关于图像分割的预处理 transform
目录
1. 介绍
2. 关于分割中的 resize 问题
3. 分割的 transform
3.1 随机缩放 RandomResize
3.2 随机水平翻转 RandomHorizontalFlip
3.3 随机竖直翻转 RandomVerticalFlip
3.4 中心裁剪 RandomCrop
3.5 ToTensor
3.6 normalization
3.7 Compose
4. 预处理结果可视化
1. 介绍
图像分割的预处理不像分类那样好操作,因为分类的label就是一个类别,图像增强的操作都是对原始图像操作的。
图像分割的label和img是严格对应的,或者说两者的空间分辨率(h*w)一样且像素点的对应位置都不能改变。否则,监督学习就失去了作用。而深度学习中,数据增强是不必可少的,对于数据更少的医学图像来说,数据增强更加必不可少。
所以,本章主要聊聊 图像分割中的数据增强
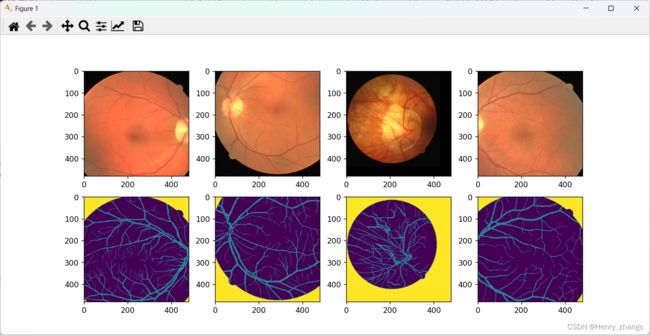
下面是DRIVE数据集的预处理可视化:
2. 关于分割中的 resize 问题
图像分割的resize问题,本人一直没有弄明白....
分割最后的目的应该是将前景从图像中口出来,那么两者的尺寸肯定需要保证一样的。然而,例如unet一类的网络输入都是固定大小480*480,那么最后分割的分辨率也就是480*480,显然已经和最原始的图像不一样了
现在不管是分类,还是分割网络的输入都不需要和原论文一致了,网络里面都做了优化,例如最大池化层等等....
不管网络如何优化,大部分预处理中都增加了resize的操作。那么能保证输入图像和输出的分辨率一样,但是最原始的图像还是不能一致。例如,原始512*512,resize 480*480 输入给网络产生 480*480 的分割图像,480和512已经不一样了
虽然最后分割出来的图像也可以通过resize还原成最原始的尺寸。但是插值又成了问题,更好的线性插值会导致分割图像的灰度值改变。例如分割的图是二值图像,背景为0前景为255,通过插值会导致出现0-255的任何一个数字,变成了灰度图像。当然最近邻插值可以避免这一问题,但最近邻插值显然在图像处理中不是一个好的选择。
之前想过,用双线性插值resize分割图像,然后利用阈值处理产生二值图。但是,这样的方法不仅仅麻烦,还有很多的问题,且违背了end to end的思想
下面纯个人瞎想...仅供参考...
所以说,解决的办法就是训练的图像随机的resize,例如需要给网络的输入是480*480,那么随机将训练图像变成缩放成例如300-500之之间任意的大小,再裁剪成480*480输入给分割网络
这样的好处就是,网络就不会对单纯的图像缩放敏感
那么,再随机分割的时候,就不需要resize,直接输入原图就行了
3. 分割的 transform
如下,分割任务中图像预处理的测试代码
其中就只要保证img和label是同时变换即可

3.1 随机缩放 RandomResize
如下,在给定的min和max直接随机生成一个整数,然后resize即可。
分割的label图像要采用最近邻算法,否则resize之后的label就不是二值图像
class RandomResize(object):
def __init__(self, min_size, max_size=None):
self.min_size = min_size
if max_size is None:
max_size = min_size
self.max_size = max_size
def __call__(self, image, target):
size = random.randint(self.min_size, self.max_size)
# 这里size传入的是int类型,所以是将图像的最小边长缩放到size大小
image = F.resize(image, size)
target = F.resize(target, size, interpolation=T.InterpolationMode.NEAREST)
return image, target
3.2 随机水平翻转 RandomHorizontalFlip
flip_prob 就是翻转的概率
class RandomHorizontalFlip(object):
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = F.hflip(image)
target = F.hflip(target)
return image, target
3.3 随机竖直翻转 RandomVerticalFlip
和水平翻转的一样
class RandomVerticalFlip(object):
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = F.vflip(image)
target = F.vflip(target)
return image, target
3.4 中心裁剪 RandomCrop
中心裁剪的代码如下,需要注意的是,因为图像很可能不足裁剪的大小,所以需要填充
class RandomCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = pad_if_smaller(image, self.size)
target = pad_if_smaller(target, self.size, fill=255)
crop_params = T.RandomCrop.get_params(image, (self.size, self.size))
image = F.crop(image, *crop_params)
target = F.crop(target, *crop_params)
return image, target
填充的代码,这里填充255代表不敢兴趣的区域
def pad_if_smaller(img, size, fill=0):
# 如果图像最小边长小于给定size,则用数值fill进行padding
min_size = min(img.size)
if min_size < size:
ow, oh = img.size
padh = size - oh if oh < size else 0
padw = size - ow if ow < size else 0
img = F.pad(img, (0, 0, padw, padh), fill=fill)
return img
3.5 ToTensor
这里label不能进行官方实现的totensor方法,因为归一化,前景像素的灰度值就会被改变
dtype 是因为要使用交叉熵损失,需要为整型,且label的维度中不能有channel
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64)
return image, target
3.6 normalization
normalization 的实现也很简单
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = F.normalize(image, mean=self.mean, std=self.std)
return image, target
3.7 Compose
将transform 逐个实现就行了
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
4. 预处理结果可视化
dataset里面改成这样就行了

加载完数据这样调用即可
![]()
测试代码:
label 中灰度值只有0 1 255
label 中没有 channel
# 可视化数据
def plot(data_loader):
plt.figure(figsize=(12,8))
imgs,labels = data_loader
for i,(x,y) in enumerate(zip(imgs,labels)):
x = np.transpose(x.numpy(),(1,2,0))
x[:,:,0] = x[:,:,0]*0.127 + 0.709 # 去 normalization
x[:,:,1] = x[:,:,1]*0.079 + 0.381
x[:,:,2] = x[:,:,2]*0.043 + 0.224
y = y.numpy()
# print(np.unique(y)) # 0 1 255
# print(x.shape) # 480*480*3
# print(y.shape) # 480*480
plt.subplot(2,4,i+1)
plt.imshow(x)
plt.subplot(2,4,i+5)
plt.imshow(y)
plt.show()
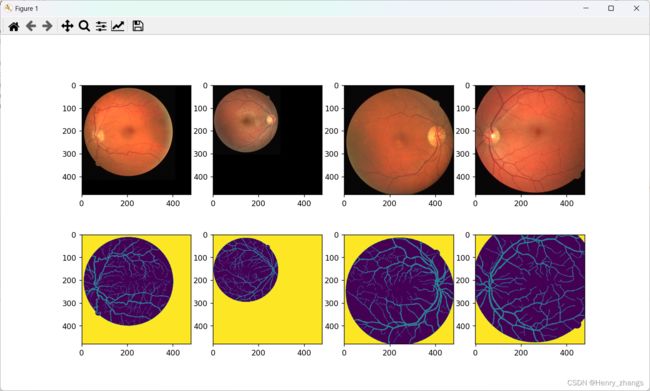
显示结果:
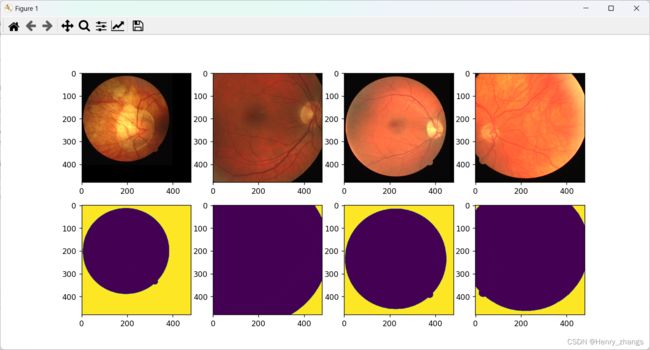
在dataset 里面,将前景像素改成120,就可以看到label的细节