腾讯发布推理框架TNN全平台版本,同时支持移动端、桌面端和服务端
本文转载自腾讯优图。
TNN是腾讯开源的新一代跨平台深度学习推理框架,也是腾讯深度学习与加速Oteam云帆的开源协同成果,由腾讯优图实验室主导,腾讯光影研究室、腾讯云架构平台部、腾讯数据平台部等团队一起协同开发。在经过4个多个月的迭代完善后,TNN新版本v0.3版本正式发布,是首个同时支持移动端、桌面端、服务端的全平台开源版本。TNN新版本在通用性、易用性、性能方面进一步获得提升。
TNN地址:
https://github.com/Tencent/TNN
01
通用性
在保证模型统一、接口统一的前提下,依托于硬件厂商提供的加速框架基础算子支持,以及手写kernel优化的方式,对移动端、桌面端和服务端提供了多种不同加速选择,实现了对常用CV、NLP模型的优化适配。
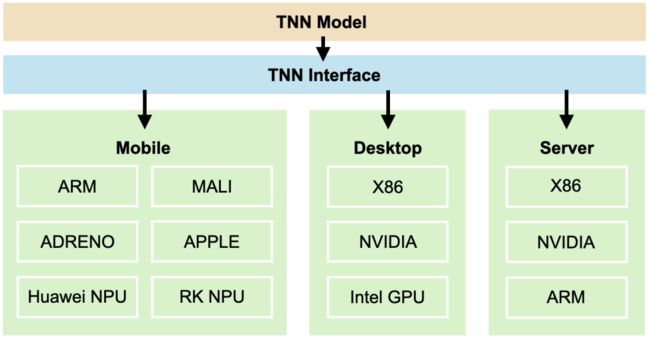
硬件平台支持
TNN通过集成OpenVINO和TensorRT的方式新增了对服务端X86和NVIDIA硬件的支持,既能快速获取硬件厂商的最新优化成果,又能基于业务模型结构特点添加自定义实现达到性能极致。同时考虑到桌面端应用对安装包大小的限制,TNN通过JIT和手工优化的方式实现了轻量级的X86后端,整体库大小仅为5MB左右。
模型算子支持
TNN新版本在CV类模型的支持上扩展了对3D-CNN、LSTM、BERT等模型结构的支持,总算子数从88个增加到107个,新增算子包括LSTM、GridSample、Histogram、OneHot、BitShift、Gather、ScatterND、LayerNorm、GroupNorm、GELU、SoftSign、Erf等。
02
易用性
动态维度和预处理支持
TNN之前版本主要支持CV类模型,网络输入基本都是NCHW4个维度且每个维度上的值基本不变。而NLP场景下同一个网络会有0维到6维的情况,且每个维度上的值根据输入而变化。为此TNN新增了输入维度配置接口, 在模型算子、硬件、系统支持等层面做了大量补充和完善。
API接口对Mat相关接口做了一定扩充,包括拷贝填充功能(CopyMakeBorder),方便SDK开发者进行网络预处理后处理加速。目前TNN已支持裁剪(Crop)、缩放(Resize)、颜色空间转换(CvtColor)、仿射变换(WarpAffine)和拷贝填充(CopyMakeBorder)等常见的预处理后处理操作。
运行时常量折叠
onnx模型导出模型时会产生很多粘合剂类的算子用于计算常量和数据Shape的信息,TNN实现了ConstFolder常量折叠功能来简化模型结构提升模型运行性能。相比开源社区工具onnx-simplifier,ConstFolder增加了对以ATen形式输出的算子的支持,同时支持运行时常量折叠以支持模型变维的需求。TNN运行时将变维计算部分的算子单独抽取出来用NAIVE(纯C++)执行,以减轻各个硬件device(ARM、Metal、OpenCL)的算子实现压力。
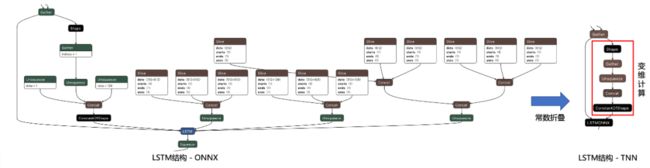
示例展示
在腾讯光影和腾讯光流团队的支持下,头发染色和人体姿态两个TNN示例在TNN中间迭代的小版本中已经发布,并展现出不错的算法效果。这次配合新版本发布,我们添加了移动端中文OCR示例以及桌面端/后台端BERT阅读理解示例。
中文OCR示例采用chineseocr lite模型,展示了如何通过文本框位置检测+文本框角度检测+文字识别3个模型串联来进行中文文字识别;
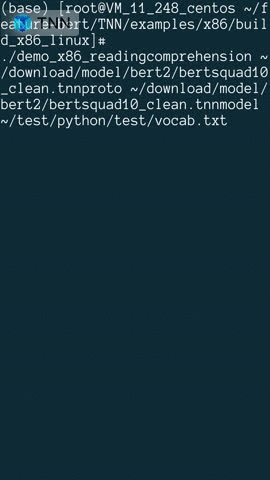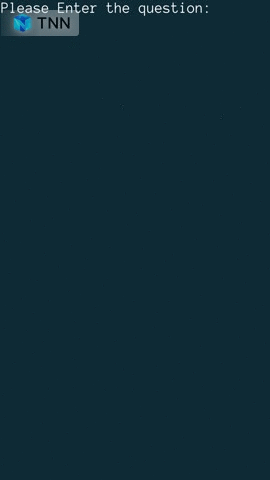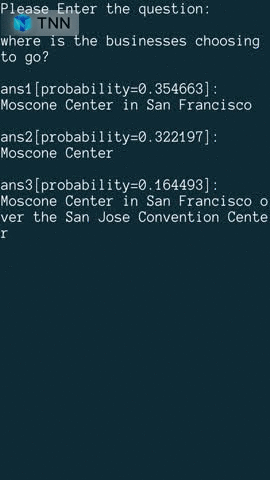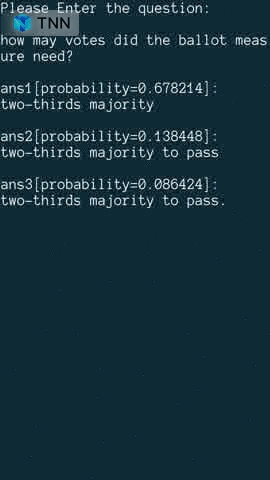
BERT 阅读理解示例采用BERT-Squad10模型,展示了如何通过预先输入上下文以及词汇表来实现一个简单的问答系统。下图依次为头发染色、人体姿态、中文OCR、BERT阅读理解效果展示。

03
性能优化
移动端性能优化
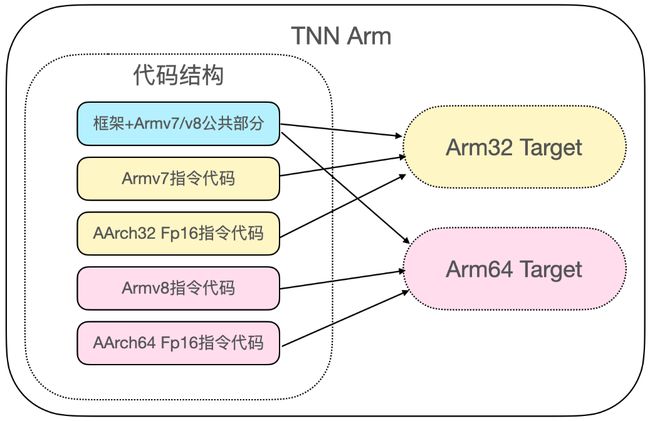
Arm性能优化:
01
armv8.2优化:fp16向量指令优化,相比于fp32预期性能翻倍,除了和大多数开源框架一样支持arm64之外,针对arm32架构也实现了fp16指令优化,让64位和32位APP都能发挥硬件fp16向量加速的能力;
02
int8优化:针对常用的算子block组合采取了更激进一些的融合策略,如conv+add+activation,能有效的减少量化反量化的开销以及内存读写,并且经内部业务验证,在提高性能的同时并不会造成精度的下降
OpenCL性能优化:
01
核心卷积优化:
a. 访存性能优化: Channel Blocking优化、以及局部内存(local memory)优化提升访存性能,实现工作组内的数据共享;
b. 计算性能优化: winograd算法优化3x3卷积, 寻址计算优化,相邻计算网格偏移量共用向量寄存器,降低fp32计算单元压力;
02
工作组尺寸优化: 优化计算策略,并通过Auto-Tuning挑选最优工作组尺寸;
03
预处理/后处理优化: 使用buffer做参数缓存,降低GPU拷贝开销。
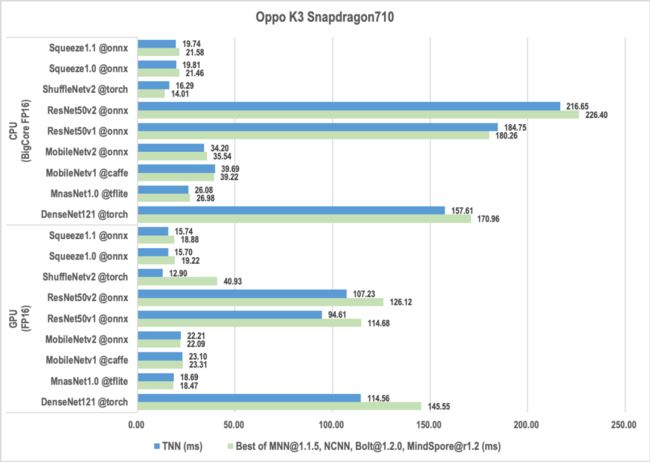

桌面端/服务端性能优化
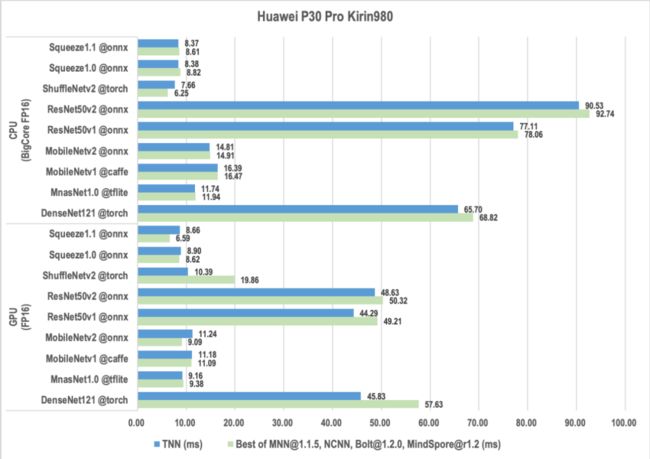
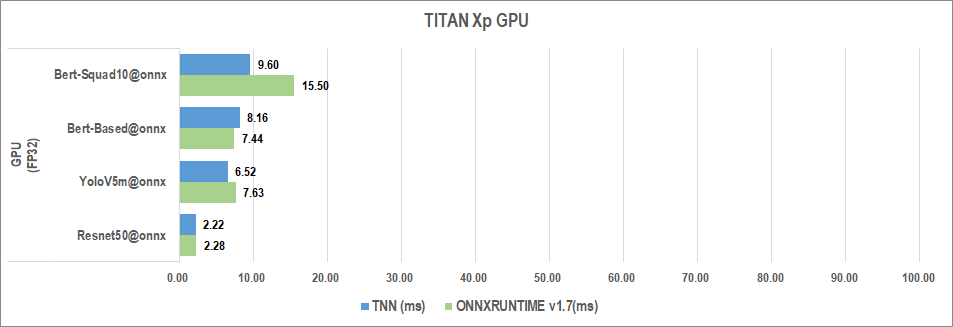
TNN服务端通过集成OpenVINO和TensorRT的方式新增了对服务端X86和NVIDIA硬件的支持,既能快速获取硬件厂商的最新优化成果,又能基于业务模型结构特点添加自定义实现达到性能极致。与业界服务端统一框架onnxruntime性能最好版本相比,TNN当前在CV类模型有一定优势,而onnxruntime在NLP类模型有一定优势。TNN刚开始支持NLP模型,后续会在这块持续优化。
TNN桌面端为了兼顾高性能和硬件兼容性,同时考虑应用App 对安装包大小的限制,通过JIT和手工优化的方式实现了轻量级的X86后端,支持SSE41、SSE42、AVX、AVX2、FMA等指令集。相比onnxruntime服务端库80MB,TNN桌面端整体库大小仅为5MB左右,而性能差距在20%以内。

04
结语
TNN的目标是做一个全平台支持的AI推理框架,在与合作伙伴的协同下会持续输出对各硬件平台(ARM、X86、NVIDIA等)的适配与优化,敬请期待!
点击【阅读原文】,即可获取TNN开源地址。

备注:部署

模型压缩与应用部署交流群
模型压缩、网络压缩、神经网络加速、轻量级网络设计、知识蒸馏、应用部署、MNN、NCNN等技术,
若已为CV君其他账号好友请直接私信。