使用MATLAB进行线性回归分析
简介
变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。回归分析就是处理变量之间的相关关系的一种数学方法。其解决问题的大致方法、步骤如下:
- 收集一组包含因变量和自变量的数据;
- 选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数;
- 利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型;
- 判断得到的模型是否适合于这组数据;
- 利用模型对因变量作出预测或解释。
常用的回归模型可以分为:一元线性回归、多元线性回归、非线性回归、逐步回归等方法等。
这里就如何利用MATLAB对自带回归函数regress学习记录。
专业词汇解释
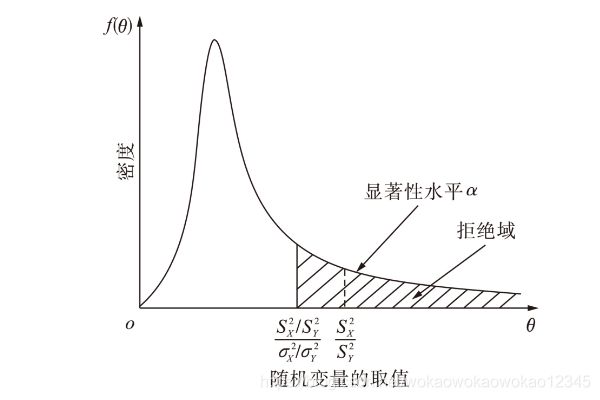
统计学中的显著性水平α和P分别是什么意思
1、显著性水平α在统计学中叫做犯第一类错误的大小,第一类错误就是原假设是对的,但是被拒绝的概率,我们一般把这个显著性水平α定为0.05。
显著性是对差异的程度而言的,程度不同说明引起变动的原因也有不同:一类是条件差异,二类是随机差异,是在进行假设检验时事先确定一个可允许的作为判断界限的小概率标准。
2、P值是用来判定假设检验结果的一个参数,也可以根据不同的分布使用分布的拒绝域进行比较。
P值(P value)就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理就有理由拒绝原假设,P值越小,拒绝原假设的理由越充分。
假设有个检验统计量是F,然后把样本数据代入F可以算出一个值记为f,那么P值就是在原假设成立的条件下P(F>f)这个概率大小,如果P值小于给定的显著性水平α我们就拒绝原假设,否则不拒绝。
总之,P值越小,表明结果越显著。但是检验的结果究竟是“显著的”、“中度显著的”还是“高度显著的”需要根据P值的大小和实际问题来解决。
regress用法
如果根据经验和有关知识认为与因变量有关联的自变量不止一个,那么就应该考虑用最小二乘准则建立多元线性回归模型。
b = regress(y,X)
[b,bint] = regress(y,X)
[b,bint,r] = regress(y,X)
[b,bint,r,rint] = regress(y,X)
[b,bint,r,rint,stats] = regress(y,X)
[___] = regress(y,X,alpha)
描述:输入y(因变量,列向量)、X(自变量组成的矩阵,每一列为一个属性)。
b:回归系数,是个向量,X有几列,对应于就有几个回归系数,回归系数顺序与X列顺序对应。
bint:回归系数的区间估计,区间越小精度越高。
r:残差。
rint:置信区间。
stats:用于检验回归模型的统计量。有4个数值:判定(决定)系数r^2,F统计量观测值,检验的p的值,误差方差的估计。
alpha:是显著性水平(缺省时默认0.05)。
其意义和用法如下:r^2的值越接近1,变量的线性相关性越强,说明模型有效;如果满足F,则认为变量与显著地有线性关系。
一元线性回归分析
回归模型可分为线性回归模型和非线性回归模型。非线性回归模型是回归函数关于未知参数具有非线性结构的回归模型。某些非线性回归模型可以化为线性回归模型处理;如果知道函数形式只是要确定其中的参数则是拟合问题,可以使用MATLAB软件的curvefit命令或nlinfit命令拟合得到参数的估计并进行统计分析。这里主要考察线性回归模型。
一元线性回归模型的建立
y = β 0 + β 1 x + ε y=\beta_0+\beta_1x+\varepsilon y=β0+β1x+ε
其中, β 0 \beta_0 β0和 β 1 \beta_1 β1是待定系数,这里需要做的就是对这两个变量进行估计。
参数的区间估计
由于我们所计算出的由于我们所计算出的 β ^ 0 \widehat{\beta}_0 β 0和 β ^ 1 \widehat{\beta}_1 β 1仍然是随机变量,因此要对 β ^ 0 \widehat{\beta}_0 β 0和 β ^ 1 \widehat{\beta}_1 β 1$取值的区间进行估计,如果区间估计值是一个较短的区间表示模型精度较高。
线性相关性的检验
由于我们采用的是一元线性回归,因此,如果模型可用的话,应该具有较好的线性关系。反映模型是否具有良好线性关系可通过相关系数R的值及F值观察(后面的例子说明)。
一元线性回归MATLAB实现
[b ,bint , r ,rint , s]=regress(y , x , alpha)
输出 b = ( β ^ 0 , β ^ 1 ) b=(\widehat{\beta}_0, \widehat{\beta}_1) b=(β 0,β 1),注意:b中元素顺序与拟合命令polyfit的输出不同。
bint是 β 0 \beta_0 β0和 β 1 \beta_1 β1的置信区间,r是残差(列向量),rint是残差的置信区间。
s包含4个统计量:决定系数 r 2 r^2 r2(相关系数为r);F值;F(1,n-2)分布大于F值的概率p;剩余方差 s 2 s^2 s2 的值(MATLAB7.0以后版本)。 s 2 s^2 s2 也可由程序sum(r.^2)/(n-2)计算。
其意义和用法如下: r 2 r^2 r2的值越接近1,变量的线性相关性越强,说明模型有效;如果满足 F 1 − ∞ ( 1 , n − 2 ) < F F_{1-\infty}(1,n-2)
例1 测得16名成年女子身高(cm)腿长(cm)所得数据如下:
88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102
143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164
代码
y=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164];
x=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102];
n=16;
X=[ones(n,1),x']; % ones(n,1)表示有常数项,如果无常数项可以去掉。
[b,bint,r,rint,s]=regress(y',X,0.05)
rcoplot(r,rint)
结果
b =
31.7713
1.2903
bint =
12.3196 51.2229
1.0846 1.4960
s =
0.9282 180.9531 0.0000 3.1277
r^2 = 0.9282, 由finv(0.95,1,14)= 4.6001,即 F 1 − ∞ ( 1 , n − 2 ) F_{1-\infty}(1,n-2) F1−∞(1,n−2)= 4.6001 例如p=0.95,v1=5,v2=10计算x=3.3258,查表置信度0.05,分子自由度5,分母自由度10,结果3.33 可以通过残差图发现,第二个数据为奇异数据 去掉该数据后运行后得到 r^2=0.9527, 由finv(0.95,1,13)= 4.6672,即 F 1 − ∞ ( 1 , n − 2 ) F_{1-\infty}(1,n-2) F1−∞(1,n−2)= 4.6672 如果根据经验和有关知识认为与因变量有关联的自变量不止一个,那么就应该考虑用最小二乘准则建立多元线性回归模型。 建立回归模型是一个相当复杂的过程,概括起来主要有以下几个方面工作(1)根据研究目的收集数据和预分析;(2)根据散点图是否具有线性关系建立基本回归模型;(3)模型的精细分析;(4)模型的确认与应用等。 仍然用命令regress(y , X),只是要注意矩阵X的形式,将通过如下例子说明其用法。 例2 工薪阶层关心年薪与哪些因素有关,以此可制定出它们自己的奋斗目标。 试建立Y与 X 1 , X 2 , X 3 X_1,X_2,X_3 X1,X2,X3之间关系的数学模型,并得出有关结论和作统计分析。 作出因变量Y与各自变量的样本散点图 从图可以看出这些点大致分布在一条直线旁边,因此,有比较好的线性关系,可以采用线性回归。 计算结果包括回归系数b=( β 0 , β 1 , β 2 , β 3 \beta_0,\beta_1,\beta_2,\beta_3 β0,β1,β2,β3 )=(18.0157, 1.0817 , 0.3212 , 1.2835),且置信区间均不包含零点;残差及其置信区间;统计变量stats ,它包含四个检验统计量:相关系数的平方 r 2 r^2 r2 ,假设检验统计量F,与F对应的概率p, s 2 s^2 s2的值。因此我们得到初步的回归方程为: 由结果对模型的判断: 回归系数置信区间不包含零点表示模型较好,残差在零点附近也表示模型较好,接着就是利用检验统计量R,F,p 的值判断该模型是否可用。 以上三种统计推断方法推断的结果是一致的,说明因变量 与自变量之间显著地有线性相关关系,所得线性回归模型可用。 s 2 s^2 s2当然越小越好,这主要在模型改进时作为参考。 模型的精细分析和改进 参考x=finv(p,v1,v2)

b =
17.6549
1.4363
s =
0.9527 261.6389 0.0000 1.9313
多元线性回归分析
多元线性回归模型的建模
设影响因变量y的主要因素(自变量)有m个,记 x = ( x 1 , . . . , x m ) x=(x_1,...,x_m) x=(x1,...,xm) ,假设它们有如下的线性关系式:
y = β 0 + β 1 x 1 + . . . + β m x m + ε y=\beta_0+\beta_1x_1+...+\beta_mx_m+\varepsilon y=β0+β1x1+...+βmxm+ε多元线性回归MATLAB实现
某科学基金会希望估计从事某研究的学者的年薪Y与他们的研究成果(论文、著作等)的质量指标X1、从事研究工作的时间X2、能成功获得资助的指标X3之间的关系,为此按一定的实验设计方法调查了24位研究学者,得到如下数据(i为学者序号):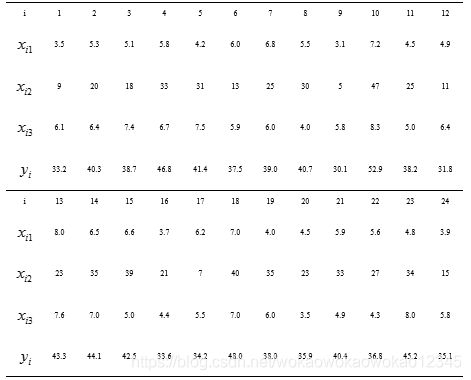
作散点图的目的主要是观察因变量Y与各自变量间是否有比较好的线性关系,以便选择恰当的数学模型形式。下图分别为年薪Y与成果质量指标 、研究工作时间 、获得资助的指标 之间的散点图,subplot(1,3,1),plot(x1,Y,'g*'),
subplot(1,3,2),plot(x2,Y,'k+'),
subplot(1,3,3),plot(x3,Y,'ro'),

x1=[3.5 5.3 5.1 5.8 4.2 6.0 6.8 5.5 3.1 7.2 4.5 4.9 8.0 6.5 6.5 3.7 6.2 7.0 4.0 4.5 5.9 5.6 4.8 3.9];
x2=[9 20 18 33 31 13 25 30 5 47 25 11 23 35 39 21 7 40 35 23 33 27 34 15];
x3=[6.1 6.4 7.4 6.7 7.5 5.9 6.0 4.0 5.8 8.3 5.0 6.4 7.6 7.0 5.0 4.0 5.5 7.0 6.0 3.5 4.9 4.3 8.0 5.0];
Y=[33.2 40.3 38.7 46.8 41.4 37.5 39.0 40.7 30.1 52.9 38.2 31.8 43.3 44.1 42.5 33.6 34.2 48.0 38.0 35.9 40.4 36.8 45.2 35.1];
n=24; m=3;
X=[ones(n,1),x1',x2',x3'];
[b,bint,r,rint,s]=regress(Y',X,0.05);
b,bint,r,rint,s,
y ^ = 18.0157 + 1.0817 x 1 + 0.3212 x 2 + 1.2835 x 3 \widehat{y}=18.0157+1.0817x_1+0.3212x_2+1.2835x_3 y =18.0157+1.0817x1+0.3212x2+1.2835x3
(1)相关系数R的评价:一般地,相关系数绝对值在0.8~1范围内,可判断回归自变量与因变量具有较强的线性相关性。本例R的绝对值为0.9542,表明线性相关性较强。
(2)F检验法:当 F > F 1 − ∞ ( m , n − m − 1 ) F>F_{1-\infty}(m,n-m-1) F>F1−∞(m,n−m−1),即认为因变量与自变量之间显著地有线性相关关系;否则认为因变量 y与自变量X之间线性相关关系不显著。本例 F=67.919> F 1 − ∞ ( 3 , 20 ) F_{1-\infty}(3,20) F1−∞(3,20)= 3.10 (查F分布表或输入命令finv(0.95,3,20)计算),其中m为自变量的数量,n为样本数量。
(3)p值检验:若 p < α p<\alpha p<α ( α \alpha α为预定显著水平),则说明因变量与自变量之间显著地有线性相关关系。本例输出结果,p<0.0001,显然满足P< α \alpha α=0.05。
残差分析
残差 e i = y i − y ^ i ( i = 1 , 2 , . . . , n ) e_i=y_i-\widehat{y}_i(i=1,2,...,n) ei=yi−y i(i=1,2,...,n),是各观测值 y i y_i yi与回归方程所对应得到的拟合值 y ^ i \widehat{y}_i y i之差,实际上,它是线性回归模型中误差 ε \varepsilon ε的估计值。 ε N ( 0 , δ 2 ) \varepsilon~N(0,\delta^2) ε N(0,δ2)即有零均值和常值方差,利用残差的这种特性反过来考察原模型的合理性就是残差分析的基本思想。利用MATLAB进行残差分析则是通过残差图或时序残差图。残差图是指以残差为纵坐标,以其他指定的量为横坐标的散点图。主要包括:(1)横坐标为观测时间或观测值序号;(2)横坐标为某个自变量的观测值;(3)横坐标为因变量的拟合值。通过观察残差图,可以对奇异点进行分析,还可以对误差的等方差性以及对回归函数中是否包含其他自变量、自变量的高次项及交叉项等问题给出直观的检验。
以观测值序号为横坐标,残差为纵坐标所得到的散点图称为时序残差图,画出时序残差图的MATLAB语句为rcoplot(r,rint)。可以清楚看到残差大都分布在零的附近,因此还是比较好的 ,不过第4、12、19这三个样本点的残差偏离原点较远,如果作为奇异点看待,去掉后重新拟合,则得回归模型为:
y ^ = 19.0808 + 0.8616 x 1 + 0.3176 x 2 + 1.3463 x 3 \widehat{y}=19.0808+0.8616x_1+0.3176x_2+1.3463x_3 y =19.0808+0.8616x1+0.3176x2+1.3463x3
且回归系数的置信区间更小均不包含原点,统计变量stats包含的三个检验统计量:相关系数的平方 r 2 r^2 r2 ,假设检验统计量F,概率P ,分别为:0.9533 ; 115.5586 ; 0.0000 ,比较可知R,F均增加模型得到改进。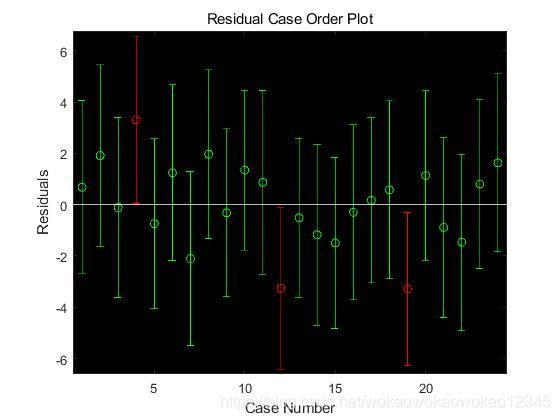
https://www.mathworks.com/help/stats/regress.html
https://wenku.baidu.com/view/8c5baa8d64ce0508763231126edb6f1aff00710d.html