从零编写linux0.11 - 第六章 任务管理
编程环境:Ubuntu Kylin 16.04、gcc-5.4.0
代码仓库:https://gitee.com/AprilSloan/linux0.11-project
linux0.11源码下载(不能直接编译,需进行修改)
本章目标
本章的目的是要创建任务,并调度到新任务中。这其中涉及到任务结构体的讲解,进程调度,内存分配,系统调用等一系列知识,是目前内容最为充实,最为丰富的一章。相信大家都会沉浸其中,无法自拔(手动滑稽)。
1.第一个任务
相信大家都学过操作系统的知识,对于任务的相关知识就不多说了,毕竟讲解任务的知识会花费超大量篇幅。但是还是请大家回顾这几个问题:为什么要有任务?怎么描述一个任务?
首先要介绍的是任务结构体,它用于描述任务,如果不先介绍它的话,后面的内容也不好展开。我在每个成员后都注释了它们的作用,便于观看。
// sched.h
struct task_struct {
long state; // 任务的运行状态(-1 不可运行,0 可运行(就绪),>0 已停止)
long counter; // 任务运行时间计数(递减),时间片
long priority; // 任务运行优先级。任务刚开始时counter=priority,越大运行时间越长
long signal; // 信号。位图形式,每个比特位代表一种信号,信号值=位偏移值+1
struct sigaction sigaction[32]; // 信号执行属性结构,对应信号将要执行的操作和标志信息
long blocked; // 任务信号屏蔽码
int exit_code; // 任务执行停止的退出码,其父进程会取
// 代码段地址,代码长度,代码长度+数据长度,总长度,堆栈段地址
unsigned long start_code, end_code, end_data, brk, start_stack;
// 进程号,父进程号,进程组号,会话号,会话首领
long pid, father, pgrp, session, leader;
unsigned short uid, euid, suid; // 用户id,有效用户id,保存的用户id
unsigned short gid, egid, sgid; // 组id,有效组id,保存的组id
long alarm; // 报警定时值(滴答数)
// 用户态运行时间,系统态运行时间,子进程用户态运行时间,子进程系统态运行时间,进程开始运行时刻
long utime, stime, cutime, cstime, start_time;
unsigned short used_math; // 标志:是否使用了协处理器
int tty; // 进程使用的tty的子设备号。-1表示没有使用
unsigned short umask; // 文件创建属性屏蔽位
unsigned long close_on_exec; // 运行可执行文件时关闭文件句柄位图
struct desc_struct ldt[3]; // 任务局部描述符表。0-空,1-代码段,2-数据和堆栈段
struct tss_struct tss; // 进程的任务状态段信息
};
tty 相关内容还没有编写,所以现在也就没什么用。在任务结构体中本来还有一些与文件系统相关的结构体,但是由于还没有文件系统,我就把这些成员删掉了,之后到了文件系统的章节再添加。
任务结构体最后一个成员是tss(Task State Segment,任务状态段),它的结构如下:
// sched.h
struct tss_struct {
long back_link; /* 16 high bits zero */
long esp0;
long ss0; /* 16 high bits zero */
long esp1;
long ss1; /* 16 high bits zero */
long esp2;
long ss2; /* 16 high bits zero */
long cr3;
long eip;
long eflags;
long eax,ecx,edx,ebx;
long esp;
long ebp;
long esi;
long edi;
long es; /* 16 high bits zero */
long cs; /* 16 high bits zero */
long ss; /* 16 high bits zero */
long ds; /* 16 high bits zero */
long fs; /* 16 high bits zero */
long gs; /* 16 high bits zero */
long ldt; /* 16 high bits zero */
long trace_bitmap; /* bits: trace 0, bitmap 16-31 */
};
这个结构体里面保存的是寄存器,保存寄存器干什么?当然是为了保护进程上下文,在任务切换时,把当前进程的寄存器信息保存起来,之后回到该任务时再把这些信息装入寄存器中,保证任务切换不会影响任务的执行。另外,我们可以通过执行 jmp 指令跳转到一个 tss 中完成任务切换。
我们可以看到,这个结构体里有3个 ss 和 esp,为什么会有这么多 ss 和 esp?这些 ss 和 esp 是用于保存不同特权级下的栈段和栈指针,如 ss0 和 esp0 是核心态下任务栈段和栈指针。好麻烦啊!只使用一个 esp 和 ss 不行吗(核心态和用户态共用一个栈不行吗)?如果核心态和用户态共用一个栈的话,栈里会同时存放核心态和用户态的数据,而用户就可以得到核心态的数据了,这可是不允许的。
那为什么没有 esp3 和 ss3 呢?因为进入核心态的时候,用户的 ss 和 esp 会存入栈中,回到用户态的时候 ss 和 esp 会出栈。
那为什么要这样定义结构体呢?一般来说,看到这么古怪的定义,那肯定是和硬件有关。下面是tss的结构示意图。只要你向系统指明了 tss 结构体的地址,在任务调度时,系统就会把原本任务的寄存器保存到相应的地方,把新任务的 tss 结构体的数值加载到相应的寄存器中。
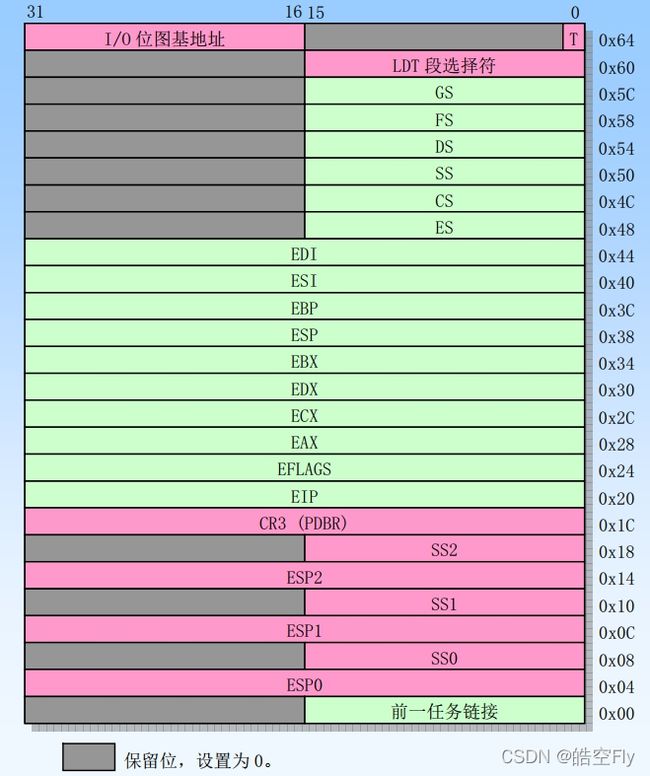
第一个任务是怎么被设置的?我们要对它进行哪些设置?
// sched.c
union task_union {
struct task_struct task;
char stack[PAGE_SIZE];
};
static union task_union init_task = {INIT_TASK, };
struct task_struct *task[NR_TASKS] = {&(init_task.task), };
// sched.h
#define NR_TASKS 64
#define INIT_TASK \
/* state etc */ { 0, 15, 15, \
/* signal... */ 0, {{},}, 0, \
/* ec,brk... */ 0, 0, 0, 0, 0, 0, \
/* pid etc.. */ 0, -1, 0, 0, 0, \
/* uid etc */ 0, 0, 0, 0, 0, 0, \
/* alarm */ 0, 0, 0, 0, 0, 0, \
/* math */ 0, \
/* tty etc */ -1, 0022,0, \
{ \
{0, 0}, \
/* ldt */ {0x9f, 0xc0fa00}, \
{0x9f, 0xc0f200}, \
}, \
/*tss*/ {0, PAGE_SIZE + (long)&init_task, 0x10, 0, 0, 0, 0, (long)&pg_dir,\
0, 0, 0, 0, 0, 0, 0, 0, \
0, 0, 0x17, 0x17, 0x17, 0x17, 0x17, 0x17, \
_LDT(0), 0x80000000, \
}, \
}
sched.c中定义了任务指针数组task,每个成员是一个任务指针,它的第一个成员(也就是第一个任务)被定义为init_task.task的地址。
union 是联合体,它的多个变量同时使用一块内存空间,空间的大小为该结构中长度最大的变量的长度。task_union占用4KB空间,你可以认为它前一部分是一个任务结构体,后一部分是字符数组,充当前面任务的核心态栈空间。第一个任务的值被设置为宏定义INIT_TASK中的数据。
由于宏定义的数据不太好观看,我将其与任务结构体的成员一一对应放在下方。
struct tss_struct {
long back_link; // 0
long esp0; // PAGE_SIZE+(long)&init_task
long ss0; // 0x10
long esp1; // 0
long ss1; // 0
long esp2; // 0
long ss2; // 0
long cr3; // (long)&pg_dir
long eip; // 0
long eflags; // 0
long eax,ecx,edx,ebx; // 0, 0, 0, 0
long esp; // 0
long ebp; // 0
long esi; // 0
long edi; // 0
long es; // 0x17,在LDT中,优先级为3
long cs; // 0x17
long ss; // 0x17
long ds; // 0x17
long fs; // 0x17
long gs; // 0x17
long ldt; // _LDT(0)
long trace_bitmap; // 0x80000000
};
struct task_struct {
long state; // 0
long counter; // 15
long priority; // 15
long signal; // 0
struct sigaction sigaction[32]; // {{},}
long blocked; // 0
int exit_code; // 0
unsigned long start_code,end_code,end_data,brk,start_stack; // 0, 0, 0, 0, 0
long pid,father,pgrp,session,leader; // 0, -1, 0, 0, 0
unsigned short uid,euid,suid; // 0, 0, 0
unsigned short gid,egid,sgid; // 0, 0, 0
long alarm; // 0
long utime,stime,cutime,cstime,start_time; // 0, 0, 0, 0, 0
unsigned short used_math; // 0
int tty; // -1
unsigned short umask; // 0022
unsigned long close_on_exec; // 0
struct desc_struct ldt[3]; // {{0,0},{0x9f,0xc0fa00},{0x9f,0xc0f200}}
struct tss_struct tss;
};
大部分变量都被赋值为0,我就挑选几个讲讲吧。
时间片和优先级都被设置为15,优先级越大,每次运行的时间就越长。时间片用完会切换任务。
第一个任务没有父进程,将 father 成员设置为-1。
ldt[1] 和 ldt[2] 分别是任务的代码段和数据段描述符,它们的起始地址都为0,长度为0x9f000,特权级都被设置为3(用户级)。
esp0 保存了 init_task 的结束地址作为核心态栈空间的起始地址。请分清核心态栈空间和用户态栈空间的区别,不然对后面内容的理解上会有困难。
pg_dir 是页目录,其地址为0,定义在head.s中,在 head.h 中引用它。
段寄存器都被设置为0x17,说明该段在 ldt 中,特权级为3。你可能会说,0x17不对啊,因为0x17在gdt中的索引号为2,代表的是系统数据段才对。但是,这个段并不在 gdt 中,而是在任务结构体的 ldt 结构体中。
tss 结构体中的 ldt 表示局部表描述符在 gdt 中的索引,_LDT(0)是什么意思呢?这是一个宏定义,代表第一个 ldt 描述符在 gdt 中的索引。
// sched.h
#define FIRST_TSS_ENTRY 4
#define FIRST_LDT_ENTRY (FIRST_TSS_ENTRY + 1)
#define _LDT(n) ((((unsigned long) n) << 4) + (FIRST_LDT_ENTRY << 3))
如下图所示。第一个 tss 描述符在 gdt 中的索引是4,第一个 ldt 描述符的索引是5,每个描述符8字节,所以第一个 ldt 在 gdt 中的地址为40。_LDT(0)展开后就是40,也就是第一个 ldt 描述符在 gdt 中的地址。

上图中的 tss 是 gdt 中的 tss 描述符,与任务结构体中的 tss 结构体不同,请不要混淆。
第一个任务的设置没完,下面要对任务的 tss 和 ldt 做进一步设置。
// sched.c
void sched_init(void)
{
set_tss_desc(gdt + FIRST_TSS_ENTRY, &(init_task.task.tss));
set_ldt_desc(gdt + FIRST_LDT_ENTRY, &(init_task.task.ldt));
__asm__("pushfl\n\t"
"andl $0xffffbfff, (%esp)\n\t"
"popfl");
ltr(0);
lldt(0);
}
这一段代码全都是汇编内敛代码。首先讲讲set_tss_desc和set_ldt_desc。
// system.h
#define _set_tssldt_desc(n, addr, type) \
__asm__ ("movw $104, %1\n\t" \
"movw %%ax, %2\n\t" \
"rorl $16, %%eax\n\t" \
"movb %%al, %3\n\t" \
"movb $" type ", %4\n\t" \
"movb $0x00, %5\n\t" \
"movb %%ah, %6\n\t" \
"rorl $16, %%eax" \
::"a"(addr), "m"(*(n)), "m"(*(n + 2)), "m"(*(n + 4)), \
"m"(*(n + 5)), "m"(*(n + 6)), "m"(*(n + 7)) \
)
#define set_tss_desc(n, addr) _set_tssldt_desc(((char *) (n)), ((int)(addr)), "0x89")
#define set_ldt_desc(n, addr) _set_tssldt_desc(((char *) (n)), ((int)(addr)), "0x82")
set_tss_desc要对照 tss 描述符理解,如下所示。各字段的意义见下表。
参数 n 代表 tss 描述符的地址,addr 代表任务结构体中 tss 结构体的地址。再说一次,请不要把 tss 描述符和 tss 结构体混淆。
addr 被存放在eax中,eax的内容会被分别放置到下图中三个基地址字段中。
movw $104, %1会把104放入段界限0-15处,104是 tss 结构体的大小。
"movb $" type ", %4\n\t"中 type 为 “0x89”,在 C 语言中,2个连续的字符串被认为是一个字符串,即"movb $" "0x89" ", %4\n\t"会被当做"movb $0x89, %4\n\t",这段代码会把 P 置为1,把 DPL 置为0,把 B 置为 0。
这样,任务切换时就会把寄存器信息保存到任务结构体的 tss 结构体中。
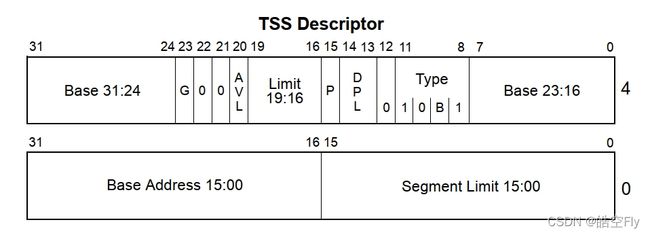
| 字段 | 意义 |
|---|---|
| 基地址 | tss结构体的地址 |
| 段界限 | tss结构体大小=段界限*段界限单位(段界限单位与G字段有关) |
| G | 粒度。用于解释段界限的含义。 G=0,段界限以字节为单位,段的扩展范围为1B-1MB(描述符的界限值为20位); G=1,段界限以4KB为单位,段的扩展范围为4KB-4GB |
| AVL | 软件可利用位。置0即可。 |
| P | 段存在位,用于表示描述符所对应的段是否存在。 P=0,表示段不在内存中。 P=1,表示段在内存中。 |
| DPL | 表示描述符的特权级。处理器支持的特权级别有4种,分别是0,1,2,3,其中0是最高特权级别。 |
| B | 忙标志位。B=1:任务正在运行。 |
ldt 描述符的结构与 tss 描述符相似,仅 type 字段不同。
__asm__("pushfl\n\t"
"andl $0xffffbfff, (%esp)\n\t"
"popfl");
这段代码会把 eflags 寄存器的值入栈,在栈中把 NT 位置零,然后再把数值送入 eflags 中。当 NT=1 时,执行iret指令会引发任务调度。在下一节中,我们会使用 iret 从核心态转到用户态,但并不希望任务调度,故把该位置零。
最后是下面两句代码。
ltr(0);
lldt(0);
这两个函数都是宏定义。
// sched.h
#define FIRST_TSS_ENTRY 4
#define FIRST_LDT_ENTRY (FIRST_TSS_ENTRY + 1)
#define _TSS(n) ((((unsigned long) n) << 4) + (FIRST_TSS_ENTRY << 3))
#define _LDT(n) ((((unsigned long) n) << 4) + (FIRST_LDT_ENTRY << 3))
#define ltr(n) __asm__("ltr %%ax"::"a"(_TSS(n)))
#define lldt(n) __asm__("lldt %%ax"::"a"(_LDT(n)))
ltr用来装载任务寄存器段选择符。当用ltr装载一个任务寄存器中的段选择符时,基地址、界限和 tss 描述符都被自动地装载到任务寄存器中。
tr(task register,任务寄存器)保存着16位的段选择符,32位基地址,16位段界限和当前任务的 tss 描述符属性。它引用 gdt 中的 tss 描述符。基地址表示 tss 结构体的起始地址,段界限指明 tss 结构体的大小。进行任务切换时,任务寄存器就自动装载新任务的 tss 描述符。
lldt指令是专门用来装载 ldtr 寄存器段选择符那部分的。包含 ldt 的段必须在 gdt 中有一个段选择符。当 lldt指令装载一个 ldtr 中的段选择符时,ldt 描述符的基地址、界限和描述符属性就自动装载到 ldtr 中。当进行任务切换时,ldtr 就会自动被装载连同新任务的段选择符和描述符。
为什么要设置这两个寄存器呢?系统可以通过 ldtr 找到任务的 ldt,通过地址变换找到任务的物理地址,或是用于判断任务是否越界等。系统通过 tr 找到任务的 tss 描述符,用于任务切换时保存环境。
最后还是修改一下main.c。
void main(void)
{
memory_end = (1 << 20) + (EXT_MEM_K << 10);
memory_end &= 0xfffff000;
if (memory_end > 16 * 1024 * 1024)
memory_end = 16 * 1024 * 1024;
if (memory_end > 12 * 1024 * 1024)
buffer_memory_end = 4 * 1024 * 1024;
else if (memory_end > 6 * 1024 * 1024)
buffer_memory_end = 2 * 1024 * 1024;
else
buffer_memory_end = 1 * 1024 * 1024;
main_memory_start = buffer_memory_end;
mem_init(main_memory_start, memory_end);
trap_init();
tty_init();
time_init();
sched_init();
buffer_init(buffer_memory_end);
printk("Now we are in the task 0\r\n");
while (1);
}
这一节还创建了signal.h,一些函数、变量声明也没有再文中体现,具体参考实际代码。可以用Beyond Compare看看每节代码的差别,我每次写博客都是用这个软件看看自己又加了哪些代码。

老实说,这个结果也看不出第一个任务设置成功没有,不过不用担心,从下一节开始,我们就能检验程序的正确与否。
2.任务初始化与用户态
上一节我们只设置了与第一个任务有关的数据,这节就把其他任务的初始化操作完成了吧。
// sched.c
void sched_init(void)
{
int i;
struct desc_struct * p;
if (sizeof(struct sigaction) != 16) {
printk("Struct sigaction MUST be 16 bytes");
while (1);
}
set_tss_desc(gdt + FIRST_TSS_ENTRY, &(init_task.task.tss));
set_ldt_desc(gdt + FIRST_LDT_ENTRY, &(init_task.task.ldt));
p = gdt + 2 + FIRST_TSS_ENTRY;
for(i = 1; i < NR_TASKS; i++) {
task[i] = NULL;
p->a = p->b = 0;
p++;
p->a = p->b = 0;
p++;
}
__asm__("pushfl\n\t"
"andl $0xffffbfff, (%esp)\n\t"
"popfl");
ltr(0);
lldt(0);
}
程序首先检查 sigaction 结构体的大小是否正确,这个结构体与信号有关,但目前又不上,就简单提一句。
在设置了第一个任务的 tss 和 ldt 描述符之后,继续对其他任务的描述符进行设置。第13行代码将 p 指向为第二个任务的 tss 描述符,之后将所有任务的 tss 和 ldt 描述符都设置为0。顺便一提,linux0.11 支持最多64个任务,这个版本的 linux 的任务管理还是比较落后,现在的 linux 理论上支持无数个任务。
接下来要进入用户态。
// main.c
void main(void)
{
...
sched_init();
buffer_init(buffer_memory_end);
sti();
move_to_user_mode();
printk("We can't invoke printk in user mode\r\n");
while (1);
}
// system.h
#define move_to_user_mode() \
__asm__ ("movl %%esp, %%eax\n\t" \
"pushl $0x17\n\t" \ // ss
"pushl %%eax\n\t" \ // esp
"pushfl\n\t" \ // eflags
"pushl $0x0f\n\t" \ // cs
"pushl $1f\n\t" \ // eip
"iret\n" \
"1:\tmovl $0x17, %%eax\n\t" \
"movw %%ax, %%ds\n\t" \
"movw %%ax, %%es\n\t" \
"movw %%ax, %%fs\n\t" \
"movw %%ax, %%gs" \
::)
在初始化操作结束后,使用 sti 指令打开所有中断,使用宏定义 move_to_user_mode 将程序用核心态转到用户态。
move_to_user_mode 中是一系列入栈操作,上一节中,我们说过,触发异常会自动将 ss、esp、eflags、cs 和 eip 入栈,iret则会把这些寄存器依次出栈。所以第21行的 iret 指令会将上面入栈的数值依次推入相应的寄存器中。其中第20行中 $1f 代表下面标号1处的地址。所以iret指令之后,eip 的值是下面标号1处的地址,系统会继续运行下面的代码。这里把与数据相关的段寄存器都设置为0x17(任务0中 ldt 结构体中的数据段描述符)。
现在我们进入了用户态,那我们还能使用 printk 函数吗?

答案是不能的。那为什么不能呢?按理说目前的所有函数都在任务0的代码段中,而且代码段的属性被设置为可读可执行,不会出现这方面的报错才对。那让我们在 bochs 上一行行运行汇编指令,看看到底是哪里出了错。最终问题定位在如下所示的代码。
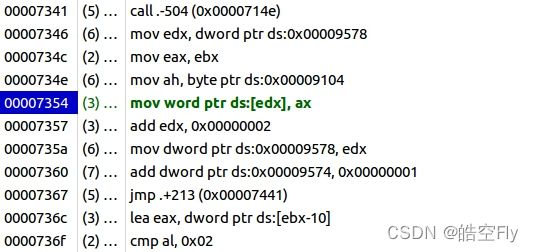
根据 System.map,我发现它的位置是在 con_write 函数中。
// System.map节选
0000714e t lf
000072f9 T con_write
000074a0 T con_init
00007603 T _etext
00007c60 r month
00007d6c T main
通过对比,我认为系统在下面这段代码触发了异常。
__asm__(
"movb %1, %%ah\n\t"
"movw %%ax, %2\n\t"
::"a"(c), "m"(attr), "m" (*(short *)pos));
这段代码会把字符写入显存中。这里我们不得不提一提上一节的一些设置了,我们把任务0的代码段基地址设置为0,段长度设置为0x9f000,而我机器上显存的起始地址是0xb8000,所以任务0访问显存就越界了。
在之后的调度算法中,当其他任务都无法运行时,系统就会运行任务0。
顺带一提,之前从核心态进入异常会出现打印 ss 和 esp 为0的情况,现在从用户态进入异常就不会出现这种情况。
3.系统调用
这一节会讲解系统调用的处理函数,并写一个简单的系统调用进行测试。
本章是任务管理的章节,就先简单写 fork 函数,之后在这基础上慢慢添加代码。下面是 fork 函数的定义。
// main.c
inline _syscall0(int, fork)
// unistd.h
#define __NR_fork 2
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
// error.c
int errno;
以宏定义的方式确实不容易理解,那就把它展开吧。
#define __NR_fork 2
int errno;
int fork(void)
{
long __res;
__asm__ volatile ("int $0x80"
:"=a"(__res)
:"0"(__NR_fork));
if (__res >= 0)
return (int) __res;
errno = -__res;
return -1;
}
这样看来,fork 函数会调用0x80号中断,将 __NR_fork 放入 eax 作为参数,返回值大于等于0会直接返回,小于0就设置 errno 后返回-1。之后我们会将系统调用设置为0x80号中断,系统调用中会使用到 eax 中的值。系统调用的代码如下所示。
# system_call.s
nr_system_calls = 72
.align 4
bad_sys_call:
movl $-1, %eax
iret
.align 4
system_call:
cmpl $nr_system_calls - 1, %eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # 将edx,ecx和ebx入栈作为参数
pushl %ebx
movl $0x10, %edx # ds和es用于访问系统数据
mov %dx, %ds
mov %dx, %es
movl $0x17, %edx # fs用于访问用户数据
mov %dx, %fs
call *sys_call_table(, %eax, 4)
3: popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
在调用中断时,也会把 ss,esp,eflags,cs 和 eip 入栈,结束中断时,又会把栈中的内容推入相应寄存器。
进入系统调用,首先比较系统调用号,linux0.11共有72个系统调用(系统调用号0-71),fork 的系统调用号为2,系统调用号在进入系统调用前会保存在 eax 中。如果系统调用号过大就返回错误。
接下来将一系列寄存器入栈,这也是中断异常的常规操作了。
将 ds 和 es 设置为系统数据段,访问系统数据。将 fs 设置为用户数据段,用于访问用户数据。
然后调用 fork 对应的处理函数。sys_call_table 是一个函数数组,保存系统调用的处理函数。
// sys.h
extern int sys_fork();
fn_ptr sys_call_table[72] = {0, 0, sys_fork};
// sched.h
typedef int (*fn_ptr)();
// system_call.s
.globl system_call, sys_fork
.align 4
sys_fork:
call print_fork
ret
*sys_call_table(, %eax, 4)表示 sys_call_table + eax * 4,在此处也就是 sys_fork 函数的地址。call 命令后的地址需要加 *,如果是函数名就不需要加 *。
简单地定义了 sys_fork 函数,让它调用 print_fork 函数后就返回。print_fork 函数也很简单,打印一条语句即可。
void print_fork()
{
printk("We are invoking fork funciton!\r\n");
}
修改 main 函数,调用 fork 函数。
void main(void)
{
memory_end = (1 << 20) + (EXT_MEM_K << 10);
memory_end &= 0xfffff000;
if (memory_end > 16 * 1024 * 1024)
memory_end = 16 * 1024 * 1024;
if (memory_end > 12 * 1024 * 1024)
buffer_memory_end = 4 * 1024 * 1024;
else if (memory_end > 6 * 1024 * 1024)
buffer_memory_end = 2 * 1024 * 1024;
else
buffer_memory_end = 1 * 1024 * 1024;
main_memory_start = buffer_memory_end;
mem_init(main_memory_start, memory_end);
trap_init();
tty_init();
time_init();
sched_init();
buffer_init(buffer_memory_end);
sti();
move_to_user_mode();
fork();
while (1);
}
也不要忘了修改 Makefile,包含库和添加函数变量声明,我偷懒就不写出来了。
成功运行!下面就来写写实际的 fork 函数吧,它的实现还是有点复杂的。
4.fork - 分配页面
这一节会实现 sys_fork 的部分功能:找到空闲的任务指针,分配空间给任务指针。
在第一节中,我们定义了任务指针数组 task,它有64个成员,目前我们只使用了第一个成员指向任务0的任务结构体。现在,我们的新任务也需要一个任务指针指向它的任务结构体,我们需要在 task 中寻找未使用过的任务指针。
// fork.c
long last_pid = 0;
int find_empty_process(void)
{
int i;
repeat: // 获取不重复的pid
if ((++last_pid) < 0)
last_pid = 1;
for(i = 0; i < NR_TASKS; i++)
if (task[i] && task[i]->pid == last_pid)
goto repeat;
for(i = 1; i < NR_TASKS; i++) // 把任务0排除在外
if (!task[i])
return i;
return -EAGAIN;
}
第6-11行是为了获得不重复的 pid。第7-8行是为了防止 last_pid 变成负数,第10-12行查看是否有任务的 pid 与 last_pid 相同,如果相同重复上述操作;如果不同就在 task 中寻找未使用的指针,返回任务号。如果所有指针都被使用则返回错误。
# system_call.s
.align 4
sys_fork:
call find_empty_process
testl %eax, %eax
js 1f
pushl %eax
call copy_process
addl $4, %esp
1: ret
在 sys_fork 中首先调用 find_empty_process 函数获得空闲指针的任务号,任务号保存在 eax 中。如果 eax 为负数就跳转到下面的标记1,直接返回。
将任务号入栈作为 copy_process 的参数,然后调用 copy_process 函数,恢复栈指针并返回。copy_process 函数会分配一块空间给新任务,存放新任务的任务结构体。一般来说,分配内容空间我们都是用 malloc 函数,但是现在内核里没有这个函数,分配内容的工作就只有交给我们自己来完成了。
// fork.c
int copy_process(int nr)
{
struct task_struct *p;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
printk("task struct address: 0x%x\n\r", p);
return last_pid;
}
这段程序很简单,使用 get_free_page 返回一个未使用的页面的地址,这个地址被当作任务结构体的地址,如果没找到未使用的页面,会返回0。将地址存入 task 数组中,返回 pid。为了直观起见,将这个地址打印出来。
// memory.c
#define LOW_MEM 0x100000
#define PAGING_MEMORY (15*1024*1024)
#define PAGING_PAGES (PAGING_MEMORY>>12)
unsigned long get_free_page(void)
{
unsigned long __res;
__asm__("std\n\trepne\n\tscasb\n\t"
"jne 1f\n\t"
"movb $1, 1(%%edi)\n\t"
"sall $12, %%ecx\n\t"
"addl %2, %%ecx\n\t"
"movl %%ecx, %%edx\n\t"
"movl $1024, %%ecx\n\t"
"leal 4092(%%edx), %%edi\n\t"
"rep\n\tstosl\n\t"
"movl %%edx, %%eax\n"
"1:"
:"=a"(__res)
:"0"(0), "i"(LOW_MEM), "c"(PAGING_PAGES),
"D"(mem_map + PAGING_PAGES - 1)
);
return __res;
}
内联汇编代码会先把 __res 设置为0,然后放入 eax 中,把 PAGING_PAGES 放入 ecx 中,把 mem_map 的最后一个元素放入 edi 中。
std\n\trepne\n\tscasb\n\t这三条指令中,scasb会将 es:[edi] 的值与 al 的值比较,std会递减 edi,如果相等,设置 eflags.ZF 为1,进入下一条指令;如果不等,repne会递减 ecx,使这个操作继续执行,直至 ecx 变成0。
第10行,如果 eflags.ZF 不为1就跳转到下面的标记1,翻译过来就是如果 mem_map 的元素没有 0 的话就直接返回0,再说直白点就是没有空闲的页面就返回0。
找到空闲页后 edi 还是会减1,所以 edi+1 才是空闲页的位置,将其置1,表示该页已被使用。
第12-13行相当于 ecx=ecx<<12+LOW_MEM 得到页面的地址。第14行将地址存入 edx 中。
第15-17行会把整个页面都填充为 eax 的值,即把整个页面都填充为0。
第18行把页面地址存入 eax 中,也就是把地址赋给 __res。
最后返回 __res。如果找到空闲页就返回空闲页地址,没找到就返回0
对于我们的这个新任务,get_free_page 函数会返回最后一个页面的地址。我们共有16MB(0x1000000)的内存,每个页面4KB,所以最后一个页面的地址是0xfff000才对,让我们运行看看,是不是这个地址。
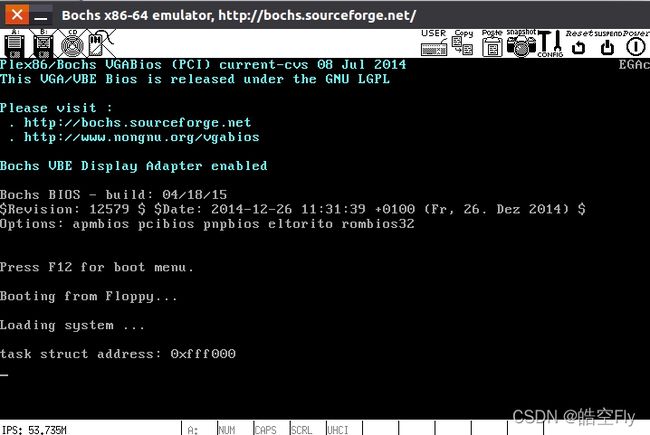
不出所料!不过,现在,我们得到了一个4KB的页面,光是给任务结构体用未免有些浪费,毕竟任务结构体也就不超过1KB,剩下的空间就当做任务的核心态栈空间吧,只不过这是下一节的内容了。
5.fork - 任务设置
上一节中,我们只是为新任务的任务结构体分配了空间,还没有对任务结构体内的成员赋值,这一节的内容都是对任务结构体的操作。
# system_call.s
.align 4
sys_fork:
call find_empty_process
testl %eax, %eax
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call copy_process
addl $20, %esp
1: ret
首先更改 sys_fork 函数,添加几个入栈操作,这些入栈的寄存器都会称为 copy_process 的参数。
// sched.c
long volatile jiffies = 0;
struct task_struct *current = &(init_task.task);
// fork.c
int copy_process(int nr, long ebp, long edi, long esi, long gs,
long none, long ebx, long ecx, long edx,
long fs, long es, long ds, long eip,
long cs, long eflags, long esp, long ss)
{
struct task_struct *p;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
__asm__("cld"::); // 必须添加这一句,否则下一句不能正确执行
*p = *current; // 复制父进程的参数
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid; // 由find_emtpy_process找到的pid
p->father = current->pid; // 设置父进程号
p->counter = p->priority;
p->signal = 0;
p->alarm = 0;
p->leader = 0;
p->utime = p->stime = 0; // 初始化用户态时间和核心态时间
p->cutime = p->cstime = 0; // 初始化子进程用户态和核心态时间
p->start_time = jiffies; // 当前滴答数时间
// 以下设置任务状态段tss所需的参数
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
p->tss.eip = eip;
p->tss.eflags = eflags;
p->tss.eax = 0;
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff; // 段寄存器仅16位有效
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr); // 新任务的局部描述符表选择符
p->tss.trace_bitmap = 0x80000000;
copy_mem(nr, p);
// 设置新任务的tss和ldt描述符
set_tss_desc(gdt + (nr << 1) + FIRST_TSS_ENTRY, &(p->tss));
set_ldt_desc(gdt + (nr << 1) + FIRST_LDT_ENTRY, &(p->ldt));
p->state = TASK_RUNNING; // 将任务设置为可运行状态
printk("We are almost done setting up!\n\r");
return last_pid;
}
jiffies 代表从开机算起的滴答数(1滴答 = 10ms)。current 指向当前任务的任务结构体,一开始被设置为指向任务0的任务结构体,之后会随任务调度改变其指向的任务结构体,这个变量很有用,我们会经常获得当前任务的任务结构体的信息。
好家伙,copy_process 的参数是真的多,除了 nr(find_empty_process 得到的任务号)和 none(无用参数)以外,全都是寄存器的值。
在为新任务获得内存空间后,将新任务的指针存入 task 数组中。*p = *current;是结构体的赋值,可以把一个结构体的内容拷贝到另一个结构体中,很方便。但是,应该是编译器的原因,这条指令并没有按照我想想的样子执行,所以我加了__asm__("cld"::);这段代码。
现在要对任务1的任务结构体进行调整。
先将任务设置为不可中断态,任务的运行状态有以下几种。有些状态可以相互转换。
// sched.h
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 3
#define TASK_STOPPED 4
再设置 pid,父进程号,时间片和起始时间等参数。接着是 tss 结构体,第31行代码表示把栈指针指向任务结构体所在页面的末尾,这是准备把任务结构体的结束地址到页面的结束地址作为任务的核心态栈空间。第33行把任务0的 eip 给了任务1,所以任务1第一次运行时,会从 fork 函数后开始运行,剩下的赋值都很简单,不多赘述。
第51行会设置 ldt 结构体(存放任务的代码段和数据段信息)。
第54-55行会将 gdt 中的 tss 和 ldt 描述符的基址设置为 新任务的 tss 和 ldt 结构体的地址。
最后将任务的状态设置为可运行状态,如果一系列设置没有大问题的话,会打印一段话,并返回任务的 pid。
接下来仔细讲讲是怎么设置 ldt 结构体的。
// fork.c
int copy_mem(int nr, struct task_struct *p)
{
unsigned long old_data_base, new_data_base, data_limit;
unsigned long old_code_base, new_code_base, code_limit;
code_limit = get_limit(0x0f);
data_limit = get_limit(0x17);
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)
panic("Bad data_limit");
new_data_base = new_code_base = nr * 0x4000000; // 新基址 = 任务号 * 64MB(任务大小)
p->start_code = new_code_base;
set_base(p->ldt[1], new_code_base); // 设置代码段基址
set_base(p->ldt[2], new_data_base); // 设置数据段基址
return 0;
}
这个函数本来是用于将当前任务的页表拷贝到新任务中,所以我们要获取三个信息:当前任务数据段的基地址,当前任务数据段的界限(长度),新任务数据段的基地址。这一节中我们只是获得和设置这些信息,拷贝的工作留到下一节。
如果你想知道为什么只拷贝页表,而不是把数据段的内容全部拷贝到新任务中,那么可以百度写时复制(copy-on-write)。
要拷贝页表,我们需要知道代码段和数据段的地址和长度。它们的长度等于段界限加1,lsll是加载段界限的指令,即把 segment 段描述符中的段界限字段装入某个寄存器,之后将段界限加1得到长度。0x0f 代表任务结构体的 ldt[1],0x17代表了 ldt[2]。
// sched.h
#define get_limit(segment) ({ \
unsigned long __limit; \
__asm__("lsll %1, %0\n\tincl %0":"=r"(__limit):"r"(segment)); \
__limit;})
接下来是获得代码段和数据段的基址。因为没有专门的指令加载段基址,就只能自己写代码加载了。段基址存放于 ldt 结构体的描述符的三个字段中,所以获得段基址的代码看起来有些繁琐,但只要知道描述符的结构体,代码应该不难理解。
// sched.h
static inline unsigned long _get_base(char * addr)
{
unsigned long __base;
__asm__("movb %3, %%dh\n\t"
"movb %2, %%dl\n\t"
"shll $16, %%edx\n\t"
"movw %1, %%dx"
:"=&d"(__base)
:"m"(*((addr) + 2)),
"m"(*((addr) + 4)),
"m"(*((addr) + 7)));
return __base;
}
#define get_base(ldt) _get_base(((char *)&(ldt)))
任务数据段和代码段的界限相同的,基址也是相同的(linux0.11不支持代码段和数据段分立的情况),那我们只获取数据段的界限和基址不就好了,为什么要多此一举获取代码段的信息?这是为了做安全检查,程序中说不定会有错误操作修改了它们的值。检查到它们不一样就打印错误信息,进入死循环。
报错代码很简单,打印信息然后死循环就好。
// panic.c
void panic(const char *s)
{
printk("Kernel panic: %s\n\r", s);
if (current == task[0])
printk("In swapper task - not syncing\n\r");
while (1);
}
新任务的代码段和数据段的基地址被设置为任务号(task 数组中的索引)乘以64MB,也就是说,每个任务都有64MB的空间。可之前不是说只能管理16MB的空间吗?没关系的,因为我们可以把现有的页面作为页表,管理更多的内存空间。
最后设置新任务的代码段和数据段基址。设置基址和获取基址的操作差不多,就不再讲解了。
// sched.h
#define _set_base(addr, base) \
__asm__ ("push %%edx\n\t" \
"movw %%dx, %0\n\t" \
"rorl $16, %%edx\n\t" \
"movb %%dl, %1\n\t" \
"movb %%dh, %2\n\t" \
"pop %%edx" \
::"m"(*((addr) + 2)), \
"m"(*((addr) + 4)), \
"m"(*((addr) + 7)), \
"d"(base) \
)
#define set_base(ldt, base) _set_base(((char *)&(ldt)), (base))
来看看运行情况把。
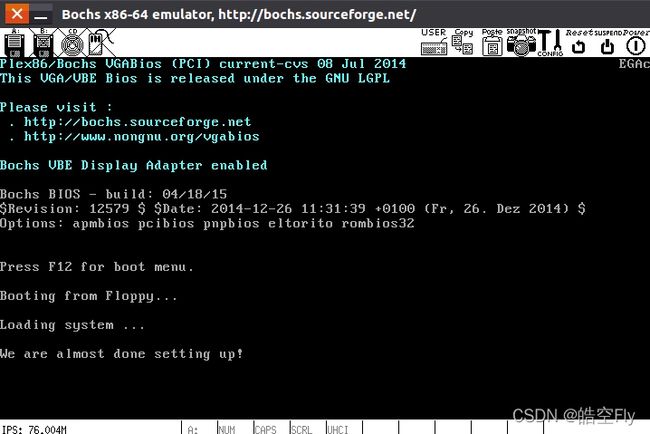
这个打印也只能说明系统没触发什么异常,至于对新任务的设置是否出错,还要看之后的章节中是否出错。
6.fork - 复制页表
这一节是将当前任务的页表拷贝到新任务中。这一节也是fork的最后一节。
我们要在 copy_mem 函数中添加一些内容。
// fork.c
int copy_mem(int nr, struct task_struct *p)
{
unsigned long old_data_base, new_data_base, data_limit;
unsigned long old_code_base, new_code_base, code_limit;
code_limit = get_limit(0x0f);
data_limit = get_limit(0x17);
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)
panic("Bad data_limit");
new_data_base = new_code_base = nr * 0x4000000; // 新基址 = 任务号 * 64MB(任务大小)
p->start_code = new_code_base;
set_base(p->ldt[1], new_code_base); // 设置代码段基址
set_base(p->ldt[2], new_data_base); // 设置数据段基址
if (copy_page_tables(old_data_base, new_data_base, data_limit)) {
printk("free_page_tables: from copy_mem\n");
free_page_tables(new_data_base, data_limit);
return -ENOMEM;
}
return 0;
}
还记得上一节讲到,只要得到当前任务数据段的基地址,当前任务数据段的界限(长度),新任务数据段的基地址,就能进行页表的拷贝。copy_page_tables 函数就将这些信息当做参数,进行拷贝操作。
// memory.c
int copy_page_tables(unsigned long from, unsigned long to, long size)
{
unsigned long *from_page_table;
unsigned long *to_page_table;
unsigned long this_page;
unsigned long *from_dir, *to_dir;
unsigned long nr;
if ((from & 0x3fffff) || (to & 0x3fffff)) // 需要4MB对齐
panic("copy_page_tables called with wrong alignment");
from_dir = (unsigned long *) ((from >> 22) << 2);
to_dir = (unsigned long *) ((to >> 22) << 2);
size = ((unsigned) (size + 0x3fffff)) >> 22; // 页目录项数量
for( ; size-- > 0; from_dir++, to_dir++) {
if (1 & *to_dir)
panic("copy_page_tables: already exist");
if (!(1 & *from_dir))
continue;
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
if (!(to_page_table = (unsigned long *) get_free_page()))
return -1; // 无空闲页面
*to_dir = ((unsigned long) to_page_table) | 7;
nr = (from == 0) ? 0xA0 : 1024; // 如果是复制任务0,只复制前160个页面
for ( ; nr-- > 0; from_page_table++, to_page_table++) {
this_page = *from_page_table;
if (!(1 & this_page))
continue;
this_page &= ~2;
*to_page_table = this_page;
if (this_page > LOW_MEM) {
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
}
}
}
invalidate();
return 0;
}
首先,我们需要保证当前任务数据段的基地址与新任务数据段的基地址是4MB(0x400000)对齐的,那为什么需要4MB对齐呢?这和页表有关,我们之前设置页面大小为4KB,一张页表管理1KB个页面,即4MB地址。我们是以页表为单位复制数据的,而页表管理的地址是4MB对齐的(如第一个页表管理0-4MB地址,第二个页表管理4MB-8MB地址)。
from_dir 和 to_dir 是页目录项的地址,它们的赋值看着有些奇怪。以 to=64MB(4000000)为例,to >> 22等于64MB地址所对应的页目录项(索引号16的页目录项),每个页目录项4字节,所以页目录项的地址是(to >> 22) * 4,就等同于(to >> 22) << 2,那能不能直接写成(to >> 20)呢?废话,能的话我何必多此一举。(to >> 22) << 2等同于(to >> 20) & 0xffc。
size 表示需要使用的页目录项数量。
第18-41行拷贝页表。*to_dir 代表页目录项的内容,其第0位是存在位,其值为1代表内存中存在该页表。我们明显是想获得未被使用过的页表,如果页表已存在就直接报错卡死。同理,对于 *from_dir 的存在位我们希望它的值是1,因为我们要复制已存在的页表。
from_page_table 代表当前任务的一个页表的地址,用 get_free_page 函数获得一个新页面,当做新任务的页表,将这张页表的地址和相关的权限设置到页目录中。
nr代表页表项的数量,如果是任务0创建新任务的话(只有任务0创建新任务时 from 才等于0),就只拷贝0xa0(160)个页表项(管理640KB空间),因为内核大小不会超过640KB,多拷贝页表项也只是浪费罢了。
第二个 for 循环会把 nr 个页表项从当前任务的页表拷贝到新任务的页表,并将每个页面的权限设置为只读。这样的话,新任务岂不是不能修改数据了?因为我们并没有拷贝数据段,所以新任务修改数据的话,当前任务的数据也会发生变化,这可是不我们想看到的。如果新任务要修改数据,这个操作会触发页错误异常,操作系统拷贝数据段,这时新任务才拥有属于自己的数据段。之后,修改操作继续,新任务修改自己数据段中的数据。这个过程被称为写时复制(copy-on-write)。另外,如果这个页面大于1MB,还需要增加页面的引用数。
在函数结束前,我们还需要刷新页变换高速缓冲,具体代码如下。
// memory.c
#define invalidate() \
__asm__("movl %%eax, %%cr3"::"a"(0))
这不就只是重新设置了 cr3 寄存器吗?和什么高速缓冲有什么关系啊?操作系统最近使用过的页面都会放在高速缓冲(cache)中,修改过页表信息之后,就需要刷新该缓冲区。重新加载页目录基址寄存器 cr3 也是刷新缓冲区的方法之一。
当没有空闲页面的时候,copy_page_tables 会返回-1,copy_mem 将会打印错误信息,并释放之前获取的页面。
// memory.c
int free_page_tables(unsigned long from, unsigned long size)
{
unsigned long *pg_table;
unsigned long *dir, nr;
if (from & 0x3fffff)
panic("free_page_tables called with wrong alignment");
if (!from)
panic("Trying to free up swapper memory space");
size = (size + 0x3fffff) >> 22;
dir = (unsigned long *) ((from >> 22) << 2);
for ( ; size-- > 0; dir++) {
if (!(1 & *dir))
continue;
pg_table = (unsigned long *) (0xfffff000 & *dir);
for (nr = 0; nr < 1024; nr++) {
if (1 & *pg_table)
free_page(0xfffff000 & *pg_table);
*pg_table = 0;
pg_table++;
}
free_page(0xfffff000 & *dir);
*dir = 0;
}
invalidate();
return 0;
}
首先还是要检查是否是4MB对齐。我们不可能释放任务0的页表,所以 from 不能为0。
size 代表页目录项数量,dir 代表页目录中的地址。
第13-25行会把页目录项对应的页表所在的页面和页表项对应的页面释放掉。第14-15行代码的意思是,如果该页目录项对应的页表不存在,则继续循环。
第16行会得到页表的地址。第17-22行会把页表中页表项对应的页面释放掉。第23行会把页表所在的页面释放掉,第24行把页目录项置零。
最后刷新 cache 并返回。
我们还得讲讲释放页面的具体过程。
void free_page(unsigned long addr)
{
if (addr < LOW_MEM)
return;
if (addr >= HIGH_MEMORY)
panic("trying to free nonexistent page");
addr -= LOW_MEM;
addr >>= 12;
if (mem_map[addr]--)
return;
mem_map[addr] = 0;
panic("trying to free free page");
}
我们不会释放对应1MB地址以下的页面,mem_map 也不管这一块地址。另外,如果地址超出了内存大小,直接报错死循环一条龙。
计算地址对应的页面在 mem_map 中的索引,如果 mem_map[addr] 为0,说明发生了错误,这个页面都没分配出去,怎么就释放了?如果不为0,则递减然后返回。
我们还需要修改一处代码。copy_process 的代码太长了,我就只放节选了。
// fork.c
int copy_process(int nr, long ebp, long edi, long esi, long gs,
long none, long ebx, long ecx, long edx,
long fs, long es, long ds, long eip,
long cs, long eflags, long esp, long ss)
{
...
if (copy_mem(nr, p)) {
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
...
}
如果复制页表失败,我们还需要把为新任务结构体申请的页面释放掉,同时把任务指针数组中的对应内容设置为 NULL,返回错误。
代码已经修改完毕。但是,我们却不能知道新任务能否成功运行,因为没有任务调度程序让CPU执行新任务,下一节就讲讲任务调度吧。另外,这节的运行结果就不展示了吧,也没什么好看的。
这一节有不少内存管理的操作,如果实在不理解,建议看看操作系统课程中关于内存管理的内容。
7.任务调度
任务调度的重要性不言而喻,没有它,你有再多任务,系统也只会一直运行一个任务。
任务调度的具体代码如下。
// sched.c
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
switch_to(next);
}
第7-22行代码是一个循环,唯有当 c 不为0时才能跳出。第12-17行代码会遍历任务指针数组,找到所有可运行任务中时间片最大的那一个,保存它的任务号。如果所有任务的时间片都用完了,此时 c 等于0,不会跳出循环,第19-21行代码会重新设置任务的时间片,然后重新查找任务。
如果所有任务都不可运行,那么 c 仍然是 -1, next 为 0,此时会跳出循环,系统会调度到任务0。任务0就是 idle 任务。
在找到调度的任务之后,进入真正的调度过程中。
// sched.h
#define switch_to(n) {\
struct {long a, b;} __tmp; \
__asm__("cmpl %%ecx, current\n\t" \
"je 1f\n\t" \
"movw %%dx, %1\n\t" \
"xchgl %%ecx, current\n\t" \
"ljmp *%0\n\t" \
"1:" \
::"m"(*&__tmp.a), "m"(*&__tmp.b), \
"d"(_TSS(n)), "c"((long) task[n])); \
}
在这个汇编内联代码中,任务指针放在 ecx 中,edx 中保存任务的 tss 段选择符(tss 描述符在 gdt 中的地址)。
首先对比要调度的任务与当前任务是否为同一个,是的话就不用调度直接结束。如果不是的话,就把 dx 的值保存到 __tmp.b 中,然后交换 current 和 ecx 中的值,此时,current 指向要调度的任务,最后使用ljmp完成任务切换。
任务切换有4种方法,其中一种就是通过jmp或call跳转到 gdt 中的 tss 描述符中。ljmp使用内存操作数时,会使用48比特位作为目标逻辑地址,高16位存放段选择符,低32位存放偏移。在这里,低32位是 __tmp.a 的内容,它的值为0。高16位是部分 __tmp.b 的内容,它的值为 dx,即要调度的任务的 tss 段选择符。也就是说,通过ljmp,我们完成了任务切换。
我们使用系统调用来进行任务调度。
// sched.c
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
schedule();
return 0;
}
// main.c
inline _syscall0(int, pause)
// unistd.h
#define __NR_pause 29
// sys.h
extern int sys_pause();
fn_ptr sys_call_table[72] = {0, 0, sys_fork, sys_print, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_pause};
pause 系统调用会让当前任务变成不可运行的状态,然后进行任务调度。
我们在 main 函数中使用 pause。
// unistd.h
#define __NR_print 3
// main.c
inline _syscall0(int, print)
void main(void)
{
...
sti();
move_to_user_mode();
if (!fork()) {
init();
}
while (1)
pause();
}
int sys_print()
{
int i;
for (i = 0; i < NR_TASKS; i++)
if (current == task[i]) {
printk("Now in task %d\n\r", i);
break;
}
}
void init(void)
{
print();
while (1);
}
对于不同任务,fork 的返回值不同。对于父进程,fork 返回子进程的 pid;对于新建的子进程,fork 返回0。通过 fork 的返回值,我们就可以让不同的任务执行不同的程序。
在任务0中,fork 返回之后就进入死循环执行 pause,pause会让任务0不可运行,并进行任务调度,此时变成任务1运行。任务1的 fork 函数返回0,进入 if 分支执行 init 函数。
在 init 函数中调用 print 函数,print 函数是我新建的一个系统调用。因为在用户态无法使用 printk 函数,我们也没有其他办法打印信息,就只好创建一个系统调用,在系统调用里打印信息。print 函数会打印当前任务的任务号。如果没有问题,屏幕上会打印Now in task 1。
好了,让我们运行看看结果吧。
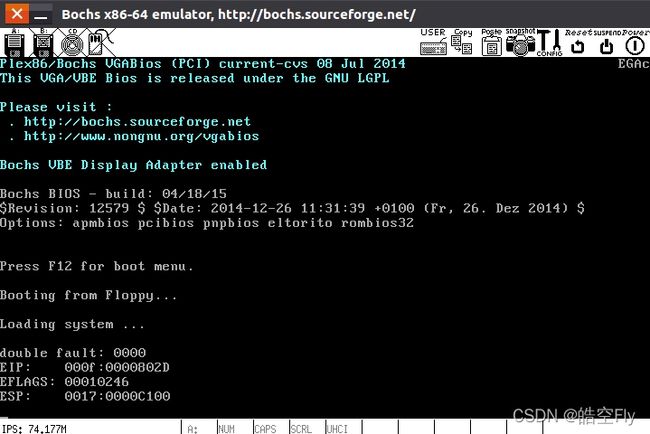
double fault???what?什么情况?(刚看到这个界面的时候,我心里陡然浮现这三个疑问)。。。让我们看看到底是哪里出了错。

这个语句应该是在调用 init 函数。不是,call怎么都能出错?现在任务1和任务0共享代码段,init 函数在内存中,可以被访问,为什么会出错?这就要说说call的实现原理了。call和jmp是不同的,call会先将 eip 入栈,然后跳转到函数中。入栈操作会向栈写入数据,但我们此时对数据段只有读权限,因此会触发页错误,而尴尬的是,我们还没有写页错误处理程序,所以才会报出双重错误。
好吧,看来我们还需要写页错误处理程序。不过,我们也可以通过某种方法绕过页错误。
void init(void)
{
print();
}
方法很简单,只要我们把 init 函数中的死循环去掉就可以了。经过编译器的优化,init 函数的内容会被放入 main 函数中。print 函数是系统调用,它会使用核心态栈空间(也就是任务结构体后面的那块空间),不会触发页错误。让我们再次运行看看情况吧。

可以看到,任务调用正常工作。但这样做会存在很多 bug,因为任务1执行完 init 函数后,会回到 main 函数的死循环执行 pause 函数,而 pause 函数会把当前任务设置成不可运行的状态。当系统中没有其它任务可以运行时,我们的任务调度算法会让任务0得到执行权。这些事情可不是我们想看到的。
最后我还要讲讲一些系统调用中断有关的内容,因为和上面的内容相比不太重要,我就放到最后了。
# system_call.s
state = 0 # 相对于任务结构体的偏移
counter = 4
.align 4
reschedule:
pushl $ret_from_sys_call
jmp schedule
.align 4
system_call:
...
call *sys_call_table(, %eax, 4)
pushl %eax
movl current, %eax
cmpl $0, state(%eax) # 状态
jne reschedule
cmpl $0, counter(%eax) # 时间片
je reschedule
ret_from_sys_call:
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
在执行系统调用函数之后,检查当前任务的状态和时间片,如果当前任务不可执行或是时间片为0,就重新调度任务,ret_from_sys_call 会作为 schedule 函数结束后的返回地址。
8.页错误
没有页错误的话,我们不仅无法调用函数,也无法修改变量的值,还是早早地加上这个异常,方便之后的处理。
# page.s
.globl page_fault
page_fault:
xchgl %eax, (%esp)
pushl %ecx
pushl %edx
push %ds
push %es
push %fs
movl $0x10, %edx
mov %dx, %ds
mov %dx, %es
mov %dx, %fs
movl %cr2, %edx # 获得触发异常的线性地址
pushl %edx
pushl %eax
testl $1, %eax
je 2f
call do_wp_page
2: addl $8, %esp
pop %fs
pop %es
pop %ds
popl %edx
popl %ecx
popl %eax
iret
页错误有错误码,错误码已经被硬件放在栈顶。通过xchgl指令将 eax 寄存器入栈,并将错误码放入 eax 中。之后就是老规矩,寄存器入栈,改段寄存器。在触发页错误时,会把出错的线性地址存入 cr2 中。把 edx(出错地址)和 eax(错误码)入栈作为 do_wp_page 的参数。
第18行代码是根据不同的错误码执行不同的代码。页错误的错误码格式如下。

| 位 | 含义 |
|---|---|
| P | 0:由一个不存在的页触发错误 1:由页级保护触发错误 |
| W/R | 0:读操作触发错误 1:写操作触发错误 |
| U/S | 0:核心态触发错误 1:用户态触发错误 |
如果 P 位为1,就说明这是任务写操作触发的中断,调用 do_wp_page 进行处理,如果不为1,就说明这是虚拟内存的缺页触发的中断,先不管,让它把寄存器出栈然后返回,缺页中断的具体实现之后的章节再介绍。
// memory.c
void un_wp_page(unsigned long *table_entry)
{
unsigned long old_page, new_page;
old_page = 0xfffff000 & *table_entry;
if (old_page >= LOW_MEM && mem_map[MAP_NR(old_page)] == 1) { // 如果页面已存在
*table_entry |= 2;
invalidate();
return;
}
new_page = get_free_page();
if (!new_page)
oom();
if (old_page >= LOW_MEM)
mem_map[MAP_NR(old_page)]--;
*table_entry = new_page | 7;
invalidate();
copy_page(old_page, new_page);
}
void do_wp_page(unsigned long error_code, unsigned long address)
{
un_wp_page((unsigned long *)
(((address>>10) & 0xffc) + (0xfffff000 &
*((unsigned long *) ((address>>20) & 0xffc)))));
}
un_wp_page 的参数是页表项的地址,我们在第24-26行代码计算的,就是address所在页面对应的页表项的地址。((address>>10) & 0xffc)计算页表项在页表的偏移地址,*((unsigned long *) ((address>>20) & 0xffc))是获得页表的地址,我们将页表的地址4KB对齐,然后与之前计算的偏移地址相加,就得到了address所在页面对应的页表项的地址。
un_wp_page 中,old_page 代表出错地址所在页面的地址。如果该页已存在而且不属于任务0,就赋予当前任务写权限,刷新缓冲区,然后返回。如果不存在,就申请一个空闲页面,如果获取空闲页面失败就报错,报错函数如下。如果出错页面不属于任务0(只有任务0的页面地址小于 LOW_MEM),就递减页面的引用数。设置页表项的基址和页权限,刷新缓冲区,拷贝原本页面的数据。
// memory.c
static inline void oom(void)
{
printk("out of memory\n\r");
while (1);
}
#define copy_page(from, to) \
__asm__("cld\n\trep\n\tmovsl"::"S"(from), "D"(to), "c"(1024))
copy_page 会从 from 地址拷贝一个页面的数据(4KB)到 to 地址。
最后还需要把 page_fault 添加到 idt 中。
// traps.c
void page_fault(void);
void trap_init(void)
{
...
set_trap_gate(13, &general_protection);
set_trap_gate(14, &page_fault);
set_trap_gate(15, &reserved);
for (i = 17; i < 48; i++)
set_trap_gate(i, &reserved);
}
让我们来看看效果吧。
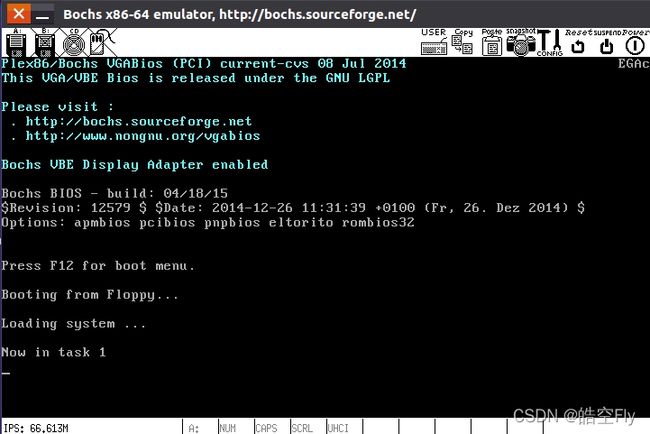
不错,终于打印出来了。对于一个任务的运行已经没有问题了,那么如果我们有多个任务应该怎么切换呢?用 pause 吗?还是创建一个新的系统调用实现它?这两个方案都不好。任务最好每隔一段时间切换一次,这样不同的任务都能有时间运行,而如果我让任务快速地切换,那么多个任务看起来就像是同时在运行一样,这就是并发。为了实现并发,我们得设置时钟中断。
9.时钟中断
我们可以通过时钟中断每隔一段时间减少任务的时间片,如果任务的时间片为0就进行任务调度。这可比 pause 方便多了,不需要我们在某个地方设置设置调度函数,也不会把当前任务改为不可运行的状态。
在看时钟中断的代码之前,我们先看看需要对时钟中断做怎样的设置。
// sched.h
#define HZ 100
// sched.c
#define LATCH (1193180 / HZ)
void sched_init(void)
{
...
ltr(0);
lldt(0);
outb_p(0x36, 0x43);
outb_p(LATCH & 0xff, 0x40); // 低位字节
outb(LATCH >> 8, 0x40); // 高位字节
set_intr_gate(0x20, &timer_interrupt);
outb(inb_p(0x21) & ~0x01, 0x21);
set_system_gate(0x80, &system_call);
}
第12行代码,我们把0x36发送到0x43端口,这是要干什么呢?我们先搞清楚0x43端口是干什么的。

0x43端口是8253可编程间隔定时器芯片的模式控制寄存器,0x36代表选择计数器0,先写低字节再写高字节,模式3(方波频率发生器),16位二进制计数器。
第13-14行代码是设置时钟的中断频率。这个1193180是什么意思啊?PC 机8253芯片的时钟频率为1.193180MHz,即1193180/每秒,1193180/100代表时钟每跳11931.8下产生一次时钟中断,即每1/100秒(10ms)产生一次时钟中断。
接下来是设置时钟中断的处理函数地址。
// system.h
#define _set_gate(gate_addr, type, dpl, addr) \
__asm__("movw %%dx, %%ax\n\t" \
"movw %0, %%dx\n\t" \
"movl %%eax, %1\n\t" \
"movl %%edx, %2" \
: \
:"i"((short) (0x8000 + (dpl << 13) + (type << 8))), \
"o"(*((char *) (gate_addr))), \
"o"(*(4 + (char *) (gate_addr))), \
"d"((char *) (addr)),"a"(0x00080000))
#define set_intr_gate(n, addr) \
_set_gate(&idt[n], 14, 0, addr)
这个宏定义和第五章讲到的 set_trap_gate 相似,仅 type 的值不同,type=14 表示这是一个中断描述符。
之后解除时钟中断的中断屏蔽,这样就可以触发时钟中断了。
现在来看时钟中断处理函数的具体代码。
# system_call.s
EAX = 0x00 # 相对于栈指针的偏移
EBX = 0x04
ECX = 0x08
EDX = 0x0C
FS = 0x10
ES = 0x14
DS = 0x18
EIP = 0x1C
CS = 0x20
EFLAGS = 0x24
OLDESP = 0x28
OLDSS = 0x2C
.globl system_call, sys_fork, timer_interrupt
.align 4
timer_interrupt:
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
pushl %ebx
pushl %eax
movl $0x10, %eax # ds和es用于访问系统数据
mov %ax, %ds
mov %ax, %es
movl $0x17, %eax # fs用于访问用户数据
mov %ax, %fs
incl jiffies
movb $0x20, %al
outb %al, $0x20
movl CS(%esp), %eax
andl $3, %eax # 设置特权级别为3
pushl %eax
call do_timer
addl $4, %esp
jmp ret_from_sys_call
寄存器入栈是中断异常的老规矩了。然后是设置段寄存器。
第31行,增加 jiffies,jiffies 代表滴答数,1滴答等于10ms。
之前在将 PIC 初始化的时候,我介绍过 ICW1-ICW4 和 OCW1,但8259芯片还有其他的寄存器,这里要介绍 OCW2(中断命令寄存器),它在0x20端口。Markdown 的表格不能像 Word 那样合并,我就不用表格表示各个位的含义了。
- bits 765:中断结束码。
- bits 43:必须为0。这是OCW2的标识位。
- bits 210:中断请求级别。
将0x20发送到0x20端口,代表这是一个发送到 OCW2 寄存器的数据。中断结束码为1,代表普通中断结束。中断请求级别为0,代表时钟中断(时钟中断是 IRQ0)。中断结束相当于 CPU 响应了中断,不然中断会再次被触发,这样可能会打乱正在服务的程序。
响应中断后,获取当前任务的 cs,并得到它的特权级别,将特权级别压入栈作为 do_timer 的参数。
调用 do_timer,恢复栈指针,从中断返回。
// sched.c
void do_timer(long cpl)
{
if (cpl)
current->utime++;
else
current->stime++;
if ((--current->counter) > 0)
return;
current->counter = 0;
if (!cpl)
return;
schedule();
}
原本 do_timer 还是有点复杂的,但是目前用不上那些功能。看看现在的代码,多么的简洁明了,多么的朴实无华。
根据特权级增加用户或是内核的运行时间。递减当前任务的时间片,如果时间片被减至0,就切换任务。简单而强大的功能。
最后修改一下代码,让调度更直观一些。
// main.c
void init2(void)
{
while (1) {
print();
for (int i = 0; i < 20000000; i++)
nop();
}
}
void init(void)
{
if (!fork())
init2();
while (1) {
print();
for (int i = 0; i < 20000000; i++)
nop();
}
}
如代码所示,init 函数会创建新任务,新任务会执行 init2 函数。如果时钟中断成功运行的话,屏幕上应该会每隔一段时间打印任务1和任务2地任务号。

意料之中!不过这任务号的顺序是不是有点奇怪啊。按理说不应该是任务1、任务2交替执行吗?怎么后面是先执行任务2再执行任务1呢?这和我们的调度算法有关系。
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
switch_to(next);
}
刚开始先执行任务1,等任务1的时间片用完再执行任务2。当任务2的时间片也用完时,系统中没有可运行的任务,调度算法会给任务重新设置时间片,然后,由于我们是倒序查找任务,所以会先找到任务2,并调度到任务2,等任务2的时间片用完再调度到任务1。所以就出现了上面的情况,还好不是 bug。
10.任务控制
有了上面的内容还不足以让我们管理任务,这节要添加任务睡眠,任务唤醒和任务结束的内容。
任务的睡眠和唤醒可以让我们更好的控制系统,比如,设置临界区。任务 a 要读取文件,但任务 b 正在读取文件,这时应该睡眠任务 a,切换任务,等任务 b 读取完文件后再切换回任务 a。
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
schedule();
if (tmp)
tmp->state = 0;
}
这个函数的参数类型是struct task_struct **,这是因为下面的代码要修改真实参数的值。比如,我们传入的参数是 &task[1],*p 就代表 task[1],修改 *p 就是修改 task[1]。如果参数类型是struct task_struct *,我们是无法修改task数组的。
首先 p 不能为空,其次当前任务不能是任务0。
在实际中,sleep_on 函数并不会将 task 数组的成员作为参数,而是把各种等待队列的地址作为参数,*p = current;相当于把当前任务加入等待队列中,然后把当前任务设置成不可运行的状态,再切换任务。直到等待队列被唤醒时,才会返回到第13行代码,如果此时还处于不可运行的状态,就把状态改为可以运行。
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
repeat:
current->state = TASK_INTERRUPTIBLE;
schedule();
if (*p && *p != current) {
(**p).state=0;
goto repeat;
}
*p = NULL;
if (tmp)
tmp->state=0;
}
interruptible_sleep_on 函数的参数也是各种等待队列的地址。同样,参数不能为空,当前任务不能是任务0。
我们把当前任务加入到等待队列中,将其状态设置为不可运行,接着切换任务。
等待队列被唤醒的时候,会运行到第14行代码处,如果等待队列中还有任务,而且这个任务不是当前任务,将该等待任务置为就绪状态,并重新执行调度程序。当 *p 执行的不是当前任务时,表示在当前任务被放入队列后,又有新的任务被插入等待队列中,因此,就应该将所有其它等待任务也置为可运行态。
若 p 为空或 p 是当前任务,就把 *p 设置为空。若任务仍处于不可运行状态,就把任务设置为可运行态。
void wake_up(struct task_struct **p)
{
if (p && *p) {
(**p).state = 0;
// *p = NULL;
}
}
唤醒操作很简单,如果 p 和 *p 都不为空就把任务的状态设置为可运行态。一般这个函数的参数也是等待队列,会把等待队列设置为空。但之后要用这个函数做测试,就注释了第5行。
有些任务并不会一直执行,比如,你编写了一个打印 Hello World 的程序,将它编译成可执行文件,当执行这个文件时就会新建一个任务,而当它结束运行时,系统会结束这个任务,回收资源。
结束任务的函数是一个系统调用。
// sched.h
#define __NR_exit 1
// sys.h
extern int sys_exit();
fn_ptr sys_call_table[72] = {0, sys_exit, sys_fork, sys_print, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_pause};
// exit.c
int do_exit(long code)
{
free_page_tables(get_base(current->ldt[1]), get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]), get_limit(0x17));
current->state = TASK_ZOMBIE;
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}
int sys_exit(int error_code)
{
return do_exit((error_code & 0xff) << 8);
}
系统调用直接调用 do_exit,主要的工作将在这个函数中进行。
首先会释放任务的页表以及页表中页表项对应的页面。接着更改任务的状态,让任务不可执行。再设置任务的退出码。
static void tell_father(int pid)
{
int i;
if (pid)
for (i = 0; i < NR_TASKS; i++) {
if (!task[i])
continue;
if (task[i]->pid != pid)
continue;
return;
}
printk("BAD BAD - no father found\n\r");
release(current);
}
tell_father 这个函数原本是子进程向父进程发送信号,让父进程处理子进程的资源。但是,我们现在的系统并没有关于信号的部分,所以这个函数就相当于废了大半。现在,这个函数检查父进程是否存在,不存在或是父进程是任务0的话就释放任务结构体所在的页面,然后进行任务调度。如果任务数组中找不到当前任务,那肯定是出错了。
void release(struct task_struct *p)
{
int i;
if (!p)
return;
for (i = 1; i < NR_TASKS; i++)
if (task[i] == p) {
task[i] = NULL;
free_page((long)p);
schedule();
return;
}
panic("trying to release non-existent task");
}
写完了内核态的处理函数,现在再写用户态的调用函数。
#define __LIBRARY__
#include 很简单的代码,相信不用我多说了。
好了,修改一下 main.c,看看程序的效果。
void init2(void)
{
int i = 0;
while (1) {
if (i == 5)
_exit(0);
print();
for (int i = 0; i < 20000000; i++)
nop();
i++;
}
}
任务2在打印3次后陷入睡眠,之后屏幕上只会出现任务1的打印信息。在总共打印10次后,任务2被唤醒,屏幕又显示任务2的信息。任务2又打印3次后被结束,之后不会再出现任务2的信息。

Perfect!确实只打印了6次任务2的信息。任务2被睡眠,唤醒,结束的操作都正常运行。请注意,这里的 sleep_on 和 wake_up 是不应该直接对 task 的成员进行操作的,此处只是为了做演示而已。
另外,我们不妨再改动一些代码吧。
// traps.c
#define _fs() ({ \
register unsigned short __res; \
__asm__("mov %%fs,%%ax":"=a" (__res):); \
__res;})
static void die(char *str, long esp_ptr, long nr)
{
long *esp = (long *) esp_ptr;
int i;
printk("%s: %04x\n\r",str, nr & 0xffff);
printk("EIP:\t%04x:%p\n\rEFLAGS:\t%p\n\rESP:\t%04x:%p\n\r",
esp[1], esp[0], esp[2], esp[4], esp[3]);
printk("fs: %04x\n\r", _fs());
printk("base: %p, limit: %p\n\r", get_base(current->ldt[1]), get_limit(0x17));
str(i);
printk("Pid: %d, process nr: %d\n\r", current->pid, 0xffff & i);
do_exit(11);
}
die 函数是大多数异常会执行的函数。我们让它打印更多的信息,并且最后会退出当前任务(之前让任务执行死循环是很浪费系统资源的)。
11.协处理器
这一节的内容不算重要,不想看也可以跳过。
首先我们需要定义这么一个变量:
// sched.c
struct task_struct *last_task_used_math = NULL;
last_task_used_math 代表了上一个使用过数学协处理器的任务的指针,对应使用过协处理器的任务,我们需要对它进行一些特别的处理。
另外,我们还需要添加一个结构体 i387_struct,这个结构体用于保存协处理器的信息,以免任务调度破坏现场。
// sched.h
struct i387_struct {
long cwd; // 控制字
long swd; // 状态字
long twd; // 标记字
long fip; // 协处理器代码指针
long fcs; // 协处理器代码段寄存器
long foo; // 内存操作数的偏移值
long fos; // 内存操作数的段值
long st_space[20]; // 8个10字节的协处理器累加器
};
struct tss_struct {
...
long trace_bitmap; /* bits: trace 0, bitmap 16-31 */
struct i387_struct i387;
};
现在,要对之前的代码进行补全。
// sched.h
#define INIT_TASK \
/* state etc */ { 0, 15, 15, \
/* signal... */ 0, {{},}, 0, \
/* ec,brk... */ 0, 0, 0, 0, 0, 0, \
/* pid etc.. */ 0, -1, 0, 0, 0, \
/* uid etc */ 0, 0, 0, 0, 0, 0, \
/* alarm */ 0, 0, 0, 0, 0, 0, \
/* math */ 0, \
/* tty etc */ -1, 0022,0, \
{ \
{0, 0}, \
/* ldt */ {0x9f, 0xc0fa00}, \
{0x9f, 0xc0f200}, \
}, \
/*tss*/ {0, PAGE_SIZE + (long)&init_task, 0x10, 0, 0, 0, 0, (long)&pg_dir,\
0, 0, 0, 0, 0, 0, 0, 0, \
0, 0, 0x17, 0x17, 0x17, 0x17, 0x17, 0x17, \
_LDT(0), 0x80000000, \
{} \
}, \
}
对于第一个任务的设置,我们只需添加第20行的空括号即可。
// fork.c
int copy_process(int nr, long ebp, long edi, long esi, long gs,
long none, long ebx, long ecx, long edx,
long fs, long es, long ds, long eip,
long cs, long eflags, long esp, long ss)
...
p->tss.ldt = _LDT(nr); // 新任务的局部描述符表选择符
p->tss.trace_bitmap = 0x80000000;
if (last_task_used_math == current)
__asm__("clts\n\tfnsave %0"::"m"(p->tss.i387));
if (copy_mem(nr, p)) {
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
...
}
在拷贝任务时,如果当前任务使用过协处理器,那么将 CR0 中的 TS 位置零(clts),因为当 TS = 1 时,是无法使用协处理器的。fnsave用于将全部的机器状态存储到内存中。
// exit.c
int do_exit(long code)
{
free_page_tables(get_base(current->ldt[1]), get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]), get_limit(0x17));
if (last_task_used_math == current)
last_task_used_math = NULL;
current->state = TASK_ZOMBIE;
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}
在结束任务的过程中,如果被结束的任务使用过协处理器,将 last_task_used_math 设置为空。
// sched.h
#define switch_to(n) {\
struct {long a, b;} __tmp; \
__asm__("cmpl %%ecx, current\n\t" \
"je 1f\n\t" \
"movw %%dx, %1\n\t" \
"xchgl %%ecx, current\n\t" \
"ljmp *%0\n\t" \
"cmpl %%ecx, last_task_used_math\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
::"m"(*&__tmp.a), "m"(*&__tmp.b), \
"d"(_TSS(n)), "c"((long) task[n])); \
}
当原本的任务重新获得执行权后,会从第9行开始运行,检查之前的任务是否使用过协处理器,如果使用过,就跳转到下面的1标记处;如果没有就清除 CR0 的 TS 标志,让 CPU 能够使用协处理器。
接下来要设置协处理器相关的中断和异常,不然如果协处理器触发中断或异常,而我们没有中断处理函数,又会触发double fault。
先是浮点处理错误。
# system_call.s
.align 4
coprocessor_error:
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
pushl %ebx
pushl %eax
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
movl $0x17,%eax
mov %ax,%fs
pushl $ret_from_sys_call
jmp math_error
在把寄存器入栈,改变段寄存器后,将 ret_from_sys_call 入栈作为返回地址,然后跳转到 math_error。
// math_emulate.c
void math_error(void)
{
__asm__("fnclex");
}
这个函数会执行汇编指令fnclex,它会清除协处理器的所有异常标志,忙标志等。
然后是协处理器中断。
# asm.s
irq13:
pushl %eax
xorb %al, %al
outb %al, $0xF0
movb $0x20, %al
outb %al, $0x20
jmp 1f
1: jmp 1f
1: outb %al, $0xA0
popl %eax
jmp coprocessor_error
协处理器在执行计算时,CPU 会等待其操作的完成。而我们通过第4行代码,消除 CPU 的 BUSY 信号,确保在继续执行协处理器的任何指令之前,响应本中断。第5-6行我们已经在时钟中断中见过,这是向8259主芯片发送中断结束信号。延时一段时间,我们再向8259从芯片发送中断结束信号。
为什么要发送两次终端结束信号?协处理器中断连接8259从芯片,而8259从芯片连接在8259主芯片的 IRQ2 上,所以当协处理器发生中断时,8259主从芯片都会产生中断响应,我们就需要向两个芯片都发送中断结束信号。
中断处理的最后跳转到协处理器异常处理函数。
最后是设备不可用的异常。
# system_call.s
.align 4
device_not_available:
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
pushl %ebx
pushl %eax
movl $0x10, %eax
mov %ax, %ds
mov %ax, %es
movl $0x17, %eax
mov %ax, %fs
pushl $ret_from_sys_call
clts
movl %cr0, %eax
testl $0x4, %eax # 检查EM位
je math_state_restore
pushl %ebp
pushl %esi
pushl %edi
call math_emulate
popl %edi
popl %esi
popl %ebp
ret
还是一堆入栈指令和改变段寄存器的指令。clts清除 CR0 的 TS 位,让 CPU 可以使用协处理器。第18-19行代码检查 CR0 的 EM 位,当 EM = 0 时,CPU 可以使用协处理器,程序会跳转到 math_state_restore,否则继续执行下面的指令。最后的ret会跳转到 ret_from_sys_call。
// sched.c
void math_state_restore()
{
if (last_task_used_math == current)
return;
__asm__("fwait");
if (last_task_used_math) {
__asm__("fnsave %0"::"m"(last_task_used_math->tss.i387));
}
last_task_used_math = current;
if (current->used_math) {
__asm__("frstor %0"::"m"(current->tss.i387));
} else {
__asm__("fninit"::);
current->used_math = 1;
}
}
如果任务没有发生变化,就直接返回。在发送协处理器命令之前要先发fwait指令。如果有别的任务使用过协处理器,就把协处理器的信息保存下来。将 last_task_used_math 设置为当前任务。如果当前任务使用过协处理器,就恢复其状态;如果没有使用过,就向协处理器发送初始化命令,并设置使用了协处理器的标志。
// setgment.h
static inline unsigned char get_fs_byte(const char * addr)
{
unsigned register char _v;
__asm__ ("movb %%fs:%1,%0":"=r"(_v):"m"(*addr));
return _v;
}
// math_emulate.c
void math_emulate(long edi, long esi, long ebp, long sys_call_ret,
long eax,long ebx,long ecx,long edx,
unsigned short fs,unsigned short es,unsigned short ds,
unsigned long eip,unsigned short cs,unsigned long eflags,
unsigned short ss, unsigned long esp)
{
unsigned char first, second;
if (cs != 0x000F) {
printk("math_emulate: %04x:%08x\n\r", cs, eip);
panic("Math emulation needed in kernel");
}
first = get_fs_byte((char *)((*&eip)++));
second = get_fs_byte((char *)((*&eip)++));
printk("%04x:%08x %02x %02x\n\r", cs, eip - 2, first, second);
}
又是老长的参数。。。第9行判断是在核心态还是在用户态触发异常,如果是在核心态,就报错死循环;如果是在用户态,就打印异常发生地址和下一条指令。为什么要用 get_fs_byte 函数获取数据呢?直接通过地址获取不行吗?在进入异常时,我们把 fs 设置为用户数据段,而且上面 eip 是用户数据段中的地址,所以需要用到 get_fs_byte 函数。
本节最后,我们还需要在 traps.c 中把中断异常处理函数设置到 idt 中。
// traps.c
void device_not_available(void);
void coprocessor_error(void);
void irq13(void);
void trap_init(void)
{
...
set_trap_gate(7, &device_not_available);
...
set_trap_gate(16, &coprocessor_error);
...
set_trap_gate(45, &irq13);
outb_p(inb_p(0x21) & 0xfb, 0x21);
outb(inb_p(0xA1) & 0xdf, 0xA1);
}
第13-14用于打开协处理器中断,之后就可以接收到接处理器的中断了。
不知道你注意到没有,其实我们并没有对协处理器做什么实际的处理,无非保存、恢复状态,清除异常标志等。那是因为 linux0.11 代码中本来就没有完整实现协处理器的仿真处理。对于没有协处理器的计算机,当使用了协处理器,就会触发异常。
12.信号
我们的任务管理程序已经完美了吗?如果我是读者,我肯定心中嘀咕:我怎么知道。确实!不过,大家可以看看任务结构体,还有不少成员我们还没有使用过,有些与任务管理无关,还有些与任务管理密切相关,比如 signal。
// sched.c
#define _S(nr) (1 << ((nr) - 1))
#define _BLOCKABLE (~(_S(SIGKILL) | _S(SIGSTOP)))
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
for(p = &LAST_TASK ; p > &FIRST_TASK; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1 << (SIGALRM - 1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
...
switch_to(next);
}
第9-18行代码是关于信号的设置。
我们要遍历所有任务,查看任务是否设置过 alarm 且已经过 alarm 时间,如果是就设置信号位图的 SIGALRM 信号,然后清零 alarm。
_BLOCKABLE & (*p)->blocked)代表不被允许响应的信号,按位取反后就代表可以被响应的信号。_BLOCKABLE代表 SIGKILL 和 SIGSTOP 信号必须要被响应。如果任务有可以响应的信号而且任务处于可中断状态,那么就把任务设置为可执行状态。
// exit.c
int do_exit(long code)
{
int i;
free_page_tables(get_base(current->ldt[1]), get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]), get_limit(0x17));
for (i = 0; i < NR_TASKS; i++)
if (task[i] && task[i]->father == current->pid) {
task[i]->father = 1;
if (task[i]->state == TASK_ZOMBIE)
(void) send_sig(SIGCHLD, task[1], 1);
}
if (last_task_used_math == current)
last_task_used_math = NULL;
current->state = TASK_ZOMBIE;
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1);
}
第7-12行用于查找当前任务是否有子进程,如果有就把它的父进程设置为 task[1],如果该子进程正处于僵死状态,还需要向 task[1] 发送 SIGCHLD 信号(子进程停止或结束)。
// kernel.h
#define suser() (current->euid == 0)
// exit.c
static inline int send_sig(long sig, struct task_struct * p, int priv)
{
if (!p || sig < 1 || sig > 32)
return -EINVAL;
if (priv || (current->euid == p->euid) || suser())
p->signal |= (1 << (sig - 1));
else
return -EPERM;
return 0;
}
如果参数不合法,就返回错误。然后检查是否有权限或有效用户 id 是否相等或是否为超级用户,如果是就设置信号,否则返回错误号。
// exit.c
static void tell_father(int pid)
{
int i;
if (pid)
for (i = 0; i < NR_TASKS; i++) {
if (!task[i])
continue;
if (task[i]->pid != pid)
continue;
task[i]->signal |= (1 << (SIGCHLD - 1));
return;
}
printk("BAD BAD - no father found\n\r");
release(current);
}
这个函数用于子进程结束时向父进程发送信号,这里添加第12行代码,用于向父进程发送子进程结束的信号。
我们发送了信号,那信号在哪里进行处理呢?
# system_call.s
state = 0 # 相对于任务结构体的偏移
counter = 4
priority = 8
signal = 12
sigaction = 16
blocked = (33 * 16)
.align 4
system_call:
...
ret_from_sys_call:
movl current, %eax # task[0]不能有信号
cmpl task, %eax
je 3f
cmpw $0x0f, CS(%esp) # 之前是在系统代码段吗?
jne 3f
cmpw $0x17, OLDSS(%esp) # 栈段是0x17吗?
jne 3f
movl signal(%eax), %ebx
movl blocked(%eax), %ecx
notl %ecx
andl %ebx, %ecx
bsfl %ecx, %ecx
je 3f
btrl %ecx, %ebx
movl %ebx, signal(%eax)
incl %ecx
pushl %ecx
call do_signal
popl %eax
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
第3-8行的变量代表该成员在任务结构体中的偏移。
第14-16行检查正在运行的任务是否是任务0,如果是就跳转到下面的3标记。第17-20行检查之前是否是处于用户态,不是就跳转到下面的3标记。因为一些中断异常也会运行到这里,所以有了这一步检查步骤。
第21-26行检查任务中是否有信号,如果没有,ecx 为0,跳转到下面的3标记;如果有,ecx 为 signal 中第一个含1的位的位号。bsfl会从低位开始扫描 ecx,看是否有1的位,若有就在 ecx 中保存该位的位号。
第27行将信号复位。第28行保存 signal 信息到当前任务的 signal 成员中。第29行调整信号值,ecx 的值的范围是0-31,而信号值的范围是1-32。
将 ecx 入栈作为 do_signal 的参数。
// signal.h
#define SIG_IGN ((void (*)(int))1) // 忽略信号
// signal.c
void do_signal(long signr,long eax, long ebx, long ecx, long edx,
long fs, long es, long ds,
long eip, long cs, long eflags,
unsigned long *esp, long ss)
{
unsigned long sa_handler;
long old_eip = eip;
struct sigaction *sa = current->sigaction + signr - 1;
int longs;
unsigned long *tmp_esp;
sa_handler = (unsigned long) sa->sa_handler;
if (sa_handler == 1)
return;
if (!sa_handler) {
if (signr == SIGCHLD)
return;
else
do_exit(1 << (signr - 1));
}
if (sa->sa_flags & SA_ONESHOT) // 如果只需要处理一次
sa->sa_handler = NULL;
*(&eip) = sa_handler;
longs = (sa->sa_flags & SA_NOMASK) ? 7 : 8;
*(&esp) -= longs;
verify_area(esp, longs * 4);
tmp_esp = esp;
put_fs_long((long) sa->sa_restorer, tmp_esp++);
put_fs_long(signr, tmp_esp++);
if (!(sa->sa_flags & SA_NOMASK))
put_fs_long(current->blocked, tmp_esp++);
put_fs_long(eax, tmp_esp++);
put_fs_long(ecx, tmp_esp++);
put_fs_long(edx, tmp_esp++);
put_fs_long(eflags, tmp_esp++);
put_fs_long(old_eip, tmp_esp++);
current->blocked |= sa->sa_mask;
}
每个任务结构体都有32个 struct sigaction 成员,每个 struct sigaction 成员有一种信号的处理函数。
我们可以通过信号值获得相对应的 struct sigaction(第12行)。用 sa_handler 保存信号的处理函数(第16行)。如果处理函数为1(SIG_IGN),就直接返回。如果没有处理函数,而且信号是 SIGCHLD,就直接返回,否则就退出当前任务。如果该信号只需处理一次,那么就把信号的函数指针设置为空。
第27行会设置栈中的 eip 的值设置为信号处理函数,所以中断结束后,会执行信号处理函数。当然,我们在第12行就保存了 eip 的值,不怕找不到回用户态的地址。
我们会把一些寄存器入栈作为参数,longs 就代表了参数的个数。我们会把 sa_restorer,signr,进程屏蔽码(如果 SA_NOMASK 没置位),eax,ecx,edx,系统调用程序返回地址和标志寄存器入栈,参数个数会因 SA_NOMASK 而发生变化。
verify_area 函数用于校验 esp 地址所在页面是否可写,如果不可写,则复制页面(写时复制)。
之后我们把之前提到的参数放入 esp 的栈中,注意,这里的 esp 是用户栈而不是系统栈。
函数最后设置任务的信号屏蔽码。
// fork.c
void verify_area(void *addr, int size)
{
unsigned long start;
start = (unsigned long) addr;
size += start & 0xfff;
start &= 0xfffff000; // 进程空间中的线性地址
start += get_base(current->ldt[2]); // 系统整个线性空间中的地址
while (size > 0) {
size -= 4096;
write_verify(start);
start += 4096;
}
}
在这个函数中,我们需要验证 [addr, addr + size] 这段空间是否可写,如果不可写,说明任务还没从父进程那里把页面复制过来。
我们需要获得地址所在页面的起始地址,并得到它在整个线性空间中的地址,需要验证的空间可能覆盖不只一个页面,我们要对每个页面都进行验证,如果没有写权限,就复制页面。
// memory.c
void write_verify(unsigned long address)
{
unsigned long page;
if (!((page = *((unsigned long *) ((address >> 20) & 0xffc))) & 1)) // 页面是否存在
return;
page &= 0xfffff000;
page += ((address >> 10) & 0xffc);
if ((3 & *(unsigned long *) page) == 1) // 如果没有写权限
un_wp_page((unsigned long *) page);
return;
}
我们首先要通过页目录项判断页表是否存在,不存在就直接返回。然后找到页面对应的页表项,如果没有写权限,就执行 un_wp_page 函数。还记得 un_wp_page 函数吗?我们在第8节中讲解过它。当发生页错误时也会调用这个函数复制页面。
本章到此结束。本来还想写 signal 系统调用,这样就可以看看效果了,不过,本章的内容是在太多了,不想再添加内容了。
下一章是终端,我们要完善输入和显示。