基于PCA和SVM的人脸识别以及MATLAB实现
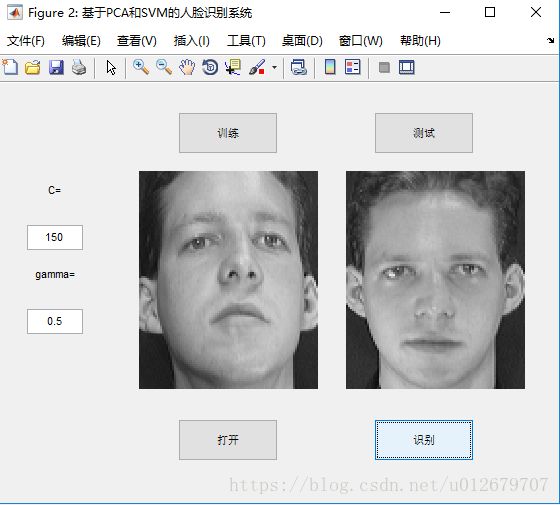
本章利用matlab实现基于PCA和SVM的人脸识别,此章共分为两部分,第一部分为基础知识讲解,第二部分为代码实现(含有本工程下所有代码)。系统界面如下:
一.什么是人脸识别?
人脸识别技术,就是以计算机为辅助手段,从静态或动态图像中识别人脸。
本问题中的人脸识别,是给定一幅人物图,利用人脸数据库 来与之进行匹配,判断其是否属于此数据库。若是,给出她所属的类别。
二. 为什么选择人脸作为识别特征来识别?
因为人脸和指纹一样,具有唯一性,可以用来鉴别一个人的身份。
也就是说,我们想要识别一个东西,要选它主要的特征,辨识度区分度高的特征,这样识别结果才可靠。 就像我们要识别一个人,为什么不去识别他的身高,体重,肤色,眼睛大小啥的?因为这些没有独特性,作为数据来说,太普通了,两个人身高体重肤色相同的概率还是很大的,所以不能作为唯一辨识特征。而选择DNA、指纹、虹膜等属性来作为识别一个人特征,就是因为这些属性具有唯一性,这世界上,不会有人和你在这些特征上重样。
三.人脸识别是怎么进行的?
1)找感兴趣区域----从复杂场景中检测并分离出人脸所在的区域;
2)抓特征---抽取人脸识别特征;
3)匹配吧---进行匹配和识别;
四. 为了实现人脸识别,你要做什么?
1)人脸数据库ORL
a) 数据库中的人脸图片一部分用来做训练数据,建立模型。
b) 另一部分可以用来做测试数据,检验识别率。
2)PCA主成分分析来降维
a)为什么要降维?
因为每幅人脸图像包含112*92=10304个像素点,每一行代表一个样本,那维度就是10304维。
如此巨大的维数使得数据处理工作很是艰难,也打消了我们直接利用像素点作为特征值来识别的念头。
b)PCA是什么?它怎么来实现降维的?
PCA是主成分分析(principal component analysis).利用PCA降维去除像素之间的相关性,取出主成分,同时抛弃那些不能为我们提供重要特征信息的分量。
PCA 通过对样本数据中各成分分量(10304维)进行排序,可选出主要成分,构成主成分分量V(n*k)矩阵(k维)且输出降维后的k维矩阵pcaA。
b1) 其中主成分矩阵V 可在 test.m 和 classify.m中直接带入公式求得降维后的矩阵。
b11) test.m中, TestFace = (TestFace-repmat(meanVec, m, 1))*V; %多个样本数据 经过pca变换降维
b12) classify.m中,xNewFace=(xNewFace-meanVec)*V; %单个样本数据 经过PCA变换降维
b2) 其中输出的k维矩阵pcaA将代替 原样本数据 参与后续数据处理,即pcaA成为样本。
3) 数据规格化scaling
a) 数据规格化是什么?
数据规格化又称数据尺度归一化,是指将某一属性的取值范围 投射到一个特定范围之内,例如常用的[0,1]或[-1,+1]归一化。
b) 数据规格化的作用?
b1) 防止那些处于相对较大的数值范围的特征 压倒那些数值范围小的 特征。例如:几个人具有变化范围大的身高(150cm-180cm)以及 变化范围小的体重(50kg-60kg), 数据规格化后,两个属性的变化差异就缩小了,很好的保护了 变化范围小的 属性依旧能对目标识别起到重要作用。
b2) 避免一些数据溢出问题,统一放缩到同一范围,例如,把数据都限定在[-1,+1]区间,让那些大个子也不得不低头。
4)SVM分类识别
a)SVM是什么?
SVM支持向量机(support vector machine)。SVM是一种分类的方法,通过训练数据来建立分类模型,将分类模型用于对测试数据的分类。就相当于是叠了一个黑盒子,然后你往里扔小球(测试数据),他就能把小球分好类。当然前提是,你得用一堆小球(训练数据)去建立这样一个黑盒。
a1) SVMTrain ---通过训练数据来建立分类模型SVMStruct
a2) SVMClassify ---通过模型来对测试数据进行分类识别
b) SVM的优点?
传统模式识别技术只考虑分类器对训练样本的拟合情况,以最小化训练集上的分类错误为目标。然而在缺乏代表性的小训练集情况下,一味降低训练集上的错误,容易导致过度拟合。 这就叫只注重已有的(训练数据),不懂得审时度势,要放眼未来(测试数据)啊大兄弟!
这时候,SVM出现了,她懂得权衡利弊,而不是一味追求完美的训练数据拟合,她呢兼顾了训练误差与测试误差,以求得全局胜利,真是有智慧的女神! 让传统识别技术的屌丝哥哥们望尘莫及啊!
c) SVM的重点?
SVM的重点,在于分类模型的选择和模型参数的选择。
c1) 分类模型:通过控制分类模型的复杂性可以防止过度拟合,因此SVM更偏爱解释数据的简单模型---二维空间中的直线,三维空间中的平面,以及更高维空间中的超平面。
c2) 参数选择:参数选择的依据是-->寻找最优分类超平面,即寻找能成功分开两类样本 且 具有最大分类间隔的最优分类超平面。
d) SVM的技术热点有什么?
核函数:低维无法将两类样本分开时,可采用非线性映射到高维,利用超平面分开。从低维到高维的映射这就用到了核函数,而且核函数很神奇的无需知道具体映射关系就能给你实现某一非线性分类变换后的线性分类,且计算复杂度相较于低维并未增加。这,简直就是个天才函数!核函数。常用核函数有:线性核函数、多项式核函数、径向基核函数、Sigmoid核函数。(知道函数表达式,找出参数,就可带进去直接用了)
SVM推广到多类:因为SVM是一个二分器,她的基本思想是分开两类样本,即只能用于两类样本的分类。若想识别多类,需用到一些策略。常用的策略有:一对多的最大响应策略、 一对一的投票策略、一对一的淘汰策略。
-----------------------------------【代码实现】-------------------------------------------------
下面将我根据教程建立的工程以及敲击的代码块一一奉上,供日后参阅。
建立以专门文件夹FaceRec,地址E:\matlab_2016b_app\bin\FaceRec。
1. E:\matlab_2016b_app\bin\FaceRec\Data 内存放ORL文件。
2. E:\matlab_2016b_app\bin\FaceRec\exportLibSVM 内存放export.m文件,以及由export( )函数生成的txt文件。
function export(strMat,strLibSVM)
%{
name: export()函数
fuction:用于从matlab导出libSVM能够使用的格式(.txt)
此工程要用libSVM的参数选择工具 grid.py,首先需要把数据集 格式化为 grid.py所要求的形式(文本文件)
Input:strMat:源文件名(包括路径),此文件中包含训练数据(traindata)和类标签(trainlabel),该文件可在训练SVM的过程中生成。
注释:MAT-文件, mat数据格式是matlab的数据存储的标准格式。mat文件是标准的 二进制文件,还可以ASCII码形式保存和加载。
strLibSVM:目标文件名(包含路径),'.txt'文件,默认为‘traindata.txt’
%}
%默认参数设置
if nargin<1
strMat ='E:/matlab_2016b_app/bin/FaceRec/Mat/trainData.mat';
strLibSVM ='E:/matlab_2016b_app/bin/FaceRec/exportLibSVM/trainData.txt';
elseif nargin<2
strLibSVM ='E:/matlab_2016b_app/bin/FaceRec/exportLibSVM/trainData.txt'
end
[fid,fMsg]= fopen(strLibSVM,'w'); %建立输出文件目标,‘w’为写入,若文件不存在,则创建此新文件
if fid==-1
disp(fMsg);
return;
end
strNewLine=[13,10];% 换行。 回车键(软回车)的ASCII码值为13,换行符(硬回车)的值为10; 在windows中换行需要‘软回车+硬回车’!
strBlack=' '; %ASCII码为32(空格)
load(strMat); %load 打开mat文件.例:load('filename','X','Y','Z') 加载filename文件中的X Y Z变量到工作区间中
[nSamp,nDim]=size(TrainData); %nSamp 行数(即为样本个数);nDim(列数),即为样本类数。
for iSamp=1:nSamp
fwrite(fid,num2str (trainLabel(iSamp)),'char' );%写入一个标签(以字符串形式写入)
for iDim=1:nDim
fwrite(fid,strBlack,'char');%fwrite(fid,32,'char');
fwrite(fid,[num2str(iDim) ':'],'char'); %写入列号
fwrite(fid,num2str(TrainData(iSamp,iDim) ),'char'); %写入该位置 的值
end
fwrite(fid,strNewLine,'char'); %换行 fwrite(fid,[13,10],'char');
end
fclose(fid);
3. E:\matlab_2016b_app\bin\FaceRec\Kernel内存放 径向基核函数 kfun_rbf.m文件。
function K=kfun_rbf(U,V,gamma)
%{
name: kfun_rbf(函数)
function: kernel_function-> rbf径向基核函数
radial basis function: exp(-gamma*|u-v|^2)
Input: U:公式中的X矩阵(m1* n1)
V:公式中的Y矩阵(m2 *n2)
gamma; 参数γ(伽马)
Output:K:返回m1*m2维矩阵
SVM 怎样能得到好的结果
1. 对数据做归一化(simple scaling)
2. 应用 RBF kernel
3. 用cross-validation和grid-search 得到最优的c和g
4. 用得到的最优c和g训练训练数据
5. 测试
%}
[m1 n1]=size(U); % m1*n1 %%%%%%%%%%%%%%%%%%%%%%%%%
[m2 n2]=size(V); % m2*n2
K=zeros(m1,m2); % m1*m2矩阵
for ii=1:m1
for jj=1:m2
K(ii,jj)= exp( -gamma * norm(U(ii,:)-V(jj,:) )^2 ); %% rbf函数公式 K(x,y)=exp( -gamma * (x-y)^2 );
end
end4. E:\matlab_2016b_app\bin\FaceRec\Mat内存放 .mat文件,.mat文件中保存有用变量。
5. E:\matlab_2016b_app\bin\FaceRec\PCA 内存放 fastPCA.m文件
function [pcaA V]=fastPCA(A,k)
%{
name: fastPCA()快速PCA函数
function: 将输入样本矩阵降维(k维)
Input:A---样本矩阵,每行为1个样本
k---降维至k维
Output:pcaA---降维后的k维矩阵
V---主成分分量
%}
% A的大小
[m,d]=size(A);
%样本均值
meanVec=mean(A); %计算各列的均值
%计算协方差矩阵的转置 covMatT
Z= ( A-repmat(meanVec,m,1) ); %样本矩阵中心化,每一维度减去该维度的均值,使得每一维度的均值为0
%repmat:Replicate Matrix复制和平铺矩阵
covMatT =Z*Z'; %covMatV :(m*d)*(d*m)=m*m
%计算covMatT的前k个本征值和本征向量
[V D]=eigs(covMatT,k); %V为m*k, k个本征向量; D为k*k,对角线上每一个元素为本征值
%得到协方差矩阵(covMatT')的本征向量
V=Z'*V;
%本征向量归一化为 单位本征向量
for i=1:k
V(:,i)=V(:,i)/norm(V(:,1)); %norm 为范数,默认为2范数(各分量的平方和 再开根号)
end
%线性变换(投影)降维至k维
pcaA=Z*V;
%保存变换矩阵V和变换原点 meanVec
save('Mat/PCA.mat','V','meanVec');
6. E:\matlab_2016b_app\bin\FaceRec\SVM 内存放SVM训练和分类函数 multiSVMTrain.m 和 multiSVMClassify.m文件
6.1 多类问题训练函数 multiSVMTrain
function multiSVMStruct =multiSVMTrain(TrainData,nSamp_PerClass,nClass,C,gamma)
%{
name:multiSVMTrain()函数
function:采用1对1投票 策略 将SVM推广至多类问题的训练过程,将多类SVM训练结果保存至multiSVMStruct中
Input:TrainData--- 训练数据,每行数据代表一个人脸
nClass---类别数(即 列数)
nSamp_PerClass--每一类中的样本数,即 nSamp_PerClass(i)=20,表示第i类有20个数据。
C---错误代价系数,默认为Inf. %Inf为infinite的前三个字母,无穷大的意思。
gamma---径向基函数rbf的gamma参数,默认为1
Output:multiSVMStruct--- 一个包含多类SVM训练结果的结构体
multiSVMStruct.nClass =nClass;
multiSVMStruct.CASVMStruct=CASVMStruct; %共有n*(n-1)/2个CASVMStruct
%}
%默认参数设置
if nargin<4
C=Inf;
gamma=1;
elseif nargin<5
gamma=1;
end
%开始训练,需要计算每两类间的分类超平面,共(nClass-1)*nClass/2个
for ii=1:nClass-1 %注意! 1-> (nClass-1)
% clear X; % X:行数为两类(ii类别和jj类别)的样本数之和;列数等于TrainData的列数 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% startPosII= sum(nSamp_PerClass(1:ii-1) ) +1;
% endPosII= startPosII + nSamp_PerClass(ii) -1;
% X(1:nSamp_PerClass(ii) ,:)=TrainData( startPosII:endPosII,:);
for jj=ii+1:nClass
clear X; % X:行数为两类(ii类别和jj类别)的样本数之和;列数等于TrainData的列数
clear Y;
startPosII= sum(nSamp_PerClass(1:ii-1) ) +1;
endPosII= startPosII + nSamp_PerClass(ii) -1;
X(1:nSamp_PerClass(ii) ,:)=TrainData( startPosII:endPosII,:);
startPosjj= sum(nSamp_PerClass(1:jj-1) ) +1;
endPosjj= startPosjj + nSamp_PerClass(jj) -1;
X(nSamp_PerClass(ii)+1 :nSamp_PerClass(ii)+nSamp_PerClass(jj), : )=TrainData(startPosjj:endPosjj,:);
%设定两两分类时的标签 (列向量,维数等于两类(ii类别和jj类别)的样本数之和)
Y=ones(nSamp_PerClass(ii)+nSamp_PerClass(jj), 1);
Y(nSamp_PerClass(ii)+1:nSamp_PerClass(ii)+nSamp_PerClass(jj),1)=0;
%第ii个类别和第jj个类别的两两分类时的分类器结构信息 %% X的行数等于Y的行数
CASVMStruct{ii}{jj}=svmtrain(X,Y,'Kernel_Function',@(X,Y) kfun_rbf(X,Y,gamma),'boxconstraint',C );
%%%% ‘{ }’大括号,用于cell型数组的分配或引用。比如 A(2,1) = {[1 2 3; 4 5 6]},
%%%% cell 为 细胞型数据结构(cell),)可以使不同类型和不同维数的数组可以共存,细胞型数组实际上可以认为是一种以任意形式的数组为分量的多维数组。
end
end
%已学得的分类结果
multiSVMStruct.nClass =nClass;
multiSVMStruct.CASVMStruct=CASVMStruct;
%保存参数
save('Mat/params.mat','C','gamma'); %保存指定变量(‘C’,'gamma')到指定文件夹.
6.2 多类问题分类函数 multiSVMClassify
function class =multiSVMClassify(TestFace,multiSVMStruct)
%{
name: multiSVMClassify()多类问题分类函数
function: 采用1对1投票策略将SVM推广至多类问题的分类问题
Input:TestFace---测试样本集,m*n维,每行一个样本
multiSVMStruct---多类SVM的训练结果,由函数multiSVMTrain()返回,默认从‘Mat/multiSVMTrain.mat’文件中读取
Output:class---m*1维矩阵,对应TestFace的类标签
%}
%读入训练结果
if nargin<2
t=dir('Mat/multiSVMTrain.mat');
if length(t)==0
error('没有找到训练结果,请在分类前先进行训练');
end
load('Mat/multiSVMTrain.mat');
end
nClass=multiSVMStruct.nClass; %读入类别数
CASVMStruct =multiSVMStruct.CASVMStruct;%%读入两两类之间的分类器信息
%%%%%%%%%%%%%%%%%%%%%%%%投票策略解决多类问题%%%%%%%%%%%%%%%%%%%%
m=size (TestFace,1);
Voting =zeros(m,nClass); %m个测试样本,每个样本有nPerson个类别的投票箱
for i=1:nClass-1
for j=i+1:nClass
classes = svmclassify (CASVMStruct{i}{j} ,TestFace);
%投票
Voting(:,i)=Voting(:,i) +(classes ==1);
Voting(:,j)=Voting(:,j) +(classes==0);
end
end
%根据结果做最后决定
[vecMaxVal, class]= max(Voting,[],2);
% fMsg=sprintf('TestFace对应的类别是%d',class);
% msgbox(fMsg);7. E:\matlab_2016b_app\bin\FaceRec内嗨存放有 classify.m
% classify.m
function nClass =classify(newFacePath)
%{
function:整个分类(识别)过程
Input:newFacePath---待识别图像的存储路径
Output:nClass---识别出的类别标号
%}
disp(' ');
disp(' ');
disp('识别开始... ');
%读入相关训练结果
disp('载入训练参数...');%%%%%%%%%%%%%%%%%%%%%%%%%%%
load('Mat/PCA.mat');
load('Mat/scaling.mat');
load('Mat/trainData.mat');
load('Mat/multiSVMTrain.mat');
disp('载入训练参数完毕....');
% PCA变维
disp('PCA变维....');
xNewFace=ReadOneFace(newFacePath);%读入一个测试样本
xNewFace=double(xNewFace);
%xNewFace=xNewFace* W; %经过PCA变换降维 W
xNewFace=(xNewFace-meanVec)*V; %经过PCA变换降维
xNewFace=scaling(xNewFace,1,A0,B0);
disp('PCA变维完毕....');
disp('身份识别中......');
nClass=multiSVMClassify(xNewFace);
disp('身份识别结束...');
8.编写界面程序FR_GUI.m
% FR_GUI.m
global h_axes1;
global h_axes2;
h_f=figure('name','基于PCA和SVM的人脸识别系统');
%设置 C 和gamma 按钮
h_textC= uicontrol(h_f,'style','text','unit','normalized','string','C=','position',[0.05 0.7 0.1 0.06] );
h_editC= uicontrol(h_f,'style','edit','unit','normalized','position',[0.05 0.6 0.1 0.06], 'callback','C=str2num(get(h_editC,''string''))' );
h_textGamma= uicontrol(h_f,'style','text','unit','normalized','string','gamma=','position',[0.05 0.5 0.1 0.06] );
h_editGamma= uicontrol(h_f,'style','edit','unit','normalized','position',[0.05 0.4 0.1 0.06], 'callback','gamma=str2num(get(h_editGamma,''string''))' );
%取得C和gamma的当前值,即最近一次训练所使用的值
t=dir('Mat/params.mat');
if(length(t) ==0) %没有找到文件
C=Inf;
gamma=1;
else
load('Mat/params.mat');
end
set(h_editC,'string',num2str(C) );
set(h_editGamma,'string',num2str(gamma) );
% axes()函数就是axes的位置,左下宽高,单位是和整个figure宽高的比例
h_axes1=axes('parent',h_f,'position',[0.25 0.23 0.32 0.6],'visible','off');
h_axes2=axes('parent',h_f,'position',[0.62 0.23 0.32 0.6],'visible','off');
h_btnOpen=uicontrol(h_f,'style','push','string','打开','unit','normalized','position',[0.32 0.1 0.18 0.1],'callback','GUIOpenFaceImage' );
h_btnRecg=uicontrol(h_f,'style','push','string','识别','unit','normalized','position',[0.67 0.1 0.18 0.1],'callback','GUIRecgFaceImage' );
h_btnTrain=uicontrol(h_f,'style','push','string','训练','unit','normalized','position',[0.32 0.83 0.18 0.1],'callback','train(C,gamma)' );
h_btnTest=uicontrol(h_f,'style','push','string','测试','unit','normalized','position',[0.67 0.83 0.18 0.1],'callback','test' );
%GUIOpenFaceImage.mglobal filepath;
[filename,pathname]= uigetfile({'*.pgm; *.jpg;*.tif', '(*.pgm),(*.jpg),(*.tif)'; '*.*','All Files(*.*)'}, ...
'Select a face image to be recognized' );
if filename ~=0 % ~= 不等于
filepath =[pathname,filename];
axes(h_axes1); % axes()函数就是axes的位置,左下宽高,单位是和整个figure宽高的比例
% h_axes 为全局变量
imshow(imread(filepath));
end
10. 识别按钮的背后函数 GUIRecgFaceImage.m
%GUIRecgFaceImage.m
nClass= classify(filepath); %filepath 为全局变量
% classify()函数为人为编写的,不是系统带的
msgbox(['所属类别为: ',num2str(nClass) ]);
axes(h_axes2);
f=imread([ 'Data/ORL/S',num2str(nClass), '/1.pgm'] );%打开该人的第一幅图像
imshow( f);11.读入多个人脸数据样本 ReadFaces.m
function [imgRow,imgCol,FaceContainer,faceLabel] = ReadFaces (nFacesPerPerson,nPerson,bTest)
%{
name: ReadFaces()读取人脸图像
function: 将人脸图像(每张112*92像素点)转换为向量形式(10304*1 向量),进而组成样本矩阵(nPerson *10304矩阵)
Input:nFacesPerPerson---每个人需要读入的人脸图像样本数目(默认为5张(训练或测试) )
nPerson---需要读入的人数(默认为40人)
bTest---bool型参数,默认为0(表示读入训练样本,即每人的前5张);如果为1,表示读入测试样本(后5张)
Output:FaceContainer---向量化后的人脸容器,nPerson * 10304的2维矩阵,每行对应一个人脸向量
%}
%默认值设置
if nargin==0 %default value
nFacesPerPerson =5;
nPerson=40;
bTest=0;
elseif nargin<3
bTest=0; % 读入训练样本
end
% 为计算尺寸先读入一张,计算出大小
img=imread('Data/ORL/S1/1.pgm'); %S1表示第一个人,1.pgm表示(此人的)第一张图像
[imgRow,imgCol]=size(img);
%转换目标容器
FaceContainer =zeros(nFacesPerPerson *nPerson,imgRow*imgCol); %(200*10304)
faceLabel =zeros(nFacesPerPerson*nPerson,1); %(200*1)
%读入训练数据
for i=1:nPerson
i0=char(i/10); % 表示第i0个人的图像(一个人有10张),0->i-1; i0=int(i/10);
i1=mod(i,10); %取模,表示第i0个人的第i1张图像
strPath='Data/ORL/S';%图像路径
if (i0~=0) %%%%%%%%但此处理只能最大是99个人,若为100人,则此法不能写出S100!!
strPath =strcat(strPath,'0'+i0);%用于s后为多位数时的处理, 例 'Data/ORL/S11'
end
strPath =strcat(strPath,'0'+i1); %字符串连接 变为 'Data/ORL/Si1'
strPath =strcat(strPath,'/'); %'Data/ORL/Si1 / '
tempStrPath=strPath;%暂存图像路径,因为后边要区分训练样本(前五张)和测试样本(后五张)
for j=1:nFacesPerPerson
strPath=tempStrPath;
if bTest==0 %读入训练数据
strPath=strcat(strPath,'0'+j); %1->5 %'Data/ORL/Si1 /j '
else
strPath=strcat(strPath,num2str(j+5) ); %6->10 % 等价于j+5+'0'
end
strPath=strcat(strPath,'.pgm');
img=imread(strPath);
%把读入的图像按列 存储为行向量 放入向量化人脸容器 faceContainer 的对应行中
FaceContainer ((i-1)*nFacesPerPerson +j,:)= img(:)' ; % 按列 存储的 行向量(最终)
% img(:)的返回值为按列存储的一维列向量,即原先的112*92矩阵,变为10304*1的列向量
% img(:)'转置后为1*10304的行向量
faceLabel((i-1)*nFacesPerPerson +j)=i;
end
end
%保存人脸样本矩阵
%save('Mat/FaceMat.mat','FaceContainer');
12. 读入当个人脸样本 ReadOneFace.m
function face=ReadOneFace(dir)
%{
function:根据指定目录只读入一张人脸图片
Input;dir---指定目录
Output:face---返回行向量向量,人脸图片按列存储在行向量里
%}
img=imread(dir);
[imgRow imgCol]=size(img); %112*92
face=zeros(1,imgRow*imgCol);
face=img(:)';
13. 数据规格化 scaling.m
function [SVFM,lowVec,upVec]= scaling(VecFeaMat,bTest, lRealBVec,uRealBVec)
%{
name: scaling()函数;
function:特征数据规格化(归一化),线性缩放特征的各个属性(维度)到【-1,+1】
Input: VecFeaMat ---需要scaling的m*n维数据矩阵(可能为训练集,可能为测试集),每行一个样本特征向量,列数为维数;
bTest--- =1,说明是对样本进行scaling,此时必须提供lRealBVec,upRealBVec这两个参数的值(应从对训练样本的scaling中得到)
lRealBVec --- n*1矩阵(即列向量),对训练样本scaling时得到的 各维的实际下限信息lowVec(lRealBVec(i)代表第i列中最小的那个值)
upRealBVec --- n*1矩阵(即列向量),对训练样本scaling时得到的 各维的实际上限信息lowVec
Output:SVFM---VecFeaMat经scaling之后的样本(m*n)
lowVec----(1*n矩阵 ,即行向量)各维特征的下限(只在对训练样本scaling时有意义,即bTest=0时)
upVec ----(1*n矩阵 ,即行向量)各维特征的上限(只在对训练样本scaling时有意义,即bTest=0时)
%}
if nargin<2 %缺省参数的默认设置
bTest =0; %默认为bTest=0(即对训练样本进行scaling)
end
%缩放目标范围[-1,+1]
lTargB=-1;
uTargB=+1;
[m n]=size(VecFeaMat);
SVFM=zeros(m,n);
if bTest %对test数据进行scaling
if nargin <4 %(输入参数缺省)
error('To do scaling on testset,param lRealB and uRealB are needed.');
end
if nargout >1
error('When do scaling on testset,only one output is supported.');
end
for iCol =1:n
if uRealBVec(iCol)== lRealBVec(iCol) %即当列最大值 最小值相等
SVFM(:,iCol)=uRealBVec(iCol); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
SVFM(:,iCol)=0;
else %test数据 规格化(归一化)
SVFM(:,iCol)= lTargB +(VecFeaMat(:,iCol) - lRealBVec(iCol))/( uRealBVec(iCol)- lRealBVec(iCol))*(uTargB-lTargB);
end
end
else %对训练集数据 进行scaling.需要返回lowVec,upVec
upVec=zeros(1,n); %行向量
lowVec=zeros(1,n);
for iCol=1:n
lowVec(iCol)=min( VecFeaMat(:,iCol) );
upVec(iCol)=max( VecFeaMat(:,iCol) );
if upVec(iCol)==lowVec(iCol)
SVFM(:,iCol)=upVec(iCol); %%%%%%%%%%%%%%%%%%%%%%%%%%%%
SVFM(:,iCol)=0;
else
SVFM(:,iCol)= lTargB +(VecFeaMat(:,iCol) - lowVec(iCol) )/( upVec(iCol)- lowVec(iCol))*(uTargB-lTargB);
end
end
end
14.测试对于整个测试集的正确率 test.m
function test()
% 测试对于整个测试集的识别率
%
% 输出:accuracy --- 对于测试集合的识别率
display(' ');
display(' ');
display('测试开始...');
nFacesPerPerson = 5;
nPerson = 40;
bTest = 1;
% 读入测试集合
display('读入测试集合...');
[imgRow,imgCol,TestFace,testLabel] = ReadFaces(nFacesPerPerson, nPerson, bTest);
display('..............................');
% 读入相关训练结果
display('载入训练参数...');
load('Mat/PCA.mat');
load('Mat/scaling.mat');
load('Mat/trainData.mat');
load('Mat/multiSVMTrain.mat');
display('..............................');
% PCA降维
display('PCA降维处理...');
[m n] = size(TestFace);
TestFace = (TestFace-repmat(meanVec, m, 1))*V; % 经过pca变换降维
TestFace = scaling(TestFace,1,A0,B0);
display('..............................');
% 多类 SVM 分类
display('测试集识别中...');
classes = multiSVMClassify(TestFace);
display('..............................');
% 计算识别率
nError = sum(classes ~= testLabel);
accuracy = 1 - nError/length(testLabel);
display(['对于测试集200个人脸样本的识别率为', num2str(accuracy*100), '%']);15. 整个训练过程train.m
function:整个训练过程
step: 1)读取人脸数据(readFaces),保存至Mat/FaceMat.mat
2)将fastPCA变换矩阵W(主分量阵)保存至Mat/PCA.mat
2)将scaling的各维上、下界信息保存至Mat/scaling.mat
3)将PCA降维并且scaling后的数据保存至Mat/trainData.mat
4)将多类SVM训练信息保存至Mat/multiSVMTrain.mat
function train(C,gamma)
%{
name: train()函数
function:整个训练过程
step: 1)读取人脸数据(readFaces),保存至Mat/FaceMat.mat
2)将fastPCA变换矩阵W(主分量阵)保存至Mat/PCA.mat
2)将scaling的各维上、下界信息保存至Mat/scaling.mat
3)将PCA降维并且scaling后的数据保存至Mat/trainData.mat
4)将多类SVM训练信息保存至Mat/multiSVMTrain.mat
%}
global imgRow;
global imgCol;
disp(' ');
disp(' ');
disp('训练开始...');
nPerson=40;
nFacesPerPerson=5;
disp('读入人脸数据...');
[imgRow,imgCol,FaceContainer,faceLabel]=ReadFaces(nFacesPerPerson,nPerson);
save('Mat/FaceMat.mat','FaceContainer');
disp('读入完毕...');
nFaces=size(FaceContainer,1); %样本(人脸)数目
disp('PCA降维...');
[pcaFaces,W]=fastPCA(FaceContainer,20); %快速主成分分析(内含保存操作)
% pcaFaces:200*20矩阵,每行一个样本(每人5张,共40人)
% W:分离变换矩阵,10304*20 (用于显示主成分脸)
%visualize_pc(W); %显示主成分脸
%save('Mat/PCA.mat','W');
disp('降维完毕...');
X=pcaFaces;
disp('scaling...');
[X,A0,B0]=scaling(X); %训练样本
save('Mat/scaling.mat','A0','B0');
disp('scaling完毕...');
%保存scaling后的训练数据至trainData.mat
TrainData=X;
trainLabel=faceLabel;
save('Mat/trainData.mat','TrainData','trainLabel');
export(); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
disp('保存trainData.mat完毕...');
for iPerson=1:nPerson
nSplPerClass(iPerson) =sum( (trainLabel == iPerson) );
end
multiSVMStruct =multiSVMTrain(TrainData,nSplPerClass,nPerson,C,gamma);
disp('正在保存训练结果...');
save('Mat/multiSVMTrain.mat','multiSVMStruct');
disp('训练结束');