Kafka底层原理分析
目录
1、Kafka源码部署
1.1 Scala环境变量
1.2 下载Kafka源码包
1.3 gradle编译部署
2、Kafka核心原理剖析
2.1 什么是分区
2.2 副本与ISR设计
2.3 日志设计
3、Kafka Server Reactor设计模型
3.1 认识Java NIO
4、Kafka 选举机制
4.1 控制器(Broker)选举
4.2 分区副本选举机制
5、Kafka HA设计解析
5.1 Replica均匀分布到整个集群
5.2 消息同步commit
6、Kafka幂等性
7、Kafka常见面试题
7.1 kafka实现高吞吐原因
7.2 kafka的偏移量存储
7.3 kafka消费数据方式
7.4 kafka如何保证数据不丢失/重复消费
7.5 Kafka元数据存哪
7.6 kafka版本问题
7.7 kafka如何保证不同副本都同步到相同的内容
7.8 Kafka Leader的选举机制
7.9 kafka 运行架构图
7.10 kafka消费速度提升
7.11 kafka ISR什么情况下broker id会消失
7.12 kafka数据存储
7.13 kafka消息有序吗
1、Kafka源码部署
1.1 Scala环境变量
因为Kafka是Java和Scala语言编写的,所以需要先安装配置JDK和Scala环境
下载:首先到Scala官网下载Scala网址为 Download | The Scala Programming Language
PS:下载版本需要根据Kafka源码中scala版本要求:
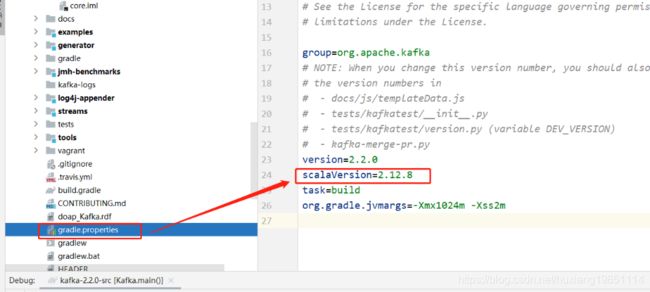

解压配置如下:

如果集群中有一个broker发生异常退出了,那么控制器就会检查这个broker是否有分区的副本leader,如果有那么这个分区就需要一个新的leader,此时控制器就会去遍历其他副本,决定哪一个成为新的leader,同时更新分区的ISR集合。

如果有一个broker加入集群中,那么控制器就会通过Broker ID去判断新加入的broker中是否含有现有分区的副本,如果有,就会从分区副本中去同步数据。
集群中每选举一次控制器,就会通过zookeeper创建一个controller epoch,每一个选举都会创建一个包含最新信息的epoch,如果有broker收到比这个epoch旧的数据,就会忽略它们,kafka也通过这个epoch来防止集群产生“脑裂”。
4.2 分区副本选举机制
Kafka在ZooKeeper中动态维护了一个ISR(in-sync replicas),这个ISR里的所有Replica都跟上了leader,只有ISR里的成员才有被选为Leader的可能。在这种模式下,如果有N+1**个Replica,一个Partition能在保证不丢失已经commit的消息的前提下容忍N个Replica的失败。在大多数使用场景中,这种模式是非常有利的。
在kafka的集群中,会存在着多个主题topic,在每一个topic中,又被划分为多个partition,为了防止数据不丢失,每一个partition又有多个副本,在整个集群中,总共有二种角色:
-
leader:每个分区都有一个leader,为了保证数据一致性,所有的生产者与消费者的请求都会经过该副本来处理。
-
follower:除了leader外的其他所有副本都是follower,follower不处理来自客户端的任何请求,只负责从leader同步数据,保证与follower保持一致。如果leader所在broker发生崩溃,就会从follower中选举出一个leader。
Kafka分区选举机制不是常见的多数选举,而是会在zookeeper上针对每一个Topic维护一个称为ISR(已同步可用副本)集合,只有这个ISR列表里面的副本才有资格称为leader,kafka在所有broker中选出一个controller(就是上面说的控制器选举),所有Partition的Leader选举都由controller决定。controller会将Leader的改变直接通过RPC的方式通知需为为此作为响应的Broker(因为zookeeper维护了ISR,所以知道通知哪些broker),这样每个Replica都要为此在ZooKeeper上注册一个Watch响应就变成了broker级别的响应了。 先试用ISR集合中的第一个,如果不行则依次类推,因为ISR里面是同步的副本,消息是最完整的且各个节点都是一样的 Data Replication如何处理Replica全部宕机? 1、等待ISR中任一Replica恢复,并选它为Leader 等待时间较长,降低可用性 或ISR中的所有Replica都无法恢复或者数据丢失,则该Partition将永不可用 2、选择第一个恢复的Replica为新的Leader,无论它是否在ISR中(包括OSR) 并未包含所有已被之前Leader Commit过的消息,因此会造成数据丢失 可用性较高 这是一个在可用性和连续性之间的权衡。如果等待ISR中的节点恢复,一旦ISR中的节点起不起来或者数据都是了,那集群就永远恢复不了了。如果等待ISR意外的节点恢复,这个节点的数据就会被作为线上数据,有可能和真实的数据有所出入,因为有些数据它可能还没同步到。 Kafka目前选择了第二种策略
5、Kafka HA设计解析
5.1 Replica均匀分布到整个集群
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。同时为了提高Kafka的容错能力,也需要将同一个Partition的Replica尽量分散到不同的机器。实际上,如果所有的Replica都在同一个Broker上,那一旦该Broker宕机,该Partition的所有Replica都无法工作,也就达不到HA的效果。同时,如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。
目前Kafka分配Replica的算法如下:
1).将所有Broker(假设共n个Broker)和待分配的Partition排序
2).将第i个Partition分配到第(i mod n)个Broker上
3).将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上5.2 消息同步commit
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK(acks=-1/all)。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供性能更高的持久性。
Consumer读消息也是从Leader读取,只有被Commit过的消息(offset低于HW的消息)才会暴露给Consumer。
Leader分区broker:
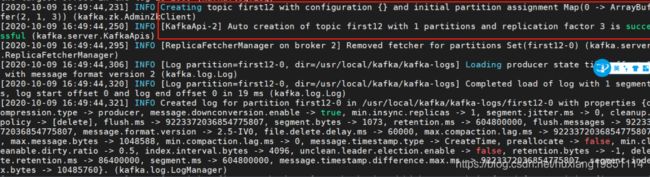
Follower分区broker:

6、Kafka幂等性
所谓幂等性,就是对接口的多次调用和一次调用是一样结果的,生产者在进行重试的时候可能会重复写入消息,而使用kafka的幂等性功能可以有条件避免这种情况!什么是有条件的避免:
1)、只能保证Producer在单个会话内不丢不重,如果Producer出现意外再重启是无法保证的(幂等性情况下是无法获取之前的状态信息,也就是说无法做到跨会话级别的不丢不重)
2)、幂等性不能跨多个Topic-Partition,只能保证单个partition内的幂等性,当涉及多个Topic-Partition,这中间的状态并没有同步Producer使用幂等性非常简单,只需要把Producer的属性配置enable.idempotence设置为true即可!
/**
当设置为'true'时,生产者将确保在流中只写入每条消息的一个副本
需要三个条件:
max.in.flight.requests.per.connection:客户端单个连接上发送的最大未确认请求数小于等于5
retries:客户端重试次数大于0
acks:所有follower副本确认(all)
*/
public static final String ENABLE_IDEMPOTENCE_CONFIG = "enable.idempotence";
public static final String ENABLE_IDEMPOTENCE_DOC = "When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. Note that enabling idempotence requires " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + " to be less than or equal to 5, " + RETRIES_CONFIG + " to be greater than 0 and " + ACKS_CONFIG + " must be 'all'. If these values "+ "are not explicitly set by the user, suitable values will be chosen. If incompatible values are set, a ConfigException will be thrown.";7、Kafka常见面试题
7.1 kafka实现高吞吐原因
为什么kafka可以实现高吞吐,就算单节点kafka的吞吐量也比其他消息队列大,为什么?
零拷贝(Zero-copy)----利用了NIO的通道(Channel)和缓冲区(Buffer)
顺写日志(单个partition,文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消 息,并且也不允许修改已写入的消息,)
预读(提前将一个比较大的磁盘块读入内存,把相关相近的数据也提前读取出来,比如LEO,offset)
后写(将很多小的逻辑写操作合并起来组成一个大的物理写操作,其实就是批量操作)
分段日志(稀疏索引)
压缩(对消息进行压缩可以极大地减少网络传输 量、降低网络 I/O,如:gzip、snappy、lz4)零拷贝:mmap

零拷贝:sendfile
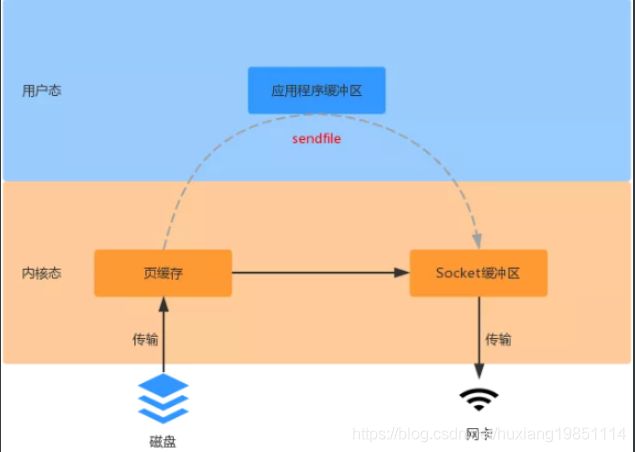
附零拷贝和传统拷贝速率测试代码,请将你的拷贝文件弄的尽可能大才能看出效果
import java.io.FileInputStream;
import java.io.FileOutputStream;
//传统拷贝
public class OldFileCopy {
public static final String source = "D:\\workspaces\\output.txt";
public static final String dest = "D:\\workspaces\\input.txt";
public static void main(String[] args) {
try {
FileInputStream inputStream = new FileInputStream(source);
FileOutputStream outputStream = new FileOutputStream(dest);
long start = System.currentTimeMillis();
byte[] buff = new byte[4096];
long read = 0, total = 0;
while ((read = inputStream.read(buff)) >= 0) {
total += read;
outputStream.write(buff);
}
outputStream.flush();
System.out.println("耗时:" + (System.currentTimeMillis() - start));
} catch (Exception e) {
e.printStackTrace();
}
}
}
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
//零拷贝-mmap
/**
map 就是在用户态直接引用文件句柄,也就是用户态和内核态共享内核态的数据缓冲区,此时数据不需要复制到用户态空间。当应用程序往 mmap 输出数据时,此时就直接输出到了内核态数据,如果此时输出设备是磁盘的话,会直接写盘(flush间隔是30秒),所以如果是这种情况,不是机械磁盘的情况下会比传统拷贝更慢。
*/
public class MmapFileCopy {
public static final String source = "D:\\workspaces\\output.txt";
public static final String dest = "D:\\workspaces\\input.txt";
public static void main(String[] args) {
try {
FileChannel sourceChannel = new RandomAccessFile(source, "rw").getChannel();
FileChannel destChannel = new RandomAccessFile(dest, "rw").getChannel();
long start = System.currentTimeMillis();
MappedByteBuffer map = destChannel.map(FileChannel.MapMode.READ_WRITE, 0, sourceChannel.size());
sourceChannel.write(map);
map.flip();
System.out.println("耗时:" + (System.currentTimeMillis() - start));
} catch (Exception e) {
e.printStackTrace();
}
}
}
import java.io.RandomAccessFile;
import java.nio.channels.FileChannel;
//零拷贝-sendfile
/*
对于sendfile 而言,数据不需要在应用程序做业务处理,仅仅是从一个 DMA 设备传输到另一个 DMA设备。 此时数据只需要复制到内核态,用户态不需要复制数据,并且也不需要像 mmap 那样对内核态的数据的句柄(文件引用)
*/
public class SendFileCopy {
public static final String source = "D:\\workspaces\\output.txt";
public static final String dest = "D:\\workspaces\\input.txt";
public static void main(String[] args) {
try {
FileChannel sourceChannel = new RandomAccessFile(source, "rw").getChannel();
FileChannel destChannel = new RandomAccessFile(dest, "rw").getChannel();
long start = System.currentTimeMillis();
sourceChannel.transferTo(0, sourceChannel.size(), destChannel);
System.out.println("耗时:" + (System.currentTimeMillis() - start));
} catch (Exception e) {
e.printStackTrace();
}
}
}
7.2 kafka的偏移量存储
0.9之前offset存储在zookeeper
0.9之后存储在kafka cluster(zookeeper topic(_consumer_offset))
7.3 kafka消费数据方式
使用poll拉取,主要考虑速率问题,反之如果使用push,消费者消费不过来可能会导致服务崩溃
7.4 kafka如何保证数据不丢失/重复消费
同步发送数据
ACK应答(-1/all)
7.5 Kafka元数据存哪
zookeeper(包括/controller,/cluster,/consumer,/broker)
7.6 kafka版本问题
kafka版本包括 :scala版本+kafka服务版本
7.7 kafka如何保证不同副本都同步到相同的内容
HW(副本高水位)
LEO(日志末端位移)
7.8 Kafka Leader的选举机制
leader broker---> create /controller
follower broker ---->watch /controller
leader partition 负责读写
old leader partition down --->/controller ----> ISR ---->follower partition---->new leader partion
7.9 kafka 运行架构图

7.10 kafka消费速度提升
-
增加分区和消费者
-
适当增加拉取数据的大小
-
适当增大批处理的大小(避免处理时间过长,被踢出了消费者组)
消费者批处理DEMO(基于springboot):
POM依赖:
org.springframework.boot
spring-boot-starter
org.springframework.kafka
spring-kafka
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
junit
junit
test
消费者配置类:
package com.ydt.springboot.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Bean(name = "kafkaListenerContainerFactor")
public KafkaListenerContainerFactory> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(1500);
factory.setBatchListener(true);//@KafkaListener 批量消费 每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);//设置提交偏移量的方式
return factory;
}
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
public Map consumerConfigs() {
Map propsMap = new HashMap<>(8);
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ydt1:9092,ydt2:9092,ydt3:9092");
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, "mytest");
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 20);//每个批次获取数
return propsMap;
}
} 消费者监听类:
package com.ydt.springboot.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class ListenerMsg {
@KafkaListener(topics = "first13",containerFactory = "kafkaListenerContainerFactor")
public void processMessage(List records , Acknowledgment ack) {
System.out.println(records.size());
try {
for (ConsumerRecord record : records) {
System.out.println(String.format("offset = %d, key = %s, value = %s", record.offset(), record.key(), record.value()));
}
System.out.println("------------------------可爱分割线--------------------------");
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();//手动提交偏移量
}
}
} 生产者测试类:
package com.ydt.springboot.kafka;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.FilterType;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
//如果是同一个项目,不排除扫描的监听类,会重复监听
@ComponentScan(excludeFilters = {@ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, classes = {ListenerMsg.class})})
public class SpringbootKafkaApplicationTests {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
public void test() {
for (int i = 0; i < 100; i++) {
this.kafkaTemplate.send("first13", "hello springboot kafka" + i);
}
}
}
测试结果:

7.11 kafka ISR什么情况下broker id会消失
-
副本所在broker down掉
-
网络延迟,阻塞,导致follower不能拉取leader数据
-
follower与leader数据同步落后,超过replica.lag.time.max.ms
7.12 kafka数据存储
topic--->partition---->segment---->index,log,timeindex--->offset(稀疏索引 offset: ,position:
7.13 kafka消息有序吗
同一分区有序,不同分区无序,如果需要消息有序,需要将有序的消息通过指定partition或者相同key进入同一个partition,并且一般只使用一个消费者专门去消费,多了也是白搭!