数据库 - SQL语言(一)
文章目录
-
- 一,SQL数据定义
- 二,基本数据类型
- 三,基本模式定义
-
- 1,CREATE TABLE 命令
- 2,修改模式(Uptable Date Table)
-
- drop table 命令
- alter table 命令
- 四,基本查询结构
-
- 1,SQL查询的基本结构
-
- select 子句
- where 子句
- from 语句
- 2,更名运算(as 子句)
- 3,字符串运算(like)
- 4,排列元组的显示次序(order by)
- 5,重复
- 6,集合运算(union、intersec、except)
-
- union 并集
- intersec 交集
- except 差集
- 7,聚集函数(Aggregate Functions)
-
- 聚集函数 - 平均(avg)
- 分组聚集(group by)
- having 子句
- 8,空值
-
- 空值的判断
- 空值的处理
- 五,嵌套子查询(Nested Subqueries)
-
- 1,集合成员资格(连接词 in)
- 2,集合的比较(some,all子句)
-
- some 子句 - 至少比某一个...
- all 子句 - 比所有都...
- 3,空关系测试(exists结构)
- 4,重复元组存在性测试(nuique结构)
- 5,from子句中的子查询
- 6,定义临时关系(with子句)
- 六,数据库的修改
-
- 删除(delete from)
- 插入(insert into)
- 更新(update语句)
- 七,总结
- 八,SQL语言(二)
- 九,SQL语言(三)
- 十,SQL语言(四)
一,SQL数据定义
(Data Definition Language)
数据库中的关系集合必须由数据定义语言(DDL)指定给系统。
例:
CREATE TABLE instructor(
ID char(5),
name varchar(20) not null,
dept_name varchar(20),
primary key (ID));
参见:
super-key
candidate key
primary key
SQL的DDL不仅能够定义一组关系,还能够定义每个关系的信息,包括:
- 每个关系模式
- 每个属性的取值类型
- 完整性约束
- 每个关系维护的索引集合
- 每个关系在磁盘上的物理存储结构
二,基本数据类型
(Domain Types in SQL)
- char(n):固定长度为 n 的字符串
- varchar(n):最大长度为 n 的,可变长度字符串
- int:整数类型(和机器相关的整数类型的子集),等价于全程 integer
- smallint:小整数类型(和机器相关的整数类型的子集)
- numeric(p,d):定点数(这个数有 p 位,其中第 d 位数在小数点的右边)
- real,double precision:浮点数与双精度浮点数,精度与机器其相关
- float(n):精度至少为 n 位的浮点数
- null:每种类型都可以包含一个特殊值,即空值。可以申明属性值不为空,禁止加入空值。
- data:日期,含 年 月 日,如“1999-02-03”
- time:时间,含 时 分 秒,如“12 : 28 : 15.07”’
- timestamp:日期 + 时间,如“1999-02-03 12 : 28 : 15.07”
SQL中有许多函数,用于处理各种类型的数据及其类型转换,但各数据库中函数的标准化程度不同

三,基本模式定义
1,CREATE TABLE 命令
我们用 create table 命令定义SQL关系:
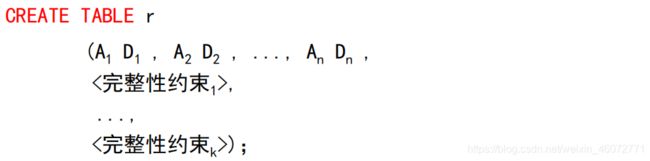
其中,r 是关系名,每个 Ai 是关系 r 模式中的一个属性名,Di 是属性 Ai 的域
SQL支持许多不同的完整性约束。
- not null:一个属性上的 not null 约束表明在该属性上不许为空值
- 主键 primary key(A1, … ,An):表明属性 A1, … ,An 构成关系的主码。主码属性必须非空且唯一。
- 外码 foreign key(A1, … ,Am)references (s):声明表示关系中任意元组的属性上 A1, … ,Am 上的取值必须对应关系 s 中某元组的主码属性上的取值
- check(P):P 是谓语条件
举例:声明 ID 为 instructor 的主码,并确保 salary 的值非负
方法一
CREATE TABLE instructor(
ID char(5),
name varchar(20) not null,
salary numeric(8,2),
primary key (ID),
check (salary >= 0));
方法二
CREATE TABLE instructor(
ID char(5) primary key,
name varchar(20) not null,
salary numeric(8,2),
check (salary >= 0));
举例:关于 foreign key(A1, … ,Am)references (s)
定义外码(dept_name),参照关系s
create table student (
ID varchar(5),
name varchar(20) not null,
dept_name varchar(20),
tot_cred numeric(3,0),
primary key (ID),
foreign key (dept_name) references department);
create table takes (
ID varchar(5),
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4,0),
grade varchar(2),
primary key (ID, course_id, sec_id, semester, year) ,
foreign key (ID) references student,
foreign key (course_id, sec_id, semester, year) references section);
2,修改模式(Uptable Date Table)
drop table 命令
用于从数据库中删除关于被去掉关系的所有信息
- drop table r
例:将 关系instructor “满门抄斩”
drop table instructor;
alter table 命令
- alter table r add A D
为已有关系(r),增加属性(A,域为 D)
关系中所有元组在新属性上取值被设定为 null
例:在 关系instructor 中加入 birthday属性(日期)
alter table instructor add birthday date;
- alter table r drop A
从关系 r 中,去掉属性 A(但很多数据库系统不支持此操作)
例:从 关系instructor 中删除 birthday属性
alter table instructor drop birthday;
- alter table r modify (A D);
还可以用来修改关系中的属性
例:修改 instructor关系中的 ID属性
alter table instructor modify (ID char(10));
四,基本查询结构
(Basic Query Structure of SQL Queries)
1,SQL查询的基本结构
SQL查询的基本结构由3个子句构成:select,from,where

select 子句
- 基本方法,找出指定内容
例:找出所有教师的名字
select name
from instructor;
![]()
注意:SQL不允许在属性名称中使用 “–”,但可以使用“_”,例:dept_name
且SQL中是不区分字母大小写的!
SQL允许在关系以及SQL表达式中出现的重复的元组
- 若要去除重复,可在select后加关键词distinct
例:查询 instructor 中所有的系名,并去除重复
select distinct dept_name
from instructor;
- 也可以使用关键词 all 来指明保留重复(SQL默认就是 all)
例:只找出所有系名
select all dept_name
from instructor;
- 星号 “ * ”,在 select子句中表示所有属性
例:选出 instructor关系中的所有属性
select *
from instructor;
- select子句还可以带有 + - * / 运算符的算术表达式,运算对象可以是常数或元组的属性
例:将 instructor关系中的属性salary (x1.05倍)
select ID,name,salary*1.05
from instructor;
where 子句
- 只选出满足给出标准的元组
例:找出所有 在数学系 且 工资超过100元 的教授
select name
from instructor
where dapt_name = ‘MATH’ and salary > 100;

- where子句中可以使用逻辑连词(and,or,not)也可使用between指定范围查询。逻辑连词的运算对象可以包含比较运算符(>,<,=,>=…)
例:找出工资在 900 ~ 1000元之间的 教师姓名
方法一:使用between关键字
select name
from instructor
where salary between 900 and 1000;
方法二:使用逻辑连词
select name
from instructor
where salary <= 1000 and salary >=900;
from 语句
指定查询求值中需要访问的关系列表,通过from子句定义了一个该子句所列出关系上的笛卡尔积
例一:查找出 instructor 和 teachers 的笛卡尔积
select *
from instructor,teachers;
例二:找出数学系的教师名和课程标识(course_name)
已知:

select name, course_name
from instructor, teachers
where instructor.ID = teachers.ID and instructor.dept_name = 'MATH'
2,更名运算(as 子句)
为关系和属性重新命名的机制,即使用 as子句
语法: old_name as new_name
注意:as子句,即可在select子句中出现的也可以在from子句中出现的。
使用更名运算对属性重命名
例一:刚刚考虑的查询,将name重命名为instructor_name
select name as instructor_name, course_name
from instructor, teachers
where instructor.ID = teachers.ID and instructor.dept_name = 'MATH'
使用关系运算对关系重命名
例二:找出所有教师,以及他们所有课程的标识
select T.name and S.sourse_id
from instructor as T, teachers as S
where T.ID = S.ID;
(为了引用简洁) ↑
例三:找出工资高于化学系工资最低标准的教师姓名
select T.name and S.sourse_id
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = 'Biology';
(为了区分) ↑
3,字符串运算(like)
对字符串进行最通常的操作是使用操作符like的模式匹配,使用以下两个字符来描述模式:
- 百分号(%):匹配任意子串
- 下划线(_):匹配任意一个字符
- ‘ _ _ _ ’:匹配任何三个字符的字符串
- ‘ _% ’:匹配任何由一个字符开头的字符串
- ‘ %happy% ’:匹配任何位置包含happy的字符串
例:找出所有建筑名称包含Waston的所有系名
select dept_name
from department
where building like '%Waston%';
例:找出所有建筑名称开头为Waston的所有系名
select dept_name
from department
where building like 'Waston%';
在like比较运算中,使用escape关键词来定义转义字符
例:使用 ‘ \ ’ 为转义字符

SQL还允许在字符串上有多种函数
例如:
> 串联(“||”)
> 提取子串
> 计算字符串长度
> 大小写转换(用upper(s)将字符串s 转换为大写或用lower(s)将字符串s 转换为小写)
> 去掉字符串后面的空格(使用trim(s))
4,排列元组的显示次序(order by)
SQL为用户提供了一些对关系中元组显示次序的控制。order by子句就可以让查询结果中元组按排列顺序显示
(默认使用升序 asc)
例:按名字的字母顺序排列所有数学系的老师
select name
from instructor
where dept_name = 'Math'
order by name;
要说明排序顺序,我们可以用desc表示降序,或者用asc表示升序(默认项)
例:按工资的降序列出整个instructor关系,如果有工资相同的教师,就将他们按姓名升序排列
select *
from instructor
order by salary desc, name asc;
5,重复


6,集合运算(union、intersec、except)
SQL作用在关系上的union、intersect和except运算对应于数学集合论中的![]()
union、intersect和except运算与select子句不同,它们会自动去除重复
如果想保留所有重复,必须用union all、intersect all和except all

补充:
在Oracle中,支持union,union ALL,intersect和Minus;但不支持Intersect ALL和Minus ALL
在SQL Server 2000中,只支持union和union ALL
union 并集
![]()
例:找出在2009年秋季开课,或者在2010年春季开课或两个学习都开课的所有课程
思路:2009年秋季开课 union 2010年春季开课
(select course_id
from section
where semester =‘Fall’and year = 2009)
union
(select course_id
from section
where semester =‘Spring’and year = 2010);
intersec 交集
例:找出在2009年秋季和2010年春季同时开课所有课程
思路:2009年秋季开课 intersec 2010年秋季开课
(select course_id
from section
where semester =‘Fall’and year = 2009)
intersect
(select course_id
from section
where semester =‘Spring’and year = 2010);
except 差集
例:找出在2009年秋季开课,但不在2010年春季开课的所有课程
思路:2009年秋季开课 except 2010年春季开课
(select course_id
from section
where semester =‘Fall’and year = 2009)
except
(select course_id
from section
where semester =‘Spring’and year = 2010);
7,聚集函数(Aggregate Functions)
聚集函数是以值的一个集合(集或多重集)为输入,返回单个值的函数。
SQL提供了五个固有聚集函数:
平均值:avg ()
最小值:min ()
最大值:max ()
总和:sum ()
计数:count()
其中,sum和avg的输入必须是数字集,但其他运算符还可作用在非数字数据类型的集合上,如字符串
除了上述的五个基本聚集函数外,还有分组聚集(group by)。group by子句中给出的一个或多个属性是用来构造分组的,在group by子句中的所有属性上取值相同的元组将被分在一个组中
having子句类似于where子句,但其是对分组限定条件,而不是对元组限定条件。having子句中的谓词在形成分组后才起作用,因此可以使用聚集函数
聚集函数 - 平均(avg)
其他四种用法类似
例:找出数学系教师的平均工资
select avg(salary) as avg_salary
from instructor
where dept_name = 'Math';

分组聚集(group by)
注意:任何没有出现在group by子句中的属性,如果出现在select子句中的话,它只能出现在聚集函数内部,否则这样的查询就是错误的!
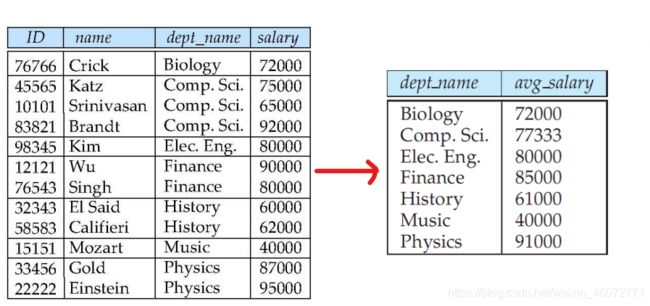
例:找出每个系的平均工资
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name ;
having 子句
注意:与select子句的情况类似,任何出现在having子句中,但没有被聚集的属性必须出现在group by子句中,否则这样的查询就是错误的!
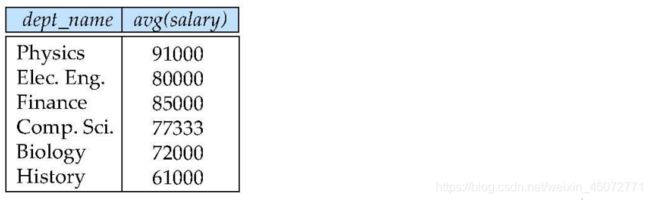
例:找出平均工资超过 42000元的系
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name
having avg(salary)>42000;
8,空值
空值的判断
SQL允许使用null值表示属性值信息缺失。
我们在谓词中可以使用特殊的关键词null测试空值,也可以使用is not null测试非空值
例:找出instructor关系中元组在属性salary上取空值的教师名
select name
from instructor
where salary is null;
空值的处理
空值的存在给聚集运算的处理也带来了麻烦。聚集函数根据以下原则处理空值:
- 除了count(*)外所有的聚集函数都忽略输入集合中的空值
- 规定:空集的count运算值为0,其他所有聚集运算在输入为空集的情况下返回一个空值
例:计算所有教师的工资总和
select sum(salary)
from instructor;
sum运算符会忽略输入中的所有空值。
如果,instructor关系中所有元组在salary上的取值都为空,则sum运算符返回的结果即为null。
涉及 null 的任何算数式的结果均为 null
Example:5 + null return null
任何与null的比较得回 unknown
Example:5 < null or null <> null or null = null
all return unknown
where子句中的谓语可以涉及逻辑运算(and,or,not),因此,逻辑运算的定义需要扩展以处理unknown值
and:
- (true and unknown) = unknown
- (false and unknown) = false
- (unknown and unknown) = unknown
or:
- (unknown or true) = true
- (unknown or false) = unknown
- (unknown or unknown) = unknown
计算结果为unknown的wehere子句,其结果被视为false
五,嵌套子查询(Nested Subqueries)
SQL提供嵌套子查询机制。
子查询是嵌套在另一个查询中的select-from-where表达式。子查询嵌套在where子句中,通常用于对集合的成员资格、集合的比较以及集合的基数进行检查。
主要用于:
- 集合成员资格
- 集合的比较
- 空关系测试
- 重复元组存在性测试
- from子句中的子查询
- with子句
1,集合成员资格(连接词 in)
(Set Membership)
由连接词 in 测试,是否是集合中的成员,
对应还有 not in
例一:找出在2009年秋季和2010年春季学期同时开课的所有课程
思路:(2009年秋季开课)中那些是(2010年春季学期开课)的成员
select distinct course_id
from section
where semester =‘Fall’and year= 2009 and
course_id in (select course_id
from section
where semester =‘Spring’and year= 2010);
例二:找出(不同的)学生总数,他们选修了ID为10101的教师所讲授的课程
select count(distinct ID)
from takes
where (course_id, sec_id, semester, year)
in (select course_id, sec_id, semester, year
from teaches
where teaches.ID = 10101);
Note:上述查詢可以寫成一個更簡單的方式,上述方法只是為了說明 SQL功能。
2,集合的比较(some,all子句)
some 子句 - 至少比某一个…
考虑查询“找出满足下面条件的所有教师的姓名,他们的工资至少比Biology系某一个教师的工资要高”,在前面,我们将此查询写作:
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name =‘Biology’;
但是SQL提供另外一种方式书写上面的查询。短语“至少比某一个要大”在SQL中 用>some表示,则此查询还可写作:
select name
from instructor
where salary > some (select salary
from instructor
where dept_name =‘Biology’);

all 子句 - 比所有都…
考虑查询“找出满足下面条件的所有教师的姓名,他们的工资比Biology系每个教师的工资都高”
在SQL中,结构>all对应于词组“比所有的都大”,则:
select name
from instructor
where salary > all(select salary
from instructor
where dept_name =‘Biology’);

例:找出平均工资最高的系
思路:A 的avg(工资)比所有都大
select dept_name
from instructor
group by dept_name
having avg (salary) >= all (select avg (salary)
from instructor
group by dept_name);
3,空关系测试(exists结构)
SQL还有一个特性可测试一个子查询的结果中是否存在元组。exists结构在作为参数的子查询不为空时返回true值

我们还可以使用not exists结构模拟集合包含(即超集)
操作:可将“关系A包含关系B”写成“not exists(B except A)”
即“B - A为空集合”
例:找出在2009年秋季学期和2010年春季学期同时开课的所有课程使用exists结构,重写该查询
select course_id
from section as S
where semester =‘Fall’and year = 2009 and
exists(select *
from section as T
where semester =‘Spring’and year= 2010 and S.course_id = T.course_id );
例:找出选修了Biology系开设的所有课程的学生
使用except结构写该查询
思路:(在Biology系开设的所有课程集合 – 每一位学生选修的所有课程集合) 所生成的集合为空集,则说明该学生选修了Biology系开设的所有课程
select distinct S.ID, S.name
from student as S
where not exists ((select course_id
from course
where dept_name = ‘Biology’)
except
(select T.course_id
from takes as T
where S.ID = T.ID));
![]()
4,重复元组存在性测试(nuique结构)
SQL提供一个布尔函数,用于测试在一个子查询的结果中是否存在重复元组。如果作为参数的子查询结果中没有重复的元组unique结构将返回true值
例:找出所有在2009年最多开设一次的课程
select T.course_id
from course as T
where unique (select R.course_id
from section as R
where T.course_id = R.course_id and R.year = 2009);
也可以将上述查询语句中的 unique 换成 1>=
例:找出所有在2009年最少开设两次的课程
select T.course_id
from course as T
where not unique (select R.course_id
from section as R
where T.course_id = R.course_id and R.year = 2009);
注意:unique, not unique 在oracle8,sql server7中不支持
5,from子句中的子查询
SQL允许在from子句中使用子查询表达式。
任何select-from-where表达式返回的结果都是关系,因而可以被插入到另一个select-from-where中任何关系可以出现的位置
例一:找出系平均工资超过42 000美元的那些系中教师的平均工资。
思路:在前面的聚集函数中,我们使用了having写此查询。现在,我们用在from子句中使用子查询重写这个查询
select dept_name, avg_salary
from (select dept_name, avg(salary)
from instructor
group by dept_name) as dept_avg (dept_name, avg_salary)
where avg_salary > 42000;
相当于建立局部视图,上述例子的局部视图为【dept_avg (dept_name, avg_salary)】关系名为dept_avg(包含两个属性,分别为dept_name, avg_salary)
例二:找出在所有系中工资总额最大的系
在此,having子句是无能为力的。但我们可以用from子句的子查询轻易地写出如下查询:
select max(tot_salary)
from (select dept_name, sum(salary)
from instructor
group by dept_name) as dept_total(dept_name, tot_salary);
上述局部视图为【dept_total(dept_name, tot_salary)】其中属性tot_salary是以dept_name分组求sum的数据
6,定义临时关系(with子句)
with子句提供定义临时关系的方法,这个定义只对包含with子句的查询有效
例一:找出具有最大预算值的系
定义临时关系
with max_budget(value) as (select max(budget)
from department)
使用临时关系
select budget
from department, max_budget
where department.budget = max_budget.value;
例二:找出工资总额大于平均值的系
with dept_total(dept_name, value) as (select dept_name, sum(salary)
from instructor
group by dept_name),
dept_total_avg(value) as (select avg(value)
from dept_total)
定义两个临时关系:
每个系的工资总和【dept_total (dept_name, value)】
所有系的平均工资【dept_total_avg (value)】
select dept_name
from dept_total as A, dept_total_avg as B
where A.value >= B.value ;
六,数据库的修改
除了数据库信息的抽取外,SQL还定义了增加、删除和更新数据库信息的操作
删除(delete from)
删除请求的表达与查询非常类似。我们只能删除整个元组,而不能只删除某些属性上的值。SQL用如下语句表示删除:
delete from r
where P;
代表,从关系 r 中删除满足条件 P 的元组
例一:从instructor关系中删除与Finance系教师相关的所有元组
delete from instructor
where dept_name = 'Finance';
例二:从instructor关系中删除所有这样的教师元组,他们在位于Watson大楼的系工作
delete from instructor
where dept_name in (select dept_name
from department
where building =‘Watson’);
例三:删除工资低于大学平均工资的教师记录
delete from instructor
where salary < (select avg(salary)
from instructor);
问题:当我们从instructor关系中删除元组时,平均工资就会改变
SQL中的解决方案:
― 首先,计算出平均工资,并找出要删除的所有元组
― 然后,删除上述找到的所有元组(不重新计算平均工资,也不重新测试元组是否符合删除条件)
― 在同一SQL语句内,除非外层查询的元组变量引入内层查询,否则内层查询只进行一次
我的解决办法(不知道对不对,望大佬批改)
with del_tuple(name) as (select name
from instructor
where salary < (select avg(salary)
from instructor);
delete from instructor
where name in (select *
from del_tuple);
插入(insert into)
SQL允许使用insert语句,向关系中插入元组,形式如下:
插入新的内容
insert into r [(c1,c2,…)]
values (e1,e2,…);
从其他关系插入至次关系
insert into r [(c1,c2,…)]
select e1,e2,…
from …;
例一:假设我们要插入的信息是Computer Science系开设的名为“Database Systems”的课程,代码为CS-437,它有4个学分
insert into course
values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
SQL允许在insert语句中指定属性,所以上述语句还可写为:
insert into course (course_id, title, dept_name, credits)
values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
若上例中, Database Systems”课程的学分未知,插入语句还可写为:
方法1:直接将其定义为 null
insert into course
values ('CS-437', 'Database Systems', 'Comp. Sci.',null);
方法2:当给出不完整的属性列表时,缺失部分会自动补为 null
insert into course (course_id, title, dept_name)
values ('CS-437', 'Database Systems', 'Comp. Sci.');
例二:假设我们想让Music系每个修满144学分的学生成为Music系的教师,其工资为18 000美元
insert into instructor
select ID, name, dept_name, 18000
from student
where dept_name = 'Music' and tot_cred > 144;
下句中的 18000 使用了泛化投影,表示 salary = 18000
select ID, name, dept_name, 18000
更新(update语句)
SQL允许使用update语句,在不改变整个元组的情况下改变其部分属性的值,形式如下:
update r
set <c1=e1 ,[c2=e2,… ]>
[where <condition>] ;
例一:假设给工资超过100 000美元的教师涨3%的工资,其余教师涨5%
我们可以写两条update语句
update instructor
set salary = salary * 1.03
where salary > 100000;
update instructor
set salary = salary * 1.05
where salary <= 100000;
注意:这两条update语句的顺序十分重要。如果调换顺序,可能导致工资略少于100 000美元的教师将增长8%的工资。
针对上例查询,我们也可以使用SQL提供的case结构,避免更新次序引发的问题,形式如下:
case
when pred1 then result1
when pred2 then result2
. . .
when predn then resultn
else result0
end
因此上例查询可重新为:
update instructor
set salary = case
when salary <= 100000 then salary * 1.05
else salary * 1.03
end
例二: 为所有学生重新计算和更新tot_creds值
update student as S
set tot_cred = (select sum(credits)
from takes, course
where takes.course_id = course.course_id and S.ID = takes.ID.and takes.grade <> 'F' and takes.grade is not null);
例三: 对未参加任何课程的学生设置tot_creds为空
update student
set tot_creds = case
when sum(credits) is not null then sum(credits)
else 0
end
七,总结
SQL查询语句的通用形式:
select <[distinct] c1,c2,…>
from <r1,…>
[where <condition>]
[group by <c1,c2,…> [having <cond2>] ]
[order by <c1[desc] ,[c2[desc|asc],…]>
-
SQL查询语句执行顺序:
from → where →group (aggregate) →having →select →order by -
SQL支持关系上的基本集合运算,包括并、交、和差运算
-
SQL支持聚集,可以把关系进行分组,还支持在分组上的集合运算
-
SQL支持在外层查询的where和from子句中嵌套子查询
-
SQL提供了用于更新、插入、删除信息的结构
(2020 - 3 - 26 星期四 数据库初学)
(2020年4月11日23:26:14 复习1)
八,SQL语言(二)
传送门:SQL 语言(二)
内容预览:
- 视图(View)
- 索引(Index)
九,SQL语言(三)
传送门:SQL语言(三)
内容预览:
- 事务(transaction)
- 完整性约束
- 断言(Assertion)
- 触发器(Trigger)
- 数据安全性
- 审计跟踪(Audit trail)
十,SQL语言(四)
传送门:SQL语言(四)
内容预览:
- 嵌入式SQL
- 开放数据库互连(ODBC)