redis 内存不足 排查_Redis——内存占用优化
# 1.优化内存占用
了解redis的内存模型,对优化redis内存占用有很大帮助。下面介绍几种优化场景。
- 1)利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
- 2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
- 3)共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整``REDIS_SHARED_INTEGERS``参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
- 4)避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
# 2.关注内存碎片率
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
# 3.内存增长排查
## 3.1 Redis内存分析
### 3.1.1 内存组成
```bash
redis> info memory
"# Memory
used_memory:29020136
used_memory_human:27.68M
used_memory_rss:15560704
used_memory_peak:45295152
used_memory_peak_human:43.20M
used_memory_lua:36864
mem_fragmentation_ratio:0.54
mem_allocator:jemalloc-3.6.0
"
```
属性名属性说明
used_memory Redis 分配器分配的内存量,也就是实际存储数据的内存总量used_memory_human 以可读格式返回 Redis 使用的内存总量used_memory_rss 从操作系统的角度,Redis进程占用的总物理内存used_memory_peak 内存分配器分配的最大内存,代表used_memory的历史峰值used_memory_peak_human 以可读的格式显示内存消耗峰值used_memory_lua Lua引擎所消耗的内存mem_fragmentation_ratio used_memory_rss /used_memory比值,表示内存碎片率mem_allocator Redis 所使用的内存分配器。默认: jemalloc---
计算公式如下:
```
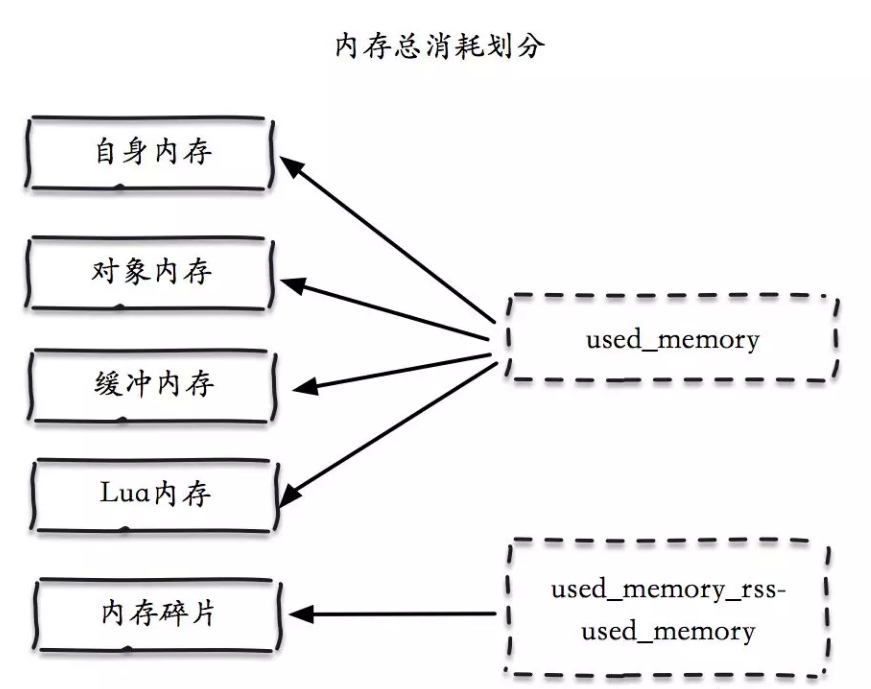
used_memory = 自身内存+对象内存+缓冲内存+lua内存
used_rss = used_memory + 内存碎片
```
如下图所示:
### 3.1.2 内存分析
- 1) 自身内存:一个空的Redis占用很小,可以忽略不计
- 2) kv内存:key对象 + value对象
- 3) 缓冲区:客户端缓冲区(普通 + slave伪装 + pubsub)以及aof缓冲区(比较固定,一般没问题)
- 4) Lua:Lua引擎所消耗的内存
### 3.1.3. 内存突增常见问题
- 1) kv内存:bigkey、大量写入
- 2) 客户端缓冲区:一般常见的有普通客户端缓冲区(例如monitor命令)或者pubsub客户端缓冲区
## 3.2 可能出现的问题排查
- 1) bigkey?
> redis --bigkeys:可以对redis整个 keyspace 进行统计(数据量大时采样,调用 scan 命令),寻找每种数据类型较大的 keys,给出数据统计
``redis-cli --bigkeys -i 0.1 -h 127.0.0.1``
- 2) 键值个数增加?
- 3) 客户端缓冲区
> 如果是因为缓冲区问题,会从``info clients``找到明显问题。重点观察是否明显的``omem``大于0的情况。
- 4) Redis的kv哈希表做了 rehash
## 3.4 rehash
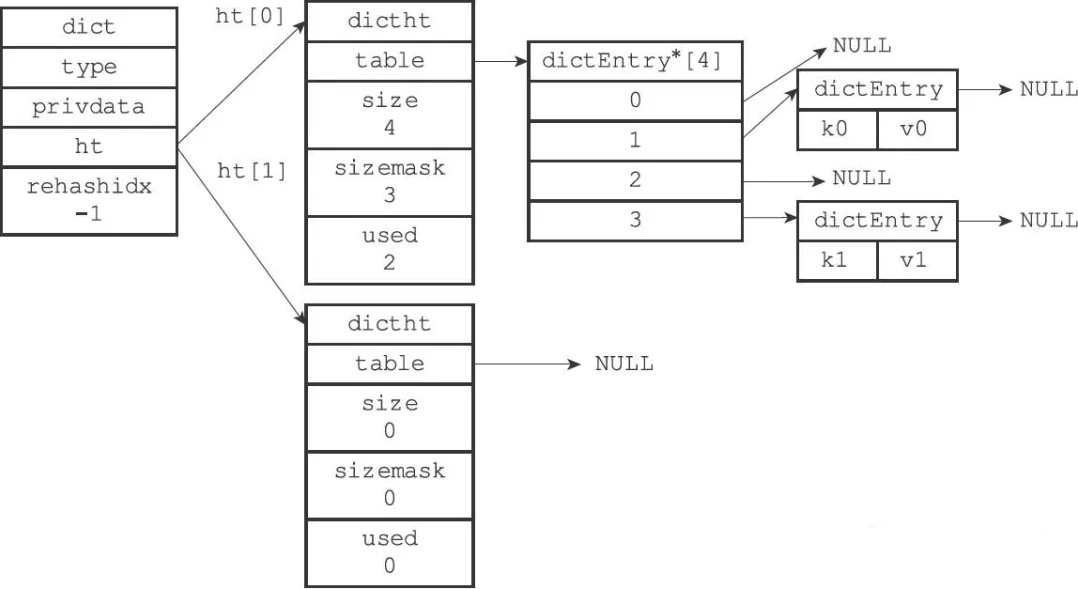
### 3.4.1 Redis的kv存储结构
如下图所示,Redis的所有kv保存在dict中,其中ht对应两个哈希表ht[0]和ht[1],平时一个空闲,一个用于存储数据,只有当需要rehash时,ht[1]才会用到。
### 3.4.2 Redis的字典rehash
为了保证哈希表的负载,当哈希表的元素个数等于哈希表槽数时候,会进行rehash扩容。扩容后h[1]的容量等于第一个大于等于ht[0].size*2的2n,例如hash表的初始化容量是4,那么下一次扩容就是8,以此类推。
## 3.5 总结
由于哈希表的特性,Redis 中键值数量大,不会对存取造成性能影响,但是会出现内存增长的情况。
控制键个数有几个建议:
- 无用的键值设置过期时间或者定期删除
- 优化键值设计:例如可以使用 ziplist hash合并优化部分字符串类型。-
- 未来改进:内核层面支持 rehash 的审计日志以及增强 rehash 的速度
参考:
[精讲Redis内存模型](https://my.oschina.net/u/3779583/blog/1829617)
[一次 Redis 内存诡异增长的排查过程](https://mp.weixin.qq.com/s/eXKkfhdG8VyS9OmKZOkeEw)