一、 介绍
Epoll 是一种高效的管理socket的模型,相对于select和poll来说具有更高的效率和易用性。传统的select以及poll的效率会因为 socket数量的线形递增而导致呈二次乃至三次方的下降,而epoll的性能不会随socket数量增加而下降。标准的linux-2.4.20内核不支持epoll,需要打patch。本文主要从linux-2.4.32和linux-2.6.10两个内核版本介绍epoll。
二、 Epoll的使用
epoll用到的所有函数都是在头文件sys/epoll.h中声明的,下面简要说明所用到的数据结构和函数:
所用到的数据结构
Linux下的I/O复用与epoll详解
-
前言
I/O多路复用有很多种实现。在linux上,2.4内核前主要是select和poll,自Linux 2.6内核正式引入epoll以来,epoll已经成为了目前实现高性能网络服务器的必备技术。尽管他们的使用方法不尽相同,但是本质上却没有什么区别。本文将重点探讨将放在EPOLL的实现与使用详解。
为什么会是EPOLL
select的缺陷
高并发的核心解决方案是1个线程处理所有连接的“等待消息准备好”,这一点上epoll和select是无争议的。但select预估错误了一件事,当数十万并发连接存在时,可能每一毫秒只有数百个活跃的连接,同时其余数十万连接在这一毫秒是非活跃的。select的使用方法是这样的: 返回的活跃连接 ==select(全部待监控的连接)。 什么时候会调用select方法呢?在你认为需要找出有报文到达的活跃连接时,就应该调用。所以,调用select在高并发时是会被频繁调用的。这样,这个频繁调用的方法就很有必要看看它是否有效率,因为,它的轻微效率损失都会被“频繁”二字所放大。它有效率损失吗?显而易见,全部待监控连接是数以十万计的,返回的只是数百个活跃连接,这本身就是无效率的表现。被放大后就会发现,处理并发上万个连接时,select就完全力不从心了。 此外,在Linux内核中,select所用到的FD_SET是有限的,即内核中有个参数__FD_SETSIZE定义了每个FD_SET的句柄个数。
View Code 其次,内核中实现 select是用轮询方法,即每次检测都会遍历所有FD_SET中的句柄,显然,select函数执行时间与FD_SET中的句柄个数有一个比例关系,即 select要检测的句柄数越多就会越费时。看到这里,您可能要要问了,你为什么不提poll?笔者认为select与poll在内部机制方面并没有太大的差异。相比于select机制,poll只是取消了最大监控文件描述符数限制,并没有从根本上解决select存在的问题。 接下来我们看张图,当并发连接为较小时,select与epoll似乎并无多少差距。可是当并发连接上来以后,select就显得力不从心了。1.1/linux/posix_types.h:2.23.3#define __FD_SETSIZE1024图 1.主流I/O复用机制的benchmark

epoll高效的奥秘
epoll精巧的使用了3个方法来实现select方法要做的事:
新建epoll描述符==epoll_create() epoll_ctrl(epoll描述符,添加或者删除所有待监控的连接) 返回的活跃连接 ==epoll_wait( epoll描述符 ) 与select相比,epoll分清了频繁调用和不频繁调用的操作。例如,epoll_ctrl是不太频繁调用的,而epoll_wait是非常频繁调用的。这时,epoll_wait却几乎没有入参,这比select的效率高出一大截,而且,它也不会随着并发连接的增加使得入参越发多起来,导致内核执行效率下降。 笔者在这里不想过多贴出epoll的代码片段。如果大家有兴趣,可以参考文末贴出的博文链接和Linux相关源码。要深刻理解epoll,首先得了解epoll的三大关键要素:mmap、红黑树、链表。
epoll是通过内核与用户空间mmap同一块内存实现的。mmap将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址(不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理地址),使得这块物理内存对内核和对用户均可见,减少用户态和内核态之间的数据交换。
epoll上就是相当减少了epoll监听的句柄从用户态copy到内核态,内核可以直接看到epoll监听的句柄,效率高。
红黑树将存储epoll所监听的套接字。上面mmap出来的内存如何保存epoll所监听的套接字,必然也得有一套数据结构,epoll在实现上采用红黑树去存储所有套接字,当添加或者删除一个套接字时(epoll_ctl),都在红黑树上去处理,红黑树本身插入和删除性能比较好,时间复杂度O(lgN)。

下面几个关键数据结构的定义
01.1struct epitem02.2{03.3struct rb_node rbn;//用于主结构管理的红黑树04.4struct list_head rdllink;//事件就绪队列05.5struct epitem *next;//用于主结构体中的链表06.6struct epoll_filefd ffd;//每个fd生成的一个结构07.7intnwait;08.8struct list_head pwqlist;//poll等待队列09.9struct eventpoll *ep;//该项属于哪个主结构体10.10struct list_head fllink;//链接fd对应的file链表11.11struct epoll_event event;//注册的感兴趣的事件,也就是用户空间的epoll_event12.12}01.1struct eventpoll02.2{03.3spin_lock_t lock;//对本数据结构的访问04.4struct mutex mtx;//防止使用时被删除05.5wait_queue_head_t wq;//sys_epoll_wait() 使用的等待队列06.6wait_queue_head_t poll_wait;//file->poll()使用的等待队列07.7struct list_head rdllist;//事件满足条件的链表08.8struct rb_root rbr;//用于管理所有fd的红黑树09.9struct epitem *ovflist;//将事件到达的fd进行链接起来发送至用户空间10.10}
添加以及返回事件
通过epoll_ctl函数添加进来的事件都会被放在红黑树的某个节点内,所以,重复添加是没有用的。当把事件添加进来的时候时候会完成关键的一步,那就是该事件都会与相应的设备(网卡)驱动程序建立回调关系,当相应的事件发生后,就会调用这个回调函数,该回调函数在内核中被称为:ep_poll_callback,这个回调函数其实就所把这个事件添加到rdlist这个双向链表中。一旦有事件发生,epoll就会将该事件添加到双向链表中。那么当我们调用epoll_wait时,epoll_wait只需要检查rdlist双向链表中是否有存在注册的事件,效率非常可观。这里也需要将发生了的事件复制到用户态内存中即可。
epoll_wait的工作流程:
epoll_wait调用ep_poll,当rdlist为空(无就绪fd)时挂起当前进程,直到rdlist不空时进程才被唤醒。 文件fd状态改变(buffer由不可读变为可读或由不可写变为可写),导致相应fd上的回调函数ep_poll_callback()被调用。 ep_poll_callback将相应fd对应epitem加入rdlist,导致rdlist不空,进程被唤醒,epoll_wait得以继续执行。 ep_events_transfer函数将rdlist中的epitem拷贝到txlist中,并将rdlist清空。 ep_send_events函数(很关键),它扫描txlist中的每个epitem,调用其关联fd对用的poll方法。此时对poll的调用仅仅是取得fd上较新的events(防止之前events被更新),之后将取得的events和相应的fd发送到用户空间(封装在struct epoll_event,从epoll_wait返回)。小结
表 1. select、poll和epoll三种I/O复用模式的比较( 摘录自《linux高性能服务器编程》)
系统调用
select
poll
epoll
事件集合
用哦过户通过3个参数分别传入感兴趣的可读,可写及异常等事件
内核通过对这些参数的在线修改来反馈其中的就绪事件
这使得用户每次调用select都要重置这3个参数
统一处理所有事件类型,因此只需要一个事件集参数。
用户通过pollfd.events传入感兴趣的事件,内核通过
修改pollfd.revents反馈其中就绪的事件
内核通过一个事件表直接管理用户感兴趣的所有事件。
因此每次调用epoll_wait时,无需反复传入用户感兴趣
的事件。epoll_wait系统调用的参数events仅用来反馈就绪的事件
应用程序索引就绪文件
描述符的时间复杂度
O(n)
O(n)
O(1)
最大支持文件描述符数
一般有最大值限制
65535
65535
工作模式
LT
LT
支持ET高效模式
内核实现和工作效率
采用轮询方式检测就绪事件,时间复杂度:O(n)
采用轮询方式检测就绪事件,时间复杂度:O(n)
采用回调方式检测就绪事件,时间复杂度:O(1)
行文至此,想必各位都应该已经明了为什么epoll会成为Linux平台下实现高性能网络服务器的首选I/O复用调用。
需要注意的是:epoll并不是在所有的应用场景都会比select和poll高很多。尤其是当活动连接比较多的时候,回调函数被触发得过于频繁的时候,epoll的效率也会受到显著影响!所以,epoll特别适用于连接数量多,但活动连接较少的情况。
接下来,笔者将介绍一下epoll使用方式的注意点。
EPOLL的使用
文件描述符的创建
1.1#include2.2intepoll_create (intsize );
在epoll早期的实现中,对于监控文件描述符的组织并不是使用红黑树,而是hash表。这里的size实际上已经没有意义。
注册监控事件
函数说明: fd:要操作的文件描述符 op:指定操作类型 操作类型: EPOLL_CTL_ADD:往事件表中注册fd上的事件 EPOLL_CTL_MOD:修改fd上的注册事件 EPOLL_CTL_DEL:删除fd上的注册事件 event:指定事件,它是epoll_event结构指针类型 epoll_event定义:1.1#include2.2intepoll_ctl (intepfd,intop,intfd, struct epoll_event *event );结构体说明: events:描述事件类型,和poll支持的事件类型基本相同(两个额外的事件:EPOLLET和EPOLLONESHOT,高效运作的关键) data成员:存储用户数据1.1struct epoll_event2.2{3.3__unit32_t events;// epoll事件4.4epoll_data_t data;// 用户数据5.5};1.1typedef union epoll_data2.2{3.3void* ptr;//指定与fd相关的用户数据4.4intfd;//指定事件所从属的目标文件描述符5.5uint32_t u32;6.6uint64_t u64;7.7} epoll_data_t;
epoll_wait函数
View Code 函数说明: 返回:成功时返回就绪的文件描述符的个数,失败时返回-1并设置errno timeout:指定epoll的超时时间,单位是毫秒。当timeout为-1是,epoll_wait调用将永远阻塞,直到某个时间发生。当timeout为0时,epoll_wait调用将立即返回。 maxevents:指定最多监听多少个事件 events:检测到事件,将所有就绪的事件从内核事件表中复制到它的第二个参数events指向的数组中。1.1#include2.2intepoll_wait (intepfd, struct epoll_event* events,intmaxevents,inttimeout );EPOLLONESHOT事件
使用场合: 一个线程在读取完某个socket上的数据后开始处理这些数据,而数据的处理过程中该socket又有新数据可读,此时另外一个线程被唤醒来读取这些新的数据。 于是,就出现了两个线程同时操作一个socket的局面。可以使用epoll的EPOLLONESHOT事件实现一个socket连接在任一时刻都被一个线程处理。 作用: 对于注册了EPOLLONESHOT事件的文件描述符,操作系统最多出发其上注册的一个可读,可写或异常事件,且只能触发一次。 使用: 注册了EPOLLONESHOT事件的socket一旦被某个线程处理完毕,该线程就应该立即重置这个socket上的EPOLLONESHOT事件,以确保这个socket下一次可读时,其EPOLLIN事件能被触发,进而让其他工作线程有机会继续处理这个sockt。 效果: 尽管一个socket在不同事件可能被不同的线程处理,但同一时刻肯定只有一个线程在为它服务,这就保证了连接的完整性,从而避免了很多可能的竞态条件。LT与ET模式
在这里,笔者强烈推荐《彻底学会使用epoll》系列博文,这是笔者看过的,对epoll的ET和LT模式讲解最为详尽和易懂的博文。下面的实例均来自该系列博文。限于篇幅原因,很多关键的细节,不能完全摘录。
话不多说,直接上代码。
程序一:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDIN_FILENO;11.11ev.events = EPOLLIN|EPOLLET;//监听读状态同时设置ET模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDIN_FILENO)19.19printf('Something happened with stdin!20.');21.20}22.21}23.22}
编译并运行,结果如下:
当用户输入一组字符,这组字符被送入buffer,字符停留在buffer中,又因为buffer由空变为不空,所以ET返回读就绪,输出”welcome to epoll's world!”。 之后程序再次执行epoll_wait,此时虽然buffer中有内容可读,但是根据我们上节的分析,ET并不返回就绪,导致epoll_wait阻塞。(底层原因是ET下就绪fd的epitem只被放入rdlist一次)。 用户再次输入一组字符,导致buffer中的内容增多,根据我们上节的分析这将导致fd状态的改变,是对应的epitem再次加入rdlist,从而使epoll_wait返回读就绪,再次输出“Welcome to epoll's world!”。
接下来我们将上面程序的第11行做如下修改:
1.1ev.events=EPOLLIN;//默认使用LT模式
编译并运行,结果如下:
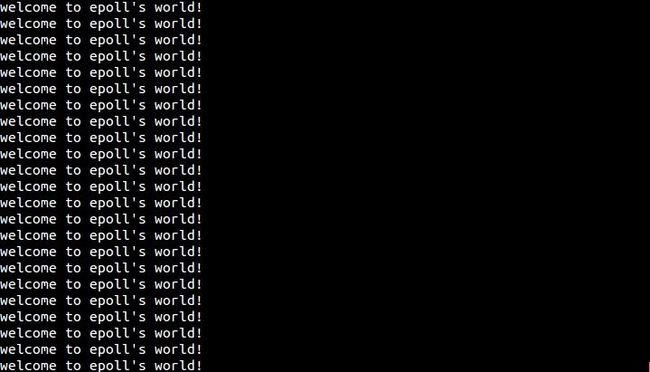
程序陷入死循环,因为用户输入任意数据后,数据被送入buffer且没有被读出,所以LT模式下每次epoll_wait都认为buffer可读返回读就绪。导致每次都会输出”welcome to epoll's world!”。
程序二:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDIN_FILENO;11.11ev.events = EPOLLIN;//监听读状态同时设置LT模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDIN_FILENO)19.19{20.20charbuf[1024] = {0};21.21read(STDIN_FILENO, buf, sizeof(buf));22.22printf('welcome to epoll's"http://www.it165.net/edu/ebg/"target="_blank"class="keylink">word!23.');24.23}25.24}26.25}27.26}
编译并运行,结果如下:

本程序依然使用LT模式,但是每次epoll_wait返回读就绪的时候我们都将buffer(缓冲)中的内容read出来,所以导致buffer再次清空,下次调用epoll_wait就会阻塞。所以能够实现我们所想要的功能——当用户从控制台有任何输入操作时,输出”welcome to epoll's world!”
程序三:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDIN_FILENO;11.11ev.events = EPOLLIN|EPOLLET;//监听读状态同时设置ET模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDIN_FILENO)19.19{20.20printf('welcome to epoll's"http://www.it165.net/edu/ebg/"target="_blank"class="keylink">word!21.');22.21ev.data.fd = STDIN_FILENO;23.22ev.events = EPOLLIN|EPOLLET;//设置ET模式24.23epoll_ctl(epfd, EPOLL_CTL_MOD, STDIN_FILENO, &ev);//重置epoll事件(ADD无效)25.24}26.25}27.26}28.27}
编译并运行,结果如下:

程序依然使用ET,但是每次读就绪后都主动的再次MOD IN事件,我们发现程序再次出现死循环,也就是每次返回读就绪。但是注意,如果我们将MOD改为ADD,将不会产生任何影响。别忘了每次ADD一个描述符都会在epitem组成的红黑树中添加一个项,我们之前已经ADD过一次,再次ADD将阻止添加,所以在次调用ADD IN事件不会有任何影响。
程序四:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDOUT_FILENO;11.11ev.events = EPOLLOUT|EPOLLET;//监听读状态同时设置ET模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDOUT_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDOUT_FILENO)19.19{20.20printf('welcome to epoll's word!21.');22.21}23.22}24.23}25.24}
编译并运行,结果如下:

这个程序的功能是只要标准输出写就绪,就输出“welcome to epoll's world”。我们发现这将是一个死循环。下面具体分析一下这个程序的执行过程:
首先初始buffer为空,buffer中有空间可写,这时无论是ET还是LT都会将对应的epitem加入rdlist,导致epoll_wait就返回写就绪。 程序想标准输出输出”welcome to epoll's world”和换行符,因为标准输出为控制台的时候缓冲是“行缓冲”,所以换行符导致buffer中的内容清空,这就对应第二节中ET模式下写就绪的第二种情况——当有旧数据被发送走时,即buffer中待写的内容变少得时候会触发fd状态的改变。所以下次epoll_wait会返回写就绪。如此循环往复。程序五:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDOUT_FILENO;11.11ev.events = EPOLLOUT|EPOLLET;//监听读状态同时设置ET模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDOUT_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDOUT_FILENO)19.19{20.20printf('welcome to epoll's word!');21.21}22.22}23.23}24.24}
编译并运行,结果如下:

与程序四相比,程序五只是将输出语句的printf的换行符移除。我们看到程序成挂起状态。因为第一次epoll_wait返回写就绪后,程序向标准输出的buffer中写入“welcome to epoll's world!”,但是因为没有输出换行,所以buffer中的内容一直存在,下次epoll_wait的时候,虽然有写空间但是ET模式下不再返回写就绪。回忆第一节关于ET的实现,这种情况原因就是第一次buffer为空,导致epitem加入rdlist,返回一次就绪后移除此epitem,之后虽然buffer仍然可写,但是由于对应epitem已经不再rdlist中,就不会对其就绪fd的events的在检测了。
程序六:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDOUT_FILENO;11.11ev.events = EPOLLOUT;//监听读状态同时设置LT模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDOUT_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDOUT_FILENO)19.19{20.20printf('welcome to epoll's word!');21.21}22.22}23.23}24.24}
编译并运行,结果如下:

程序六相对程序五仅仅是修改ET模式为默认的LT模式,我们发现程序再次死循环。这时候原因已经很清楚了,因为当向buffer写入”welcome to epoll's world!”后,虽然buffer没有输出清空,但是LT模式下只有buffer有写空间就返回写就绪,所以会一直输出”welcome to epoll's world!”,当buffer满的时候,buffer会自动刷清输出,同样会造成epoll_wait返回写就绪。
程序七:
01.1#include02.2#include03.3#include04.405.5intmain(void)06.6{07.7intepfd,nfds;08.8struct epoll_event ev,events[5];//ev用于注册事件,数组用于返回要处理的事件09.9epfd = epoll_create(1);//只需要监听一个描述符——标准输入10.10ev.data.fd = STDOUT_FILENO;11.11ev.events = EPOLLOUT|EPOLLET;//监听读状态同时设置LT模式12.12epoll_ctl(epfd, EPOLL_CTL_ADD, STDOUT_FILENO, &ev);//注册epoll事件13.13for(;;)14.14{15.15nfds = epoll_wait(epfd, events,5, -1);16.16for(inti =0; i < nfds; i++)17.17{18.18if(events[i].data.fd==STDOUT_FILENO)19.19{20.20printf('welcome to epoll's word!');21.21ev.data.fd = STDOUT_FILENO;22.22ev.events = EPOLLOUT|EPOLLET;//设置ET模式23.23epoll_ctl(epfd, EPOLL_CTL_MOD, STDOUT_FILENO, &ev);//重置epoll事件(ADD无效)24.24}25.25}26.26}27.27}
编译并运行,结果如下:

程序七相对于程序五在每次向标准输出的buffer输出”welcome to epoll's world!”后,重新MOD OUT事件。所以相当于每次都会返回就绪,导致程序循环输出。
经过前面的案例分析,我们已经了解到,当epoll工作在ET模式下时,对于读操作,如果read一次没有读尽buffer中的数据,那么下次将得不到读就绪的通知,造成buffer中已有的数据无机会读出,除非有新的数据再次到达。对于写操作,主要是因为ET模式下fd通常为非阻塞造成的一个问题——如何保证将用户要求写的数据写完。
要解决上述两个ET模式下的读写问题,我们必须实现:
对于读,只要buffer中还有数据就一直读; 对于写,只要buffer还有空间且用户请求写的数据还未写完,就一直写。ET模式下的accept问题
请思考以下一种场景:在某一时刻,有多个连接同时到达,服务器的 TCP 就绪队列瞬间积累多个就绪连接,由于是边缘触发模式,epoll 只会通知一次,accept 只处理一个连接,导致 TCP 就绪队列中剩下的连接都得不到处理。在这种情形下,我们应该如何有效的处理呢?
解决的方法是:解决办法是用 while 循环抱住 accept 调用,处理完 TCP 就绪队列中的所有连接后再退出循环。如何知道是否处理完就绪队列中的所有连接呢? accept 返回 -1 并且 errno 设置为 EAGAIN 就表示所有连接都处理完。
关于ET的accept问题,这篇博文的参考价值很高,如果有兴趣,可以链接过去围观一下。
ET模式为什么要设置在非阻塞模式下工作
因为ET模式下的读写需要一直读或写直到出错(对于读,当读到的实际字节数小于请求字节数时就可以停止),而如果你的文件描述符如果不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。这样就不能在阻塞在epoll_wait上了,造成其他文件描述符的任务饿死。
epoll的使用实例
这样的实例,网上已经有很多了(包括参考链接),笔者这里就略过了。
小结
LT:水平触发,效率会低于ET触发,尤其在大并发,大流量的情况下。但是LT对代码编写要求比较低,不容易出现问题。LT模式服务编写上的表现是:只要有数据没有被获取,内核就不断通知你,因此不用担心事件丢失的情况。
ET:边缘触发,效率非常高,在并发,大流量的情况下,会比LT少很多epoll的系统调用,因此效率高。但是对编程要求高,需要细致的处理每个请求,否则容易发生丢失事件的情况。
从本质上讲:与LT相比,ET模型是通过减少系统调用来达到提高并行效率的。
总结
epoll使用的梳理与总结到这里就告一段落了。限于篇幅原因,很多细节都被略过了。后面参考给出的链接,强烈推荐阅读。疏谬之处,万望斧正!
-
深入了解epoll 函数
-
- typedef union epoll_data {
- void ptr;
- int fd;
- __uint32_t u32;
- __uint64_t u64;
- } epoll_data_t;
- struct epoll_event {
- __uint32_t events; / Epoll events /
- epoll_data_t data; / User data variable /
- };
结构体epoll_event 被用于注册所感兴趣的事件和回传所发生待处理的事件,其中epoll_data 联合体用来保存触发事件的某个文件描述符相关的数据,例如一个client连接到服务器,服务器通过调用accept函数可以得到于这个client对应的socket文件描述符,可以把这文件描述符赋给epoll_data的fd字段以便后面的读写操作在这个文件描述符上进行。epoll_event 结构体的events字段是表示感兴趣的事件和被触发的事件可能的取值为:EPOLLIN :表示对应的文件描述符可以读;
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET:表示对应的文件描述符设定为edge模式;
所用到的函数:
1、epoll_create函数
函数声明:int epoll_create(int size)
该函数生成一个epoll专用的文件描述符,其中的参数是指定生成描述符的最大范围。在linux-2.4.32内核中根据size大小初始化哈希表的大小,在linux2.6.10内核中该参数无用,使用红黑树管理所有的文件描述符,而不是hash。
2、epoll_ctl函数
函数声明:int epoll_ctl(int epfd, int op, int fd, struct epoll_event event)
该函数用于控制某个文件描述符上的事件,可以注册事件,修改事件,删除事件。
参数:epfd:由 epoll_create 生成的epoll专用的文件描述符;
op:要进行的操作例如注册事件,可能的取值
EPOLL_CTL_ADD 注册、
EPOLL_CTL_MOD 修改、
EPOLL_CTL_DEL 删除
fd:关联的文件描述符;
event:指向epoll_event的指针;
如果调用成功返回0,不成功返回-1
3、epoll_wait函数
函数声明:int epoll_wait(int epfd,struct epoll_event events,int maxevents,int timeout)
该函数用于轮询I/O事件的发生;
参数:
epfd:由epoll_create 生成的epoll专用的文件描述符;
epoll_event:用于回传代处理事件的数组;
maxevents:每次能处理的事件数;
timeout:等待I/O事件发生的超时值(ms);-1永不超时,直到有事件产生才触发,0立即返回。
返回发生事件数。-1有错误。
举一个简单的例子:- main()
- {
- //声明epoll_event结构体的变量,ev用于注册事件,数组用于回传要处理的事件
- struct epoll_event ev,events[20];
- epfd=epoll_create(10000); //创建epoll句柄
- listenfd = socket(AF_INET, SOCK_STREAM, 0);
- //把socket设置为非阻塞方式
- setnonblocking(listenfd);
- bzero(&serveraddr, sizeof(serveraddr));
- serveraddr.sin_family = AF_INET;
- serveraddr.sin_addr.s_addr = INADDR_ANY;
- serveraddr.sin_port=htons(SERV_PORT);
- bind(listenfd,(struct sockaddr )&serveraddr, sizeof(serveraddr));
- listen(listenfd, 255);
- //设置与要处理的事件相关的文件描述符
- ev.data.fd=listenfd;
- //设置要处理的事件类型
- ev.events=EPOLLIN;
- //注册epoll事件
- epoll_ctl(epfd,EPOLL_CTL_ADD,listenfd,&ev);
- for ( ; ; ){
- //等待epoll事件的发生
- nfds=epoll_wait(epfd,events,20,1000);
- //处理所发生的所有事件
- for(i=0;i
- if(events .data.fd==listenfd){
- connfd = accept(listenfd,(struct sockaddr )&clientaddr, &clilen);
- if(connfd<0){
- perror("connfd<0");
- }
- setnonblocking(connfd);
- //设置用于读操作的文件描述符
- ev.data.fd=connfd;
- //设置用于注测的读操作事件
- ev.events=EPOLLIN|EPOLLET;
- //注册event
- epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev);
- }else if(events .events&EPOLLIN){
- read_socket(events .data.fd);
- ev.data.fd=events .data.fd;
- ev.events=EPOLLIN|EPOLLOUT|EPOLLET;
- epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);
- }else if(events .events&EPOLLOUT){
- write_socket(events .data.fd);
- ev.data.fd=events .data.fd;
- ev.events=EPOLLIN|EPOLLET; //ET模式
- epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);
- }else{
- perror("other event");
- }
- }
- }
- }
Epoll的ET模式与LT模式
ET(Edge Triggered)与LT(Level Triggered)的主要区别可以从下面的例子看出
eg:
1. 标示管道读者的文件句柄注册到epoll中;
2. 管道写者向管道中写入2KB的数据;
3. 调用epoll_wait可以获得管道读者为已就绪的文件句柄;
4. 管道读者读取1KB的数据
5. 一次epoll_wait调用完成
如果是ET模式,管道中剩余的1KB被挂起,再次调用epoll_wait,得不到管道读者的文件句柄,除非有新的数据写入管道。如果是LT模式,只要管道中有数据可读,每次调用epoll_wait都会触发。
另一点区别就是设为ET模式的文件句柄必须是非阻塞的。
三、 Epoll的实现
Epoll 的源文件在/usr/src/linux/fs/eventpoll.c,在module_init时注册一个文件系统 eventpoll_fs_type,对该文件系统提供两种操作poll和release,所以epoll_create返回的文件句柄可以被poll、 select或者被其它epoll epoll_wait。对epoll的操作主要通过三个系统调用实现:
1. sys_epoll_create
2. sys_epoll_ctl
3. sys_epoll_wait
下面结合源码讲述这三个系统调用。
1.1 long sys_epoll_create (int size)
该系统调用主要分配文件句柄、inode以及file结构。在linux-2.4.32内核中,使用hash保存所有注册到该epoll的文件句柄,在该系统调用中根据size大小分配hash的大小。具体为不小于size,但小于2size的2的某次方。最小为2的9次方(512),最大为2的17次方(128 x 1024)。在linux-2.6.10内核中,使用红黑树保存所有注册到该epoll的文件句柄,size参数未使用。
1.2 long sys_epoll_ctl(int epfd, int op, int fd, struct epoll_event event)
1. 注册句柄 op = EPOLL_CTL_ADD
注册过程主要包括:
A.将fd插入到hash(或rbtree)中,如果原来已经存在返回-EEXIST,
B.给fd注册一个回调函数,该函数会在fd有事件时调用,在该函数中将fd加入到epoll的就绪队列中。
C.检查fd当前是否已经有期望的事件产生。如果有,将其加入到epoll的就绪队列中,唤醒epoll_wait。
2. 修改事件 op = EPOLL_CTL_MOD
修改事件只是将新的事件替换旧的事件,然后检查fd是否有期望的事件。如果有,将其加入到epoll的就绪队列中,唤醒epoll_wait。
3. 删除句柄 op = EPOLL_CTL_DEL
将fd从hash(rbtree)中清除。
1.3 long sys_epoll_wait(int epfd, struct epoll_event events, int maxevents,int timeout)
如果epoll的就绪队列为空,并且timeout非0,挂起当前进程,引起CPU调度。
如果epoll的就绪队列不空,遍历就绪队列。对队列中的每一个节点,获取该文件已触发的事件,判断其中是否有我们期待的事件,如果有,将其对应的epoll_event结构copy到用户events。
revents = epi->file->f_op->poll(epi->file, NULL);
epi->revents = revents & epi->event.events;
if (epi->revents) {
……
copy_to_user;
……
}
需要注意的是,在LT模式下,把符合条件的事件copy到用户空间后,还会把对应的文件重新挂接到就绪队列。所以在LT模式下,如果一次epoll_wait某个socket没有read/write完所有数据,下次epoll_wait还会返回该socket句柄。
四、 使用epoll的注意事项
1. ET模式比LT模式高效,但比较难控制。
2. 如果某个句柄期待的事件不变,不需要EPOLL_CTL_MOD,但每次读写后将该句柄modify一次有助于提高稳定性,特别在ET模式。
3. socket关闭后最好将该句柄从epoll中delete(EPOLL_CTL_DEL),虽然epoll自身有处理,但会使epoll的hash的节点数增多,影响搜索hash的速度。
Q:网络服务器的瓶颈在哪?
A:IO效率。
在大家苦苦的为在线人数的增长而导致的系统资源吃紧上的问题正在发愁的时候,Linux 2.6内核中提供的System Epoll为我们提供了一套完美的解决方案。传统的select以及poll的效率会因为在线人数的线形递增而导致呈二次乃至三次方的下降,这些直接导致了网络服务器可以支持的人数有了个比较明显的限制。
自从Linux提供了/dev/epoll的设备以及后来2.6内核中对/dev /epoll设备的访问的封装(System Epoll)之后,这种现象得到了大大的缓解,如果说几个月前,大家还对epoll不熟悉,那么现在来说的话,epoll的应用已经得到了大范围的普及。
那么究竟如何来使用epoll呢?其实非常简单。
通过在包含一个头文件#include 以及几个简单的API将可以大大的提高你的网络服务器的支持人数。
首先通过create_epoll(int maxfds)来创建一个epoll的句柄,其中maxfds为你epoll所支持的最大句柄数。这个函数会返回一个新的epoll句柄,之后的所有操作将通过这个句柄来进行操作。在用完之后,记得用close()来关闭这个创建出来的epoll句柄。
之后在你的网络主循环里面,每一帧的调用epoll_wait(int epfd, epoll_event events, int max events, int timeout)来查询所有的网络接口,看哪一个可以读,哪一个可以写了。基本的语法为:
nfds = epoll_wait(kdpfd, events, maxevents, -1);
其中kdpfd为用epoll_create创建之后的句柄,events是一个epoll_event的指针,当epoll_wait这个函数操作成功之后,epoll_events里面将储存所有的读写事件。max_events是当前需要监听的所有socket句柄数。最后一个timeout是 epoll_wait的超时,为0的时候表示马上返回,为-1的时候表示一直等下去,直到有事件范围,为任意正整数的时候表示等这么长的时间,如果一直没有事件,则范围。一般如果网络主循环是单独的线程的话,可以用-1来等,这样可以保证一些效率,如果是和主逻辑在同一个线程的话,则可以用0来保证主循环的效率。
epoll_wait范围之后应该是一个循环,遍利所有的事件:- for(n = 0; n < nfds; ++n) {
- if(events[n].data.fd == listener) { //如果是主socket的事件的话,则表示有新连接进入了,进行新连接的处理。
- client = accept(listener, (struct sockaddr ) &local,&addrlen);
- if(client < 0){
- perror("accept");
- continue;
- }
- setnonblocking(client); // 将新连接置于非阻塞模式
- ev.events = EPOLLIN | EPOLLET; // 并且将新连接也加入EPOLL的监听队列。
- /*
- 注意,这里的参数EPOLLIN | EPOLLET并没有设置对写socket的监听,\
- 如果有写操作的话,这个时候epoll是不会返回事件的,如果要对写操作也监听的话,应该是EPOLLIN | EPOLLOUT | EPOLLET
- */
- ev.data.fd = client;
- if (epoll_ctl(kdpfd, EPOLL_CTL_ADD, client, &ev) < 0) {
- /*
- 设置好event之后,将这个新的event通过epoll_ctl加入到epoll的监听队列里面,\
- 这里用EPOLL_CTL_ADD来加一个新的 epoll事件,通过EPOLL_CTL_DEL来减少一个epoll事件,\
- 通过EPOLL_CTL_MOD来改变一个事件的监听方式。
- */
- fprintf(stderr, "epoll set insertion error: fd=d0,client);
- return -1;
- }
- }else{
- /*
- 如果不是主socket的事件的话,则代表是一个用户socket的事件,则来处理这个用户socket的事情,\
- 比如说read(fd,xxx)之类的,或者一些其他的处理。
- */
- do_use_fd(events[n].data.fd);
- }
- }
对,epoll的操作就这么简单,总共不过4个API:epoll_create, epoll_ctl, epoll_wait和close。Linux 2.6内核中提高网络I/O性能的新方法
1、为什么select是落后的?
首先,在Linux内核中,select所用到的FD_SET是有限的,即内核中有个参数__FD_SETSIZE定义了每个FD_SET的句柄个数,在我用的2.6.15-25-386内核中,该值是1024,搜索内核源代码得到:
include/linux/posix_types.h:#define __FD_SETSIZE 1024
也就是说,如果想要同时检测1025个句柄的可读状态是不可能用select实现的。或者同时检测1025个句柄的可写状态也是不可能的。
其次,内核中实现select是用轮询方法,即每次检测都会遍历所有FD_SET中的句柄,显然,select函数执行时间与FD_SET中的句柄个数有一个比例关系,即select要检测的句柄数越多就会越费时。
当然,在前文中我并没有提及poll方法,事实上用select的朋友一定也试过poll,我个人觉得select和poll大同小异,个人偏好于用select而已。
2、2.6内核中提高I/O性能的新方法epoll
epoll是什么?按照man手册的说法:是为处理大批量句柄而作了改进的poll。要使用epoll只需要这三个系统调用:epoll_create(2), epoll_ctl(2), epoll_wait(2)。
当然,这不是2.6内核才有的,它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux kernel 2.5.44)
epoll的优点
<1>支持一个进程打开大数目的socket描述符(FD)
select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是2048。对于那些需要支持的上万连接数目的IM服务器来说显然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的 Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。不过 epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
<2>IO效率不随FD数目增加而线性下降
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是"活跃"的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个"伪"AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的---比如一个高速LAN环境,epoll并不比select/poll有什么效率,相反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
<3>使用mmap加速内核与用户空间的消息传递。
这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。而如果你想我一样从2.5内核就关注epoll的话,一定不会忘记手工 mmap这一步的。
<4>内核微调
这一点其实不算epoll的优点了,而是整个linux平台的优点。也许你可以怀疑linux平台,但是你无法回避linux平台赋予你微调内核的能力。比如,内核TCP/IP协议栈使用内存池管理sk_buff结构,那么可以在运行时期动态调整这个内存pool(skb_head_pool)的大小 --- 通过echo XXXX>/proc/sys/net/core/hot_list_length完成。再比如listen函数的第2个参数(TCP完成3次握手的数据包队列长度),也可以根据你平台内存大小动态调整。更甚至在一个数据包面数目巨大但同时每个数据包本身大小却很小的特殊系统上尝试最新的NAPI网卡驱动架构。
epoll的使用
令人高兴的是,2.6内核的epoll比其2.5开发版本的/dev/epoll简洁了许多,所以,大部分情况下,强大的东西往往是简单的。唯一有点麻烦是epoll有2种工作方式:LT和ET。
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表.
ET (edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once),不过在TCP协议中,ET模式的加速效用仍需要更多的benchmark确认。
epoll只有epoll_create,epoll_ctl,epoll_wait 3个系统调用,具体用法请参考http://www.xmailserver.org/linux-patches/nio-improve.html ,
在http://www.kegel.com/rn/也有一个完整的例子,大家一看就知道如何使用了
Leader/follower模式线程pool实现,以及和epoll的配合在Linux上开发网络服务器的一些相关细节:poll与epoll
随着2.6内核对epoll的完全支持,网络上很多的文章和示例代码都提供了这样一个信息:使用epoll代替传统的 poll能给网络服务应用带来性能上的提升。但大多文章里关于性能提升的原因解释的较少,这里我将试分析一下内核(2.6.21.1)代码中poll与 epoll的工作原理,然后再通过一些测试数据来对比具体效果。 POLL:
先说poll,poll或select为大部分Unix/Linux程序员所熟悉,这俩个东西原理类似,性能上也不存在明显差异,但select对所监控的文件描述符数量有限制,所以这里选用poll做说明。
poll是一个系统调用,其内核入口函数为sys_poll,sys_poll几乎不做任何处理直接调用do_sys_poll,do_sys_poll的执行过程可以分为三个部分:
1,将用户传入的pollfd数组拷贝到内核空间,因为拷贝操作和数组长度相关,时间上这是一个O(n)操作,这一步的代码在do_sys_poll中包括从函数开始到调用do_poll前的部分。
2,查询每个文件描述符对应设备的状态,如果该设备尚未就绪,则在该设备的等待队列中加入一项并继续查询下一设备的状态。查询完所有设备后如果没有一个设备就绪,这时则需要挂起当前进程等待,直到设备就绪或者超时,挂起操作是通过调用schedule_timeout执行的。设备就绪后进程被通知继续运行,这时再次遍历所有设备,以查找就绪设备。这一步因为两次遍历所有设备,时间复杂度也是O(n),这里面不包括等待时间。相关代码在do_poll函数中。
3,将获得的数据传送到用户空间并执行释放内存和剥离等待队列等善后工作,向用户空间拷贝数据与剥离等待队列等操作的的时间复杂度同样是O(n),具体代码包括do_sys_poll函数中调用do_poll后到结束的部分。
EPOLL:
接下来分析epoll,与poll/select不同,epoll不再是一个单独的系统调用,而是由epoll_create/epoll_ctl/epoll_wait三个系统调用组成,后面将会看到这样做的好处。
先来看sys_epoll_create(epoll_create对应的内核函数),这个函数主要是做一些准备工作,比如创建数据结构,初始化数据并最终返回一个文件描述符(表示新创建的虚拟epoll文件),这个操作可以认为是一个固定时间的操作。
epoll是做为一个虚拟文件系统来实现的,这样做至少有以下两个好处:
1,可以在内核里维护一些信息,这些信息在多次epoll_wait间是保持的,比如所有受监控的文件描述符。
2, epoll本身也可以被poll/epoll;
具体epoll的虚拟文件系统的实现和性能分析无关,不再赘述。
在sys_epoll_create中还能看到一个细节,就是epoll_create的参数size在现阶段是没有意义的,只要大于零就行。
接着是sys_epoll_ctl(epoll_ctl对应的内核函数),需要明确的是每次调用sys_epoll_ctl只处理一个文件描述符,这里主要描述当op为EPOLL_CTL_ADD时的执行过程,sys_epoll_ctl做一些安全性检查后进入ep_insert,ep_insert里将 ep_poll_callback做为回掉函数加入设备的等待队列(假定这时设备尚未就绪),由于每次poll_ctl只操作一个文件描述符,因此也可以认为这是一个O(1)操作
ep_poll_callback函数很关键,它在所等待的设备就绪后被系统回掉,执行两个操作:
1,将就绪设备加入就绪队列,这一步避免了像poll那样在设备就绪后再次轮询所有设备找就绪者,降低了时间复杂度,由O(n)到O(1);
2,唤醒虚拟的epoll文件;
最后是sys_epoll_wait,这里实际执行操作的是ep_poll函数。该函数等待将进程自身插入虚拟epoll文件的等待队列,直到被唤醒(见上面ep_poll_callback函数描述),最后执行ep_events_transfer将结果拷贝到用户空间。由于只拷贝就绪设备信息,所以这里的拷贝是一个O(1)操作。
还有一个让人关心的问题就是epoll对EPOLLET的处理,即边沿触发的处理,粗略看代码就是把一部分水平触发模式下内核做的工作交给用户来处理,直觉上不会对性能有太大影响,感兴趣的朋友欢迎讨论。
POLL/EPOLL对比:
表面上poll的过程可以看作是由一次epoll_create/若干次epoll_ctl/一次epoll_wait/一次close等系统调用构成,实际上epoll将poll分成若干部分实现的原因正是因为服务器软件中使用poll的特点(比如Web服务器):
1,需要同时poll大量文件描述符;
2,每次poll完成后就绪的文件描述符只占所有被poll的描述符的很少一部分。
3,前后多次poll调用对文件描述符数组(ufds)的修改只是很小;
传统的poll函数相当于每次调用都重起炉灶,从用户空间完整读入ufds,完成后再次完全拷贝到用户空间,另外每次poll都需要对所有设备做至少做一次加入和删除等待队列操作,这些都是低效的原因。
epoll将以上情况都细化考虑,不需要每次都完整读入输出ufds,只需使用epoll_ctl调整其中一小部分,不需要每次epoll_wait都执行一次加入删除等待队列操作,另外改进后的机制使的不必在某个设备就绪后搜索整个设备数组进行查找,这些都能提高效率。另外最明显的一点,从用户的使用来说,使用epoll不必每次都轮询所有返回结果已找出其中的就绪部分,O(n)变O(1),对性能也提高不少。
此外这里还发现一点,是不是将epoll_ctl改成一次可以处理多个fd(像semctl那样)会提高些许性能呢?特别是在假设系统调用比较耗时的基础上。不过关于系统调用的耗时问题还会在以后分析。POLL/EPOLL测试数据对比:
测试的环境:我写了三段代码来分别模拟服务器,活动的客户端,僵死的客户端,服务器运行于一个自编译的标准2.6.11内核系统上,硬件为 PIII933,两个客户端各自运行在另外的PC上,这两台PC比服务器的硬件性能要好,主要是保证能轻易让服务器满载,三台机器间使用一个100M交换机连接。
服务器接受并poll所有连接,如果有request到达则回复一个response,然后继续poll。
活动的客户端(Active Client)模拟若干并发的活动连接,这些连接不间断的发送请求接受回复。
僵死的客户端(zombie)模拟一些只连接但不发送请求的客户端,其目的只是占用服务器的poll描述符资源。
测试过程:保持10个并发活动连接,不断的调整僵并发连接数,记录在不同比例下使用poll与epoll的性能差别。僵死并发连接数根据比例分别是:0,10,20,40,80,160,320,640,1280,2560,5120,10240。
下图中横轴表示僵死并发连接与活动并发连接之比,纵轴表示完成40000次请求回复所花费的时间,以秒为单位。红色线条表示poll数据,绿色表示 epoll数据。可以看出,poll在所监控的文件描述符数量增加时,其耗时呈线性增长,而epoll则维持了一个平稳的状态,几乎不受描述符个数影响。
在监控的所有客户端都是活动时,poll的效率会略高于epoll(主要在原点附近,即僵死并发连接为0时,图上不易看出来),究竟epoll实现比poll复杂,监控少量描述符并非它的长处。