小林coding阅读笔记:计算机网络基础篇-TCP\IP模型
前言
- 参考/导流:
小林coding - 2.1 TCP/IP 网络模型有哪几层? - 学习意义
- 学习分层设计思想
- 构建网络层次以及各层协议作用知识体系
- 为网络编程奠定理论基础,对于RPC框架or分布式系统通信都是极为重要的一节,是提升整个系统效率的关键所在,而非像单体时代去更多关注本地机器高并发。
- 相关说明
该篇博文是个人阅读的重要梳理,仅做简单参考,详细请阅读小林coding的原文!
一、TPC\IP网络模型
问题引入
问大家,为什么要有 TCP/IP 网络模型?
对于同一台设备上的进程间通信,有很多种方式,比如有管道、消息队列、共享内存、信号等方式,而对于不同设备上的进程间通信,就需要网络通信,而设备是多样性的,所以要兼容多种多样的设备【复用、抽象的体现,当写代码时出现大量重复的逻辑,可考虑封装工具类供大家使用】,就协商出了一套通用的网络协议。
注:分布式通信方式,消息传递、内存共享;Java采用内存共享(JMM)机制实现
常见的软件设计风格有:
- 主子程序式
- MVC
- 分层结构
- 面向对象式
这个网络协议是分层的,每一层都有各自的作用和职责,接下来就根据「 TCP/IP 网络模型」分别对每一层进行介绍。【分层结构设计,设计清晰、易于理解,复用性好!但交互协议需要稳定】
个人理解:体现职责分离、分工,更好地复用性,分解复杂问题,避免通信混乱。
基本关键词: 分层 + 逐级封装\拆解【对比过滤链设计】(在传递单位、数据对象体现) + 委托(在行为职责调用体现)
学习关键就在于:分析传递的数据结构、以及该数据是如何传递(各层如何去调用),附加考虑他们的可靠性、安全性、网络阻塞等的事情【也来源于人们某种需求,对信息的可靠性等等】,最后在此基础上去 分析、掌握各层的 关键 协议和实现原理。
TPC\IP
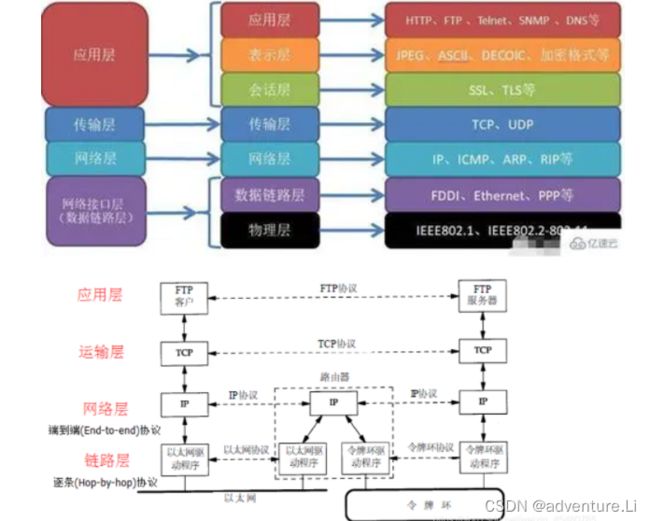
应用层
最上层的,也是我们能直接接触到的就是应用层(Application Layer),我们电脑或手机使用的应用软件都是在应用层实现。那么,当两个不同设备的应用需要通信的时候,应用就把应用数据传给下一层,也就是传输层。
所以,应用层只需要专注于为用户提供应用功能,比如 HTTP、FTP、Telnet、DNS、SMTP等。
而且应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。
而编程语言对其进行了封装,例如Java中的HttpUrlConnection,httpClient;对于大型软件,一般会在此基础上进行在此封装,例如RestTemplate之类。
- HttpUrlConnection
- HttpClientImpl
传输层
应用层的数据包会传给传输层,传输层是为应用层提供网络支持的,最终是交由网卡(对于网卡的笔记本),网卡通过电信号传至路由器。
在传输层会有两个传输协议(同样是 效率(速度) 和 可用性(可靠性) 的平衡取舍)
- TCP
- UDP
TCP 的全称叫传输控制协议(Transmission Control Protocol),大部分应用使用的正是 TCP 传输层协议,比如 HTTP 应用层协议。TCP 相比 UDP 多了很多特性,比如流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方。
UDP 相对来说就很简单,简单到只负责发送数据包,不保证数据包是否能抵达对方,但它实时性相对更好,传输效率也高。当然,UDP 也可以实现可靠传输,把 **TCP 的特性在应用层上实现就可以,**不过要实现一个商用的可靠 UDP 传输协议,也不是一件简单的事情。
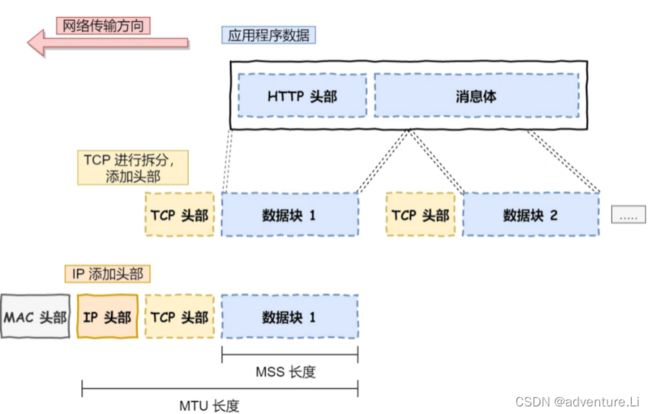
应用需要传输的数据可能会非常大,如果直接传输就不好控制,因此当传输层的数据包大小超过 MSS(TCP 最大报文段长度) ,就要将数据包分块,这样即使中途有一个分块丢失或损坏了,只需要重新发送这一个分块,而不用重新发送整个数据包。在 TCP 协议中,我们把每个分块称为一个 TCP 段(TCP Segment)。
当设备作为接收方时,传输层则要负责把数据包传给应用,但是一台设备上可能会有很多应用在接收或者传输数据,因此需要用一个编号将应用区分开来,这个编号就是端口。
比如 80 端口通常是 Web 服务器用的,22 端口通常是远程登录服务器用的。而对于浏览器(客户端)中的每个标签栏都是一个独立的进程,操作系统会为这些进程分配临时的端口号。
由于传输层的报文中会携带端口号,因此接收方可以识别出该报文是发送给哪个应用。
socket = ip:port →唯一标识 进程;主机间的通信实则为进程间的通信【那么思考为什么设计时,不是定位到ip建立连接呢?或者定位线程的粒度,继续来个subPort之类的呢?大概是一般一个应用处理一类目标,方便分工协作,刚好切分的粒度较好,以及历史发展原因,当初的线程设计还—】
网络层
传输层可能大家刚接触的时候,会认为它负责将数据从一个设备传输到另一个设备,事实上它并不负责。
实际场景中的网络环节是错综复杂的,中间有各种各样的线路和分叉路口,如果一个设备的数据要传输给另一个设备,就需要在各种各样的路径和节点进行选择,而传输层的设计理念是简单、高效、专注,如果传输层还负责这一块功能就有点违背设计原则了。
也就是说,我们不希望传输层协议处理太多的事情,只需要服务好应用即可,让其作为应用间数据传输的媒介,帮助实现应用到应用的通信,而实际的传输功能就交给下一层,也就是网络层(Internet Layer)
网络层最常使用的是 IP 协议(Internet Protocol),IP 协议会将传输层的报文作为数据部分,再加上 IP 包头组装成 IP 报文,如果 IP 报文大小超过 MTU(以太网中一般为 1500 字节)就会再次进行分片,得到一个即将发送到网络的 IP 报文。
寻址能力
通过IP地址进行寻址,寻址到主机;IP 地址分成两种意义:
- 一个是网络号,负责标识该 IP 地址是属于哪个「子网」的;
- 一个是主机号,负责标识同一「子网」下的不同主机;
→
公网地址、私网地址;本地地址、广播地址、回环地址;
路由
通过IP地址,我们知道了目标在哪,带设备间是通过错综复杂的路由器和线路连接起来的。这时则需要用的 路由协议来实现。
- 静态路由算法(非自适应路由算法)
- 动态路由算法
(一)距离-向量路由算法(分散性)
描述:收敛速速慢,“坏消息”传的慢,导致网络问题。路由器只掌握物理相连的邻居及链路费用(对比gossip的扩散传播)。
应用:RIP协议,它采用“跳数”作为距离的度量
1.路由选择表内容:
(1)每条路径的目的地(另一结点)
(2)路径的代价(也称距离)
2.更新路由表的条件:
(1)被通告一条新的路由,若该路由在本结点的路由表中不存在,则加入
(2)路由信息中有一条到达某个目的地的路由,该路由与当前使用的路由相比,有较短的距离(较小的代价)
3.缺点:容易出现路由环路问题(慢收敛导致路由器接受了无效的路由信息)
(二)链路状态路由算法(全局性)
描述:具有快速收敛的优点。所有路由器掌握完整的网络拓扑和链路费用信息
1.应用:OSPF协议,用于大型的或路由信息变化聚敛的互联网环境
2.全网路由器的拓扑数据库是一致的
3.使用泛洪法向所有相邻的路由器发送信息,然后相邻路由器又向其他相邻路由器发送信息
4.每个路由器都得到网络的完整拓扑后,使用Dijkstra最短路径算法来找出它到其他路由器的路径长度。
原文链接:https://blog.csdn.net/weixin_45825865/article/details/126336494
所以,IP 协议的寻址作用是告诉我们去往下一个目的地该朝哪个方向走,路由则是根据「下一个目的地」选择路径。寻址更像在导航,路由更像在操作方向盘。
网络接口
生成了 IP 头部之后,接下来要交给**网络接口层,**在 IP 头部的前面加上 MAC 头部,并封装成数据帧(Data frame)发送到网络上。
IP 头部中的接收方 IP 地址表示网络包的目的地,通过这个地址我们就可以判断要将包发到哪里,但在以太网的世界中,这个思路是行不通的。
什么是以太网呢?电脑上的以太网接口,Wi-Fi接口,以太网交换机、路由器上的千兆,万兆以太网口,还有网线,它们都是以太网的组成部分。
以太网就是一种在「局域网」内,把附近的设备连接起来,使它们之间可以进行通讯的技术。
以太网在判断网络包目的地时和 IP 的方式不同,因此必须采用相匹配的方式才能在以太网中将包发往目的地,而 MAC 头部就是干这个用的,所以,在以太网进行通讯要用到 MAC 地址。
MAC 头部是以太网使用的头部,它包含了接收方和发送方的 MAC 地址等信息,我们可以通过 ARP 协议获取对方的 MAC 地址。
所以说,网络接口层主要为网络层提供**「链路级别」传输**的服务,负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标识网络上的设备。
网卡将管理网卡的设备驱动程序安装在计算机的操作系统中。这个驱动程序以后就会告诉网卡,应当从存储器的什么位置上将局域网传送过来的数据块存储下来。