方案的可行性;
• 比如我们需要对比所有并行模型,再结合业务条件来确定最终的实施落地方案。
总而言之,预测模型的建立是一个复杂而漫长的过程。为找到一个适合当下业务,当下市场环境的模型方案,企业一定会耗费不少的时间与精力。
- 结语
希望通过这篇文章,大家能够对逻辑回归有更进一步的了解。
我们下一篇文章准备为大家简单介绍一下深度学习。如果大家对数据分析或者预测模型感兴趣,欢迎在文后留言与我们交流,也欢迎大家提出宝贵意见或建议。