中国少数民族古籍数字化平台研究进展
中国少数民族古籍数字化平台
目录
-
- 中国少数民族古籍数字化平台
- 1. 背景介绍
- 2. 总体框架
- 3. 技术路线
- 4. 成果简介
1. 背景介绍
中国是一个拥有 56 个民族的统一的多民族国家,中国自古以来就是多民族聚居的国家,且拥有悠久的历史。各民族在历史上形成了丰富多样的古籍文献,本研究旨在对中国少数民族古籍进行数字化,保护优秀民族文化遗产。
上世纪末,清华大学的丁晓青团队与各研究单位、高校开始民族文档的识别研究工作。
2004年,全球首款在统一系统框架中支持维吾尔文、哈萨克文、柯尔克孜文(维哈克文)以及阿拉伯文(阿文)的印刷文档识别系统在清华大学问世,这标志着我国阿拉伯文字体系文档识别技术已经位居国际前列。据悉,该系统可以准确、高效的将维哈柯文的纸质文档转化为电子文档,因此极大的方便了上述文字资料的信息化处理,必将促进我国少数民族地区的经济文化建设和对外交流。
之后又相继开发可以识别藏、蒙、满等民族的文档识别系统。
国家自然科学基金重点项目“面向数字人文的中国古籍文档图像智能识别与理解”简介:
中国几千年辉煌的文明,留下了海量的古籍资料,承载着丰富的历史和文化传承。但目前有超过96%的古籍还未完成文字转录等透彻数字化工作。“面向数字人文的中文古籍文字智能识别与理解”项目针对古籍文档图像版式复杂、噪声干扰、污迹墨迹影响、笔迹残缺、刻字风格多样等一系列挑战,从古籍图像增强及恢复、古籍版面分析及理解、弱标注低质版古籍文字识别、跨模态古籍文档检索、古籍风格分类与认证等五个方面来研究解决古籍图像的智能识别理解问题,构建面向中文古籍文档图像智能处理的理论与技术支撑方法。相关工作对数字人文、古籍文物保护、古籍模式信息发现等有极其重要的研究价值和社会效益。
我院2019年国家自然科学基金申报立项喜获丰收. http://www2.scut.edu.cn/ee/2019/0827/c16285a331183/page.htm
而现在古籍文档整理过多依赖人工,随着国家越来越重视民族古籍文物,全国各省市均建立起相应的少数民族古籍工作机构,积极推动信息化、数字化和规范化建设。建设中不可或缺的重要组成部分就是人才和技术,要着力培养一批具有丰富民族文化整合经验的人,并能够熟练地应用计算机技术,是文献整理和数字化融为一体,减少中间环节,提高少数民族文献资源数字化建设的效率。
因此想从事该工作的有志青年,欢迎报考我校研究生,详情GitHub简介。
该项目已中2021年度国家社科基金冷门绝学研究专项[1,6]。


2. 总体框架
“少数民族文字古籍文档图像智能识别与文献数字化保护研究”主要针对我国少数民族文字古籍存在缺页、噪声污染大和版面复杂、语种文种多等特点,提出利用深度学习技术解决少数民族文字古籍智能识别和数字化保护。
项目从少数民族古籍的文档文种分类、少数民族古籍预处理、少数民族古籍版面分析以及少数民族古籍单字识别四个方面进行研究,努力实现中国少数民族文字古籍识别及文献数字化保护,为抢救濒危文献贡献力量。

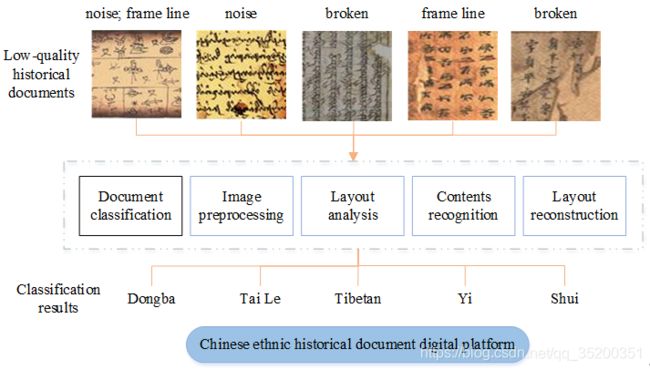
3. 技术路线
90年代到21世纪初,模式识别和机器学习(模式分类器设计是一个学习问题,因此大多机器学习研究面向模式识别)领域多种新的方法兴起,典型的有多分类器系统(早期工作出现在1990年,后来发展成为集成学习方向)。在模式识别中发挥重要作用的半监督学习、多标签学习、多任务学习、迁移学习和领域自适应(与领域自适应类似的分类器自适应早在上世纪60年代就已经有尝试)、以马尔科夫随机场和条件随机场为典型代表的概率图模型等均兴起于这个时期。
2006年以后,深度学习(深度神经网络方法)逐渐成为主流,并陆续在多数模式识别应用任务中大幅超越传统模式识别方法(基于人工特征提取的分类方法)的性能。深度学习的方法最早发表在2006年,后来陆续提出了一系列改进训练收敛性和泛化性能的深度神经网络模型和训练算法,包括不同的训练方法或正则化方法、不同的卷积神经网络结构、循环神经网络、self-attention网络、图卷积网络等。2012年深度卷积神经网络在大规模图像分类竞赛Imagenet中取得巨大成功,从此推动深度学习的研究和应用进入高潮。深度学习的优越性能从视觉领域延伸到自然语言处理领域,开始在机器翻译、阅读理解、自动问答等语言理解任务中大幅超越基于统计语言模型的方法。
目前,深度学习方法仍然在模式识别和人工智能领域占据统治地位。但是随着研究的深入和应用的扩展,深度学习方法的不足也越来越凸显,如小样本泛化能力不足、可解释性不足、鲁棒性(稳定性)差、语义理解和结构理解能力弱,连续学习中遗忘严重,等等。针对这些缺陷学术界在不断探索新的模型(包括与知识规则和传统模式识别方法的结合)和学习算法等,研究和应用都还在不断向前发展。比如,面向开放环境的鲁棒模式识别、可解释性神经网络、面向小样本学习和可解释性的模块化神经网络、结合感知和符号推理的模型、自监督学习、连续学习(又称终生学习)等。
复杂文档识别与重构的技术难点和研究重点在于克服现有技术的不足:(1)复杂版面分析能力不足。版面样式变化特别多,而目前基于规则和基于深度学习的方法都不能解决所有版式的正确分割、逻辑分析、版面理解、版式还原(重构)问题。(2)识别精度和置信度不够。当前,自由书写和图像质量退化场合识别率会明显下降,即使对于识别率较高的场合,当前技术也不能根据识别结果的置信度将存疑字符标记出来,不便于人工校对或自动处理,也限制了文档识别在一些重要的新兴领域如机器人流程自动化(RPA)的大规模广泛应用。(3)小样本泛化能力不足。当前广泛使用的深度神经网络的泛化性能依赖大规模数据集训练,而有些应用场合难以收集标注大量样本来训练识别模型。(4)图形符号识别性能不足。图文混合文档中存在的表格、数理化公式及符号、流程图、签名印章等还不能得到满意的识别性能。(5)文档图像的内容理解与认知能力不足。目前大部分研究工作集中在解决文档图像中的文字信息感知问题(例如版面分割、文字检测、文字识别),对文档图像中的语义信息理解及信息发现还未得到很好的解决,典型的问题包括文档图像结构化理解(例如端到端信息抽取)、基于文档图像的视觉问答(Text VQA)等。
本文得到模式识别国家重点实验室(公众号: 模式识别国家重点实验室)授权发布
参考链接:模式识别国家重点实验室. 模式识别学科发展报告. http://www.nlpr.ia.ac.cn/cn/news/1603.html
4. 成果简介
[1] 全国哲学社会科学工作办公室. 2021年度国家社科基金冷门绝学研究专项立项名单公布[EB/OL]. http://www.nopss.gov.cn/n1/2021/1102/c431029-32271460.html, 2021-11-02.
[2] Guo, H., Liu, Y., Yang, D. et al. Offline handwritten Tai Le character recognition using ensemble deep learning [J]. Vis. Comput. (2021). doi: 10.1007/s00371-021-02230-2.
[3] Guo, H., Yang, D., Zhao, J. et al. Research on the Preprocessing of Tai Le Character Recognition[C]//2nd International Conference on Electronic Engineering and Informatics, Lanzhou, China, 2020. Journal of Physics Conference Series 1617:012039, doi:10.1088/1742-6596/1617/1/012039.
[4] 德宏傣文古籍图像二值化数据集(Tai Le historical document image binarization dataset, TLHDIBD2021).https://github.com/yddcode/TLHDIBD2021.
[5] 中国少数民族古籍文档分类(脚本识别)数据集. Chinese Ethnic Ancient Handwritten Documents database, CEAHD2021-5. https://github.com/yddcode/CEAHD2021-5.
[6] 米怀飞. 我校获批一项国家社科基金冷门绝学研究专项项目.https://new.dlnu.edu.cn/info/1041/21404.htm, 2021-12-08.
[7] Text Line Recognition of Dai Language using Statistical Characteristics of Texture Analysis and Deep Gaussian Process. May 2021. DOI: 10.46300/9106.2021.15.52. ISBN: 1998-4464
[8] Chinese ancient books script identification with deep CNNs via multi-branch and SPP[J]. Pattern Analysis and Applications. 2023.
[9] H Guo, D Yang, J Zhao, Z Shi, D Zhu, T Wang. Hybrid-CBF: A hybrid classification and binarization framework for historical Tai Le document image binarization. under review.